 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
EVC: Towards Real-Time Neural Image Compression with Mask Decay
Feb 10, 2023
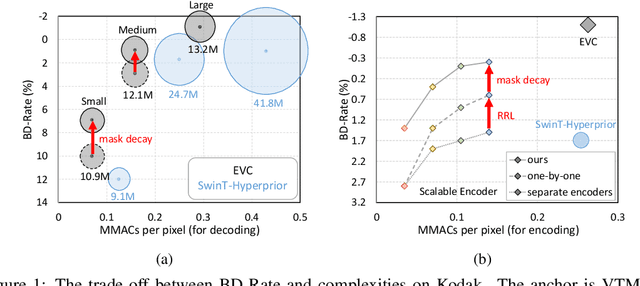
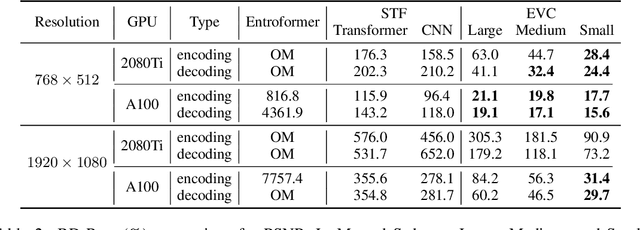
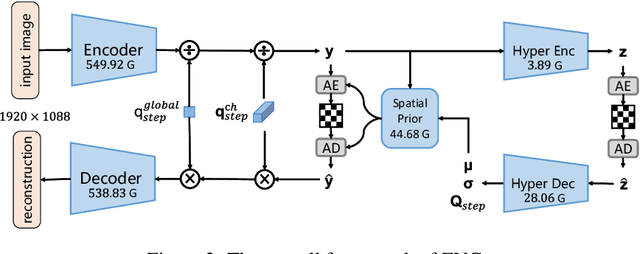
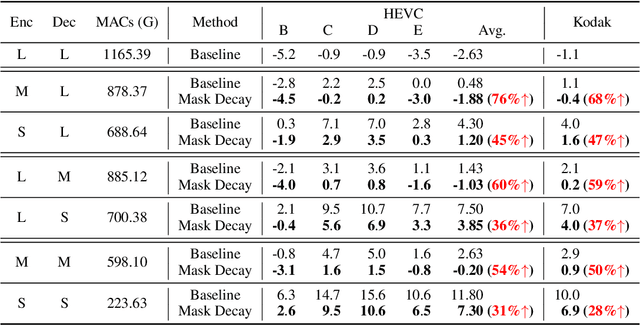
Neural image compression has surpassed state-of-the-art traditional codecs (H.266/VVC) for rate-distortion (RD) performance, but suffers from large complexity and separate models for different rate-distortion trade-offs. In this paper, we propose an Efficient single-model Variable-bit-rate Codec (EVC), which is able to run at 30 FPS with 768x512 input images and still outperforms VVC for the RD performance. By further reducing both encoder and decoder complexities, our small model even achieves 30 FPS with 1920x1080 input images. To bridge the performance gap between our different capacities models, we meticulously design the mask decay, which transforms the large model's parameters into the small model automatically. And a novel sparsity regularization loss is proposed to mitigate shortcomings of $L_p$ regularization. Our algorithm significantly narrows the performance gap by 50% and 30% for our medium and small models, respectively. At last, we advocate the scalable encoder for neural image compression. The encoding complexity is dynamic to meet different latency requirements. We propose decaying the large encoder multiple times to reduce the residual representation progressively. Both mask decay and residual representation learning greatly improve the RD performance of our scalable encoder. Our code is at https://github.com/microsoft/DCVC.
A Learnheuristic Approach to A Constrained Multi-Objective Portfolio Optimisation Problem
Apr 13, 2023Multi-objective portfolio optimisation is a critical problem researched across various fields of study as it achieves the objective of maximising the expected return while minimising the risk of a given portfolio at the same time. However, many studies fail to include realistic constraints in the model, which limits practical trading strategies. This study introduces realistic constraints, such as transaction and holding costs, into an optimisation model. Due to the non-convex nature of this problem, metaheuristic algorithms, such as NSGA-II, R-NSGA-II, NSGA-III and U-NSGA-III, will play a vital role in solving the problem. Furthermore, a learnheuristic approach is taken as surrogate models enhance the metaheuristics employed. These algorithms are then compared to the baseline metaheuristic algorithms, which solve a constrained, multi-objective optimisation problem without using learnheuristics. The results of this study show that, despite taking significantly longer to run to completion, the learnheuristic algorithms outperform the baseline algorithms in terms of hypervolume and rate of convergence. Furthermore, the backtesting results indicate that utilising learnheuristics to generate weights for asset allocation leads to a lower risk percentage, higher expected return and higher Sharpe ratio than backtesting without using learnheuristics. This leads us to conclude that using learnheuristics to solve a constrained, multi-objective portfolio optimisation problem produces superior and preferable results than solving the problem without using learnheuristics.
Probably Approximately Correct Federated Learning
Apr 13, 2023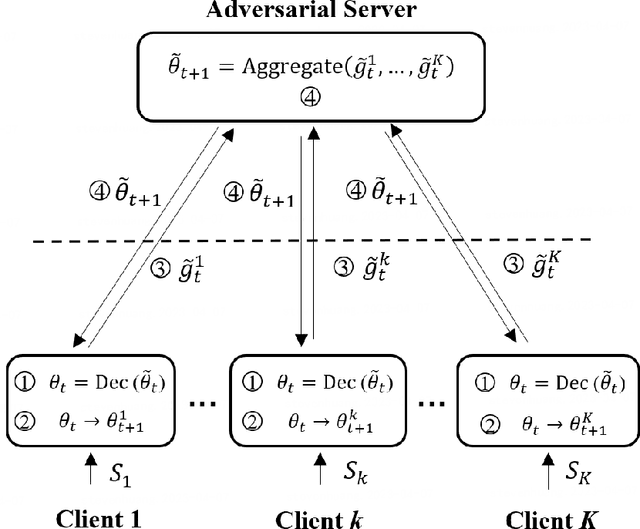

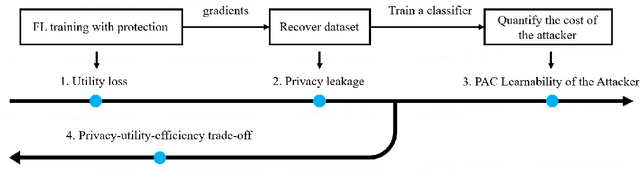
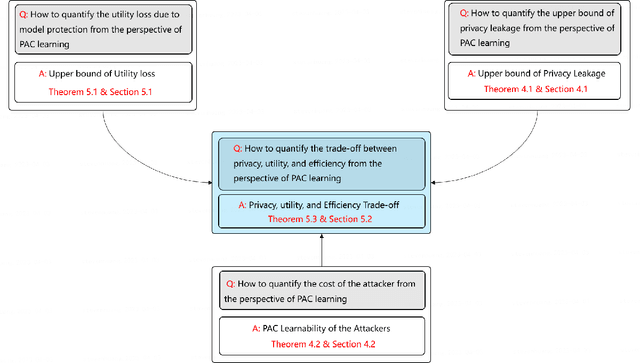
Federated learning (FL) is a new distributed learning paradigm, with privacy, utility, and efficiency as its primary pillars. Existing research indicates that it is unlikely to simultaneously attain infinitesimal privacy leakage, utility loss, and efficiency. Therefore, how to find an optimal trade-off solution is the key consideration when designing the FL algorithm. One common way is to cast the trade-off problem as a multi-objective optimization problem, i.e., the goal is to minimize the utility loss and efficiency reduction while constraining the privacy leakage not exceeding a predefined value. However, existing multi-objective optimization frameworks are very time-consuming, and do not guarantee the existence of the Pareto frontier, this motivates us to seek a solution to transform the multi-objective problem into a single-objective problem because it is more efficient and easier to be solved. To this end, we propose FedPAC, a unified framework that leverages PAC learning to quantify multiple objectives in terms of sample complexity, such quantification allows us to constrain the solution space of multiple objectives to a shared dimension, so that it can be solved with the help of a single-objective optimization algorithm. Specifically, we provide the results and detailed analyses of how to quantify the utility loss, privacy leakage, privacy-utility-efficiency trade-off, as well as the cost of the attacker from the PAC learning perspective.
Generalizable Deep Learning Method for Suppressing Unseen and Multiple MRI Artifacts Using Meta-learning
Apr 13, 2023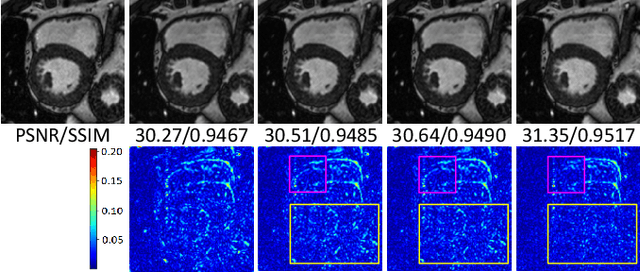
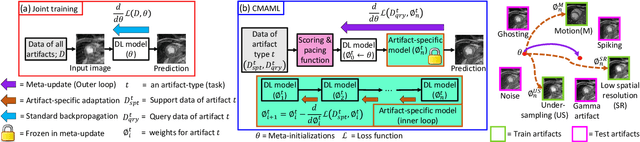
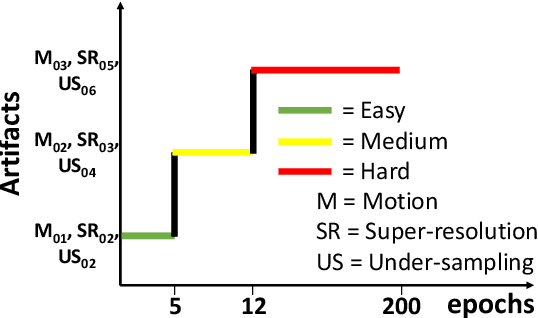
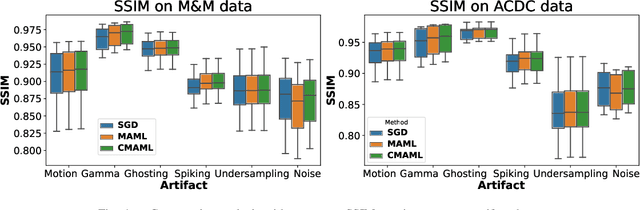
Magnetic Resonance (MR) images suffer from various types of artifacts due to motion, spatial resolution, and under-sampling. Conventional deep learning methods deal with removing a specific type of artifact, leading to separately trained models for each artifact type that lack the shared knowledge generalizable across artifacts. Moreover, training a model for each type and amount of artifact is a tedious process that consumes more training time and storage of models. On the other hand, the shared knowledge learned by jointly training the model on multiple artifacts might be inadequate to generalize under deviations in the types and amounts of artifacts. Model-agnostic meta-learning (MAML), a nested bi-level optimization framework is a promising technique to learn common knowledge across artifacts in the outer level of optimization, and artifact-specific restoration in the inner level. We propose curriculum-MAML (CMAML), a learning process that integrates MAML with curriculum learning to impart the knowledge of variable artifact complexity to adaptively learn restoration of multiple artifacts during training. Comparative studies against Stochastic Gradient Descent and MAML, using two cardiac datasets reveal that CMAML exhibits (i) better generalization with improved PSNR for 83% of unseen types and amounts of artifacts and improved SSIM in all cases, and (ii) better artifact suppression in 4 out of 5 cases of composite artifacts (scans with multiple artifacts).
A Framework for Learning Behavior Trees in Collaborative Robotic Applications
Mar 20, 2023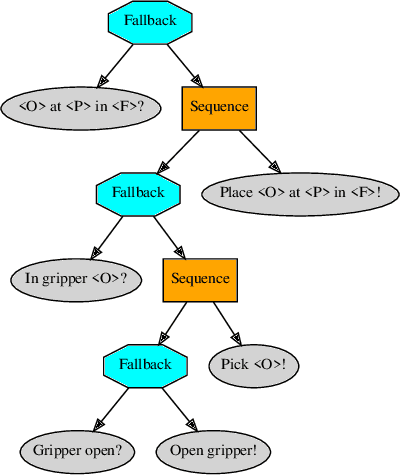
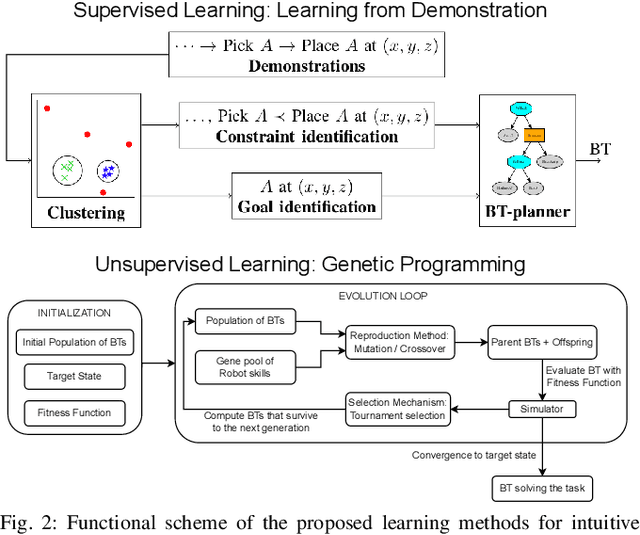
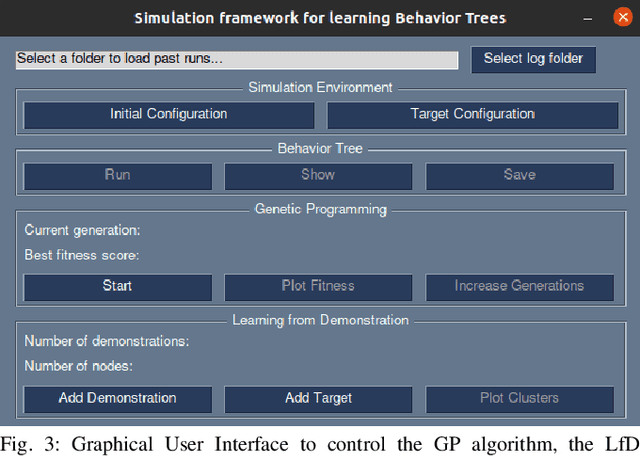
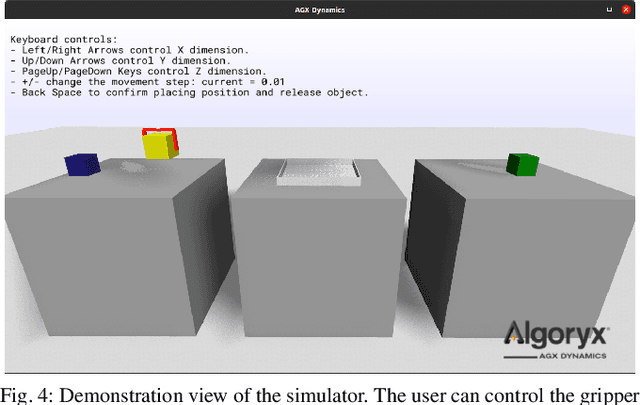
In modern industrial collaborative robotic applications, it is desirable to create robot programs automatically, intuitively, and time-efficiently. Moreover, robots need to be controlled by reactive policies to face the unpredictability of the environment they operate in. In this paper we propose a framework that combines a method that learns Behavior Trees (BTs) from demonstration with a method that evolves them with Genetic Programming (GP) for collaborative robotic applications. The main contribution of this paper is to show that by combining the two learning methods we obtain a method that allows non-expert users to semi-automatically, time-efficiently, and interactively generate BTs. We validate the framework with a series of manipulation experiments. The BT is fully learnt in simulation and then transferred to a real collaborative robot.
Practical Realization of Bessel's Correction for a Bias-Free Estimation of the Auto-Covariance and the Cross-Covariance Functions
Mar 20, 2023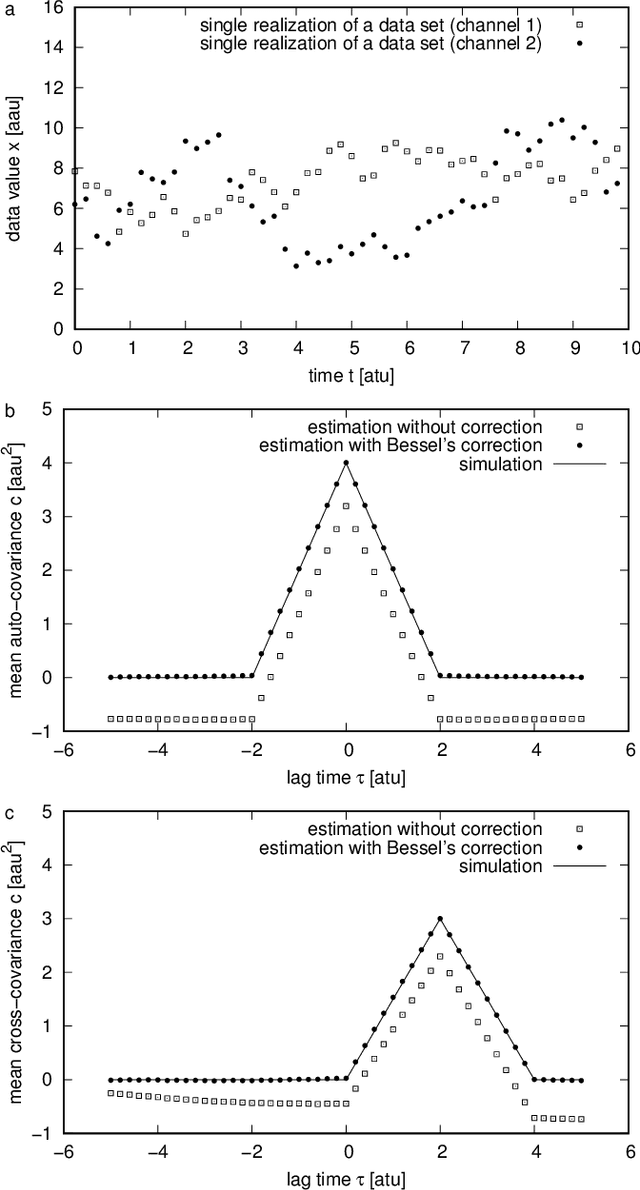
To derive the auto-covariance function from a sampled and time-limited signal or the cross-covariance function from two such signals, the mean values must be estimated and removed from the signals. If no a priori information about the correct mean values is available and the mean values must be derived from the time series themselves, the estimates will be biased. For the estimation of the variance from independent data the appropriate correction is widely known as Bessel's correction. Similar corrections for the auto-covariance and for the cross-covariance functions are shown here, including individual weighting of the samples. The corrected estimates then can be used to correct also the variance estimate in the case of correlated data. The programs used here are available online at http://sigproc.nambis.de/programs.
cs-net: structural approach to time-series forecasting for high-dimensional feature space data with limited observations
Dec 05, 2022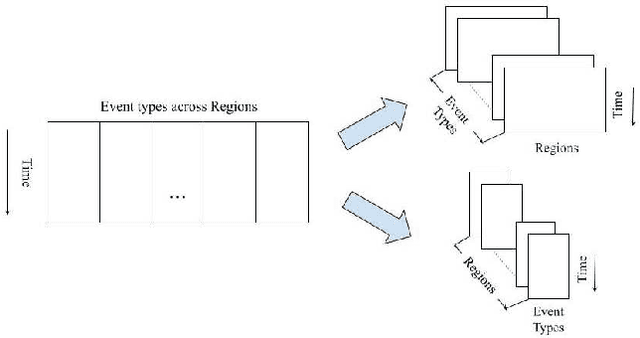
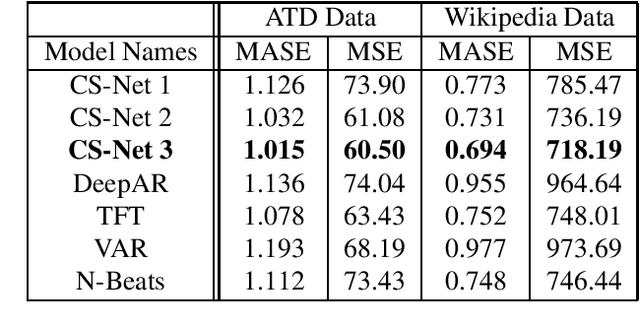
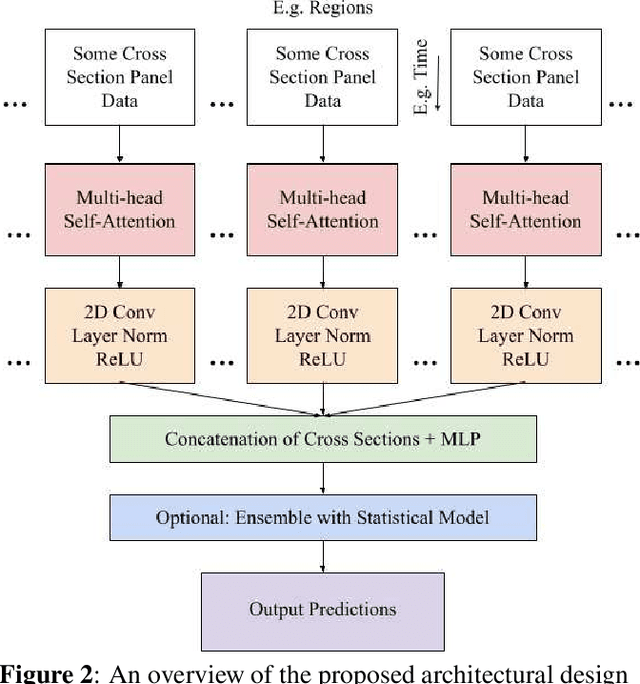
In recent years, deep-learning-based approaches have been introduced to solving time-series forecasting-related problems. These novel methods have demonstrated impressive performance in univariate and low-dimensional multivariate time-series forecasting tasks. However, when these novel methods are used to handle high-dimensional multivariate forecasting problems, their performance is highly restricted by a practical training time and a reasonable GPU memory configuration. In this paper, inspired by a change of basis in the Hilbert space, we propose a flexible data feature extraction technique that excels in high-dimensional multivariate forecasting tasks. Our approach was originally developed for the National Science Foundation (NSF) Algorithms for Threat Detection (ATD) 2022 Challenge. Implemented using the attention mechanism and Convolutional Neural Networks (CNN) architecture, our method demonstrates great performance and compatibility. Our models trained on the GDELT Dataset finished 1st and 2nd places in the ATD sprint series and hold promise for other datasets for time series forecasting.
Exploring Kinodynamic Fabrics for Reactive Whole-Body Control of Underactuated Humanoid Robots
Mar 09, 2023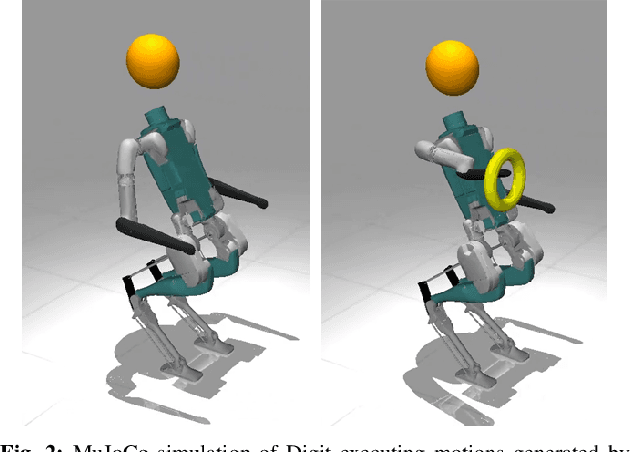
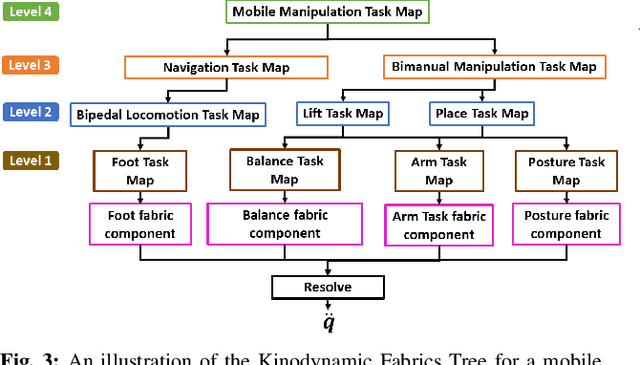
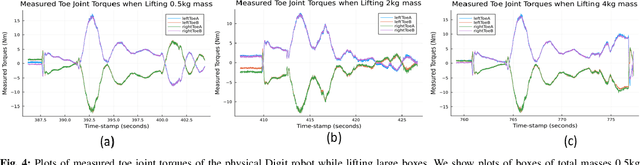
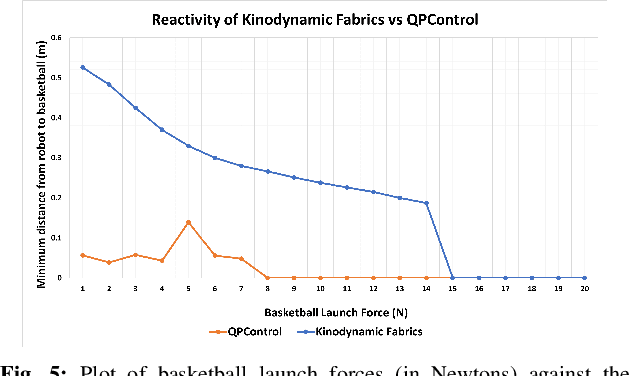
For bipedal humanoid robots to successfully operate in the real world, they must be competent at simultaneously executing multiple motion tasks while reacting to unforeseen external disturbances in real-time. We propose Kinodynamic Fabrics as an approach for the specification, solution and simultaneous execution of multiple motion tasks in real-time while being reactive to dynamism in the environment. Kinodynamic Fabrics allows for the specification of prioritized motion tasks as forced spectral semi-sprays and solves for desired robot joint accelerations at real-time frequencies. We evaluate the capabilities of Kinodynamic fabrics on diverse physically challenging whole-body control tasks with a bipedal humanoid robot both in simulation and in the real-world. Kinodynamic Fabrics outperforms the state-of-the-art Quadratic Program based whole-body controller on a variety of whole-body control tasks on run-time and reactivity metrics in our experiments. Our open-source implementation of Kinodynamic Fabrics as well as robot demonstration videos can be found at this url: https://adubredu.github.io/kinofabs.
AMS-DRL: Learning Multi-Pursuit Evasion for Safe Targeted Navigation of Drones
Apr 07, 2023
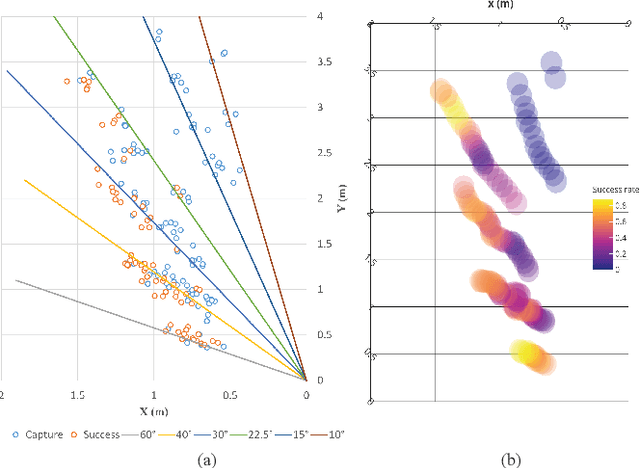
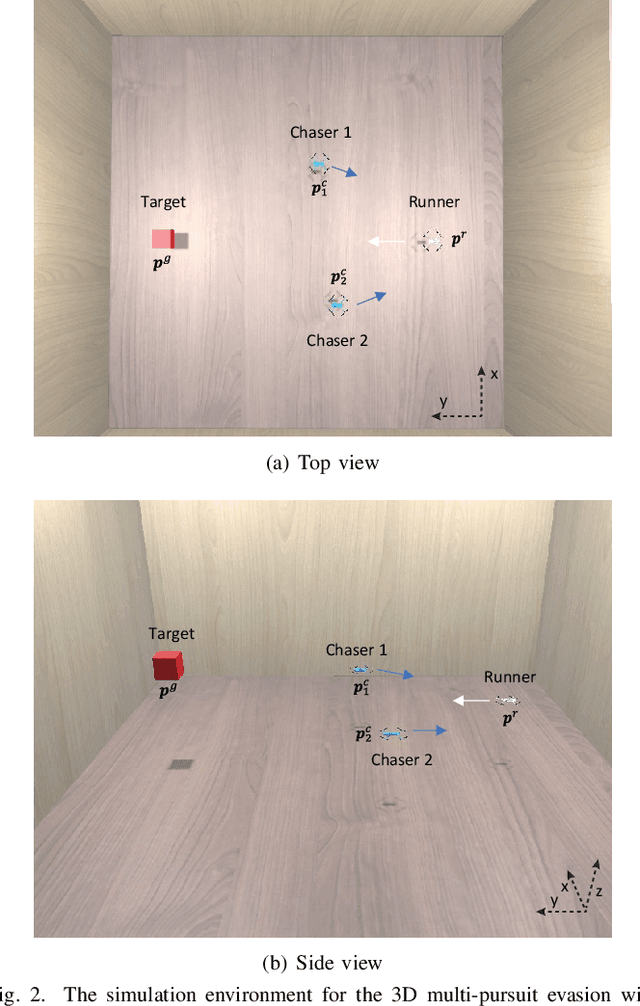
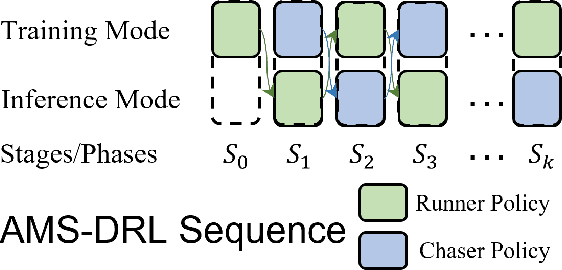
Safe navigation of drones in the presence of adversarial physical attacks from multiple pursuers is a challenging task. This paper proposes a novel approach, asynchronous multi-stage deep reinforcement learning (AMS-DRL), to train an adversarial neural network that can learn from the actions of multiple pursuers and adapt quickly to their behavior, enabling the drone to avoid attacks and reach its target. Our approach guarantees convergence by ensuring Nash Equilibrium among agents from the game-theory analysis. We evaluate our method in extensive simulations and show that it outperforms baselines with higher navigation success rates. We also analyze how parameters such as the relative maximum speed affect navigation performance. Furthermore, we have conducted physical experiments and validated the effectiveness of the trained policies in real-time flights. A success rate heatmap is introduced to elucidate how spatial geometry influences navigation outcomes. Project website: https://github.com/NTU-UAVG/AMS-DRL-for-Pursuit-Evasion.
Ring-Rotor: A Novel Retractable Ring-shaped Quadrotor with Aerial Grasping and Transportation Capability
Apr 07, 2023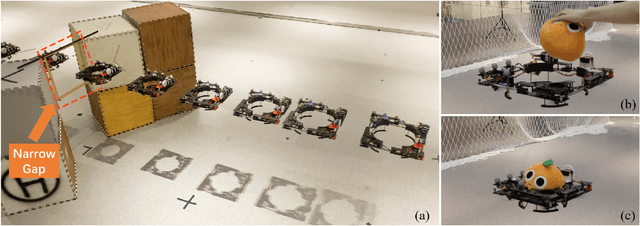



This letter presents a novel and retractable ring-shaped quadrotor called Ring-Rotor that can adjust the vehicle's length and width simultaneously. Unlike other morphing quadrotors with high platform complexity and poor controllability, Ring-Rotor uses only one servo motor for morphing but reduces the largest dimension of the vehicle by approximately 31.4\%. It can guarantee passibility while flying through small spaces in its compact form and energy saving in its standard form. Meanwhile, the vehicle breaks the cross configuration of general quadrotors with four arms connected to the central body and innovates a ring-shaped mechanical structure with spare central space. Based on this, an ingenious whole-body aerial grasping and transportation scheme is designed to carry various shapes of objects without the external manipulator mechanism. Moreover, we exploit a nonlinear model predictive control (NMPC) strategy that uses a time-variant physical parameter model to adapt to the quadrotor morphology. Above mentioned applications are performed in real-world experiments to demonstrate the system's high versatility.