 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Diversified and Personalized Multi-rater Medical Image Segmentation
Mar 20, 2024
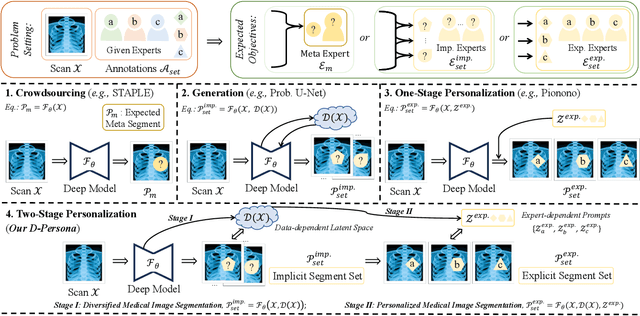
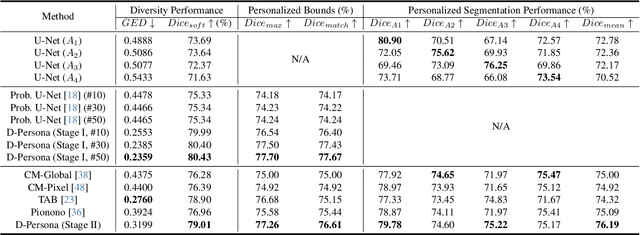
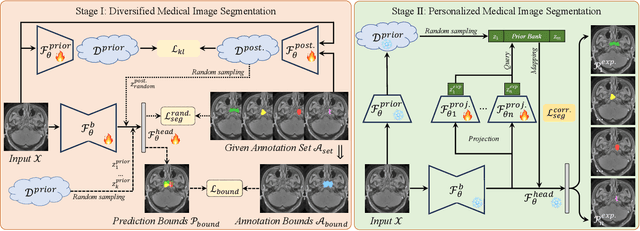
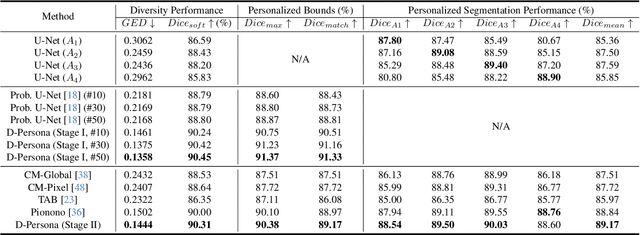
Annotation ambiguity due to inherent data uncertainties such as blurred boundaries in medical scans and different observer expertise and preferences has become a major obstacle for training deep-learning based medical image segmentation models. To address it, the common practice is to gather multiple annotations from different experts, leading to the setting of multi-rater medical image segmentation. Existing works aim to either merge different annotations into the "groundtruth" that is often unattainable in numerous medical contexts, or generate diverse results, or produce personalized results corresponding to individual expert raters. Here, we bring up a more ambitious goal for multi-rater medical image segmentation, i.e., obtaining both diversified and personalized results. Specifically, we propose a two-stage framework named D-Persona (first Diversification and then Personalization). In Stage I, we exploit multiple given annotations to train a Probabilistic U-Net model, with a bound-constrained loss to improve the prediction diversity. In this way, a common latent space is constructed in Stage I, where different latent codes denote diversified expert opinions. Then, in Stage II, we design multiple attention-based projection heads to adaptively query the corresponding expert prompts from the shared latent space, and then perform the personalized medical image segmentation. We evaluated the proposed model on our in-house Nasopharyngeal Carcinoma dataset and the public lung nodule dataset (i.e., LIDC-IDRI). Extensive experiments demonstrated our D-Persona can provide diversified and personalized results at the same time, achieving new SOTA performance for multi-rater medical image segmentation. Our code will be released at https://github.com/ycwu1997/D-Persona.
Bridging scales in multiscale bubble growth dynamics with correlated fluctuations using neural operator learning
Mar 20, 2024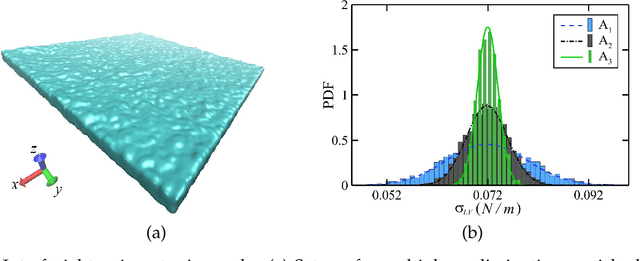
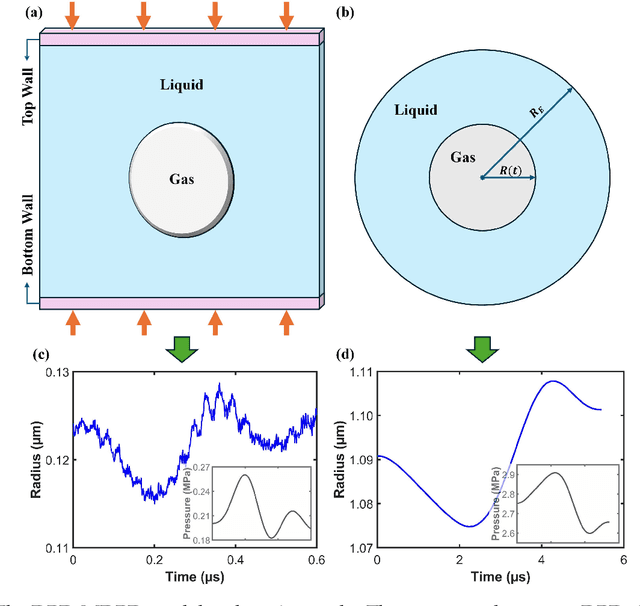
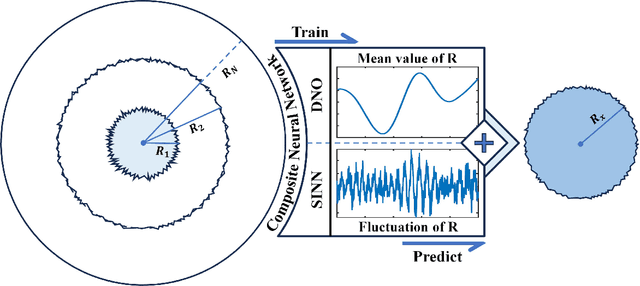
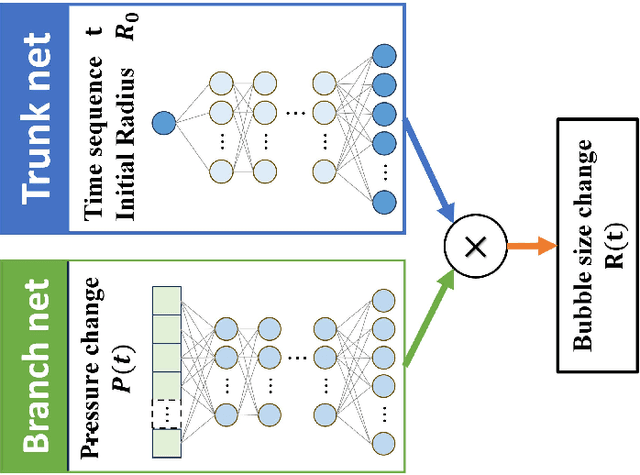
The intricate process of bubble growth dynamics involves a broad spectrum of physical phenomena from microscale mechanics of bubble formation to macroscale interplay between bubbles and surrounding thermo-hydrodynamics. Traditional bubble dynamics models including atomistic approaches and continuum-based methods segment the bubble dynamics into distinct scale-specific models. In order to bridge the gap between microscale stochastic fluid models and continuum-based fluid models for bubble dynamics, we develop a composite neural operator model to unify the analysis of nonlinear bubble dynamics across microscale and macroscale regimes by integrating a many-body dissipative particle dynamics (mDPD) model with a continuum-based Rayleigh-Plesset (RP) model through a novel neural network architecture, which consists of a deep operator network for learning the mean behavior of bubble growth subject to pressure variations and a long short-term memory network for learning the statistical features of correlated fluctuations in microscale bubble dynamics. Training and testing data are generated by conducting mDPD and RP simulations for nonlinear bubble dynamics with initial bubble radii ranging from 0.1 to 1.5 micrometers. Results show that the trained composite neural operator model can accurately predict bubble dynamics across scales, with a 99% accuracy for the time evaluation of the bubble radius under varying external pressure while containing correct size-dependent stochastic fluctuations in microscale bubble growth dynamics. The composite neural operator is the first deep learning surrogate for multiscale bubble growth dynamics that can capture correct stochastic fluctuations in microscopic fluid phenomena, which sets a new direction for future research in multiscale fluid dynamics modeling.
Waypoint-Based Reinforcement Learning for Robot Manipulation Tasks
Mar 20, 2024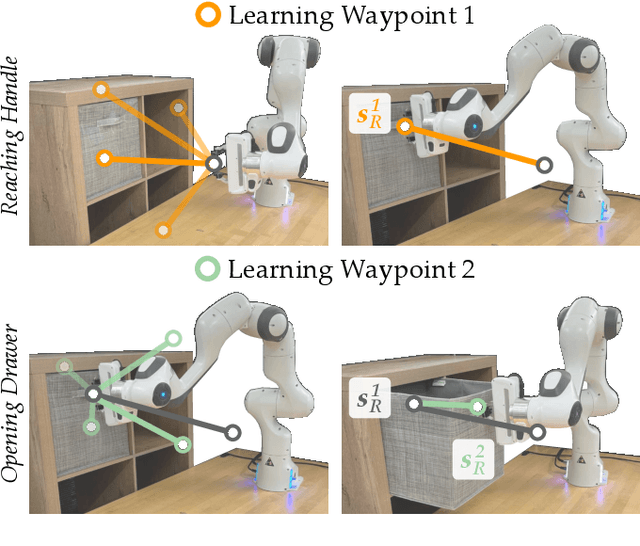
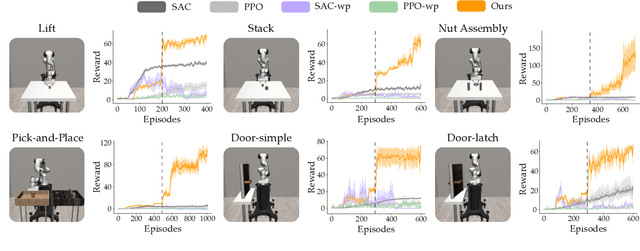
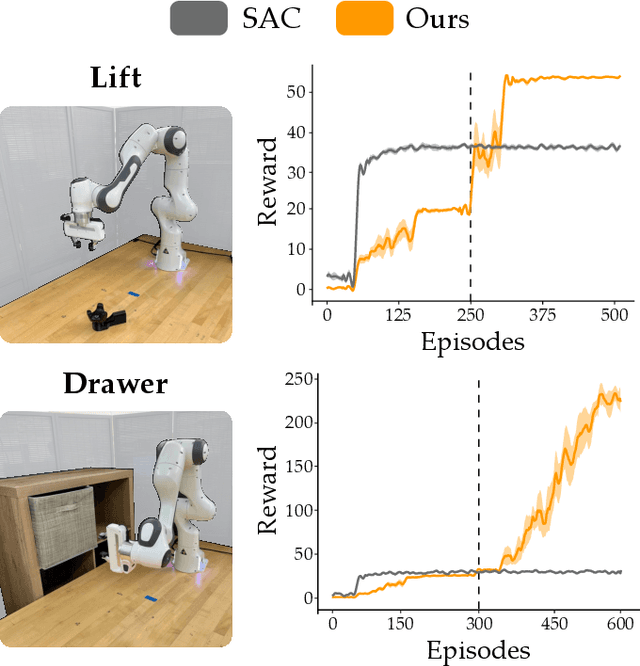
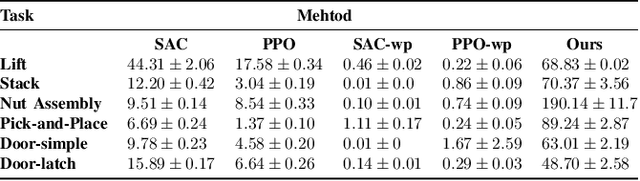
Robot arms should be able to learn new tasks. One framework here is reinforcement learning, where the robot is given a reward function that encodes the task, and the robot autonomously learns actions to maximize its reward. Existing approaches to reinforcement learning often frame this problem as a Markov decision process, and learn a policy (or a hierarchy of policies) to complete the task. These policies reason over hundreds of fine-grained actions that the robot arm needs to take: e.g., moving slightly to the right or rotating the end-effector a few degrees. But the manipulation tasks that we want robots to perform can often be broken down into a small number of high-level motions: e.g., reaching an object or turning a handle. In this paper we therefore propose a waypoint-based approach for model-free reinforcement learning. Instead of learning a low-level policy, the robot now learns a trajectory of waypoints, and then interpolates between those waypoints using existing controllers. Our key novelty is framing this waypoint-based setting as a sequence of multi-armed bandits: each bandit problem corresponds to one waypoint along the robot's motion. We theoretically show that an ideal solution to this reformulation has lower regret bounds than standard frameworks. We also introduce an approximate posterior sampling solution that builds the robot's motion one waypoint at a time. Results across benchmark simulations and two real-world experiments suggest that this proposed approach learns new tasks more quickly than state-of-the-art baselines. See videos here: https://youtu.be/MMEd-lYfq4Y
A Large Language Model Enhanced Sequential Recommender for Joint Video and Comment Recommendation
Mar 20, 2024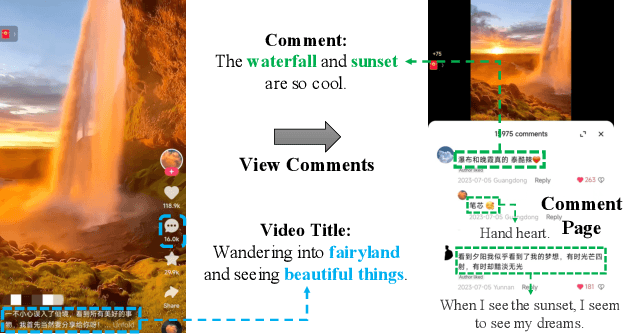

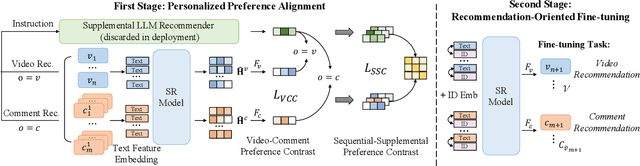
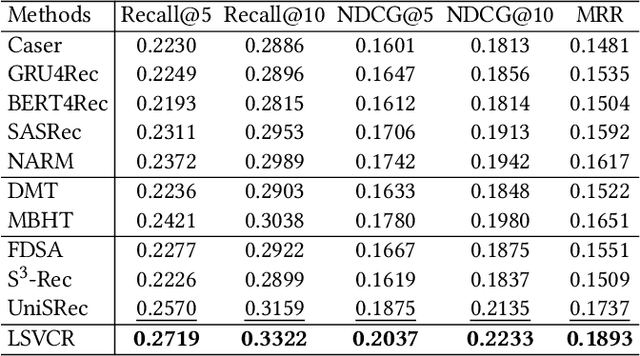
In online video platforms, reading or writing comments on interesting videos has become an essential part of the video watching experience. However, existing video recommender systems mainly model users' interaction behaviors with videos, lacking consideration of comments in user behavior modeling. In this paper, we propose a novel recommendation approach called LSVCR by leveraging user interaction histories with both videos and comments, so as to jointly conduct personalized video and comment recommendation. Specifically, our approach consists of two key components, namely sequential recommendation (SR) model and supplemental large language model (LLM) recommender. The SR model serves as the primary recommendation backbone (retained in deployment) of our approach, allowing for efficient user preference modeling. Meanwhile, we leverage the LLM recommender as a supplemental component (discarded in deployment) to better capture underlying user preferences from heterogeneous interaction behaviors. In order to integrate the merits of the SR model and the supplemental LLM recommender, we design a twostage training paradigm. The first stage is personalized preference alignment, which aims to align the preference representations from both components, thereby enhancing the semantics of the SR model. The second stage is recommendation-oriented fine-tuning, in which the alignment-enhanced SR model is fine-tuned according to specific objectives. Extensive experiments in both video and comment recommendation tasks demonstrate the effectiveness of LSVCR. Additionally, online A/B testing on the KuaiShou platform verifies the actual benefits brought by our approach. In particular, we achieve a significant overall gain of 4.13% in comment watch time.
Cloud gap-filling with deep learning for improved grassland monitoring
Mar 14, 2024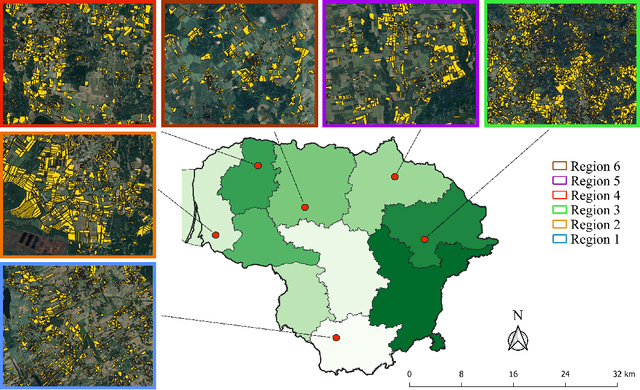
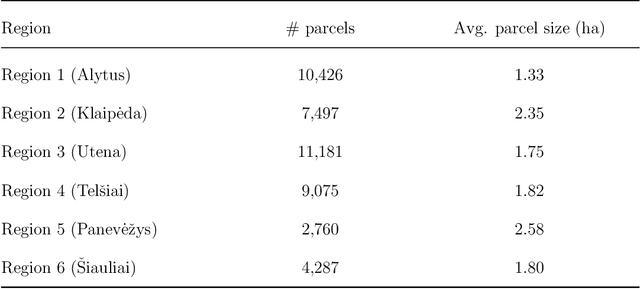

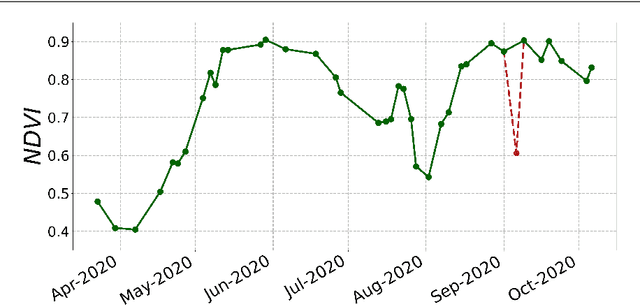
Uninterrupted optical image time series are crucial for the timely monitoring of agricultural land changes. However, the continuity of such time series is often disrupted by clouds. In response to this challenge, we propose a deep learning method that integrates cloud-free optical (Sentinel-2) observations and weather-independent (Sentinel-1) Synthetic Aperture Radar (SAR) data, using a combined Convolutional Neural Network (CNN)-Recurrent Neural Network (RNN) architecture to generate continuous Normalized Difference Vegetation Index (NDVI) time series. We emphasize the significance of observation continuity by assessing the impact of the generated time series on the detection of grassland mowing events. We focus on Lithuania, a country characterized by extensive cloud coverage, and compare our approach with alternative interpolation techniques (i.e., linear, Akima, quadratic). Our method surpasses these techniques, with an average MAE of 0.024 and R^2 of 0.92. It not only improves the accuracy of event detection tasks by employing a continuous time series, but also effectively filters out sudden shifts and noise originating from cloudy observations that cloud masks often fail to detect.
Continuous Jumping of a Parallel Wire-Driven Monopedal Robot RAMIEL Using Reinforcement Learning
Mar 17, 2024
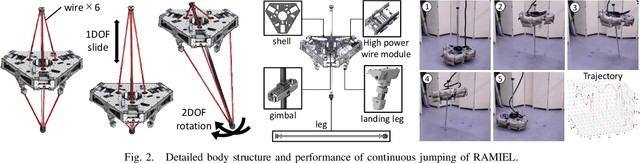
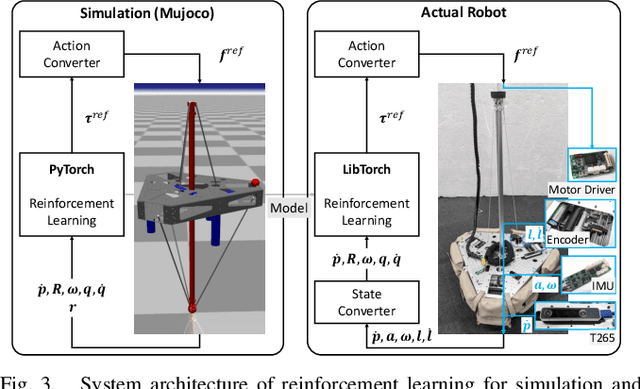
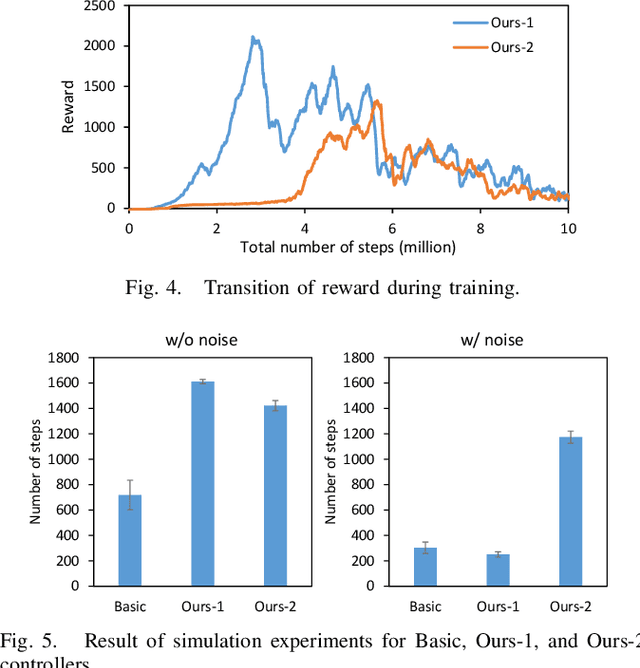
We have developed a parallel wire-driven monopedal robot, RAMIEL, which has both speed and power due to the parallel wire mechanism and a long acceleration distance. RAMIEL is capable of jumping high and continuously, and so has high performance in traveling. On the other hand, one of the drawbacks of a minimal parallel wire-driven robot without joint encoders is that the current joint velocities estimated from the wire lengths oscillate due to the elongation of the wires, making the values unreliable. Therefore, despite its high performance, the control of the robot is unstable, and in 10 out of 16 jumps, the robot could only jump up to two times continuously. In this study, we propose a method to realize a continuous jumping motion by reinforcement learning in simulation, and its application to the actual robot. Because the joint velocities oscillate with the elongation of the wires, they are not used directly, but instead are inferred from the time series of joint angles. At the same time, noise that imitates the vibration caused by the elongation of the wires is added for transfer to the actual robot. The results show that the system can be applied to the actual robot RAMIEL as well as to the stable continuous jumping motion in simulation.
Polaris: A Safety-focused LLM Constellation Architecture for Healthcare
Mar 20, 2024
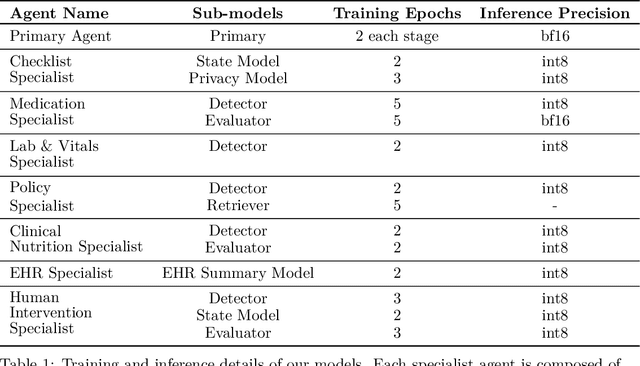
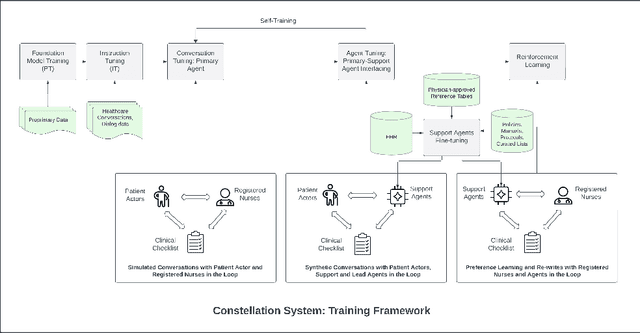
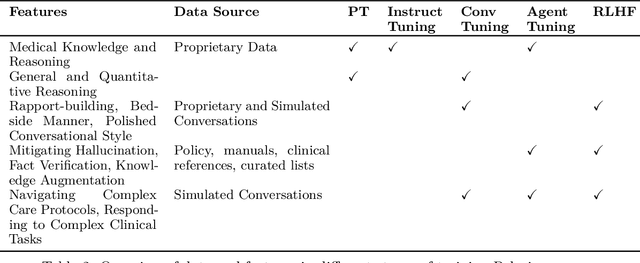
We develop Polaris, the first safety-focused LLM constellation for real-time patient-AI healthcare conversations. Unlike prior LLM works in healthcare focusing on tasks like question answering, our work specifically focuses on long multi-turn voice conversations. Our one-trillion parameter constellation system is composed of several multibillion parameter LLMs as co-operative agents: a stateful primary agent that focuses on driving an engaging conversation and several specialist support agents focused on healthcare tasks performed by nurses to increase safety and reduce hallucinations. We develop a sophisticated training protocol for iterative co-training of the agents that optimize for diverse objectives. We train our models on proprietary data, clinical care plans, healthcare regulatory documents, medical manuals, and other medical reasoning documents. We align our models to speak like medical professionals, using organic healthcare conversations and simulated ones between patient actors and experienced nurses. This allows our system to express unique capabilities such as rapport building, trust building, empathy and bedside manner. Finally, we present the first comprehensive clinician evaluation of an LLM system for healthcare. We recruited over 1100 U.S. licensed nurses and over 130 U.S. licensed physicians to perform end-to-end conversational evaluations of our system by posing as patients and rating the system on several measures. We demonstrate Polaris performs on par with human nurses on aggregate across dimensions such as medical safety, clinical readiness, conversational quality, and bedside manner. Additionally, we conduct a challenging task-based evaluation of the individual specialist support agents, where we demonstrate our LLM agents significantly outperform a much larger general-purpose LLM (GPT-4) as well as from its own medium-size class (LLaMA-2 70B).
Enhancing Law Enforcement Training: A Gamified Approach to Detecting Terrorism Financing
Mar 20, 2024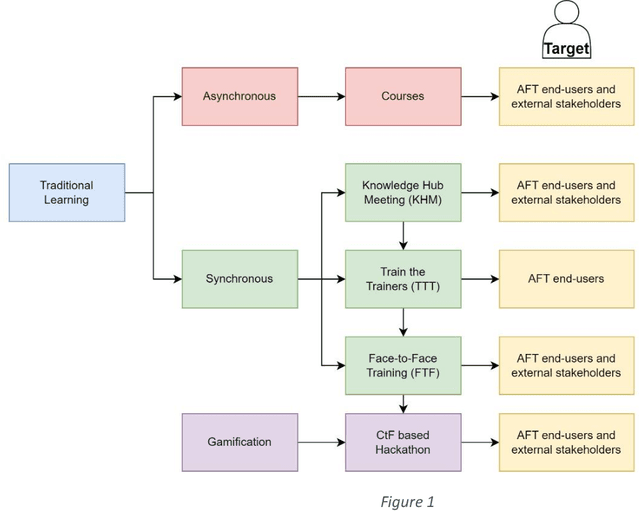
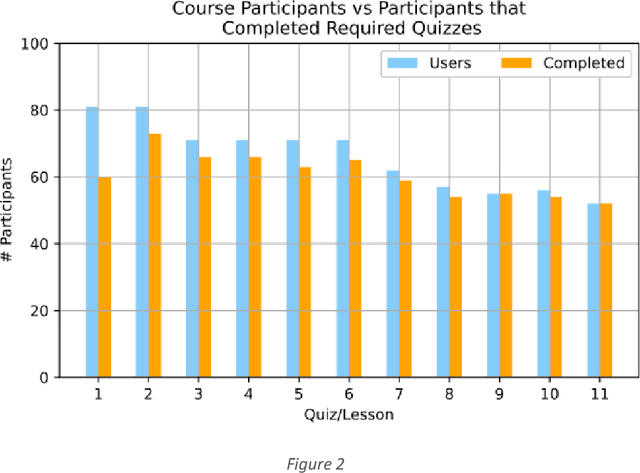
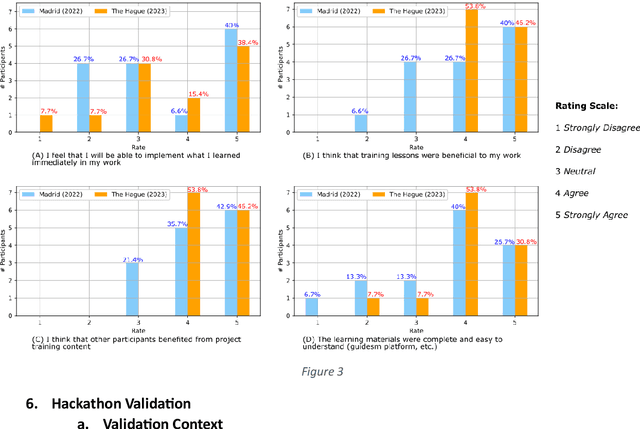
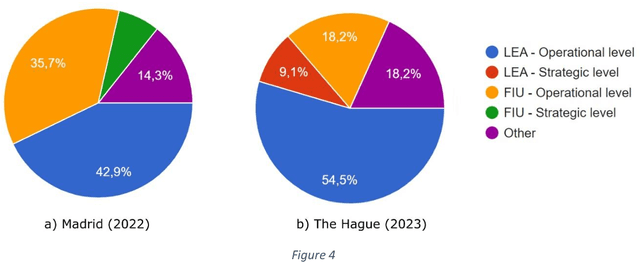
Tools for fighting cyber-criminal activities using new technologies are promoted and deployed every day. However, too often, they are unnecessarily complex and hard to use, requiring deep domain and technical knowledge. These characteristics often limit the engagement of law enforcement and end-users in these technologies that, despite their potential, remain misunderstood. For this reason, in this study, we describe our experience in combining learning and training methods and the potential benefits of gamification to enhance technology transfer and increase adult learning. In fact, in this case, participants are experienced practitioners in professions/industries that are exposed to terrorism financing (such as Law Enforcement Officers, Financial Investigation Officers, private investigators, etc.) We define training activities on different levels for increasing the exchange of information about new trends and criminal modus operandi among and within law enforcement agencies, intensifying cross-border cooperation and supporting efforts to combat and prevent terrorism funding activities. On the other hand, a game (hackathon) is designed to address realistic challenges related to the dark net, crypto assets, new payment systems and dark web marketplaces that could be used for terrorist activities. The entire methodology was evaluated using quizzes, contest results, and engagement metrics. In particular, training events show about 60% of participants complete the 11-week training course, while the Hackathon results, gathered in two pilot studies (Madrid and The Hague), show increasing expertise among the participants (progression in the achieved points on average). At the same time, more than 70% of participants positively evaluate the use of the gamification approach, and more than 85% of them consider the implemented Use Cases suitable for their investigations.
Real-time Surgical Instrument Segmentation in Video Using Point Tracking and Segment Anything
Mar 12, 2024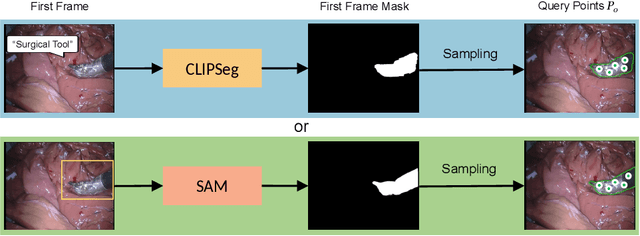
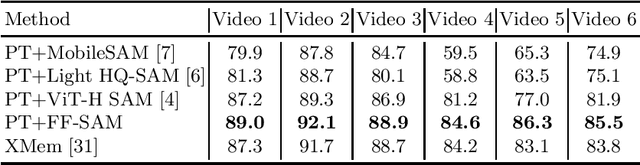
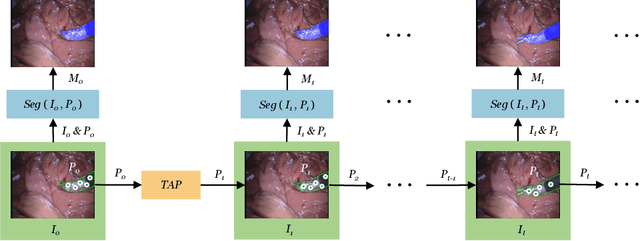
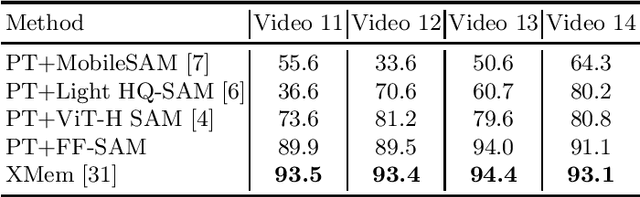
The Segment Anything Model (SAM) is a powerful vision foundation model that is revolutionizing the traditional paradigm of segmentation. Despite this, a reliance on prompting each frame and large computational cost limit its usage in robotically assisted surgery. Applications, such as augmented reality guidance, require little user intervention along with efficient inference to be usable clinically. In this study, we address these limitations by adopting lightweight SAM variants to meet the speed requirement and employing fine-tuning techniques to enhance their generalization in surgical scenes. Recent advancements in Tracking Any Point (TAP) have shown promising results in both accuracy and efficiency, particularly when points are occluded or leave the field of view. Inspired by this progress, we present a novel framework that combines an online point tracker with a lightweight SAM model that is fine-tuned for surgical instrument segmentation. Sparse points within the region of interest are tracked and used to prompt SAM throughout the video sequence, providing temporal consistency. The quantitative results surpass the state-of-the-art semi-supervised video object segmentation method on the EndoVis 2015 dataset, with an over 25 FPS inference speed running on a single GeForce RTX 4060 GPU.
Anytime Neural Architecture Search on Tabular Data
Mar 15, 2024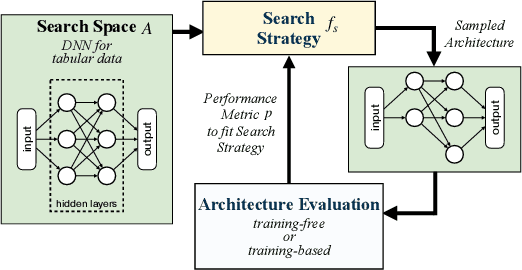


The increasing demand for tabular data analysis calls for transitioning from manual architecture design to Neural Architecture Search (NAS). This transition demands an efficient and responsive anytime NAS approach that is capable of returning current optimal architectures within any given time budget while progressively enhancing architecture quality with increased budget allocation. However, the area of research on Anytime NAS for tabular data remains unexplored. To this end, we introduce ATLAS, the first anytime NAS approach tailored for tabular data. ATLAS introduces a novel two-phase filtering-and-refinement optimization scheme with joint optimization, combining the strengths of both paradigms of training-free and training-based architecture evaluation. Specifically, in the filtering phase, ATLAS employs a new zero-cost proxy specifically designed for tabular data to efficiently estimate the performance of candidate architectures, thereby obtaining a set of promising architectures. Subsequently, in the refinement phase, ATLAS leverages a fixed-budget search algorithm to schedule the training of the promising candidates, so as to accurately identify the optimal architecture. To jointly optimize the two phases for anytime NAS, we also devise a budget-aware coordinator that delivers high NAS performance within constraints. Experimental evaluations demonstrate that our ATLAS can obtain a good-performing architecture within any predefined time budget and return better architectures as and when a new time budget is made available. Overall, it reduces the search time on tabular data by up to 82.75x compared to existing NAS approaches.