 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Motif-guided Time Series Counterfactual Explanations
Nov 08, 2022
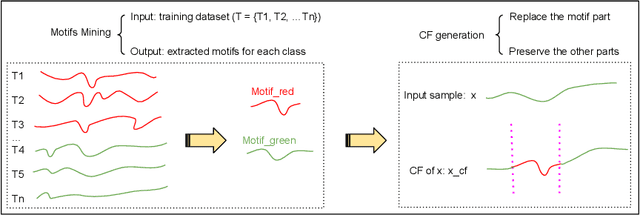
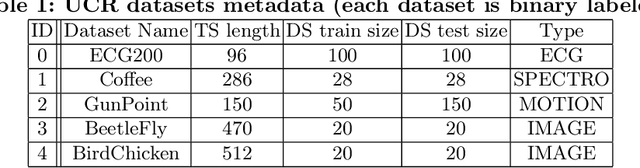
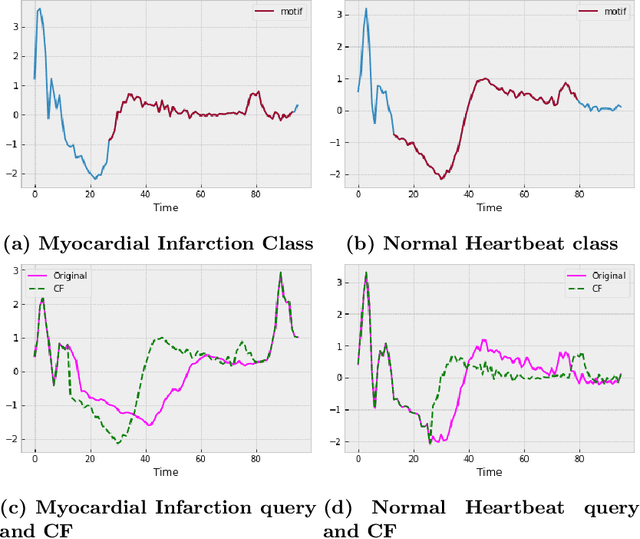
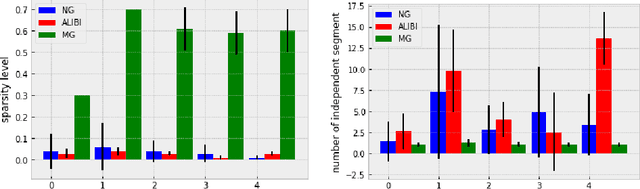
With the rising need of interpretable machine learning methods, there is a necessity for a rise in human effort to provide diverse explanations of the influencing factors of the model decisions. To improve the trust and transparency of AI-based systems, the EXplainable Artificial Intelligence (XAI) field has emerged. The XAI paradigm is bifurcated into two main categories: feature attribution and counterfactual explanation methods. While feature attribution methods are based on explaining the reason behind a model decision, counterfactual explanation methods discover the smallest input changes that will result in a different decision. In this paper, we aim at building trust and transparency in time series models by using motifs to generate counterfactual explanations. We propose Motif-Guided Counterfactual Explanation (MG-CF), a novel model that generates intuitive post-hoc counterfactual explanations that make full use of important motifs to provide interpretive information in decision-making processes. To the best of our knowledge, this is the first effort that leverages motifs to guide the counterfactual explanation generation. We validated our model using five real-world time-series datasets from the UCR repository. Our experimental results show the superiority of MG-CF in balancing all the desirable counterfactual explanations properties in comparison with other competing state-of-the-art baselines.
Automated deep reinforcement learning for real-time scheduling strategy of multi-energy system integrated with post-carbon and direct-air carbon captured system
Jan 18, 2023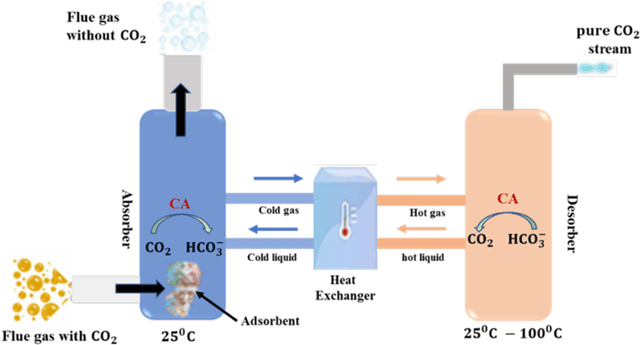
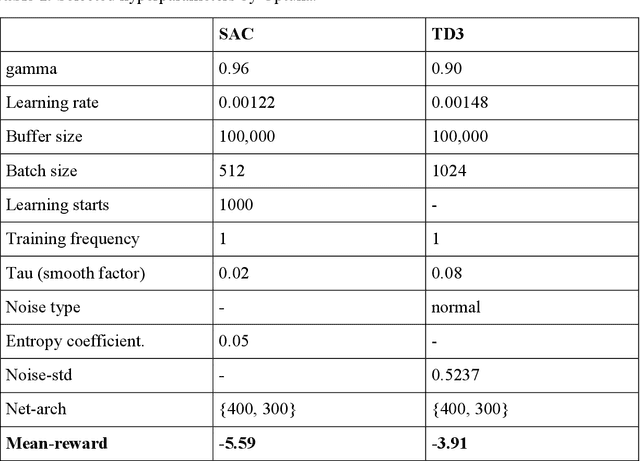
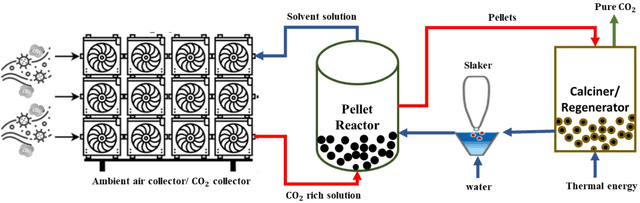
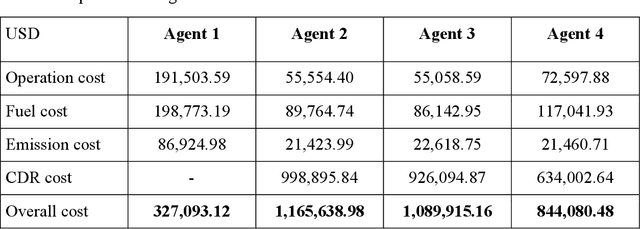
The carbon-capturing process with the aid of CO2 removal technology (CDRT) has been recognised as an alternative and a prominent approach to deep decarbonisation. However, the main hindrance is the enormous energy demand and the economic implication of CDRT if not effectively managed. Hence, a novel deep reinforcement learning agent (DRL), integrated with an automated hyperparameter selection feature, is proposed in this study for the real-time scheduling of a multi-energy system coupled with CDRT. Post-carbon capture systems (PCCS) and direct-air capture systems (DACS) are considered CDRT. Various possible configurations are evaluated using real-time multi-energy data of a district in Arizona and CDRT parameters from manufacturers' catalogues and pilot project documentation. The simulation results validate that an optimised soft-actor critic (SAC) algorithm outperformed the TD3 algorithm due to its maximum entropy feature. We then trained four (4) SAC agents, equivalent to the number of considered case studies, using optimised hyperparameter values and deployed them in real time for evaluation. The results show that the proposed DRL agent can meet the prosumers' multi-energy demand and schedule the CDRT energy demand economically without specified constraints violation. Also, the proposed DRL agent outperformed rule-based scheduling by 23.65%. However, the configuration with PCCS and solid-sorbent DACS is considered the most suitable configuration with a high CO2 captured-released ratio of 38.54, low CO2 released indicator value of 2.53, and a 36.5% reduction in CDR cost due to waste heat utilisation and high absorption capacity of the selected sorbent. However, the adoption of CDRT is not economically viable at the current carbon price. Finally, we showed that CDRT would be attractive at a carbon price of 400-450USD/ton with the provision of tax incentives by the policymakers.
* 39 pages; postprint
MGADN: A Multi-task Graph Anomaly Detection Network for Multivariate Time Series
Nov 27, 2022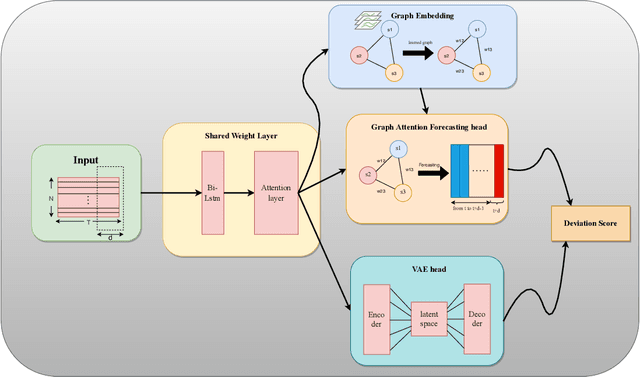
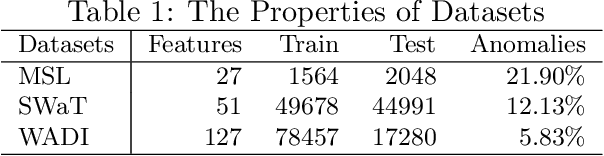
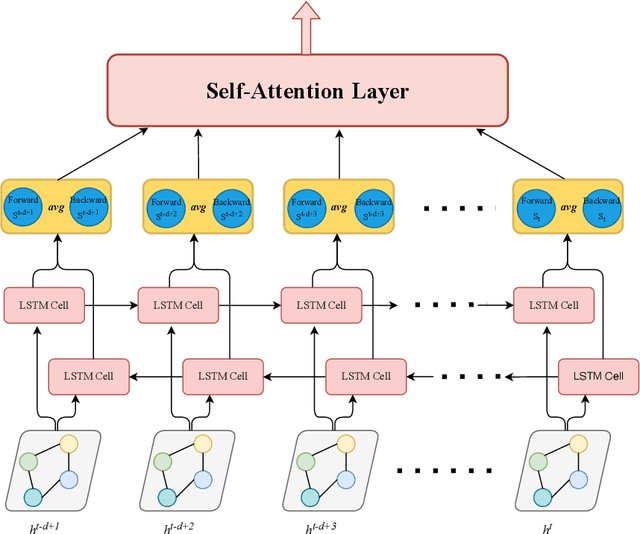
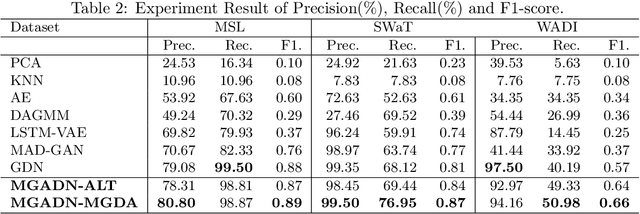
Anomaly detection of time series, especially multivariate time series(time series with multiple sensors), has been focused on for several years. Though existing method has achieved great progress, there are several challenging problems to be solved. Firstly, existing method including neural network only concentrate on the relationship in terms of timestamp. To be exact, they only want to know how does the data in the past influence which in the future. However, one sensor sometimes intervenes in other sensor such as the speed of wind may cause decrease of temperature. Secondly, there exist two categories of model for time series anomaly detection: prediction model and reconstruction model. Prediction model is adept at learning timely representation while short of capability when faced with sparse anomaly. Conversely, reconstruction model is opposite. Therefore, how can we efficiently get the relationship both in terms of both timestamp and sensors becomes our main topic. Our approach uses GAT, which is originated from graph neural network, to obtain connection between sensors. And LSTM is used to obtain relationships timely. Our approach is also designed to be double headed to calculate both prediction loss and reconstruction loss via VAE(Variational Auto-Encoder). In order to take advantage of two sorts of model, multi-task optimization algorithm is used in this model.
Continuous-Time Gaussian Process Motion-Compensation for Event-vision Pattern Tracking with Distance Fields
Mar 05, 2023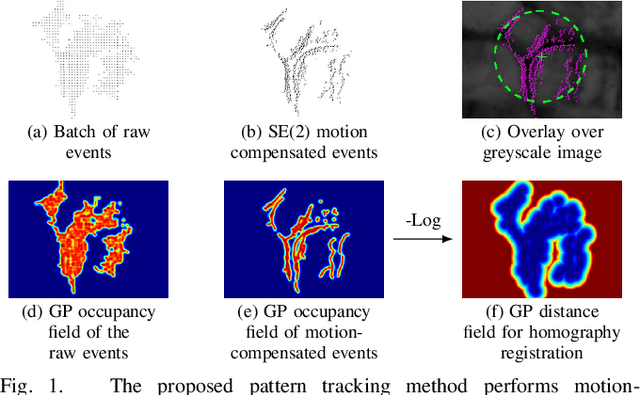
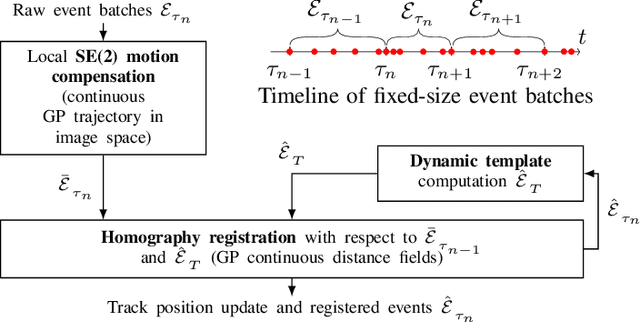

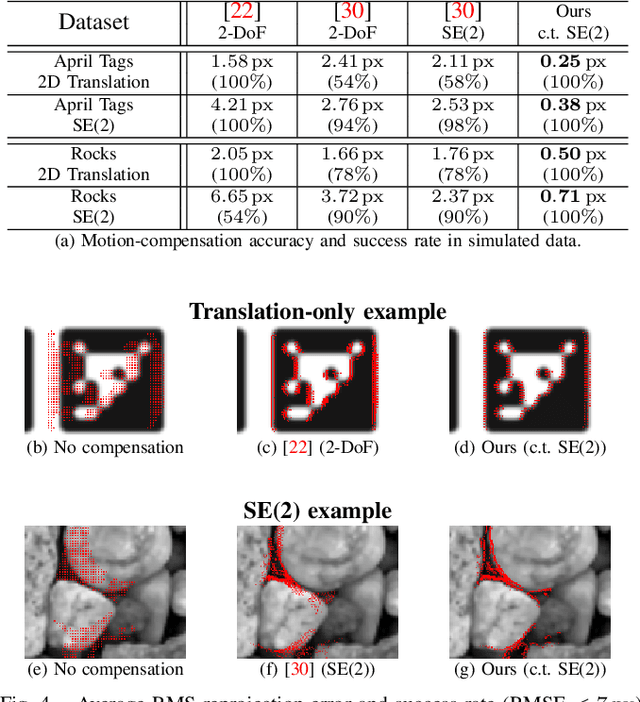
This work addresses the issue of motion compensation and pattern tracking in event camera data. An event camera generates asynchronous streams of events triggered independently by each of the pixels upon changes in the observed intensity. Providing great advantages in low-light and rapid-motion scenarios, such unconventional data present significant research challenges as traditional vision algorithms are not directly applicable to this sensing modality. The proposed method decomposes the tracking problem into a local SE(2) motion-compensation step followed by a homography registration of small motion-compensated event batches. The first component relies on Gaussian Process (GP) theory to model the continuous occupancy field of the events in the image plane and embed the camera trajectory in the covariance kernel function. In doing so, estimating the trajectory is done similarly to GP hyperparameter learning by maximising the log marginal likelihood of the data. The continuous occupancy fields are turned into distance fields and used as templates for homography-based registration. By benchmarking the proposed method against other state-of-the-art techniques, we show that our open-source implementation performs high-accuracy motion compensation and produces high-quality tracks in real-world scenarios.
Self-Supervised Scene Dynamic Recovery from Rolling Shutter Images and Events
Apr 19, 2023
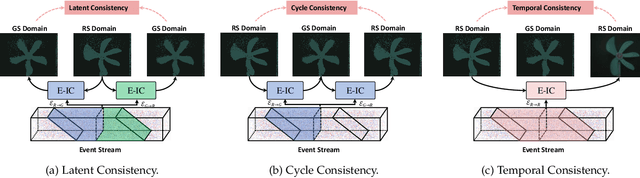

Scene Dynamic Recovery (SDR) by inverting distorted Rolling Shutter (RS) images to an undistorted high frame-rate Global Shutter (GS) video is a severely ill-posed problem due to the missing temporal dynamic information in both RS intra-frame scanlines and inter-frame exposures, particularly when prior knowledge about camera/object motions is unavailable. Commonly used artificial assumptions on scenes/motions and data-specific characteristics are prone to producing sub-optimal solutions in real-world scenarios. To address this challenge, we propose an event-based SDR network within a self-supervised learning paradigm, i.e., SelfUnroll. We leverage the extremely high temporal resolution of event cameras to provide accurate inter/intra-frame dynamic information. Specifically, an Event-based Inter/intra-frame Compensator (E-IC) is proposed to predict the per-pixel dynamic between arbitrary time intervals, including the temporal transition and spatial translation. Exploring connections in terms of RS-RS, RS-GS, and GS-RS, we explicitly formulate mutual constraints with the proposed E-IC, resulting in supervisions without ground-truth GS images. Extensive evaluations over synthetic and real datasets demonstrate that the proposed method achieves state-of-the-art and shows remarkable performance for event-based RS2GS inversion in real-world scenarios. The dataset and code are available at https://w3un.github.io/selfunroll/.
Decadal Temperature Prediction via Chaotic Behavior Tracking
Apr 19, 2023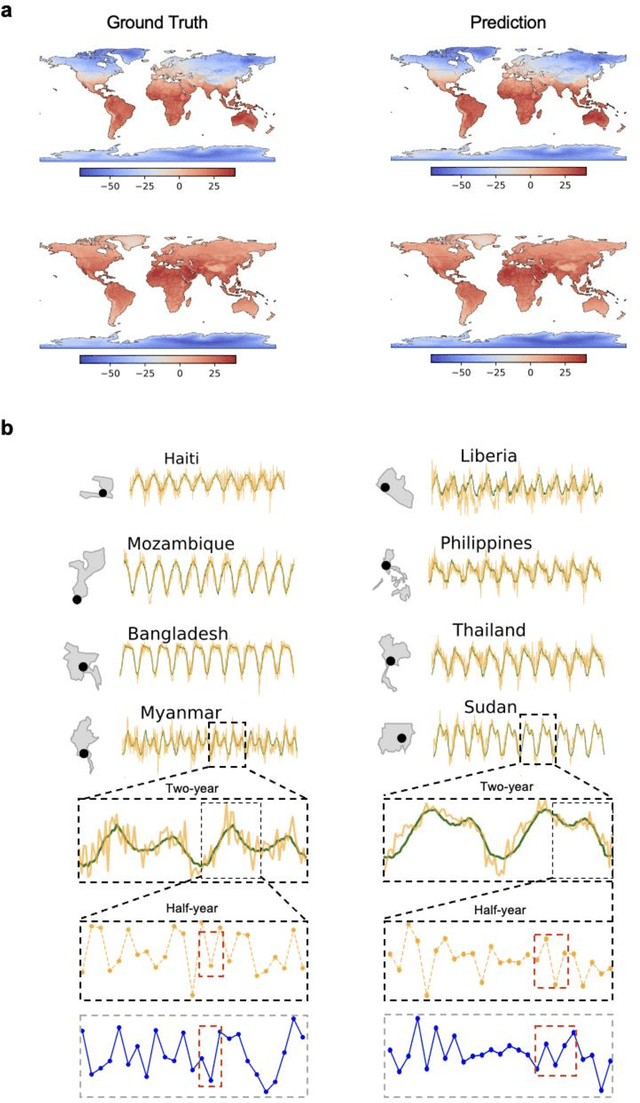
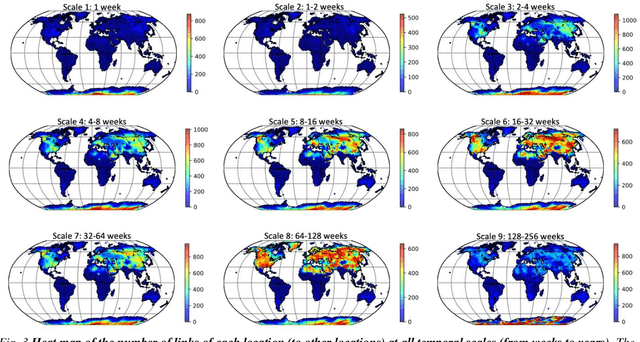
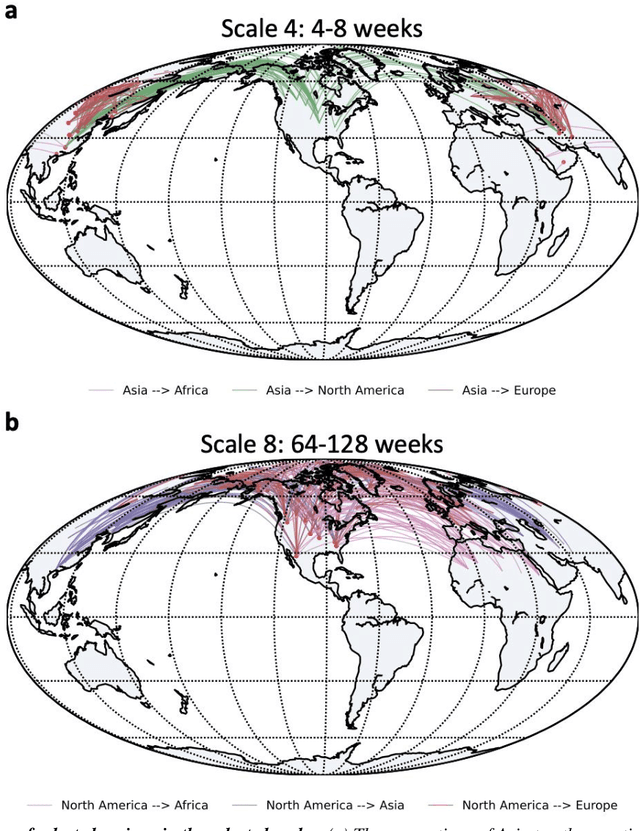
Decadal temperature prediction provides crucial information for quantifying the expected effects of future climate changes and thus informs strategic planning and decision-making in various domains. However, such long-term predictions are extremely challenging, due to the chaotic nature of temperature variations. Moreover, the usefulness of existing simulation-based and machine learning-based methods for this task is limited because initial simulation or prediction errors increase exponentially over time. To address this challenging task, we devise a novel prediction method involving an information tracking mechanism that aims to track and adapt to changes in temperature dynamics during the prediction phase by providing probabilistic feedback on the prediction error of the next step based on the current prediction. We integrate this information tracking mechanism, which can be considered as a model calibrator, into the objective function of our method to obtain the corrections needed to avoid error accumulation. Our results show the ability of our method to accurately predict global land-surface temperatures over a decadal range. Furthermore, we demonstrate that our results are meaningful in a real-world context: the temperatures predicted using our method are consistent with and can be used to explain the well-known teleconnections within and between different continents.
MTrainS: Improving DLRM training efficiency using heterogeneous memories
Apr 19, 2023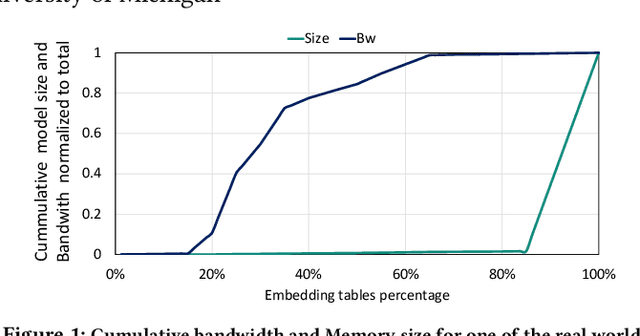
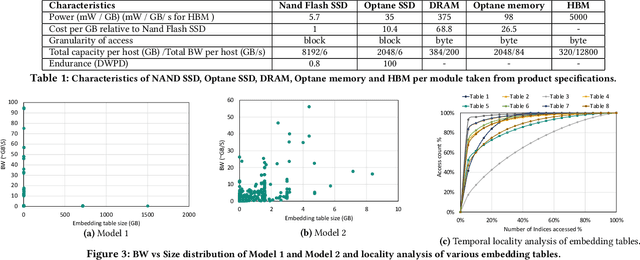
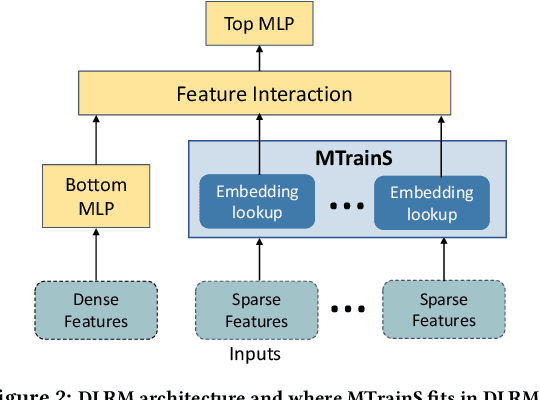

Recommendation models are very large, requiring terabytes (TB) of memory during training. In pursuit of better quality, the model size and complexity grow over time, which requires additional training data to avoid overfitting. This model growth demands a large number of resources in data centers. Hence, training efficiency is becoming considerably more important to keep the data center power demand manageable. In Deep Learning Recommendation Models (DLRM), sparse features capturing categorical inputs through embedding tables are the major contributors to model size and require high memory bandwidth. In this paper, we study the bandwidth requirement and locality of embedding tables in real-world deployed models. We observe that the bandwidth requirement is not uniform across different tables and that embedding tables show high temporal locality. We then design MTrainS, which leverages heterogeneous memory, including byte and block addressable Storage Class Memory for DLRM hierarchically. MTrainS allows for higher memory capacity per node and increases training efficiency by lowering the need to scale out to multiple hosts in memory capacity bound use cases. By optimizing the platform memory hierarchy, we reduce the number of nodes for training by 4-8X, saving power and cost of training while meeting our target training performance.
Progressive Transfer Learning for Dexterous In-Hand Manipulation with Multi-Fingered Anthropomorphic Hand
Apr 19, 2023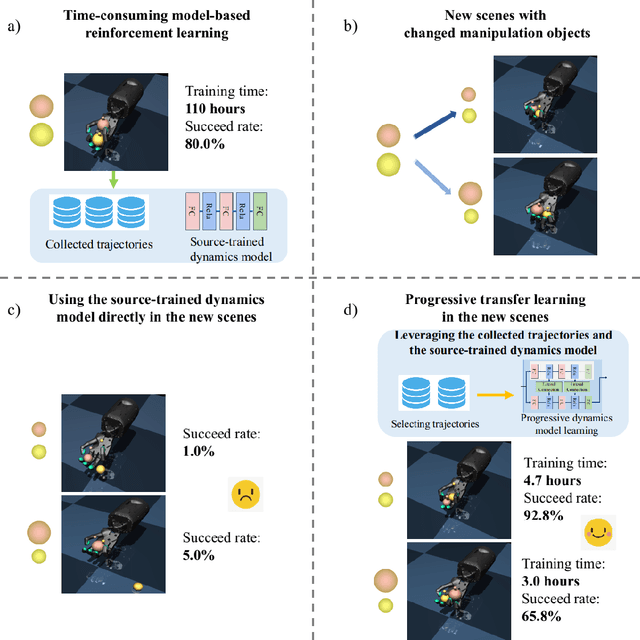
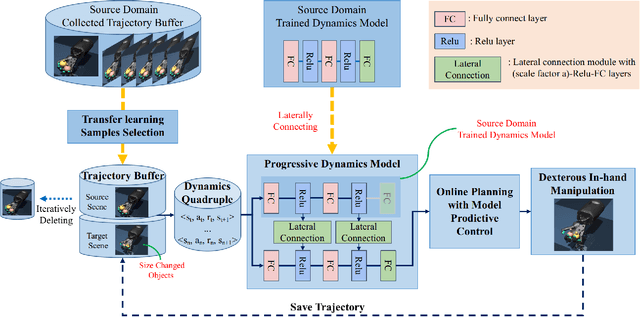
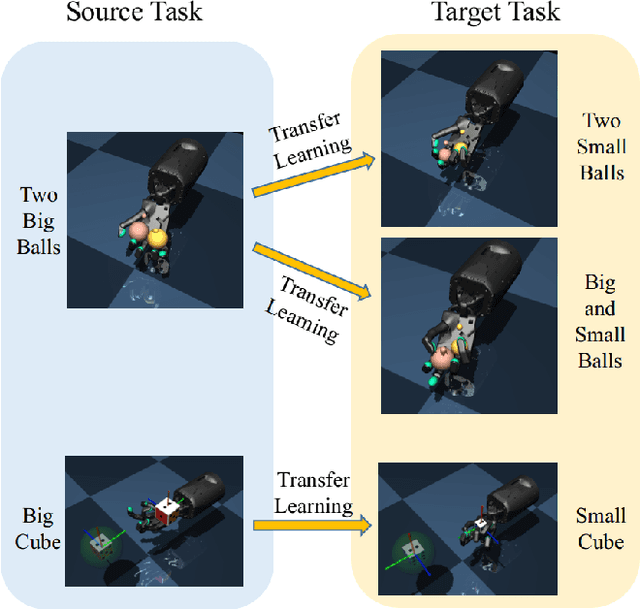
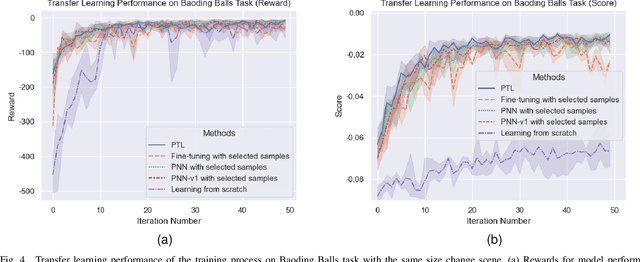
Dexterous in-hand manipulation for a multi-fingered anthropomorphic hand is extremely difficult because of the high-dimensional state and action spaces, rich contact patterns between the fingers and objects. Even though deep reinforcement learning has made moderate progress and demonstrated its strong potential for manipulation, it is still faced with certain challenges, such as large-scale data collection and high sample complexity. Especially, for some slight change scenes, it always needs to re-collect vast amounts of data and carry out numerous iterations of fine-tuning. Remarkably, humans can quickly transfer learned manipulation skills to different scenarios with little supervision. Inspired by human flexible transfer learning capability, we propose a novel dexterous in-hand manipulation progressive transfer learning framework (PTL) based on efficiently utilizing the collected trajectories and the source-trained dynamics model. This framework adopts progressive neural networks for dynamics model transfer learning on samples selected by a new samples selection method based on dynamics properties, rewards and scores of the trajectories. Experimental results on contact-rich anthropomorphic hand manipulation tasks show that our method can efficiently and effectively learn in-hand manipulation skills with a few online attempts and adjustment learning under the new scene. Compared to learning from scratch, our method can reduce training time costs by 95%.
Time-aware Prompting for Text Generation
Nov 03, 2022
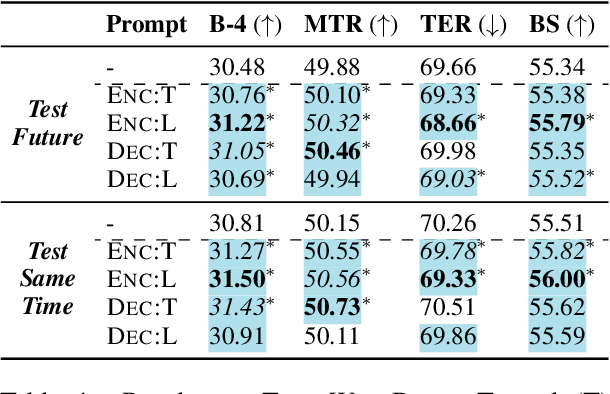
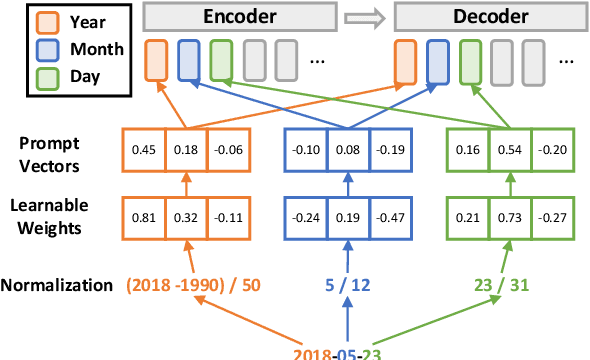
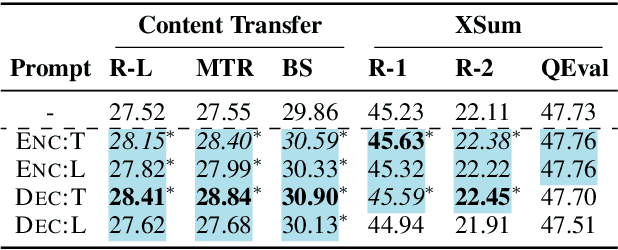
In this paper, we study the effects of incorporating timestamps, such as document creation dates, into generation systems. Two types of time-aware prompts are investigated: (1) textual prompts that encode document timestamps in natural language sentences; and (2) linear prompts that convert timestamps into continuous vectors. To explore extrapolation to future data points, we further introduce a new data-to-text generation dataset, TempWikiBio, containing more than 4 millions of chronologically ordered revisions of biographical articles from English Wikipedia, each paired with structured personal profiles. Through data-to-text generation on TempWikiBio, text-to-text generation on the content transfer dataset, and summarization on XSum, we show that linear prompts on encoder and textual prompts improve the generation quality on all datasets. Despite having less performance drop when testing on data drawn from a later time, linear prompts focus more on non-temporal information and are less sensitive to the given timestamps, according to human evaluations and sensitivity analyses. Meanwhile, textual prompts establish the association between the given timestamps and the output dates, yielding more factual temporal information in the output.
Causal Repair of Learning-enabled Cyber-physical Systems
Apr 06, 2023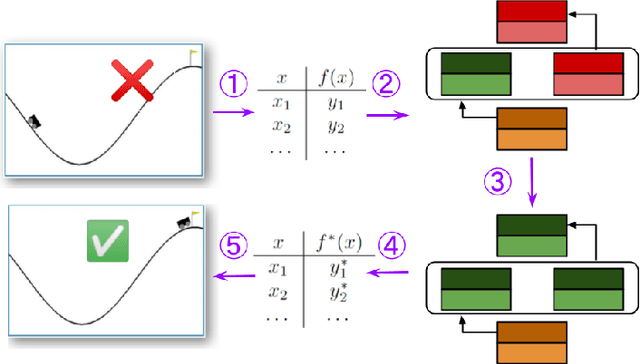
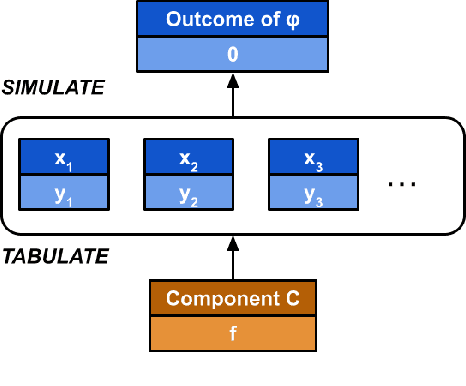
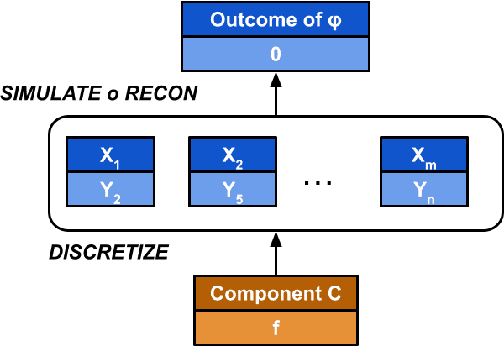
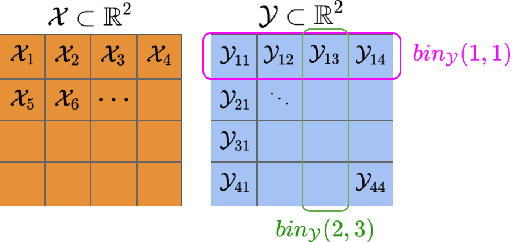
Models of actual causality leverage domain knowledge to generate convincing diagnoses of events that caused an outcome. It is promising to apply these models to diagnose and repair run-time property violations in cyber-physical systems (CPS) with learning-enabled components (LEC). However, given the high diversity and complexity of LECs, it is challenging to encode domain knowledge (e.g., the CPS dynamics) in a scalable actual causality model that could generate useful repair suggestions. In this paper, we focus causal diagnosis on the input/output behaviors of LECs. Specifically, we aim to identify which subset of I/O behaviors of the LEC is an actual cause for a property violation. An important by-product is a counterfactual version of the LEC that repairs the run-time property by fixing the identified problematic behaviors. Based on this insights, we design a two-step diagnostic pipeline: (1) construct and Halpern-Pearl causality model that reflects the dependency of property outcome on the component's I/O behaviors, and (2) perform a search for an actual cause and corresponding repair on the model. We prove that our pipeline has the following guarantee: if an actual cause is found, the system is guaranteed to be repaired; otherwise, we have high probabilistic confidence that the LEC under analysis did not cause the property violation. We demonstrate that our approach successfully repairs learned controllers on a standard OpenAI Gym benchmark.