 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CRU: A Novel Neural Architecture for Improving the Predictive Performance of Time-Series Data
Nov 30, 2022
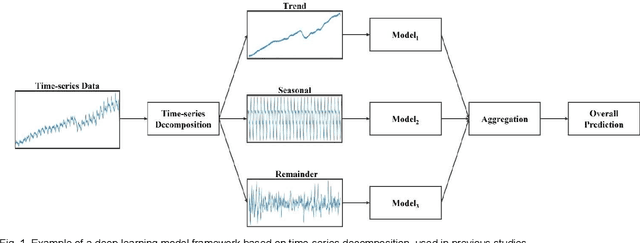
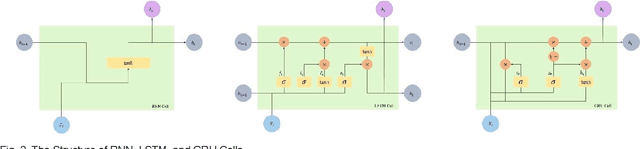
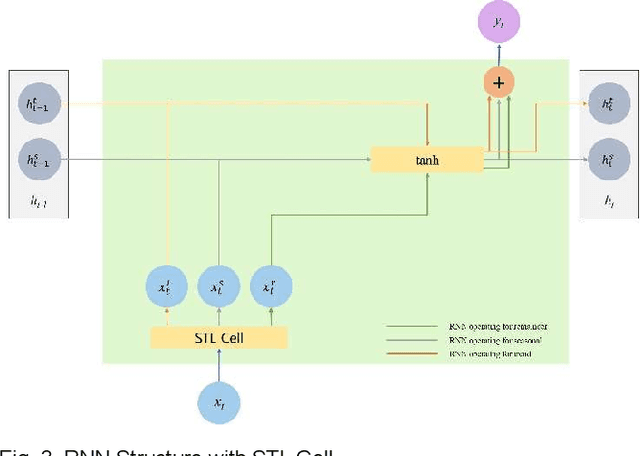
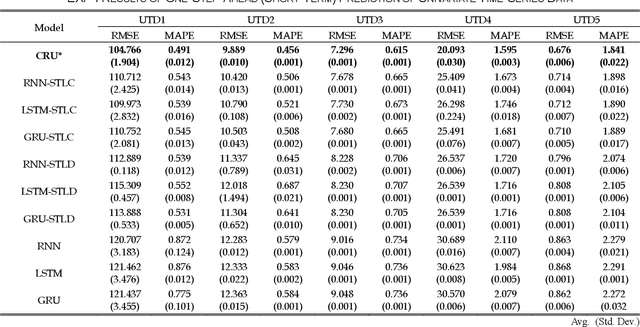
The time-series forecasting (TSF) problem is a traditional problem in the field of artificial intelligence. Models such as Recurrent Neural Network (RNN), Long Short Term Memory (LSTM), and GRU (Gate Recurrent Units) have contributed to improving the predictive accuracy of TSF. Furthermore, model structures have been proposed to combine time-series decomposition methods, such as seasonal-trend decomposition using Loess (STL) to ensure improved predictive accuracy. However, because this approach is learned in an independent model for each component, it cannot learn the relationships between time-series components. In this study, we propose a new neural architecture called a correlation recurrent unit (CRU) that can perform time series decomposition within a neural cell and learn correlations (autocorrelation and correlation) between each decomposition component. The proposed neural architecture was evaluated through comparative experiments with previous studies using five univariate time-series datasets and four multivariate time-series data. The results showed that long- and short-term predictive performance was improved by more than 10%. The experimental results show that the proposed CRU is an excellent method for TSF problems compared to other neural architectures.
Space-Time- and Frequency- Spreading for Interference Minimization in Dense IoT
Dec 04, 2022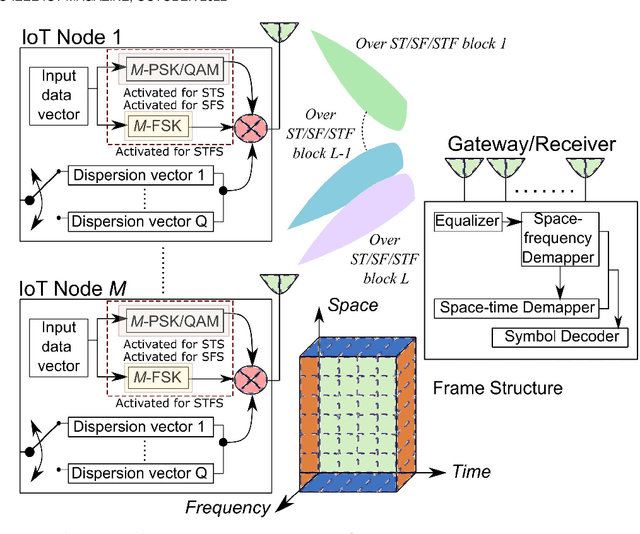
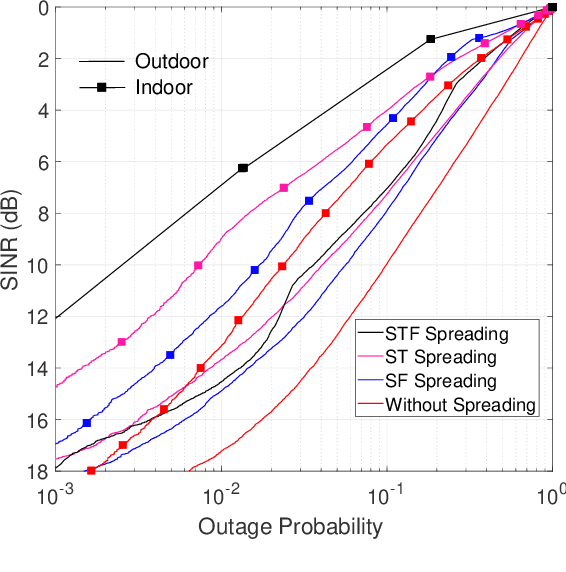
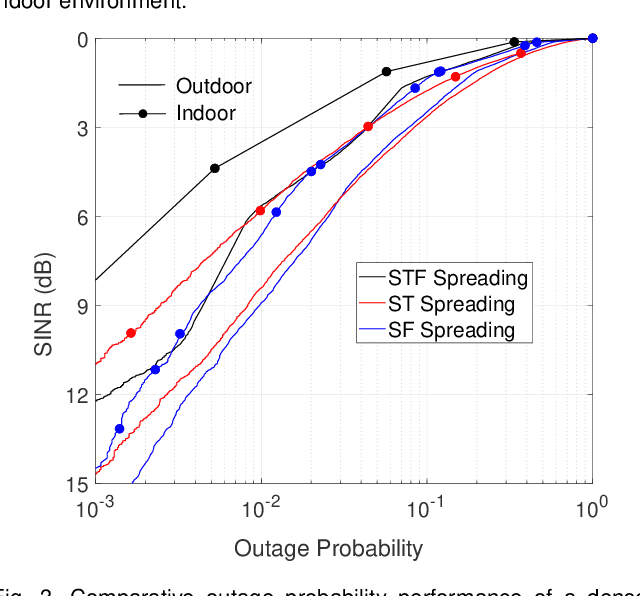
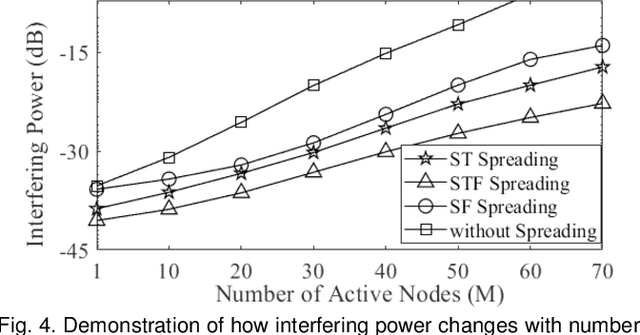
In this article, we propose a space spreading-assisted framework that leverages either time or frequency diversity or both to reduce interference and signal loss owing to channel impairments and facilitate the efficient operation of large-scale dense Internet-of-Things (IoT). Our approach employs dispersion of data-streams transmitted from individual IoT devices over indexed space-time (ST), space-frequency (SF) or space-time-frequency (STF) blocks. As a result, no two devices transmit on the same block; only one is activated while the rest of the devices in the network is silent, thereby minimizing possibility of interference on the transmit side. On the receive side, multiple-antenna array ameliorates performance in presence of channel impairments while exploiting array-processing gain. As interference due to superposition of multiple data-streams is killed at its root, no extra energy is wasted in fighting interference and other impairments, thereby enabling energy-efficient transmission from multiple devices over multiple access channel (MAC). To validate the proposed concept, we simulate the performance of the framework against dense IoT networks deployed in generalized indoor and outdoor scenarios in terms of probability of signal outage. Results demonstrate that our conceptualized framework benefits from interference-free transmission as well as enhancement in overall system performance.
Context-Aware Ensemble Learning for Time Series
Nov 30, 2022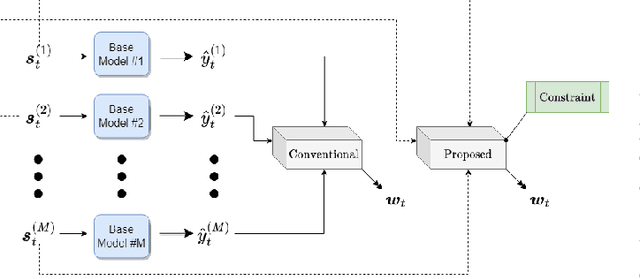
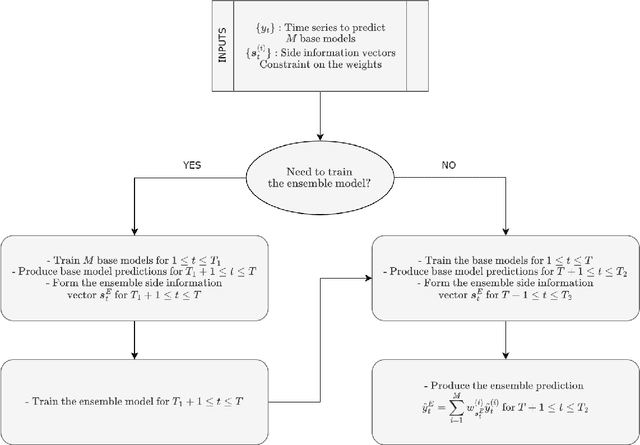
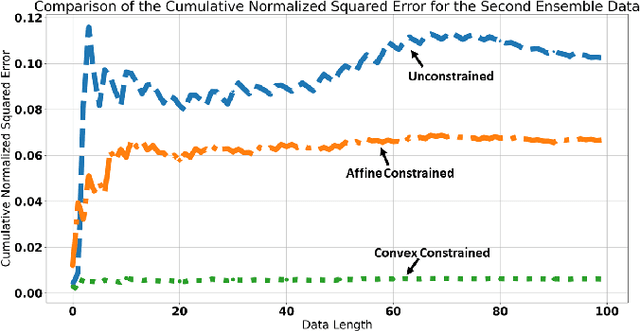
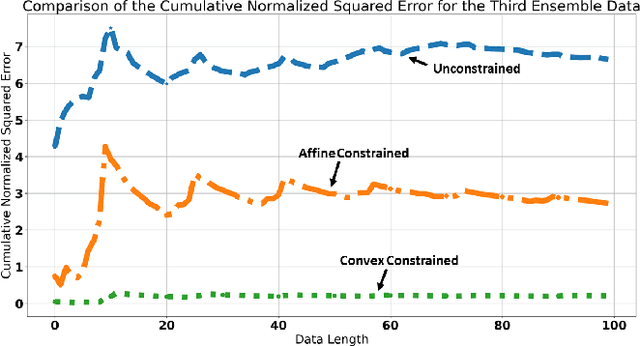
We investigate ensemble methods for prediction in an online setting. Unlike all the literature in ensembling, for the first time, we introduce a new approach using a meta learner that effectively combines the base model predictions via using a superset of the features that is the union of the base models' feature vectors instead of the predictions themselves. Here, our model does not use the predictions of the base models as inputs to a machine learning algorithm, but choose the best possible combination at each time step based on the state of the problem. We explore three different constraint spaces for the ensembling of the base learners that linearly combines the base predictions, which are convex combinations where the components of the ensembling vector are all nonnegative and sum up to 1; affine combinations where the weight vector components are required to sum up to 1; and the unconstrained combinations where the components are free to take any real value. The constraints are both theoretically analyzed under known statistics and integrated into the learning procedure of the meta learner as a part of the optimization in an automated manner. To show the practical efficiency of the proposed method, we employ a gradient-boosted decision tree and a multi-layer perceptron separately as the meta learners. Our framework is generic so that one can use other machine learning architectures as the ensembler as long as they allow for a custom differentiable loss for minimization. We demonstrate the learning behavior of our algorithm on synthetic data and the significant performance improvements over the conventional methods over various real life datasets, extensively used in the well-known data competitions. Furthermore, we openly share the source code of the proposed method to facilitate further research and comparison.
Graph Kalman Filters
Mar 21, 2023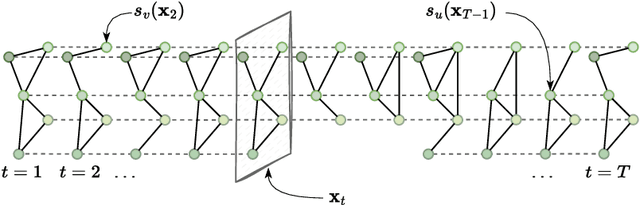
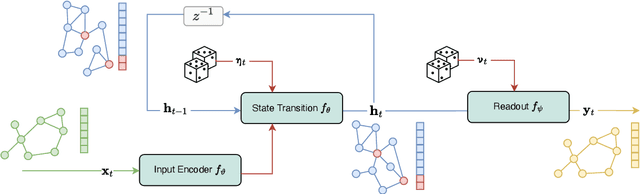
The well-known Kalman filters model dynamical systems by relying on state-space representations with the next state updated, and its uncertainty controlled, by fresh information associated with newly observed system outputs. This paper generalizes, for the first time in the literature, Kalman and extended Kalman filters to discrete-time settings where inputs, states, and outputs are represented as attributed graphs whose topology and attributes can change with time. The setup allows us to adapt the framework to cases where the output is a vector or a scalar too (node/graph level tasks). Within the proposed theoretical framework, the unknown state-transition and the readout functions are learned end-to-end along with the downstream prediction task.
The State-of-the-Art in Air Pollution Monitoring and Forecasting Systems using IoT, Big Data, and Machine Learning
Apr 19, 2023The quality of air is closely linked with the life quality of humans, plantations, and wildlife. It needs to be monitored and preserved continuously. Transportations, industries, construction sites, generators, fireworks, and waste burning have a major percentage in degrading the air quality. These sources are required to be used in a safe and controlled manner. Using traditional laboratory analysis or installing bulk and expensive models every few miles is no longer efficient. Smart devices are needed for collecting and analyzing air data. The quality of air depends on various factors, including location, traffic, and time. Recent researches are using machine learning algorithms, big data technologies, and the Internet of Things to propose a stable and efficient model for the stated purpose. This review paper focuses on studying and compiling recent research in this field and emphasizes the Data sources, Monitoring, and Forecasting models. The main objective of this paper is to provide the astuteness of the researches happening to improve the various aspects of air polluting models. Further, it casts light on the various research issues and challenges also.
Should Collaborative Robots be Transparent?
Apr 23, 2023
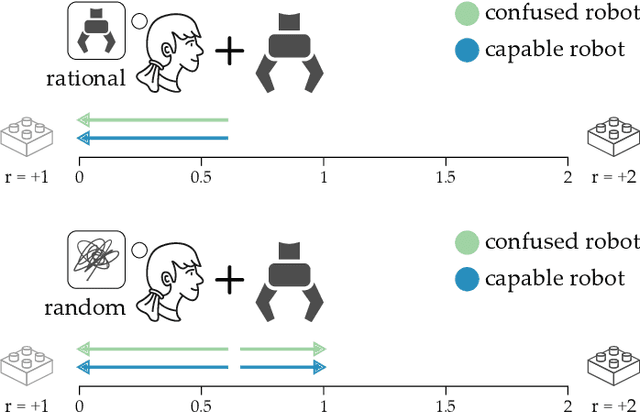
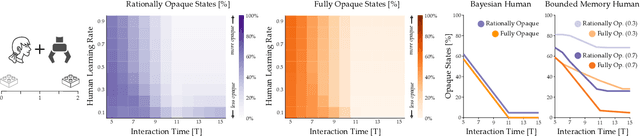
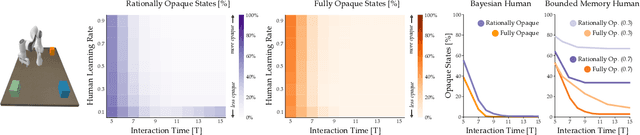
Today's robots often assume that their behavior should be transparent. These transparent (e.g., legible, explainable) robots intentionally choose actions that convey their internal state to nearby humans. But while transparent behavior seems beneficial, is it actually optimal? In this paper we consider collaborative settings where the human and robot have the same objective, and the human is uncertain about the robot's type (i.e., the robot's internal state). We extend a recursive combination of Bayesian Nash equilibrium and the Bellman equation to solve for optimal robot policies. Interestingly, we discover that it is not always optimal for collaborative robots to be transparent; instead, human and robot teams can sometimes achieve higher rewards when the robot is opaque. Opaque robots select the same actions regardless of their internal state: because each type of opaque robot behaves in the same way, the human cannot infer the robot's type. Our analysis suggests that opaque behavior becomes optimal when either (a) human-robot interactions have a short time horizon or (b) users are slow to learn from the robot's actions. Across online and in-person user studies with 43 total participants, we find that users reach higher rewards when working with opaque partners, and subjectively rate opaque robots as about equal to transparent robots. See videos of our experiments here: https://youtu.be/u8q1Z7WHUuI
IDLL: Inverse Depth Line based Visual Localization in Challenging Environments
Apr 23, 2023
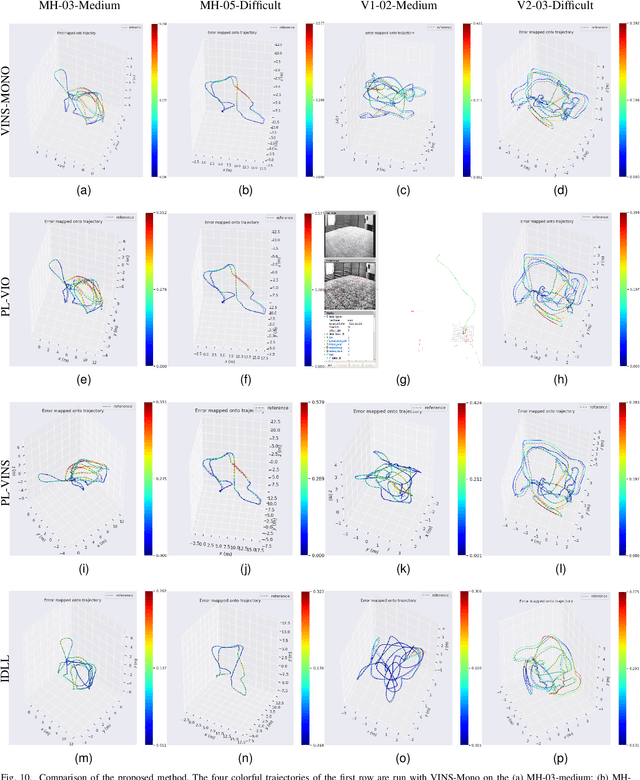
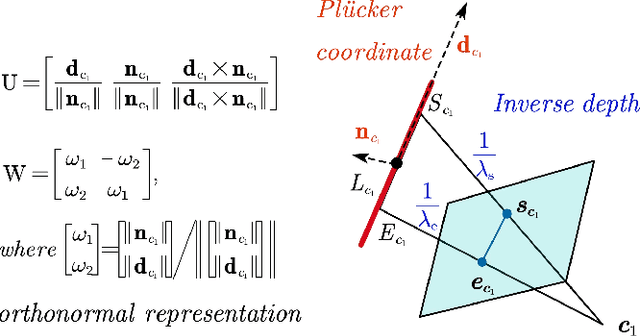
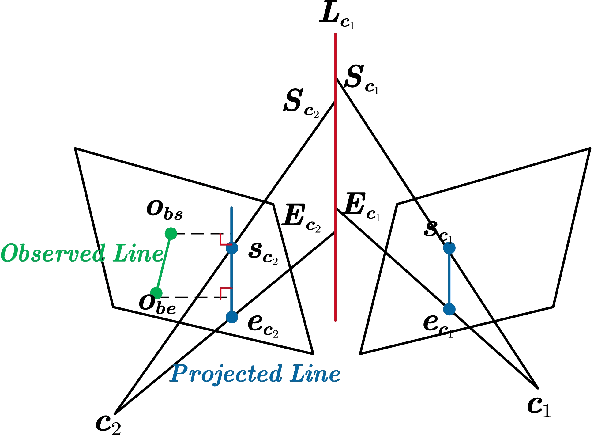
Precise and real-time localization of unmanned aerial vehicles (UAVs) or robots in GNSS denied indoor environments are critically important for various logistics and surveillance applications. Vision-based simultaneously locating and mapping (VSLAM) are key solutions but suffer location drifts in texture-less, man-made indoor environments. Line features are rich in man-made environments which can be exploited to improve the localization robustness, but existing point-line based VSLAM methods still lack accuracy and efficiency for the representation of lines introducing unnecessary degrees of freedoms. In this paper, we propose Inverse Depth Line Localization(IDLL), which models each extracted line feature using two inverse depth variables exploiting the fact that the projected pixel coordinates on the image plane are rather accurate, which partially restrict the lines. This freedom-reduced representation of lines enables easier line determination and faster convergence of bundle adjustment in each step, therefore achieves more accurate and more efficient frame-to-frame registration and frame-to-map registration using both point and line visual features. We redesign the whole front-end and back-end modules of VSLAM using this line model. IDLL is extensively evaluated in multiple perceptually-challenging datasets. The results show it is more accurate, robust, and needs lower computational overhead than the current state-of-the-art of feature-based VSLAM methods.
In-situ crack and keyhole pore detection in laser directed energy deposition through acoustic signal and deep learning
Apr 10, 2023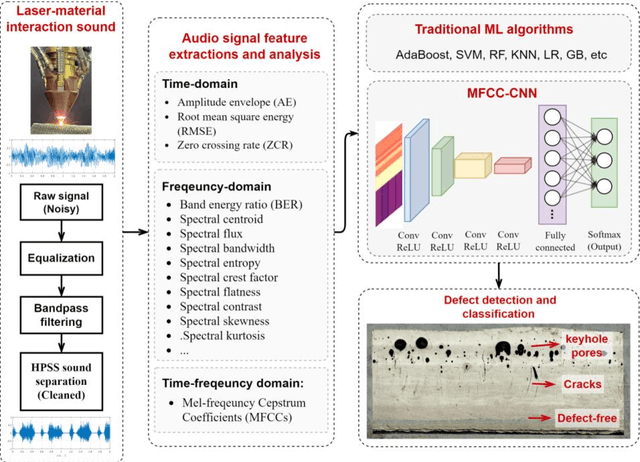
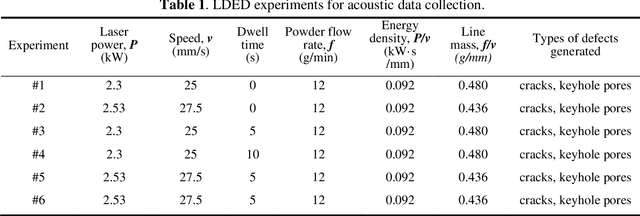


Cracks and keyhole pores are detrimental defects in alloys produced by laser directed energy deposition (LDED). Laser-material interaction sound may hold information about underlying complex physical events such as crack propagation and pores formation. However, due to the noisy environment and intricate signal content, acoustic-based monitoring in LDED has received little attention. This paper proposes a novel acoustic-based in-situ defect detection strategy in LDED. The key contribution of this study is to develop an in-situ acoustic signal denoising, feature extraction, and sound classification pipeline that incorporates convolutional neural networks (CNN) for online defect prediction. Microscope images are used to identify locations of the cracks and keyhole pores within a part. The defect locations are spatiotemporally registered with acoustic signal. Various acoustic features corresponding to defect-free regions, cracks, and keyhole pores are extracted and analysed in time-domain, frequency-domain, and time-frequency representations. The CNN model is trained to predict defect occurrences using the Mel-Frequency Cepstral Coefficients (MFCCs) of the lasermaterial interaction sound. The CNN model is compared to various classic machine learning models trained on the denoised acoustic dataset and raw acoustic dataset. The validation results shows that the CNN model trained on the denoised dataset outperforms others with the highest overall accuracy (89%), keyhole pore prediction accuracy (93%), and AUC-ROC score (98%). Furthermore, the trained CNN model can be deployed into an in-house developed software platform for online quality monitoring. The proposed strategy is the first study to use acoustic signals with deep learning for insitu defect detection in LDED process.
SPHR-SAR-Net: Superpixel High-resolution SAR Imaging Network Based on Nonlocal Total Variation
Apr 10, 2023
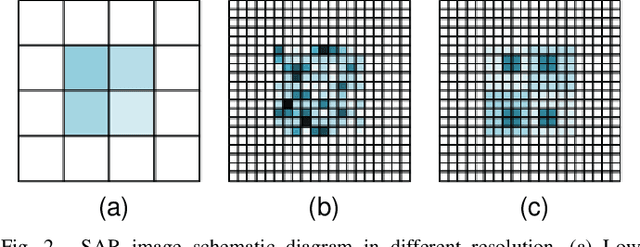
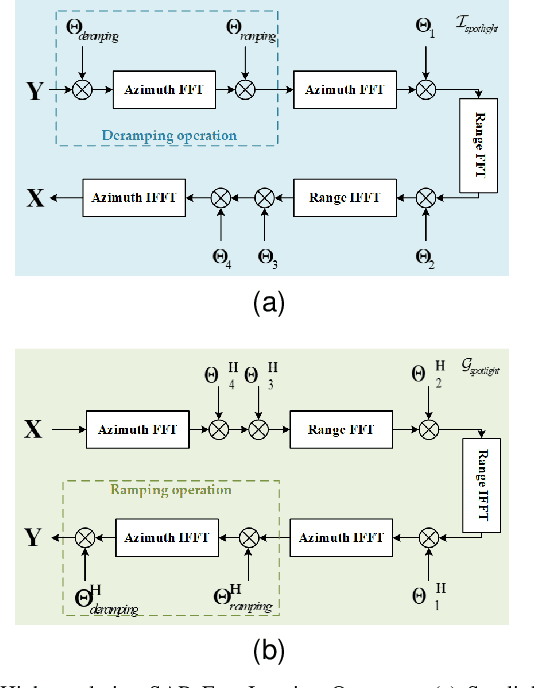

High-resolution is a key trend in the development of synthetic aperture radar (SAR), which enables the capture of fine details and accurate representation of backscattering properties. However, traditional high-resolution SAR imaging algorithms face several challenges. Firstly, these algorithms tend to focus on local information, neglecting non-local information between different pixel patches. Secondly, speckle is more pronounced and difficult to filter out in high-resolution SAR images. Thirdly, the process of high-resolution SAR imaging generally involves high time and computational complexity, making real-time imaging difficult to achieve. To address these issues, we propose a Superpixel High-Resolution SAR Imaging Network (SPHR-SAR-Net) for rapid despeckling in high-resolution SAR mode. Based on the concept of superpixel techniques, we initially combine non-convex and non-local total variation as compound regularization. This approach more effectively despeckles and manages the relationship between pixels while reducing bias effects caused by convex constraints. Subsequently, we solve the compound regularization model using the Alternating Direction Method of Multipliers (ADMM) algorithm and unfold it into a Deep Unfolded Network (DUN). The network's parameters are adaptively learned in a data-driven manner, and the learned network significantly increases imaging speed. Additionally, the Deep Unfolded Network is compatible with high-resolution imaging modes such as spotlight, staring spotlight, and sliding spotlight. In this paper, we demonstrate the superiority of SPHR-SAR-Net through experiments in both simulated and real SAR scenarios. The results indicate that SPHR-SAR-Net can rapidly perform high-resolution SAR imaging from raw echo data, producing accurate imaging results.
DeFeeNet: Consecutive 3D Human Motion Prediction with Deviation Feedback
Apr 10, 2023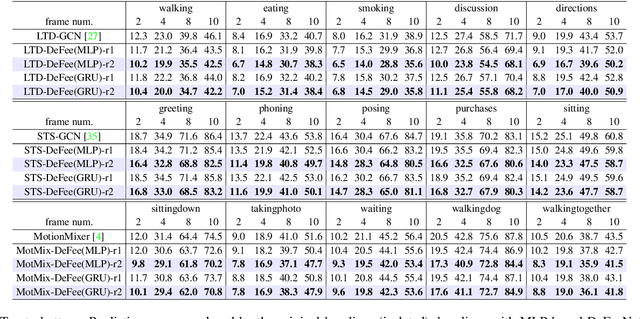

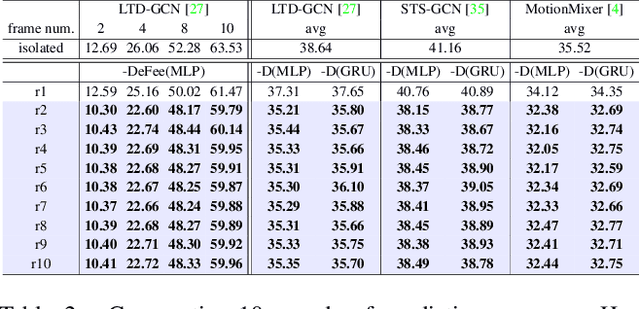
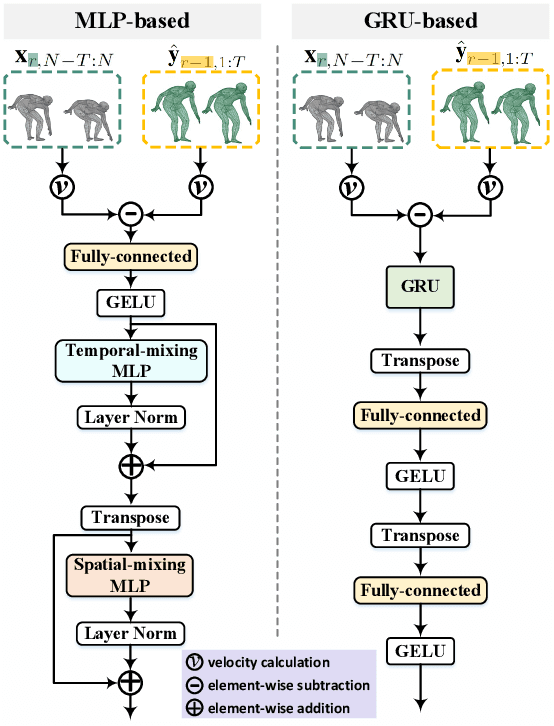
Let us rethink the real-world scenarios that require human motion prediction techniques, such as human-robot collaboration. Current works simplify the task of predicting human motions into a one-off process of forecasting a short future sequence (usually no longer than 1 second) based on a historical observed one. However, such simplification may fail to meet practical needs due to the neglect of the fact that motion prediction in real applications is not an isolated ``observe then predict'' unit, but a consecutive process composed of many rounds of such unit, semi-overlapped along the entire sequence. As time goes on, the predicted part of previous round has its corresponding ground truth observable in the new round, but their deviation in-between is neither exploited nor able to be captured by existing isolated learning fashion. In this paper, we propose DeFeeNet, a simple yet effective network that can be added on existing one-off prediction models to realize deviation perception and feedback when applied to consecutive motion prediction task. At each prediction round, the deviation generated by previous unit is first encoded by our DeFeeNet, and then incorporated into the existing predictor to enable a deviation-aware prediction manner, which, for the first time, allows for information transmit across adjacent prediction units. We design two versions of DeFeeNet as MLP-based and GRU-based, respectively. On Human3.6M and more complicated BABEL, experimental results indicate that our proposed network improves consecutive human motion prediction performance regardless of the basic model.