 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
EEGSN: Towards Efficient Low-latency Decoding of EEG with Graph Spiking Neural Networks
Apr 18, 2023
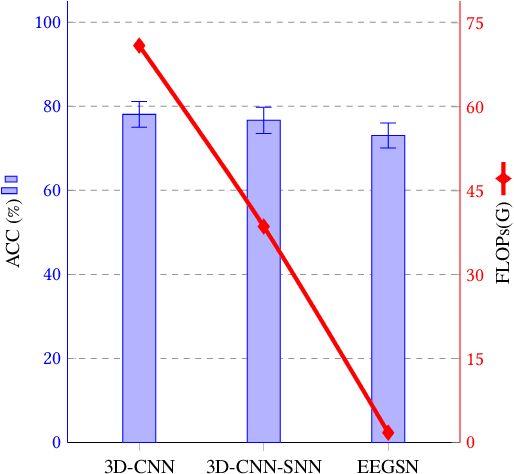
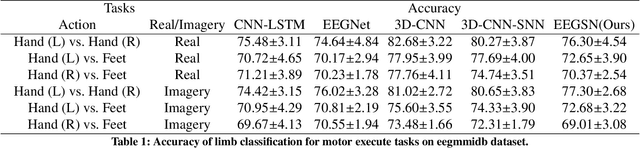
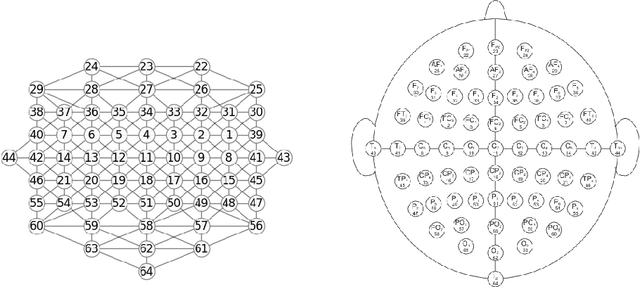
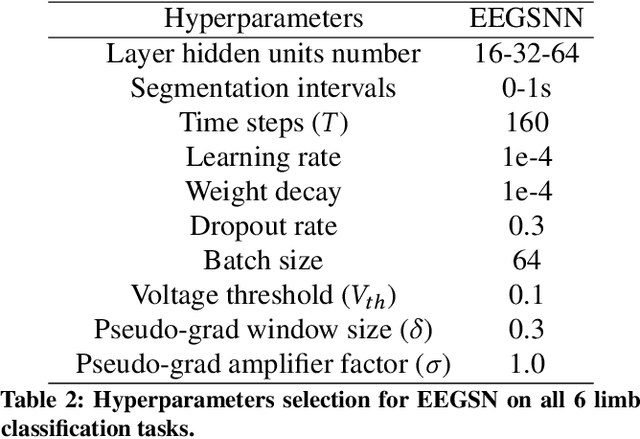
A vast majority of spiking neural networks (SNNs) are trained based on inductive biases that are not necessarily a good fit for several critical tasks that require low-latency and power efficiency. Inferring brain behavior based on the associated electroenchephalography (EEG) signals is an example of how networks training and inference efficiency can be heavily impacted by learning spatio-temporal dependencies. Up to now, SNNs rely solely on general inductive biases to model the dynamic relations between different data streams. Here, we propose a graph spiking neural network architecture for multi-channel EEG classification (EEGSN) that learns the dynamic relational information present in the distributed EEG sensors. Our method reduced the inference computational complexity by $\times 20$ compared to the state-of-the-art SNNs, while achieved comparable accuracy on motor execution classification tasks. Overall, our work provides a framework for interpretable and efficient training of graph spiking networks that are suitable for low-latency and low-power real-time applications.
Federated Alternate Training (FAT): Leveraging Unannotated Data Silos in Federated Segmentation for Medical Imaging
Apr 18, 2023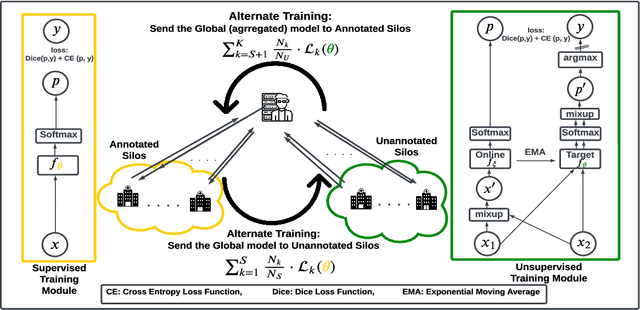
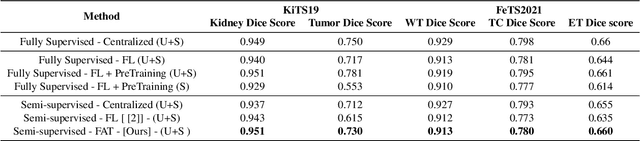
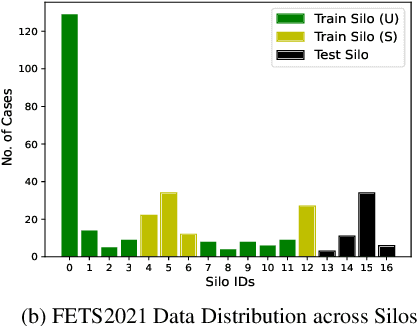
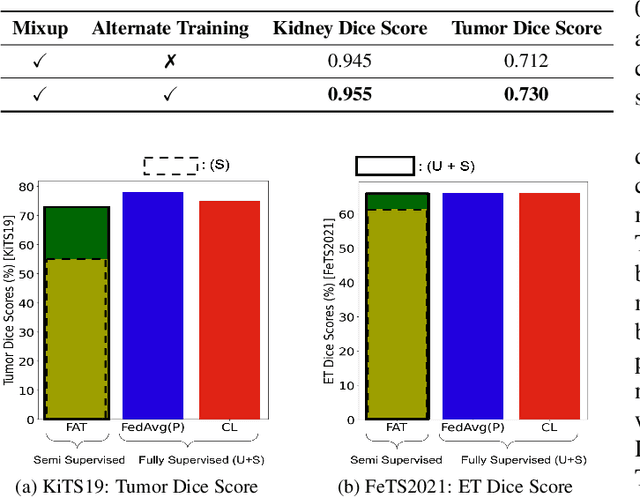
Federated Learning (FL) aims to train a machine learning (ML) model in a distributed fashion to strengthen data privacy with limited data migration costs. It is a distributed learning framework naturally suitable for privacy-sensitive medical imaging datasets. However, most current FL-based medical imaging works assume silos have ground truth labels for training. In practice, label acquisition in the medical field is challenging as it often requires extensive labor and time costs. To address this challenge and leverage the unannotated data silos to improve modeling, we propose an alternate training-based framework, Federated Alternate Training (FAT), that alters training between annotated data silos and unannotated data silos. Annotated data silos exploit annotations to learn a reasonable global segmentation model. Meanwhile, unannotated data silos use the global segmentation model as a target model to generate pseudo labels for self-supervised learning. We evaluate the performance of the proposed framework on two naturally partitioned Federated datasets, KiTS19 and FeTS2021, and show its promising performance.
DeepGEMM: Accelerated Ultra Low-Precision Inference on CPU Architectures using Lookup Tables
Apr 18, 2023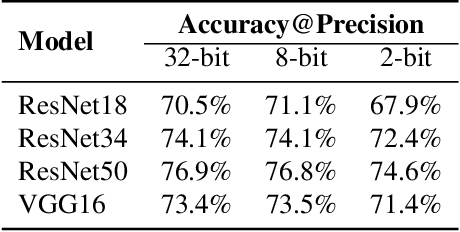
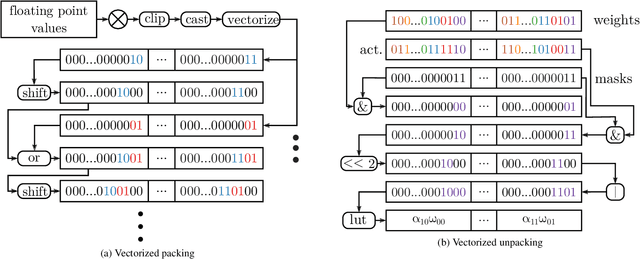
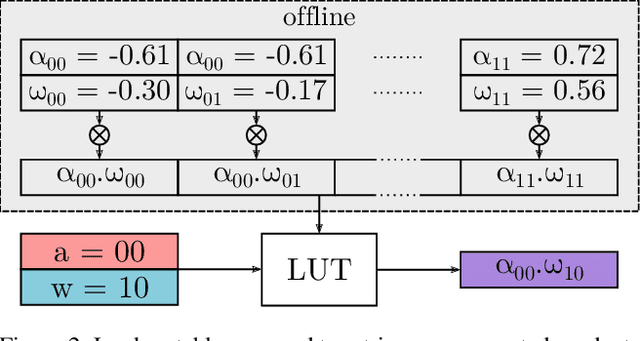

A lot of recent progress has been made in ultra low-bit quantization, promising significant improvements in latency, memory footprint and energy consumption on edge devices. Quantization methods such as Learned Step Size Quantization can achieve model accuracy that is comparable to full-precision floating-point baselines even with sub-byte quantization. However, it is extremely challenging to deploy these ultra low-bit quantized models on mainstream CPU devices because commodity SIMD (Single Instruction, Multiple Data) hardware typically supports no less than 8-bit precision. To overcome this limitation, we propose DeepGEMM, a lookup table based approach for the execution of ultra low-precision convolutional neural networks on SIMD hardware. The proposed method precomputes all possible products of weights and activations, stores them in a lookup table, and efficiently accesses them at inference time to avoid costly multiply-accumulate operations. Our 2-bit implementation outperforms corresponding 8-bit integer kernels in the QNNPACK framework by up to 1.74x on x86 platforms.
Full-Duplex Wireless for 6G: Progress Brings New Opportunities and Challenges
Apr 18, 2023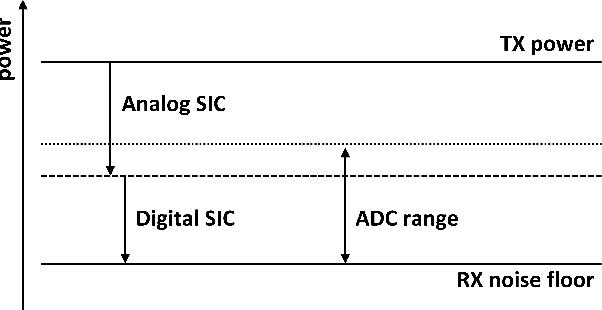
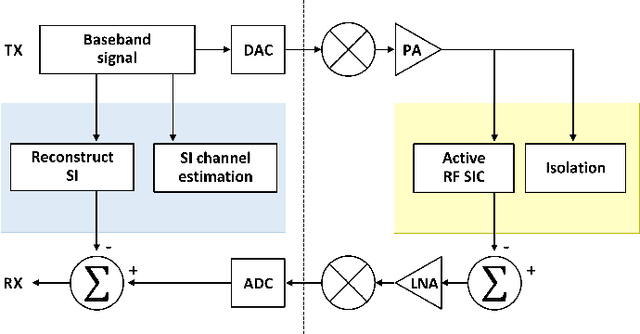
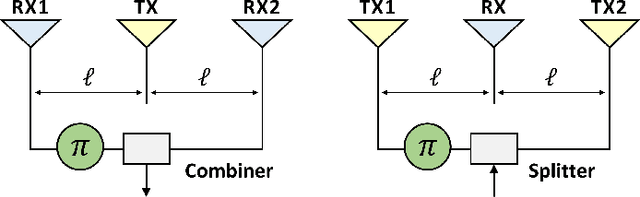
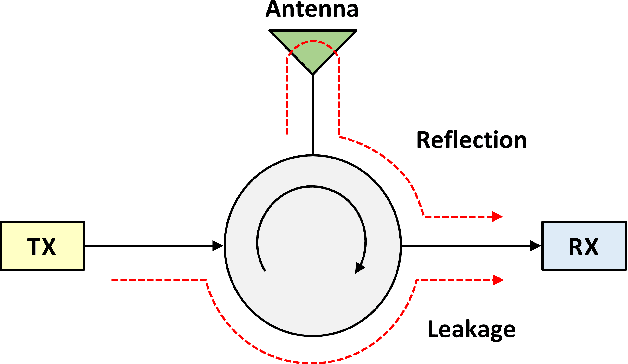
The use of in-band full-duplex (FD) enables nodes to simultaneously transmit and receive on the same frequency band, which challenges the traditional assumption in wireless network design. The full-duplex capability enhances spectral efficiency and decreases latency, which are two key drivers pushing the performance expectations of next-generation mobile networks. In less than ten years, in-band FD has advanced from being demonstrated in research labs to being implemented in standards and products, presenting new opportunities to utilize its foundational concepts. Some of the most significant opportunities include using FD to enable wireless networks to sense the physical environment, integrate sensing and communication applications, develop integrated access and backhaul solutions, and work with smart signal propagation environments powered by reconfigurable intelligent surfaces. However, these new opportunities also come with new challenges for large-scale commercial deployment of FD technology, such as managing self-interference, combating cross-link interference in multi-cell networks, and coexistence of dynamic time division duplex, subband FD and FD networks.
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality
Apr 28, 2023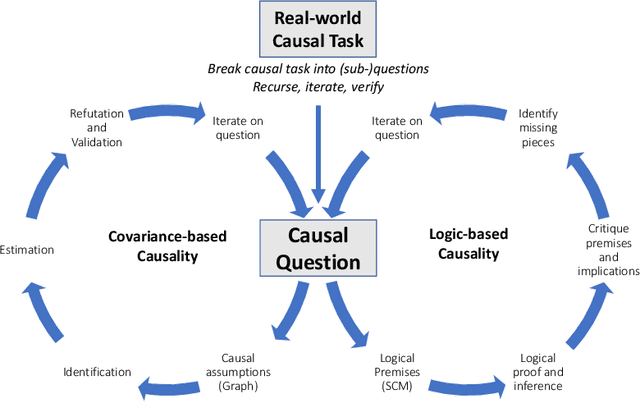
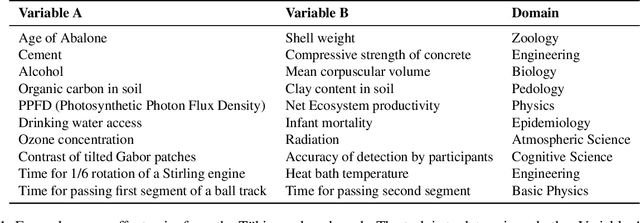

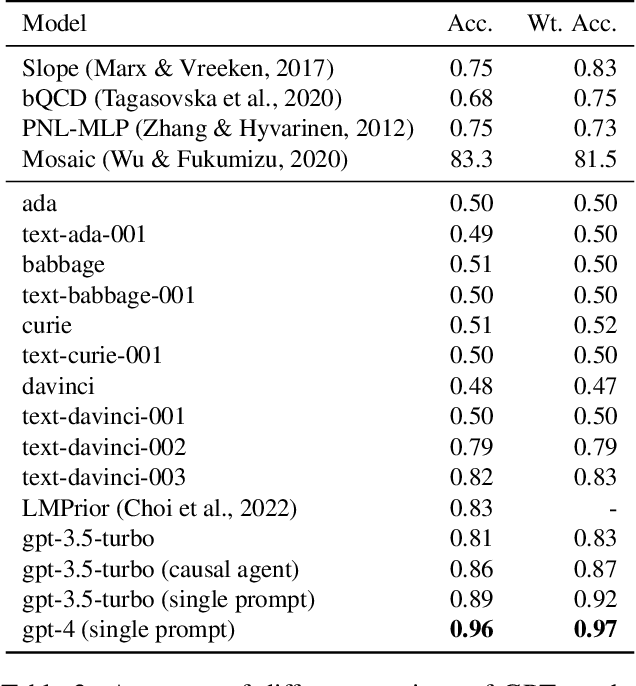
The causal capabilities of large language models (LLMs) is a matter of significant debate, with critical implications for the use of LLMs in societally impactful domains such as medicine, science, law, and policy. We further our understanding of LLMs and their causal implications, considering the distinctions between different types of causal reasoning tasks, as well as the entangled threats of construct and measurement validity. LLM-based methods establish new state-of-the-art accuracies on multiple causal benchmarks. Algorithms based on GPT-3.5 and 4 outperform existing algorithms on a pairwise causal discovery task (97%, 13 points gain), counterfactual reasoning task (92%, 20 points gain), and actual causality (86% accuracy in determining necessary and sufficient causes in vignettes). At the same time, LLMs exhibit unpredictable failure modes and we provide some techniques to interpret their robustness. Crucially, LLMs perform these causal tasks while relying on sources of knowledge and methods distinct from and complementary to non-LLM based approaches. Specifically, LLMs bring capabilities so far understood to be restricted to humans, such as using collected knowledge to generate causal graphs or identifying background causal context from natural language. We envision LLMs to be used alongside existing causal methods, as a proxy for human domain knowledge and to reduce human effort in setting up a causal analysis, one of the biggest impediments to the widespread adoption of causal methods. We also see existing causal methods as promising tools for LLMs to formalize, validate, and communicate their reasoning especially in high-stakes scenarios. In capturing common sense and domain knowledge about causal mechanisms and supporting translation between natural language and formal methods, LLMs open new frontiers for advancing the research, practice, and adoption of causality.
Contactless hand tremor amplitude measurement using smartphones: development and pilot evaluation
Apr 28, 2023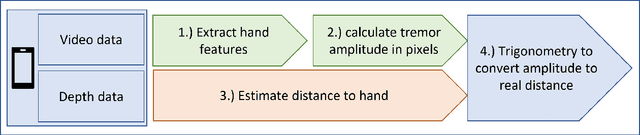
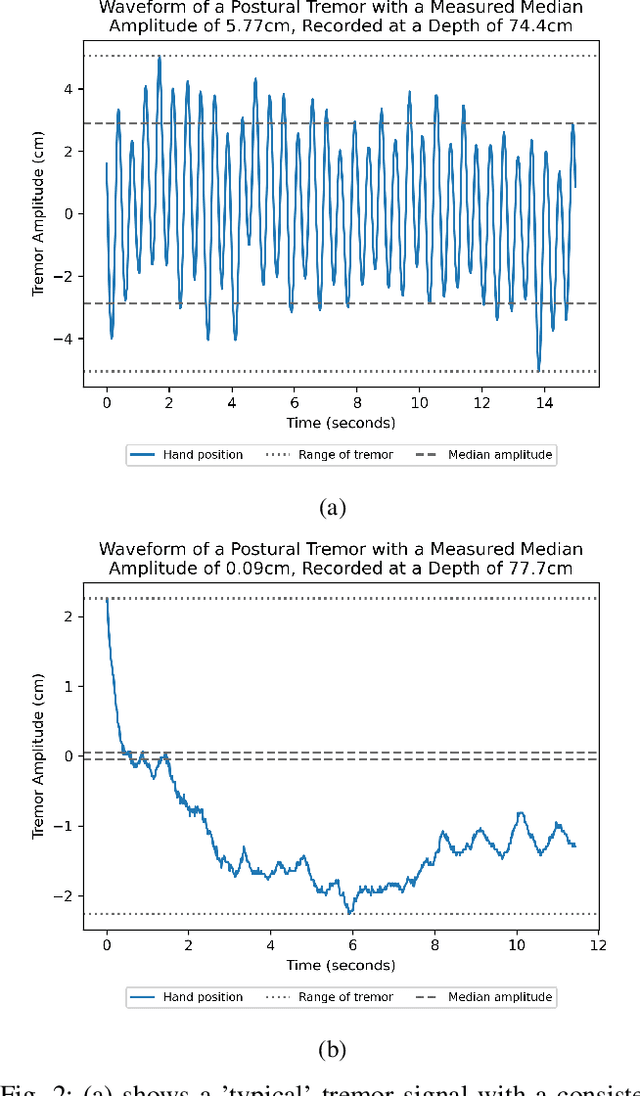

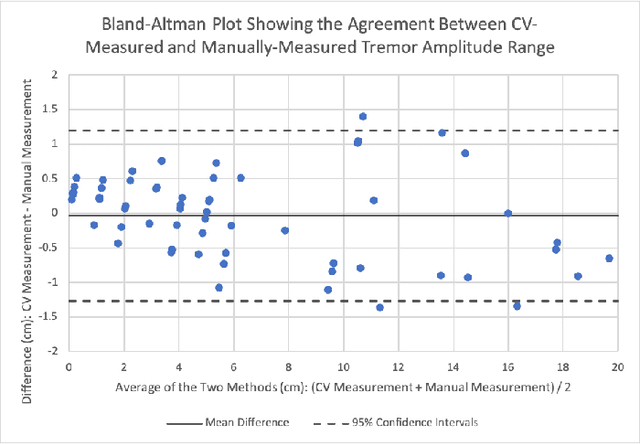
Background: Physiological tremor is defined as an involuntary and rhythmic shaking. Tremor of the hand is a key symptom of multiple neurological diseases, and its frequency and amplitude differs according to both disease type and disease progression. In routine clinical practice, tremor frequency and amplitude are assessed by expert rating using a 0 to 4 integer scale. Such ratings are subjective and have poor inter-rater reliability. There is thus a clinical need for a practical and accurate method for objectively assessing hand tremor. Objective: to develop a proof of principle method to measure hand tremor amplitude from smartphone videos. Methods: We created a computer vision pipeline that automatically extracts salient points on the hand and produces a 1-D time series of movement due to tremor, in pixels. Using the smartphones' depth measurement, we convert this measure into real distance units. We assessed the accuracy of the method using 60 videos of simulated tremor of different amplitudes from two healthy adults. Videos were taken at distances of 50, 75 and 100 cm between hand and camera. The participants had skin tone II and VI on the Fitzpatrick scale. We compared our method to a gold-standard measurement from a slide rule. Bland-Altman methods agreement analysis indicated a bias of 0.04 cm and 95% limits of agreement from -1.27 to 1.20 cm. Furthermore, we qualitatively observed that the method was robust to differences in skin tone and limited occlusion, such as a band-aid affixed to the participant's hand. Clinical relevance: We have demonstrated how tremor amplitude can be measured from smartphone videos. In conjunction with tremor frequency, this approach could be used to help diagnose and monitor neurological diseases
GPT-NER: Named Entity Recognition via Large Language Models
Apr 26, 2023
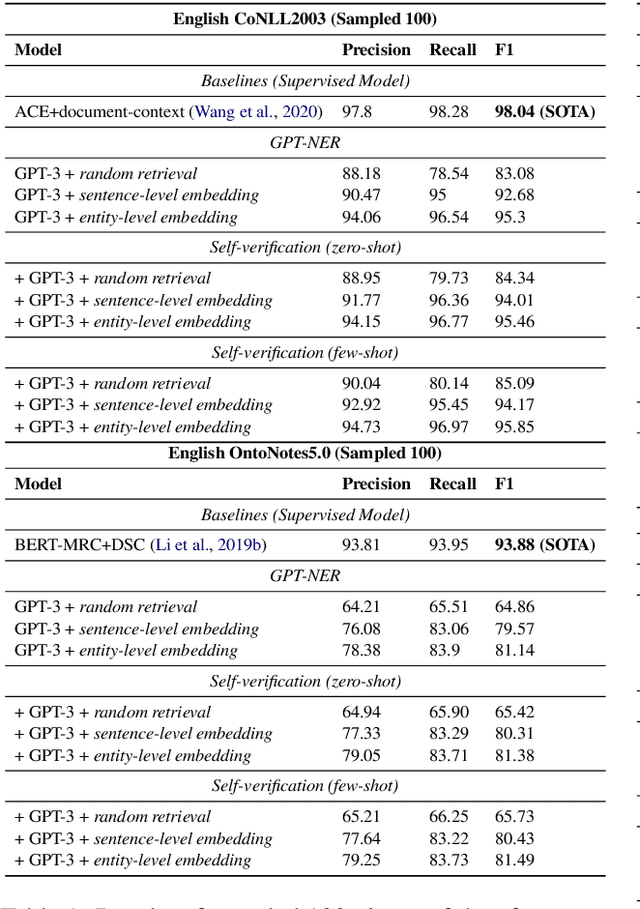
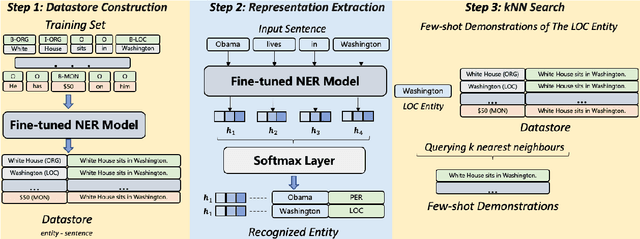
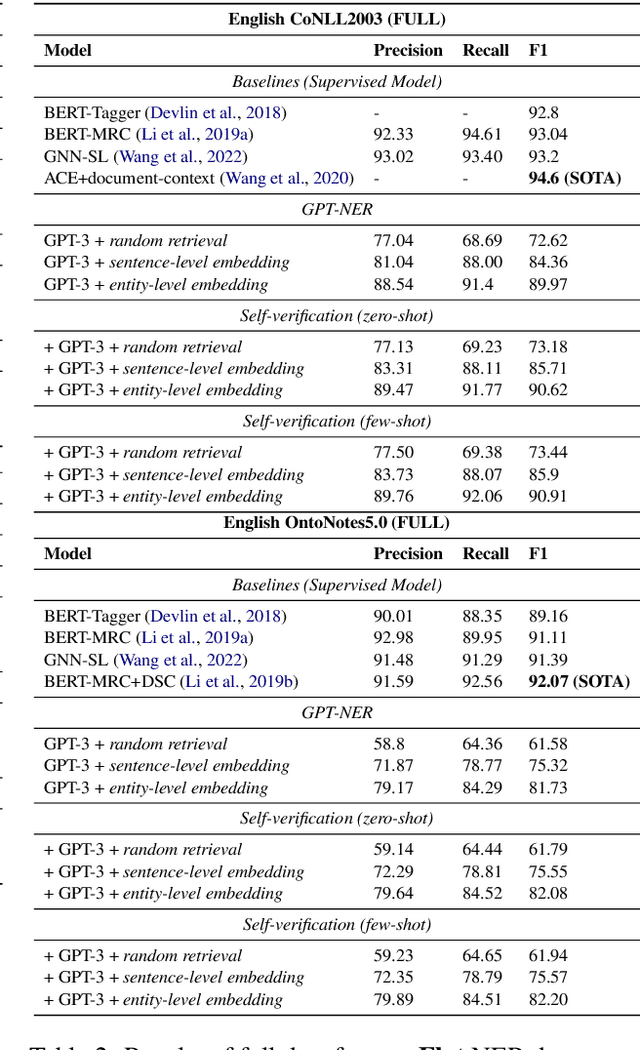
Despite the fact that large-scale Language Models (LLM) have achieved SOTA performances on a variety of NLP tasks, its performance on NER is still significantly below supervised baselines. This is due to the gap between the two tasks the NER and LLMs: the former is a sequence labeling task in nature while the latter is a text-generation model. In this paper, we propose GPT-NER to resolve this issue. GPT-NER bridges the gap by transforming the sequence labeling task to a generation task that can be easily adapted by LLMs e.g., the task of finding location entities in the input text "Columbus is a city" is transformed to generate the text sequence "@@Columbus## is a city", where special tokens @@## marks the entity to extract. To efficiently address the "hallucination" issue of LLMs, where LLMs have a strong inclination to over-confidently label NULL inputs as entities, we propose a self-verification strategy by prompting LLMs to ask itself whether the extracted entities belong to a labeled entity tag. We conduct experiments on five widely adopted NER datasets, and GPT-NER achieves comparable performances to fully supervised baselines, which is the first time as far as we are concerned. More importantly, we find that GPT-NER exhibits a greater ability in the low-resource and few-shot setups, when the amount of training data is extremely scarce, GPT-NER performs significantly better than supervised models. This demonstrates the capabilities of GPT-NER in real-world NER applications where the number of labeled examples is limited.
SSTM: Spatiotemporal Recurrent Transformers for Multi-frame Optical Flow Estimation
Apr 26, 2023

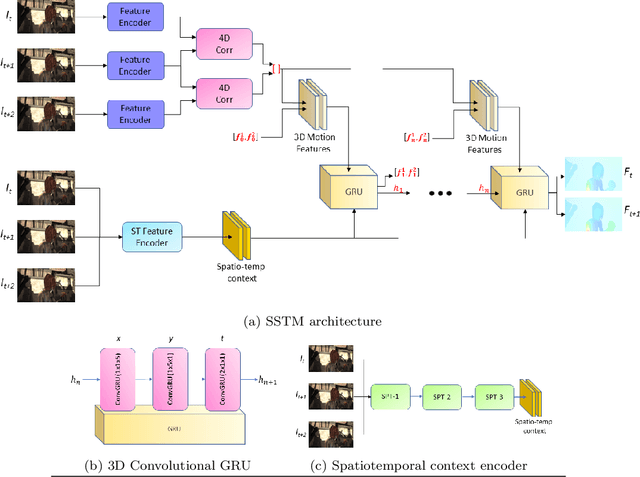
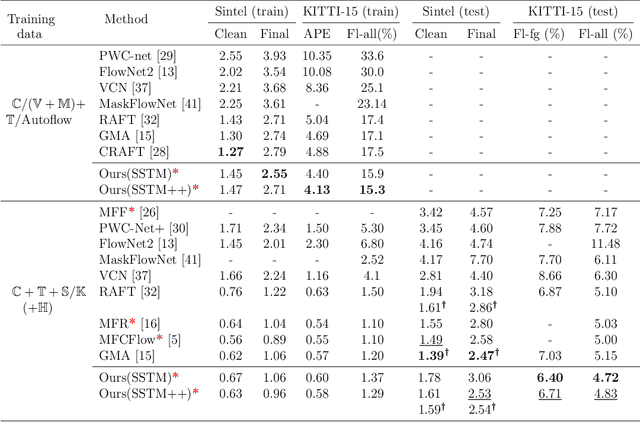
Inaccurate optical flow estimates in and near occluded regions, and out-of-boundary regions are two of the current significant limitations of optical flow estimation algorithms. Recent state-of-the-art optical flow estimation algorithms are two-frame based methods where optical flow is estimated sequentially for each consecutive image pair in a sequence. While this approach gives good flow estimates, it fails to generalize optical flows in occluded regions mainly due to limited local evidence regarding moving elements in a scene. In this work, we propose a learning-based multi-frame optical flow estimation method that estimates two or more consecutive optical flows in parallel from multi-frame image sequences. Our underlying hypothesis is that by understanding temporal scene dynamics from longer sequences with more than two frames, we can characterize pixel-wise dependencies in a larger spatiotemporal domain, generalize complex motion patterns and thereby improve the accuracy of optical flow estimates in occluded regions. We present learning-based spatiotemporal recurrent transformers for multi-frame based optical flow estimation (SSTMs). Our method utilizes 3D Convolutional Gated Recurrent Units (3D-ConvGRUs) and spatiotemporal transformers to learn recurrent space-time motion dynamics and global dependencies in the scene and provide a generalized optical flow estimation. When compared with recent state-of-the-art two-frame and multi-frame methods on real world and synthetic datasets, performance of the SSTMs were significantly higher in occluded and out-of-boundary regions. Among all published state-of-the-art multi-frame methods, SSTM achieved state-of the-art results on the Sintel Final and KITTI2015 benchmark datasets.
Performance Optimization using Multimodal Modeling and Heterogeneous GNN
Apr 27, 2023

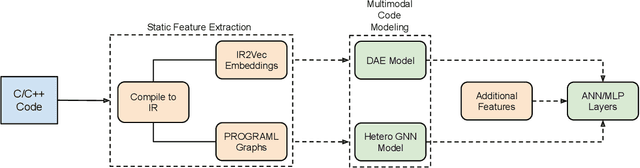
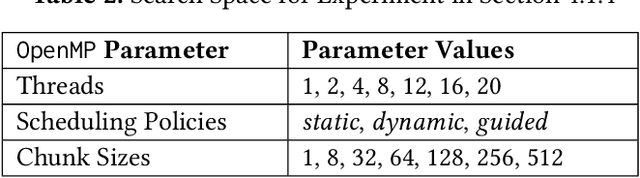
Growing heterogeneity and configurability in HPC architectures has made auto-tuning applications and runtime parameters on these systems very complex. Users are presented with a multitude of options to configure parameters. In addition to application specific solutions, a common approach is to use general purpose search strategies, which often might not identify the best configurations or their time to convergence is a significant barrier. There is, thus, a need for a general purpose and efficient tuning approach that can be easily scaled and adapted to various tuning tasks. We propose a technique for tuning parallel code regions that is general enough to be adapted to multiple tasks. In this paper, we analyze IR-based programming models to make task-specific performance optimizations. To this end, we propose the Multimodal Graph Neural Network and Autoencoder (MGA) tuner, a multimodal deep learning based approach that adapts Heterogeneous Graph Neural Networks and Denoizing Autoencoders for modeling IR-based code representations that serve as separate modalities. This approach is used as part of our pipeline to model a syntax, semantics, and structure-aware IR-based code representation for tuning parallel code regions/kernels. We extensively experiment on OpenMP and OpenCL code regions/kernels obtained from PolyBench, Rodinia, STREAM, DataRaceBench, AMD SDK, NPB, NVIDIA SDK, Parboil, SHOC, and LULESH benchmarks. We apply our multimodal learning techniques to the tasks of i) optimizing the number of threads, scheduling policy and chunk size in OpenMP loops and, ii) identifying the best device for heterogeneous device mapping of OpenCL kernels. Our experiments show that this multimodal learning based approach outperforms the state-of-the-art in all experiments.
Robust Mean Teacher for Continual and Gradual Test-Time Adaptation
Nov 23, 2022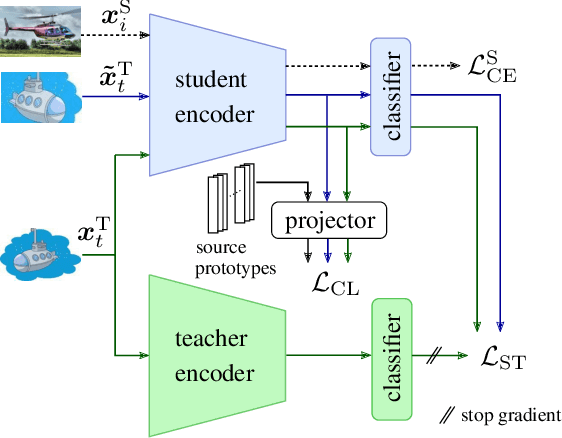
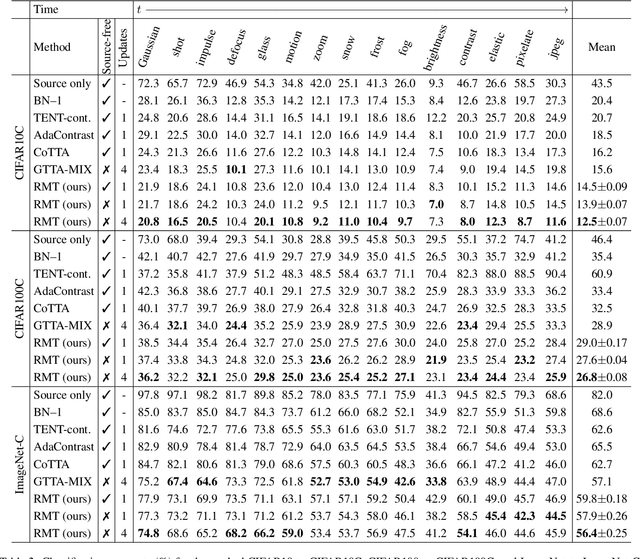
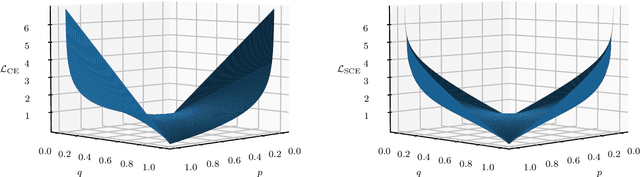
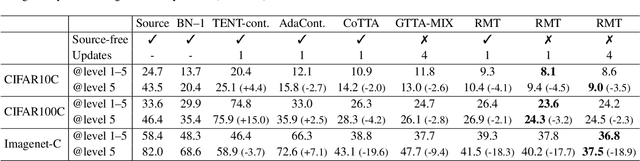
Since experiencing domain shifts during test-time is inevitable in practice, test-time adaption (TTA) continues to adapt the model during deployment. Recently, the area of continual and gradual test-time adaptation (TTA) emerged. In contrast to standard TTA, continual TTA considers not only a single domain shift, but a sequence of shifts. Gradual TTA further exploits the property that some shifts evolve gradually over time. Since in both settings long test sequences are present, error accumulation needs to be addressed for methods relying on self-training. In this work, we propose and show that in the setting of TTA, the symmetric cross-entropy is better suited as a consistency loss for mean teachers compared to the commonly used cross-entropy. This is justified by our analysis with respect to the (symmetric) cross-entropy's gradient properties. To pull the test feature space closer to the source domain, where the pre-trained model is well posed, contrastive learning is leveraged. Since applications differ in their requirements, we address different settings, namely having source data available and the more challenging source-free setting. We demonstrate the effectiveness of our proposed method 'robust mean teacher' (RMT) on the continual and gradual corruption benchmarks CIFAR10C, CIFAR100C, and Imagenet-C. We further consider ImageNet-R and propose a new continual DomainNet-126 benchmark. State-of-the-art results are achieved on all benchmarks.