 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Situation Hyper-Graphs for Video Question Answering
Apr 18, 2023
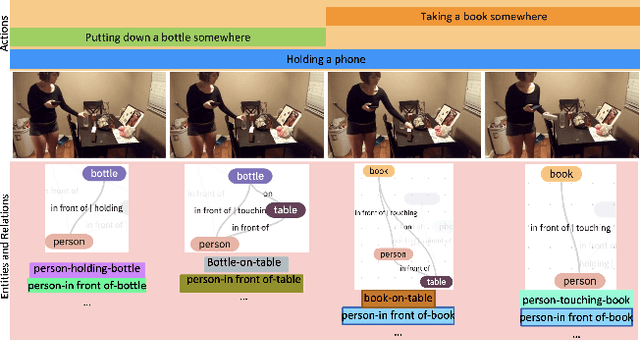

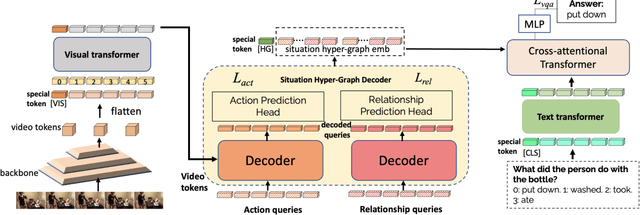

Answering questions about complex situations in videos requires not only capturing the presence of actors, objects, and their relations but also the evolution of these relationships over time. A situation hyper-graph is a representation that describes situations as scene sub-graphs for video frames and hyper-edges for connected sub-graphs and has been proposed to capture all such information in a compact structured form. In this work, we propose an architecture for Video Question Answering (VQA) that enables answering questions related to video content by predicting situation hyper-graphs, coined Situation Hyper-Graph based Video Question Answering (SHG-VQA). To this end, we train a situation hyper-graph decoder to implicitly identify graph representations with actions and object/human-object relationships from the input video clip. and to use cross-attention between the predicted situation hyper-graphs and the question embedding to predict the correct answer. The proposed method is trained in an end-to-end manner and optimized by a VQA loss with the cross-entropy function and a Hungarian matching loss for the situation graph prediction. The effectiveness of the proposed architecture is extensively evaluated on two challenging benchmarks: AGQA and STAR. Our results show that learning the underlying situation hyper-graphs helps the system to significantly improve its performance for novel challenges of video question-answering tasks.
Event Camera and LiDAR based Human Tracking for Adverse Lighting Conditions in Subterranean Environments
Apr 18, 2023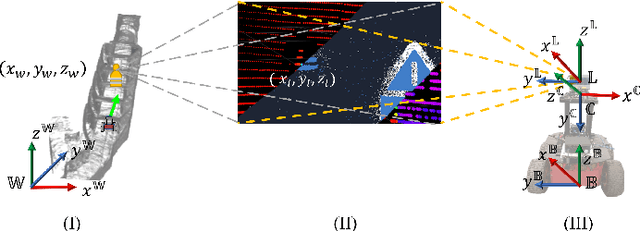



In this article, we propose a novel LiDAR and event camera fusion modality for subterranean (SubT) environments for fast and precise object and human detection in a wide variety of adverse lighting conditions, such as low or no light, high-contrast zones and in the presence of blinding light sources. In the proposed approach, information from the event camera and LiDAR are fused to localize a human or an object-of-interest in a robot's local frame. The local detection is then transformed into the inertial frame and used to set references for a Nonlinear Model Predictive Controller (NMPC) for reactive tracking of humans or objects in SubT environments. The proposed novel fusion uses intensity filtering and K-means clustering on the LiDAR point cloud and frequency filtering and connectivity clustering on the events induced in an event camera by the returning LiDAR beams. The centroids of the clusters in the event camera and LiDAR streams are then paired to localize reflective markers present on safety vests and signs in SubT environments. The efficacy of the proposed scheme has been experimentally validated in a real SubT environment (a mine) with a Pioneer 3AT mobile robot. The experimental results show real-time performance for human detection and the NMPC-based controller allows for reactive tracking of a human or object of interest, even in complete darkness.
Joint Neural Architecture and Hyperparameter Search for Correlated Time Series Forecasting
Nov 29, 2022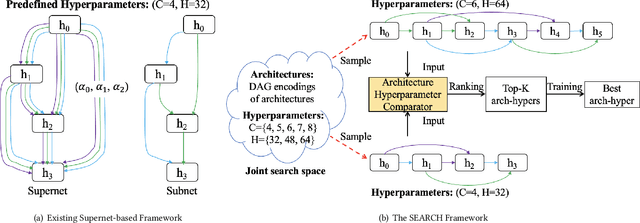
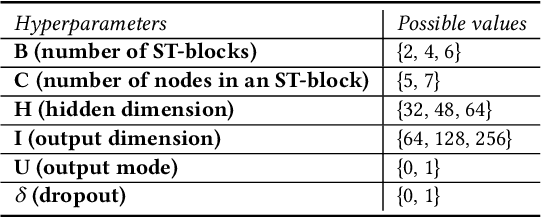


Sensors in cyber-physical systems often capture interconnected processes and thus emit correlated time series (CTS), the forecasting of which enables important applications. The key to successful CTS forecasting is to uncover the temporal dynamics of time series and the spatial correlations among time series. Deep learning-based solutions exhibit impressive performance at discerning these aspects. In particular, automated CTS forecasting, where the design of an optimal deep learning architecture is automated, enables forecasting accuracy that surpasses what has been achieved by manual approaches. However, automated CTS solutions remain in their infancy and are only able to find optimal architectures for predefined hyperparameters and scale poorly to large-scale CTS. To overcome these limitations, we propose SEARCH, a joint, scalable framework, to automatically devise effective CTS forecasting models. Specifically, we encode each candidate architecture and accompanying hyperparameters into a joint graph representation. We introduce an efficient Architecture-Hyperparameter Comparator (AHC) to rank all architecture-hyperparameter pairs, and we then further evaluate the top-ranked pairs to select a final result. Extensive experiments on six benchmark datasets demonstrate that SEARCH not only eliminates manual efforts but also is capable of better performance than manually designed and existing automatically designed CTS models. In addition, it shows excellent scalability to large CTS.
Time-aware Random Walk Diffusion to Improve Dynamic Graph Learning
Nov 04, 2022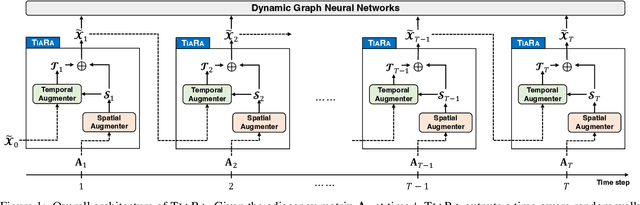
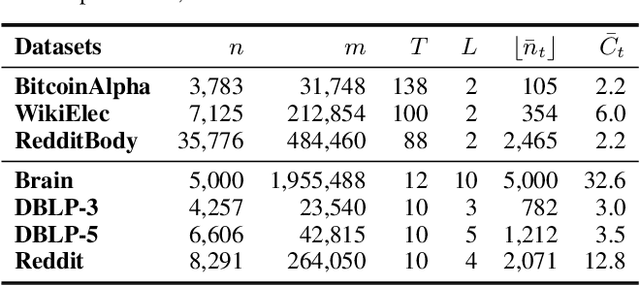
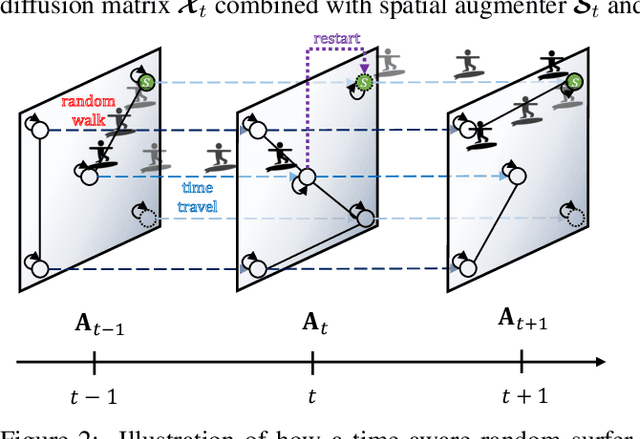
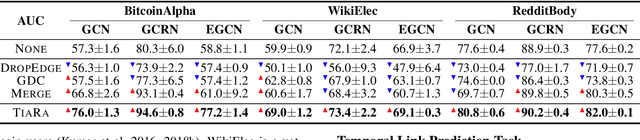
How can we augment a dynamic graph for improving the performance of dynamic graph neural networks? Graph augmentation has been widely utilized to boost the learning performance of GNN-based models. However, most existing approaches only enhance spatial structure within an input static graph by transforming the graph, and do not consider dynamics caused by time such as temporal locality, i.e., recent edges are more influential than earlier ones, which remains challenging for dynamic graph augmentation. In this work, we propose TiaRa (Time-aware Random Walk Diffusion), a novel diffusion-based method for augmenting a dynamic graph represented as a discrete-time sequence of graph snapshots. For this purpose, we first design a time-aware random walk proximity so that a surfer can walk along the time dimension as well as edges, resulting in spatially and temporally localized scores. We then derive our diffusion matrices based on the time-aware random walk, and show they become enhanced adjacency matrices that both spatial and temporal localities are augmented. Throughout extensive experiments, we demonstrate that TiaRa effectively augments a given dynamic graph, and leads to significant improvements in dynamic GNN models for various graph datasets and tasks.
Time-aware Multiway Adaptive Fusion Network for Temporal Knowledge Graph Question Answering
Feb 24, 2023
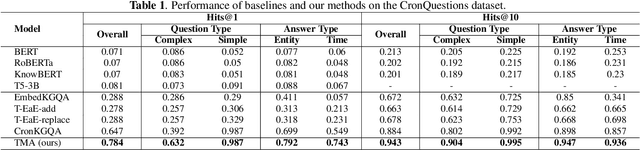
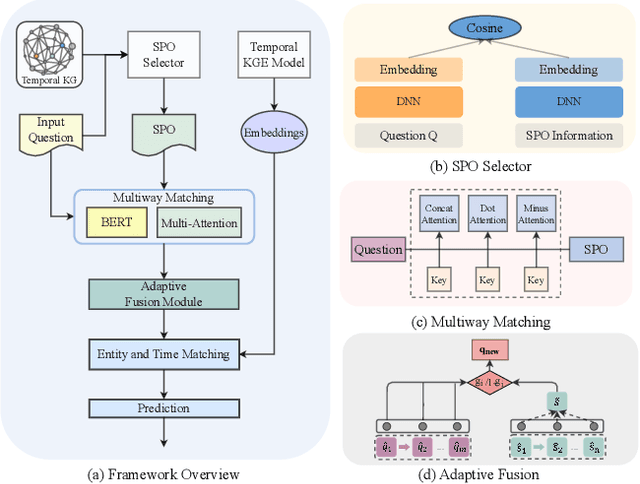
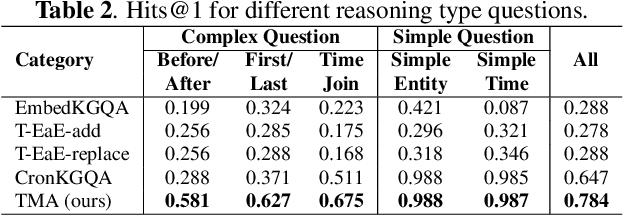
Knowledge graphs (KGs) have received increasing attention due to its wide applications on natural language processing. However, its use case on temporal question answering (QA) has not been well-explored. Most of existing methods are developed based on pre-trained language models, which might not be capable to learn \emph{temporal-specific} presentations of entities in terms of temporal KGQA task. To alleviate this problem, we propose a novel \textbf{T}ime-aware \textbf{M}ultiway \textbf{A}daptive (\textbf{TMA}) fusion network. Inspired by the step-by-step reasoning behavior of humans. For each given question, TMA first extracts the relevant concepts from the KG, and then feeds them into a multiway adaptive module to produce a \emph{temporal-specific} representation of the question. This representation can be incorporated with the pre-trained KG embedding to generate the final prediction. Empirical results verify that the proposed model achieves better performance than the state-of-the-art models in the benchmark dataset. Notably, the Hits@1 and Hits@10 results of TMA on the CronQuestions dataset's complex questions are absolutely improved by 24\% and 10\% compared to the best-performing baseline. Furthermore, we also show that TMA employing an adaptive fusion mechanism can provide interpretability by analyzing the proportion of information in question representations.
* ICASSP 2023
Efficient Multi-stage Inference on Tabular Data
Mar 21, 2023Many ML applications and products train on medium amounts of input data but get bottlenecked in real-time inference. When implementing ML systems, conventional wisdom favors segregating ML code into services queried by product code via Remote Procedure Call (RPC) APIs. This approach clarifies the overall software architecture and simplifies product code by abstracting away ML internals. However, the separation adds network latency and entails additional CPU overhead. Hence, we simplify inference algorithms and embed them into the product code to reduce network communication. For public datasets and a high-performance real-time platform that deals with tabular data, we show that over half of the inputs are often amenable to such optimization, while the remainder can be handled by the original model. By applying our optimization with AutoML to both training and inference, we reduce inference latency by 1.3x, CPU resources by 30%, and network communication between application front-end and ML back-end by about 50% for a commercial end-to-end ML platform that serves millions of real-time decisions per second.
Local object crop collision network for efficient simulation of non-convex objects in GPU-based simulators
Apr 19, 2023
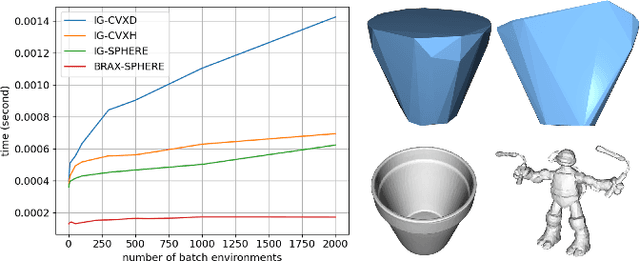
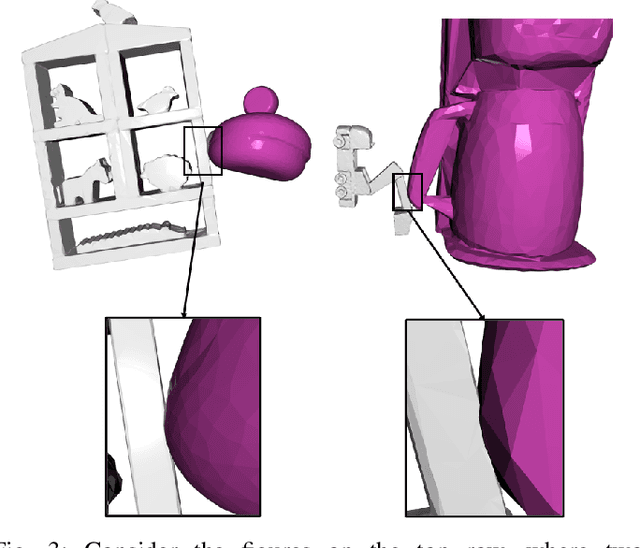
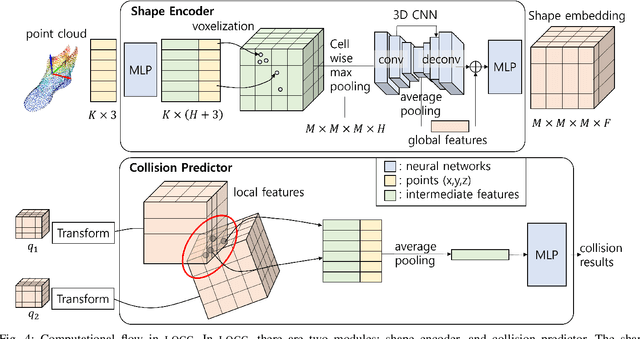
Our goal is to develop an efficient contact detection algorithm for large-scale GPU-based simulation of non-convex objects. Current GPU-based simulators such as IsaacGym and Brax must trade-off speed with fidelity, generality, or both when simulating non-convex objects. Their main issue lies in contact detection (CD): existing CD algorithms, such as Gilbert-Johnson-Keerthi (GJK), must trade off their computational speed with accuracy which becomes expensive as the number of collisions among non-convex objects increases. We propose a data-driven approach for CD, whose accuracy depends only on the quality and quantity of offline dataset rather than online computation time. Unlike GJK, our method inherently has a uniform computational flow, which facilitates efficient GPU usage based on advanced compilers such as XLA (Accelerated Linear Algebra). Further, we offer a data-efficient solution by learning the patterns of colliding local crop object shapes, rather than global object shapes which are harder to learn. We demonstrate our approach improves the efficiency of existing CD methods by a factor of 5-10 for non-convex objects with comparable accuracy. Using the previous work on contact resolution for a neural-network-based contact detector, we integrate our CD algorithm into the open-source GPU-based simulator, Brax, and show that we can improve the efficiency over IsaacGym and generality over standard Brax. We highly recommend the videos of our simulator included in the supplementary materials.
Automatic Individual Identification of Patterned Solitary Species Based on Unlabeled Video Data
Apr 19, 2023


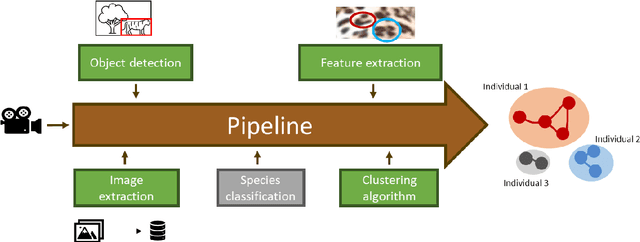
The manual processing and analysis of videos from camera traps is time-consuming and includes several steps, ranging from the filtering of falsely triggered footage to identifying and re-identifying individuals. In this study, we developed a pipeline to automatically analyze videos from camera traps to identify individuals without requiring manual interaction. This pipeline applies to animal species with uniquely identifiable fur patterns and solitary behavior, such as leopards (Panthera pardus). We assumed that the same individual was seen throughout one triggered video sequence. With this assumption, multiple images could be assigned to an individual for the initial database filling without pre-labeling. The pipeline was based on well-established components from computer vision and deep learning, particularly convolutional neural networks (CNNs) and scale-invariant feature transform (SIFT) features. We augmented this basis by implementing additional components to substitute otherwise required human interactions. Based on the similarity between frames from the video material, clusters were formed that represented individuals bypassing the open set problem of the unknown total population. The pipeline was tested on a dataset of leopard videos collected by the Pan African Programme: The Cultured Chimpanzee (PanAf) and achieved a success rate of over 83% for correct matches between previously unknown individuals. The proposed pipeline can become a valuable tool for future conservation projects based on camera trap data, reducing the work of manual analysis for individual identification, when labeled data is unavailable.
$Δ$-Networks for Efficient Model Patching
Mar 26, 2023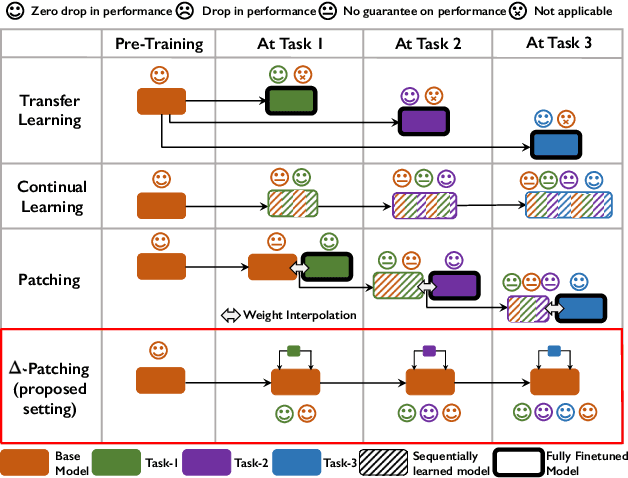

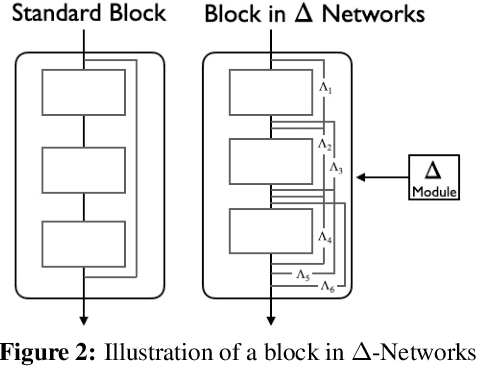
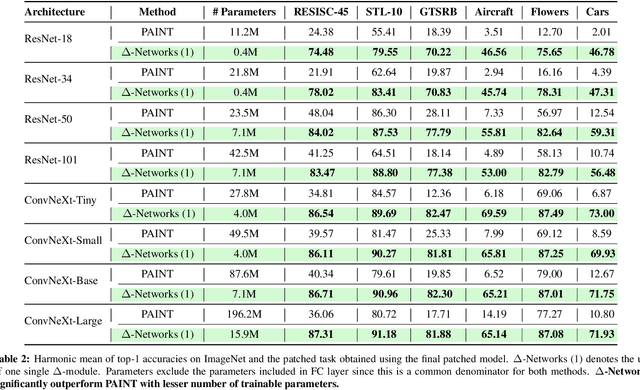
Models pre-trained on large-scale datasets are often finetuned to support newer tasks and datasets that arrive over time. This process necessitates storing copies of the model over time for each task that the pre-trained model is finetuned to. Building on top of recent model patching work, we propose $\Delta$-Patching for finetuning neural network models in an efficient manner, without the need to store model copies. We propose a simple and lightweight method called $\Delta$-Networks to achieve this objective. Our comprehensive experiments across setting and architecture variants show that $\Delta$-Networks outperform earlier model patching work while only requiring a fraction of parameters to be trained. We also show that this approach can be used for other problem settings such as transfer learning and zero-shot domain adaptation, as well as other tasks such as detection and segmentation.
Low-Complexity Memoryless Linearizer for Analog-to-Digital Interfaces
Apr 12, 2023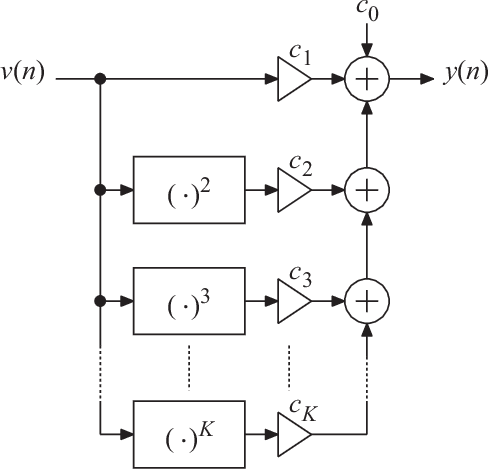
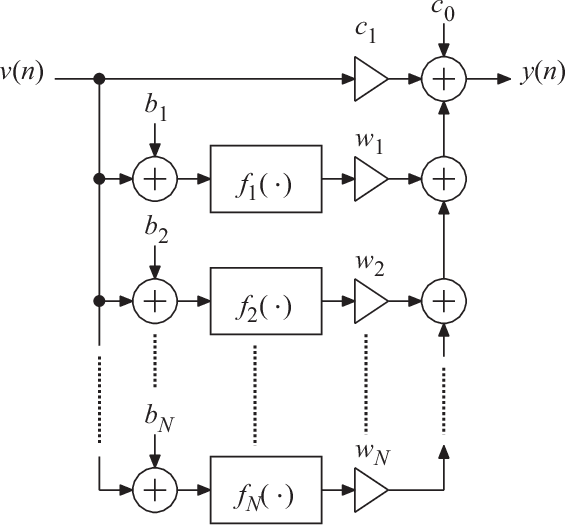
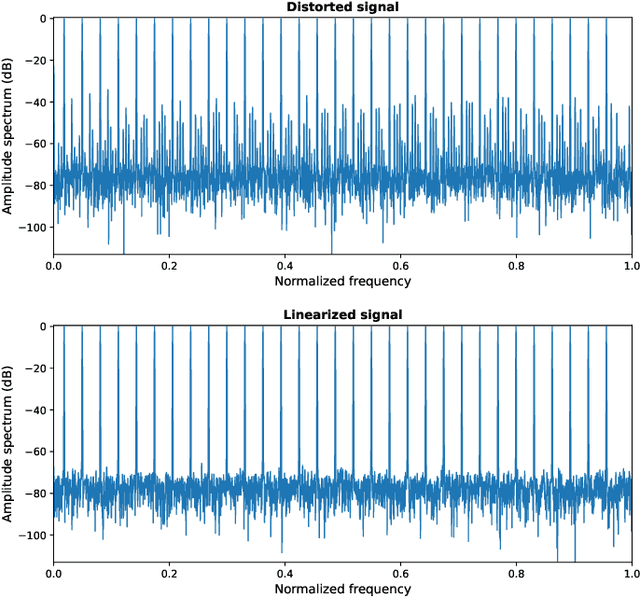
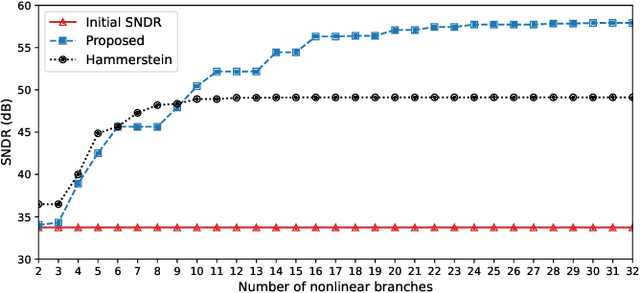
This paper introduces a low-complexity memoryless linearizer for suppression of distortion in analog-to-digital interfaces. It is inspired by neural networks, but has a substantially lower complexity than the neural-network schemes that have appeared earlier in the literature in this context. The paper demonstrates that the proposed linearizer can outperform the conventional parallel memoryless Hammerstein linearizer even when the nonlinearities have been generated through a memoryless polynomial model. Further, a design procedure is proposed in which the linearizer parameters are obtained through matrix inversion. Thereby, the costly and time consuming numerical optimization that is traditionally used when training neural networks is eliminated. Moreover, the design and evaluation incorporate a large set of multi-tone signals covering the first Nyquist band. Simulations show signal-to-noise-and-distortion ratio (SNDR) improvements of some 25 dB for multi-tone signals that correspond to the quadrature parts of OFDM signals with QPSK modulation.