 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
UniverSeg: Universal Medical Image Segmentation
Apr 12, 2023
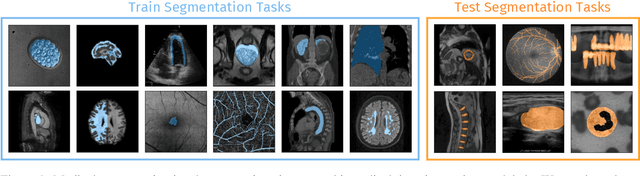

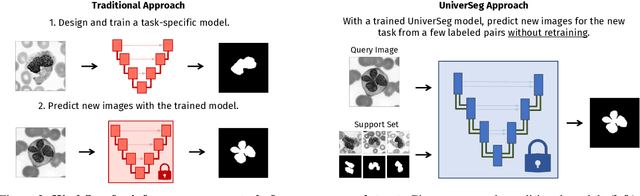
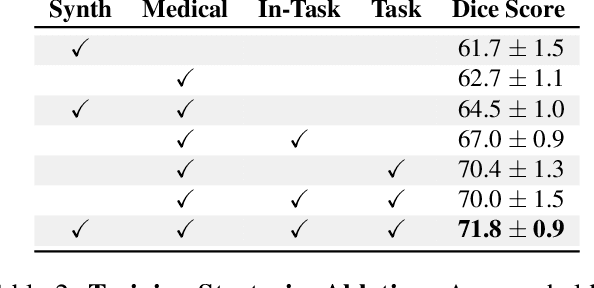
While deep learning models have become the predominant method for medical image segmentation, they are typically not capable of generalizing to unseen segmentation tasks involving new anatomies, image modalities, or labels. Given a new segmentation task, researchers generally have to train or fine-tune models, which is time-consuming and poses a substantial barrier for clinical researchers, who often lack the resources and expertise to train neural networks. We present UniverSeg, a method for solving unseen medical segmentation tasks without additional training. Given a query image and example set of image-label pairs that define a new segmentation task, UniverSeg employs a new Cross-Block mechanism to produce accurate segmentation maps without the need for additional training. To achieve generalization to new tasks, we have gathered and standardized a collection of 53 open-access medical segmentation datasets with over 22,000 scans, which we refer to as MegaMedical. We used this collection to train UniverSeg on a diverse set of anatomies and imaging modalities. We demonstrate that UniverSeg substantially outperforms several related methods on unseen tasks, and thoroughly analyze and draw insights about important aspects of the proposed system. The UniverSeg source code and model weights are freely available at https://universeg.csail.mit.edu
RESET: Revisiting Trajectory Sets for Conditional Behavior Prediction
Apr 12, 2023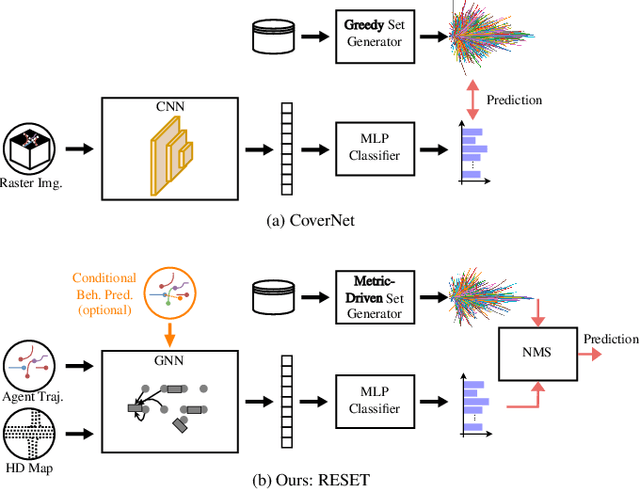
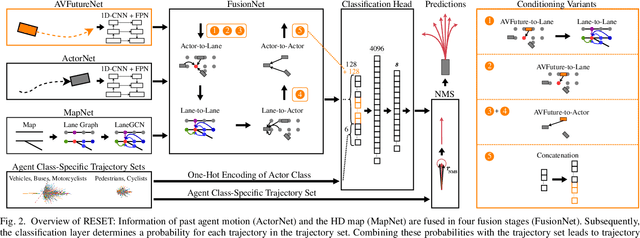
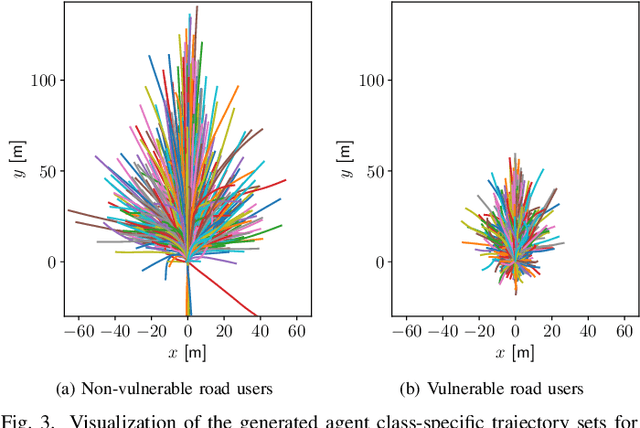
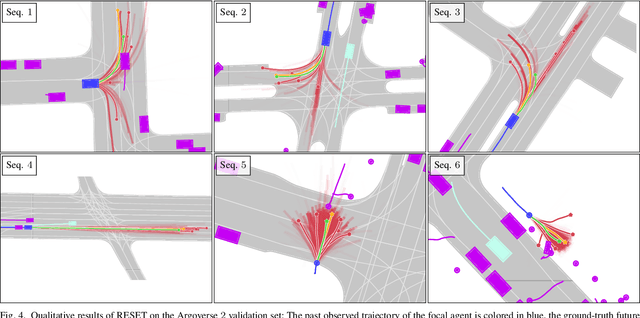
It is desirable to predict the behavior of traffic participants conditioned on different planned trajectories of the autonomous vehicle. This allows the downstream planner to estimate the impact of its decisions. Recent approaches for conditional behavior prediction rely on a regression decoder, meaning that coordinates or polynomial coefficients are regressed. In this work we revisit set-based trajectory prediction, where the probability of each trajectory in a predefined trajectory set is determined by a classification model, and first-time employ it to the task of conditional behavior prediction. We propose RESET, which combines a new metric-driven algorithm for trajectory set generation with a graph-based encoder. For unconditional prediction, RESET achieves comparable performance to a regression-based approach. Due to the nature of set-based approaches, it has the advantageous property of being able to predict a flexible number of trajectories without influencing runtime or complexity. For conditional prediction, RESET achieves reasonable results with late fusion of the planned trajectory, which was not observed for regression-based approaches before. This means that RESET is computationally lightweight to combine with a planner that proposes multiple future plans of the autonomous vehicle, as large parts of the forward pass can be reused.
Precise localization of corneal reflections in eye images using deep learning trained on synthetic data
Apr 12, 2023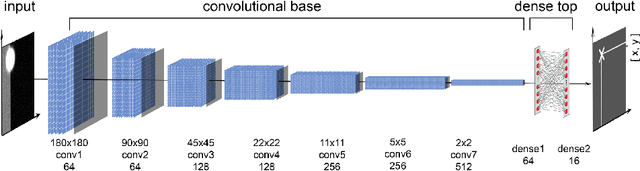

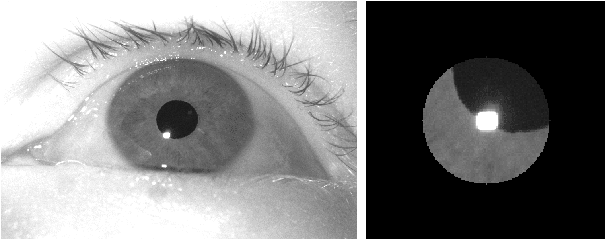
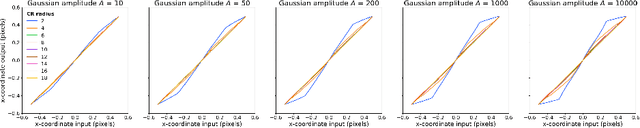
We present a deep learning method for accurately localizing the center of a single corneal reflection (CR) in an eye image. Unlike previous approaches, we use a convolutional neural network (CNN) that was trained solely using simulated data. Using only simulated data has the benefit of completely sidestepping the time-consuming process of manual annotation that is required for supervised training on real eye images. To systematically evaluate the accuracy of our method, we first tested it on images with simulated CRs placed on different backgrounds and embedded in varying levels of noise. Second, we tested the method on high-quality videos captured from real eyes. Our method outperformed state-of-the-art algorithmic methods on real eye images with a 35% reduction in terms of spatial precision, and performed on par with state-of-the-art on simulated images in terms of spatial accuracy.We conclude that our method provides a precise method for CR center localization and provides a solution to the data availability problem which is one of the important common roadblocks in the development of deep learning models for gaze estimation. Due to the superior CR center localization and ease of application, our method has the potential to improve the accuracy and precision of CR-based eye trackers
Modality-Invariant Representation for Infrared and Visible Image Registration
Apr 12, 2023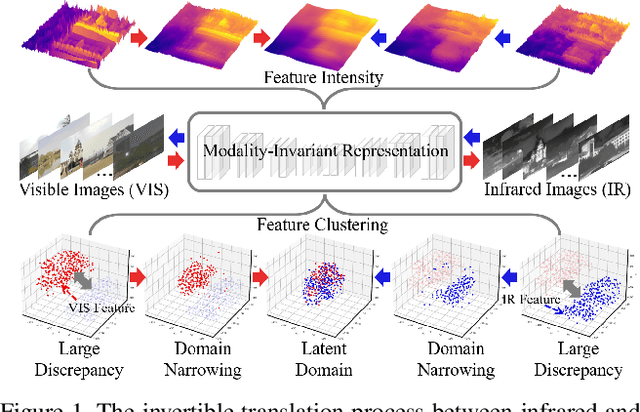
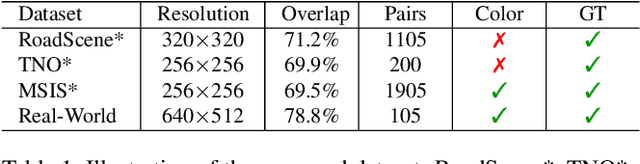
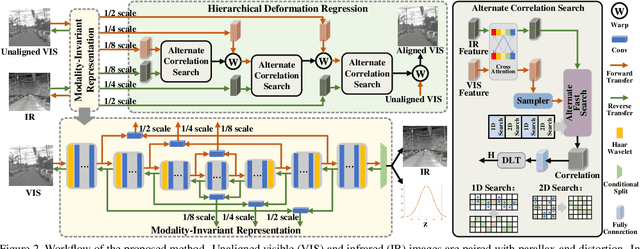
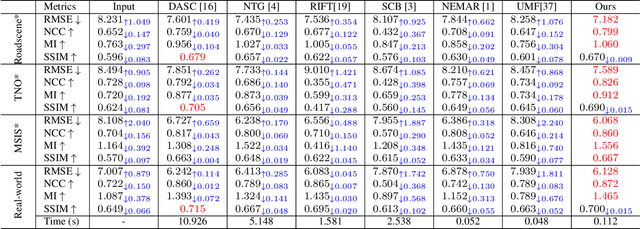
Since the differences in viewing range, resolution and relative position, the multi-modality sensing module composed of infrared and visible cameras needs to be registered so as to have more accurate scene perception. In practice, manual calibration-based registration is the most widely used process, and it is regularly calibrated to maintain accuracy, which is time-consuming and labor-intensive. To cope with these problems, we propose a scene-adaptive infrared and visible image registration. Specifically, in regard of the discrepancy between multi-modality images, an invertible translation process is developed to establish a modality-invariant domain, which comprehensively embraces the feature intensity and distribution of both infrared and visible modalities. We employ homography to simulate the deformation between different planes and develop a hierarchical framework to rectify the deformation inferred from the proposed latent representation in a coarse-to-fine manner. For that, the advanced perception ability coupled with the residual estimation conducive to the regression of sparse offsets, and the alternate correlation search facilitates a more accurate correspondence matching. Moreover, we propose the first ground truth available misaligned infrared and visible image dataset, involving three synthetic sets and one real-world set. Extensive experiments validate the effectiveness of the proposed method against the state-of-the-arts, advancing the subsequent applications.
A Scalable Framework for Automatic Playlist Continuation on Music Streaming Services
Apr 12, 2023
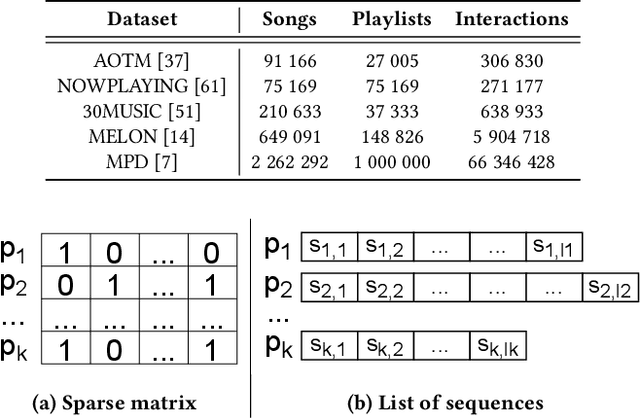
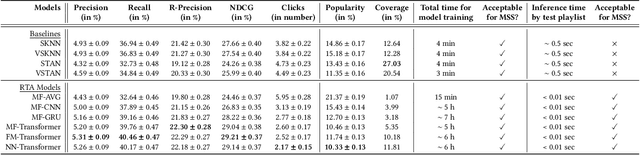
Music streaming services often aim to recommend songs for users to extend the playlists they have created on these services. However, extending playlists while preserving their musical characteristics and matching user preferences remains a challenging task, commonly referred to as Automatic Playlist Continuation (APC). Besides, while these services often need to select the best songs to recommend in real-time and among large catalogs with millions of candidates, recent research on APC mainly focused on models with few scalability guarantees and evaluated on relatively small datasets. In this paper, we introduce a general framework to build scalable yet effective APC models for large-scale applications. Based on a represent-then-aggregate strategy, it ensures scalability by design while remaining flexible enough to incorporate a wide range of representation learning and sequence modeling techniques, e.g., based on Transformers. We demonstrate the relevance of this framework through in-depth experimental validation on Spotify's Million Playlist Dataset (MPD), the largest public dataset for APC. We also describe how, in 2022, we successfully leveraged this framework to improve APC in production on Deezer. We report results from a large-scale online A/B test on this service, emphasizing the practical impact of our approach in such a real-world application.
C-SFDA: A Curriculum Learning Aided Self-Training Framework for Efficient Source Free Domain Adaptation
Mar 30, 2023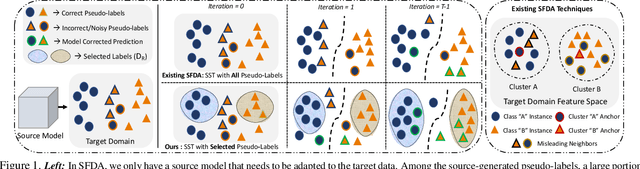
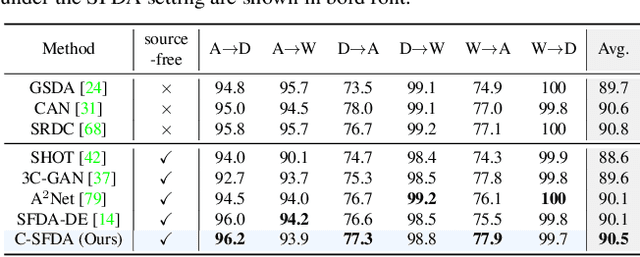
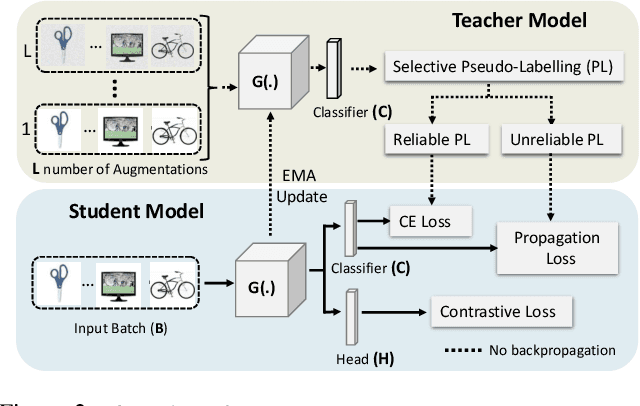
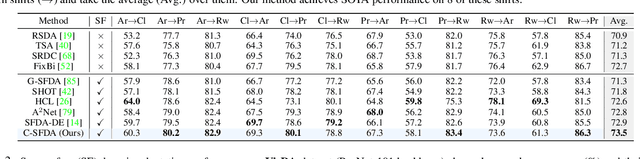
Unsupervised domain adaptation (UDA) approaches focus on adapting models trained on a labeled source domain to an unlabeled target domain. UDA methods have a strong assumption that the source data is accessible during adaptation, which may not be feasible in many real-world scenarios due to privacy concerns and resource constraints of devices. In this regard, source-free domain adaptation (SFDA) excels as access to source data is no longer required during adaptation. Recent state-of-the-art (SOTA) methods on SFDA mostly focus on pseudo-label refinement based self-training which generally suffers from two issues: i) inevitable occurrence of noisy pseudo-labels that could lead to early training time memorization, ii) refinement process requires maintaining a memory bank which creates a significant burden in resource constraint scenarios. To address these concerns, we propose C-SFDA, a curriculum learning aided self-training framework for SFDA that adapts efficiently and reliably to changes across domains based on selective pseudo-labeling. Specifically, we employ a curriculum learning scheme to promote learning from a restricted amount of pseudo labels selected based on their reliabilities. This simple yet effective step successfully prevents label noise propagation during different stages of adaptation and eliminates the need for costly memory-bank based label refinement. Our extensive experimental evaluations on both image recognition and semantic segmentation tasks confirm the effectiveness of our method. C-SFDA is readily applicable to online test-time domain adaptation and also outperforms previous SOTA methods in this task.
Progress towards an improved particle flow algorithm at CMS with machine learning
Mar 30, 2023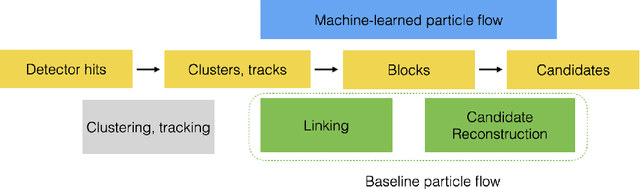

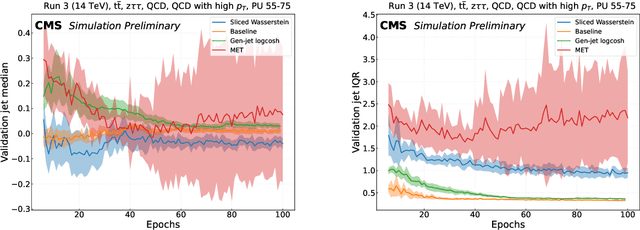
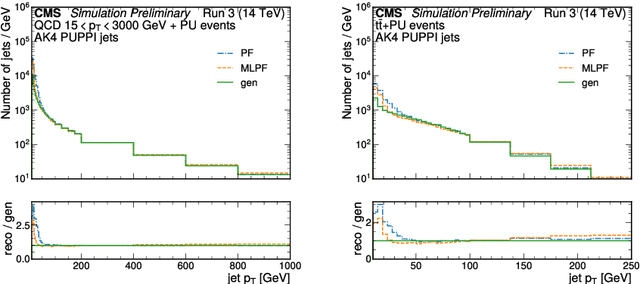
The particle-flow (PF) algorithm, which infers particles based on tracks and calorimeter clusters, is of central importance to event reconstruction in the CMS experiment at the CERN LHC, and has been a focus of development in light of planned Phase-2 running conditions with an increased pileup and detector granularity. In recent years, the machine learned particle-flow (MLPF) algorithm, a graph neural network that performs PF reconstruction, has been explored in CMS, with the possible advantages of directly optimizing for the physical quantities of interest, being highly reconfigurable to new conditions, and being a natural fit for deployment to heterogeneous accelerators. We discuss progress in CMS towards an improved implementation of the MLPF reconstruction, now optimized using generator/simulation-level particle information as the target for the first time. This paves the way to potentially improving the detector response in terms of physical quantities of interest. We describe the simulation-based training target, progress and studies on event-based loss terms, details on the model hyperparameter tuning, as well as physics validation with respect to the current PF algorithm in terms of high-level physical quantities such as the jet and missing transverse momentum resolutions. We find that the MLPF algorithm, trained on a generator/simulator level particle information for the first time, results in broadly compatible particle and jet reconstruction performance with the baseline PF, setting the stage for improving the physics performance by additional training statistics and model tuning.
* 7 pages, 4 Figures, 1 Table
Surrogate Neural Networks for Efficient Simulation-based Trajectory Planning Optimization
Mar 30, 2023
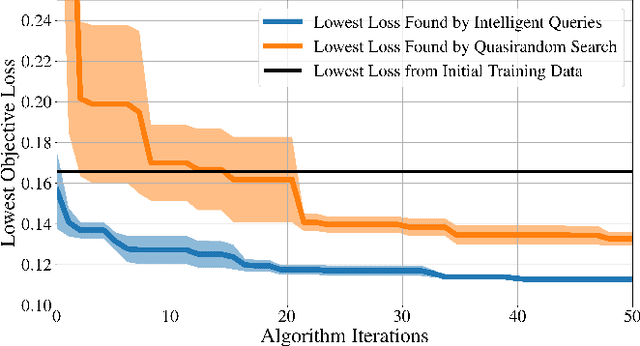
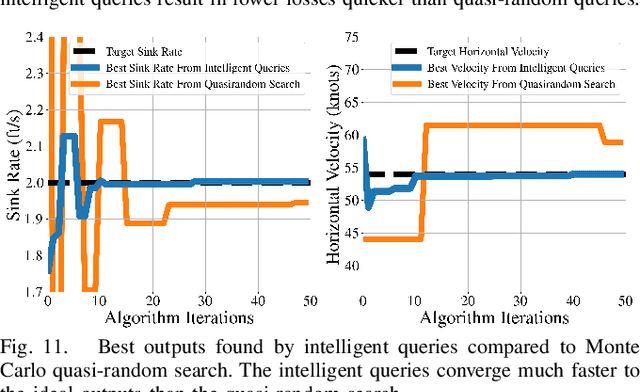
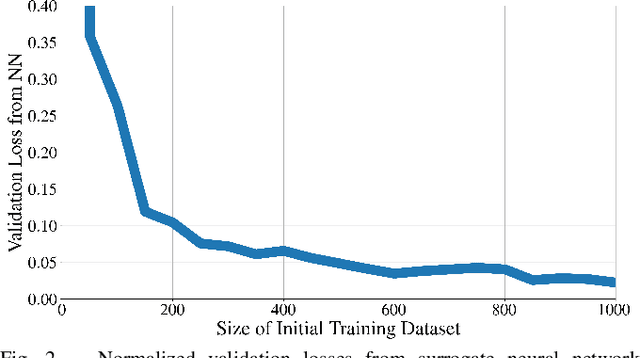
This paper presents a novel methodology that uses surrogate models in the form of neural networks to reduce the computation time of simulation-based optimization of a reference trajectory. Simulation-based optimization is necessary when there is no analytical form of the system accessible, only input-output data that can be used to create a surrogate model of the simulation. Like many high-fidelity simulations, this trajectory planning simulation is very nonlinear and computationally expensive, making it challenging to optimize iteratively. Through gradient descent optimization, our approach finds the optimal reference trajectory for landing a hypersonic vehicle. In contrast to the large datasets used to create the surrogate models in prior literature, our methodology is specifically designed to minimize the number of simulation executions required by the gradient descent optimizer. We demonstrated this methodology to be more efficient than the standard practice of hand-tuning the inputs through trial-and-error or randomly sampling the input parameter space. Due to the intelligently selected input values to the simulation, our approach yields better simulation outcomes that are achieved more rapidly and to a higher degree of accuracy. Optimizing the hypersonic vehicle's reference trajectory is very challenging due to the simulation's extreme nonlinearity, but even so, this novel approach found a 74% better-performing reference trajectory compared to nominal, and the numerical results clearly show a substantial reduction in computation time for designing future trajectories.
Design of Efficient Point-Mass Filter with Application in Terrain Aided Navigation
Mar 09, 2023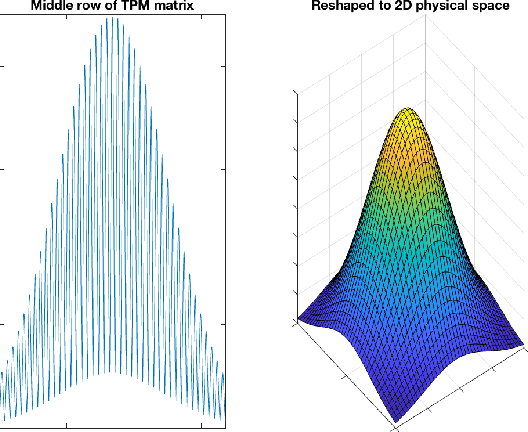
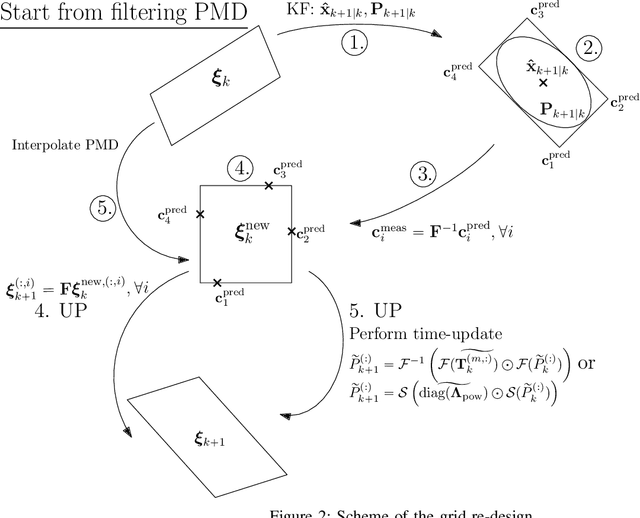
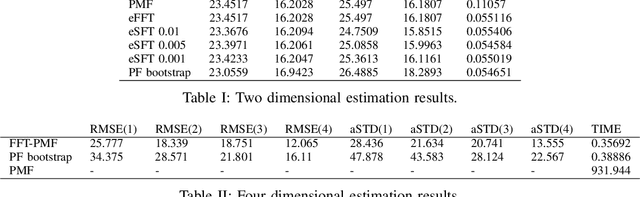
This paper deals with state estimation of stochastic models with linear state dynamics, continuous or discrete in time. The emphasis is laid on a numerical solution to the state prediction by the time-update step of the grid-point-based point-mass filter (PMF), which is the most computationally demanding part of the PMF algorithm. A novel efficient PMF (ePMF) estimator is proposed, designed, and discussed. By numerical illustrations, it is shown, that the proposed ePMF can lead to a time complexity reduction that exceeds 99.9% without compromising accuracy. The MATLAB code of the ePMF is released with this paper.
EVC: Towards Real-Time Neural Image Compression with Mask Decay
Feb 10, 2023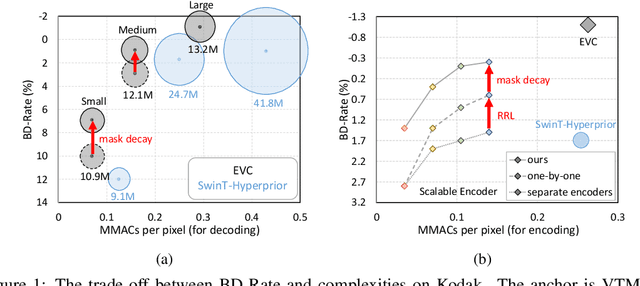
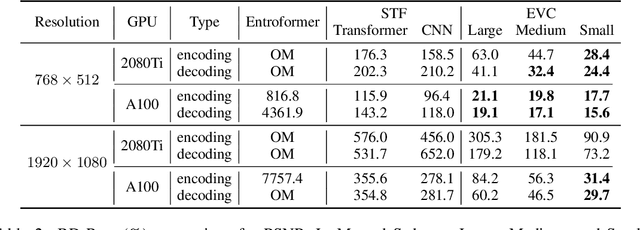
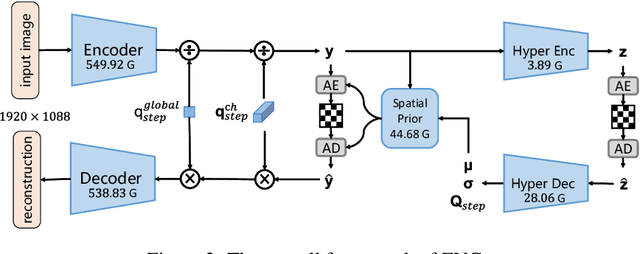
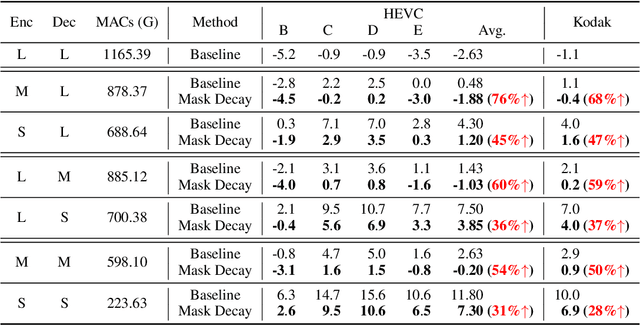
Neural image compression has surpassed state-of-the-art traditional codecs (H.266/VVC) for rate-distortion (RD) performance, but suffers from large complexity and separate models for different rate-distortion trade-offs. In this paper, we propose an Efficient single-model Variable-bit-rate Codec (EVC), which is able to run at 30 FPS with 768x512 input images and still outperforms VVC for the RD performance. By further reducing both encoder and decoder complexities, our small model even achieves 30 FPS with 1920x1080 input images. To bridge the performance gap between our different capacities models, we meticulously design the mask decay, which transforms the large model's parameters into the small model automatically. And a novel sparsity regularization loss is proposed to mitigate shortcomings of $L_p$ regularization. Our algorithm significantly narrows the performance gap by 50% and 30% for our medium and small models, respectively. At last, we advocate the scalable encoder for neural image compression. The encoding complexity is dynamic to meet different latency requirements. We propose decaying the large encoder multiple times to reduce the residual representation progressively. Both mask decay and residual representation learning greatly improve the RD performance of our scalable encoder. Our code is at https://github.com/microsoft/DCVC.