 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Test-Time Training for Graph Neural Networks
Oct 17, 2022

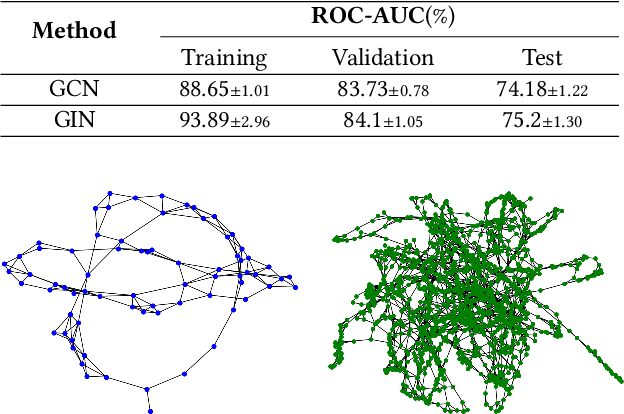
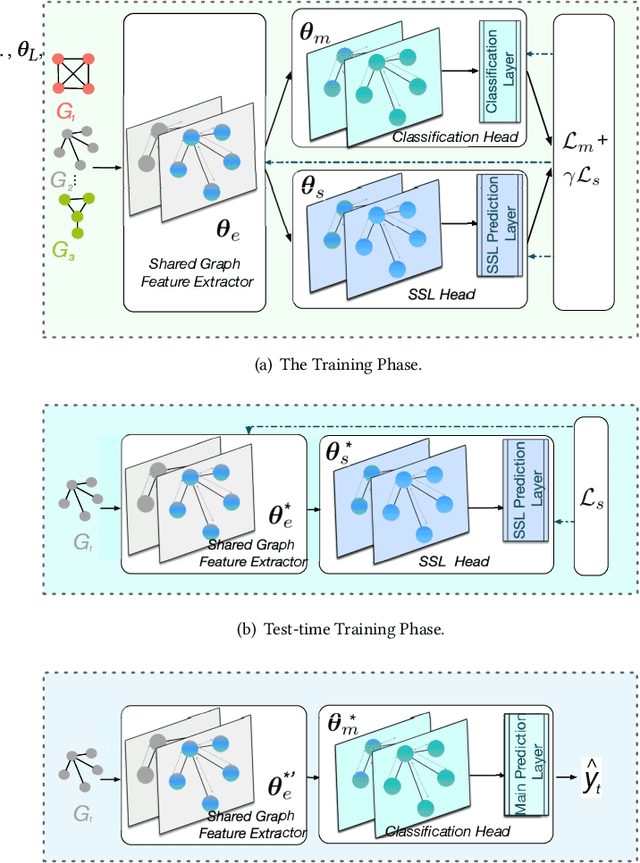
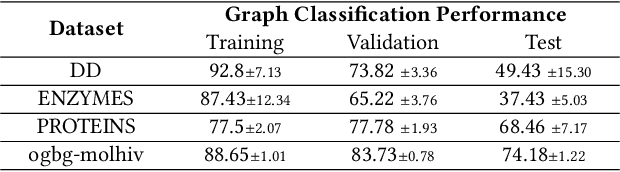
Graph Neural Networks (GNNs) have made tremendous progress in the graph classification task. However, a performance gap between the training set and the test set has often been noticed. To bridge such gap, in this work we introduce the first test-time training framework for GNNs to enhance the model generalization capacity for the graph classification task. In particular, we design a novel test-time training strategy with self-supervised learning to adjust the GNN model for each test graph sample. Experiments on the benchmark datasets have demonstrated the effectiveness of the proposed framework, especially when there are distribution shifts between training set and test set. We have also conducted exploratory studies and theoretical analysis to gain deeper understandings on the rationality of the design of the proposed graph test time training framework (GT3).
ULEEN: A Novel Architecture for Ultra Low-Energy Edge Neural Networks
Apr 20, 2023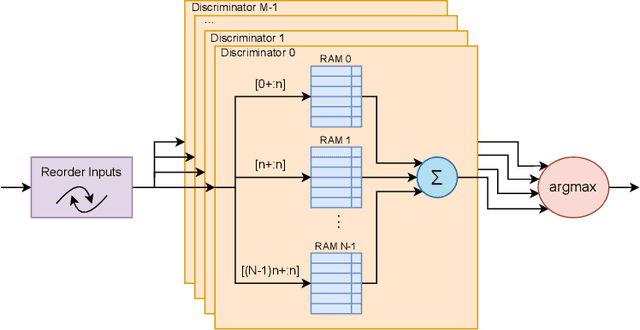
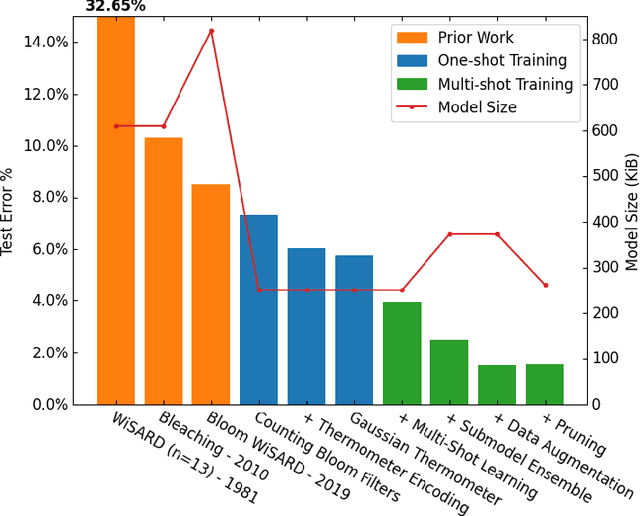
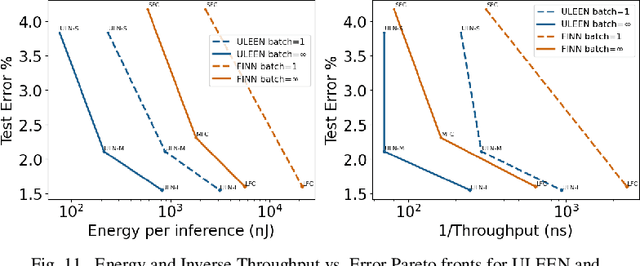
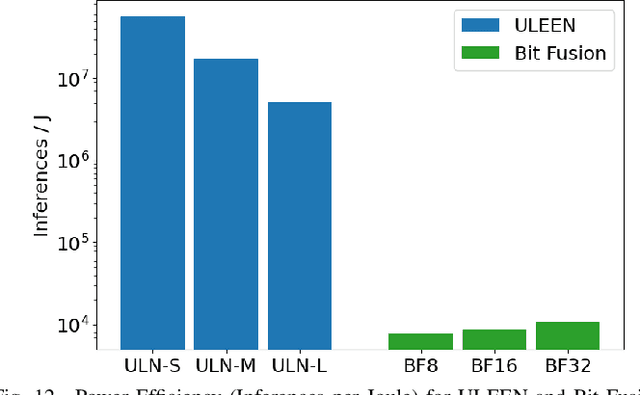
The deployment of AI models on low-power, real-time edge devices requires accelerators for which energy, latency, and area are all first-order concerns. There are many approaches to enabling deep neural networks (DNNs) in this domain, including pruning, quantization, compression, and binary neural networks (BNNs), but with the emergence of the "extreme edge", there is now a demand for even more efficient models. In order to meet the constraints of ultra-low-energy devices, we propose ULEEN, a model architecture based on weightless neural networks. Weightless neural networks (WNNs) are a class of neural model which use table lookups, not arithmetic, to perform computation. The elimination of energy-intensive arithmetic operations makes WNNs theoretically well suited for edge inference; however, they have historically suffered from poor accuracy and excessive memory usage. ULEEN incorporates algorithmic improvements and a novel training strategy inspired by BNNs to make significant strides in improving accuracy and reducing model size. We compare FPGA and ASIC implementations of an inference accelerator for ULEEN against edge-optimized DNN and BNN devices. On a Xilinx Zynq Z-7045 FPGA, we demonstrate classification on the MNIST dataset at 14.3 million inferences per second (13 million inferences/Joule) with 0.21 $\mu$s latency and 96.2% accuracy, while Xilinx FINN achieves 12.3 million inferences per second (1.69 million inferences/Joule) with 0.31 $\mu$s latency and 95.83% accuracy. In a 45nm ASIC, we achieve 5.1 million inferences/Joule and 38.5 million inferences/second at 98.46% accuracy, while a quantized Bit Fusion model achieves 9230 inferences/Joule and 19,100 inferences/second at 99.35% accuracy. In our search for ever more efficient edge devices, ULEEN shows that WNNs are deserving of consideration.
Mixing Backward- with Forward-Chaining for Metacognitive Skill Acquisition and Transfer
Mar 18, 2023Metacognitive skills have been commonly associated with preparation for future learning in deductive domains. Many researchers have regarded strategy- and time-awareness as two metacognitive skills that address how and when to use a problem-solving strategy, respectively. It was shown that students who are both strategy-and time-aware (StrTime) outperformed their nonStrTime peers across deductive domains. In this work, students were trained on a logic tutor that supports a default forward-chaining (FC) and a backward-chaining (BC) strategy. We investigated the impact of mixing BC with FC on teaching strategy- and time-awareness for nonStrTime students. During the logic instruction, the experimental students (Exp) were provided with two BC worked examples and some problems in BC to practice how and when to use BC. Meanwhile, their control (Ctrl) and StrTime peers received no such intervention. Six weeks later, all students went through a probability tutor that only supports BC to evaluate whether the acquired metacognitive skills are transferred from logic. Our results show that on both tutors, Exp outperformed Ctrl and caught up with StrTime.
Multiple Hankel matrix rank minimization for audio inpainting
Mar 31, 2023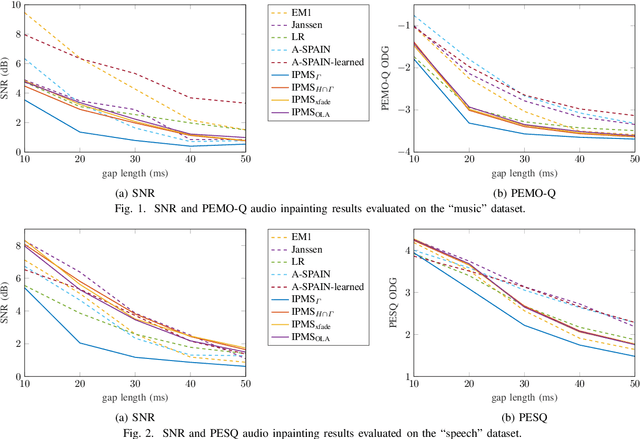

Sasaki et al. (2018) presented an efficient audio declipping algorithm, based on the properties of Hankel-structured matrices constructed from time-domain signal blocks. We adapt their approach to solve the audio inpainting problem, where samples are missing in the signal. We analyze the algorithm and provide modifications, some of them leading to an improved performance. Overall, it turns out that the new algorithms perform reasonably well for speech signals but they are not competitive in the case of music signals.
Unsupervised Anomaly Detection in Time-series: An Extensive Evaluation and Analysis of State-of-the-art Methods
Dec 06, 2022
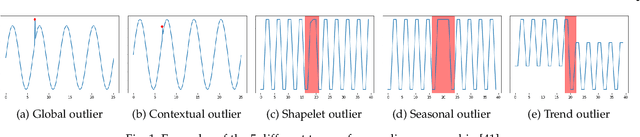
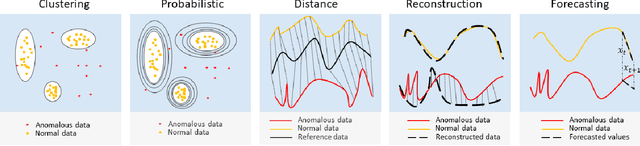
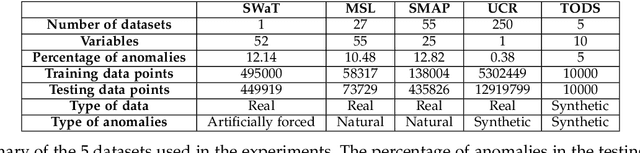
Unsupervised anomaly detection in time-series has been extensively investigated in the literature. Notwithstanding the relevance of this topic in numerous application fields, a complete and extensive evaluation of recent state-of-the-art techniques is still missing. Few efforts have been made to compare existing unsupervised time-series anomaly detection methods rigorously. However, only standard performance metrics, namely precision, recall, and F1-score are usually considered. Essential aspects for assessing their practical relevance are therefore neglected. This paper proposes an original and in-depth evaluation study of recent unsupervised anomaly detection techniques in time-series. Instead of relying solely on standard performance metrics, additional yet informative metrics and protocols are taken into account. In particular, (1) more elaborate performance metrics specifically tailored for time-series are used; (2) the model size and the model stability are studied; (3) an analysis of the tested approaches with respect to the anomaly type is provided; and (4) a clear and unique protocol is followed for all experiments. Overall, this extensive analysis aims to assess the maturity of state-of-the-art time-series anomaly detection, give insights regarding their applicability under real-world setups and provide to the community a more complete evaluation protocol.
Learning unidirectional coupling using echo-state network
Mar 23, 2023Reservoir Computing has found many potential applications in the field of complex dynamics. In this article, we exploit the exceptional capability of the echo-state network (ESN) model to make it learn a unidirectional coupling scheme from only a few time series data of the system. We show that, once trained with a few example dynamics of a drive-response system, the machine is able to predict the response system's dynamics for any driver signal with the same coupling. Only a few time series data of an $A-B$ type drive-response system in training is sufficient for the ESN to learn the coupling scheme. After training even if we replace drive system $A$ with a different system $C$, the ESN can reproduce the dynamics of response system $B$ using the dynamics of new drive system $C$ only.
A Formal Metareasoning Model of Concurrent Planning and Execution
Mar 05, 2023
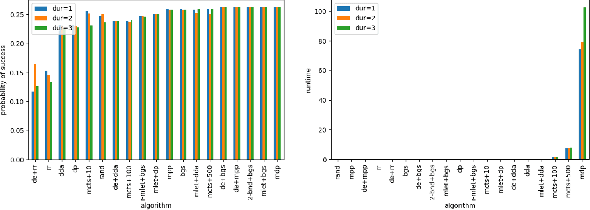
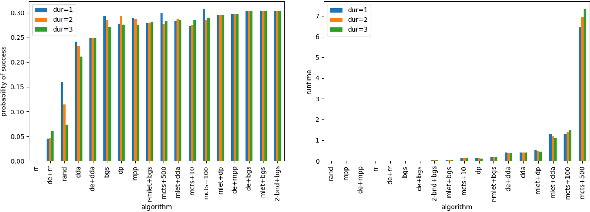
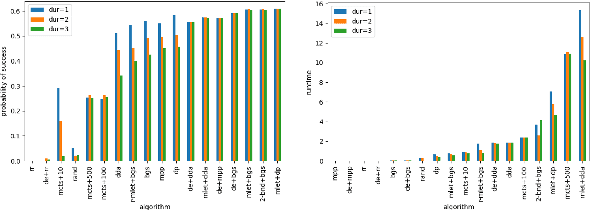
Agents that plan and act in the real world must deal with the fact that time passes as they are planning. When timing is tight, there may be insufficient time to complete the search for a plan before it is time to act. By commencing execution before search concludes, one gains time to search by making planning and execution concurrent. However, this incurs the risk of making incorrect action choices, especially if actions are irreversible. This tradeoff between opportunity and risk is the problem addressed in this paper. Our main contribution is to formally define this setting as an abstract metareasoning problem. We find that the abstract problem is intractable. However, we identify special cases that are solvable in polynomial time, develop greedy solution algorithms, and, through tests on instances derived from search problems, find several methods that achieve promising practical performance. This work lays the foundation for a principled time-aware executive that concurrently plans and executes.
Contingency Games for Multi-Agent Interaction
Apr 14, 2023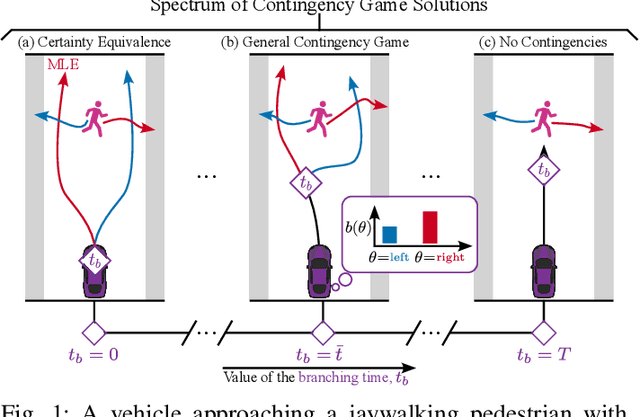
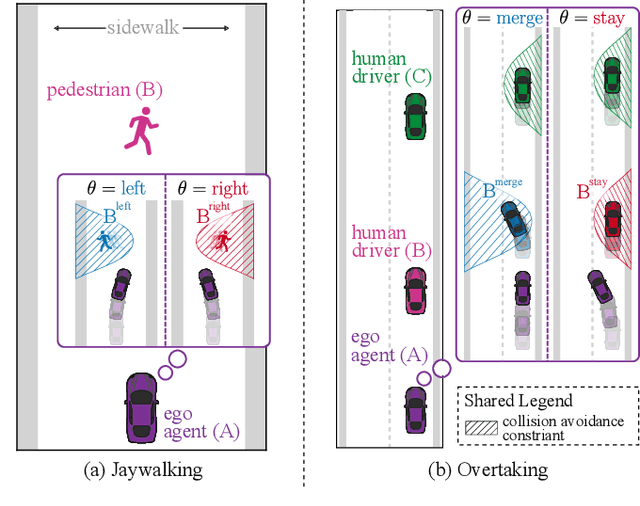
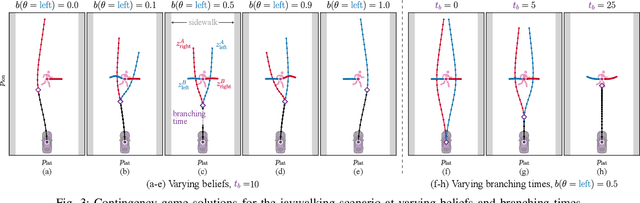
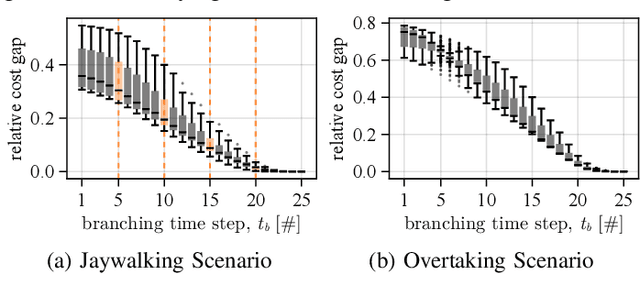
Contingency planning, wherein an agent generates a set of possible plans conditioned on the outcome of an uncertain event, is an increasingly popular way for robots to act under uncertainty. In this work, we take a game-theoretic perspective on contingency planning which is tailored to multi-agent scenarios in which a robot's actions impact the decisions of other agents and vice versa. The resulting contingency game allows the robot to efficiently coordinate with other agents by generating strategic motion plans conditioned on multiple possible intents for other actors in the scene. Contingency games are parameterized via a scalar variable which represents a future time at which intent uncertainty will be resolved. Varying this parameter enables a designer to easily adjust how conservatively the robot behaves in the game. Interestingly, we also find that existing variants of game-theoretic planning under uncertainty are readily obtained as special cases of contingency games. Lastly, we offer an efficient method for solving N-player contingency games with nonlinear dynamics and non-convex costs and constraints. Through a series of simulated autonomous driving scenarios, we demonstrate that plans generated via contingency games provide quantitative performance gains over game-theoretic motion plans that do not account for future uncertainty reduction.
Grouping Shapley Value Feature Importances of Random Forests for explainable Yield Prediction
Apr 14, 2023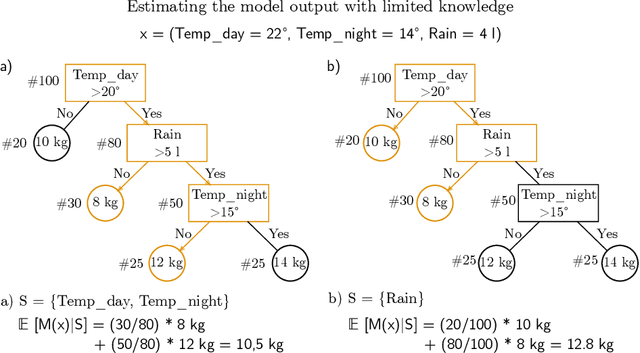
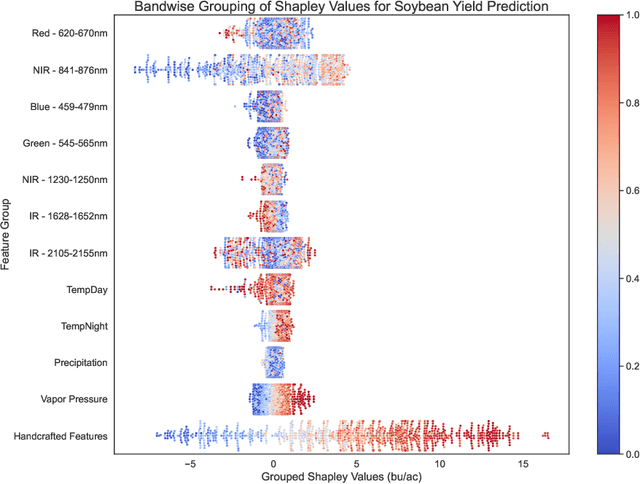
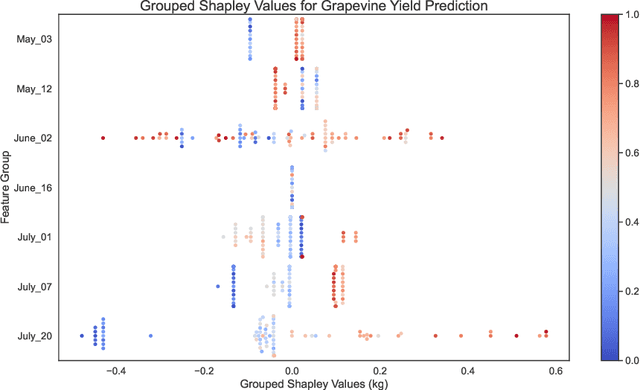
Explainability in yield prediction helps us fully explore the potential of machine learning models that are already able to achieve high accuracy for a variety of yield prediction scenarios. The data included for the prediction of yields are intricate and the models are often difficult to understand. However, understanding the models can be simplified by using natural groupings of the input features. Grouping can be achieved, for example, by the time the features are captured or by the sensor used to do so. The state-of-the-art for interpreting machine learning models is currently defined by the game-theoretic approach of Shapley values. To handle groups of features, the calculated Shapley values are typically added together, ignoring the theoretical limitations of this approach. We explain the concept of Shapley values directly computed for predefined groups of features and introduce an algorithm to compute them efficiently on tree structures. We provide a blueprint for designing swarm plots that combine many local explanations for global understanding. Extensive evaluation of two different yield prediction problems shows the worth of our approach and demonstrates how we can enable a better understanding of yield prediction models in the future, ultimately leading to mutual enrichment of research and application.
Collaborative Ground-Aerial Multi-Robot System for Disaster Response Missions with a Low-Cost Drone Add-On for Off-the-Shelf Drones
Apr 14, 2023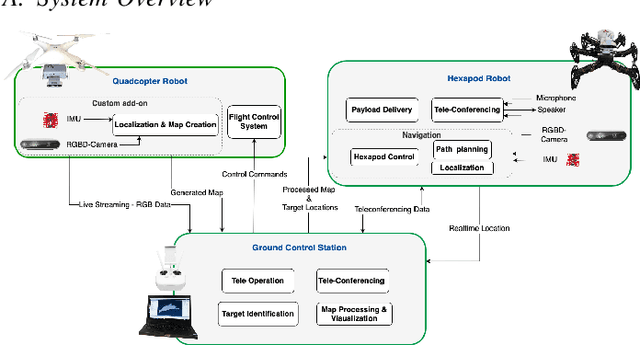


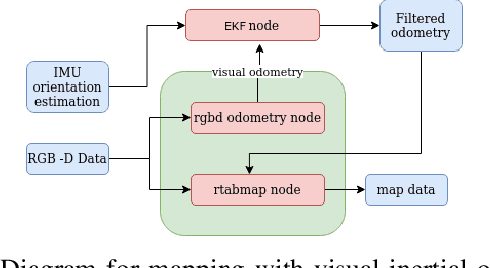
In disaster-stricken environments, it's vital to assess the damage quickly, analyse the stability of the environment, and allocate resources to the most vulnerable areas where victims might be present. These missions are difficult and dangerous to be conducted directly by humans. Using the complementary capabilities of both the ground and aerial robots, we investigate a collaborative approach of aerial and ground robots to address this problem. With an increased field of view, faster speed, and compact size, the aerial robot explores the area and creates a 3D feature-based map graph of the environment while providing a live video stream to the ground control station. Once the aerial robot finishes the exploration run, the ground control station processes the map and sends it to the ground robot. The ground robot, with its higher operation time, static stability, payload delivery and tele-conference capabilities, can then autonomously navigate to identified high-vulnerability locations. We have conducted experiments using a quadcopter and a hexapod robot in an indoor modelled environment with obstacles and uneven ground. Additionally, we have developed a low-cost drone add-on with value-added capabilities, such as victim detection, that can be attached to an off-the-shelf drone. The system was assessed for cost-effectiveness, energy efficiency, and scalability.