 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Route Planning with Distributional Reinforcement Learning in a Stochastic Road Network Environment
Apr 19, 2023

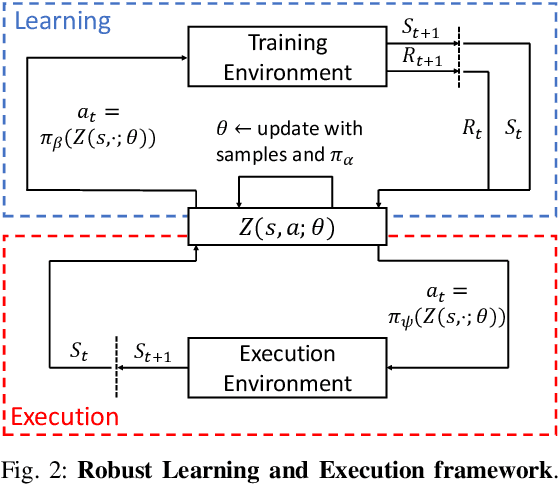
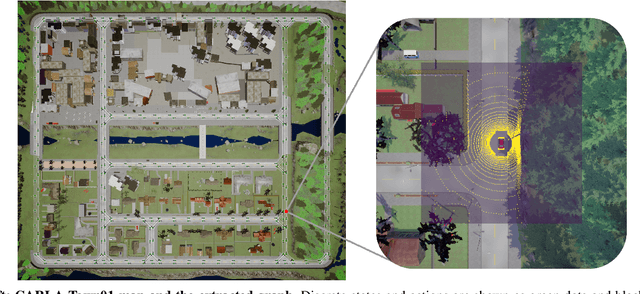

Route planning is essential to mobile robot navigation problems. In recent years, deep reinforcement learning (DRL) has been applied to learning optimal planning policies in stochastic environments without prior knowledge. However, existing works focus on learning policies that maximize the expected return, the performance of which can vary greatly when the level of stochasticity in the environment is high. In this work, we propose a distributional reinforcement learning based framework that learns return distributions which explicitly reflect environmental stochasticity. Policies based on the second-order stochastic dominance (SSD) relation can be used to make adjustable route decisions according to user preference on performance robustness. Our proposed method is evaluated in a simulated road network environment, and experimental results show that our method is able to plan the shortest routes that minimize stochasticity in travel time when robustness is preferred, while other state-of-the-art DRL methods are agnostic to environmental stochasticity.
Power Law Trends in Speedrunning and Machine Learning
Apr 19, 2023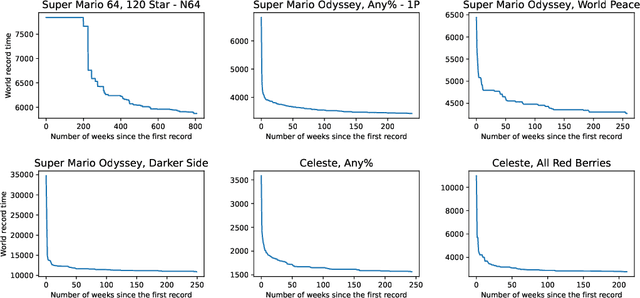
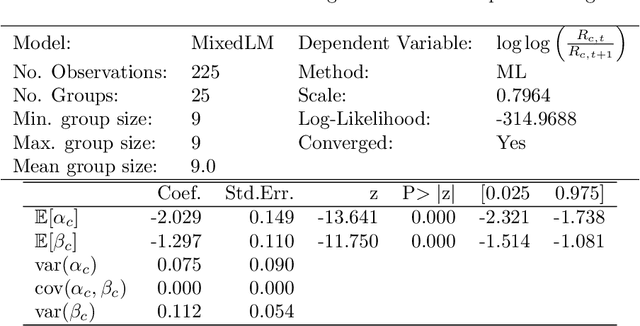
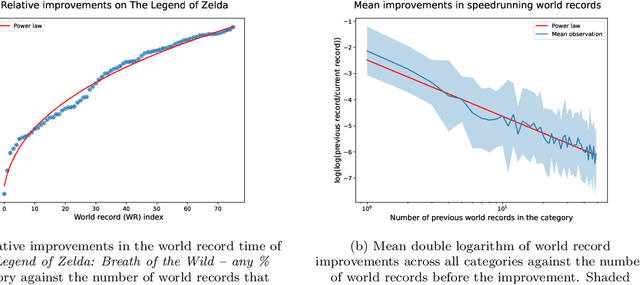

We find that improvements in speedrunning world records follow a power law pattern. Using this observation, we answer an outstanding question from previous work: How do we improve on the baseline of predicting no improvement when forecasting speedrunning world records out to some time horizon, such as one month? Using a random effects model, we improve on this baseline for relative mean square error made on predicting out-of-sample world record improvements as the comparison metric at a $p < 10^{-5}$ significance level. The same set-up improves \textit{even} on the ex-post best exponential moving average forecasts at a $p = 0.15$ significance level while having access to substantially fewer data points. We demonstrate the effectiveness of this approach by applying it to Machine Learning benchmarks and achieving forecasts that exceed a baseline. Finally, we interpret the resulting model to suggest that 1) ML benchmarks are far from saturation and 2) sudden large improvements in Machine Learning are unlikely but cannot be ruled out.
Big-Little Adaptive Neural Networks on Low-Power Near-Subthreshold Processors
Apr 19, 2023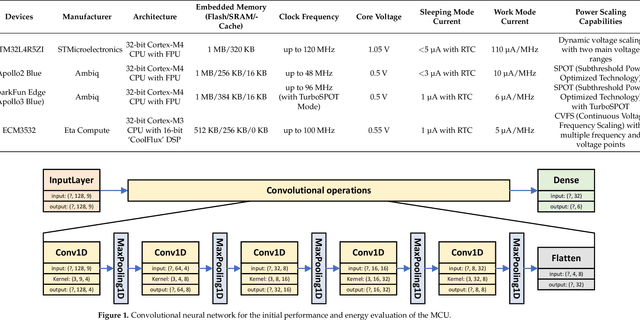
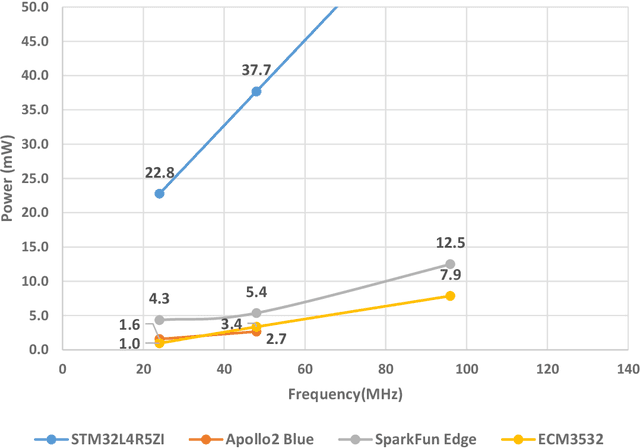
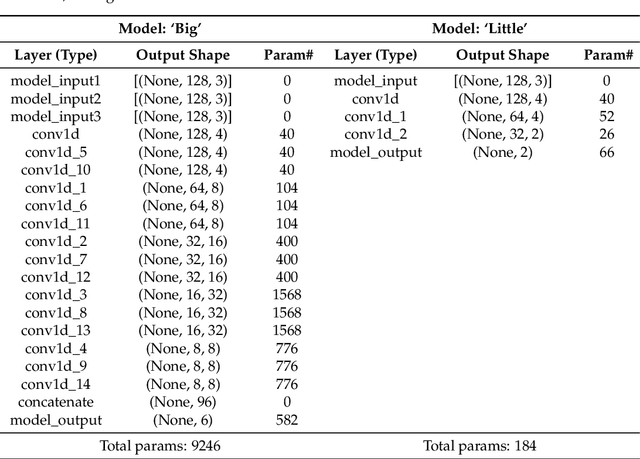
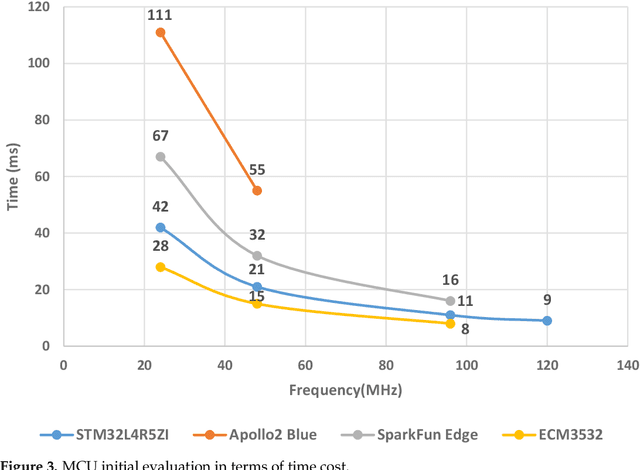
This paper investigates the energy savings that near-subthreshold processors can obtain in edge AI applications and proposes strategies to improve them while maintaining the accuracy of the application. The selected processors deploy adaptive voltage scaling techniques in which the frequency and voltage levels of the processor core are determined at the run-time. In these systems, embedded RAM and flash memory size is typically limited to less than 1 megabyte to save power. This limited memory imposes restrictions on the complexity of the neural networks model that can be mapped to these devices and the required trade-offs between accuracy and battery life. To address these issues, we propose and evaluate alternative 'big-little' neural network strategies to improve battery life while maintaining prediction accuracy. The strategies are applied to a human activity recognition application selected as a demonstrator that shows that compared to the original network, the best configurations obtain an energy reduction measured at 80% while maintaining the original level of inference accuracy.
* 27 pages, 17 figures, https://github.com/DarkSZChao/Big-Little_NN_Strategies
Learning policies for resource allocation in business processes
Apr 19, 2023
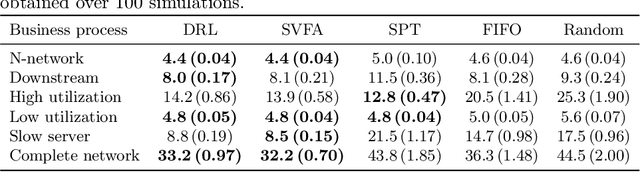
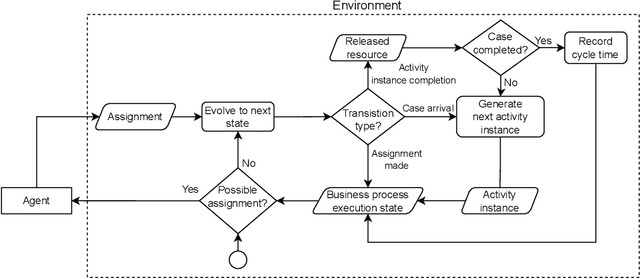
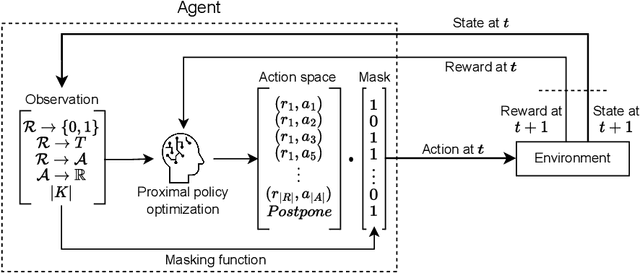
Resource allocation is the assignment of resources to activities that must be executed in a business process at a particular moment at run-time. While resource allocation is well-studied in other fields, such as manufacturing, there exist only a few methods in business process management. Existing methods are not suited for application in large business processes or focus on optimizing resource allocation for a single case rather than for all cases combined. To fill this gap, this paper proposes two learning-based methods for resource allocation in business processes: a deep reinforcement learning-based approach and a score-based value function approximation approach. The two methods are compared against existing heuristics in a set of scenarios that represent typical business process structures and on a complete network that represents a realistic business process. The results show that our learning-based methods outperform or are competitive with common heuristics in most scenarios and outperform heuristics in the complete network.
Recurrence without Recurrence: Stable Video Landmark Detection with Deep Equilibrium Models
Apr 02, 2023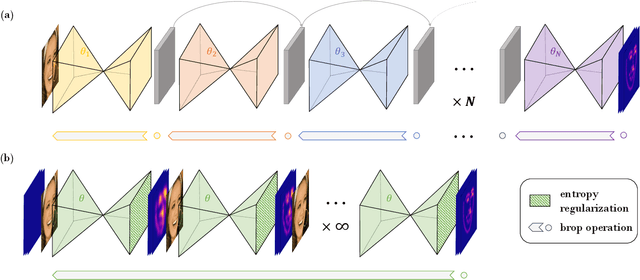
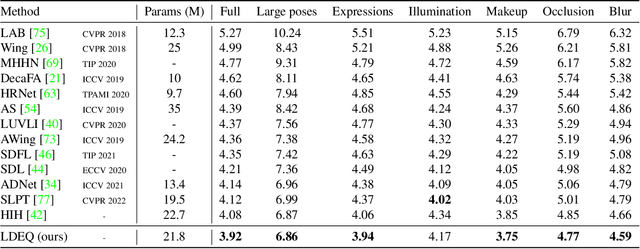
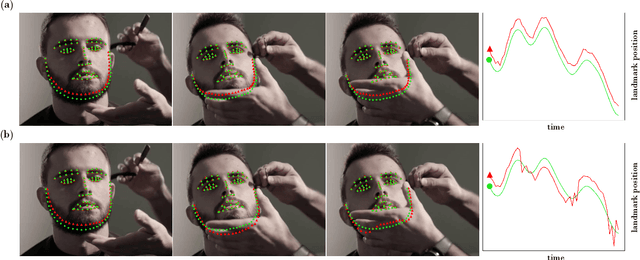
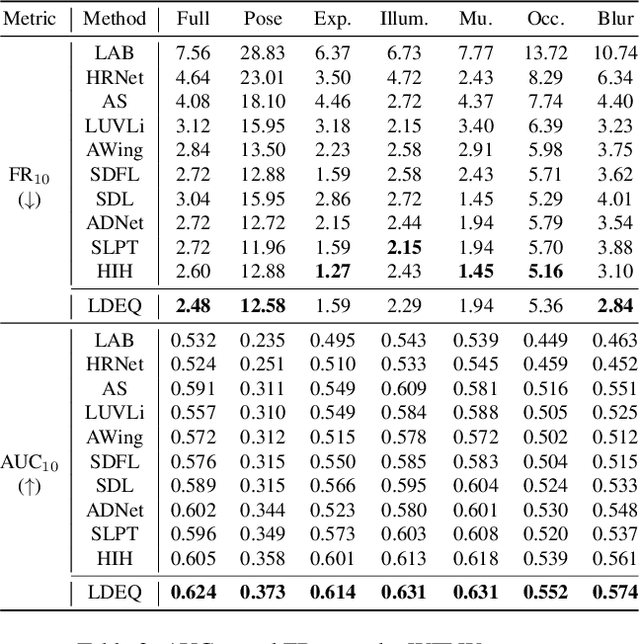
Cascaded computation, whereby predictions are recurrently refined over several stages, has been a persistent theme throughout the development of landmark detection models. In this work, we show that the recently proposed Deep Equilibrium Model (DEQ) can be naturally adapted to this form of computation. Our Landmark DEQ (LDEQ) achieves state-of-the-art performance on the challenging WFLW facial landmark dataset, reaching $3.92$ NME with fewer parameters and a training memory cost of $\mathcal{O}(1)$ in the number of recurrent modules. Furthermore, we show that DEQs are particularly suited for landmark detection in videos. In this setting, it is typical to train on still images due to the lack of labelled videos. This can lead to a ``flickering'' effect at inference time on video, whereby a model can rapidly oscillate between different plausible solutions across consecutive frames. By rephrasing DEQs as a constrained optimization, we emulate recurrence at inference time, despite not having access to temporal data at training time. This Recurrence without Recurrence (RwR) paradigm helps in reducing landmark flicker, which we demonstrate by introducing a new metric, normalized mean flicker (NMF), and contributing a new facial landmark video dataset (WFLW-V) targeting landmark uncertainty. On the WFLW-V hard subset made up of $500$ videos, our LDEQ with RwR improves the NME and NMF by $10$ and $13\%$ respectively, compared to the strongest previously published model using a hand-tuned conventional filter.
FANS: Fast Non-Autoregressive Sequence Generation for Item List Continuation
Apr 02, 2023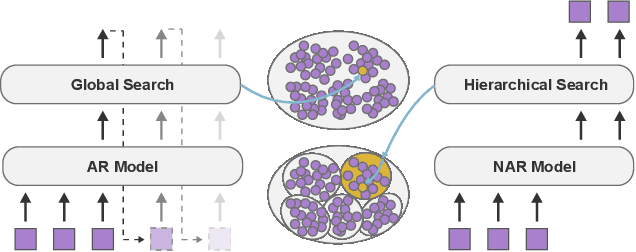
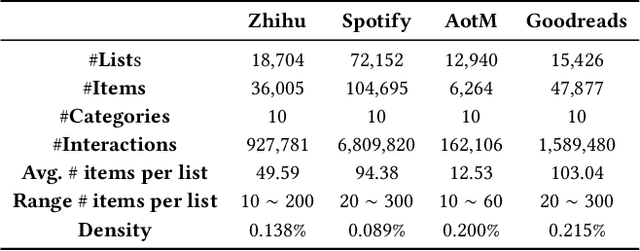
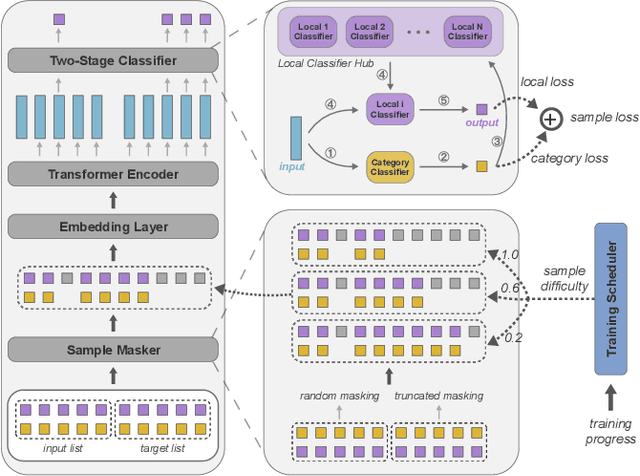
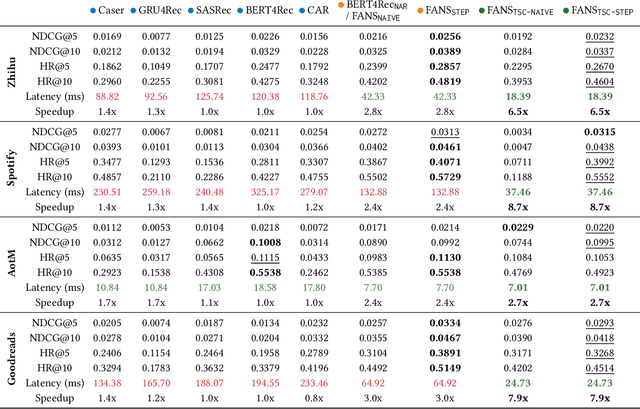
User-curated item lists, such as video-based playlists on Youtube and book-based lists on Goodreads, have become prevalent for content sharing on online platforms. Item list continuation is proposed to model the overall trend of a list and predict subsequent items. Recently, Transformer-based models have shown promise in comprehending contextual information and capturing item relationships in a list. However, deploying them in real-time industrial applications is challenging, mainly because the autoregressive generation mechanism used in them is time-consuming. In this paper, we propose a novel fast non-autoregressive sequence generation model, namely FANS, to enhance inference efficiency and quality for item list continuation. First, we use a non-autoregressive generation mechanism to decode next $K$ items simultaneously instead of one by one in existing models. Then, we design a two-stage classifier to replace the vanilla classifier used in current transformer-based models to further reduce the decoding time. Moreover, to improve the quality of non-autoregressive generation, we employ a curriculum learning strategy to optimize training. Experimental results on four real-world item list continuation datasets including Zhihu, Spotify, AotM, and Goodreads show that our FANS model can significantly improve inference efficiency (up to 8.7x) while achieving competitive or better generation quality for item list continuation compared with the state-of-the-art autoregressive models. We also validate the efficiency of FANS in an industrial setting. Our source code and data will be available at MindSpore/models and Github.
Traffic Volume Prediction using Memory-Based Recurrent Neural Networks: A comparative analysis of LSTM and GRU
Mar 22, 2023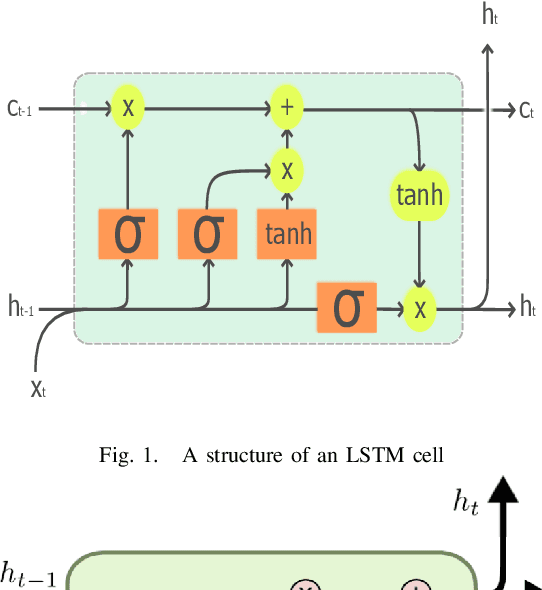
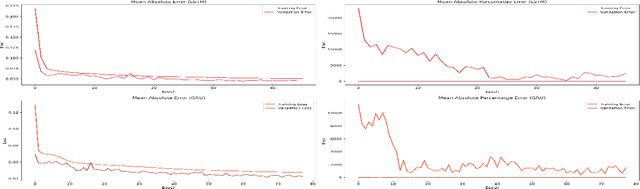
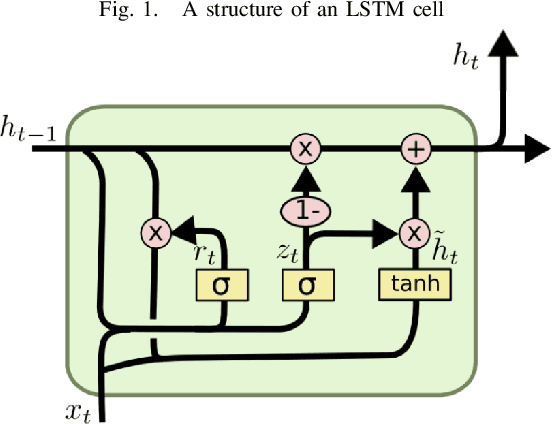
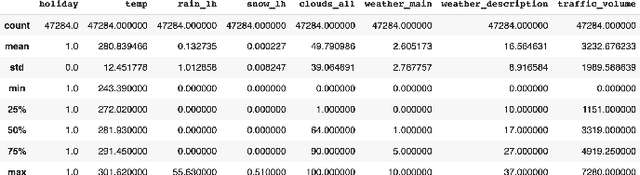
Predicting traffic volume in real-time can improve both traffic flow and road safety. A precise traffic volume forecast helps alert drivers to the flow of traffic along their preferred routes, preventing potential deadlock situations. Existing parametric models cannot reliably forecast traffic volume in dynamic and complex traffic conditions. Therefore, in order to evaluate and forecast the traffic volume for every given time step in a real-time manner, we develop non-linear memory-based deep neural network models. Our extensive experiments run on the Metro Interstate Traffic Volume dataset demonstrate the effectiveness of the proposed models in predicting traffic volume in highly dynamic and heterogeneous traffic environments.
Knowledge Distillation from 3D to Bird's-Eye-View for LiDAR Semantic Segmentation
Apr 22, 2023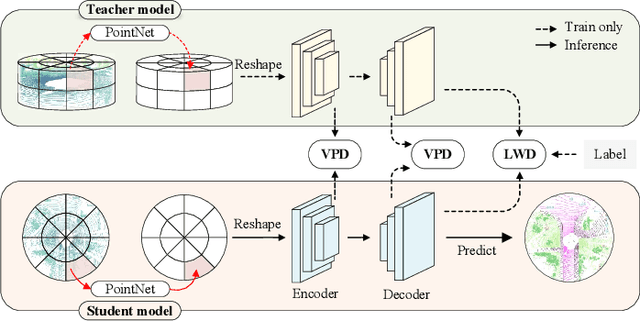
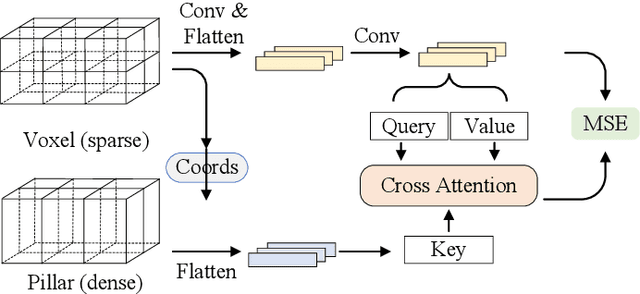
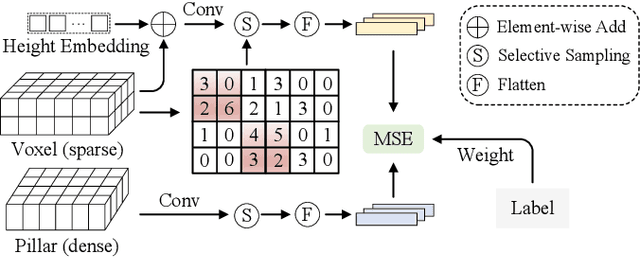
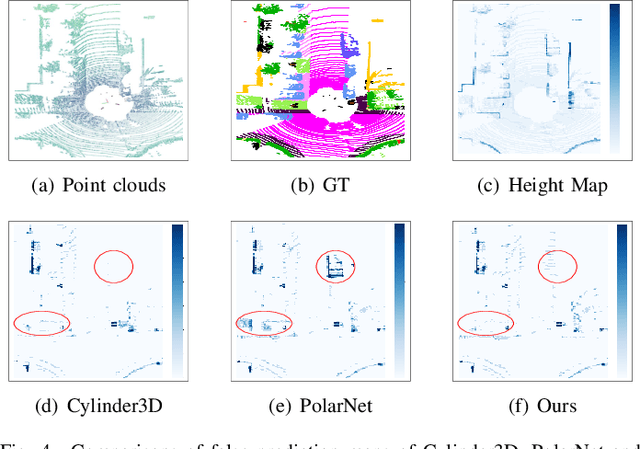
LiDAR point cloud segmentation is one of the most fundamental tasks for autonomous driving scene understanding. However, it is difficult for existing models to achieve both high inference speed and accuracy simultaneously. For example, voxel-based methods perform well in accuracy, while Bird's-Eye-View (BEV)-based methods can achieve real-time inference. To overcome this issue, we develop an effective 3D-to-BEV knowledge distillation method that transfers rich knowledge from 3D voxel-based models to BEV-based models. Our framework mainly consists of two modules: the voxel-to-pillar distillation module and the label-weight distillation module. Voxel-to-pillar distillation distills sparse 3D features to BEV features for middle layers to make the BEV-based model aware of more structural and geometric information. Label-weight distillation helps the model pay more attention to regions with more height information. Finally, we conduct experiments on the SemanticKITTI dataset and Paris-Lille-3D. The results on SemanticKITTI show more than 5% improvement on the test set, especially for classes such as motorcycle and person, with more than 15% improvement. The code can be accessed at https://github.com/fengjiang5/Knowledge-Distillation-from-Cylinder3D-to-PolarNet.
Fast Diffusion Probabilistic Model Sampling through the lens of Backward Error Analysis
Apr 22, 2023
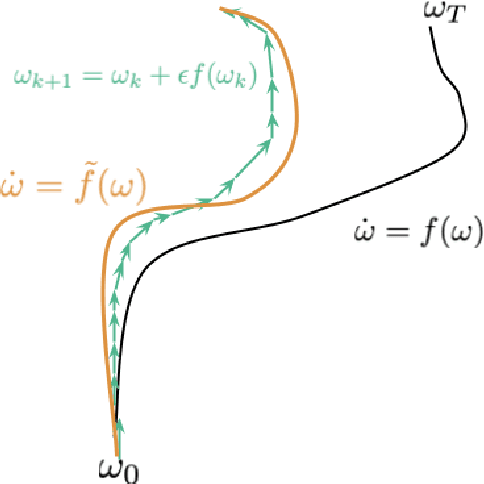
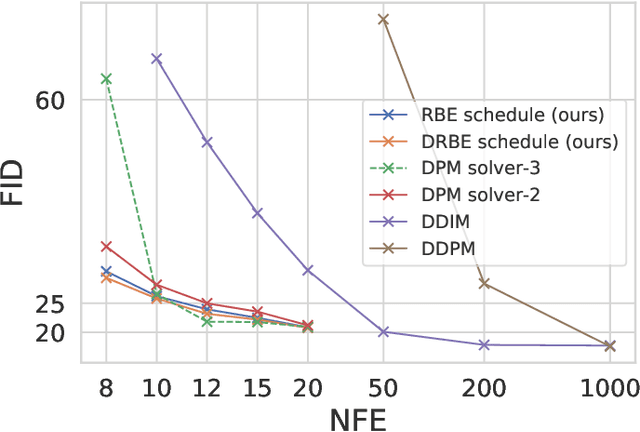
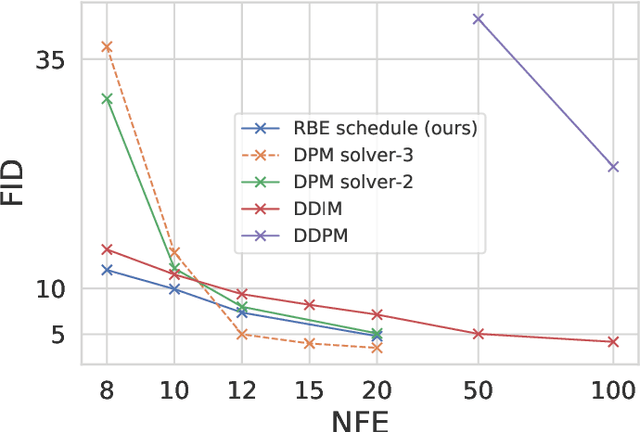
Denoising diffusion probabilistic models (DDPMs) are a class of powerful generative models. The past few years have witnessed the great success of DDPMs in generating high-fidelity samples. A significant limitation of the DDPMs is the slow sampling procedure. DDPMs generally need hundreds or thousands of sequential function evaluations (steps) of neural networks to generate a sample. This paper aims to develop a fast sampling method for DDPMs requiring much fewer steps while retaining high sample quality. The inference process of DDPMs approximates solving the corresponding diffusion ordinary differential equations (diffusion ODEs) in the continuous limit. This work analyzes how the backward error affects the diffusion ODEs and the sample quality in DDPMs. We propose fast sampling through the \textbf{Restricting Backward Error schedule (RBE schedule)} based on dynamically moderating the long-time backward error. Our method accelerates DDPMs without any further training. Our experiments show that sampling with an RBE schedule generates high-quality samples within only 8 to 20 function evaluations on various benchmark datasets. We achieved 12.01 FID in 8 function evaluations on the ImageNet $128\times128$, and a $20\times$ speedup compared with previous baseline samplers.
Latent Evolution Model for Change Point Detection in Time-varying Networks
Dec 17, 2022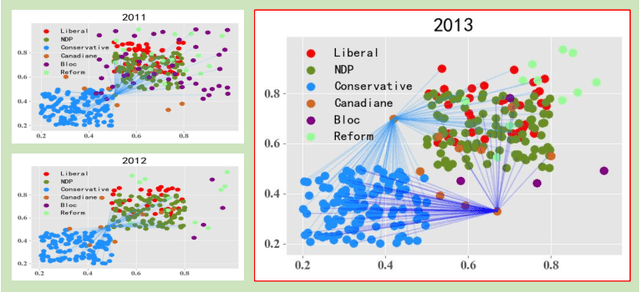
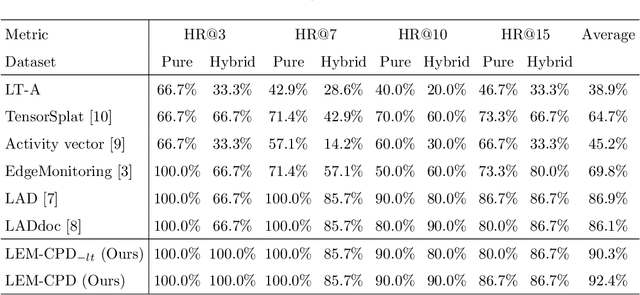
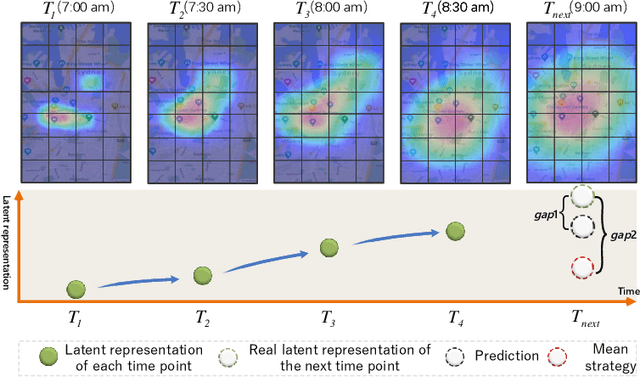
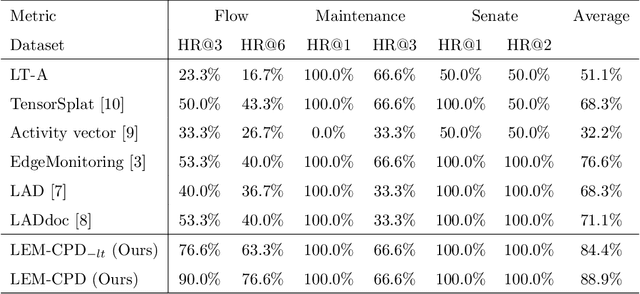
Graph-based change point detection (CPD) play an irreplaceable role in discovering anomalous graphs in the time-varying network. While several techniques have been proposed to detect change points by identifying whether there is a significant difference between the target network and successive previous ones, they neglect the natural evolution of the network. In practice, real-world graphs such as social networks, traffic networks, and rating networks are constantly evolving over time. Considering this problem, we treat the problem as a prediction task and propose a novel CPD method for dynamic graphs via a latent evolution model. Our method focuses on learning the low-dimensional representations of networks and capturing the evolving patterns of these learned latent representations simultaneously. After having the evolving patterns, a prediction of the target network can be achieved. Then, we can detect the change points by comparing the prediction and the actual network by leveraging a trade-off strategy, which balances the importance between the prediction network and the normal graph pattern extracted from previous networks. Intensive experiments conducted on both synthetic and real-world datasets show the effectiveness and superiority of our model.