 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modality-Invariant Representation for Infrared and Visible Image Registration
Apr 12, 2023
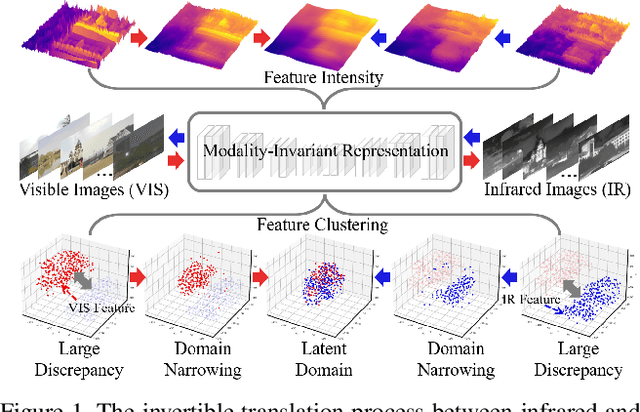
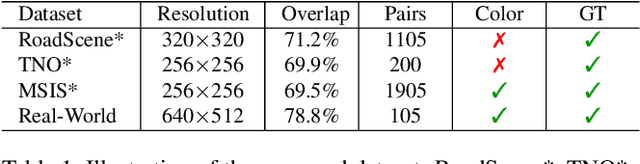
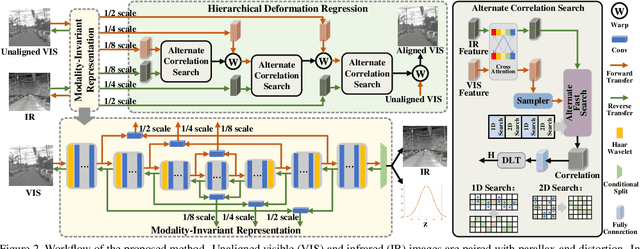
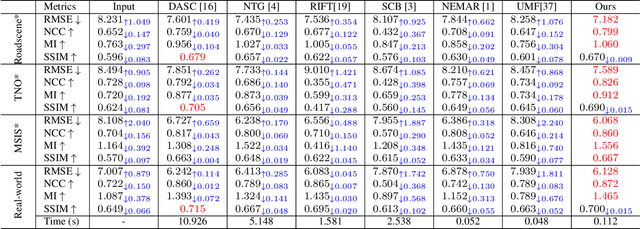
Since the differences in viewing range, resolution and relative position, the multi-modality sensing module composed of infrared and visible cameras needs to be registered so as to have more accurate scene perception. In practice, manual calibration-based registration is the most widely used process, and it is regularly calibrated to maintain accuracy, which is time-consuming and labor-intensive. To cope with these problems, we propose a scene-adaptive infrared and visible image registration. Specifically, in regard of the discrepancy between multi-modality images, an invertible translation process is developed to establish a modality-invariant domain, which comprehensively embraces the feature intensity and distribution of both infrared and visible modalities. We employ homography to simulate the deformation between different planes and develop a hierarchical framework to rectify the deformation inferred from the proposed latent representation in a coarse-to-fine manner. For that, the advanced perception ability coupled with the residual estimation conducive to the regression of sparse offsets, and the alternate correlation search facilitates a more accurate correspondence matching. Moreover, we propose the first ground truth available misaligned infrared and visible image dataset, involving three synthetic sets and one real-world set. Extensive experiments validate the effectiveness of the proposed method against the state-of-the-arts, advancing the subsequent applications.
A Scalable Framework for Automatic Playlist Continuation on Music Streaming Services
Apr 12, 2023
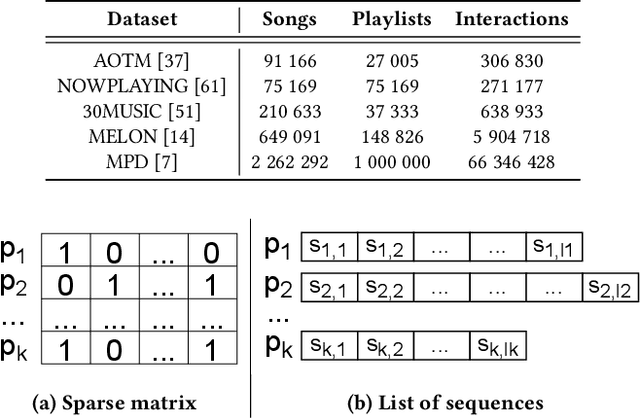
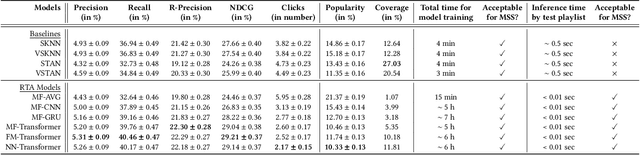
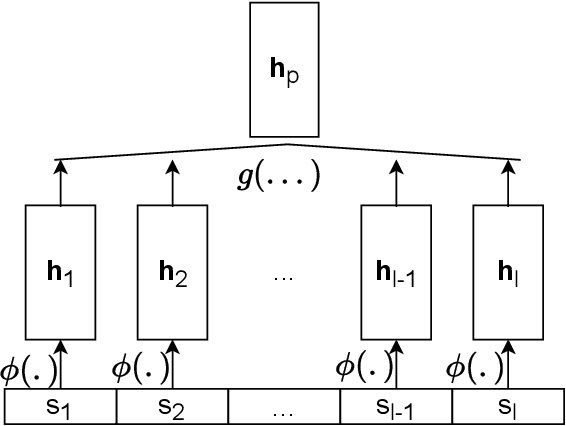
Music streaming services often aim to recommend songs for users to extend the playlists they have created on these services. However, extending playlists while preserving their musical characteristics and matching user preferences remains a challenging task, commonly referred to as Automatic Playlist Continuation (APC). Besides, while these services often need to select the best songs to recommend in real-time and among large catalogs with millions of candidates, recent research on APC mainly focused on models with few scalability guarantees and evaluated on relatively small datasets. In this paper, we introduce a general framework to build scalable yet effective APC models for large-scale applications. Based on a represent-then-aggregate strategy, it ensures scalability by design while remaining flexible enough to incorporate a wide range of representation learning and sequence modeling techniques, e.g., based on Transformers. We demonstrate the relevance of this framework through in-depth experimental validation on Spotify's Million Playlist Dataset (MPD), the largest public dataset for APC. We also describe how, in 2022, we successfully leveraged this framework to improve APC in production on Deezer. We report results from a large-scale online A/B test on this service, emphasizing the practical impact of our approach in such a real-world application.
Continuous Risk Measures for Driving Support
Mar 14, 2023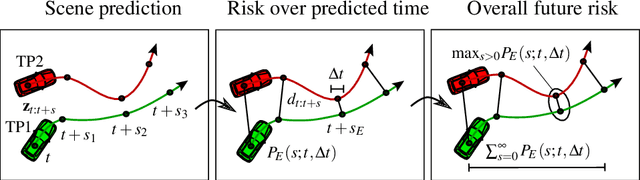
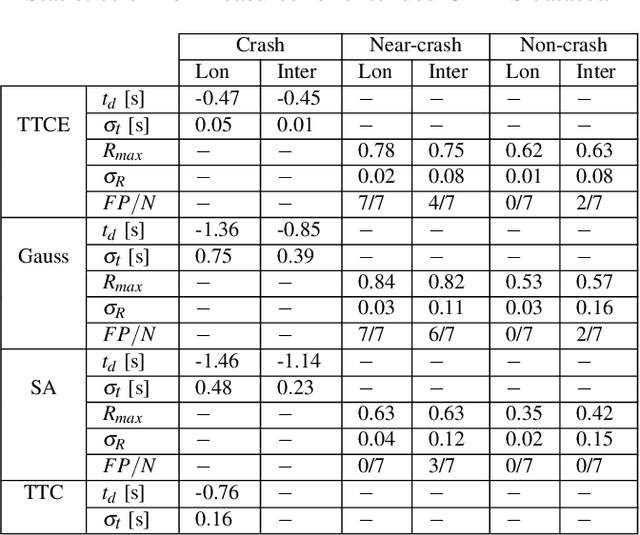
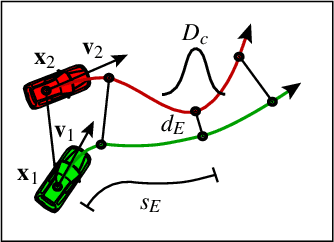
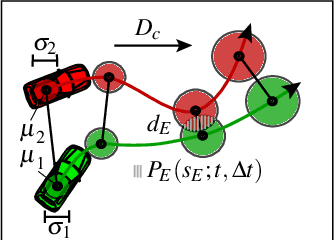
In this paper, we compare three different model-based risk measures by evaluating their stengths and weaknesses qualitatively and testing them quantitatively on a set of real longitudinal and intersection scenarios. We start with the traditional heuristic Time-To-Collision (TTC), which we extend towards 2D operation and non-crash cases to retrieve the Time-To-Closest-Encounter (TTCE). The second risk measure models position uncertainty with a Gaussian distribution and uses spatial occupancy probabilities for collision risks. We then derive a novel risk measure based on the statistics of sparse critical events and so-called survival conditions. The resulting survival analysis shows to have an earlier detection time of crashes and less false positive detections in near-crash and non-crash cases supported by its solid theoretical grounding. It can be seen as a generalization of TTCE and the Gaussian method which is suitable for the validation of ADAS and AD.
Efficient Point Mass Predictor for Continuous and Discrete Models with Linear Dynamics
Mar 06, 2023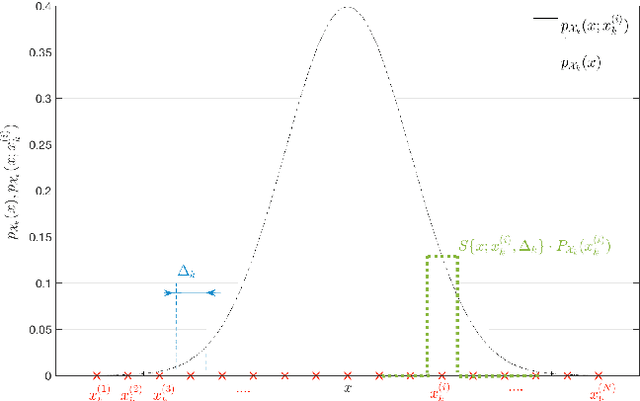
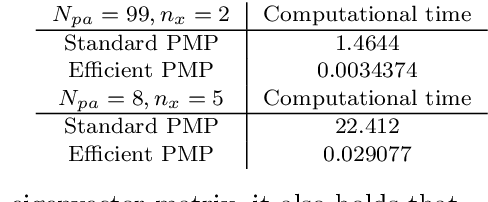
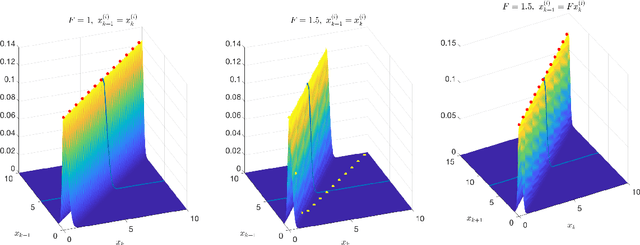
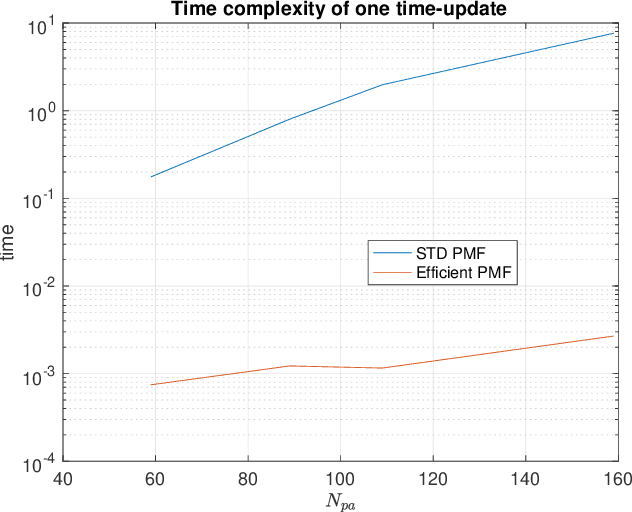
This paper deals with state estimation of stochastic models with linear state dynamics, continuous or discrete in time. The emphasis is laid on a numerical solution to the state prediction by the time-update step of the grid-point-based point-mass filter (PMF), which is the most computationally demanding part of the PMF algorithm. A novel way of manipulating the grid, leading to the time-update in form of a convolution, is proposed. This reduces the PMF time complexity from quadratic to log-linear with respect to the number of grid points. Furthermore, the number of unique transition probability values is greatly reduced causing a significant reduction of the data storage needed. The proposed PMF prediction step is verified in a numerical study.
AWT -- Clustering Meteorological Time Series Using an Aggregated Wavelet Tree
Dec 13, 2022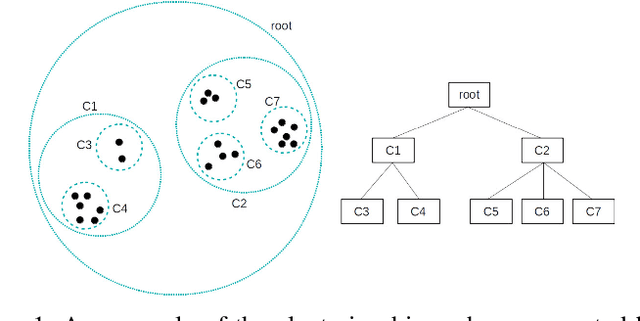
Both clustering and outlier detection play an important role for meteorological measurements. We present the AWT algorithm, a clustering algorithm for time series data that also performs implicit outlier detection during the clustering. AWT integrates ideas of several well-known K-Means clustering algorithms. It chooses the number of clusters automatically based on a user-defined threshold parameter, and it can be used for heterogeneous meteorological input data as well as for data sets that exceed the available memory size. We apply AWT to crowd sourced 2-m temperature data with an hourly resolution from the city of Vienna to detect outliers and to investigate if the final clusters show general similarities and similarities with urban land-use characteristics. It is shown that both the outlier detection and the implicit mapping to land-use characteristic is possible with AWT which opens new possible fields of application, specifically in the rapidly evolving field of urban climate and urban weather.
Improving Accuracy Without Losing Interpretability: A ML Approach for Time Series Forecasting
Dec 13, 2022
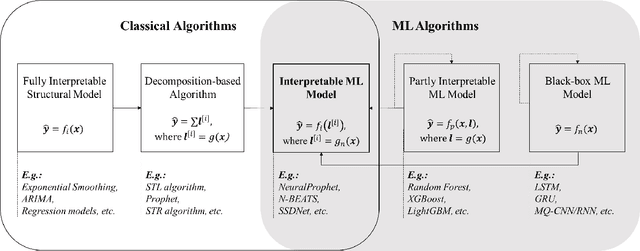
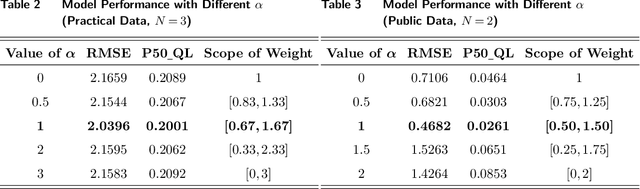
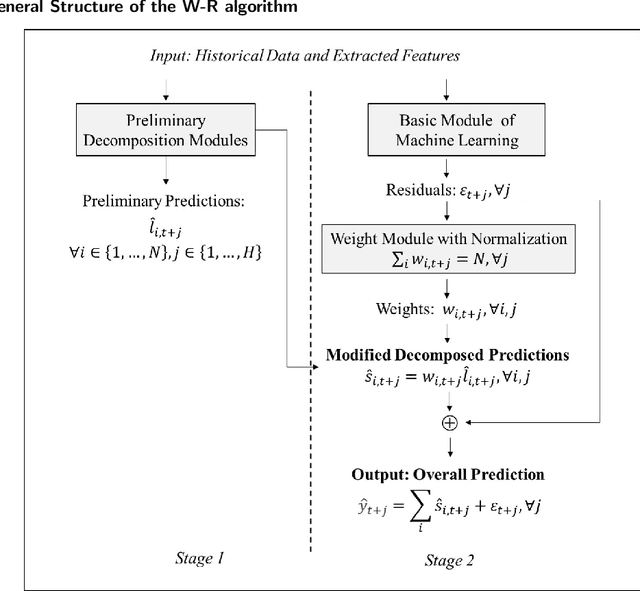
In time series forecasting, decomposition-based algorithms break aggregate data into meaningful components and are therefore appreciated for their particular advantages in interpretability. Recent algorithms often combine machine learning (hereafter ML) methodology with decomposition to improve prediction accuracy. However, incorporating ML is generally considered to sacrifice interpretability inevitably. In addition, existing hybrid algorithms usually rely on theoretical models with statistical assumptions and focus only on the accuracy of aggregate predictions, and thus suffer from accuracy problems, especially in component estimates. In response to the above issues, this research explores the possibility of improving accuracy without losing interpretability in time series forecasting. We first quantitatively define interpretability for data-driven forecasts and systematically review the existing forecasting algorithms from the perspective of interpretability. Accordingly, we propose the W-R algorithm, a hybrid algorithm that combines decomposition and ML from a novel perspective. Specifically, the W-R algorithm replaces the standard additive combination function with a weighted variant and uses ML to modify the estimates of all components simultaneously. We mathematically analyze the theoretical basis of the algorithm and validate its performance through extensive numerical experiments. In general, the W-R algorithm outperforms all decomposition-based and ML benchmarks. Based on P50_QL, the algorithm relatively improves by 8.76% in accuracy on the practical sales forecasts of JD.com and 77.99% on a public dataset of electricity loads. This research offers an innovative perspective to combine the statistical and ML algorithms, and JD.com has implemented the W-R algorithm to make accurate sales predictions and guide its marketing activities.
A deep learning Attention model to solve the Vehicle Routing Problem and the Pick-up and Delivery Problem with Time Windows
Dec 20, 2022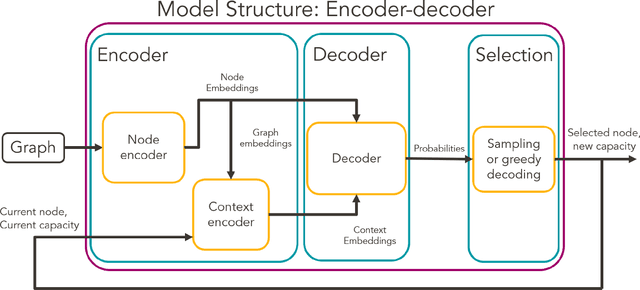
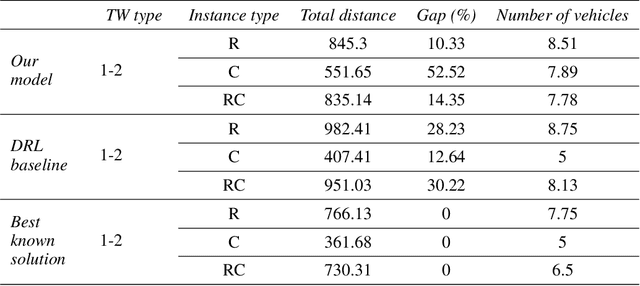
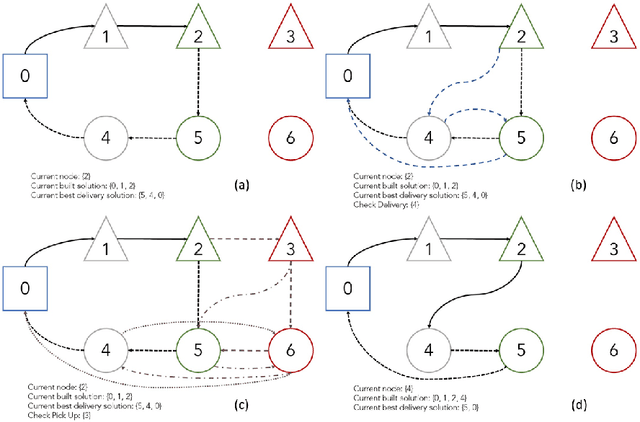
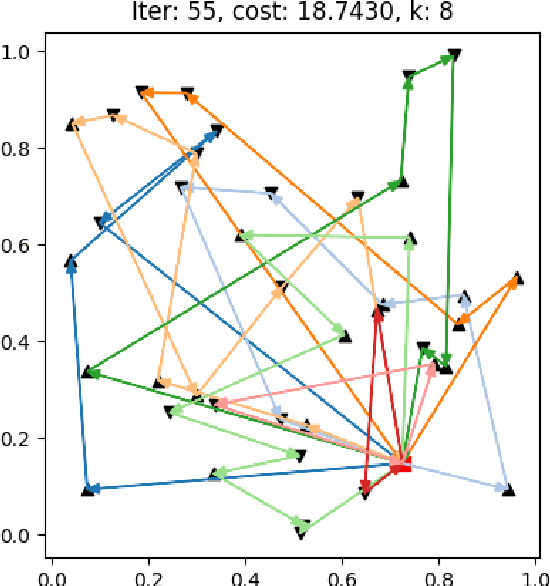
SNCF, the French public train company, is experimenting to develop new types of transportation services by tackling vehicle routing problems. While many deep learning models have been used to tackle efficiently vehicle routing problems, it is difficult to take into account time related constraints. In this paper, we solve the Capacitated Vehicle Routing Problem with Time Windows (CVRPTW) and the Capacitated Pickup and Delivery Problem with Time Windows (CPDPTW) with a constructive iterative Deep Learning algorithm. We use an Attention Encoder-Decoder structure and design a novel insertion heuristic for the feasibility check of the CPDPTW. Our models yields results that are better than best known learning solutions on the CVRPTW. We show the feasibility of deep learning techniques for solving the CPDPTW but witness the limitations of our iterative approach in terms of computational complexity.
A Learnheuristic Approach to A Constrained Multi-Objective Portfolio Optimisation Problem
Apr 13, 2023Multi-objective portfolio optimisation is a critical problem researched across various fields of study as it achieves the objective of maximising the expected return while minimising the risk of a given portfolio at the same time. However, many studies fail to include realistic constraints in the model, which limits practical trading strategies. This study introduces realistic constraints, such as transaction and holding costs, into an optimisation model. Due to the non-convex nature of this problem, metaheuristic algorithms, such as NSGA-II, R-NSGA-II, NSGA-III and U-NSGA-III, will play a vital role in solving the problem. Furthermore, a learnheuristic approach is taken as surrogate models enhance the metaheuristics employed. These algorithms are then compared to the baseline metaheuristic algorithms, which solve a constrained, multi-objective optimisation problem without using learnheuristics. The results of this study show that, despite taking significantly longer to run to completion, the learnheuristic algorithms outperform the baseline algorithms in terms of hypervolume and rate of convergence. Furthermore, the backtesting results indicate that utilising learnheuristics to generate weights for asset allocation leads to a lower risk percentage, higher expected return and higher Sharpe ratio than backtesting without using learnheuristics. This leads us to conclude that using learnheuristics to solve a constrained, multi-objective portfolio optimisation problem produces superior and preferable results than solving the problem without using learnheuristics.
Probably Approximately Correct Federated Learning
Apr 13, 2023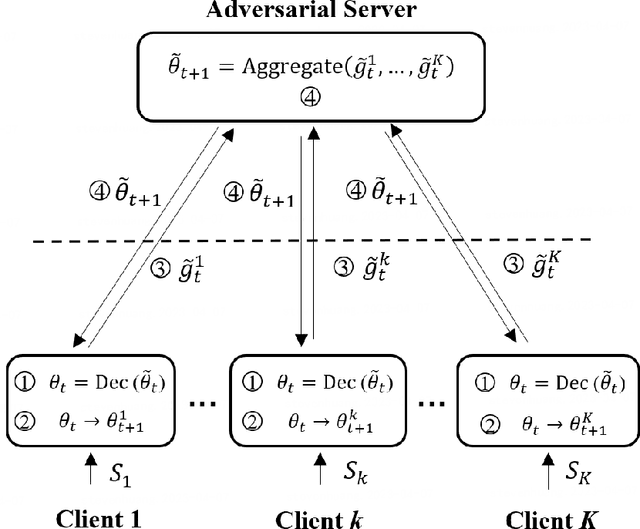

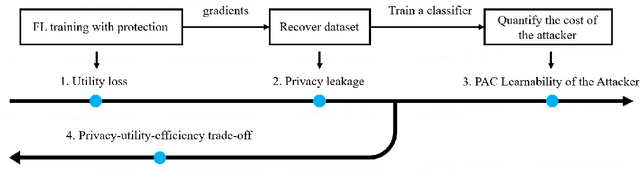
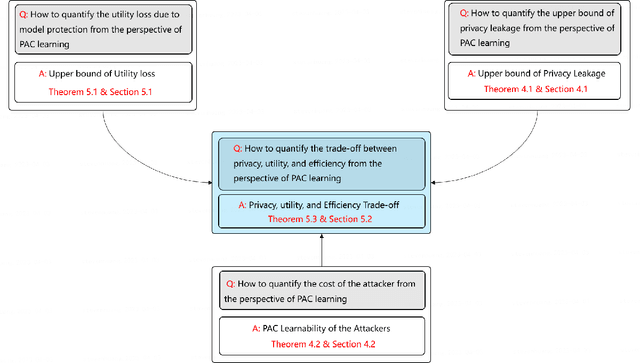
Federated learning (FL) is a new distributed learning paradigm, with privacy, utility, and efficiency as its primary pillars. Existing research indicates that it is unlikely to simultaneously attain infinitesimal privacy leakage, utility loss, and efficiency. Therefore, how to find an optimal trade-off solution is the key consideration when designing the FL algorithm. One common way is to cast the trade-off problem as a multi-objective optimization problem, i.e., the goal is to minimize the utility loss and efficiency reduction while constraining the privacy leakage not exceeding a predefined value. However, existing multi-objective optimization frameworks are very time-consuming, and do not guarantee the existence of the Pareto frontier, this motivates us to seek a solution to transform the multi-objective problem into a single-objective problem because it is more efficient and easier to be solved. To this end, we propose FedPAC, a unified framework that leverages PAC learning to quantify multiple objectives in terms of sample complexity, such quantification allows us to constrain the solution space of multiple objectives to a shared dimension, so that it can be solved with the help of a single-objective optimization algorithm. Specifically, we provide the results and detailed analyses of how to quantify the utility loss, privacy leakage, privacy-utility-efficiency trade-off, as well as the cost of the attacker from the PAC learning perspective.
Generalizable Deep Learning Method for Suppressing Unseen and Multiple MRI Artifacts Using Meta-learning
Apr 13, 2023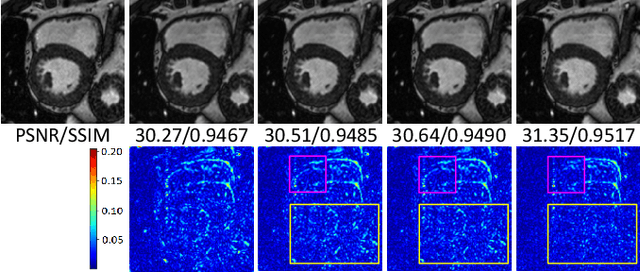
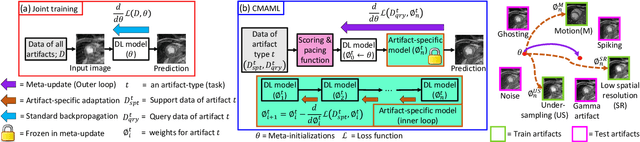
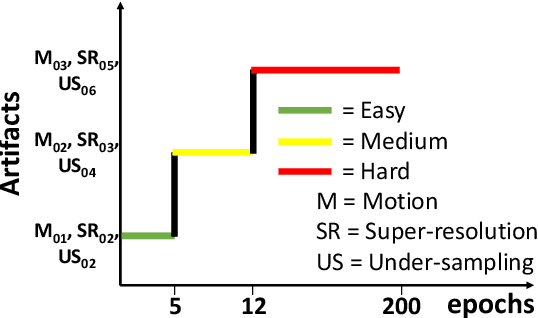
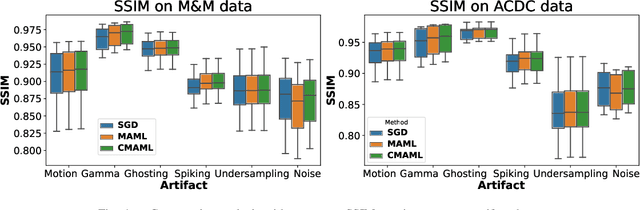
Magnetic Resonance (MR) images suffer from various types of artifacts due to motion, spatial resolution, and under-sampling. Conventional deep learning methods deal with removing a specific type of artifact, leading to separately trained models for each artifact type that lack the shared knowledge generalizable across artifacts. Moreover, training a model for each type and amount of artifact is a tedious process that consumes more training time and storage of models. On the other hand, the shared knowledge learned by jointly training the model on multiple artifacts might be inadequate to generalize under deviations in the types and amounts of artifacts. Model-agnostic meta-learning (MAML), a nested bi-level optimization framework is a promising technique to learn common knowledge across artifacts in the outer level of optimization, and artifact-specific restoration in the inner level. We propose curriculum-MAML (CMAML), a learning process that integrates MAML with curriculum learning to impart the knowledge of variable artifact complexity to adaptively learn restoration of multiple artifacts during training. Comparative studies against Stochastic Gradient Descent and MAML, using two cardiac datasets reveal that CMAML exhibits (i) better generalization with improved PSNR for 83% of unseen types and amounts of artifacts and improved SSIM in all cases, and (ii) better artifact suppression in 4 out of 5 cases of composite artifacts (scans with multiple artifacts).