 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Smart Metro: Deep Learning Approaches to Forecasting the MRT Line 3 Ridership
Apr 14, 2023
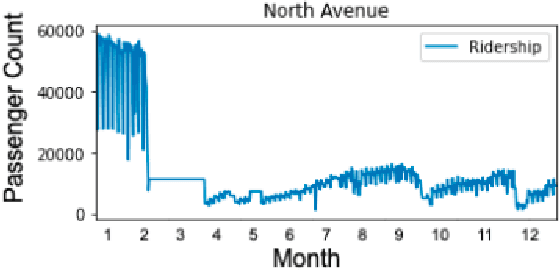
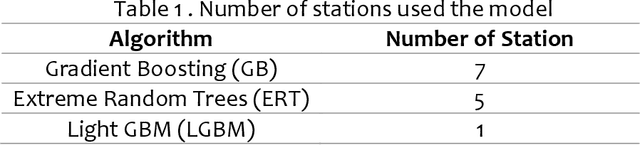
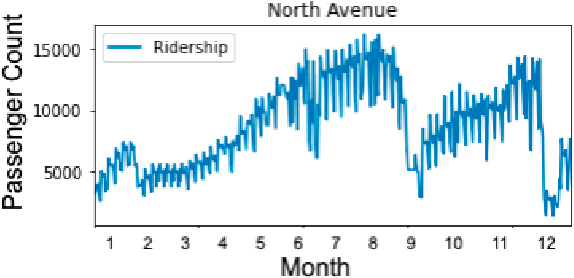
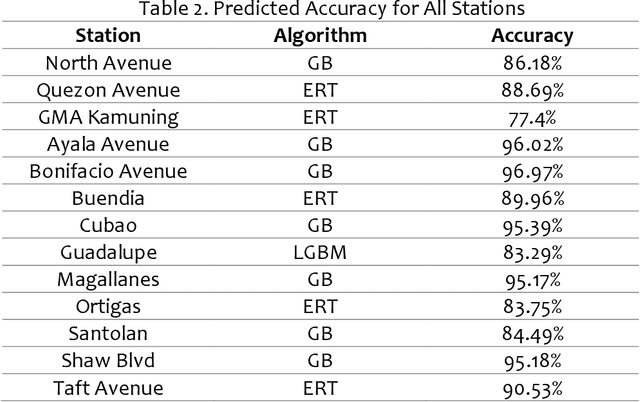
Since its establishment in 1999, the Metro Rail Transit Line 3 (MRT3) has served as a transportation option for numerous passengers in Metro Manila, Philippines. The Philippine government's transportation department records more than a thousand people using the MRT3 daily and forecasting the daily passenger count may be rather challenging. The MRT3's daily ridership fluctuates owing to variables such as holidays, working days, and other unexpected issues. Commuters do not know how many other commuters are on their route on a given day, which may hinder their ability to plan an efficient itinerary. Currently, the DOTr depends on spreadsheets containing historical data, which might be challenging to examine. This study presents a time series prediction of daily traffic to anticipate future attendance at a particular station on specific days.
Stochastic Code Generation
Apr 14, 2023



Large language models pre-trained for code generation can generate high-quality short code but often struggle with generating coherent long code and understanding higher-level or system-level specifications. This issue is also observed in language modeling for long text generation, and one proposed solution is the use of a latent stochastic process. This approach involves generating a document plan and then producing text that is consistent with it. In this study, we investigate whether this technique can be applied to code generation to improve coherence. We base our proposed encoder and decoder on the pre-trained GPT-2 based CodeParrot model and utilize the APPS dataset for training. We evaluate our results using the HumanEval benchmark and observe that the modified Time Control model performs similarly to CodeParrot on this evaluation.
Near Field iToF LIDAR Depth Improvement from Limited Number of Shots
Apr 14, 2023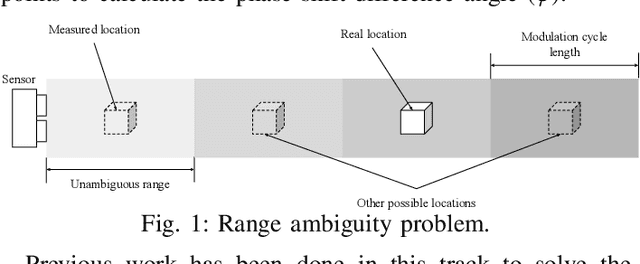
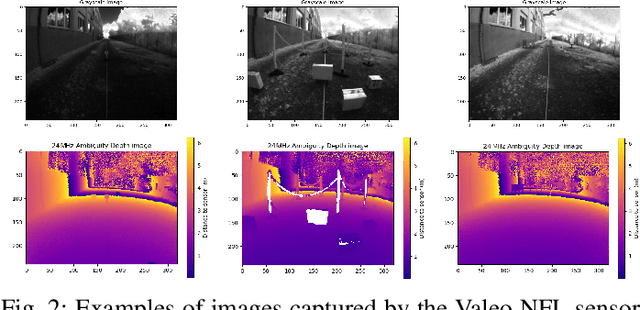
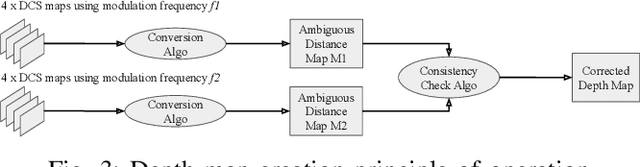
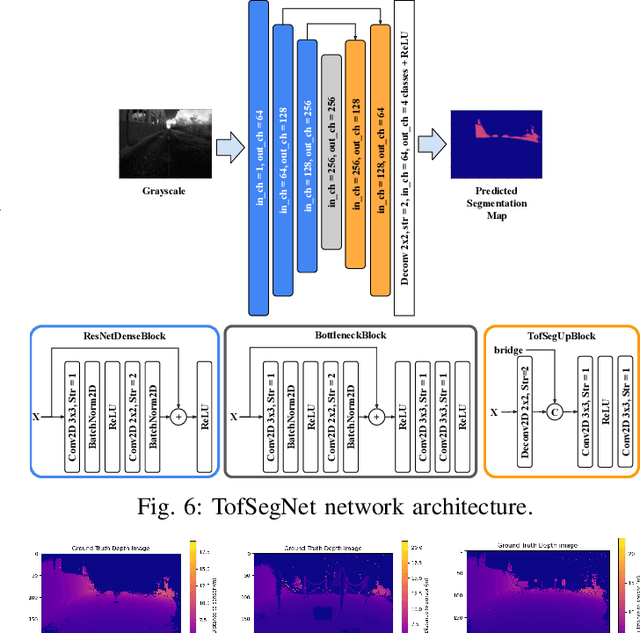
Indirect Time of Flight LiDARs can indirectly calculate the scene's depth from the phase shift angle between transmitted and received laser signals with amplitudes modulated at a predefined frequency. Unfortunately, this method generates ambiguity in calculated depth when the phase shift angle value exceeds $2\pi$. Current state-of-the-art methods use raw samples generated using two distinct modulation frequencies to overcome this ambiguity problem. However, this comes at the cost of increasing laser components' stress and raising their temperature, which reduces their lifetime and increases power consumption. In our work, we study two different methods to recover the entire depth range of the LiDAR using fewer raw data sample shots from a single modulation frequency with the support of sensor's gray scale output to reduce the laser components' stress and power consumption.
Shape of You: Precise 3D shape estimations for diverse body types
Apr 14, 2023
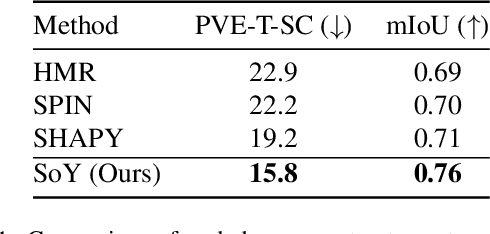
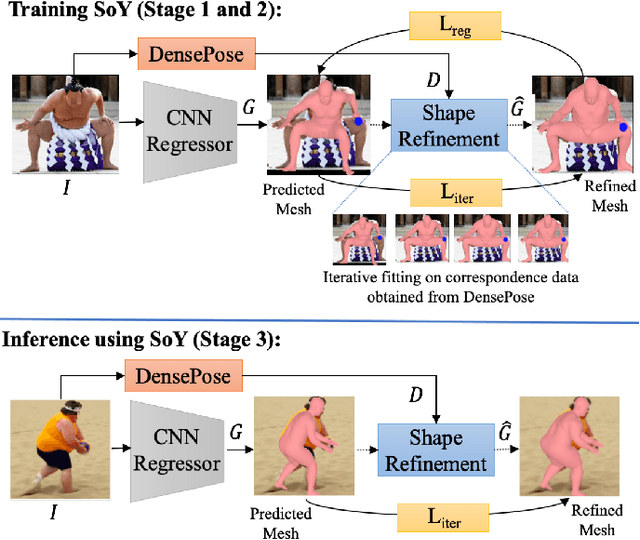
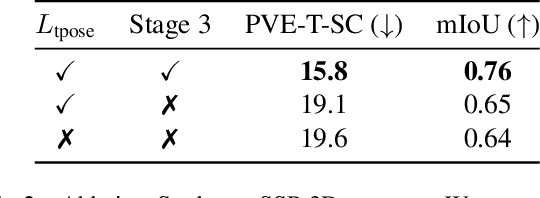
This paper presents Shape of You (SoY), an approach to improve the accuracy of 3D body shape estimation for vision-based clothing recommendation systems. While existing methods have successfully estimated 3D poses, there remains a lack of work in precise shape estimation, particularly for diverse human bodies. To address this gap, we propose two loss functions that can be readily integrated into parametric 3D human reconstruction pipelines. Additionally, we propose a test-time optimization routine that further improves quality. Our method improves over the recent SHAPY method by 17.7% on the challenging SSP-3D dataset. We consider our work to be a step towards a more accurate 3D shape estimation system that works reliably on diverse body types and holds promise for practical applications in the fashion industry.
Audio Time-Scale Modification with Temporal Compressing Networks
Oct 31, 2022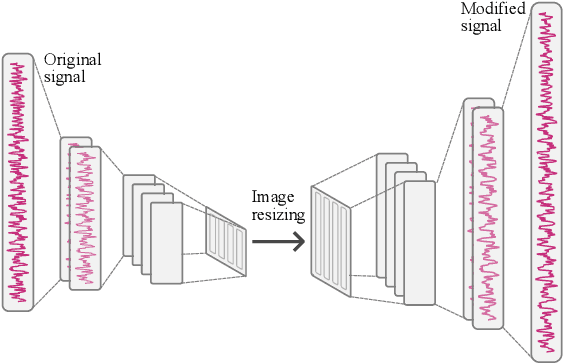
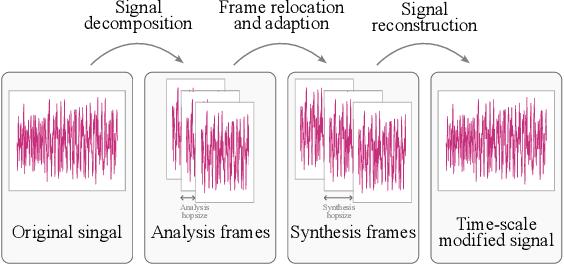
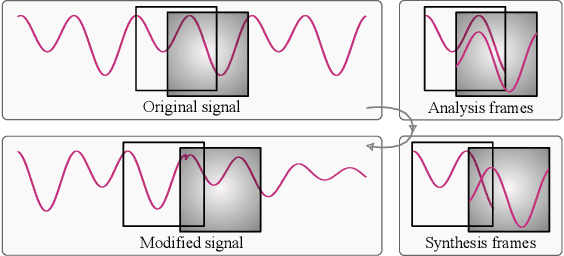
We proposed a novel approach in the field of time-scale modification on audio signals. While traditional methods use the framing technique, spectral approach uses the short-time Fourier transform to preserve the frequency during temporal stretching. TSM-Net, our neural-network model encodes the raw audio into a high-level latent representation. We call it Neuralgram, in which one vector represents 1024 audio samples. It is inspired by the framing technique but addresses the clipping artifacts. The Neuralgram is a two-dimensional matrix with real values, we can apply some existing image resizing techniques on the Neuralgram and decode it using our neural decoder to obtain the time-scaled audio. Both the encoder and decoder are trained with GANs, which shows fair generalization ability on the scaled Neuralgrams. Our method yields little artifacts and opens a new possibility in the research of modern time-scale modification. The audio samples can be found on https://ernestchu.github.io/tsm-net-demo/
Structured Dynamic Pricing: Optimal Regret in a Global Shrinkage Model
Mar 28, 2023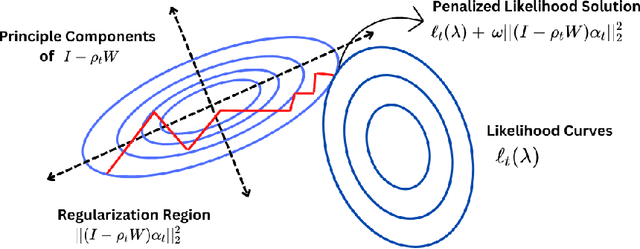
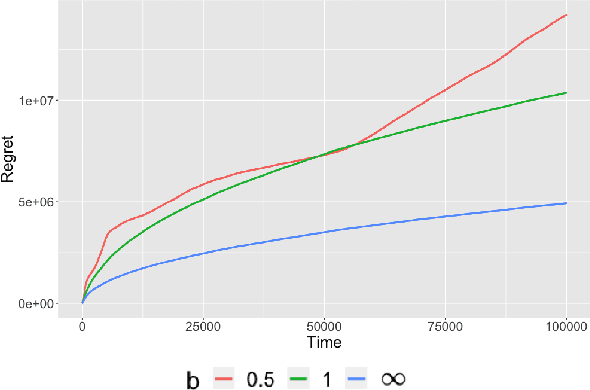
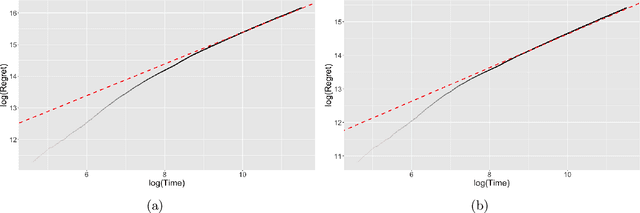
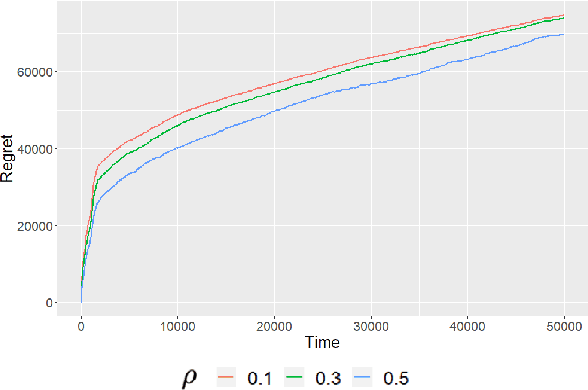
We consider dynamic pricing strategies in a streamed longitudinal data set-up where the objective is to maximize, over time, the cumulative profit across a large number of customer segments. We consider a dynamic probit model with the consumers' preferences as well as price sensitivity varying over time. Building on the well-known finding that consumers sharing similar characteristics act in similar ways, we consider a global shrinkage structure, which assumes that the consumers' preferences across the different segments can be well approximated by a spatial autoregressive (SAR) model. In such a streamed longitudinal set-up, we measure the performance of a dynamic pricing policy via regret, which is the expected revenue loss compared to a clairvoyant that knows the sequence of model parameters in advance. We propose a pricing policy based on penalized stochastic gradient descent (PSGD) and explicitly characterize its regret as functions of time, the temporal variability in the model parameters as well as the strength of the auto-correlation network structure spanning the varied customer segments. Our regret analysis results not only demonstrate asymptotic optimality of the proposed policy but also show that for policy planning it is essential to incorporate available structural information as policies based on unshrunken models are highly sub-optimal in the aforementioned set-up.
From Retrieval to Generation: Efficient and Effective Entity Set Expansion
Apr 07, 2023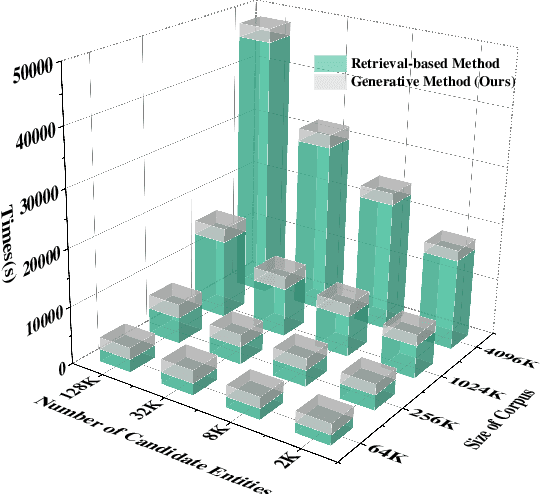
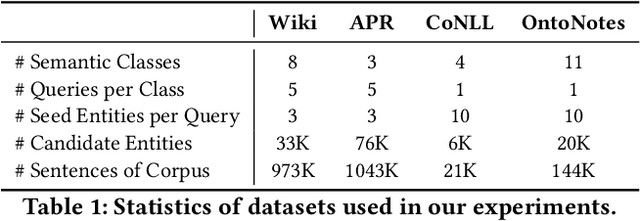
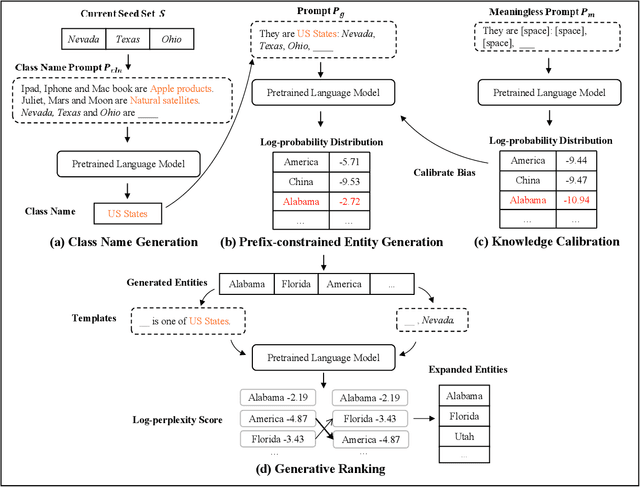
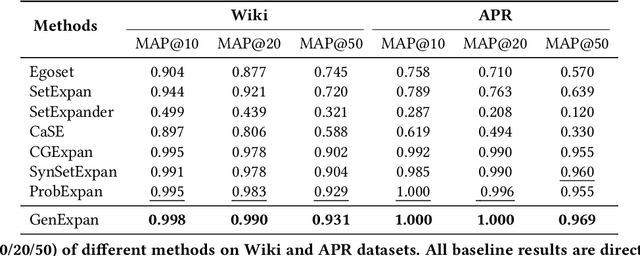
Entity Set Expansion (ESE) is a critical task aiming to expand entities of the target semantic class described by a small seed entity set. Most existing ESE methods are retrieval-based frameworks that need to extract the contextual features of entities and calculate the similarity between seed entities and candidate entities. To achieve the two purposes, they should iteratively traverse the corpus and the entity vocabulary provided in the datasets, resulting in poor efficiency and scalability. The experimental results indicate that the time consumed by the retrieval-based ESE methods increases linearly with entity vocabulary and corpus size. In this paper, we firstly propose a generative ESE framework, Generative Entity Set Expansion (GenExpan), which utilizes a generative pre-trained language model to accomplish ESE task. Specifically, a prefix tree is employed to guarantee the validity of entity generation, and automatically generated class names are adopted to guide the model to generate target entities. Moreover, we propose Knowledge Calibration and Generative Ranking to further bridge the gap between generic knowledge of the language model and the goal of ESE task. Experiments on publicly available datasets show that GenExpan is efficient and effective. For efficiency, expansion time consumed by GenExpan is independent of entity vocabulary and corpus size, and GenExpan achieves an average 600% speedup compared to strong baselines. For expansion performance, our framework outperforms previous state-of-the-art ESE methods.
Sheaf Neural Networks for Graph-based Recommender Systems
Apr 07, 2023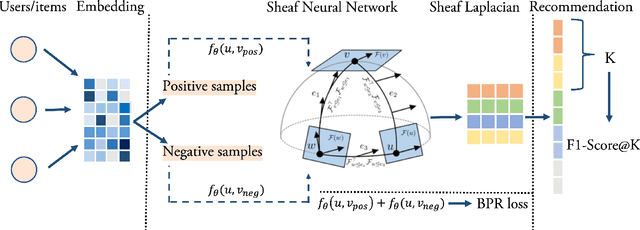
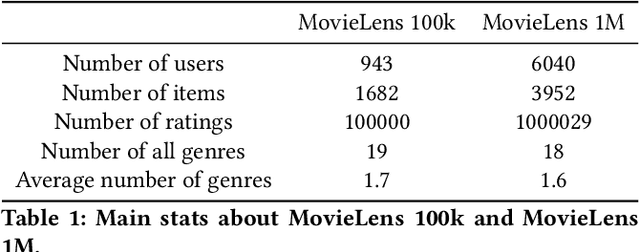
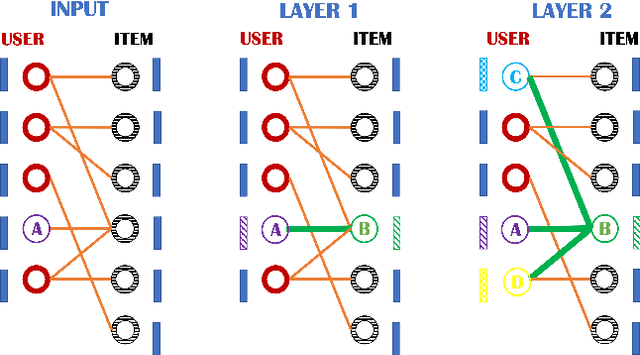
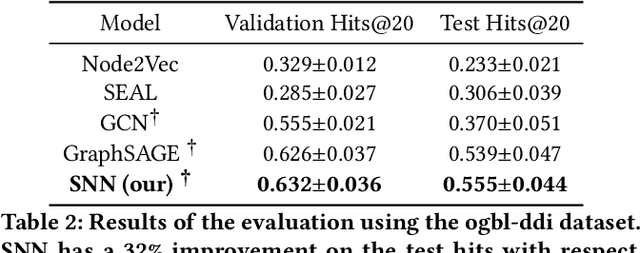
Recent progress in Graph Neural Networks has resulted in wide adoption by many applications, including recommendation systems. The reason for Graph Neural Networks' superiority over other approaches is that many problems in recommendation systems can be naturally modeled as graphs, where nodes can be either users or items and edges represent preference relationships. In current Graph Neural Network approaches, nodes are represented with a static vector learned at training time. This static vector might only be suitable to capture some of the nuances of users or items they define. To overcome this limitation, we propose using a recently proposed model inspired by category theory: Sheaf Neural Networks. Sheaf Neural Networks, and its connected Laplacian, can address the previous problem by associating every node (and edge) with a vector space instead than a single vector. The vector space representation is richer and allows picking the proper representation at inference time. This approach can be generalized for different related tasks on graphs and achieves state-of-the-art performance in terms of F1-Score@N in collaborative filtering and Hits@20 in link prediction. For collaborative filtering, the approach is evaluated on the MovieLens 100K with a 5.1% improvement, on MovieLens 1M with a 5.4% improvement and on Book-Crossing with a 2.8% improvement, while for link prediction on the ogbl-ddi dataset with a 1.6% refinement with respect to the respective baselines.
Variational Inference Aided Estimation of Time Varying Channels
Nov 03, 2022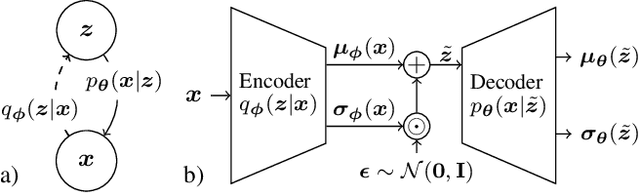

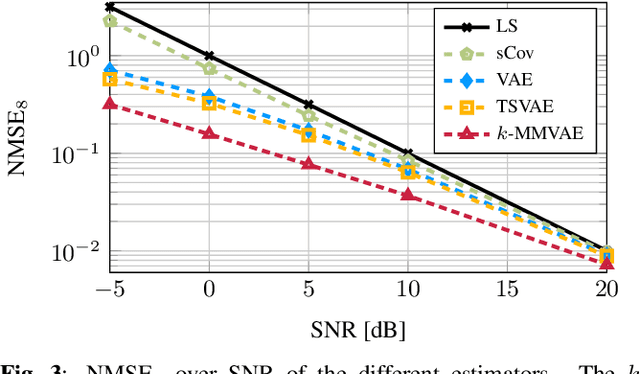
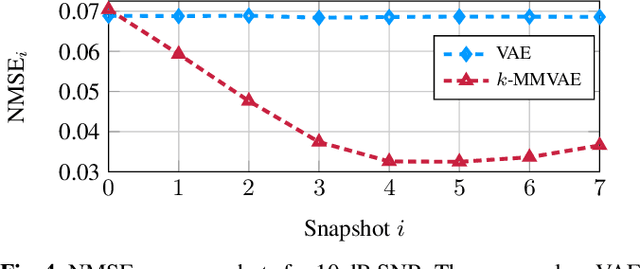
One way to improve the estimation of time varying channels is to incorporate knowledge of previous observations. In this context, Dynamical VAEs (DVAEs) build a promising deep learning (DL) framework which is well suited to learn the distribution of time series data. We introduce a new DVAE architecture, called k-MemoryMarkovVAE (k-MMVAE), whose sparsity can be controlled by an additional memory parameter. Following the approach in [1] we derive a k-MMVAE aided channel estimator which takes temporal correlations of successive observations into account. The results are evaluated on simulated channels by QuaDRiGa and show that the k-MMVAE aided channel estimator clearly outperforms other machine learning (ML) aided estimators which are either memoryless or naively extended to time varying channels without major adaptions.
Motif-guided Time Series Counterfactual Explanations
Nov 11, 2022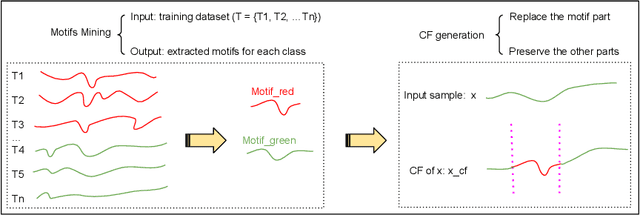
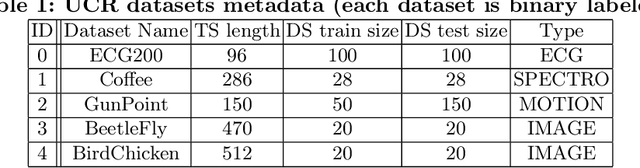
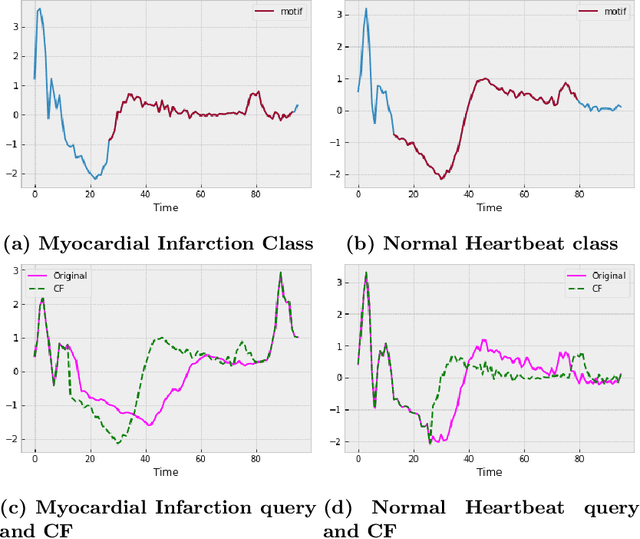
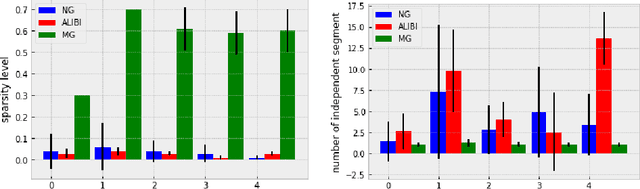
With the rising need of interpretable machine learning methods, there is a necessity for a rise in human effort to provide diverse explanations of the influencing factors of the model decisions. To improve the trust and transparency of AI-based systems, the EXplainable Artificial Intelligence (XAI) field has emerged. The XAI paradigm is bifurcated into two main categories: feature attribution and counterfactual explanation methods. While feature attribution methods are based on explaining the reason behind a model decision, counterfactual explanation methods discover the smallest input changes that will result in a different decision. In this paper, we aim at building trust and transparency in time series models by using motifs to generate counterfactual explanations. We propose Motif-Guided Counterfactual Explanation (MG-CF), a novel model that generates intuitive post-hoc counterfactual explanations that make full use of important motifs to provide interpretive information in decision-making processes. To the best of our knowledge, this is the first effort that leverages motifs to guide the counterfactual explanation generation. We validated our model using five real-world time-series datasets from the UCR repository. Our experimental results show the superiority of MG-CF in balancing all the desirable counterfactual explanations properties in comparison with other competing state-of-the-art baselines.