 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-aware Random Walk Diffusion to Improve Dynamic Graph Learning
Nov 04, 2022
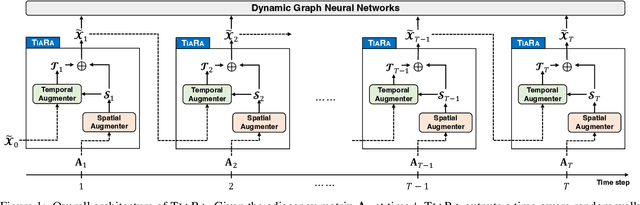
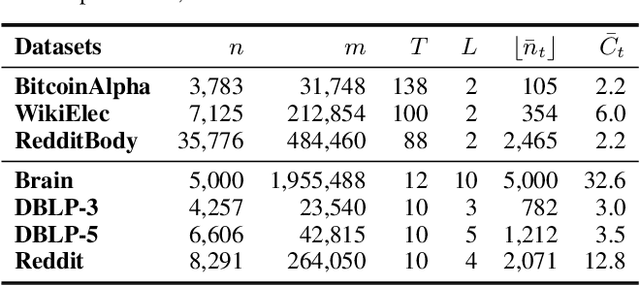
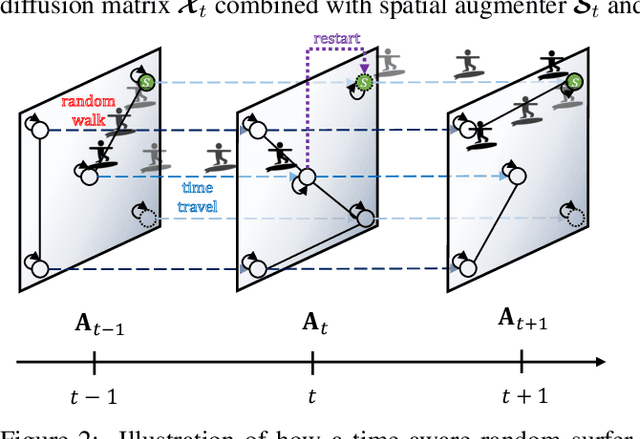
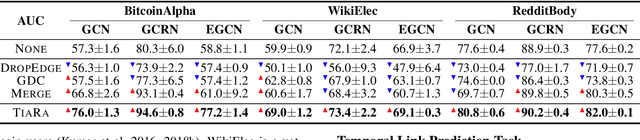
How can we augment a dynamic graph for improving the performance of dynamic graph neural networks? Graph augmentation has been widely utilized to boost the learning performance of GNN-based models. However, most existing approaches only enhance spatial structure within an input static graph by transforming the graph, and do not consider dynamics caused by time such as temporal locality, i.e., recent edges are more influential than earlier ones, which remains challenging for dynamic graph augmentation. In this work, we propose TiaRa (Time-aware Random Walk Diffusion), a novel diffusion-based method for augmenting a dynamic graph represented as a discrete-time sequence of graph snapshots. For this purpose, we first design a time-aware random walk proximity so that a surfer can walk along the time dimension as well as edges, resulting in spatially and temporally localized scores. We then derive our diffusion matrices based on the time-aware random walk, and show they become enhanced adjacency matrices that both spatial and temporal localities are augmented. Throughout extensive experiments, we demonstrate that TiaRa effectively augments a given dynamic graph, and leads to significant improvements in dynamic GNN models for various graph datasets and tasks.
GPT-NER: Named Entity Recognition via Large Language Models
Apr 20, 2023
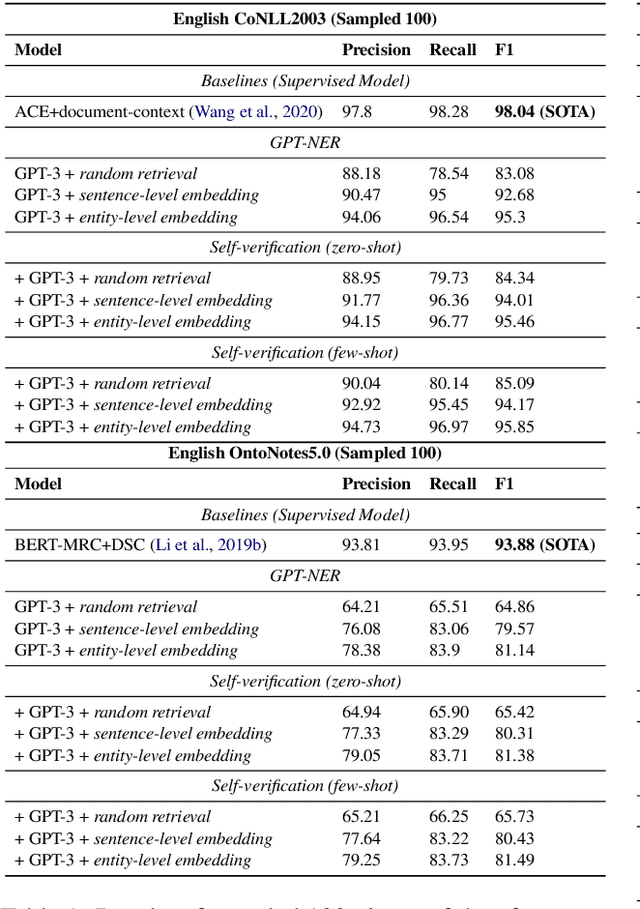
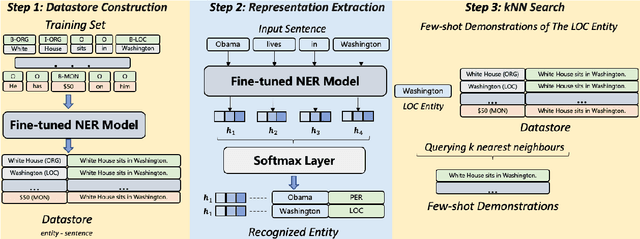
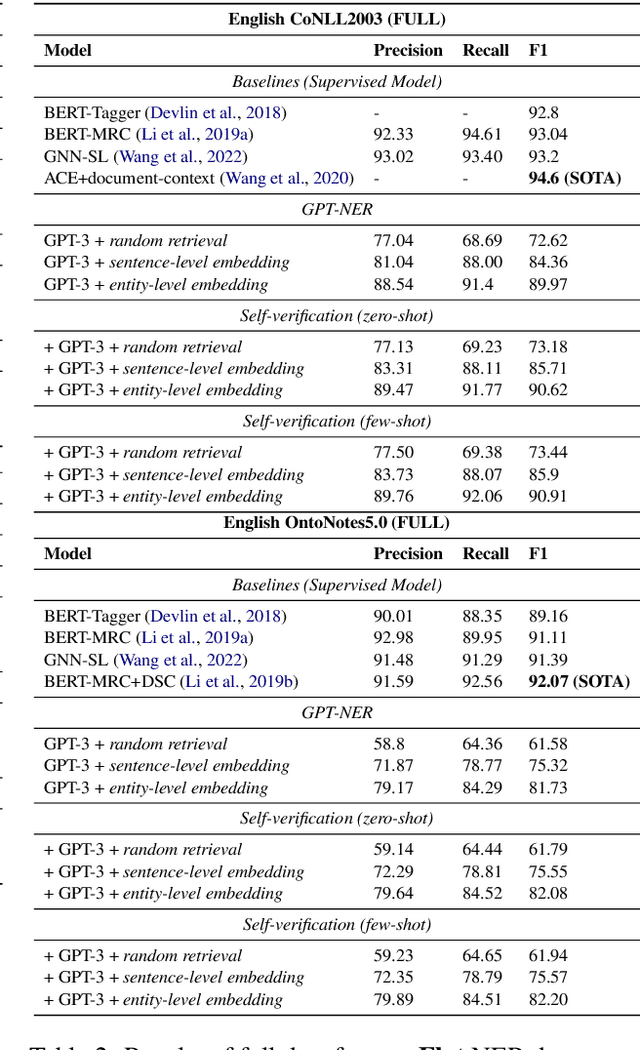
Despite the fact that large-scale Language Models (LLM) have achieved SOTA performances on a variety of NLP tasks, its performance on NER is still significantly below supervised baselines. This is due to the gap between the two tasks the NER and LLMs: the former is a sequence labeling task in nature while the latter is a text-generation model. In this paper, we propose GPT-NER to resolve this issue. GPT-NER bridges the gap by transforming the sequence labeling task to a generation task that can be easily adapted by LLMs e.g., the task of finding location entities in the input text "Columbus is a city" is transformed to generate the text sequence "@@Columbus## is a city", where special tokens @@## marks the entity to extract. To efficiently address the "hallucination" issue of LLMs, where LLMs have a strong inclination to over-confidently label NULL inputs as entities, we propose a self-verification strategy by prompting LLMs to ask itself whether the extracted entities belong to a labeled entity tag. We conduct experiments on five widely adopted NER datasets, and GPT-NER achieves comparable performances to fully supervised baselines, which is the first time as far as we are concerned. More importantly, we find that GPT-NER exhibits a greater ability in the low-resource and few-shot setups, when the amount of training data is extremely scarce, GPT-NER performs significantly better than supervised models. This demonstrates the capabilities of GPT-NER in real-world NER applications where the number of labeled examples is limited.
"HOT" ChatGPT: The promise of ChatGPT in detecting and discriminating hateful, offensive, and toxic comments on social media
Apr 20, 2023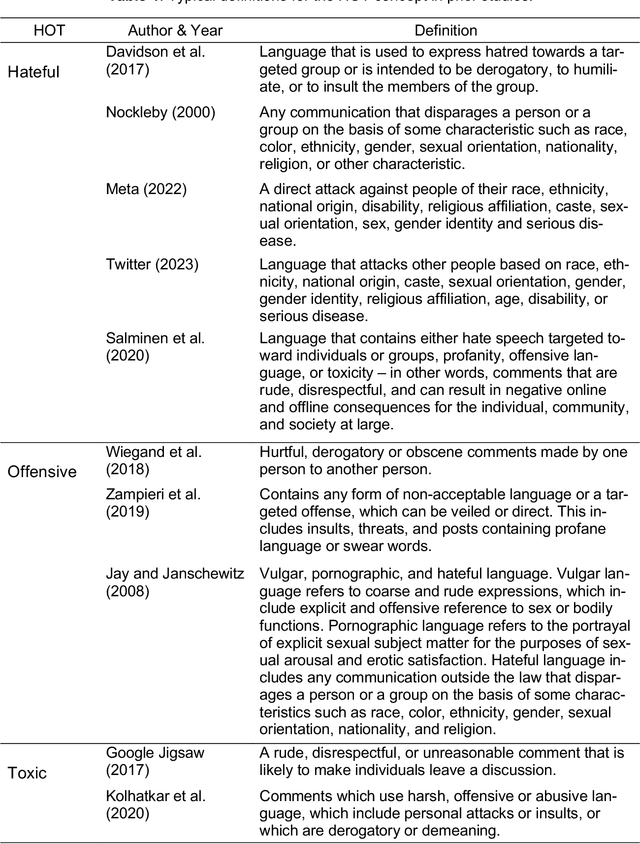
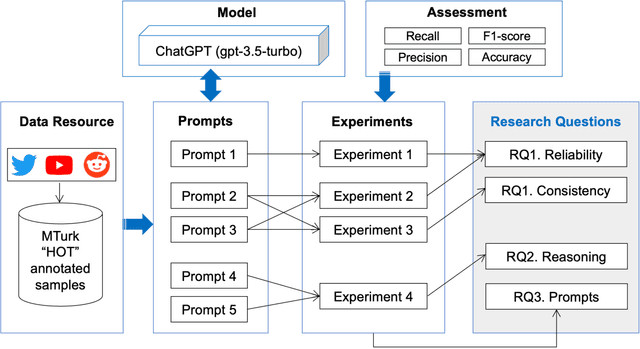
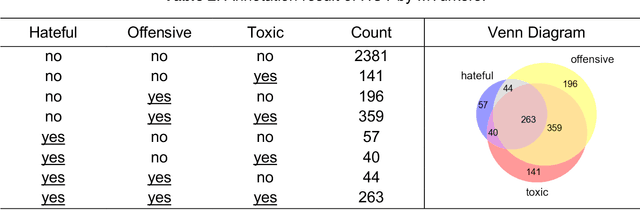
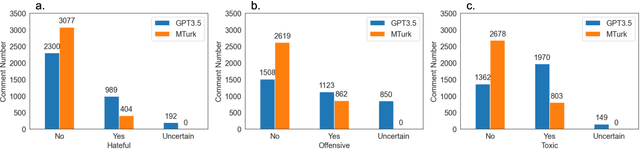
Harmful content is pervasive on social media, poisoning online communities and negatively impacting participation. A common approach to address this issue is to develop detection models that rely on human annotations. However, the tasks required to build such models expose annotators to harmful and offensive content and may require significant time and cost to complete. Generative AI models have the potential to understand and detect harmful content. To investigate this potential, we used ChatGPT and compared its performance with MTurker annotations for three frequently discussed concepts related to harmful content: Hateful, Offensive, and Toxic (HOT). We designed five prompts to interact with ChatGPT and conducted four experiments eliciting HOT classifications. Our results show that ChatGPT can achieve an accuracy of approximately 80% when compared to MTurker annotations. Specifically, the model displays a more consistent classification for non-HOT comments than HOT comments compared to human annotations. Our findings also suggest that ChatGPT classifications align with provided HOT definitions, but ChatGPT classifies "hateful" and "offensive" as subsets of "toxic." Moreover, the choice of prompts used to interact with ChatGPT impacts its performance. Based on these in-sights, our study provides several meaningful implications for employing ChatGPT to detect HOT content, particularly regarding the reliability and consistency of its performance, its understand-ing and reasoning of the HOT concept, and the impact of prompts on its performance. Overall, our study provides guidance about the potential of using generative AI models to moderate large volumes of user-generated content on social media.
The e-Bike Motor Assembly: Towards Advanced Robotic Manipulation for Flexible Manufacturing
Apr 20, 2023
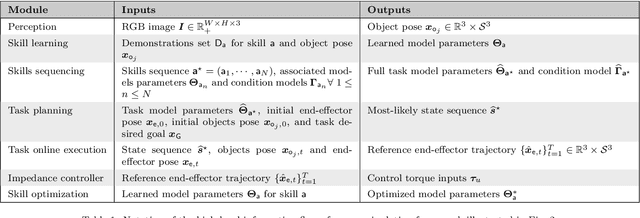
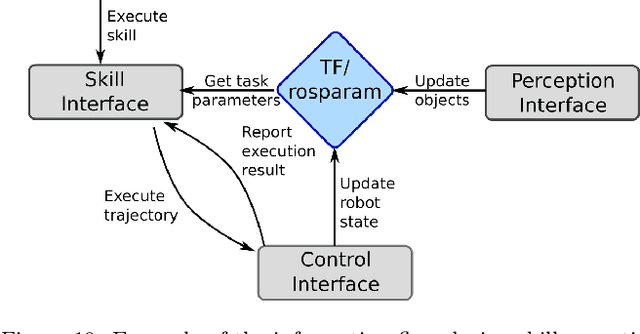
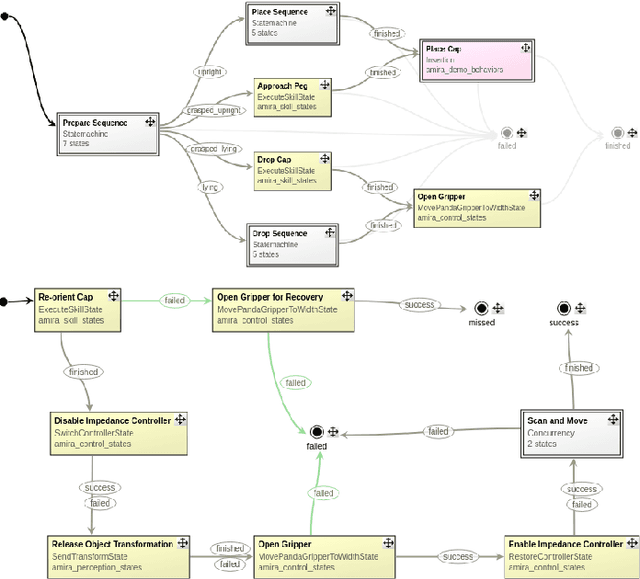
Robotic manipulation is currently undergoing a profound paradigm shift due to the increasing needs for flexible manufacturing systems, and at the same time, because of the advances in enabling technologies such as sensing, learning, optimization, and hardware. This demands for robots that can observe and reason about their workspace, and that are skillfull enough to complete various assembly processes in weakly-structured settings. Moreover, it remains a great challenge to enable operators for teaching robots on-site, while managing the inherent complexity of perception, control, motion planning and reaction to unexpected situations. Motivated by real-world industrial applications, this paper demonstrates the potential of such a paradigm shift in robotics on the industrial case of an e-Bike motor assembly. The paper presents a concept for teaching and programming adaptive robots on-site and demonstrates their potential for the named applications. The framework includes: (i) a method to teach perception systems onsite in a self-supervised manner, (ii) a general representation of object-centric motion skills and force-sensitive assembly skills, both learned from demonstration, (iii) a sequencing approach that exploits a human-designed plan to perform complex tasks, and (iv) a system solution for adapting and optimizing skills online. The aforementioned components are interfaced through a four-layer software architecture that makes our framework a tangible industrial technology. To demonstrate the generality of the proposed framework, we provide, in addition to the motivating e-Bike motor assembly, a further case study on dense box packing for logistics automation.
Search-Map-Search: A Frame Selection Paradigm for Action Recognition
Apr 20, 2023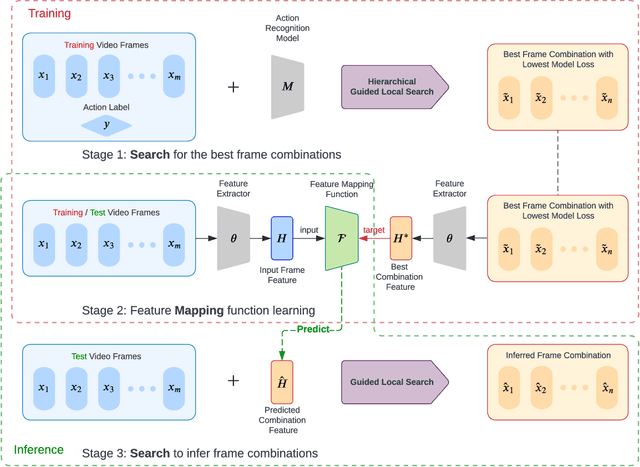


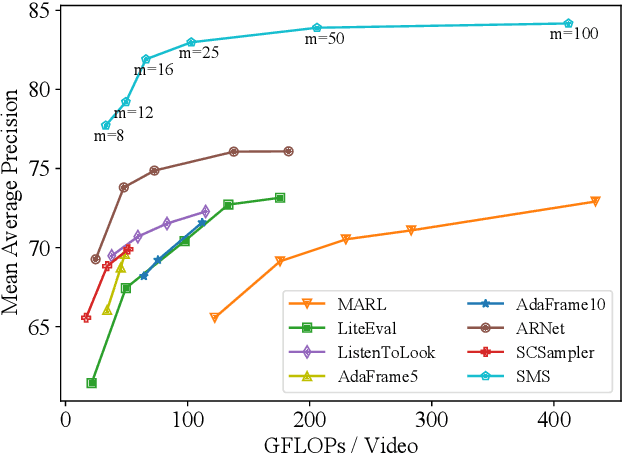
Despite the success of deep learning in video understanding tasks, processing every frame in a video is computationally expensive and often unnecessary in real-time applications. Frame selection aims to extract the most informative and representative frames to help a model better understand video content. Existing frame selection methods either individually sample frames based on per-frame importance prediction, without considering interaction among frames, or adopt reinforcement learning agents to find representative frames in succession, which are costly to train and may lead to potential stability issues. To overcome the limitations of existing methods, we propose a Search-Map-Search learning paradigm which combines the advantages of heuristic search and supervised learning to select the best combination of frames from a video as one entity. By combining search with learning, the proposed method can better capture frame interactions while incurring a low inference overhead. Specifically, we first propose a hierarchical search method conducted on each training video to search for the optimal combination of frames with the lowest error on the downstream task. A feature mapping function is then learned to map the frames of a video to the representation of its target optimal frame combination. During inference, another search is performed on an unseen video to select a combination of frames whose feature representation is close to the projected feature representation. Extensive experiments based on several action recognition benchmarks demonstrate that our frame selection method effectively improves performance of action recognition models, and significantly outperforms a number of competitive baselines.
Auditing and Generating Synthetic Data with Controllable Trust Trade-offs
Apr 21, 2023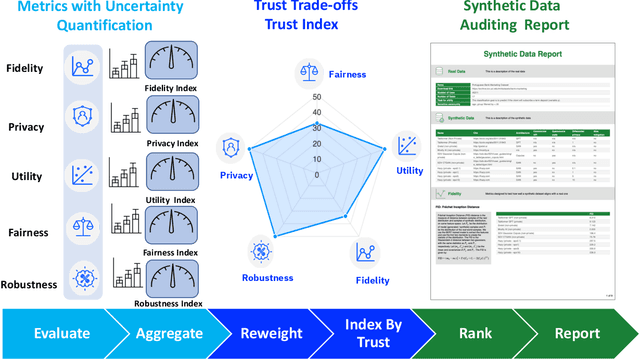
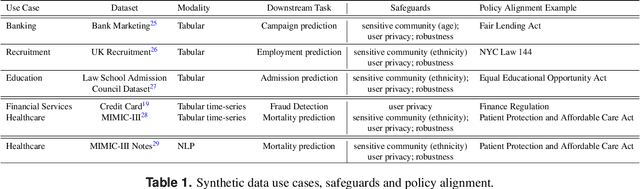
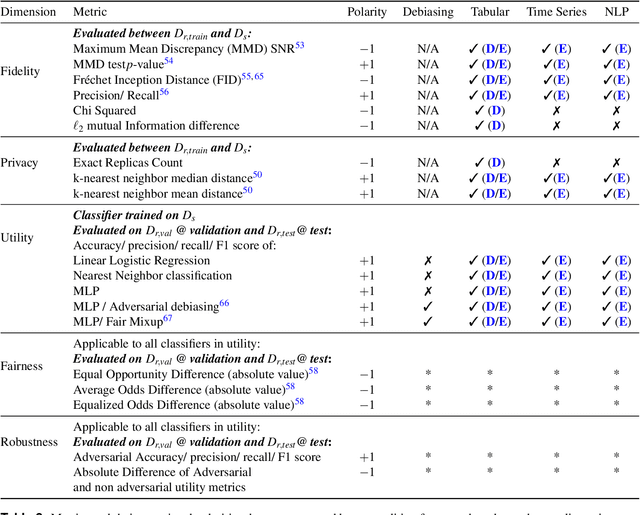
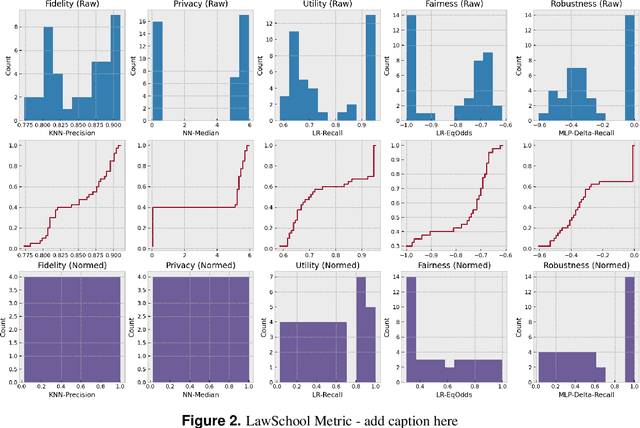
Data collected from the real world tends to be biased, unbalanced, and at risk of exposing sensitive and private information. This reality has given rise to the idea of creating synthetic datasets to alleviate risk, bias, harm, and privacy concerns inherent in the real data. This concept relies on Generative AI models to produce unbiased, privacy-preserving synthetic data while being true to the real data. In this new paradigm, how can we tell if this approach delivers on its promises? We present an auditing framework that offers a holistic assessment of synthetic datasets and AI models trained on them, centered around bias and discrimination prevention, fidelity to the real data, utility, robustness, and privacy preservation. We showcase our framework by auditing multiple generative models on diverse use cases, including education, healthcare, banking, human resources, and across different modalities, from tabular, to time-series, to natural language. Our use cases demonstrate the importance of a holistic assessment in order to ensure compliance with socio-technical safeguards that regulators and policymakers are increasingly enforcing. For this purpose, we introduce the trust index that ranks multiple synthetic datasets based on their prescribed safeguards and their desired trade-offs. Moreover, we devise a trust-index-driven model selection and cross-validation procedure via auditing in the training loop that we showcase on a class of transformer models that we dub TrustFormers, across different modalities. This trust-driven model selection allows for controllable trust trade-offs in the resulting synthetic data. We instrument our auditing framework with workflows that connect different stakeholders from model development to audit and certification via a synthetic data auditing report.
BERT Based Clinical Knowledge Extraction for Biomedical Knowledge Graph Construction and Analysis
Apr 21, 2023
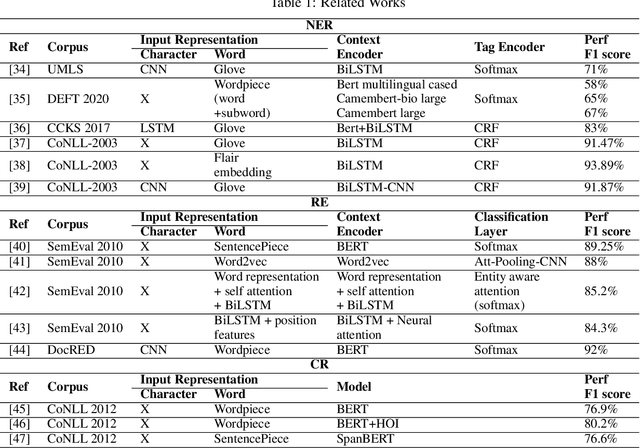
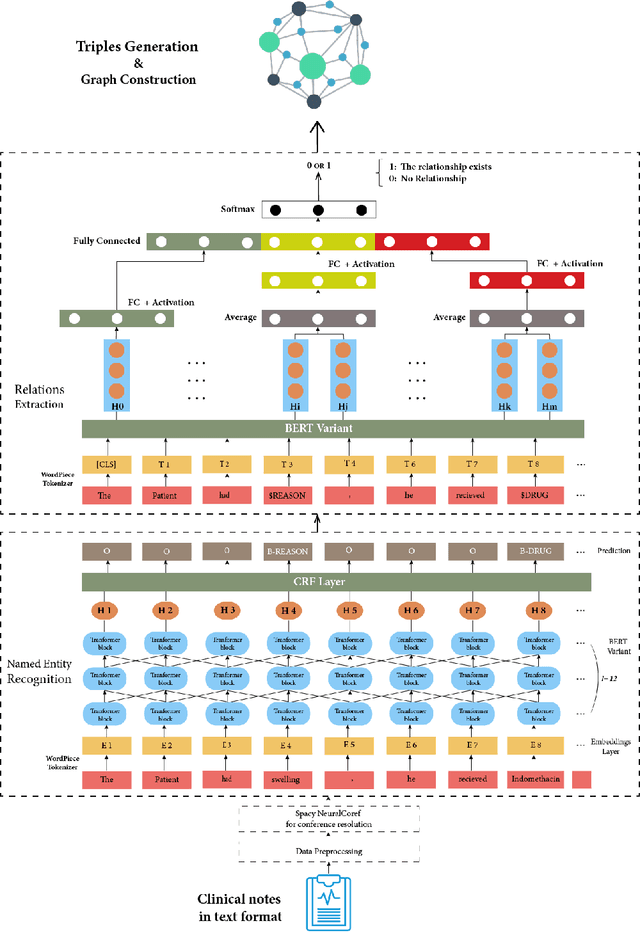
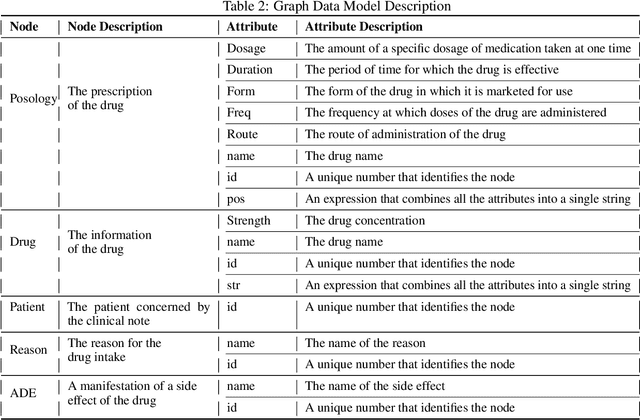
Background : Knowledge is evolving over time, often as a result of new discoveries or changes in the adopted methods of reasoning. Also, new facts or evidence may become available, leading to new understandings of complex phenomena. This is particularly true in the biomedical field, where scientists and physicians are constantly striving to find new methods of diagnosis, treatment and eventually cure. Knowledge Graphs (KGs) offer a real way of organizing and retrieving the massive and growing amount of biomedical knowledge. Objective : We propose an end-to-end approach for knowledge extraction and analysis from biomedical clinical notes using the Bidirectional Encoder Representations from Transformers (BERT) model and Conditional Random Field (CRF) layer. Methods : The approach is based on knowledge graphs, which can effectively process abstract biomedical concepts such as relationships and interactions between medical entities. Besides offering an intuitive way to visualize these concepts, KGs can solve more complex knowledge retrieval problems by simplifying them into simpler representations or by transforming the problems into representations from different perspectives. We created a biomedical Knowledge Graph using using Natural Language Processing models for named entity recognition and relation extraction. The generated biomedical knowledge graphs (KGs) are then used for question answering. Results : The proposed framework can successfully extract relevant structured information with high accuracy (90.7% for Named-entity recognition (NER), 88% for relation extraction (RE)), according to experimental findings based on real-world 505 patient biomedical unstructured clinical notes. Conclusions : In this paper, we propose a novel end-to-end system for the construction of a biomedical knowledge graph from clinical textual using a variation of BERT models.
SmartBook: AI-Assisted Situation Report Generation
Mar 28, 2023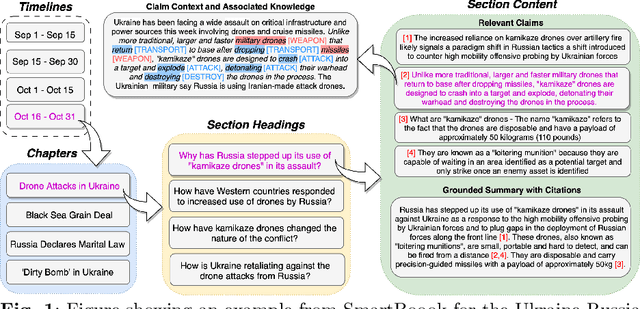
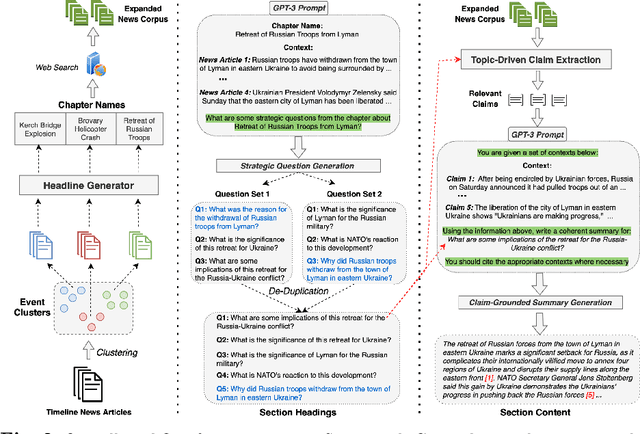


Emerging events, such as the COVID pandemic and the Ukraine Crisis, require a time-sensitive comprehensive understanding of the situation to allow for appropriate decision-making and effective action response. Automated generation of situation reports can significantly reduce the time, effort, and cost for domain experts when preparing their official human-curated reports. However, AI research toward this goal has been very limited, and no successful trials have yet been conducted to automate such report generation. We propose SmartBook, a novel task formulation targeting situation report generation, which consumes large volumes of news data to produce a structured situation report with multiple hypotheses (claims) summarized and grounded with rich links to factual evidence. We realize SmartBook for the Ukraine-Russia crisis by automatically generating intelligence analysis reports to assist expert analysts. The machine-generated reports are structured in the form of timelines, with each timeline organized by major events (or chapters), corresponding strategic questions (or sections) and their grounded summaries (or section content). Our proposed framework automatically detects real-time event-related strategic questions, which are more directed than manually-crafted analyst questions, which tend to be too complex, hard to parse, vague and high-level. Results from thorough qualitative evaluations show that roughly 82% of the questions in Smartbook have strategic importance, with at least 93% of the sections in the report being tactically useful. Further, experiments show that expert analysts tend to add more information into the SmartBook reports, with only 2.3% of the existing tokens being deleted, meaning SmartBook can serve as a useful foundation for analysts to build upon when creating intelligence reports.
Automated Formation Control Synthesis from Temporal Logic Specifications
Apr 01, 2023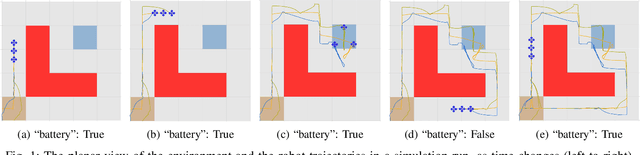
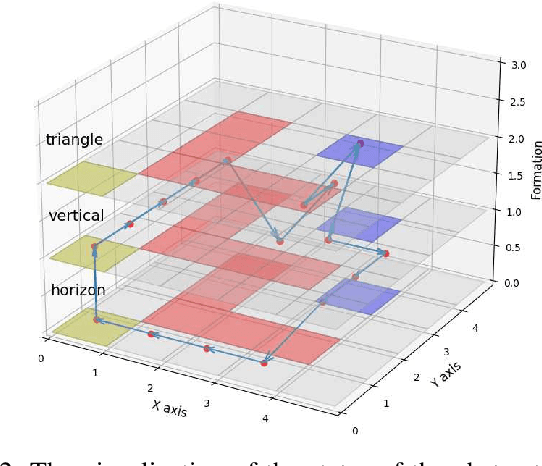
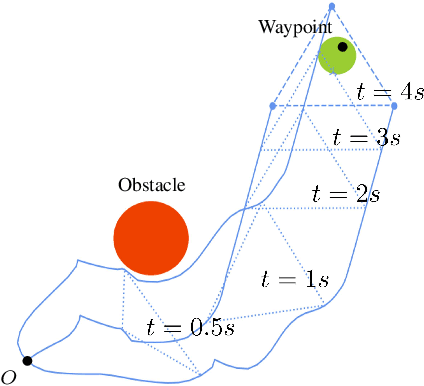
In this paper, we propose a novel framework using formal methods to synthesize a navigation control strategy for a multi-robot swarm system with automated formation. The main objective of the problem is to navigate the robot swarm toward a goal position while passing a series of waypoints. The formation of the robot swarm should be changed according to the terrain restrictions around the corresponding waypoint. Also, the motion of the robots should always satisfy certain runtime safety requirements, such as avoiding collision with other robots and obstacles. We prescribe the desired waypoints and formation for the robot swarm using a temporal logic (TL) specification. Then, we formulate the transition of the waypoints and the formation as a deterministic finite transition system (DFTS) and synthesize a control strategy subject to the TL specification. Meanwhile, the runtime safety requirements are encoded using control barrier functions, and fixed-time control Lyapunov functions ensure fixed-time convergence. A quadratic program (QP) problem is solved to refine the DFTS control strategy to generate the control inputs for the robots, such that both TL specifications and runtime safety requirements are satisfied simultaneously. This work enlights a novel solution for multi-robot systems with complicated task specifications. The efficacy of the proposed framework is validated with a simulation study.
MSAT: Biologically Inspired Multi-Stage Adaptive Threshold for Conversion of Spiking Neural Networks
Mar 23, 2023
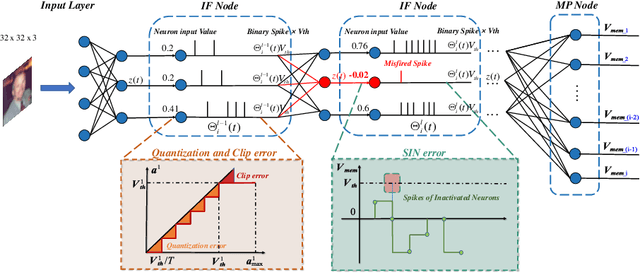
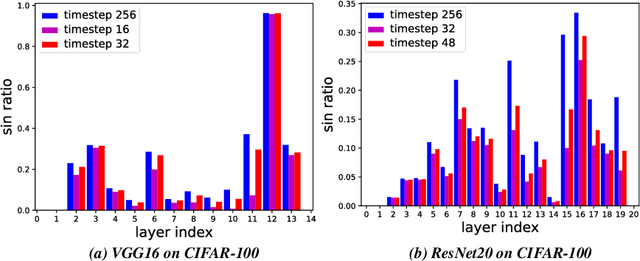
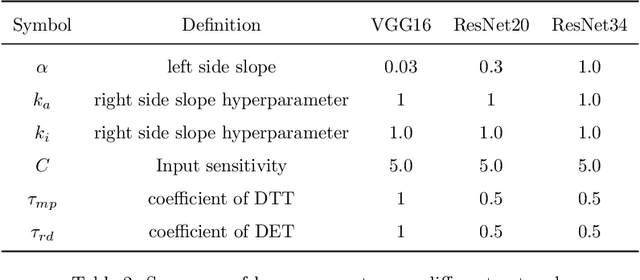
Spiking Neural Networks (SNNs) can do inference with low power consumption due to their spike sparsity. ANN-SNN conversion is an efficient way to achieve deep SNNs by converting well-trained Artificial Neural Networks (ANNs). However, the existing methods commonly use constant threshold for conversion, which prevents neurons from rapidly delivering spikes to deeper layers and causes high time delay. In addition, the same response for different inputs may result in information loss during the information transmission. Inspired by the biological model mechanism, we propose a multi-stage adaptive threshold (MSAT). Specifically, for each neuron, the dynamic threshold varies with firing history and input properties and is positively correlated with the average membrane potential and negatively correlated with the rate of depolarization. The self-adaptation to membrane potential and input allows a timely adjustment of the threshold to fire spike faster and transmit more information. Moreover, we analyze the Spikes of Inactivated Neurons error which is pervasive in early time steps and propose spike confidence accordingly as a measurement of confidence about the neurons that correctly deliver spikes. We use such spike confidence in early time steps to determine whether to elicit spike to alleviate this error. Combined with the proposed method, we examine the performance on non-trivial datasets CIFAR-10, CIFAR-100, and ImageNet. We also conduct sentiment classification and speech recognition experiments on the IDBM and Google speech commands datasets respectively. Experiments show near-lossless and lower latency ANN-SNN conversion. To the best of our knowledge, this is the first time to build a biologically inspired multi-stage adaptive threshold for converted SNN, with comparable performance to state-of-the-art methods while improving energy efficiency.