 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Statistical and computational rates in high rank tensor estimation
Apr 08, 2023

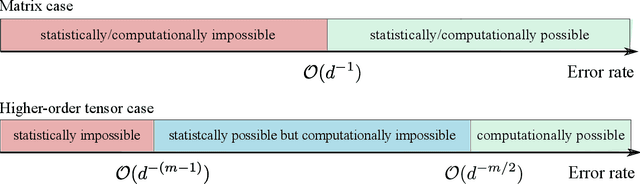
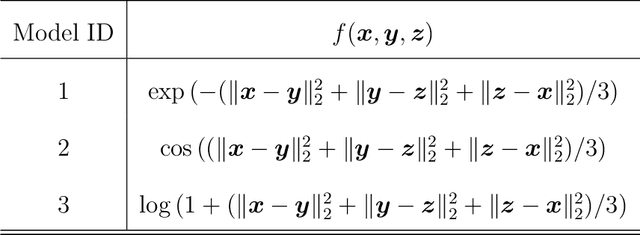
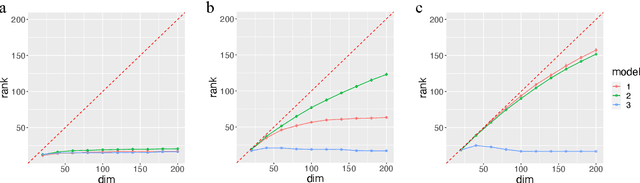
Higher-order tensor datasets arise commonly in recommendation systems, neuroimaging, and social networks. Here we develop probable methods for estimating a possibly high rank signal tensor from noisy observations. We consider a generative latent variable tensor model that incorporates both high rank and low rank models, including but not limited to, simple hypergraphon models, single index models, low-rank CP models, and low-rank Tucker models. Comprehensive results are developed on both the statistical and computational limits for the signal tensor estimation. We find that high-dimensional latent variable tensors are of log-rank; the fact explains the pervasiveness of low-rank tensors in applications. Furthermore, we propose a polynomial-time spectral algorithm that achieves the computationally optimal rate. We show that the statistical-computational gap emerges only for latent variable tensors of order 3 or higher. Numerical experiments and two real data applications are presented to demonstrate the practical merits of our methods.
Faulty Branch Identification in Passive Optical Networks using Machine Learning
Apr 03, 2023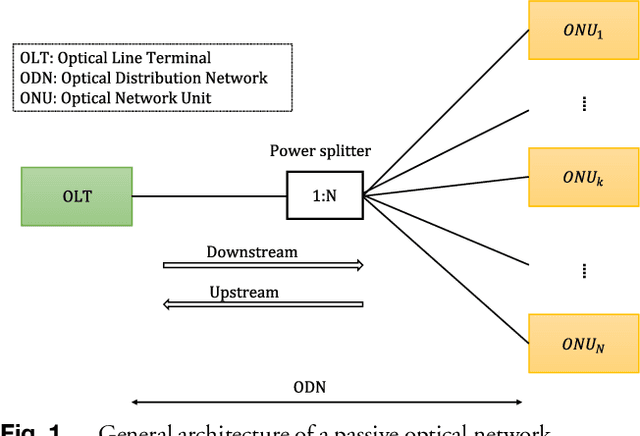

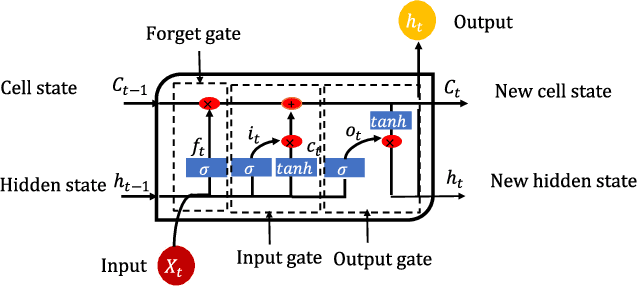
Passive optical networks (PONs) have become a promising broadband access network solution. To ensure a reliable transmission, and to meet service level agreements, PON systems have to be monitored constantly in order to quickly identify and localize networks faults. Typically, a service disruption in a PON system is mainly due to fiber cuts and optical network unit (ONU) transmitter/receiver failures. When the ONUs are located at different distances from the optical line terminal (OLT), the faulty ONU or branch can be identified by analyzing the recorded optical time domain reflectometry (OTDR) traces. However, faulty branch isolation becomes very challenging when the reflections originating from two or more branches with similar length overlap, which makes it very hard to discriminate the faulty branches given the global backscattered signal. Recently, machine learning (ML) based approaches have shown great potential for managing optical faults in PON systems. Such techniques perform well when trained and tested with data derived from the same PON system. But their performance may severely degrade, if the PON system (adopted for the generation of the training data) has changed, e.g. by adding more branches or varying the length difference between two neighboring branches. etc. A re-training of the ML models has to be conducted for each network change, which can be time consuming. In this paper, to overcome the aforementioned issues, we propose a generic ML approach trained independently of the network architecture for identifying the faulty branch in PON systems given OTDR signals for the cases of branches with close lengths. Such an approach can be applied to an arbitrary PON system without requiring to be re-trained for each change of the network. The proposed approach is validated using experimental data derived from PON system.
An End-to-End Human Simulator for Task-Oriented Multimodal Human-Robot Collaboration
Apr 02, 2023

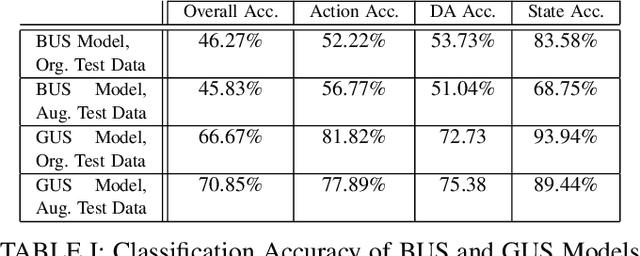
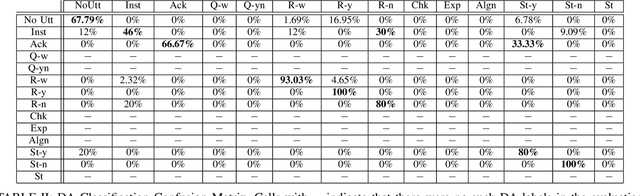
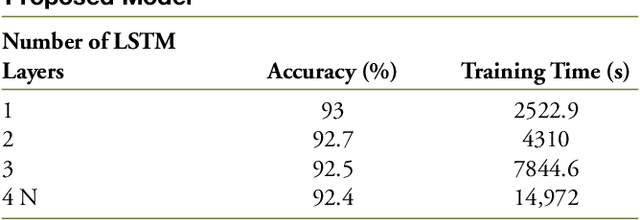
This paper proposes a neural network-based user simulator that can provide a multimodal interactive environment for training Reinforcement Learning (RL) agents in collaborative tasks involving multiple modes of communication. The simulator is trained on the existing ELDERLY-AT-HOME corpus and accommodates multiple modalities such as language, pointing gestures, and haptic-ostensive actions. The paper also presents a novel multimodal data augmentation approach, which addresses the challenge of using a limited dataset due to the expensive and time-consuming nature of collecting human demonstrations. Overall, the study highlights the potential for using RL and multimodal user simulators in developing and improving domestic assistive robots.
Design of Efficient Point-Mass Filter with Application in Terrain Aided Navigation
Mar 09, 2023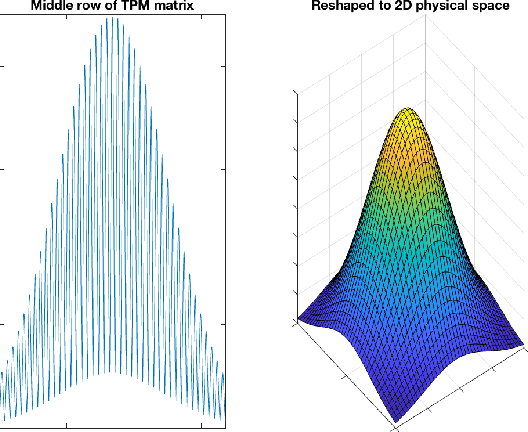
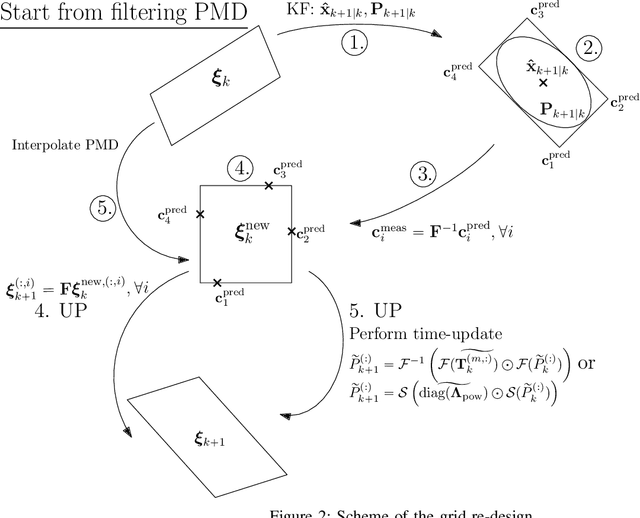
This paper deals with state estimation of stochastic models with linear state dynamics, continuous or discrete in time. The emphasis is laid on a numerical solution to the state prediction by the time-update step of the grid-point-based point-mass filter (PMF), which is the most computationally demanding part of the PMF algorithm. A novel efficient PMF (ePMF) estimator is proposed, designed, and discussed. By numerical illustrations, it is shown, that the proposed ePMF can lead to a time complexity reduction that exceeds 99.9% without compromising accuracy. The MATLAB code of the ePMF is released with this paper.
SST: Real-time End-to-end Monocular 3D Reconstruction via Sparse Spatial-Temporal Guidance
Dec 13, 2022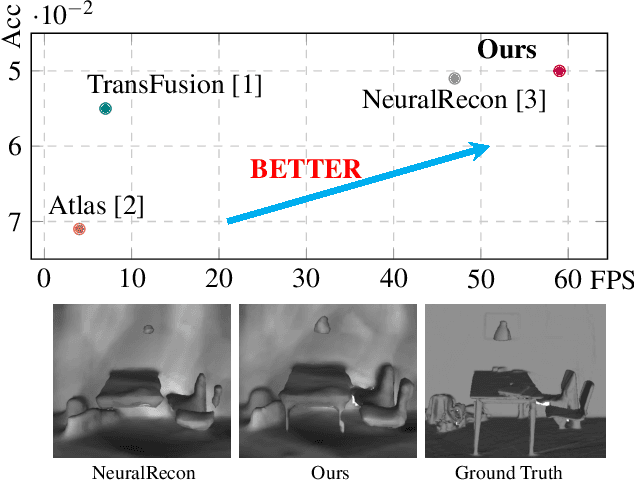
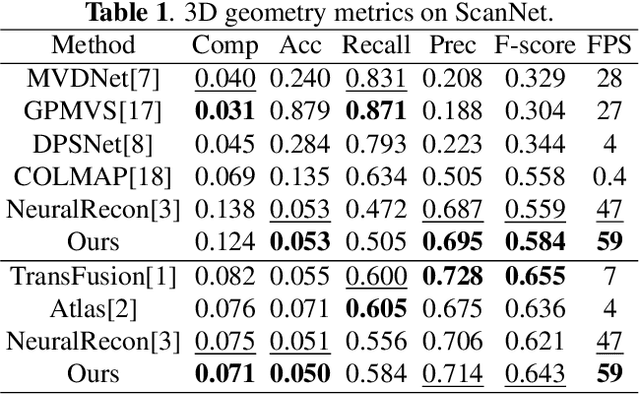
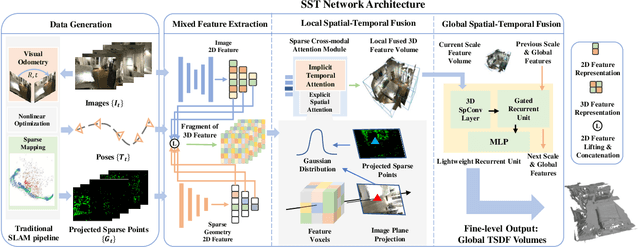
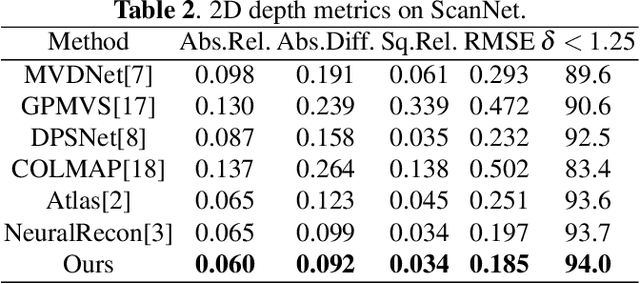
Real-time monocular 3D reconstruction is a challenging problem that remains unsolved. Although recent end-to-end methods have demonstrated promising results, tiny structures and geometric boundaries are hardly captured due to their insufficient supervision neglecting spatial details and oversimplified feature fusion ignoring temporal cues. To address the problems, we propose an end-to-end 3D reconstruction network SST, which utilizes Sparse estimated points from visual SLAM system as additional Spatial guidance and fuses Temporal features via a novel cross-modal attention mechanism, achieving more detailed reconstruction results. We propose a Local Spatial-Temporal Fusion module to exploit more informative spatial-temporal cues from multi-view color information and sparse priors, as well a Global Spatial-Temporal Fusion module to refine the local TSDF volumes with the world-frame model from coarse to fine. Extensive experiments on ScanNet and 7-Scenes demonstrate that SST outperforms all state-of-the-art competitors, whilst keeping a high inference speed at 59 FPS, enabling real-world applications with real-time requirements.
Computationally Budgeted Continual Learning: What Does Matter?
Mar 20, 2023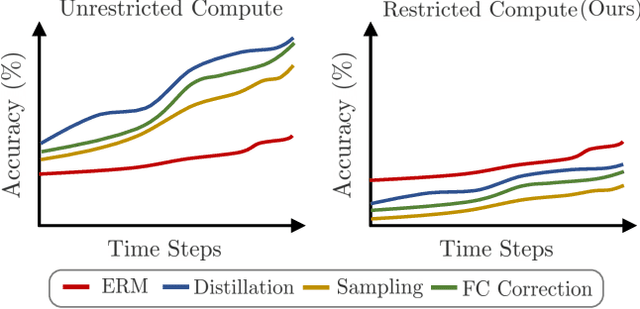
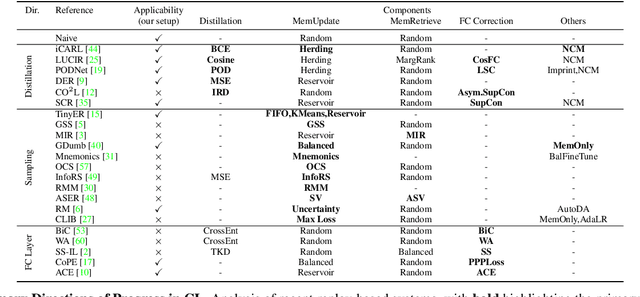
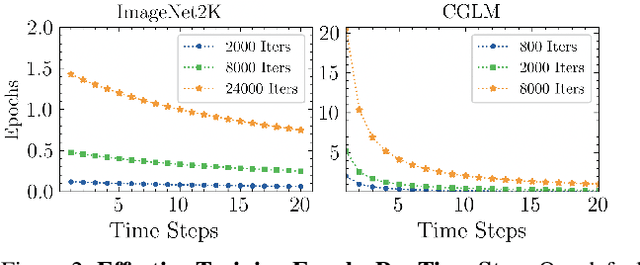
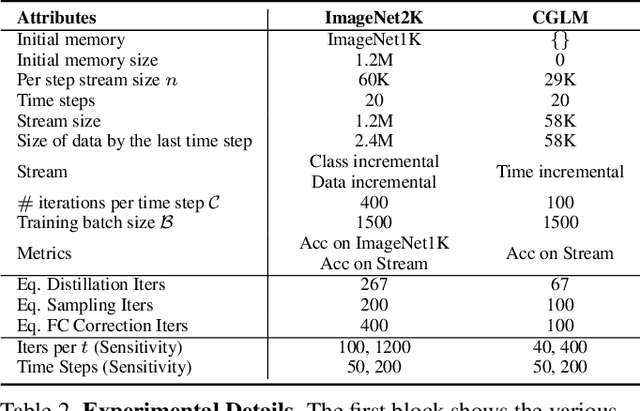
Continual Learning (CL) aims to sequentially train models on streams of incoming data that vary in distribution by preserving previous knowledge while adapting to new data. Current CL literature focuses on restricted access to previously seen data, while imposing no constraints on the computational budget for training. This is unreasonable for applications in-the-wild, where systems are primarily constrained by computational and time budgets, not storage. We revisit this problem with a large-scale benchmark and analyze the performance of traditional CL approaches in a compute-constrained setting, where effective memory samples used in training can be implicitly restricted as a consequence of limited computation. We conduct experiments evaluating various CL sampling strategies, distillation losses, and partial fine-tuning on two large-scale datasets, namely ImageNet2K and Continual Google Landmarks V2 in data incremental, class incremental, and time incremental settings. Through extensive experiments amounting to a total of over 1500 GPU-hours, we find that, under compute-constrained setting, traditional CL approaches, with no exception, fail to outperform a simple minimal baseline that samples uniformly from memory. Our conclusions are consistent in a different number of stream time steps, e.g., 20 to 200, and under several computational budgets. This suggests that most existing CL methods are particularly too computationally expensive for realistic budgeted deployment. Code for this project is available at: https://github.com/drimpossible/BudgetCL.
GNN-Assisted Phase Space Integration with Application to Atomistics
Mar 20, 2023
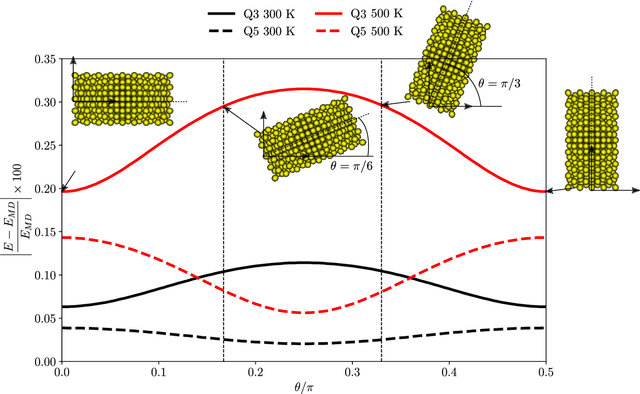
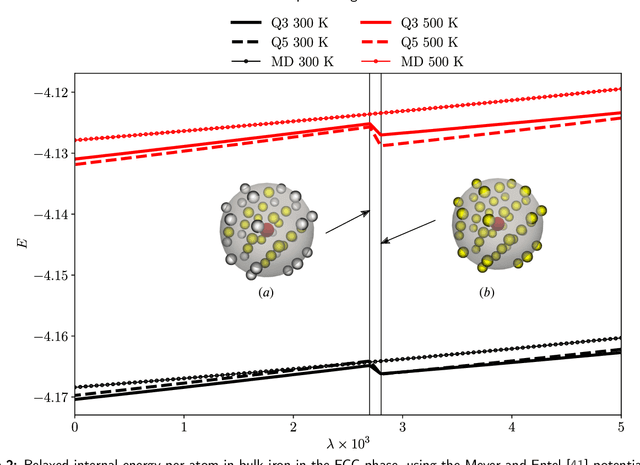

Overcoming the time scale limitations of atomistics can be achieved by switching from the state-space representation of Molecular Dynamics (MD) to a statistical-mechanics-based representation in phase space, where approximations such as maximum-entropy or Gaussian phase packets (GPP) evolve the atomistic ensemble in a time-coarsened fashion. In practice, this requires the computation of expensive high-dimensional integrals over all of phase space of an atomistic ensemble. This, in turn, is commonly accomplished efficiently by low-order numerical quadrature. We show that numerical quadrature in this context, unfortunately, comes with a set of inherent problems, which corrupt the accuracy of simulations -- especially when dealing with crystal lattices with imperfections. As a remedy, we demonstrate that Graph Neural Networks, trained on Monte-Carlo data, can serve as a replacement for commonly used numerical quadrature rules, overcoming their deficiencies and significantly improving the accuracy. This is showcased by three benchmarks: the thermal expansion of copper, the martensitic phase transition of iron, and the energy of grain boundaries. We illustrate the benefits of the proposed technique over classically used third- and fifth-order Gaussian quadrature, we highlight the impact on time-coarsened atomistic predictions, and we discuss the computational efficiency. The latter is of general importance when performing frequent evaluation of phase space or other high-dimensional integrals, which is why the proposed framework promises applications beyond the scope of atomistics.
Learning the Delay Using Neural Delay Differential Equations
Apr 03, 2023
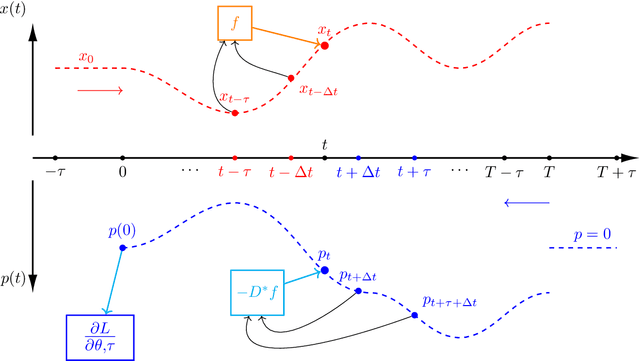
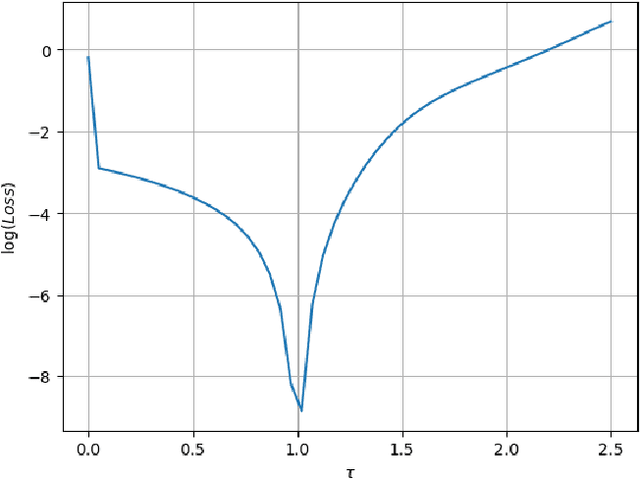
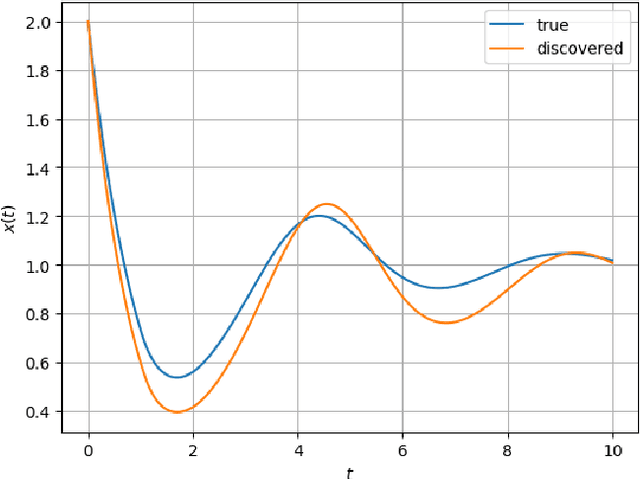
The intersection of machine learning and dynamical systems has generated considerable interest recently. Neural Ordinary Differential Equations (NODEs) represent a rich overlap between these fields. In this paper, we develop a continuous time neural network approach based on Delay Differential Equations (DDEs). Our model uses the adjoint sensitivity method to learn the model parameters and delay directly from data. Our approach is inspired by that of NODEs and extends earlier neural DDE models, which have assumed that the value of the delay is known a priori. We perform a sensitivity analysis on our proposed approach and demonstrate its ability to learn DDE parameters from benchmark systems. We conclude our discussion with potential future directions and applications.
V2V-based Collision-avoidance Decision Strategy for Autonomous Vehicles Interacting with Fully Occluded Pedestrians at Midblock on Multilane Roadways
Mar 23, 2023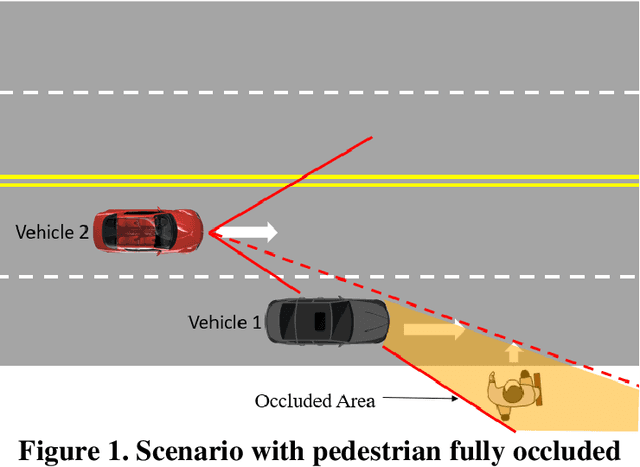

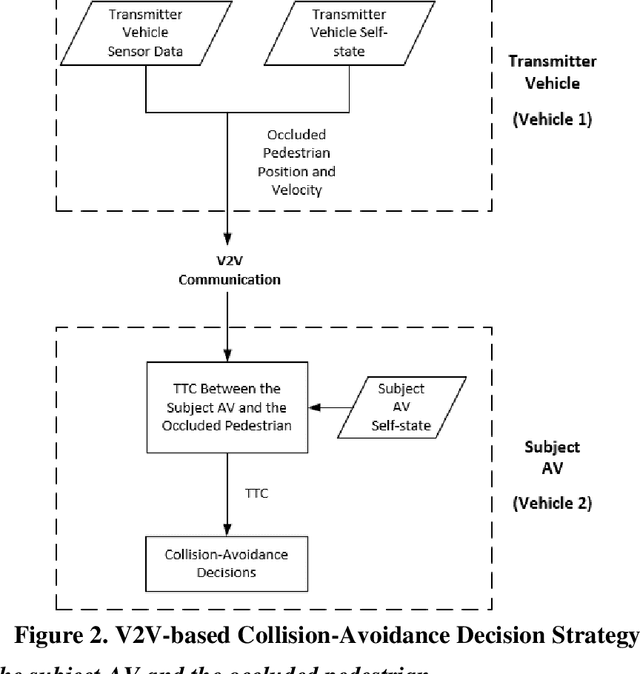
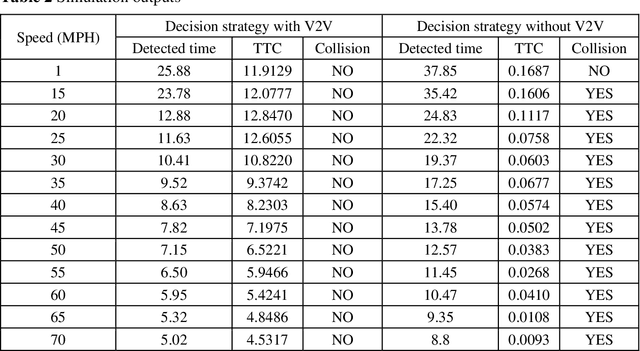
Pedestrian occlusion is challenging for autonomous vehicles (AVs) at midblock locations on multilane roadways because an AV cannot detect crossing pedestrians that are fully occluded by downstream vehicles in adjacent lanes. This paper tests the capability of vehicle-to-vehicle (V2V) communication between an AV and its downstream vehicles to share midblock pedestrian crossings information. The researchers developed a V2V-based collision-avoidance decision strategy and compared it to a base scenario (i.e., decision strategy without the utilization of V2V). Simulation results showed that for the base scenario, the near-zero time-to-collision (TTC) indicated no time for the AV to take appropriate action and resulted in dramatic braking followed by collisions. But the V2V-based collision-avoidance decision strategy allowed for a proportional braking approach to increase the TTC allowing the pedestrian to cross safely. To conclude, the V2V-based collision-avoidance decision strategy has higher safety benefits for an AV interacting with fully occluded pedestrians at midblock locations on multilane roadways.
Backdoor Defense via Adaptively Splitting Poisoned Dataset
Mar 23, 2023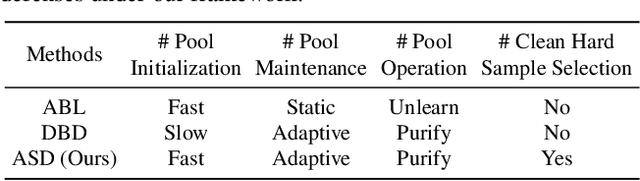
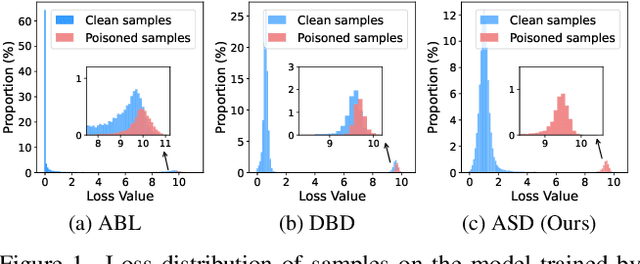
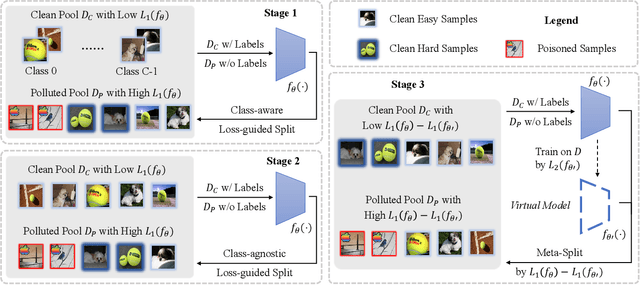
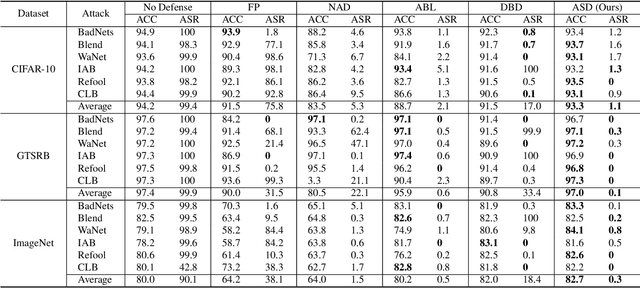
Backdoor defenses have been studied to alleviate the threat of deep neural networks (DNNs) being backdoor attacked and thus maliciously altered. Since DNNs usually adopt some external training data from an untrusted third party, a robust backdoor defense strategy during the training stage is of importance. We argue that the core of training-time defense is to select poisoned samples and to handle them properly. In this work, we summarize the training-time defenses from a unified framework as splitting the poisoned dataset into two data pools. Under our framework, we propose an adaptively splitting dataset-based defense (ASD). Concretely, we apply loss-guided split and meta-learning-inspired split to dynamically update two data pools. With the split clean data pool and polluted data pool, ASD successfully defends against backdoor attacks during training. Extensive experiments on multiple benchmark datasets and DNN models against six state-of-the-art backdoor attacks demonstrate the superiority of our ASD. Our code is available at https://github.com/KuofengGao/ASD.