 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robotic Navigation Autonomy for Subretinal Injection via Intelligent Real-Time Virtual iOCT Volume Slicing
Jan 17, 2023
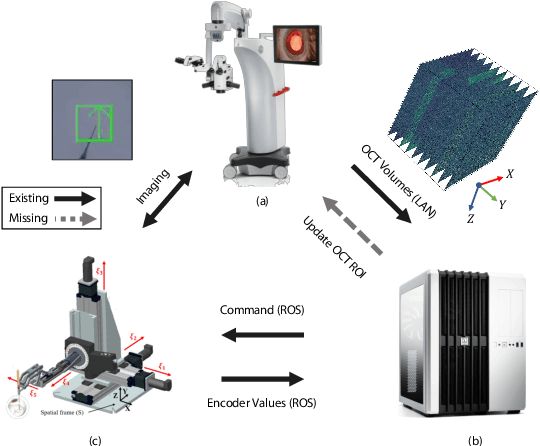
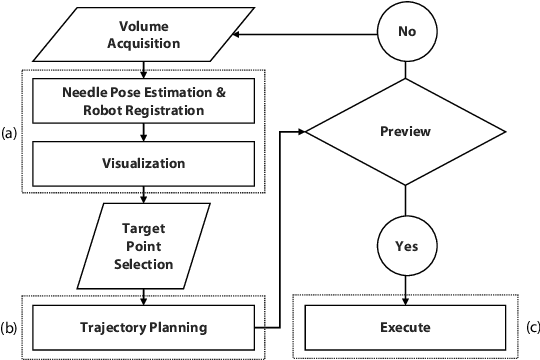

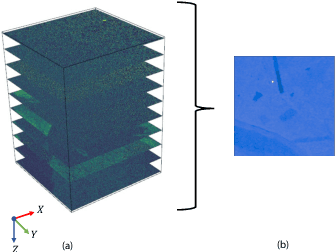
In the last decade, various robotic platforms have been introduced that could support delicate retinal surgeries. Concurrently, to provide semantic understanding of the surgical area, recent advances have enabled microscope-integrated intraoperative Optical Coherent Tomography (iOCT) with high-resolution 3D imaging at near video rate. The combination of robotics and semantic understanding enables task autonomy in robotic retinal surgery, such as for subretinal injection. This procedure requires precise needle insertion for best treatment outcomes. However, merging robotic systems with iOCT introduces new challenges. These include, but are not limited to high demands on data processing rates and dynamic registration of these systems during the procedure. In this work, we propose a framework for autonomous robotic navigation for subretinal injection, based on intelligent real-time processing of iOCT volumes. Our method consists of an instrument pose estimation method, an online registration between the robotic and the iOCT system, and trajectory planning tailored for navigation to an injection target. We also introduce intelligent virtual B-scans, a volume slicing approach for rapid instrument pose estimation, which is enabled by Convolutional Neural Networks (CNNs). Our experiments on ex-vivo porcine eyes demonstrate the precision and repeatability of the method. Finally, we discuss identified challenges in this work and suggest potential solutions to further the development of such systems.
Motion Informed Object Detection of Small Insects in Time-lapse Camera Recordings
Dec 01, 2022
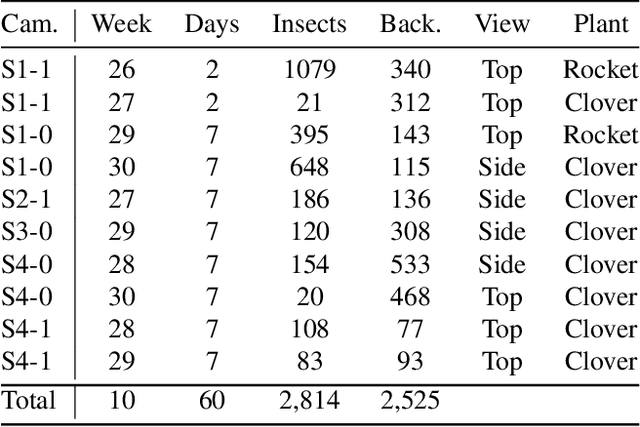

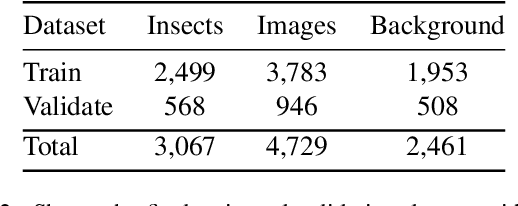
Insects as pollinators play a key role in ecosystem management and world food production. However, insect populations are declining, calling for a necessary global demand of insect monitoring. Existing methods analyze video or time-lapse images of insects in nature, but the analysis is challenging since insects are small objects in complex and dynamic scenes of natural vegetation. The current paper provides a dataset of primary honeybees visiting three different plant species during two months of summer-period. The dataset consists of more than 700,000 time-lapse images from multiple cameras, including more than 100,000 annotated images. The paper presents a new method pipeline for detecting insects in time-lapse RGB-images. The pipeline consists of a two-step process. Firstly, the time-lapse RGB-images are preprocessed to enhance insects in the images. We propose a new prepossessing enhancement method: Motion-Informed-enhancement. The technique uses motion and colors to enhance insects in images. The enhanced images are subsequently fed into a Convolutional Neural network (CNN) object detector. Motion-Informed-enhancement improves the deep learning object detectors You Only Look Once (YOLO) and Faster Region-based Convolutional Neural Networks (Faster R-CNN). Using Motion-Informed-enhancement the YOLO-detector improves average micro F1-score from 0.49 to 0.71, and the Faster R-CNN-detector improves average micro F1-score from 0.32 to 0.56 on the our dataset. Our datasets are published on: https://vision.eng.au.dk/mie/
Self-Supervised Scene Dynamic Recovery from Rolling Shutter Images and Events
Apr 19, 2023
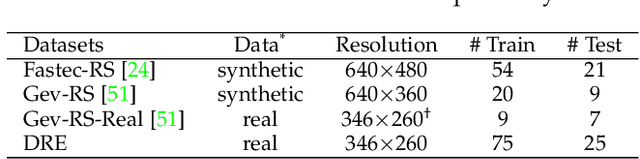
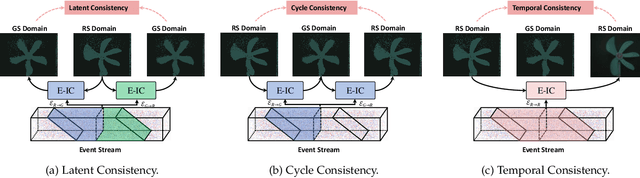

Scene Dynamic Recovery (SDR) by inverting distorted Rolling Shutter (RS) images to an undistorted high frame-rate Global Shutter (GS) video is a severely ill-posed problem due to the missing temporal dynamic information in both RS intra-frame scanlines and inter-frame exposures, particularly when prior knowledge about camera/object motions is unavailable. Commonly used artificial assumptions on scenes/motions and data-specific characteristics are prone to producing sub-optimal solutions in real-world scenarios. To address this challenge, we propose an event-based SDR network within a self-supervised learning paradigm, i.e., SelfUnroll. We leverage the extremely high temporal resolution of event cameras to provide accurate inter/intra-frame dynamic information. Specifically, an Event-based Inter/intra-frame Compensator (E-IC) is proposed to predict the per-pixel dynamic between arbitrary time intervals, including the temporal transition and spatial translation. Exploring connections in terms of RS-RS, RS-GS, and GS-RS, we explicitly formulate mutual constraints with the proposed E-IC, resulting in supervisions without ground-truth GS images. Extensive evaluations over synthetic and real datasets demonstrate that the proposed method achieves state-of-the-art and shows remarkable performance for event-based RS2GS inversion in real-world scenarios. The dataset and code are available at https://w3un.github.io/selfunroll/.
Decadal Temperature Prediction via Chaotic Behavior Tracking
Apr 19, 2023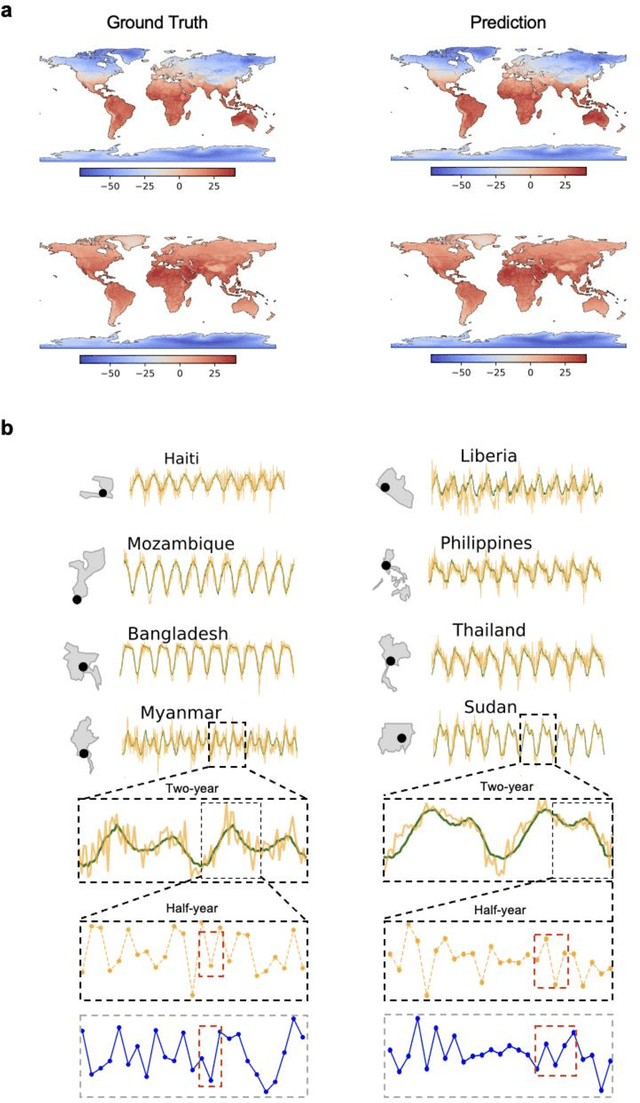
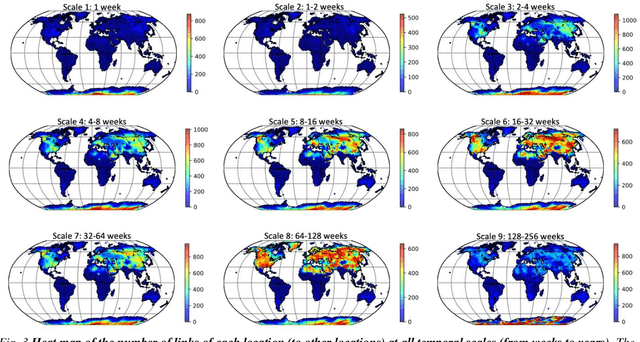
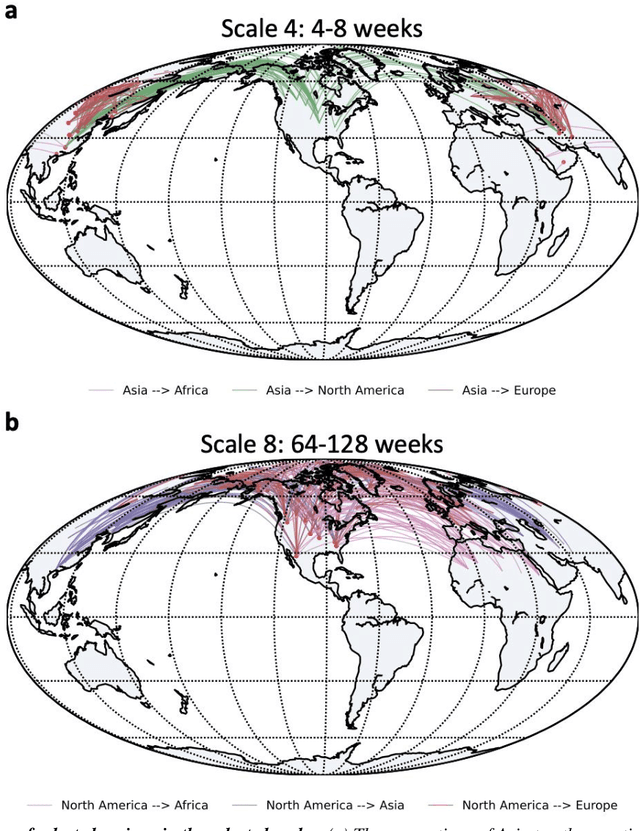
Decadal temperature prediction provides crucial information for quantifying the expected effects of future climate changes and thus informs strategic planning and decision-making in various domains. However, such long-term predictions are extremely challenging, due to the chaotic nature of temperature variations. Moreover, the usefulness of existing simulation-based and machine learning-based methods for this task is limited because initial simulation or prediction errors increase exponentially over time. To address this challenging task, we devise a novel prediction method involving an information tracking mechanism that aims to track and adapt to changes in temperature dynamics during the prediction phase by providing probabilistic feedback on the prediction error of the next step based on the current prediction. We integrate this information tracking mechanism, which can be considered as a model calibrator, into the objective function of our method to obtain the corrections needed to avoid error accumulation. Our results show the ability of our method to accurately predict global land-surface temperatures over a decadal range. Furthermore, we demonstrate that our results are meaningful in a real-world context: the temperatures predicted using our method are consistent with and can be used to explain the well-known teleconnections within and between different continents.
MTrainS: Improving DLRM training efficiency using heterogeneous memories
Apr 19, 2023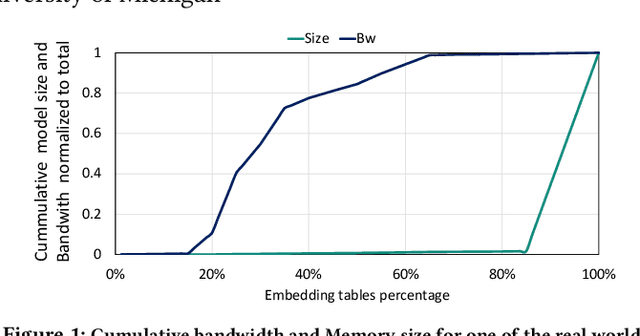
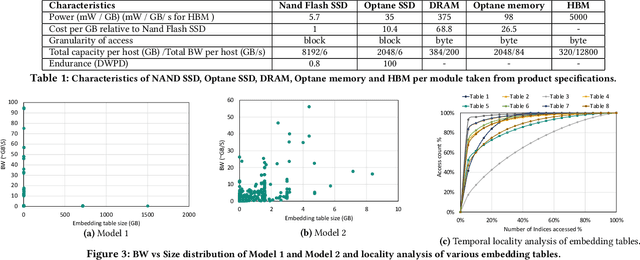
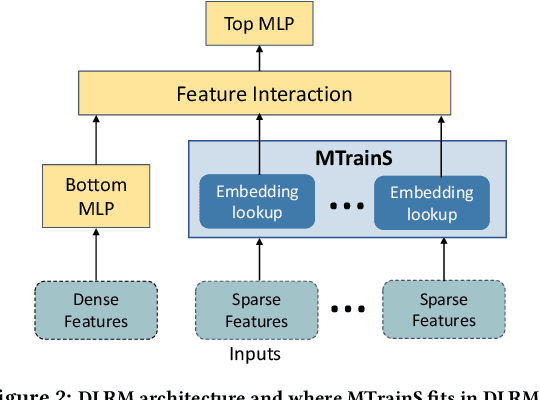

Recommendation models are very large, requiring terabytes (TB) of memory during training. In pursuit of better quality, the model size and complexity grow over time, which requires additional training data to avoid overfitting. This model growth demands a large number of resources in data centers. Hence, training efficiency is becoming considerably more important to keep the data center power demand manageable. In Deep Learning Recommendation Models (DLRM), sparse features capturing categorical inputs through embedding tables are the major contributors to model size and require high memory bandwidth. In this paper, we study the bandwidth requirement and locality of embedding tables in real-world deployed models. We observe that the bandwidth requirement is not uniform across different tables and that embedding tables show high temporal locality. We then design MTrainS, which leverages heterogeneous memory, including byte and block addressable Storage Class Memory for DLRM hierarchically. MTrainS allows for higher memory capacity per node and increases training efficiency by lowering the need to scale out to multiple hosts in memory capacity bound use cases. By optimizing the platform memory hierarchy, we reduce the number of nodes for training by 4-8X, saving power and cost of training while meeting our target training performance.
Progressive Transfer Learning for Dexterous In-Hand Manipulation with Multi-Fingered Anthropomorphic Hand
Apr 19, 2023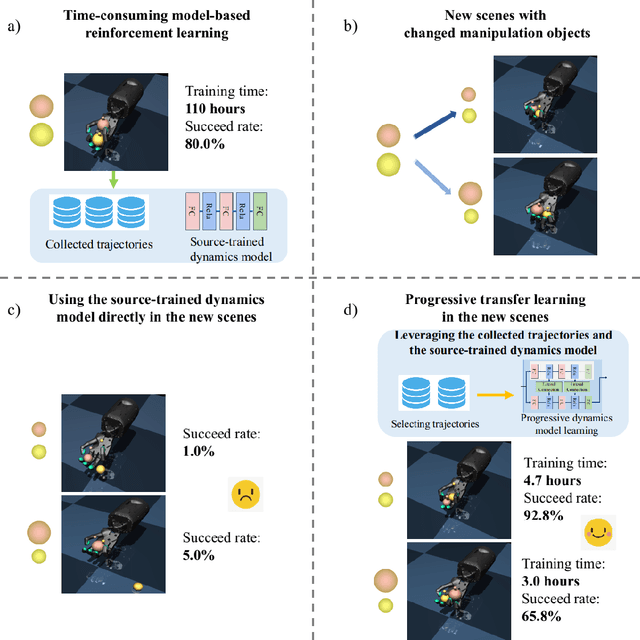
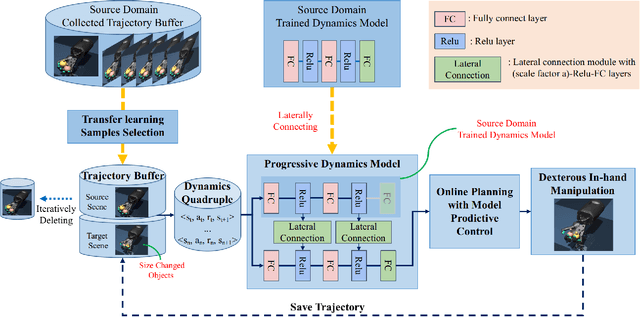
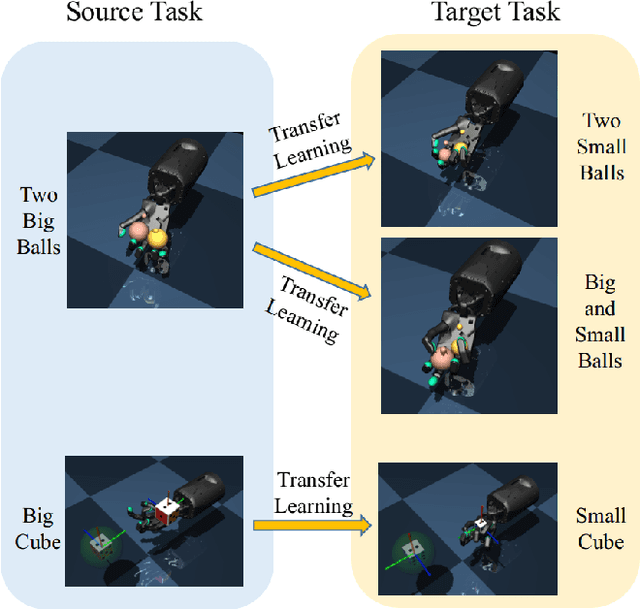
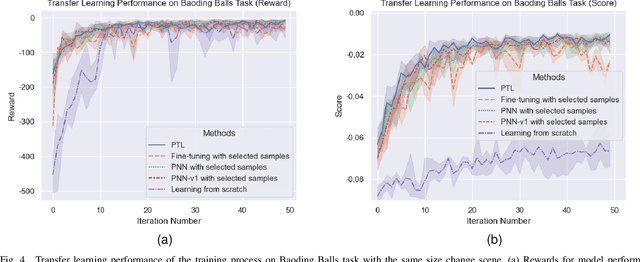
Dexterous in-hand manipulation for a multi-fingered anthropomorphic hand is extremely difficult because of the high-dimensional state and action spaces, rich contact patterns between the fingers and objects. Even though deep reinforcement learning has made moderate progress and demonstrated its strong potential for manipulation, it is still faced with certain challenges, such as large-scale data collection and high sample complexity. Especially, for some slight change scenes, it always needs to re-collect vast amounts of data and carry out numerous iterations of fine-tuning. Remarkably, humans can quickly transfer learned manipulation skills to different scenarios with little supervision. Inspired by human flexible transfer learning capability, we propose a novel dexterous in-hand manipulation progressive transfer learning framework (PTL) based on efficiently utilizing the collected trajectories and the source-trained dynamics model. This framework adopts progressive neural networks for dynamics model transfer learning on samples selected by a new samples selection method based on dynamics properties, rewards and scores of the trajectories. Experimental results on contact-rich anthropomorphic hand manipulation tasks show that our method can efficiently and effectively learn in-hand manipulation skills with a few online attempts and adjustment learning under the new scene. Compared to learning from scratch, our method can reduce training time costs by 95%.
Spatially Constrained Time-Optimal Motion Planning
Oct 05, 2022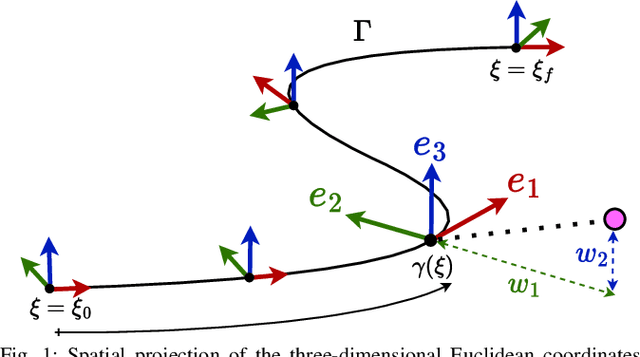

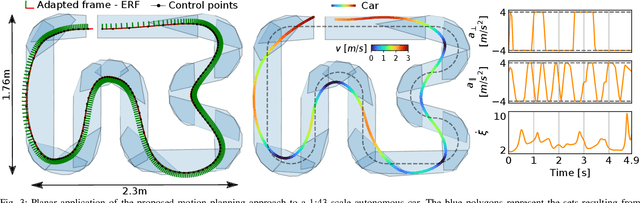
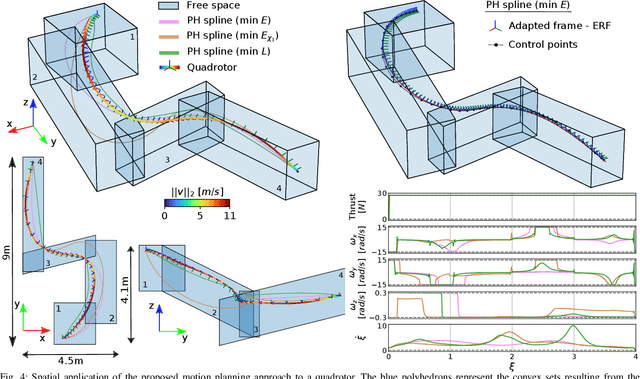
This paper focuses on spatial time-optimal motion planning, a generalization of the exact time-optimal path following problem that allows the system to plan within a predefined space. In contrast to state-of-the-art methods, we drop the assumption that a collision-free geometric reference is given. Instead, we present a two-stage motion planning method that solely relies on a goal location and a geometric representation of the environment to compute a time-optimal trajectory that is compliant with system dynamics and constraints. To do so, the proposed scheme first computes an obstacle-free Pythagorean Hodograph parametric spline, and second solves a spatially reformulated minimum-time optimization problem. The spline obtained in the first stage is not a geometric reference, but an extension of the environment representation, and thus, time-optimality of the solution is guaranteed. The efficacy of the proposed approach is benchmarked by a known planar example and validated in a more complex spatial system, illustrating its versatility and applicability.
Toward Multi-Service Edge-Intelligence Paradigm: Temporal-Adaptive Prediction for Time-Critical Control over Wireless
Dec 12, 2022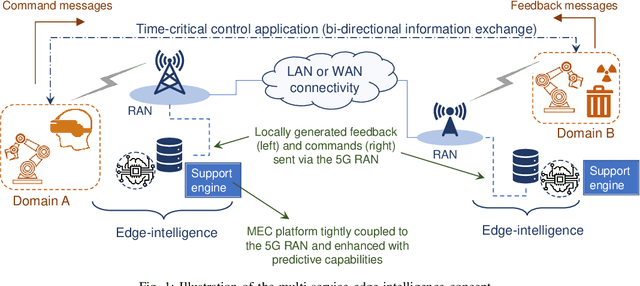
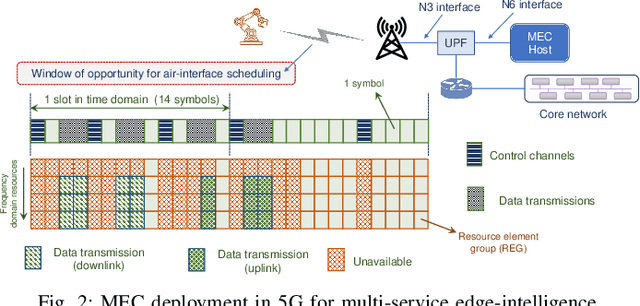
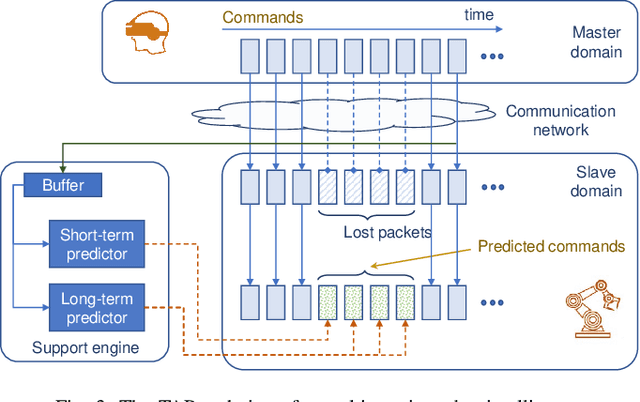
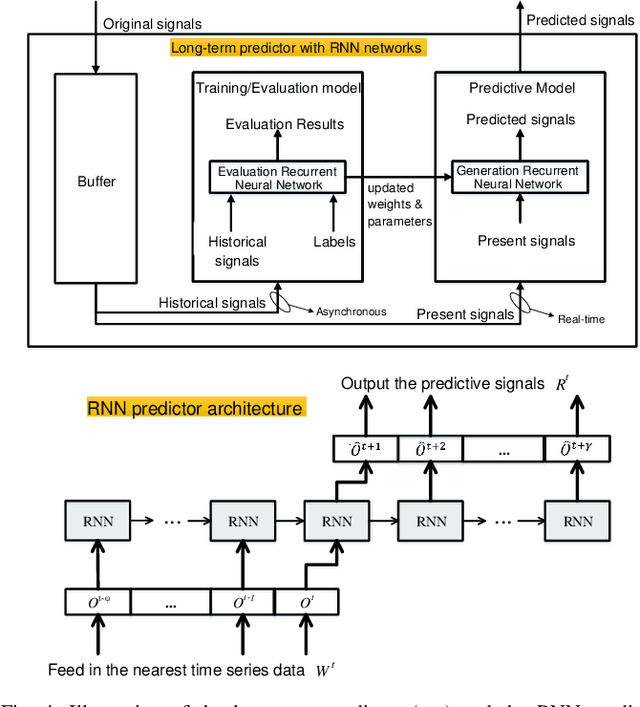
Time-critical control applications typically pose stringent connectivity requirements for communication networks. The imperfections associated with the wireless medium such as packet losses, synchronization errors, and varying delays have a detrimental effect on performance of real-time control, often with safety implications. This paper introduces multi-service edge-intelligence as a new paradigm for realizing time-critical control over wireless. It presents the concept of multi-service edge-intelligence which revolves around tight integration of wireless access, edge-computing and machine learning techniques, in order to provide stability guarantees under wireless imperfections. The paper articulates some of the key system design aspects of multi-service edge-intelligence. It also presents a temporal-adaptive prediction technique to cope with dynamically changing wireless environments. It provides performance results in a robotic teleoperation scenario. Finally, it discusses some open research and design challenges for multi-service edge-intelligence.
PCPNet: An Efficient and Semantic-Enhanced Transformer Network for Point Cloud Prediction
Apr 16, 2023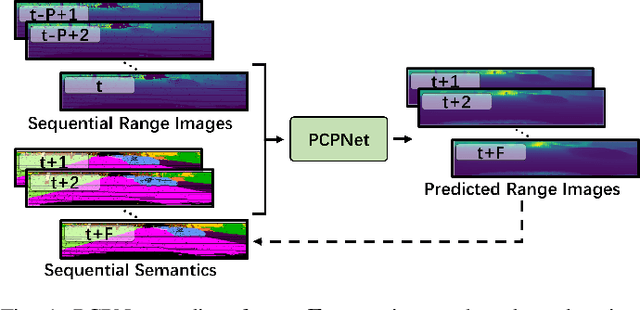
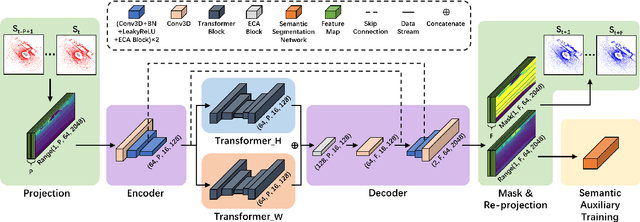
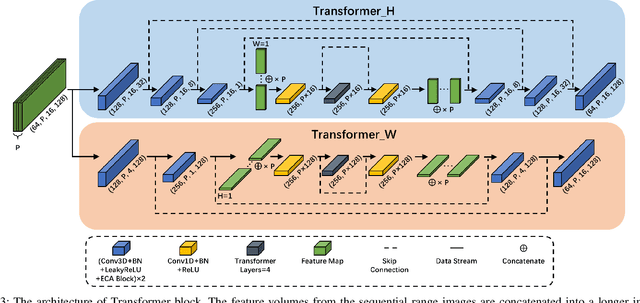
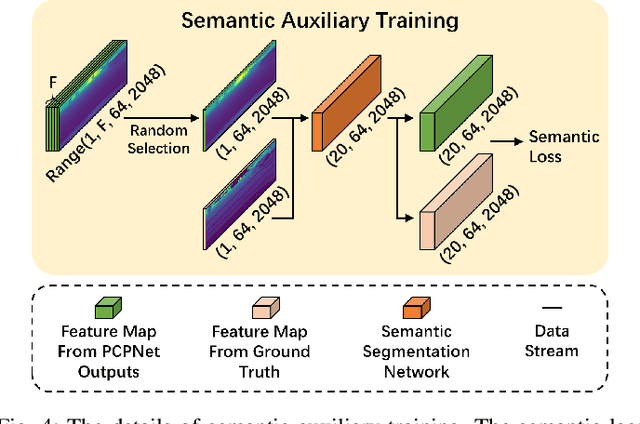
The ability to predict future structure features of environments based on past perception information is extremely needed by autonomous vehicles, which helps to make the following decision-making and path planning more reasonable. Recently, point cloud prediction (PCP) is utilized to predict and describe future environmental structures by the point cloud form. In this letter, we propose a novel efficient Transformer-based network to predict the future LiDAR point clouds exploiting the past point cloud sequences. We also design a semantic auxiliary training strategy to make the predicted LiDAR point cloud sequence semantically similar to the ground truth and thus improves the significance of the deployment for more tasks in real-vehicle applications. Our approach is completely self-supervised, which means it does not require any manual labeling and has a solid generalization ability toward different environments. The experimental results show that our method outperforms the state-of-the-art PCP methods on the prediction results and semantic similarity, and has a good real-time performance. Our open-source code and pre-trained models are available at https://github.com/Blurryface0814/PCPNet.
Causal Repair of Learning-enabled Cyber-physical Systems
Apr 06, 2023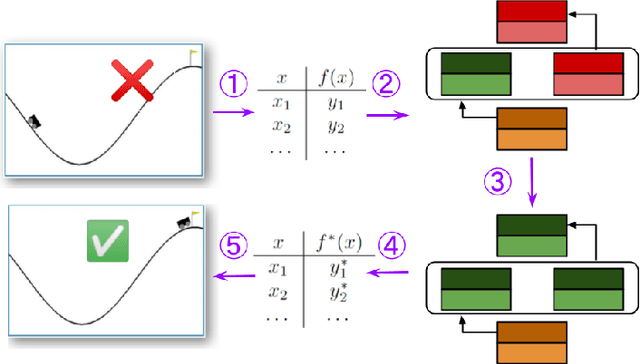
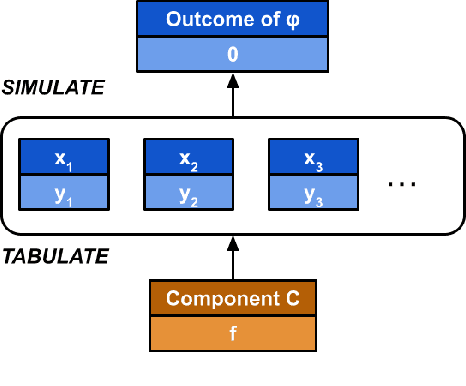
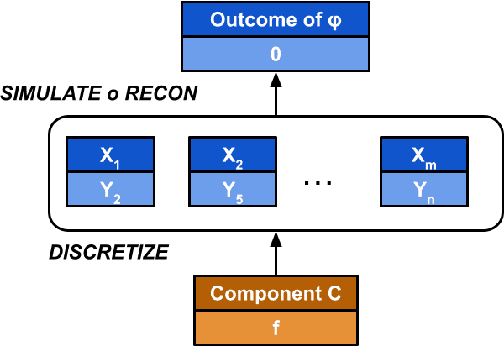
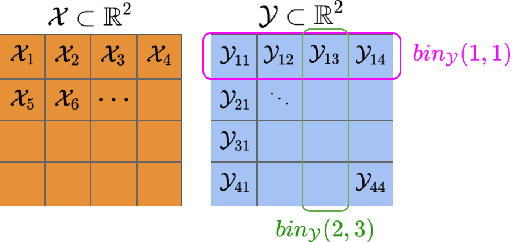
Models of actual causality leverage domain knowledge to generate convincing diagnoses of events that caused an outcome. It is promising to apply these models to diagnose and repair run-time property violations in cyber-physical systems (CPS) with learning-enabled components (LEC). However, given the high diversity and complexity of LECs, it is challenging to encode domain knowledge (e.g., the CPS dynamics) in a scalable actual causality model that could generate useful repair suggestions. In this paper, we focus causal diagnosis on the input/output behaviors of LECs. Specifically, we aim to identify which subset of I/O behaviors of the LEC is an actual cause for a property violation. An important by-product is a counterfactual version of the LEC that repairs the run-time property by fixing the identified problematic behaviors. Based on this insights, we design a two-step diagnostic pipeline: (1) construct and Halpern-Pearl causality model that reflects the dependency of property outcome on the component's I/O behaviors, and (2) perform a search for an actual cause and corresponding repair on the model. We prove that our pipeline has the following guarantee: if an actual cause is found, the system is guaranteed to be repaired; otherwise, we have high probabilistic confidence that the LEC under analysis did not cause the property violation. We demonstrate that our approach successfully repairs learned controllers on a standard OpenAI Gym benchmark.