 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MGIC: A Multi-Label Gradient Inversion Attack based on Canny Edge Detection on Federated Learning
Mar 13, 2024
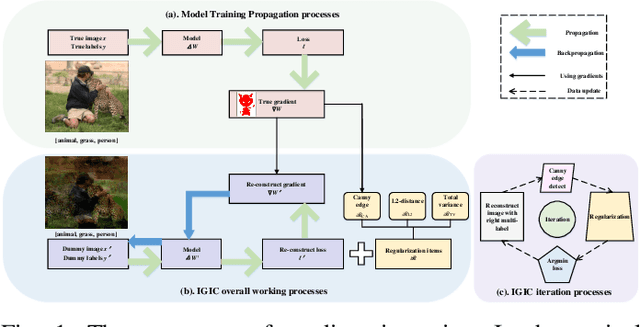
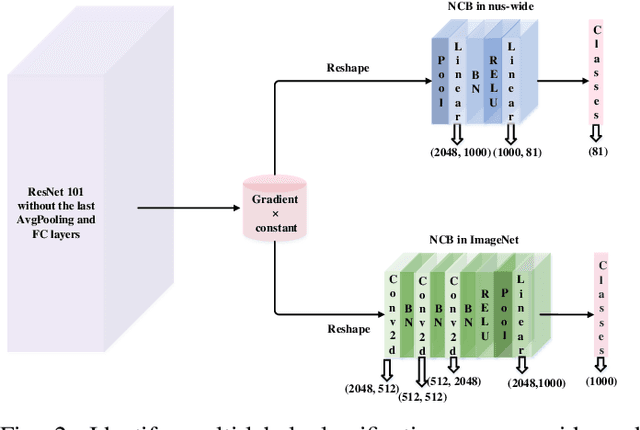


As a new distributed computing framework that can protect data privacy, federated learning (FL) has attracted more and more attention in recent years. It receives gradients from users to train the global model and releases the trained global model to working users. Nonetheless, the gradient inversion (GI) attack reflects the risk of privacy leakage in federated learning. Attackers only need to use gradients through hundreds of thousands of simple iterations to obtain relatively accurate private data stored on users' local devices. For this, some works propose simple but effective strategies to obtain user data under a single-label dataset. However, these strategies induce a satisfactory visual effect of the inversion image at the expense of higher time costs. Due to the semantic limitation of a single label, the image obtained by gradient inversion may have semantic errors. We present a novel gradient inversion strategy based on canny edge detection (MGIC) in both the multi-label and single-label datasets. To reduce semantic errors caused by a single label, we add new convolution layers' blocks in the trained model to obtain the image's multi-label. Through multi-label representation, serious semantic errors in inversion images are reduced. Then, we analyze the impact of parameters on the difficulty of input image reconstruction and discuss how image multi-subjects affect the inversion performance. Our proposed strategy has better visual inversion image results than the most widely used ones, saving more than 78% of time costs in the ImageNet dataset.
Towards a Digital Twin Framework in Additive Manufacturing: Machine Learning and Bayesian Optimization for Time Series Process Optimization
Feb 27, 2024Laser-directed-energy deposition (DED) offers advantages in additive manufacturing (AM) for creating intricate geometries and material grading. Yet, challenges like material inconsistency and part variability remain, mainly due to its layer-wise fabrication. A key issue is heat accumulation during DED, which affects the material microstructure and properties. While closed-loop control methods for heat management are common in DED research, few integrate real-time monitoring, physics-based modeling, and control in a unified framework. Our work presents a digital twin (DT) framework for real-time predictive control of DED process parameters to meet specific design objectives. We develop a surrogate model using Long Short-Term Memory (LSTM)-based machine learning with Bayesian Inference to predict temperatures in DED parts. This model predicts future temperature states in real time. We also introduce Bayesian Optimization (BO) for Time Series Process Optimization (BOTSPO), based on traditional BO but featuring a unique time series process profile generator with reduced dimensions. BOTSPO dynamically optimizes processes, identifying optimal laser power profiles to attain desired mechanical properties. The established process trajectory guides online optimizations, aiming to enhance performance. This paper outlines the digital twin framework's components, promoting its integration into a comprehensive system for AM.
Towards the Reusability and Compositionality of Causal Representations
Mar 14, 2024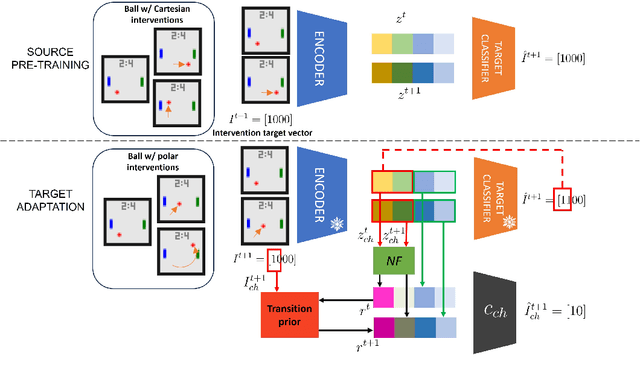
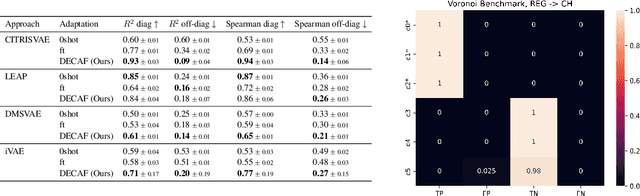
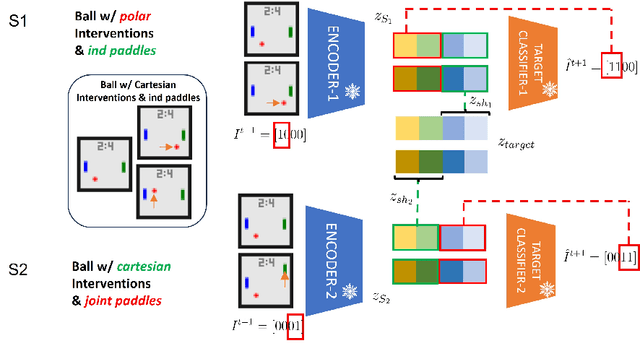

Causal Representation Learning (CRL) aims at identifying high-level causal factors and their relationships from high-dimensional observations, e.g., images. While most CRL works focus on learning causal representations in a single environment, in this work we instead propose a first step towards learning causal representations from temporal sequences of images that can be adapted in a new environment, or composed across multiple related environments. In particular, we introduce DECAF, a framework that detects which causal factors can be reused and which need to be adapted from previously learned causal representations. Our approach is based on the availability of intervention targets, that indicate which variables are perturbed at each time step. Experiments on three benchmark datasets show that integrating our framework with four state-of-the-art CRL approaches leads to accurate representations in a new environment with only a few samples.
Enhancing Multivariate Time Series Forecasting with Mutual Information-driven Cross-Variable and Temporal Modeling
Mar 01, 2024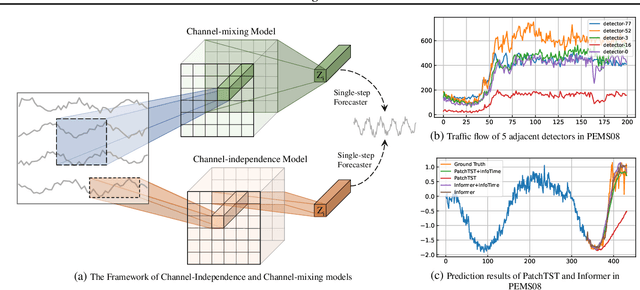
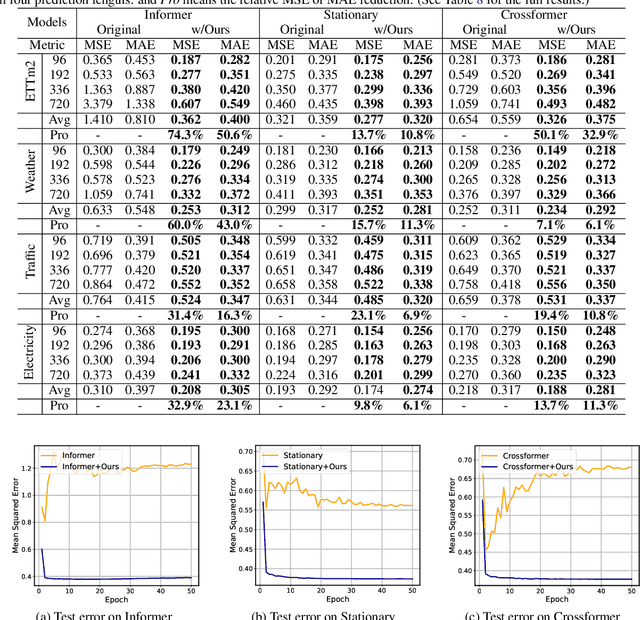
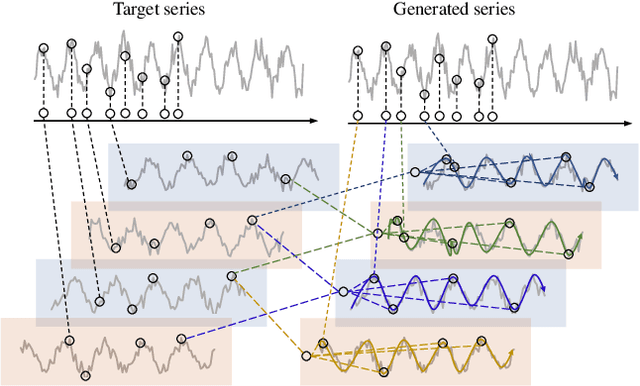
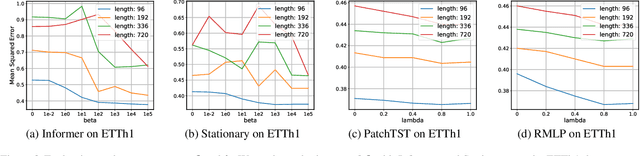
Recent advancements have underscored the impact of deep learning techniques on multivariate time series forecasting (MTSF). Generally, these techniques are bifurcated into two categories: Channel-independence and Channel-mixing approaches. Although Channel-independence methods typically yield better results, Channel-mixing could theoretically offer improvements by leveraging inter-variable correlations. Nonetheless, we argue that the integration of uncorrelated information in channel-mixing methods could curtail the potential enhancement in MTSF model performance. To substantiate this claim, we introduce the Cross-variable Decorrelation Aware feature Modeling (CDAM) for Channel-mixing approaches, aiming to refine Channel-mixing by minimizing redundant information between channels while enhancing relevant mutual information. Furthermore, we introduce the Temporal correlation Aware Modeling (TAM) to exploit temporal correlations, a step beyond conventional single-step forecasting methods. This strategy maximizes the mutual information between adjacent sub-sequences of both the forecasted and target series. Combining CDAM and TAM, our novel framework significantly surpasses existing models, including those previously considered state-of-the-art, in comprehensive tests.
Run-time Introspection of 2D Object Detection in Automated Driving Systems Using Learning Representations
Mar 02, 2024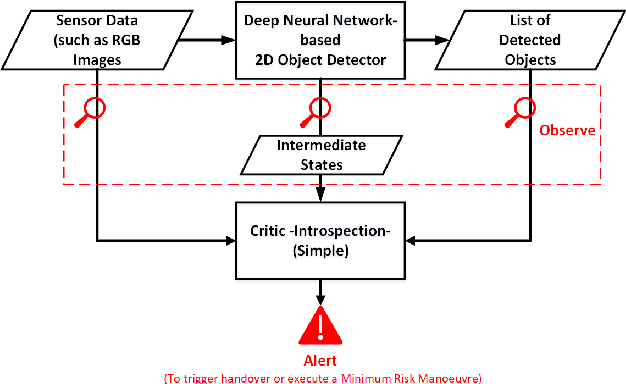
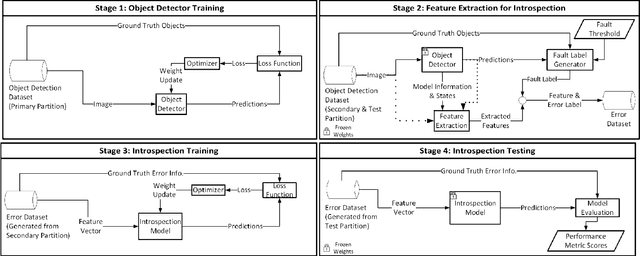
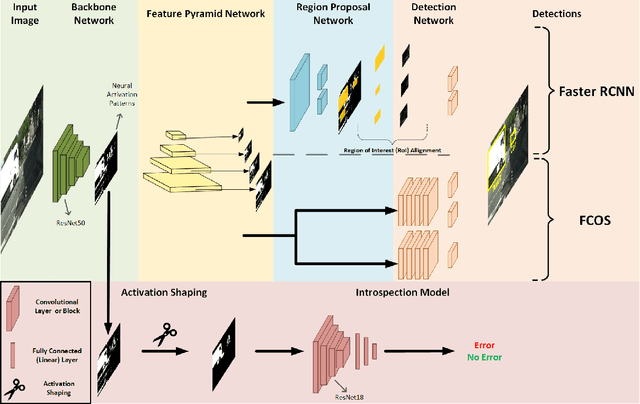
Reliable detection of various objects and road users in the surrounding environment is crucial for the safe operation of automated driving systems (ADS). Despite recent progresses in developing highly accurate object detectors based on Deep Neural Networks (DNNs), they still remain prone to detection errors, which can lead to fatal consequences in safety-critical applications such as ADS. An effective remedy to this problem is to equip the system with run-time monitoring, named as introspection in the context of autonomous systems. Motivated by this, we introduce a novel introspection solution, which operates at the frame level for DNN-based 2D object detection and leverages neural network activation patterns. The proposed approach pre-processes the neural activation patterns of the object detector's backbone using several different modes. To provide extensive comparative analysis and fair comparison, we also adapt and implement several state-of-the-art (SOTA) introspection mechanisms for error detection in 2D object detection, using one-stage and two-stage object detectors evaluated on KITTI and BDD datasets. We compare the performance of the proposed solution in terms of error detection, adaptability to dataset shift, and, computational and memory resource requirements. Our performance evaluation shows that the proposed introspection solution outperforms SOTA methods, achieving an absolute reduction in the missed error ratio of 9% to 17% in the BDD dataset.
Better Understandings and Configurations in MaxSAT Local Search Solvers via Anytime Performance Analysis
Mar 11, 2024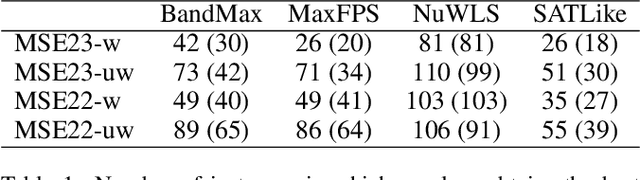
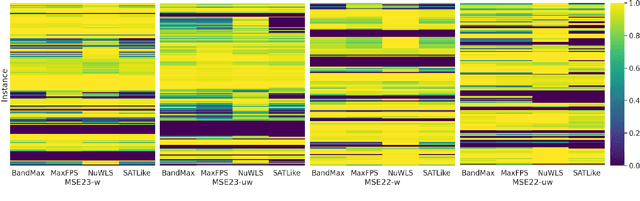
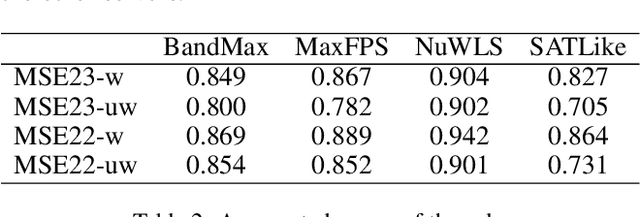
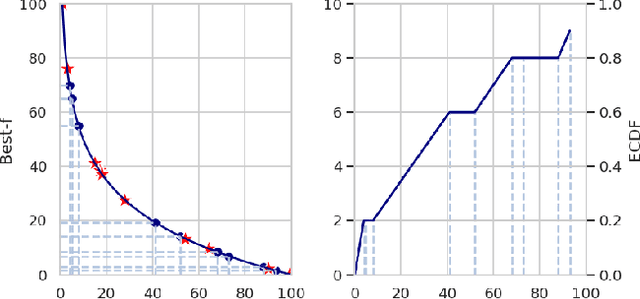
Though numerous solvers have been proposed for the MaxSAT problem, and the benchmark environment such as MaxSAT Evaluations provides a platform for the comparison of the state-of-the-art solvers, existing assessments were usually evaluated based on the quality, e.g., fitness, of the best-found solutions obtained within a given running time budget. However, concerning solely the final obtained solutions regarding specific time budgets may restrict us from comprehending the behavior of the solvers along the convergence process. This paper demonstrates that Empirical Cumulative Distribution Functions can be used to compare MaxSAT local search solvers' anytime performance across multiple problem instances and various time budgets. The assessment reveals distinctions in solvers' performance and displays that the (dis)advantages of solvers adjust along different running times. This work also exhibits that the quantitative and high variance assessment of anytime performance can guide machines, i.e., automatic configurators, to search for better parameter settings. Our experimental results show that the hyperparameter optimization tool, i.e., SMAC, generally achieves better parameter settings of local search when using the anytime performance as the cost function, compared to using the fitness of the best-found solutions.
Performance Analysis on RIS-Aided Wideband Massive MIMO OFDM Systems with Low-Resolution ADCs
Mar 14, 2024This paper investigates a reconfigurable intelligent surface (RIS)-aided wideband massive multiple-input multiple-output (MIMO) orthogonal frequency division multiplexing (OFDM) system with low-resolution analog-to-digital converters (ADCs). Frequency-selective Rician fading channels are considered, and the OFDM data transmission process is presented in time domain. This paper derives the closed-form approximate expression of the uplink achievable rate, based on which the asymptotic system performance is analyzed when the number of the antennas at the base station and the number of reflecting elements at the RIS grow to infinity. Besides, the power scaling laws of the considered system are revealed to provide energy-saving insights. Furthermore, this paper proposes a gradient ascent-based algorithm to design the phase shifts of the RIS for maximizing the minimum user rate. Finally, numerical results are presented to verify the correctness of analytical conclusions and draw insights.
Relaxing Accurate Initialization Constraint for 3D Gaussian Splatting
Mar 14, 2024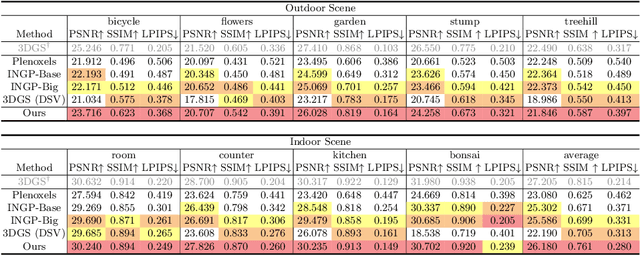
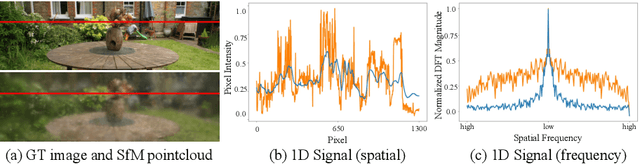
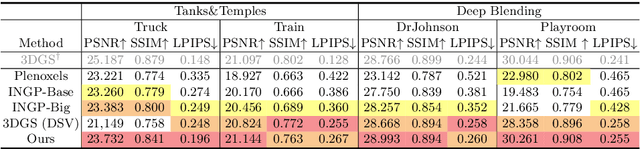
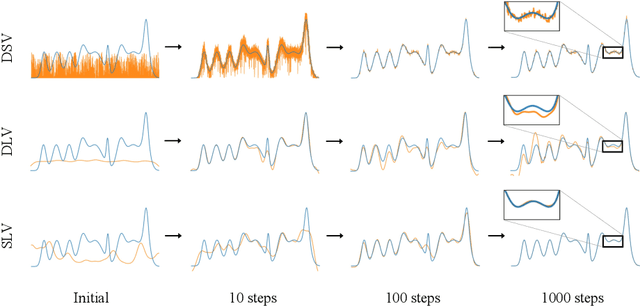
3D Gaussian splatting (3DGS) has recently demonstrated impressive capabilities in real-time novel view synthesis and 3D reconstruction. However, 3DGS heavily depends on the accurate initialization derived from Structure-from-Motion (SfM) methods. When trained with randomly initialized point clouds, 3DGS fails to maintain its ability to produce high-quality images, undergoing large performance drops of 4-5 dB in PSNR. Through extensive analysis of SfM initialization in the frequency domain and analysis of a 1D regression task with multiple 1D Gaussians, we propose a novel optimization strategy dubbed RAIN-GS (Relaxing Accurate Initialization Constraint for 3D Gaussian Splatting), that successfully trains 3D Gaussians from random point clouds. We show the effectiveness of our strategy through quantitative and qualitative comparisons on multiple datasets, largely improving the performance in all settings. Our project page and code can be found at https://ku-cvlab.github.io/RAIN-GS.
An AI-Driven Approach to Wind Turbine Bearing Fault Diagnosis from Acoustic Signals
Mar 14, 2024
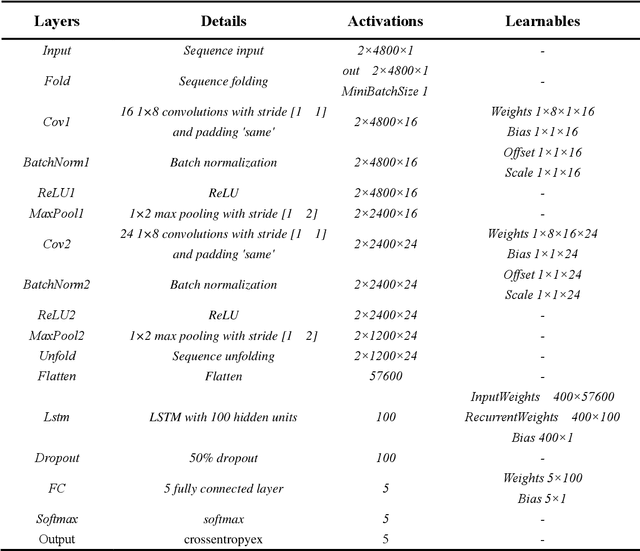
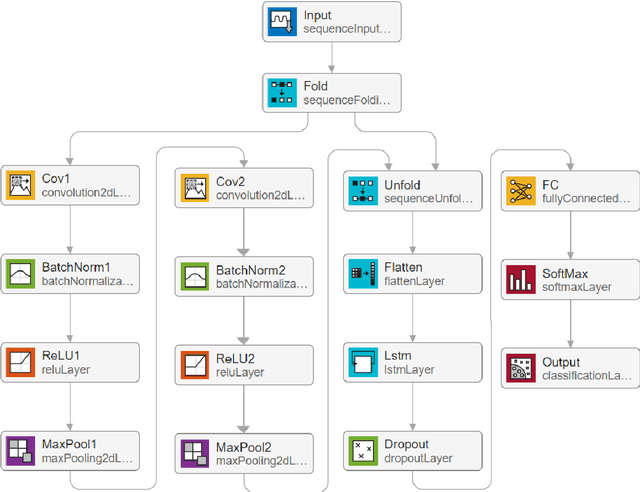
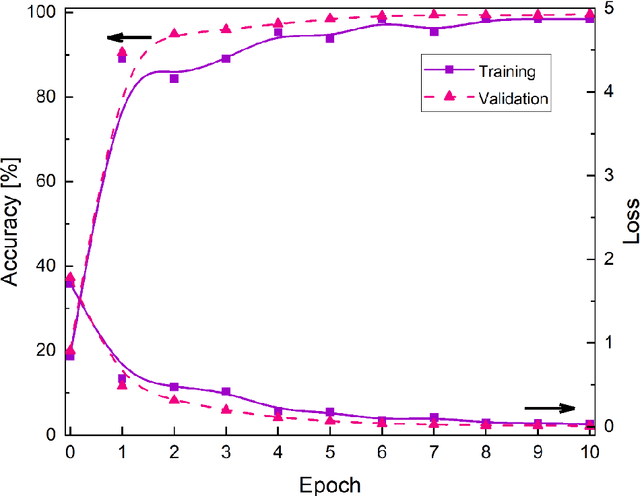
This study aimed to develop a deep learning model for the classification of bearing faults in wind turbine generators from acoustic signals. A convolutional LSTM model was successfully constructed and trained by using audio data from five predefined fault types for both training and validation. To create the dataset, raw audio signal data was collected and processed in frames to capture time and frequency domain information. The model exhibited outstanding accuracy on training samples and demonstrated excellent generalization ability during validation, indicating its proficiency of generalization capability. On the test samples, the model achieved remarkable classification performance, with an overall accuracy exceeding 99.5%, and a false positive rate of less than 1% for normal status. The findings of this study provide essential support for the diagnosis and maintenance of bearing faults in wind turbine generators, with the potential to enhance the reliability and efficiency of wind power generation.
FastVideoEdit: Leveraging Consistency Models for Efficient Text-to-Video Editing
Mar 10, 2024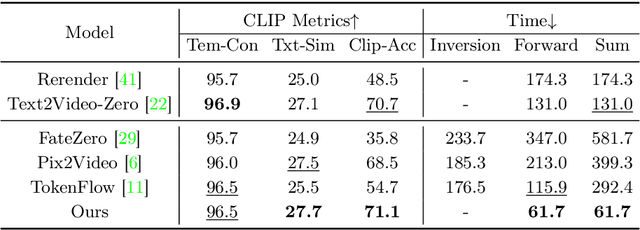
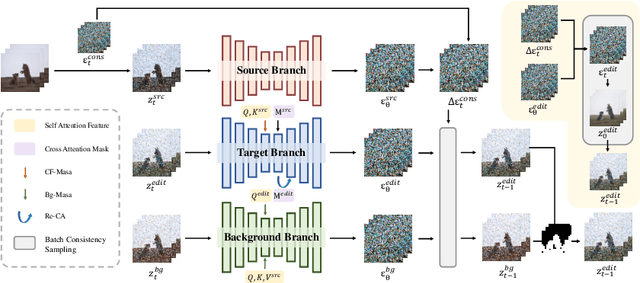
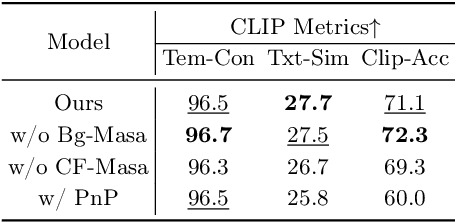

Diffusion models have demonstrated remarkable capabilities in text-to-image and text-to-video generation, opening up possibilities for video editing based on textual input. However, the computational cost associated with sequential sampling in diffusion models poses challenges for efficient video editing. Existing approaches relying on image generation models for video editing suffer from time-consuming one-shot fine-tuning, additional condition extraction, or DDIM inversion, making real-time applications impractical. In this work, we propose FastVideoEdit, an efficient zero-shot video editing approach inspired by Consistency Models (CMs). By leveraging the self-consistency property of CMs, we eliminate the need for time-consuming inversion or additional condition extraction, reducing editing time. Our method enables direct mapping from source video to target video with strong preservation ability utilizing a special variance schedule. This results in improved speed advantages, as fewer sampling steps can be used while maintaining comparable generation quality. Experimental results validate the state-of-the-art performance and speed advantages of FastVideoEdit across evaluation metrics encompassing editing speed, temporal consistency, and text-video alignment.