 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Reference Model for Collaborative Business Intelligence Virtual Assistants
Apr 20, 2023
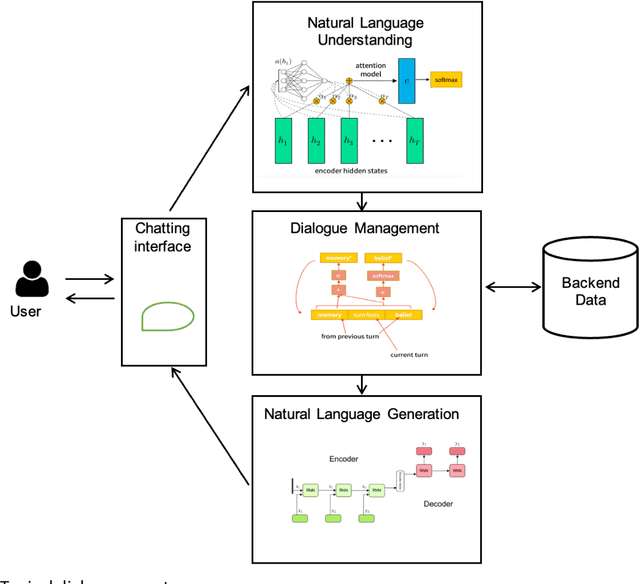
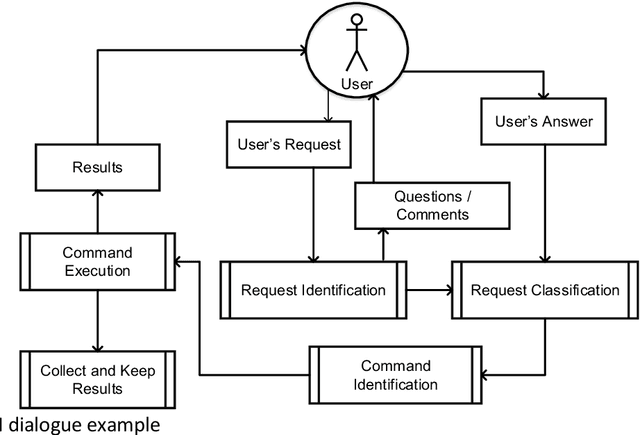
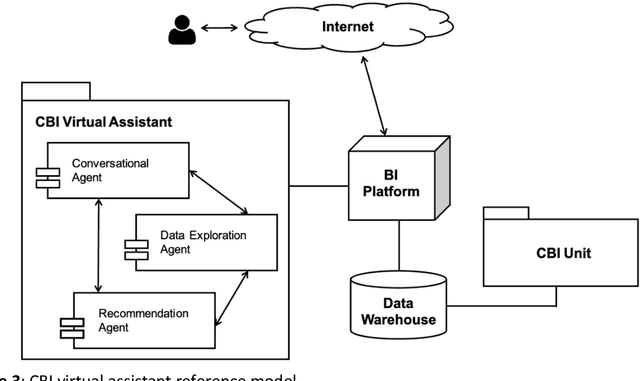
Collaborative Business Analysis (CBA) is a methodology that involves bringing together different stakeholders, including business users, analysts, and technical specialists, to collaboratively analyze data and gain insights into business operations. The primary objective of CBA is to encourage knowledge sharing and collaboration between the different groups involved in business analysis, as this can lead to a more comprehensive understanding of the data and better decision-making. CBA typically involves a range of activities, including data gathering and analysis, brainstorming, problem-solving, decision-making and knowledge sharing. These activities may take place through various channels, such as in-person meetings, virtual collaboration tools or online forums. This paper deals with virtual collaboration tools as an important part of Business Intelligence (BI) platform. Collaborative Business Intelligence (CBI) tools are becoming more user-friendly, accessible, and flexible, allowing users to customize their experience and adapt to their specific needs. The goal of a virtual assistant is to make data exploration more accessible to a wider range of users and to reduce the time and effort required for data analysis. It describes the unified business intelligence semantic model, coupled with a data warehouse and collaborative unit to employ data mining technology. Moreover, we propose a virtual assistant for CBI and a reference model of virtual tools for CBI, which consists of three components: conversational, data exploration and recommendation agents. We believe that the allocation of these three functional tasks allows you to structure the CBI issue and apply relevant and productive models for human-like dialogue, text-to-command transferring, and recommendations simultaneously. The complex approach based on these three points gives the basis for virtual tool for collaboration. CBI encourages people, processes, and technology to enable everyone sharing and leveraging collective expertise, knowledge and data to gain valuable insights for making better decisions. This allows to respond more quickly and effectively to changes in the market or internal operations and improve the progress.
StarNet: Style-Aware 3D Point Cloud Generation
Mar 28, 2023
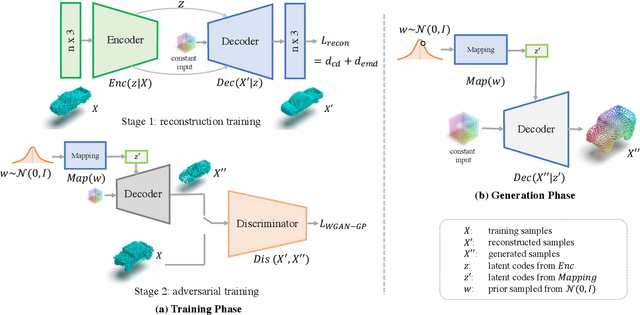
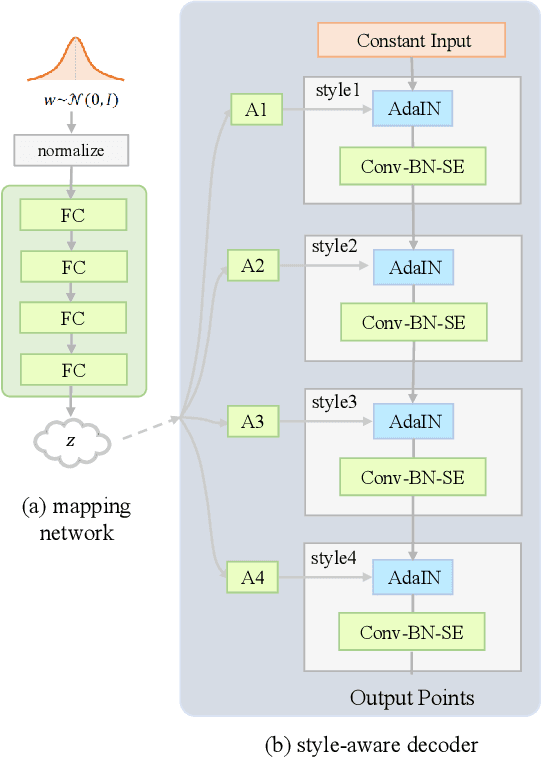

This paper investigates an open research task of reconstructing and generating 3D point clouds. Most existing works of 3D generative models directly take the Gaussian prior as input for the decoder to generate 3D point clouds, which fail to learn disentangled latent codes, leading noisy interpolated results. Most of the GAN-based models fail to discriminate the local geometries, resulting in the point clouds generated not evenly distributed at the object surface, hence degrading the point cloud generation quality. Moreover, prevailing methods adopt computation-intensive frameworks, such as flow-based models and Markov chains, which take plenty of time and resources in the training phase. To resolve these limitations, this paper proposes a unified style-aware network architecture combining both point-wise distance loss and adversarial loss, StarNet which is able to reconstruct and generate high-fidelity and even 3D point clouds using a mapping network that can effectively disentangle the Gaussian prior from input's high-level attributes in the mapped latent space to generate realistic interpolated objects. Experimental results demonstrate that our framework achieves comparable state-of-the-art performance on various metrics in the point cloud reconstruction and generation tasks, but is more lightweight in model size, requires much fewer parameters and less time for model training.
FeDiSa: A Semi-asynchronous Federated Learning Framework for Power System Fault and Cyberattack Discrimination
Mar 28, 2023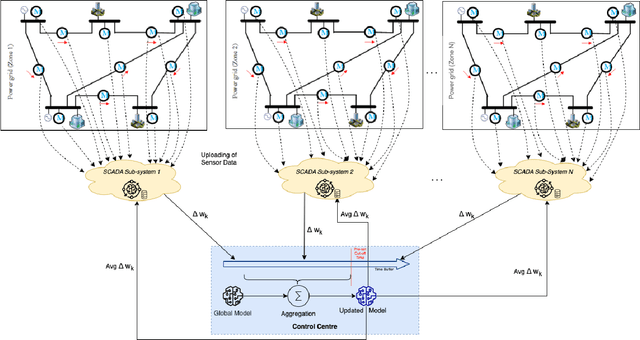
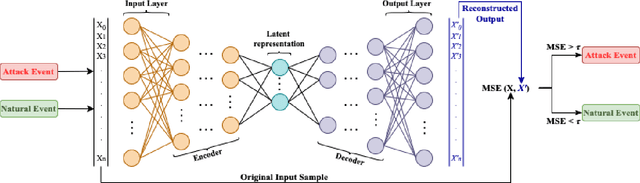
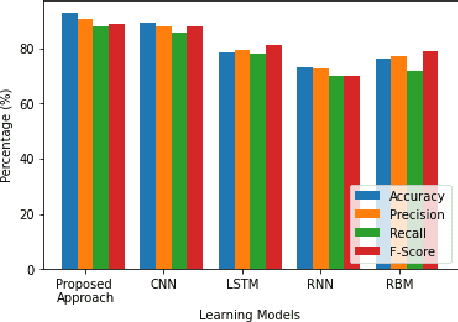
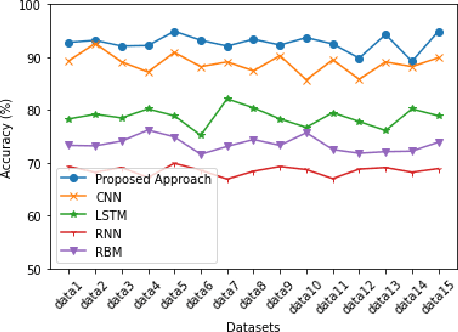
With growing security and privacy concerns in the Smart Grid domain, intrusion detection on critical energy infrastructure has become a high priority in recent years. To remedy the challenges of privacy preservation and decentralized power zones with strategic data owners, Federated Learning (FL) has contemporarily surfaced as a viable privacy-preserving alternative which enables collaborative training of attack detection models without requiring the sharing of raw data. To address some of the technical challenges associated with conventional synchronous FL, this paper proposes FeDiSa, a novel Semi-asynchronous Federated learning framework for power system faults and cyberattack Discrimination which takes into account communication latency and stragglers. Specifically, we propose a collaborative training of deep auto-encoder by Supervisory Control and Data Acquisition sub-systems which upload their local model updates to a control centre, which then perform a semi-asynchronous model aggregation for a new global model parameters based on a buffer system and a preset cut-off time. Experiments on the proposed framework using publicly available industrial control systems datasets reveal superior attack detection accuracy whilst preserving data confidentiality and minimizing the adverse effects of communication latency and stragglers. Furthermore, we see a 35% improvement in training time, thus validating the robustness of our proposed method.
Statistical and computational rates in high rank tensor estimation
Apr 08, 2023
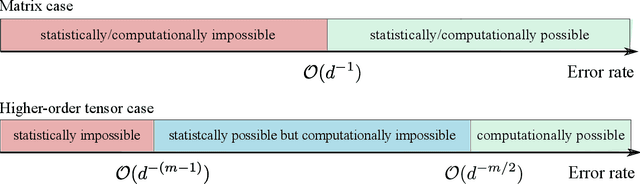
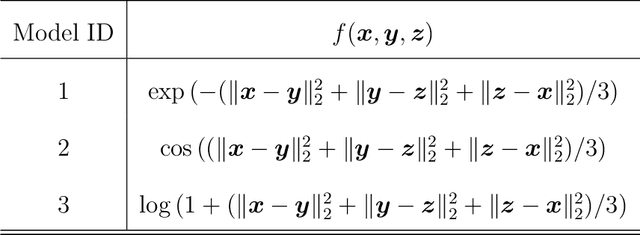
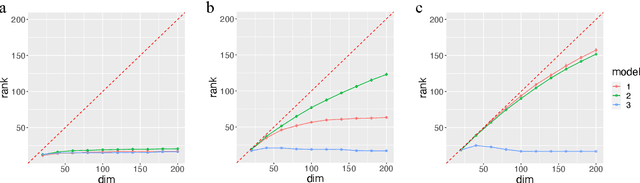
Higher-order tensor datasets arise commonly in recommendation systems, neuroimaging, and social networks. Here we develop probable methods for estimating a possibly high rank signal tensor from noisy observations. We consider a generative latent variable tensor model that incorporates both high rank and low rank models, including but not limited to, simple hypergraphon models, single index models, low-rank CP models, and low-rank Tucker models. Comprehensive results are developed on both the statistical and computational limits for the signal tensor estimation. We find that high-dimensional latent variable tensors are of log-rank; the fact explains the pervasiveness of low-rank tensors in applications. Furthermore, we propose a polynomial-time spectral algorithm that achieves the computationally optimal rate. We show that the statistical-computational gap emerges only for latent variable tensors of order 3 or higher. Numerical experiments and two real data applications are presented to demonstrate the practical merits of our methods.
Test-Time Training for Graph Neural Networks
Oct 17, 2022
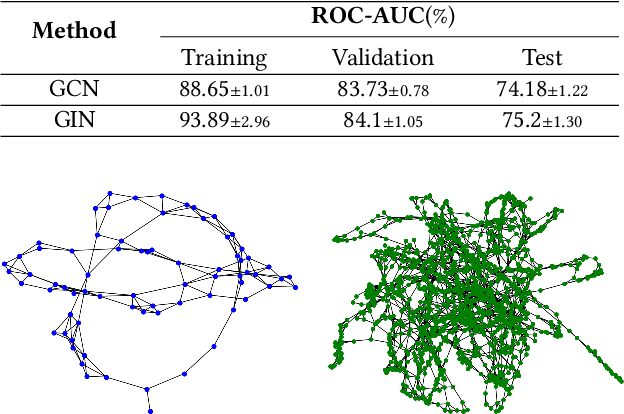
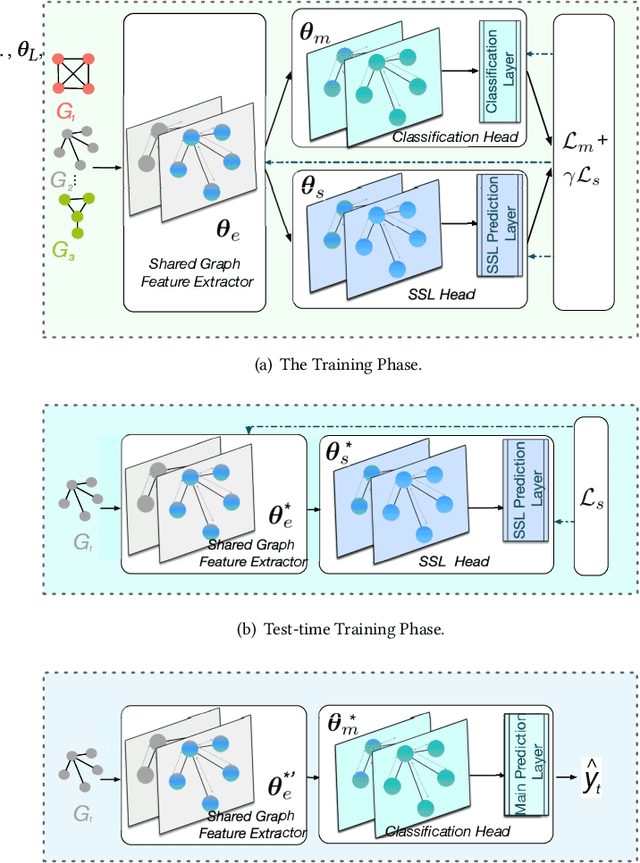
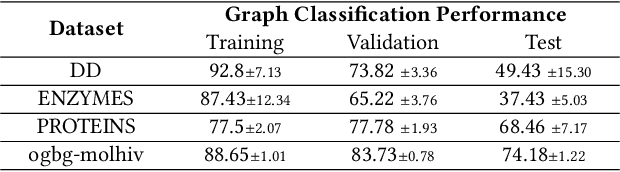
Graph Neural Networks (GNNs) have made tremendous progress in the graph classification task. However, a performance gap between the training set and the test set has often been noticed. To bridge such gap, in this work we introduce the first test-time training framework for GNNs to enhance the model generalization capacity for the graph classification task. In particular, we design a novel test-time training strategy with self-supervised learning to adjust the GNN model for each test graph sample. Experiments on the benchmark datasets have demonstrated the effectiveness of the proposed framework, especially when there are distribution shifts between training set and test set. We have also conducted exploratory studies and theoretical analysis to gain deeper understandings on the rationality of the design of the proposed graph test time training framework (GT3).
Faulty Branch Identification in Passive Optical Networks using Machine Learning
Apr 03, 2023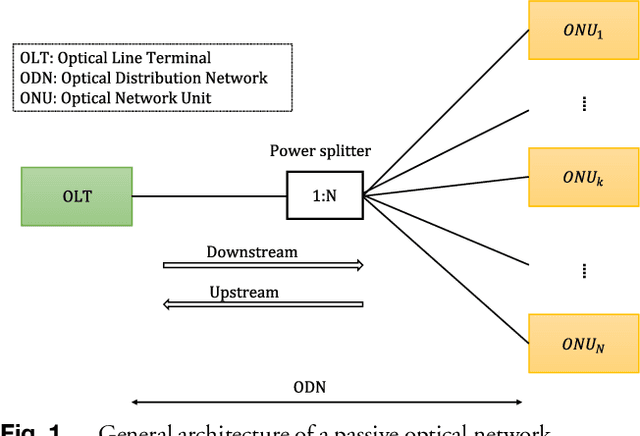

Passive optical networks (PONs) have become a promising broadband access network solution. To ensure a reliable transmission, and to meet service level agreements, PON systems have to be monitored constantly in order to quickly identify and localize networks faults. Typically, a service disruption in a PON system is mainly due to fiber cuts and optical network unit (ONU) transmitter/receiver failures. When the ONUs are located at different distances from the optical line terminal (OLT), the faulty ONU or branch can be identified by analyzing the recorded optical time domain reflectometry (OTDR) traces. However, faulty branch isolation becomes very challenging when the reflections originating from two or more branches with similar length overlap, which makes it very hard to discriminate the faulty branches given the global backscattered signal. Recently, machine learning (ML) based approaches have shown great potential for managing optical faults in PON systems. Such techniques perform well when trained and tested with data derived from the same PON system. But their performance may severely degrade, if the PON system (adopted for the generation of the training data) has changed, e.g. by adding more branches or varying the length difference between two neighboring branches. etc. A re-training of the ML models has to be conducted for each network change, which can be time consuming. In this paper, to overcome the aforementioned issues, we propose a generic ML approach trained independently of the network architecture for identifying the faulty branch in PON systems given OTDR signals for the cases of branches with close lengths. Such an approach can be applied to an arbitrary PON system without requiring to be re-trained for each change of the network. The proposed approach is validated using experimental data derived from PON system.
Discovering Dynamic Patterns from Spatiotemporal Data with Time-Varying Low-Rank Autoregression
Nov 28, 2022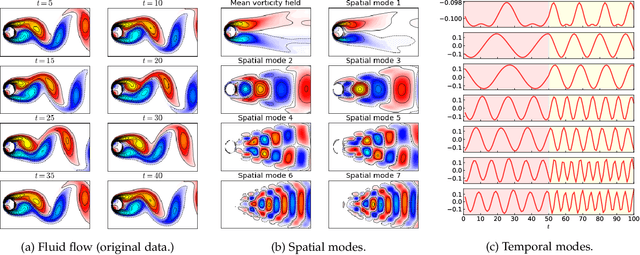
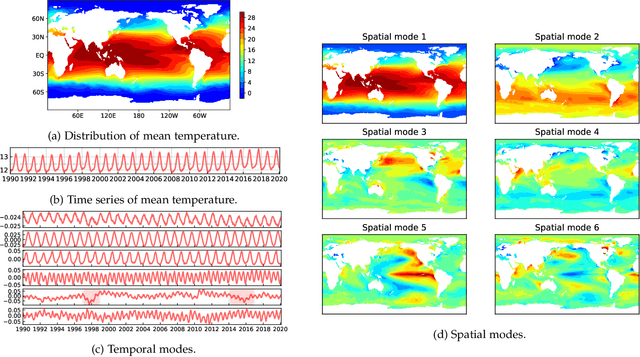
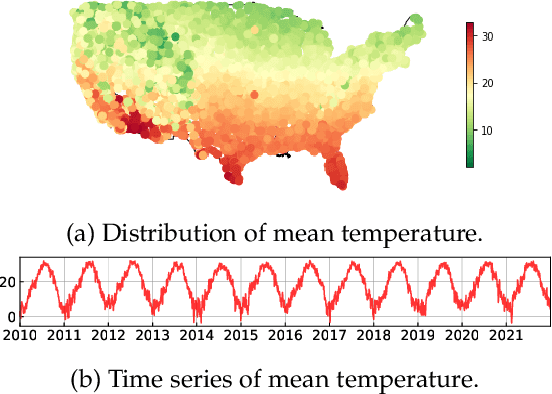
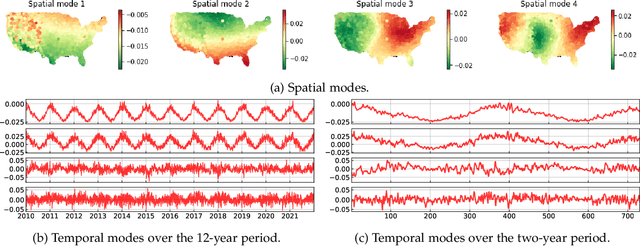
The problem of broad practical interest in spatiotemporal data analysis, i.e., discovering interpretable dynamic patterns from spatiotemporal data, is studied in this paper. Towards this end, we develop a time-varying reduced-rank vector autoregression (VAR) model whose coefficient matrices are parameterized by low-rank tensor factorization. Benefiting from the tensor factorization structure, the proposed model can simultaneously achieve model compression and pattern discovery. In particular, the proposed model allows one to characterize nonstationarity and time-varying system behaviors underlying spatiotemporal data. To evaluate the proposed model, extensive experiments are conducted on various spatiotemporal data representing different nonlinear dynamical systems, including fluid dynamics, sea surface temperature, USA surface temperature, and NYC taxi trips. Experimental results demonstrate the effectiveness of modeling spatiotemporal data and characterizing spatial/temporal patterns with the proposed model. In the spatial context, the spatial patterns can be automatically extracted and intuitively characterized by the spatial modes. In the temporal context, the complex time-varying system behaviors can be revealed by the temporal modes in the proposed model. Thus, our model lays an insightful foundation for understanding complex spatiotemporal data in real-world dynamical systems. The adapted datasets and Python implementation are publicly available at https://github.com/xinychen/vars.
An End-to-End Human Simulator for Task-Oriented Multimodal Human-Robot Collaboration
Apr 02, 2023

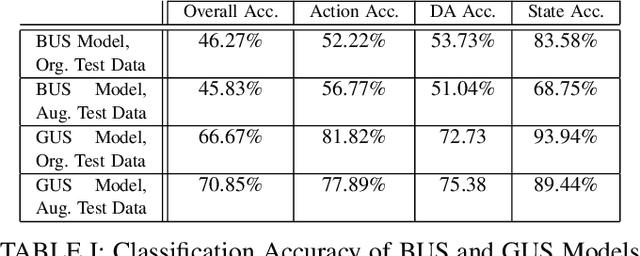
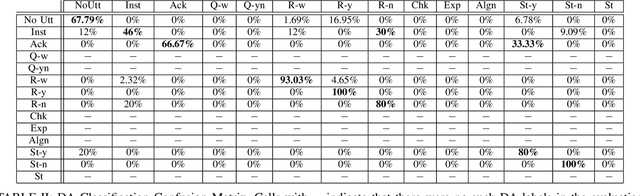
This paper proposes a neural network-based user simulator that can provide a multimodal interactive environment for training Reinforcement Learning (RL) agents in collaborative tasks involving multiple modes of communication. The simulator is trained on the existing ELDERLY-AT-HOME corpus and accommodates multiple modalities such as language, pointing gestures, and haptic-ostensive actions. The paper also presents a novel multimodal data augmentation approach, which addresses the challenge of using a limited dataset due to the expensive and time-consuming nature of collecting human demonstrations. Overall, the study highlights the potential for using RL and multimodal user simulators in developing and improving domestic assistive robots.
Zoom is what you need: An empirical study of the power of zoom and spatial biases in image classification
Apr 11, 2023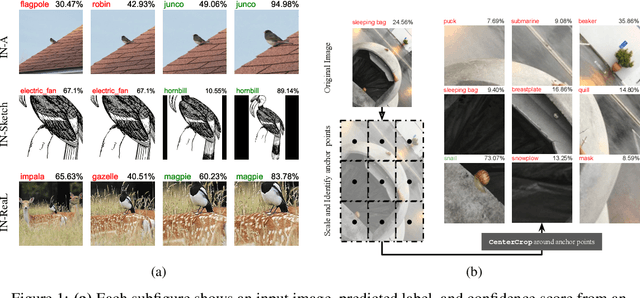



Image classifiers are information-discarding machines, by design. Yet, how these models discard information remains mysterious. We hypothesize that one way for image classifiers to reach high accuracy is to first zoom to the most discriminative region in the image and then extract features from there to predict image labels. We study six popular networks ranging from AlexNet to CLIP and find that proper framing of the input image can lead to the correct classification of 98.91% of ImageNet images. Furthermore, we explore the potential and limits of zoom transforms in image classification and uncover positional biases in various datasets, especially a strong center bias in two popular datasets: ImageNet-A and ObjectNet. Finally, leveraging our insights into the potential of zoom, we propose a state-of-the-art test-time augmentation (TTA) technique that improves classification accuracy by forcing models to explicitly perform zoom-in operations before making predictions. Our method is more interpretable, accurate, and faster than MEMO, a state-of-the-art TTA method. Additionally, we propose ImageNet-Hard, a new benchmark where zooming in alone often does not help state-of-the-art models better label images.
Improving Neural Radiance Fields with Depth-aware Optimization for Novel View Synthesis
Apr 11, 2023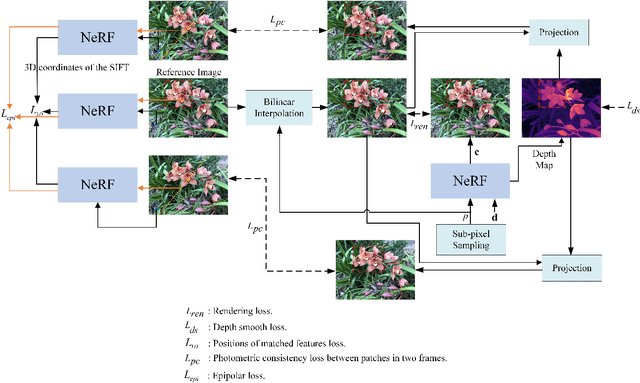

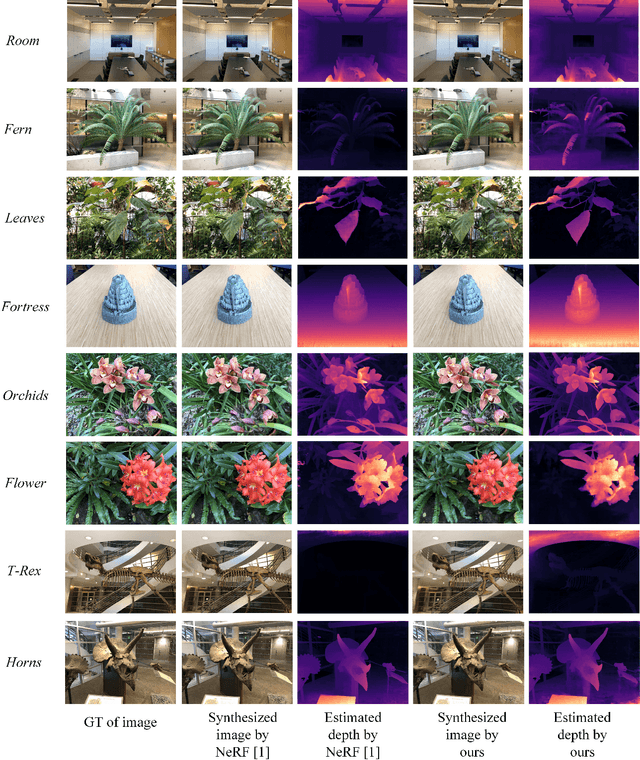

With dense inputs, Neural Radiance Fields (NeRF) is able to render photo-realistic novel views under static conditions. Although the synthesis quality is excellent, existing NeRF-based methods fail to obtain moderate three-dimensional (3D) structures. The novel view synthesis quality drops dramatically given sparse input due to the implicitly reconstructed inaccurate 3D-scene structure. We propose SfMNeRF, a method to better synthesize novel views as well as reconstruct the 3D-scene geometry. SfMNeRF leverages the knowledge from the self-supervised depth estimation methods to constrain the 3D-scene geometry during view synthesis training. Specifically, SfMNeRF employs the epipolar, photometric consistency, depth smoothness, and position-of-matches constraints to explicitly reconstruct the 3D-scene structure. Through these explicit constraints and the implicit constraint from NeRF, our method improves the view synthesis as well as the 3D-scene geometry performance of NeRF at the same time. In addition, SfMNeRF synthesizes novel sub-pixels in which the ground truth is obtained by image interpolation. This strategy enables SfMNeRF to include more samples to improve generalization performance. Experiments on two public datasets demonstrate that SfMNeRF surpasses state-of-the-art approaches. Code is available at https://github.com/XTU-PR-LAB/SfMNeRF