 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Score-based Continuous-time Discrete Diffusion Models
Nov 30, 2022



Score-based modeling through stochastic differential equations (SDEs) has provided a new perspective on diffusion models, and demonstrated superior performance on continuous data. However, the gradient of the log-likelihood function, i.e., the score function, is not properly defined for discrete spaces. This makes it non-trivial to adapt \textcolor{\cdiff}{the score-based modeling} to categorical data. In this paper, we extend diffusion models to discrete variables by introducing a stochastic jump process where the reverse process denoises via a continuous-time Markov chain. This formulation admits an analytical simulation during backward sampling. To learn the reverse process, we extend score matching to general categorical data and show that an unbiased estimator can be obtained via simple matching of the conditional marginal distributions. We demonstrate the effectiveness of the proposed method on a set of synthetic and real-world music and image benchmarks.
Dynamics of Finite Width Kernel and Prediction Fluctuations in Mean Field Neural Networks
Apr 06, 2023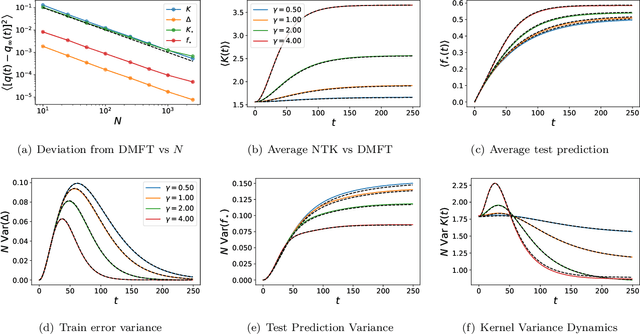

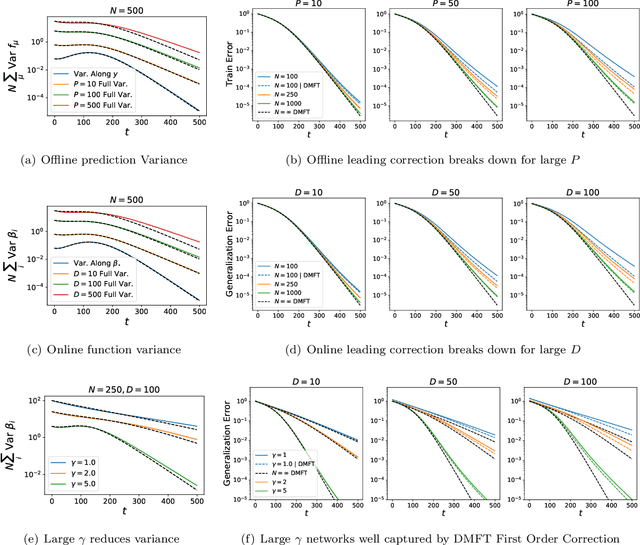
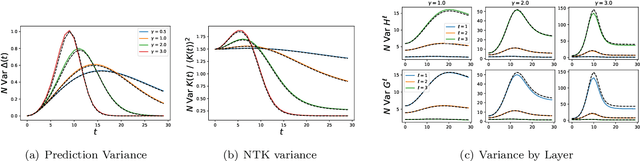
We analyze the dynamics of finite width effects in wide but finite feature learning neural networks. Unlike many prior analyses, our results, while perturbative in width, are non-perturbative in the strength of feature learning. Starting from a dynamical mean field theory (DMFT) description of infinite width deep neural network kernel and prediction dynamics, we provide a characterization of the $\mathcal{O}(1/\sqrt{\text{width}})$ fluctuations of the DMFT order parameters over random initialization of the network weights. In the lazy limit of network training, all kernels are random but static in time and the prediction variance has a universal form. However, in the rich, feature learning regime, the fluctuations of the kernels and predictions are dynamically coupled with variance that can be computed self-consistently. In two layer networks, we show how feature learning can dynamically reduce the variance of the final NTK and final network predictions. We also show how initialization variance can slow down online learning in wide but finite networks. In deeper networks, kernel variance can dramatically accumulate through subsequent layers at large feature learning strengths, but feature learning continues to improve the SNR of the feature kernels. In discrete time, we demonstrate that large learning rate phenomena such as edge of stability effects can be well captured by infinite width dynamics and that initialization variance can decrease dynamically. For CNNs trained on CIFAR-10, we empirically find significant corrections to both the bias and variance of network dynamics due to finite width.
Pointerformer: Deep Reinforced Multi-Pointer Transformer for the Traveling Salesman Problem
Apr 19, 2023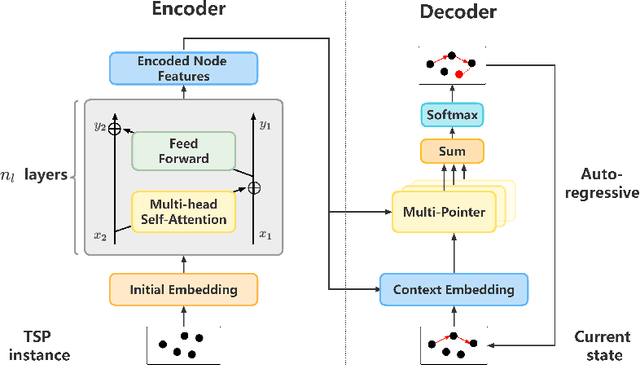
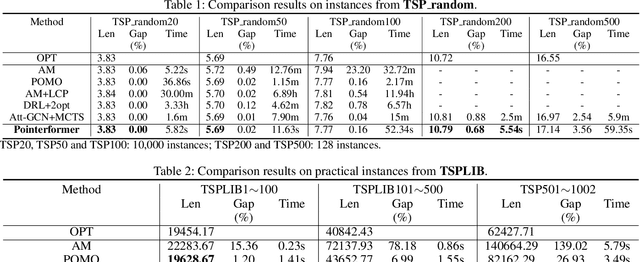
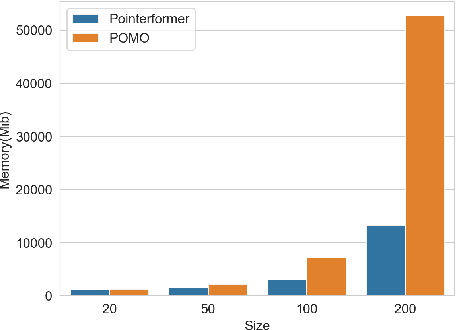
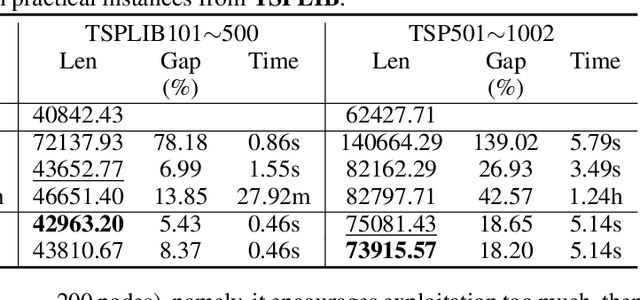
Traveling Salesman Problem (TSP), as a classic routing optimization problem originally arising in the domain of transportation and logistics, has become a critical task in broader domains, such as manufacturing and biology. Recently, Deep Reinforcement Learning (DRL) has been increasingly employed to solve TSP due to its high inference efficiency. Nevertheless, most of existing end-to-end DRL algorithms only perform well on small TSP instances and can hardly generalize to large scale because of the drastically soaring memory consumption and computation time along with the enlarging problem scale. In this paper, we propose a novel end-to-end DRL approach, referred to as Pointerformer, based on multi-pointer Transformer. Particularly, Pointerformer adopts both reversible residual network in the encoder and multi-pointer network in the decoder to effectively contain memory consumption of the encoder-decoder architecture. To further improve the performance of TSP solutions, Pointerformer employs both a feature augmentation method to explore the symmetries of TSP at both training and inference stages as well as an enhanced context embedding approach to include more comprehensive context information in the query. Extensive experiments on a randomly generated benchmark and a public benchmark have shown that, while achieving comparative results on most small-scale TSP instances as SOTA DRL approaches do, Pointerformer can also well generalize to large-scale TSPs.
Applying Learning-from-observation to household service robots: three common-sense formulation
Apr 19, 2023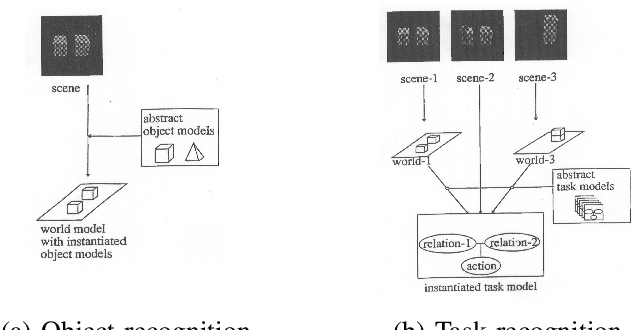


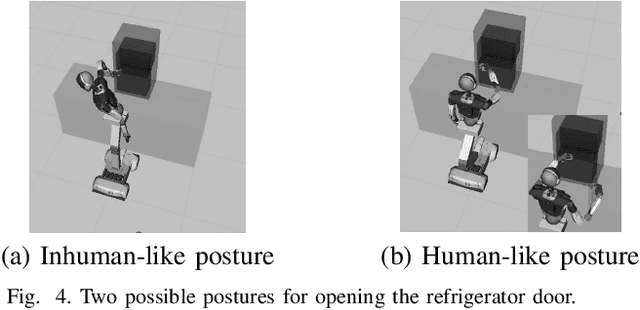
Utilizing a robot in a new application requires the robot to be programmed at each time. To reduce such programmings efforts, we have been developing ``Learning-from-observation (LfO)'' that automatically generates robot programs by observing human demonstrations. One of the main issues with introducing this LfO system into the domain of household tasks is the cluttered environments, which cause difficulty in determining which elements are important for task execution when observing demonstrations. To overcome this issue, it is necessary for the system to have common sense shared with the human demonstrator. This paper addresses three relationships that LfO in the household domain should focus on when observing demonstrations and proposes representations to describe the common sense used by the demonstrator for optimal execution of task sequences. Specifically, the paper proposes to use labanotation to describe the postures between the environment and the robot, contact-webs to describe the grasping methods between the robot and the tool, and physical and semantic constraints to describe the motions between the tool and the environment. Then, based on these representations, the paper formulates task models, machine-independent robot programs, that indicate what to do and how to do. Third, the paper explains the task encoder to obtain task models and task decoder to execute the task models on the robot hardware. Finally, this paper presents how the system actually works through several example scenes.
Realistic Data Enrichment for Robust Image Segmentation in Histopathology
Apr 19, 2023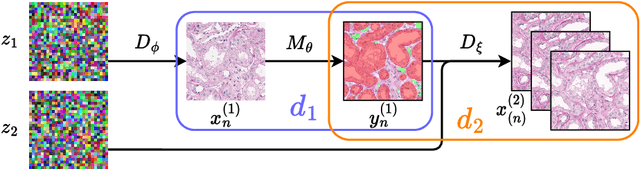
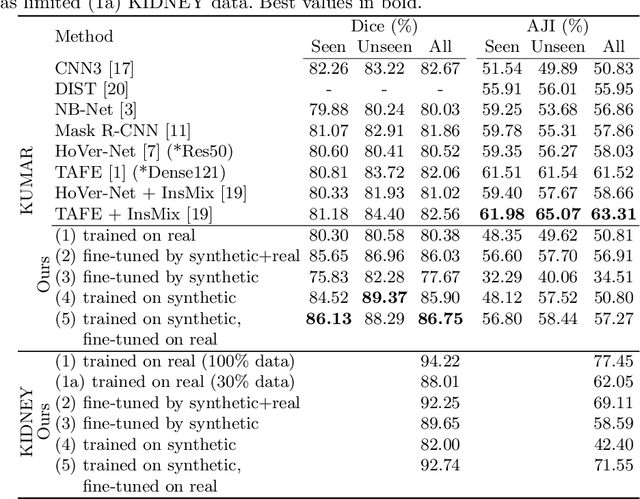

Poor performance of quantitative analysis in histopathological Whole Slide Images (WSI) has been a significant obstacle in clinical practice. Annotating large-scale WSIs manually is a demanding and time-consuming task, unlikely to yield the expected results when used for fully supervised learning systems. Rarely observed disease patterns and large differences in object scales are difficult to model through conventional patient intake. Prior methods either fall back to direct disease classification, which only requires learning a few factors per image, or report on average image segmentation performance, which is highly biased towards majority observations. Geometric image augmentation is commonly used to improve robustness for average case predictions and to enrich limited datasets. So far no method provided sampling of a realistic posterior distribution to improve stability, e.g. for the segmentation of imbalanced objects within images. Therefore, we propose a new approach, based on diffusion models, which can enrich an imbalanced dataset with plausible examples from underrepresented groups by conditioning on segmentation maps. Our method can simply expand limited clinical datasets making them suitable to train machine learning pipelines, and provides an interpretable and human-controllable way of generating histopathology images that are indistinguishable from real ones to human experts. We validate our findings on two datasets, one from the public domain and one from a Kidney Transplant study.
Self-supervised Learning with Speech Modulation Dropout
Mar 22, 2023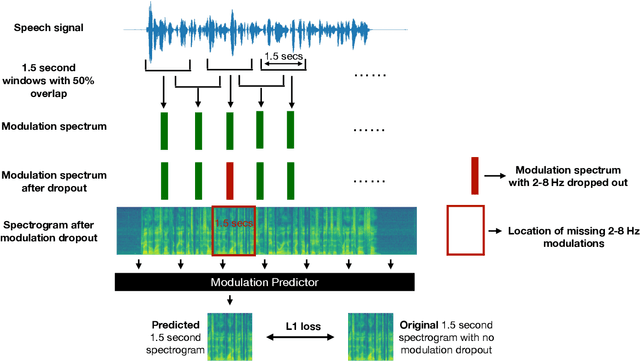

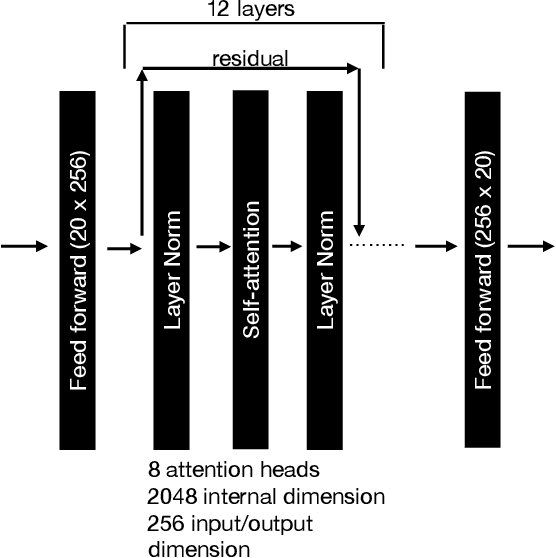
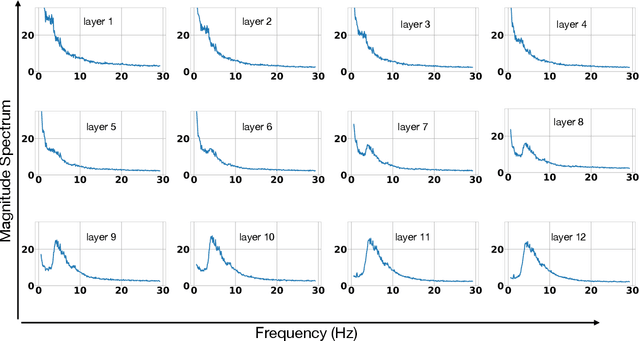
We show that training a multi-headed self-attention-based deep network to predict deleted, information-dense 2-8 Hz speech modulations over a 1.5-second section of a speech utterance is an effective way to make machines learn to extract speech modulations using time-domain contextual information. Our work exhibits that, once trained on large volumes of unlabelled data, the outputs of the self-attention layers vary in time with a modulation peak at 4 Hz. These pre-trained layers can be used to initialize parts of an Automatic Speech Recognition system to reduce its reliance on labeled speech data greatly.
Real-Time Deformable-Contact-Aware Model Predictive Control for Force-Modulated Manipulation
Dec 19, 2022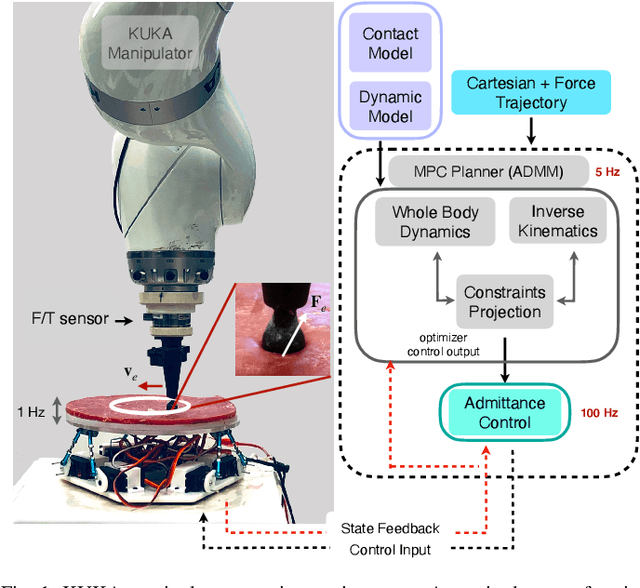
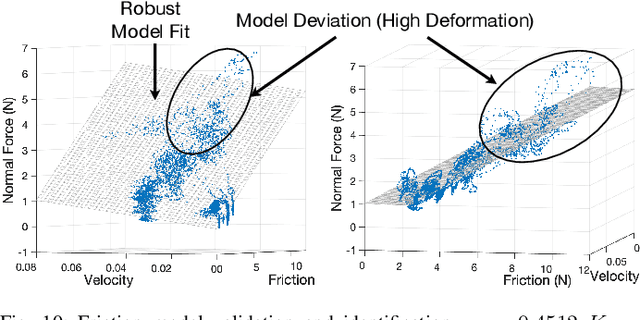
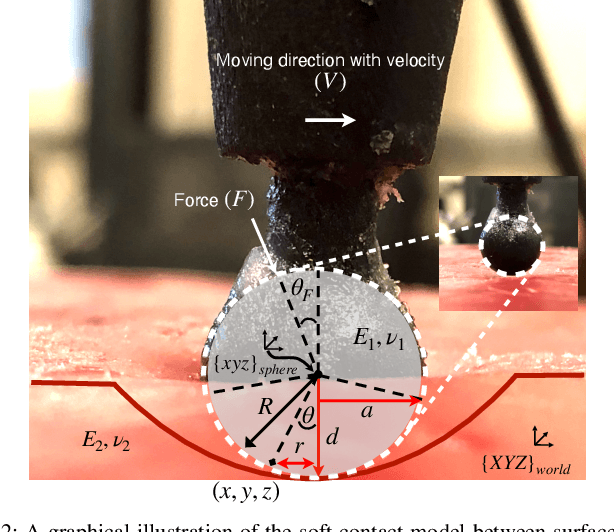
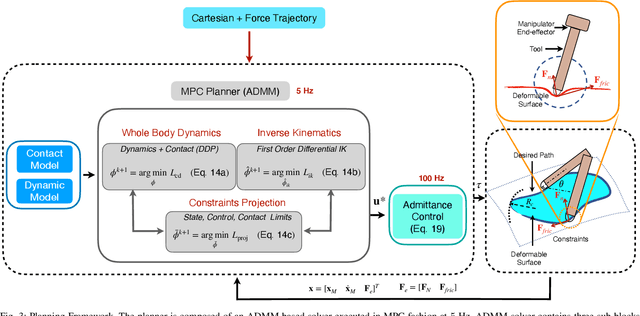
Force modulation of robotic manipulators has been extensively studied for several decades. However, it is not yet commonly used in safety-critical applications due to a lack of accurate interaction contact modeling and weak performance guarantees - a large proportion of them concerning the modulation of interaction forces. This study presents a high-level framework for simultaneous trajectory optimization and force control of the interaction between a manipulator and soft environments, which is prone to external disturbances. Sliding friction and normal contact force are taken into account. The dynamics of the soft contact model and the manipulator are simultaneously incorporated in a trajectory optimizer to generate desired motion and force profiles. A constrained optimization framework based on Alternative Direction Method of Multipliers (ADMM) has been employed to efficiently generate real-time optimal control inputs and high-dimensional state trajectories in a Model Predictive Control fashion. Experimental validation of the model performance is conducted on a soft substrate with known material properties using a Cartesian space force control mode. Results show a comparison of ground truth and real-time model-based contact force and motion tracking for multiple Cartesian motions in the valid range of the friction model. It is shown that a contact model-based motion planner can compensate for frictional forces and motion disturbances and improve the overall motion and force tracking accuracy. The proposed high-level planner has the potential to facilitate the automation of medical tasks involving the manipulation of compliant, delicate, and deformable tissues.
Generative Agents: Interactive Simulacra of Human Behavior
Apr 07, 2023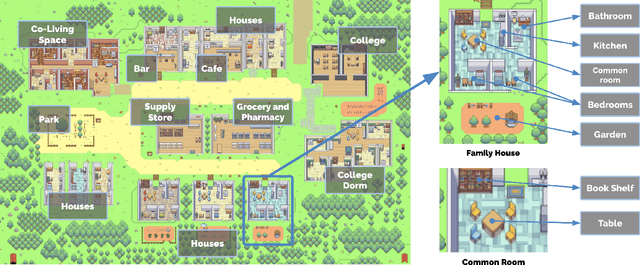
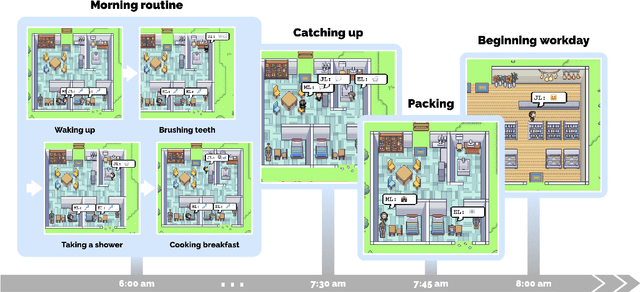
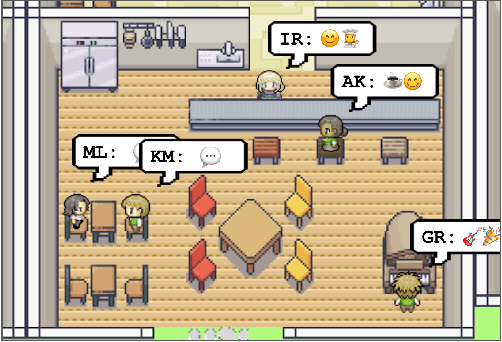
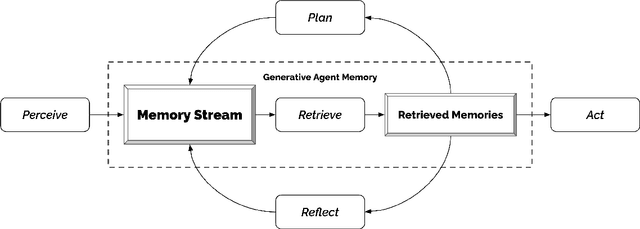
Believable proxies of human behavior can empower interactive applications ranging from immersive environments to rehearsal spaces for interpersonal communication to prototyping tools. In this paper, we introduce generative agents--computational software agents that simulate believable human behavior. Generative agents wake up, cook breakfast, and head to work; artists paint, while authors write; they form opinions, notice each other, and initiate conversations; they remember and reflect on days past as they plan the next day. To enable generative agents, we describe an architecture that extends a large language model to store a complete record of the agent's experiences using natural language, synthesize those memories over time into higher-level reflections, and retrieve them dynamically to plan behavior. We instantiate generative agents to populate an interactive sandbox environment inspired by The Sims, where end users can interact with a small town of twenty five agents using natural language. In an evaluation, these generative agents produce believable individual and emergent social behaviors: for example, starting with only a single user-specified notion that one agent wants to throw a Valentine's Day party, the agents autonomously spread invitations to the party over the next two days, make new acquaintances, ask each other out on dates to the party, and coordinate to show up for the party together at the right time. We demonstrate through ablation that the components of our agent architecture--observation, planning, and reflection--each contribute critically to the believability of agent behavior. By fusing large language models with computational, interactive agents, this work introduces architectural and interaction patterns for enabling believable simulations of human behavior.
SPOT: Sequential Predictive Modeling of Clinical Trial Outcome with Meta-Learning
Apr 07, 2023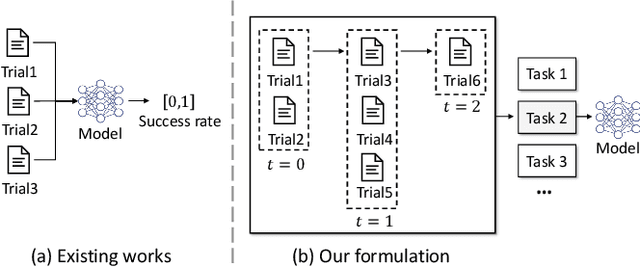
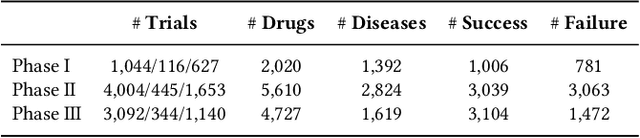
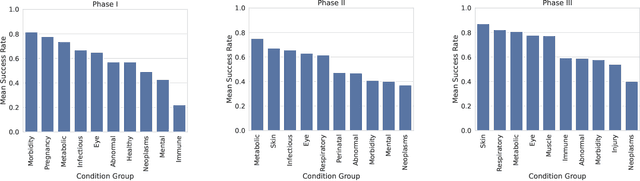
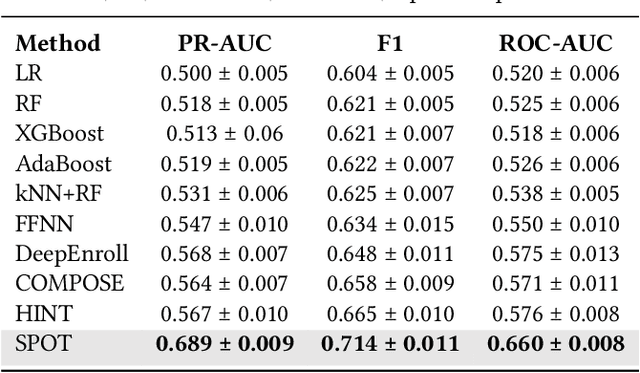
Clinical trials are essential to drug development but time-consuming, costly, and prone to failure. Accurate trial outcome prediction based on historical trial data promises better trial investment decisions and more trial success. Existing trial outcome prediction models were not designed to model the relations among similar trials, capture the progression of features and designs of similar trials, or address the skewness of trial data which causes inferior performance for less common trials. To fill the gap and provide accurate trial outcome prediction, we propose Sequential Predictive mOdeling of clinical Trial outcome (SPOT) that first identifies trial topics to cluster the multi-sourced trial data into relevant trial topics. It then generates trial embeddings and organizes them by topic and time to create clinical trial sequences. With the consideration of each trial sequence as a task, it uses a meta-learning strategy to achieve a point where the model can rapidly adapt to new tasks with minimal updates. In particular, the topic discovery module enables a deeper understanding of the underlying structure of the data, while sequential learning captures the evolution of trial designs and outcomes. This results in predictions that are not only more accurate but also more interpretable, taking into account the temporal patterns and unique characteristics of each trial topic. We demonstrate that SPOT wins over the prior methods by a significant margin on trial outcome benchmark data: with a 21.5\% lift on phase I, an 8.9\% lift on phase II, and a 5.5\% lift on phase III trials in the metric of the area under precision-recall curve (PR-AUC).
coExplore: Combining multiple rankings for multi-robot exploration
Mar 30, 2023

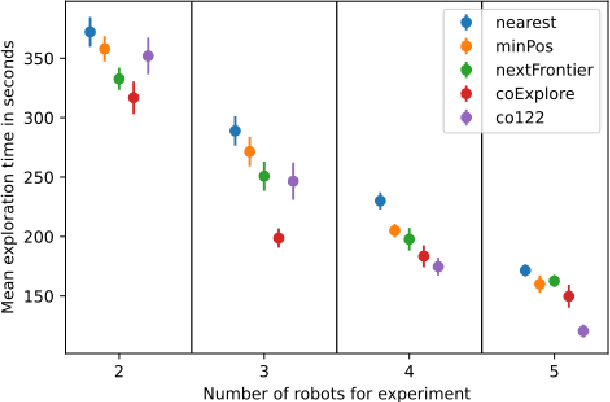
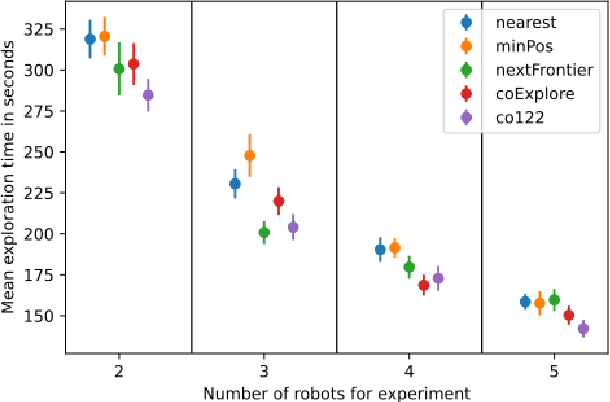
Multi-robot exploration is a field which tackles the challenge of exploring a previously unknown environment with a number of robots. This is especially relevant for search and rescue operations where time is essential. Current state of the art approaches are able to explore a given environment with a large number of robots by assigning them to frontiers. However, this assignment generally favors large frontiers and hence omits potentially valuable medium-sized frontiers. In this paper we showcase a novel multi-robot exploration algorithm, which improves and adapts the existing approaches. Through the addition of information gain based ranking we improve the exploration time for closed urban environments while maintaining similar exploration performance compared to the state-of-the-art for open environments. Accompanying this paper, we further publish our research code in order to lower the barrier to entry for further multi-robot exploration research. We evaluate the performance in three simulated scenarios, two urban and one open scenario, where our algorithm outperforms the state of the art by 5\% overall.