 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Text-Conditional Contextualized Avatars For Zero-Shot Personalization
Apr 14, 2023
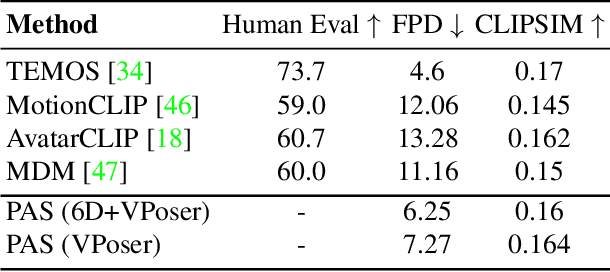
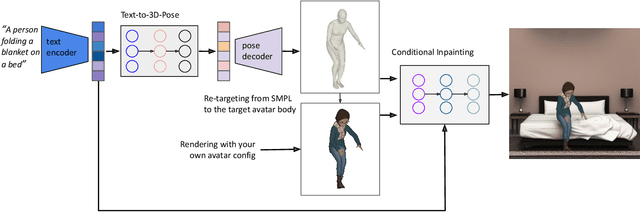
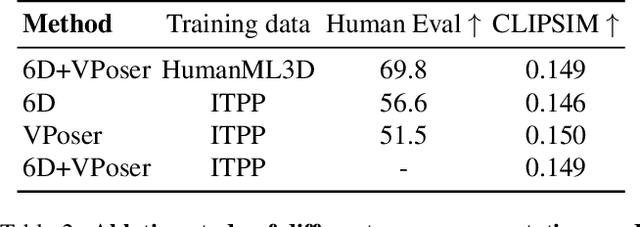
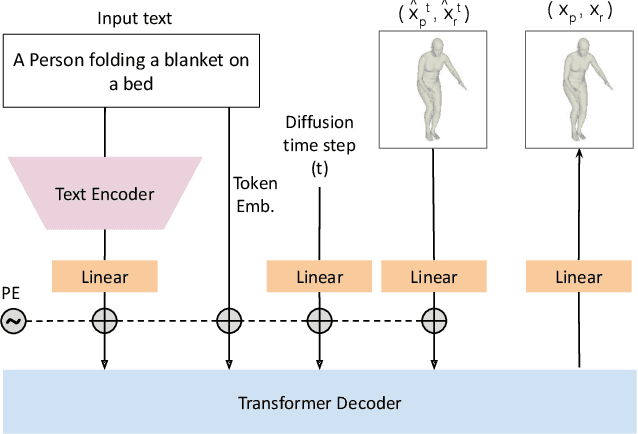
Recent large-scale text-to-image generation models have made significant improvements in the quality, realism, and diversity of the synthesized images and enable users to control the created content through language. However, the personalization aspect of these generative models is still challenging and under-explored. In this work, we propose a pipeline that enables personalization of image generation with avatars capturing a user's identity in a delightful way. Our pipeline is zero-shot, avatar texture and style agnostic, and does not require training on the avatar at all - it is scalable to millions of users who can generate a scene with their avatar. To render the avatar in a pose faithful to the given text prompt, we propose a novel text-to-3D pose diffusion model trained on a curated large-scale dataset of in-the-wild human poses improving the performance of the SOTA text-to-motion models significantly. We show, for the first time, how to leverage large-scale image datasets to learn human 3D pose parameters and overcome the limitations of motion capture datasets.
Accelerating Vision-Language Pretraining with Free Language Modeling
Mar 24, 2023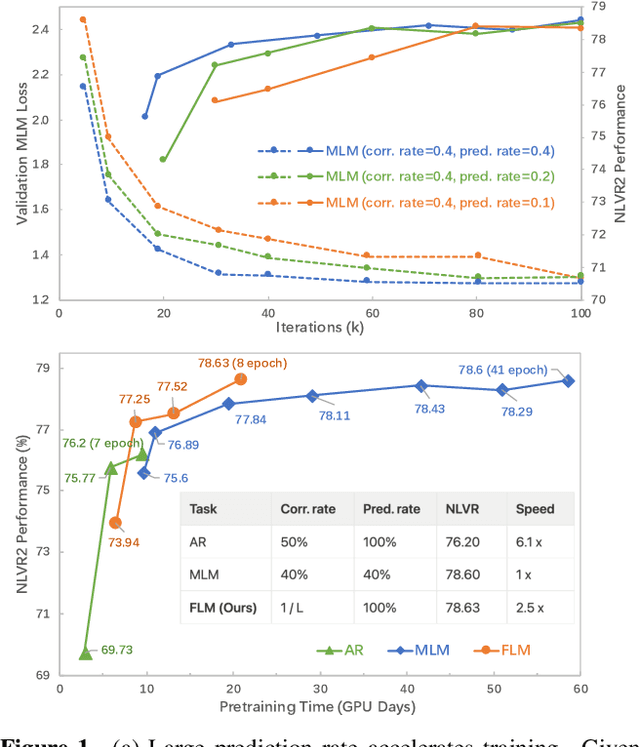
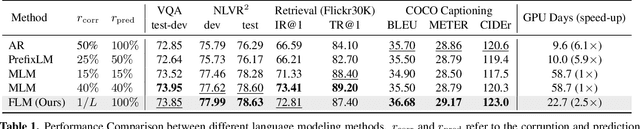
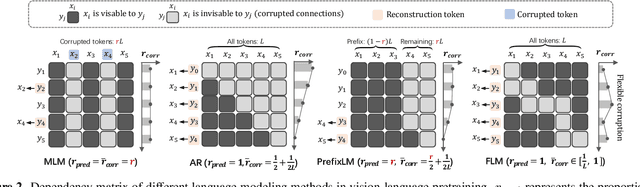
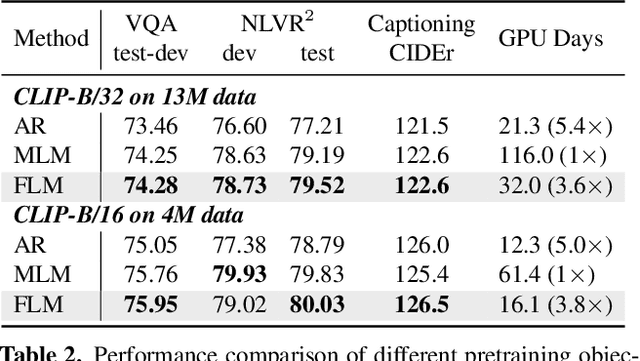
The state of the arts in vision-language pretraining (VLP) achieves exemplary performance but suffers from high training costs resulting from slow convergence and long training time, especially on large-scale web datasets. An essential obstacle to training efficiency lies in the entangled prediction rate (percentage of tokens for reconstruction) and corruption rate (percentage of corrupted tokens) in masked language modeling (MLM), that is, a proper corruption rate is achieved at the cost of a large portion of output tokens being excluded from prediction loss. To accelerate the convergence of VLP, we propose a new pretraining task, namely, free language modeling (FLM), that enables a 100% prediction rate with arbitrary corruption rates. FLM successfully frees the prediction rate from the tie-up with the corruption rate while allowing the corruption spans to be customized for each token to be predicted. FLM-trained models are encouraged to learn better and faster given the same GPU time by exploiting bidirectional contexts more flexibly. Extensive experiments show FLM could achieve an impressive 2.5x pretraining time reduction in comparison to the MLM-based methods, while keeping competitive performance on both vision-language understanding and generation tasks. Code will be public at https://github.com/TencentARC/FLM.
Neural Implicit Vision-Language Feature Fields
Mar 20, 2023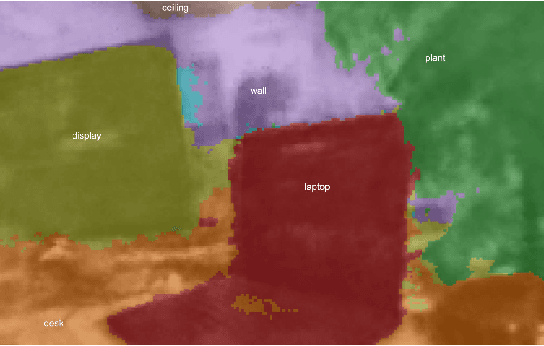
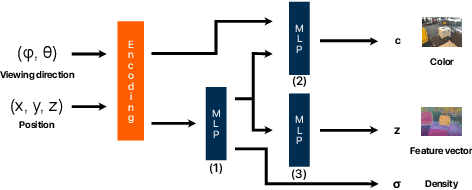


Recently, groundbreaking results have been presented on open-vocabulary semantic image segmentation. Such methods segment each pixel in an image into arbitrary categories provided at run-time in the form of text prompts, as opposed to a fixed set of classes defined at training time. In this work, we present a zero-shot volumetric open-vocabulary semantic scene segmentation method. Our method builds on the insight that we can fuse image features from a vision-language model into a neural implicit representation. We show that the resulting feature field can be segmented into different classes by assigning points to natural language text prompts. The implicit volumetric representation enables us to segment the scene both in 3D and 2D by rendering feature maps from any given viewpoint of the scene. We show that our method works on noisy real-world data and can run in real-time on live sensor data dynamically adjusting to text prompts. We also present quantitative comparisons on the ScanNet dataset.
Dealing With Heterogeneous 3D MR Knee Images: A Federated Few-Shot Learning Method With Dual Knowledge Distillation
Apr 18, 2023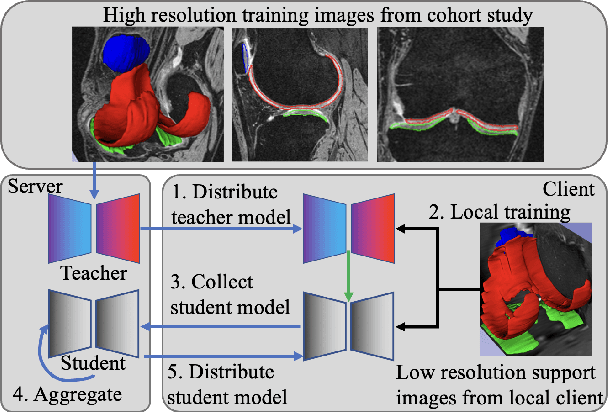

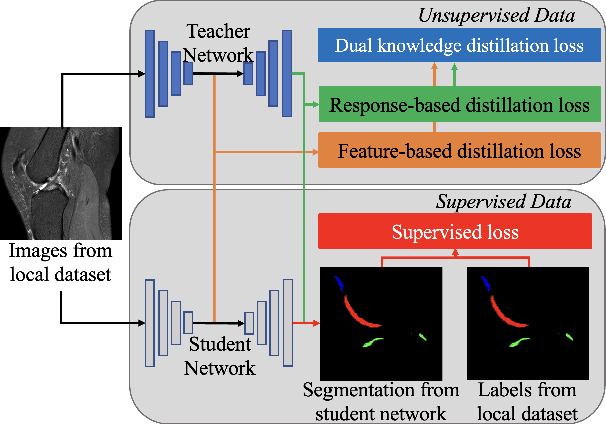
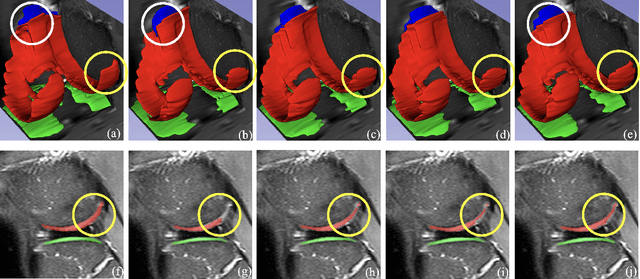
Federated Learning has gained popularity among medical institutions since it enables collaborative training between clients (e.g., hospitals) without aggregating data. However, due to the high cost associated with creating annotations, especially for large 3D image datasets, clinical institutions do not have enough supervised data for training locally. Thus, the performance of the collaborative model is subpar under limited supervision. On the other hand, large institutions have the resources to compile data repositories with high-resolution images and labels. Therefore, individual clients can utilize the knowledge acquired in the public data repositories to mitigate the shortage of private annotated images. In this paper, we propose a federated few-shot learning method with dual knowledge distillation. This method allows joint training with limited annotations across clients without jeopardizing privacy. The supervised learning of the proposed method extracts features from limited labeled data in each client, while the unsupervised data is used to distill both feature and response-based knowledge from a national data repository to further improve the accuracy of the collaborative model and reduce the communication cost. Extensive evaluations are conducted on 3D magnetic resonance knee images from a private clinical dataset. Our proposed method shows superior performance and less training time than other semi-supervised federated learning methods. Codes and additional visualization results are available at https://github.com/hexiaoxiao-cs/fedml-knee.
Learning Situation Hyper-Graphs for Video Question Answering
Apr 18, 2023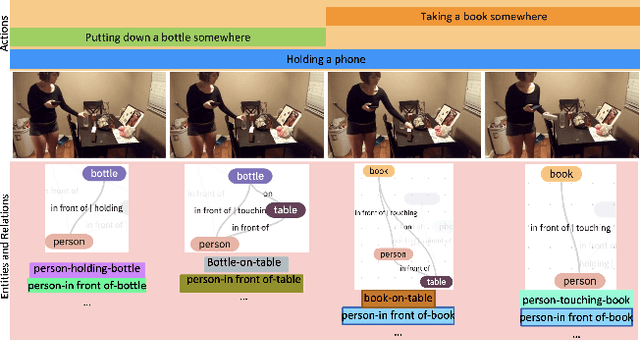

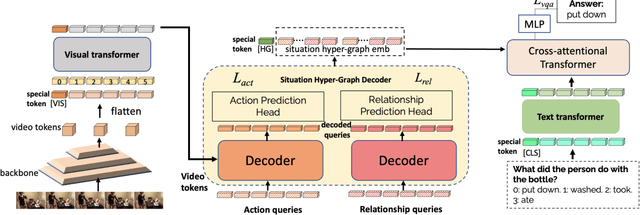

Answering questions about complex situations in videos requires not only capturing the presence of actors, objects, and their relations but also the evolution of these relationships over time. A situation hyper-graph is a representation that describes situations as scene sub-graphs for video frames and hyper-edges for connected sub-graphs and has been proposed to capture all such information in a compact structured form. In this work, we propose an architecture for Video Question Answering (VQA) that enables answering questions related to video content by predicting situation hyper-graphs, coined Situation Hyper-Graph based Video Question Answering (SHG-VQA). To this end, we train a situation hyper-graph decoder to implicitly identify graph representations with actions and object/human-object relationships from the input video clip. and to use cross-attention between the predicted situation hyper-graphs and the question embedding to predict the correct answer. The proposed method is trained in an end-to-end manner and optimized by a VQA loss with the cross-entropy function and a Hungarian matching loss for the situation graph prediction. The effectiveness of the proposed architecture is extensively evaluated on two challenging benchmarks: AGQA and STAR. Our results show that learning the underlying situation hyper-graphs helps the system to significantly improve its performance for novel challenges of video question-answering tasks.
Event Camera and LiDAR based Human Tracking for Adverse Lighting Conditions in Subterranean Environments
Apr 18, 2023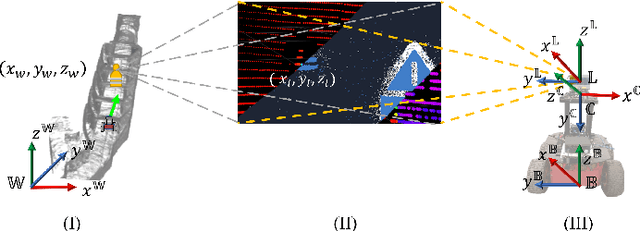



In this article, we propose a novel LiDAR and event camera fusion modality for subterranean (SubT) environments for fast and precise object and human detection in a wide variety of adverse lighting conditions, such as low or no light, high-contrast zones and in the presence of blinding light sources. In the proposed approach, information from the event camera and LiDAR are fused to localize a human or an object-of-interest in a robot's local frame. The local detection is then transformed into the inertial frame and used to set references for a Nonlinear Model Predictive Controller (NMPC) for reactive tracking of humans or objects in SubT environments. The proposed novel fusion uses intensity filtering and K-means clustering on the LiDAR point cloud and frequency filtering and connectivity clustering on the events induced in an event camera by the returning LiDAR beams. The centroids of the clusters in the event camera and LiDAR streams are then paired to localize reflective markers present on safety vests and signs in SubT environments. The efficacy of the proposed scheme has been experimentally validated in a real SubT environment (a mine) with a Pioneer 3AT mobile robot. The experimental results show real-time performance for human detection and the NMPC-based controller allows for reactive tracking of a human or object of interest, even in complete darkness.
LivePose: Online 3D Reconstruction from Monocular Video with Dynamic Camera Poses
Mar 31, 2023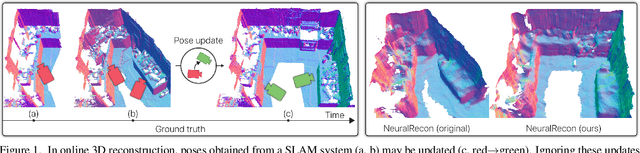

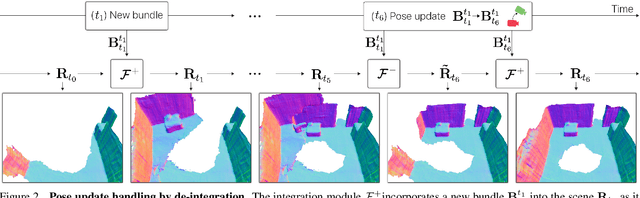
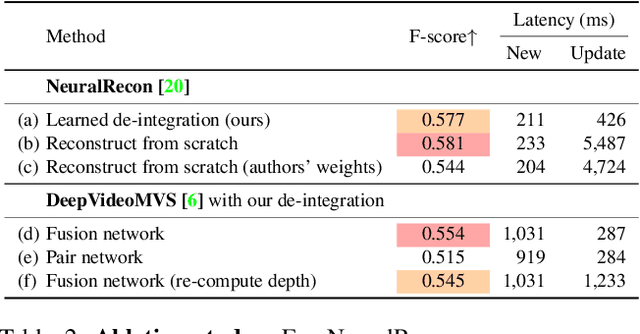
Dense 3D reconstruction from RGB images traditionally assumes static camera pose estimates. This assumption has endured, even as recent works have increasingly focused on real-time methods for mobile devices. However, the assumption of one pose per image does not hold for online execution: poses from real-time SLAM are dynamic and may be updated following events such as bundle adjustment and loop closure. This has been addressed in the RGB-D setting, by de-integrating past views and re-integrating them with updated poses, but it remains largely untreated in the RGB-only setting. We formalize this problem to define the new task of online reconstruction from dynamically-posed images. To support further research, we introduce a dataset called LivePose containing the dynamic poses from a SLAM system running on ScanNet. We select three recent reconstruction systems and apply a framework based on de-integration to adapt each one to the dynamic-pose setting. In addition, we propose a novel, non-linear de-integration module that learns to remove stale scene content. We show that responding to pose updates is critical for high-quality reconstruction, and that our de-integration framework is an effective solution.
A robust deep learning-based damage identification approach for SHM considering missing data
Mar 31, 2023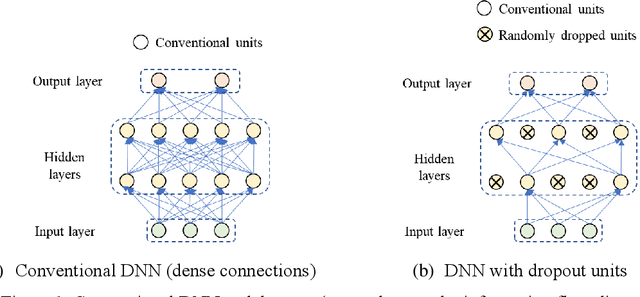
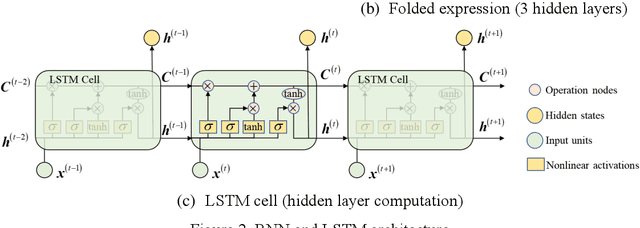
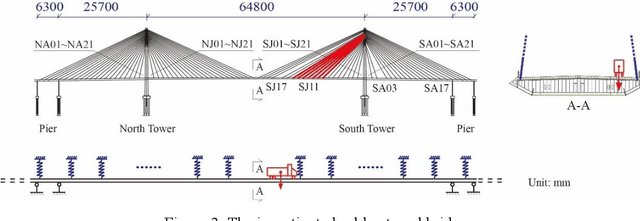
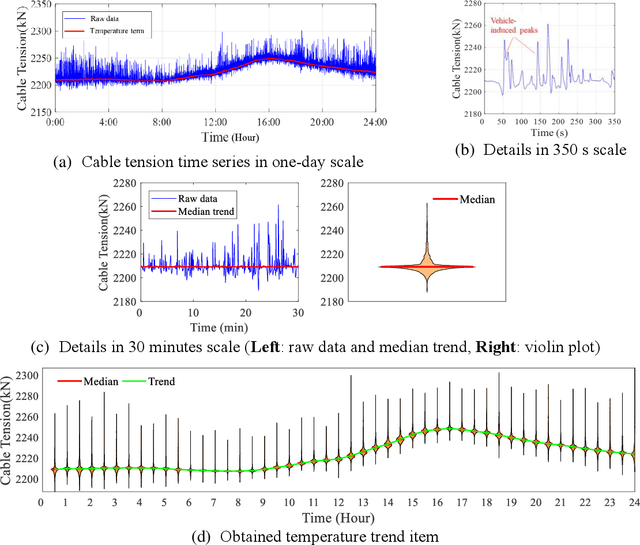
Data-driven method for Structural Health Monitoring (SHM), that mine the hidden structural performance from the correlations among monitored time series data, has received widely concerns recently. However, missing data significantly impacts the conduction of this method. Missing data is a frequently encountered issue in time series data in SHM and many other real-world applications, that harms to the standardized data mining and downstream tasks, such as condition assessment. Imputation approaches based on spatiotemporal relations among monitoring data are developed to handle this issue, however, no additional information is added during imputation. This paper thus develops a robust method for damage identification that considers the missing data occasions, based on long-short term memory (LSTM) model and dropout mechanism in the autoencoder (AE) framework. Inputs channels are randomly dropped to simulate the missing data in training, and reconstruction errors are used as the loss function and the damage indicator. Quasi-static response (cable tension) of a cable-stayed bridge released in 1st IPC-SHM is employed to verify this proposed method, and results show that the missing data imputation and damage identification can be implemented together in a unified way.
MGADN: A Multi-task Graph Anomaly Detection Network for Multivariate Time Series
Nov 27, 2022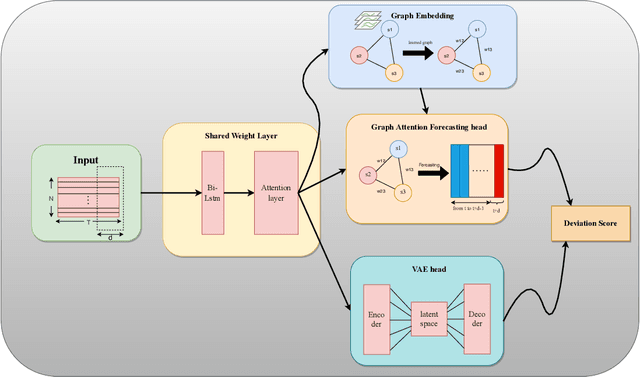
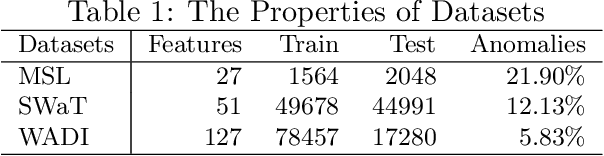
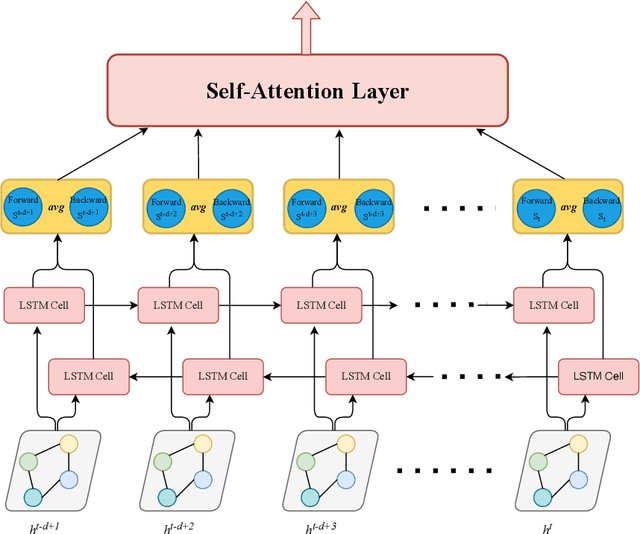
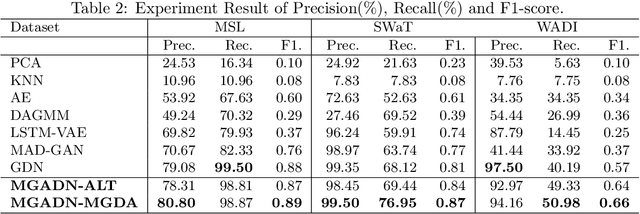
Anomaly detection of time series, especially multivariate time series(time series with multiple sensors), has been focused on for several years. Though existing method has achieved great progress, there are several challenging problems to be solved. Firstly, existing method including neural network only concentrate on the relationship in terms of timestamp. To be exact, they only want to know how does the data in the past influence which in the future. However, one sensor sometimes intervenes in other sensor such as the speed of wind may cause decrease of temperature. Secondly, there exist two categories of model for time series anomaly detection: prediction model and reconstruction model. Prediction model is adept at learning timely representation while short of capability when faced with sparse anomaly. Conversely, reconstruction model is opposite. Therefore, how can we efficiently get the relationship both in terms of both timestamp and sensors becomes our main topic. Our approach uses GAT, which is originated from graph neural network, to obtain connection between sensors. And LSTM is used to obtain relationships timely. Our approach is also designed to be double headed to calculate both prediction loss and reconstruction loss via VAE(Variational Auto-Encoder). In order to take advantage of two sorts of model, multi-task optimization algorithm is used in this model.
Spatially Constrained Time-Optimal Motion Planning
Oct 05, 2022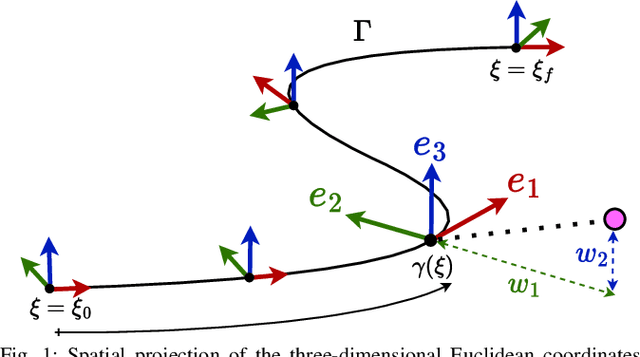

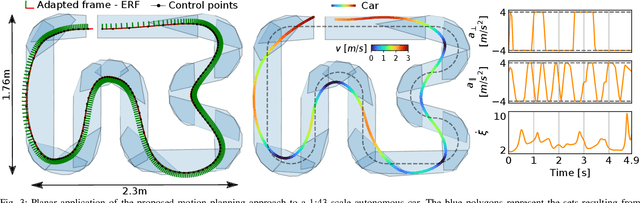
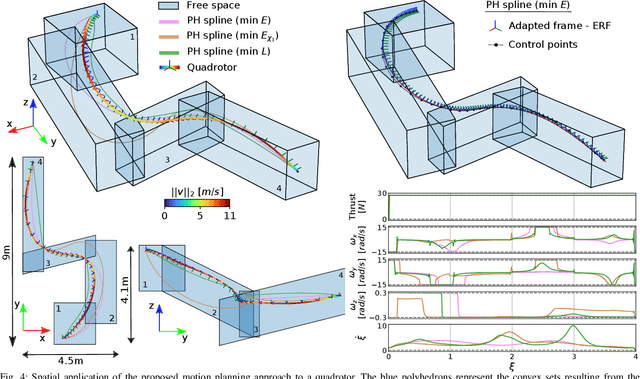
This paper focuses on spatial time-optimal motion planning, a generalization of the exact time-optimal path following problem that allows the system to plan within a predefined space. In contrast to state-of-the-art methods, we drop the assumption that a collision-free geometric reference is given. Instead, we present a two-stage motion planning method that solely relies on a goal location and a geometric representation of the environment to compute a time-optimal trajectory that is compliant with system dynamics and constraints. To do so, the proposed scheme first computes an obstacle-free Pythagorean Hodograph parametric spline, and second solves a spatially reformulated minimum-time optimization problem. The spline obtained in the first stage is not a geometric reference, but an extension of the environment representation, and thus, time-optimality of the solution is guaranteed. The efficacy of the proposed approach is benchmarked by a known planar example and validated in a more complex spatial system, illustrating its versatility and applicability.