 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SmartBook: AI-Assisted Situation Report Generation
Mar 25, 2023
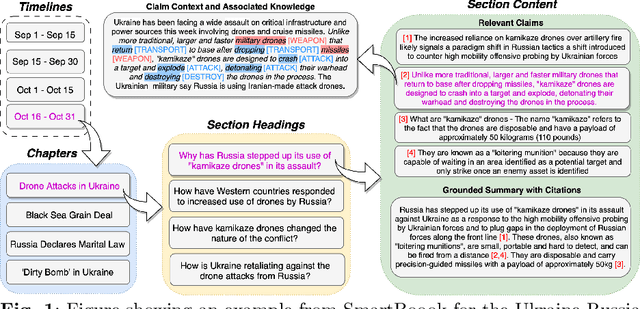
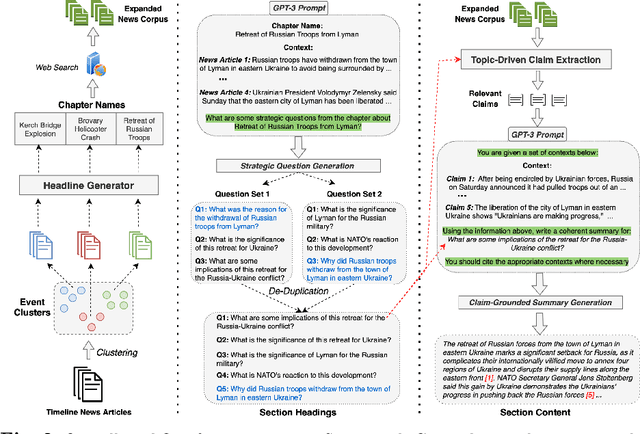


Emerging events, such as the COVID pandemic and the Ukraine Crisis, require a time-sensitive comprehensive understanding of the situation to allow for appropriate decision-making and effective action response. Automated generation of situation reports can significantly reduce the time, effort, and cost for domain experts when preparing their official human-curated reports. However, AI research toward this goal has been very limited, and no successful trials have yet been conducted to automate such report generation. We propose SmartBook, a novel task formulation targeting situation report generation, which consumes large volumes of news data to produce a structured situation report with multiple hypotheses (claims) summarized and grounded with rich links to factual evidence. We realize SmartBook for the Ukraine-Russia crisis by automatically generating intelligence analysis reports to assist expert analysts. The machine-generated reports are structured in the form of timelines, with each timeline organized by major events (or chapters), corresponding strategic questions (or sections) and their grounded summaries (or section content). Our proposed framework automatically detects real-time event-related strategic questions, which are more directed than manually-crafted analyst questions, which tend to be too complex, hard to parse, vague and high-level. Results from thorough qualitative evaluations show that roughly 82% of the questions in Smartbook have strategic importance, with at least 93% of the sections in the report being tactically useful. Further, experiments show that expert analysts tend to add more information into the SmartBook reports, with only 2.3% of the existing tokens being deleted, meaning SmartBook can serve as a useful foundation for analysts to build upon when creating intelligence reports.
Efficient human-in-loop deep learning model training with iterative refinement and statistical result validation
Apr 03, 2023

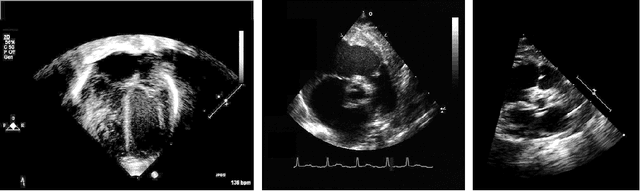
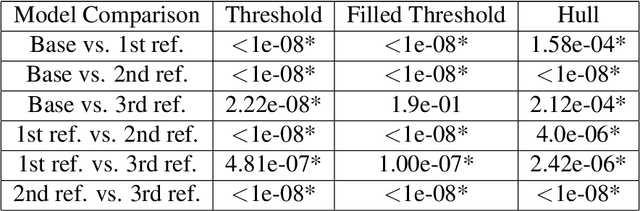
Annotation and labeling of images are some of the biggest challenges in applying deep learning to medical data. Current processes are time and cost-intensive and, therefore, a limiting factor for the wide adoption of the technology. Additionally validating that measured performance improvements are significant is important to select the best model. In this paper, we demonstrate a method for creating segmentations, a necessary part of a data cleaning for ultrasound imaging machine learning pipelines. We propose a four-step method to leverage automatically generated training data and fast human visual checks to improve model accuracy while keeping the time/effort and cost low. We also showcase running experiments multiple times to allow the usage of statistical analysis. Poor quality automated ground truth data and quick visual inspections efficiently train an initial base model, which is refined using a small set of more expensive human-generated ground truth data. The method is demonstrated on a cardiac ultrasound segmentation task, removing background data, including static PHI. Significance is shown by running the experiments multiple times and using the student's t-test on the performance distributions. The initial segmentation accuracy of a simple thresholding algorithm of 92% was improved to 98%. The performance of models trained on complicated algorithms can be matched or beaten by pre-training with the poorer performing algorithms and a small quantity of high-quality data. The introduction of statistic significance analysis for deep learning models helps to validate the performance improvements measured. The method offers a cost-effective and fast approach to achieving high-accuracy models while minimizing the cost and effort of acquiring high-quality training data.
Multi-Agent Reinforcement Learning with Action Masking for UAV-enabled Mobile Communications
Mar 29, 2023
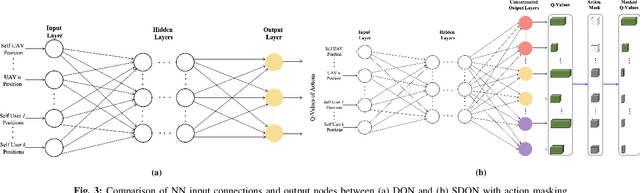
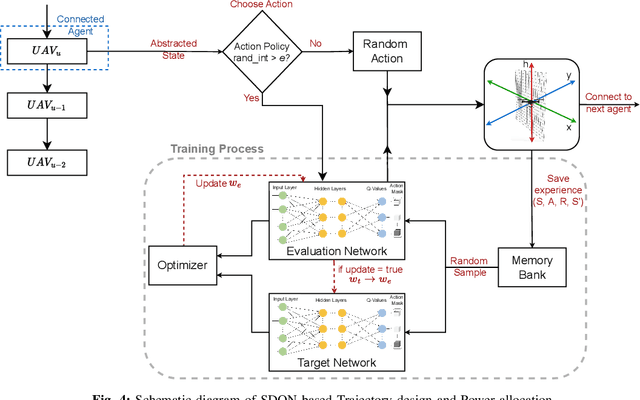
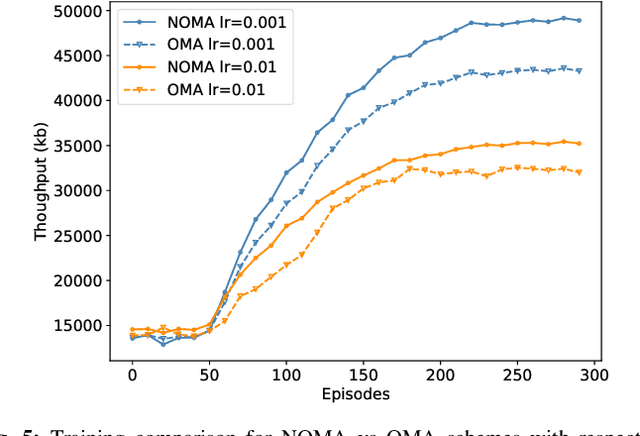
Unmanned Aerial Vehicles (UAVs) are increasingly used as aerial base stations to provide ad hoc communications infrastructure. Building upon prior research efforts which consider either static nodes, 2D trajectories or single UAV systems, this paper focuses on the use of multiple UAVs for providing wireless communication to mobile users in the absence of terrestrial communications infrastructure. In particular, we jointly optimize UAV 3D trajectory and NOMA power allocation to maximize system throughput. Firstly, a weighted K-means-based clustering algorithm establishes UAV-user associations at regular intervals. The efficacy of training a novel Shared Deep Q-Network (SDQN) with action masking is then explored. Unlike training each UAV separately using DQN, the SDQN reduces training time by using the experiences of multiple UAVs instead of a single agent. We also show that SDQN can be used to train a multi-agent system with differing action spaces. Simulation results confirm that: 1) training a shared DQN outperforms a conventional DQN in terms of maximum system throughput (+20%) and training time (-10%); 2) it can converge for agents with different action spaces, yielding a 9% increase in throughput compared to mutual learning algorithms; and 3) combining NOMA with an SDQN architecture enables the network to achieve a better sum rate compared with existing baseline schemes.
Exploring Asymmetric Tunable Blind-Spots for Self-supervised Denoising in Real-World Scenarios
Mar 29, 2023
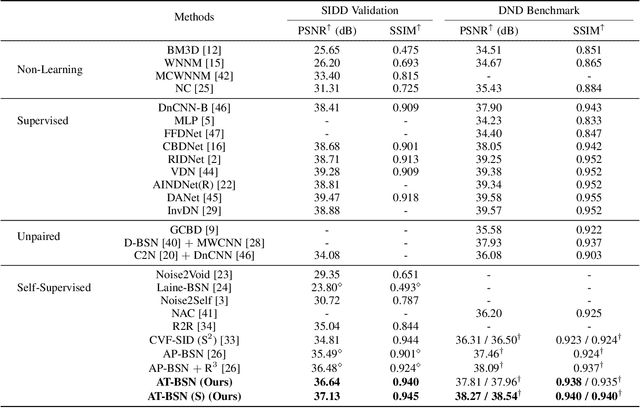
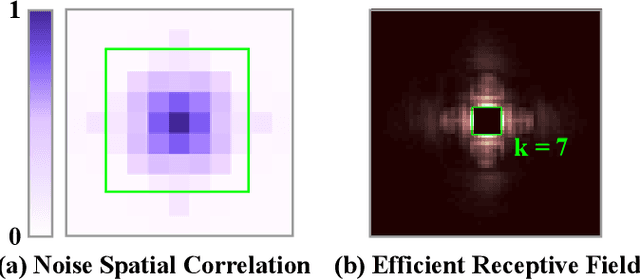
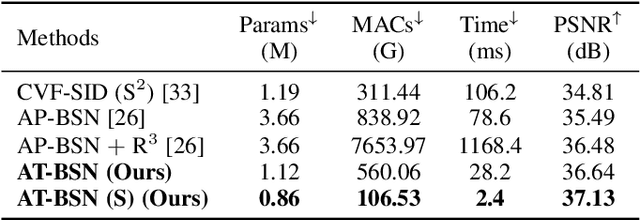
Self-supervised denoising has attracted widespread attention due to its ability to train without clean images. However, noise in real-world scenarios is often spatially correlated, which causes many self-supervised algorithms based on the pixel-wise independent noise assumption to perform poorly on real-world images. Recently, asymmetric pixel-shuffle downsampling (AP) has been proposed to disrupt the spatial correlation of noise. However, downsampling introduces aliasing effects, and the post-processing to eliminate these effects can destroy the spatial structure and high-frequency details of the image, in addition to being time-consuming. In this paper, we systematically analyze downsampling-based methods and propose an Asymmetric Tunable Blind-Spot Network (AT-BSN) to address these issues. We design a blind-spot network with a freely tunable blind-spot size, using a large blind-spot during training to suppress local spatially correlated noise while minimizing damage to the global structure, and a small blind-spot during inference to minimize information loss. Moreover, we propose blind-spot self-ensemble and distillation of non-blind-spot network to further improve performance and reduce computational complexity. Experimental results demonstrate that our method achieves state-of-the-art results while comprehensively outperforming other self-supervised methods in terms of image texture maintaining, parameter count, computation cost, and inference time.
CLVOS23: A Long Video Object Segmentation Dataset for Continual Learning
Apr 09, 2023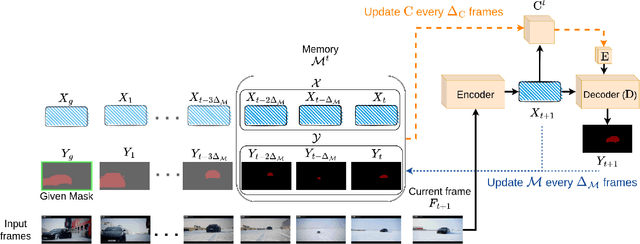
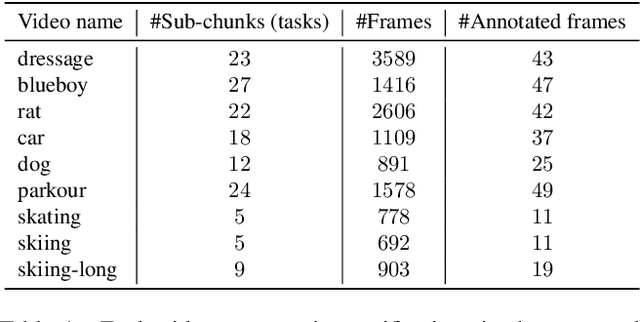


Continual learning in real-world scenarios is a major challenge. A general continual learning model should have a constant memory size and no predefined task boundaries, as is the case in semi-supervised Video Object Segmentation (VOS), where continual learning challenges particularly present themselves in working on long video sequences. In this article, we first formulate the problem of semi-supervised VOS, specifically online VOS, as a continual learning problem, and then secondly provide a public VOS dataset, CLVOS23, focusing on continual learning. Finally, we propose and implement a regularization-based continual learning approach on LWL, an existing online VOS baseline, to demonstrate the efficacy of continual learning when applied to online VOS and to establish a CLVOS23 baseline. We apply the proposed baseline to the Long Videos dataset as well as to two short video VOS datasets, DAVIS16 and DAVIS17. To the best of our knowledge, this is the first time that VOS has been defined and addressed as a continual learning problem.
H2CGL: Modeling Dynamics of Citation Network for Impact Prediction
Apr 16, 2023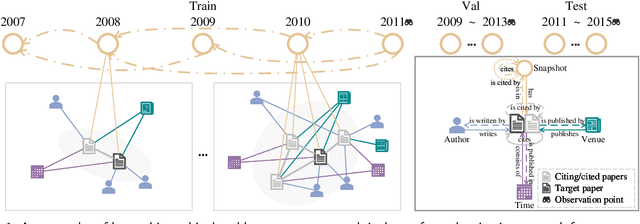
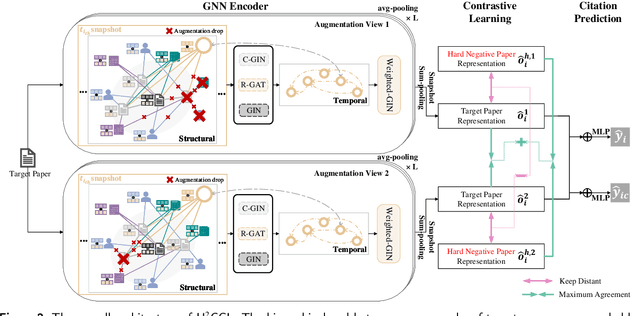

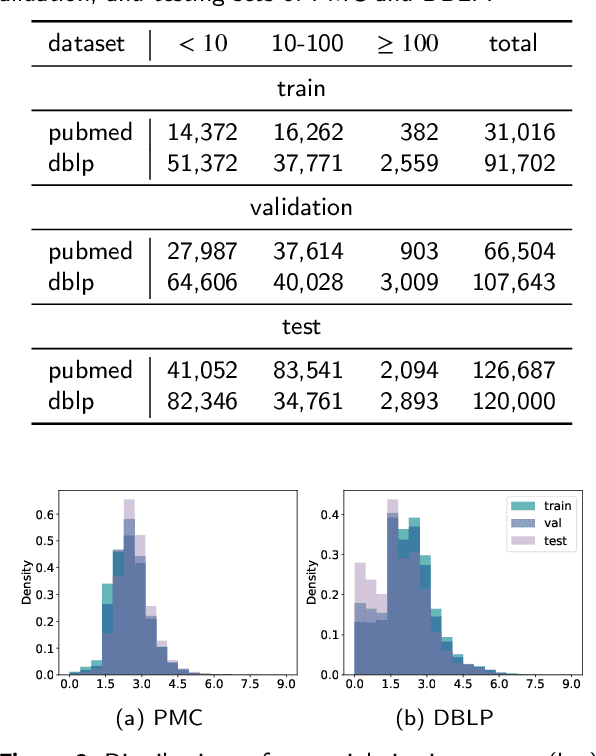
The potential impact of a paper is often quantified by how many citations it will receive. However, most commonly used models may underestimate the influence of newly published papers over time, and fail to encapsulate this dynamics of citation network into the graph. In this study, we construct hierarchical and heterogeneous graphs for target papers with an annual perspective. The constructed graphs can record the annual dynamics of target papers' scientific context information. Then, a novel graph neural network, Hierarchical and Heterogeneous Contrastive Graph Learning Model (H2CGL), is proposed to incorporate heterogeneity and dynamics of the citation network. H2CGL separately aggregates the heterogeneous information for each year and prioritizes the highly-cited papers and relationships among references, citations, and the target paper. It then employs a weighted GIN to capture dynamics between heterogeneous subgraphs over years. Moreover, it leverages contrastive learning to make the graph representations more sensitive to potential citations. Particularly, co-cited or co-citing papers of the target paper with large citation gap are taken as hard negative samples, while randomly dropping low-cited papers could generate positive samples. Extensive experimental results on two scholarly datasets demonstrate that the proposed H2CGL significantly outperforms a series of baseline approaches for both previously and freshly published papers. Additional analyses highlight the significance of the proposed modules. Our codes and settings have been released on Github (https://github.com/ECNU-Text-Computing/H2CGL)
Deep learning universal crater detection using Segment Anything Model (SAM)
Apr 16, 2023
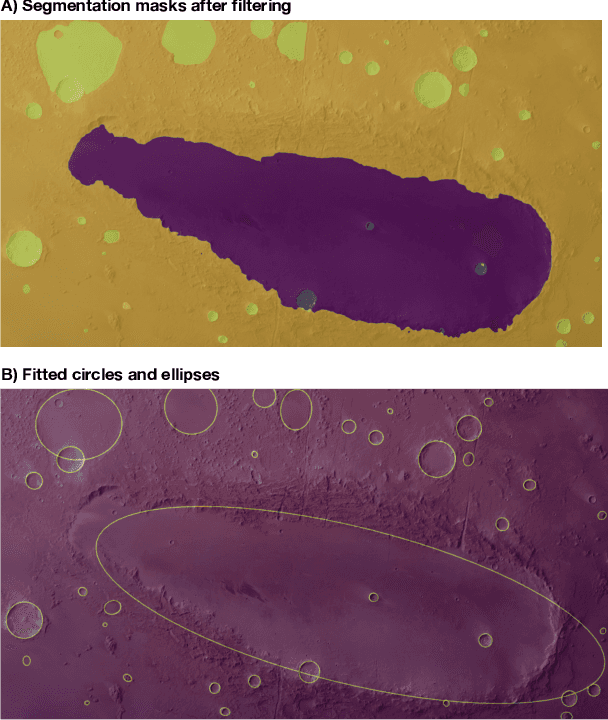


Craters are amongst the most important morphological features in planetary exploration. To that extent, detecting, mapping and counting craters is a mainstream process in planetary science, done primarily manually, which is a very laborious and time-consuming process. Recently, machine learning (ML) and computer vision have been successfully applied for both detecting craters and estimating their size. Existing ML approaches for automated crater detection have been trained in specific types of data e.g. digital elevation model (DEM), images and associated metadata for orbiters such as the Lunar Reconnaissance Orbiter Camera (LROC) etc.. Due to that, each of the resulting ML schemes is applicable and reliable only to the type of data used during the training process. Data from different sources, angles and setups can compromise the reliability of these ML schemes. In this paper we present a universal crater detection scheme that is based on the recently proposed Segment Anything Model (SAM) from META AI. SAM is a prompt-able segmentation system with zero-shot generalization to unfamiliar objects and images without the need for additional training. Using SAM we can successfully identify crater-looking objects in any type of data (e,g, raw satellite images Level-1 and 2 products, DEMs etc.) for different setups (e.g. Lunar, Mars) and different capturing angles. Moreover, using shape indexes, we only keep the segmentation masks of crater-like features. These masks are subsequently fitted with an ellipse, recovering both the location and the size/geometry of the detected craters.
Exploring the Use of ChatGPT as a Tool for Learning and Assessment in Undergraduate Computer Science Curriculum: Opportunities and Challenges
Apr 16, 2023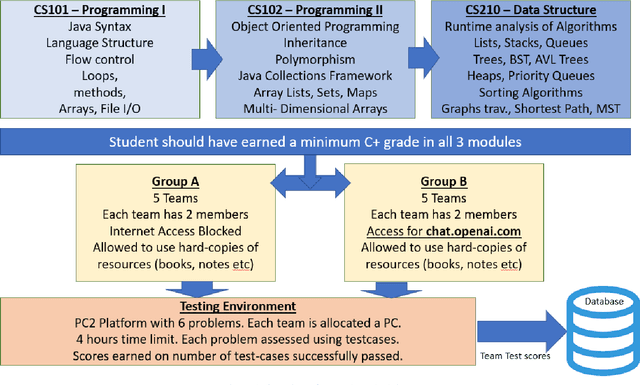
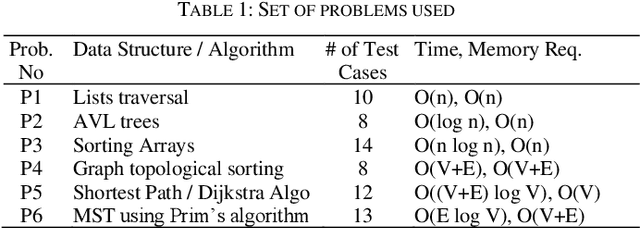
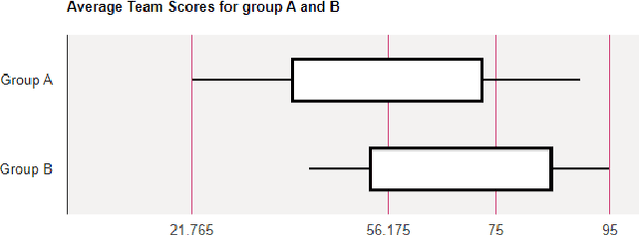
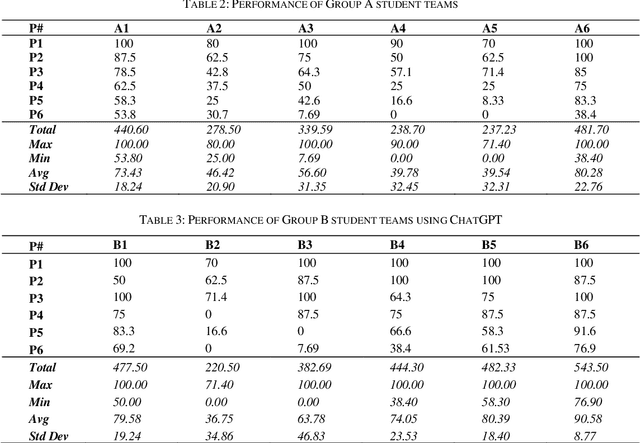
The application of Artificial intelligence for teaching and learning in the academic sphere is a trending subject of interest in the computing education. ChatGPT, as an AI-based tool, provides various advantages, such as heightened student involvement, cooperation, accessibility and availability. This paper addresses the prospects and obstacles associated with utilizing ChatGPT as a tool for learning and assessment in undergraduate Computer Science curriculum in particular to teaching and learning fundamental programming courses. Students having completed the course work for a Data Structures and Algorithms (a sophomore level course) participated in this study. Two groups of students were given programming challenges to solve within a short period of time. The control group (group A) had access to text books and notes of programming courses, however no Internet access was provided. Group B students were given access to ChatGPT and were encouraged to use it to help solve the programming challenges. The challenge was conducted in a computer lab environment using PC2 environment. Each team of students address the problem by writing executable code that satisfies certain number of test cases. Student teams were scored based on their performance in terms of number of successful passed testcases. Results show that students using ChatGPT had an advantage in terms of earned scores, however there were inconsistencies and inaccuracies in the submitted code consequently affecting the overall performance. After a thorough analysis, the paper's findings indicate that incorporating AI in higher education brings about various opportunities and challenges.
A Formal Metareasoning Model of Concurrent Planning and Execution
Mar 05, 2023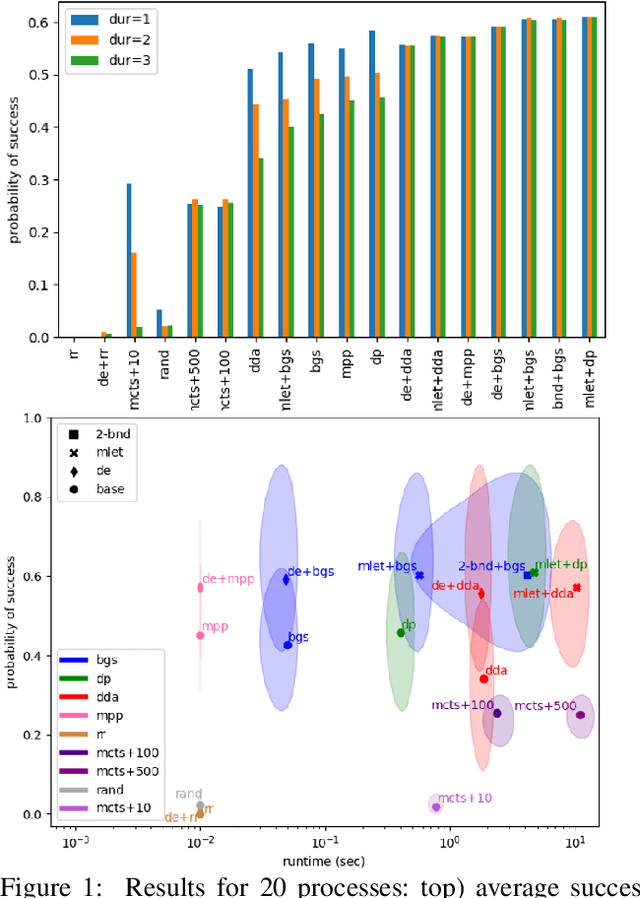
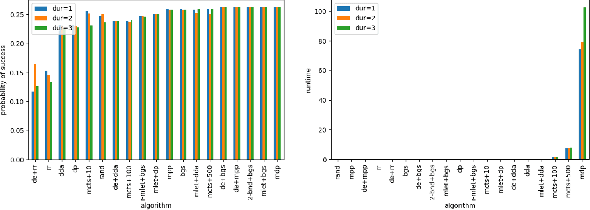
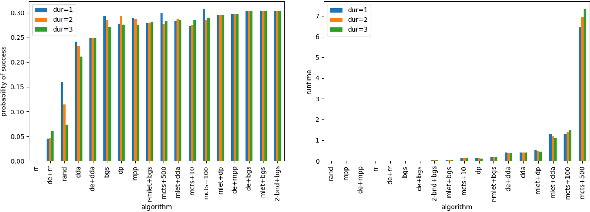
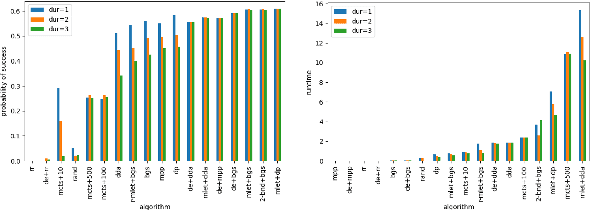
Agents that plan and act in the real world must deal with the fact that time passes as they are planning. When timing is tight, there may be insufficient time to complete the search for a plan before it is time to act. By commencing execution before search concludes, one gains time to search by making planning and execution concurrent. However, this incurs the risk of making incorrect action choices, especially if actions are irreversible. This tradeoff between opportunity and risk is the problem addressed in this paper. Our main contribution is to formally define this setting as an abstract metareasoning problem. We find that the abstract problem is intractable. However, we identify special cases that are solvable in polynomial time, develop greedy solution algorithms, and, through tests on instances derived from search problems, find several methods that achieve promising practical performance. This work lays the foundation for a principled time-aware executive that concurrently plans and executes.
Predicting dynamic, motion-related changes in B0 field in the brain at a 7 T MRI using a subject-specific fine-tuned U-net
Apr 17, 2023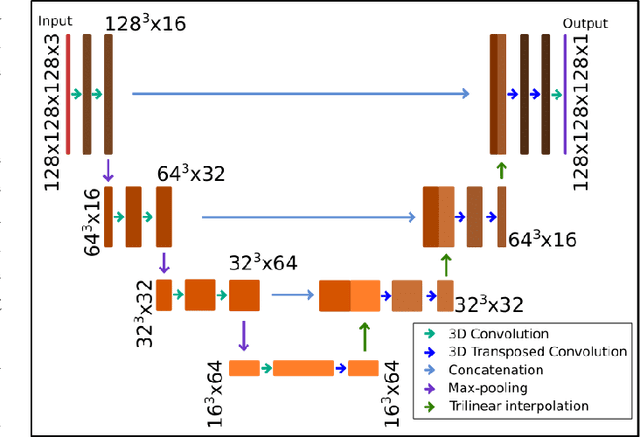
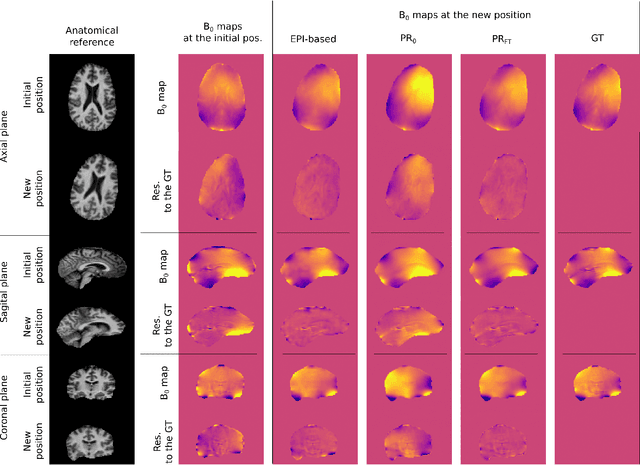
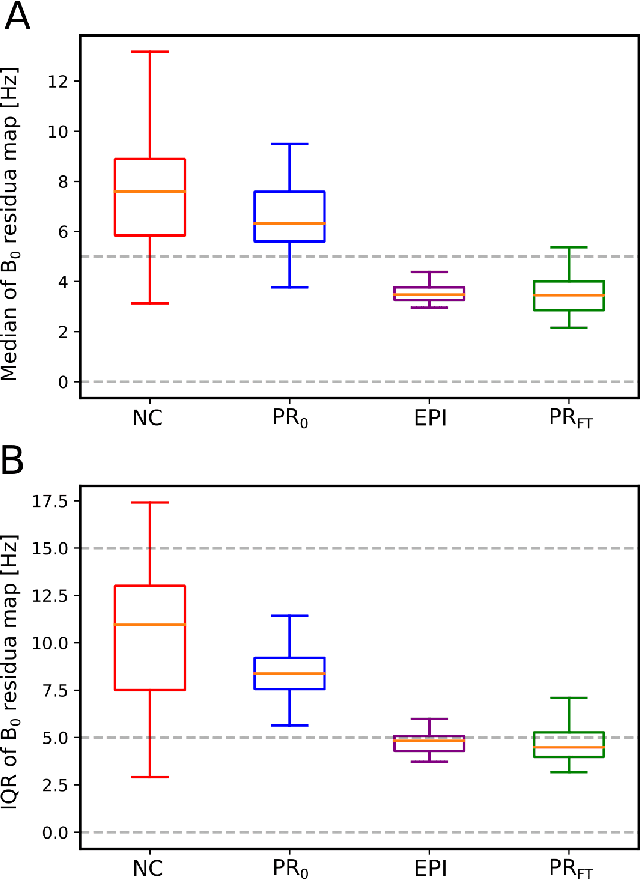
Subject movement during the magnetic resonance examination is inevitable and causes not only image artefacts but also deteriorates the homogeneity of the main magnetic field (B0), which is a prerequisite for high quality data. Thus, characterization of changes to B0, e.g. induced by patient movement, is important for MR applications that are prone to B0 inhomogeneities. We propose a deep learning based method to predict such changes within the brain from the change of the head position to facilitate retrospective or even real-time correction. A 3D U-net was trained on in vivo brain 7T MRI data. The input consisted of B0 maps and anatomical images at an initial position, and anatomical images at a different head position (obtained by applying a rigid-body transformation on the initial anatomical image). The output consisted of B0 maps at the new head positions. We further fine-tuned the network weights to each subject by measuring a limited number of head positions of the given subject, and trained the U-net with these data. Our approach was compared to established dynamic B0 field mapping via interleaved navigators, which suffer from limited spatial resolution and the need for undesirable sequence modifications. Qualitative and quantitative comparison showed similar performance between an interleaved navigator-equivalent method and proposed method. We therefore conclude that it is feasible to predict B0 maps from rigid subject movement and, when combined with external tracking hardware, this information could be used to improve the quality of magnetic resonance acquisitions without the use of navigators.