 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Low-code LLM: Visual Programming over LLMs
Apr 20, 2023
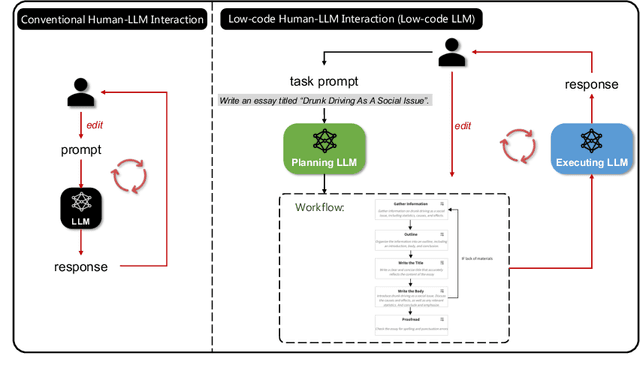
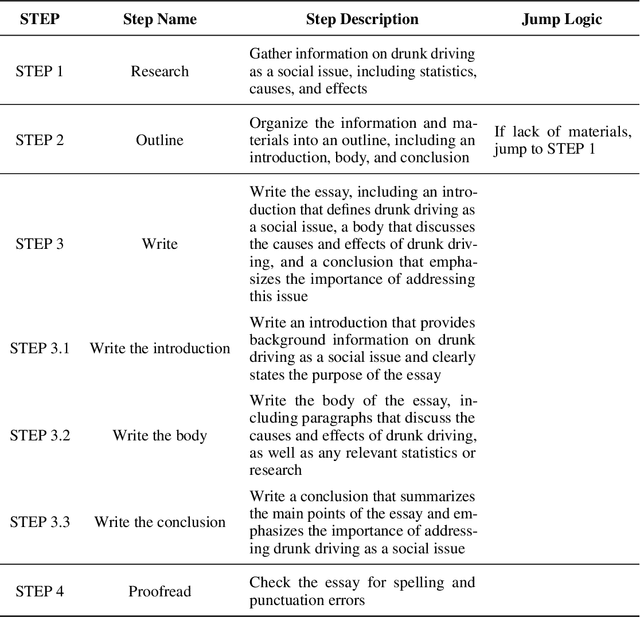
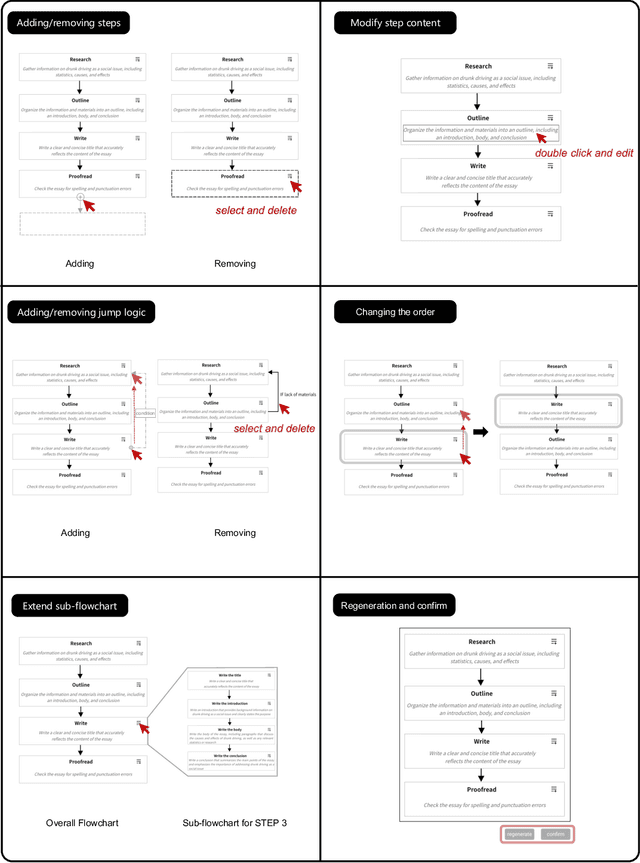

Effectively utilizing LLMs for complex tasks is challenging, often involving a time-consuming and uncontrollable prompt engineering process. This paper introduces a novel human-LLM interaction framework, Low-code LLM. It incorporates six types of simple low-code visual programming interactions, all supported by clicking, dragging, or text editing, to achieve more controllable and stable responses. Through visual interaction with a graphical user interface, users can incorporate their ideas into the workflow without writing trivial prompts. The proposed Low-code LLM framework consists of a Planning LLM that designs a structured planning workflow for complex tasks, which can be correspondingly edited and confirmed by users through low-code visual programming operations, and an Executing LLM that generates responses following the user-confirmed workflow. We highlight three advantages of the low-code LLM: controllable generation results, user-friendly human-LLM interaction, and broadly applicable scenarios. We demonstrate its benefits using four typical applications. By introducing this approach, we aim to bridge the gap between humans and LLMs, enabling more effective and efficient utilization of LLMs for complex tasks. Our system will be soon publicly available at LowCodeLLM.
Multi-domain learning CNN model for microscopy image classification
Apr 20, 2023
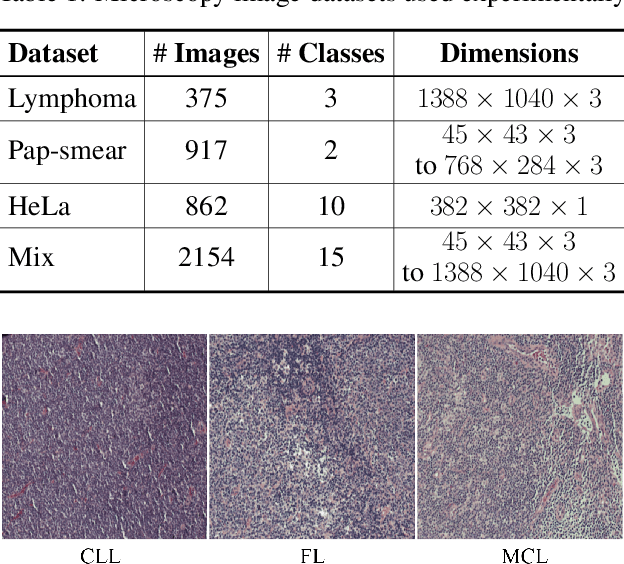
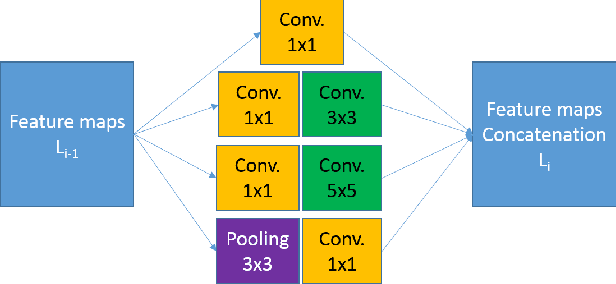
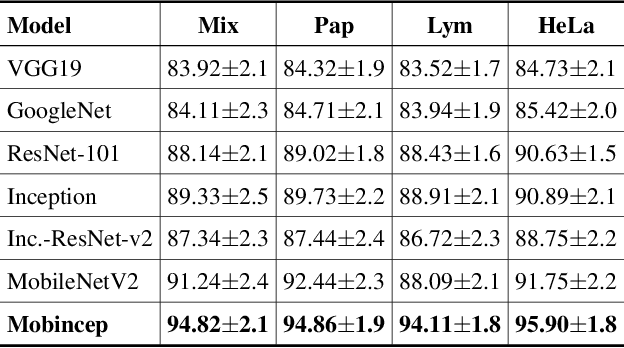
For any type of microscopy image, getting a deep learning model to work well requires considerable effort to select a suitable architecture and time to train it. As there is a wide range of microscopes and experimental setups, designing a single model that can apply to multiple imaging domains, instead of having multiple per-domain models, becomes more essential. This task is challenging and somehow overlooked in the literature. In this paper, we present a multi-domain learning architecture for the classification of microscopy images that differ significantly in types and contents. Unlike previous methods that are computationally intensive, we have developed a compact model, called Mobincep, by combining the simple but effective techniques of depth-wise separable convolution and the inception module. We also introduce a new optimization technique to regulate the latent feature space during training to improve the network's performance. We evaluated our model on three different public datasets and compared its performance in single-domain and multiple-domain learning modes. The proposed classifier surpasses state-of-the-art results and is robust for limited labeled data. Moreover, it helps to eliminate the burden of designing a new network when switching to new experiments.
A Hybrid Antenna Switching Scheme for Dynamic Channel Sounding
Apr 20, 2023
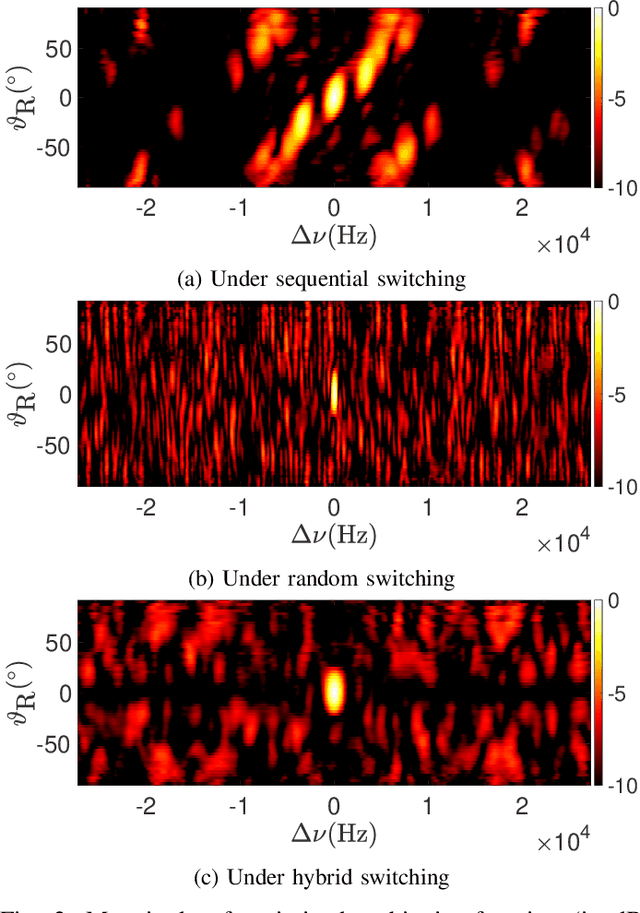
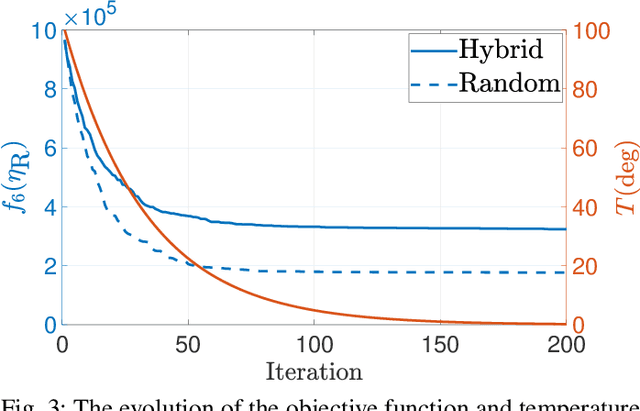
Channel sounding is essential for the development of radio systems. One flexible strategy is the switched-array-based channel sounding, where antenna elements are activated at different time instants to measure the channel spatial characteristics. Although its hardware complexity is decreased due to fewer radio-frequency (RF) chains, sequentially switching the antenna elements can result in aliasing in the joint estimation of angles and Doppler frequencies of multipath components (MPCs). Therefore, pseudo-random switching has been proposed to mitigate such aliasing and increase estimation accuracy in both angular and Doppler domains. Nevertheless, the increased Doppler resolution could cause additional post-processing complexity of parameter estimation, which is relevant when the Doppler frequencies are not of interest, e.g., for spatial channel modeling. This paper proposes an improved hybrid sequential and random switching scheme. The primary purpose is to maintain the estimation accuracy of angles of MPCs while decreasing the resolution of Doppler frequencies for minimized complexity of channel parameter estimation. A simulated-annealing algorithm is exploited to obtain an optimized switching sequence. The effectiveness of the proposed scheme is also demonstrated with a realistic antenna array.
ZEBRA: Z-order Curve-based Event Retrieval Approach to Efficiently Explore Automotive Data
Apr 20, 2023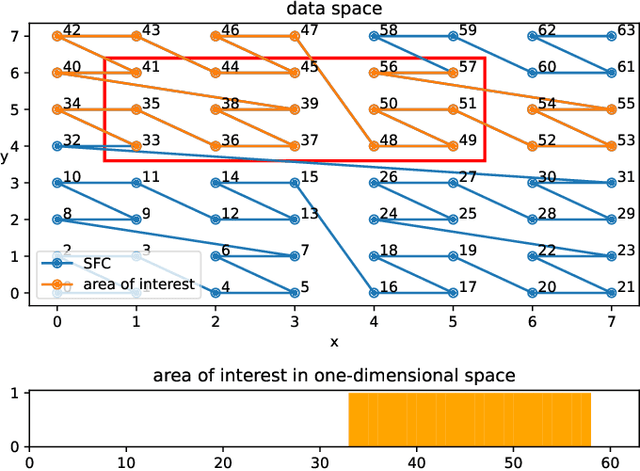
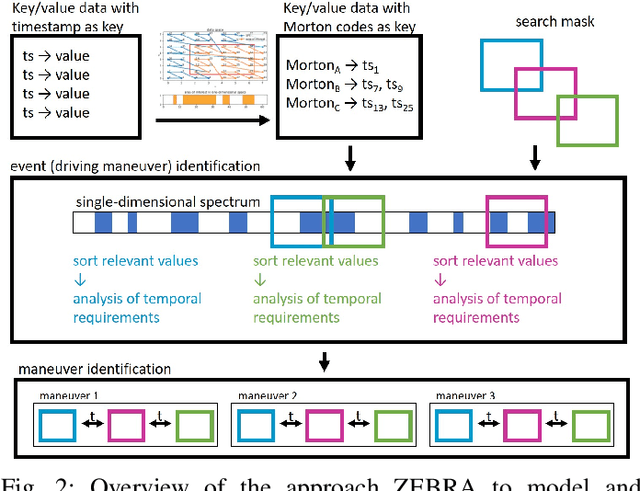
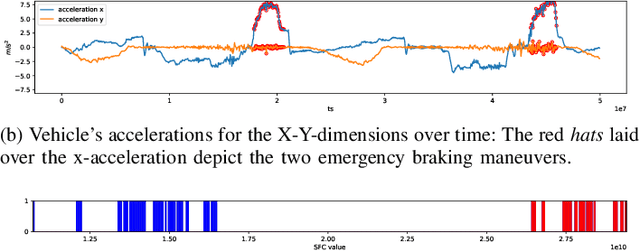

Evaluating the performance of software for automated vehicles is predominantly driven by data collected from the real world. While professional test drivers are supported with technical means to semi-automatically annotate driving maneuvers to allow better event identification, simple data loggers in large vehicle fleets typically lack automatic and detailed event classification and hence, extra effort is needed when post-processing such data. Yet, the data quality from professional test drivers is apparently higher than the one from large fleets where labels are missing, but the non-annotated data set from large vehicle fleets is much more representative for typical, realistic driving scenarios to be handled by automated vehicles. However, while growing the data from large fleets is relatively simple, adding valuable annotations during post-processing has become increasingly expensive. In this paper, we leverage Z-order space-filling curves to systematically reduce data dimensionality while preserving domain-specific data properties, which allows us to explore even large-scale field data sets to spot interesting events orders of magnitude faster than processing time-series data directly. Furthermore, the proposed concept is based on an analytical approach, which preserves explainability for the identified events.
Decouple Graph Neural Networks: Train Multiple Simple GNNs Simultaneously Instead of One
Apr 20, 2023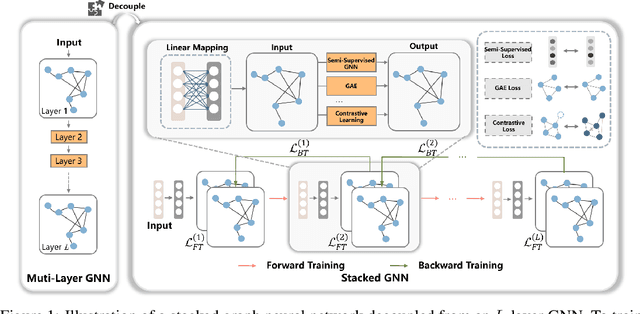
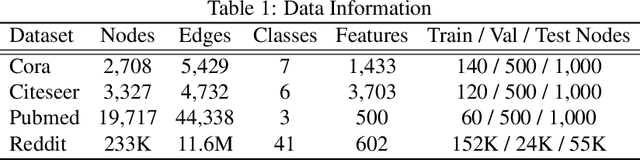
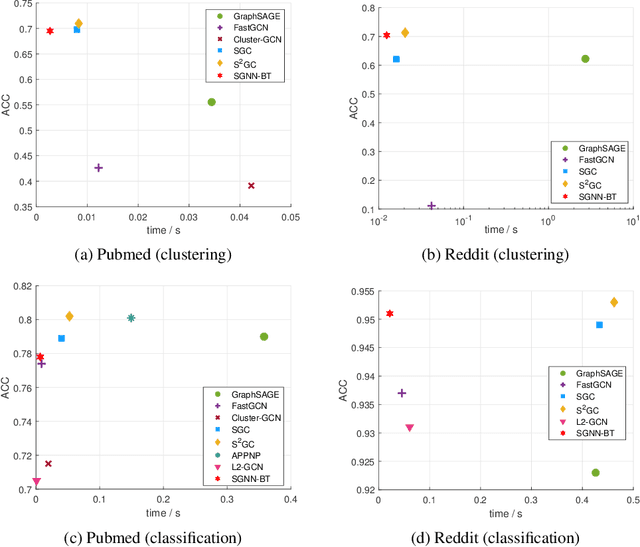
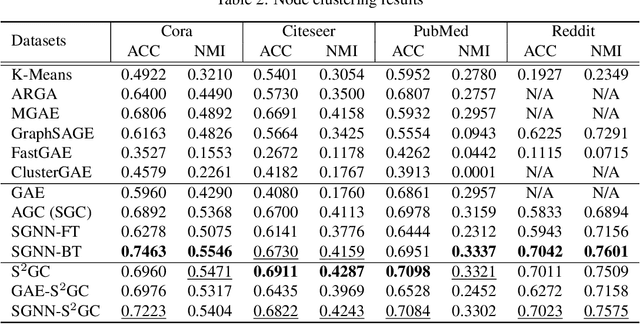
Graph neural networks (GNN) suffer from severe inefficiency. It is mainly caused by the exponential growth of node dependency with the increase of layers. It extremely limits the application of stochastic optimization algorithms so that the training of GNN is usually time-consuming. To address this problem, we propose to decouple a multi-layer GNN as multiple simple modules for more efficient training, which is comprised of classical forward training (FT)and designed backward training (BT). Under the proposed framework, each module can be trained efficiently in FT by stochastic algorithms without distortion of graph information owing to its simplicity. To avoid the only unidirectional information delivery of FT and sufficiently train shallow modules with the deeper ones, we develop a backward training mechanism that makes the former modules perceive the latter modules. The backward training introduces the reversed information delivery into the decoupled modules as well as the forward information delivery. To investigate how the decoupling and greedy training affect the representational capacity, we theoretically prove that the error produced by linear modules will not accumulate on unsupervised tasks in most cases. The theoretical and experimental results show that the proposed framework is highly efficient with reasonable performance.
MS-LSTM: Exploring Spatiotemporal Multiscale Representations in Video Prediction Domain
Apr 16, 2023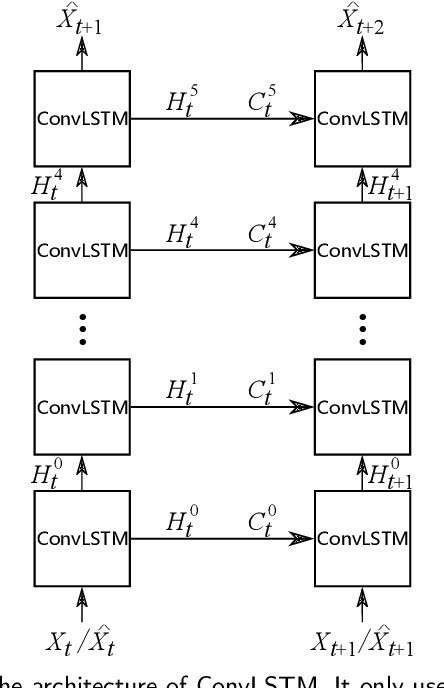
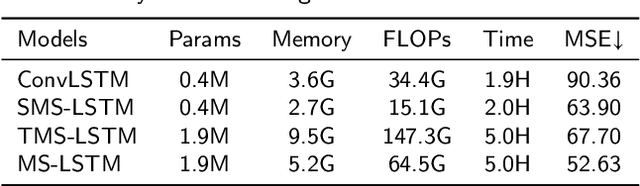
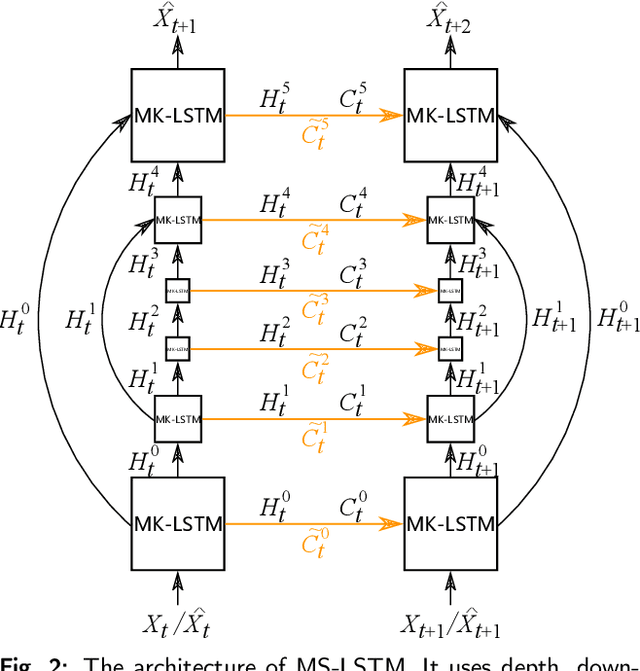
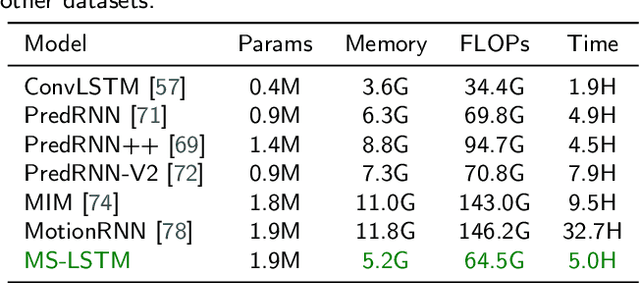
The drastic variation of motion in spatial and temporal dimensions makes the video prediction task extremely challenging. Existing RNN models obtain higher performance by deepening or widening the model. They obtain the multi-scale features of the video only by stacking layers, which is inefficient and brings unbearable training costs (such as memory, FLOPs, and training time). Different from them, this paper proposes a spatiotemporal multi-scale model called MS-LSTM wholly from a multi-scale perspective. On the basis of stacked layers, MS-LSTM incorporates two additional efficient multi-scale designs to fully capture spatiotemporal context information. Concretely, we employ LSTMs with mirrored pyramid structures to construct spatial multi-scale representations and LSTMs with different convolution kernels to construct temporal multi-scale representations. Detailed comparison experiments with eight baseline models on four video datasets show that MS-LSTM has better performance but lower training costs.
Data Efficient Contrastive Learning in Histopatholgy using Active Sampling
Mar 28, 2023
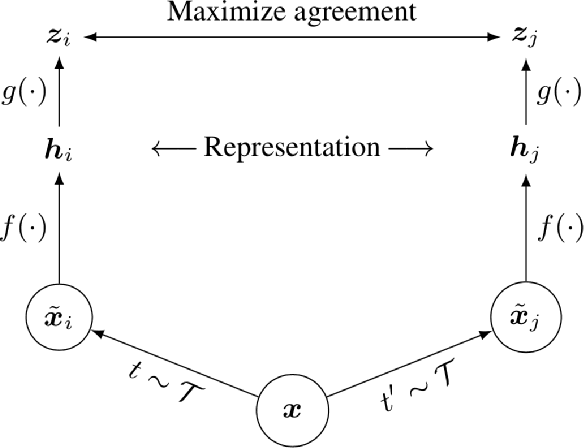
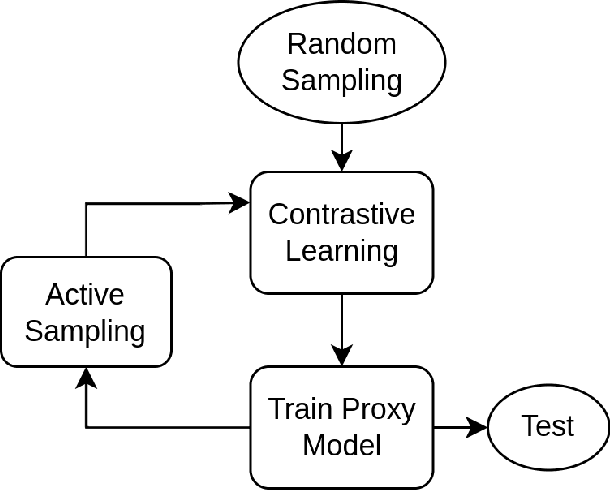
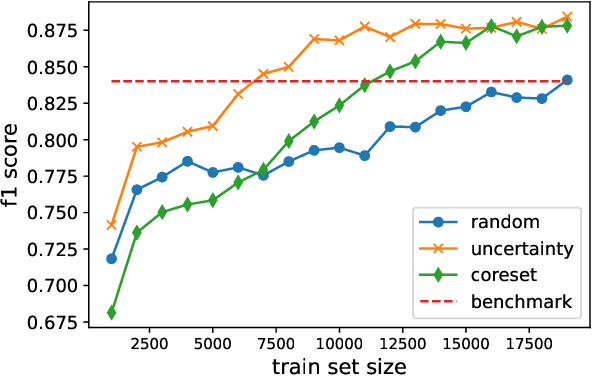
Deep Learning based diagnostics systems can provide accurate and robust quantitative analysis in digital pathology. Training these algorithms requires large amounts of annotated data which is impractical in pathology due to the high resolution of histopathological images. Hence, self-supervised methods have been proposed to learn features using ad-hoc pretext tasks. The self-supervised training process is time consuming and often leads to subpar feature representation due to a lack of constrain on the learnt feature space, particularly prominent under data imbalance. In this work, we propose to actively sample the training set using a handful of labels and a small proxy network, decreasing sample requirement by 93% and training time by 99%.
Robust Text-driven Image Editing Method that Adaptively Explores Directions in Latent Spaces of StyleGAN and CLIP
Apr 03, 2023
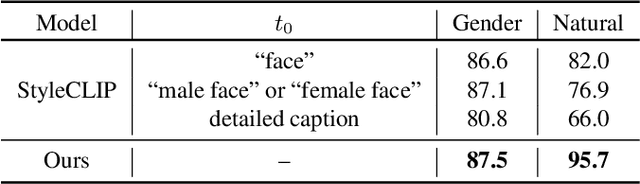
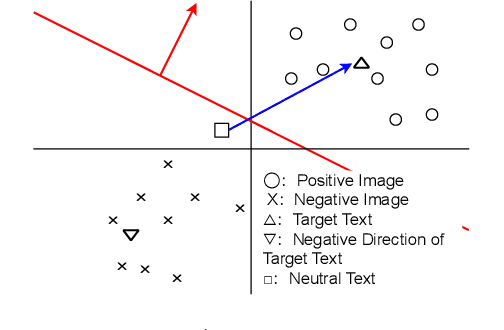

Automatic image editing has great demands because of its numerous applications, and the use of natural language instructions is essential to achieving flexible and intuitive editing as the user imagines. A pioneering work in text-driven image editing, StyleCLIP, finds an edit direction in the CLIP space and then edits the image by mapping the direction to the StyleGAN space. At the same time, it is difficult to tune appropriate inputs other than the original image and text instructions for image editing. In this study, we propose a method to construct the edit direction adaptively in the StyleGAN and CLIP spaces with SVM. Our model represents the edit direction as a normal vector in the CLIP space obtained by training a SVM to classify positive and negative images. The images are retrieved from a large-scale image corpus, originally used for pre-training StyleGAN, according to the CLIP similarity between the images and the text instruction. We confirmed that our model performed as well as the StyleCLIP baseline, whereas it allows simple inputs without increasing the computational time.
Autonomous Power Line Inspection with Drones via Perception-Aware MPC
Apr 03, 2023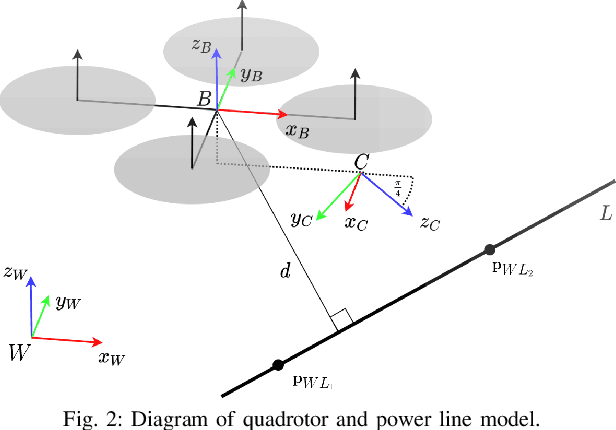
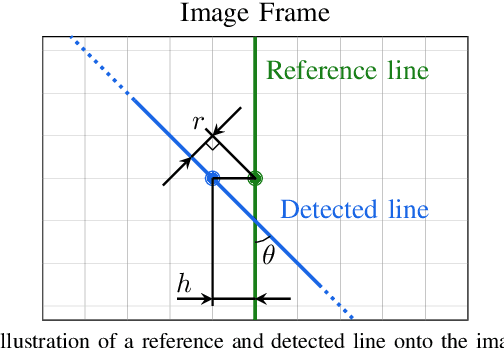
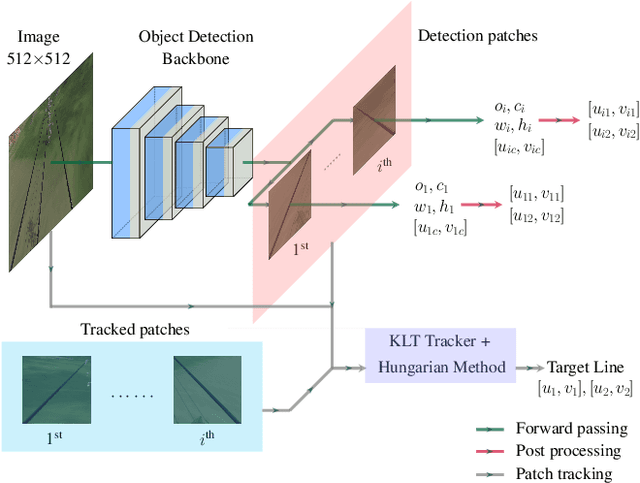

Drones have the potential to revolutionize power line inspection by increasing productivity, reducing inspection time, improving data quality, and eliminating the risks for human operators. Current state-of-the-art systems for power line inspection have two shortcomings: (i) control is decoupled from perception and needs accurate information about the location of the power lines and masts; (ii) collision avoidance is decoupled from the power line tracking, which results in poor tracking in the vicinity of the power masts, and, consequently, in decreased data quality for visual inspection. In this work, we propose a model predictive controller (MPC) that overcomes these limitations by tightly coupling perception and action. Our controller generates commands that maximize the visibility of the power lines while, at the same time, safely avoiding the power masts. For power line detection, we propose a lightweight learning-based detector that is trained only on synthetic data and is able to transfer zero-shot to real-world power line images. We validate our system in simulation and real-world experiments on a mock-up power line infrastructure.
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Nov 27, 2022
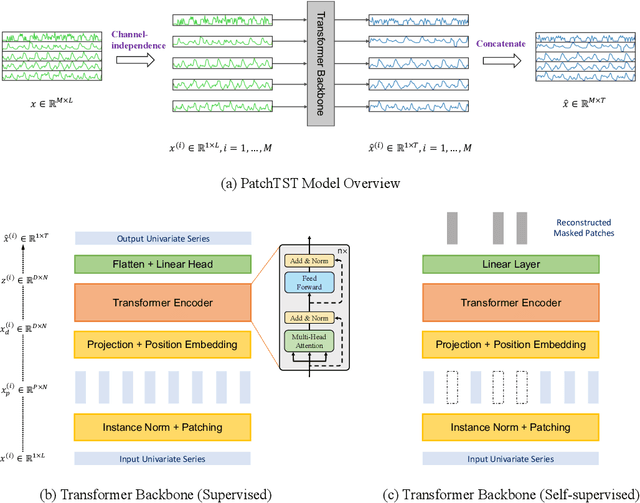

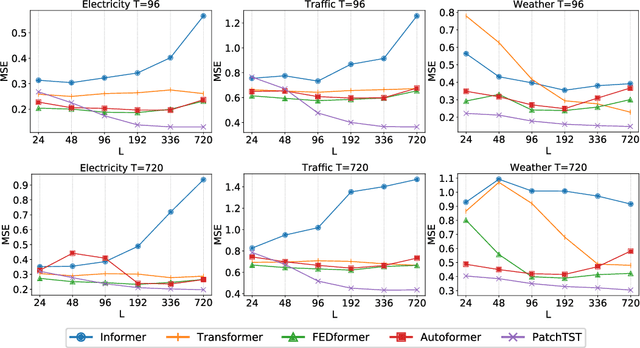
We propose an efficient design of Transformer-based models for multivariate time series forecasting and self-supervised representation learning. It is based on two key components: (i) segmentation of time series into subseries-level patches which are served as input tokens to Transformer; (ii) channel-independence where each channel contains a single univariate time series that shares the same embedding and Transformer weights across all the series. Patching design naturally has three-fold benefit: local semantic information is retained in the embedding; computation and memory usage of the attention maps are quadratically reduced given the same look-back window; and the model can attend longer history. Our channel-independent patch time series Transformer (PatchTST) can improve the long-term forecasting accuracy significantly when compared with that of SOTA Transformer-based models. We also apply our model to self-supervised pre-training tasks and attain excellent fine-tuning performance, which outperforms supervised training on large datasets. Transferring of masked pre-trained representation on one dataset to others also produces SOTA forecasting accuracy. Code is available at: https://github.com/yuqinie98/PatchTST.