 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MTrainS: Improving DLRM training efficiency using heterogeneous memories
Apr 19, 2023
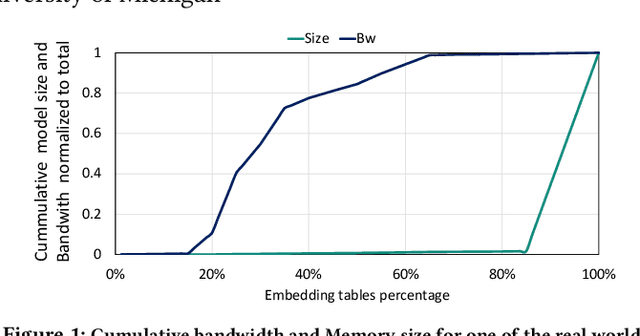
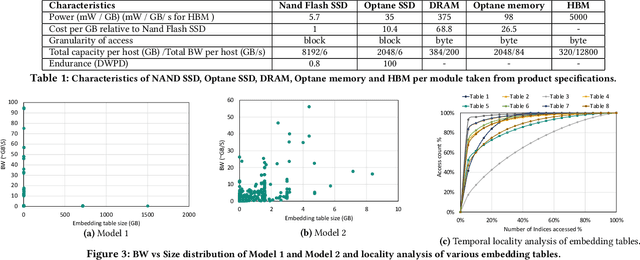
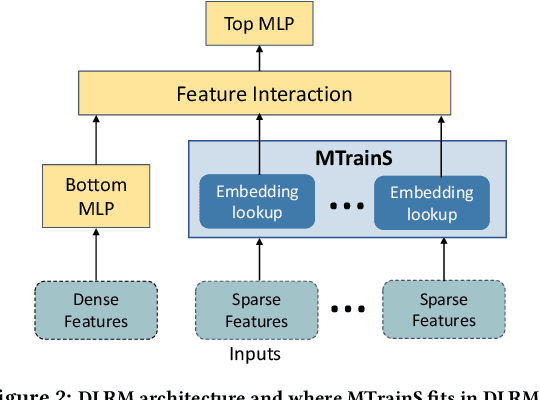

Recommendation models are very large, requiring terabytes (TB) of memory during training. In pursuit of better quality, the model size and complexity grow over time, which requires additional training data to avoid overfitting. This model growth demands a large number of resources in data centers. Hence, training efficiency is becoming considerably more important to keep the data center power demand manageable. In Deep Learning Recommendation Models (DLRM), sparse features capturing categorical inputs through embedding tables are the major contributors to model size and require high memory bandwidth. In this paper, we study the bandwidth requirement and locality of embedding tables in real-world deployed models. We observe that the bandwidth requirement is not uniform across different tables and that embedding tables show high temporal locality. We then design MTrainS, which leverages heterogeneous memory, including byte and block addressable Storage Class Memory for DLRM hierarchically. MTrainS allows for higher memory capacity per node and increases training efficiency by lowering the need to scale out to multiple hosts in memory capacity bound use cases. By optimizing the platform memory hierarchy, we reduce the number of nodes for training by 4-8X, saving power and cost of training while meeting our target training performance.
Progressive Transfer Learning for Dexterous In-Hand Manipulation with Multi-Fingered Anthropomorphic Hand
Apr 19, 2023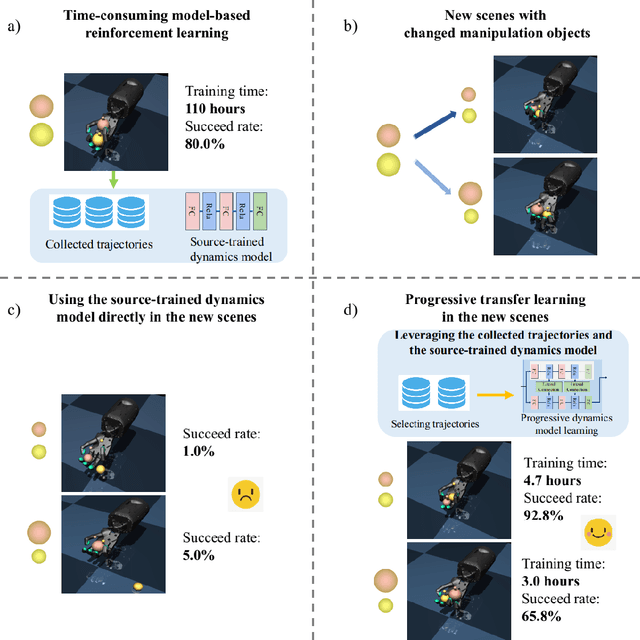
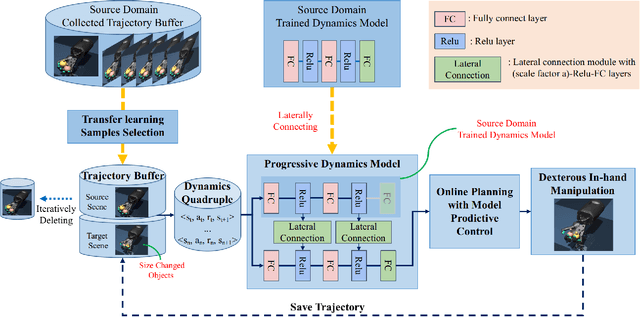
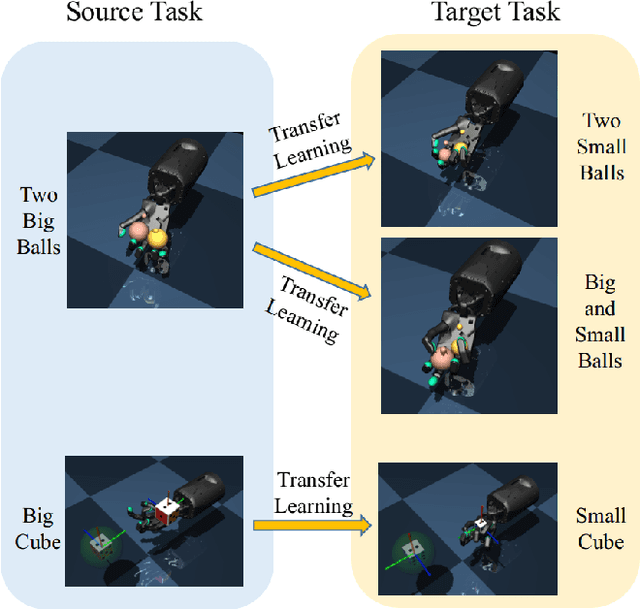
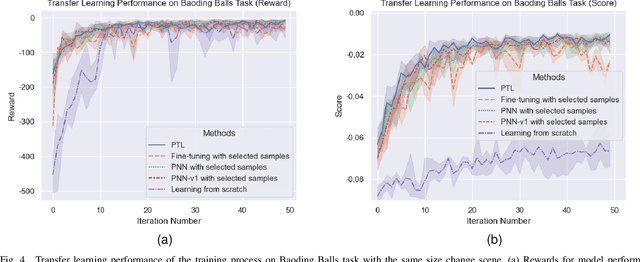
Dexterous in-hand manipulation for a multi-fingered anthropomorphic hand is extremely difficult because of the high-dimensional state and action spaces, rich contact patterns between the fingers and objects. Even though deep reinforcement learning has made moderate progress and demonstrated its strong potential for manipulation, it is still faced with certain challenges, such as large-scale data collection and high sample complexity. Especially, for some slight change scenes, it always needs to re-collect vast amounts of data and carry out numerous iterations of fine-tuning. Remarkably, humans can quickly transfer learned manipulation skills to different scenarios with little supervision. Inspired by human flexible transfer learning capability, we propose a novel dexterous in-hand manipulation progressive transfer learning framework (PTL) based on efficiently utilizing the collected trajectories and the source-trained dynamics model. This framework adopts progressive neural networks for dynamics model transfer learning on samples selected by a new samples selection method based on dynamics properties, rewards and scores of the trajectories. Experimental results on contact-rich anthropomorphic hand manipulation tasks show that our method can efficiently and effectively learn in-hand manipulation skills with a few online attempts and adjustment learning under the new scene. Compared to learning from scratch, our method can reduce training time costs by 95%.
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Nov 27, 2022
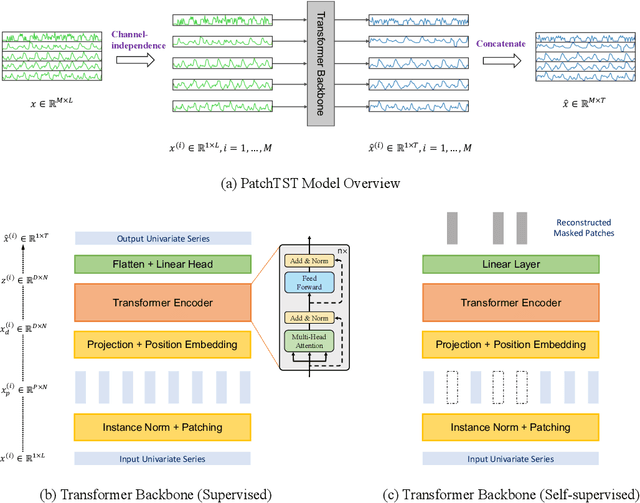

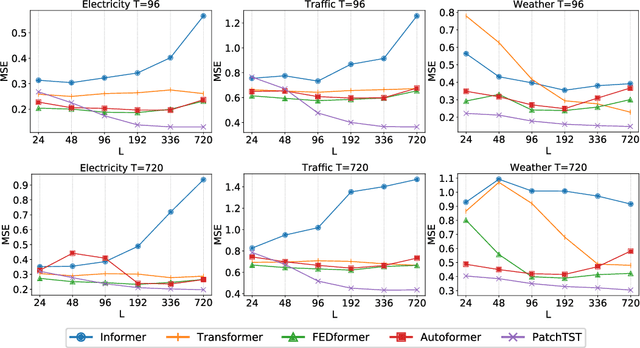
We propose an efficient design of Transformer-based models for multivariate time series forecasting and self-supervised representation learning. It is based on two key components: (i) segmentation of time series into subseries-level patches which are served as input tokens to Transformer; (ii) channel-independence where each channel contains a single univariate time series that shares the same embedding and Transformer weights across all the series. Patching design naturally has three-fold benefit: local semantic information is retained in the embedding; computation and memory usage of the attention maps are quadratically reduced given the same look-back window; and the model can attend longer history. Our channel-independent patch time series Transformer (PatchTST) can improve the long-term forecasting accuracy significantly when compared with that of SOTA Transformer-based models. We also apply our model to self-supervised pre-training tasks and attain excellent fine-tuning performance, which outperforms supervised training on large datasets. Transferring of masked pre-trained representation on one dataset to others also produces SOTA forecasting accuracy. Code is available at: https://github.com/yuqinie98/PatchTST.
PCPNet: An Efficient and Semantic-Enhanced Transformer Network for Point Cloud Prediction
Apr 16, 2023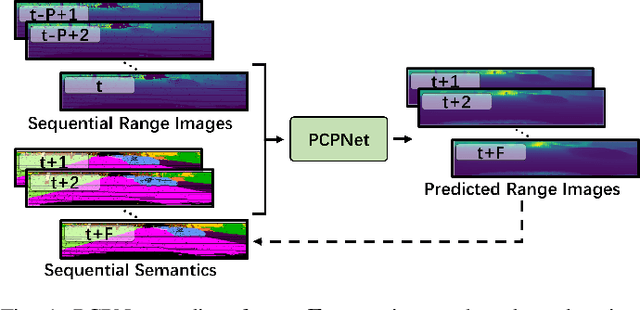
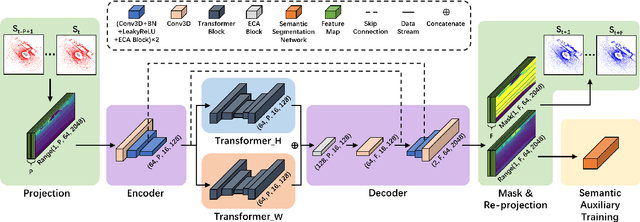
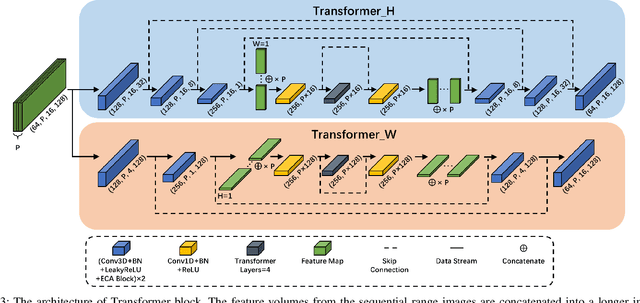
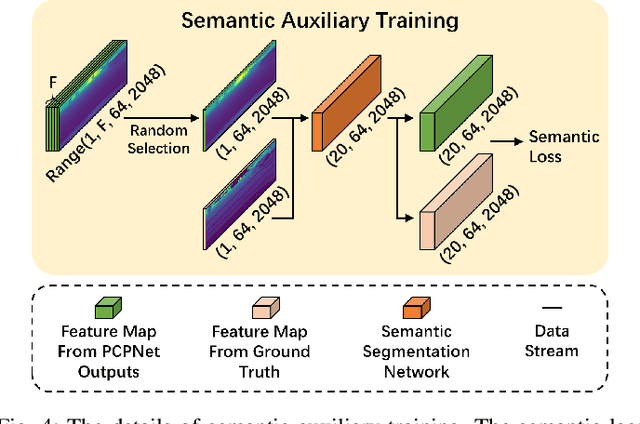
The ability to predict future structure features of environments based on past perception information is extremely needed by autonomous vehicles, which helps to make the following decision-making and path planning more reasonable. Recently, point cloud prediction (PCP) is utilized to predict and describe future environmental structures by the point cloud form. In this letter, we propose a novel efficient Transformer-based network to predict the future LiDAR point clouds exploiting the past point cloud sequences. We also design a semantic auxiliary training strategy to make the predicted LiDAR point cloud sequence semantically similar to the ground truth and thus improves the significance of the deployment for more tasks in real-vehicle applications. Our approach is completely self-supervised, which means it does not require any manual labeling and has a solid generalization ability toward different environments. The experimental results show that our method outperforms the state-of-the-art PCP methods on the prediction results and semantic similarity, and has a good real-time performance. Our open-source code and pre-trained models are available at https://github.com/Blurryface0814/PCPNet.
Learning Self-Supervised Representations for Label Efficient Cross-Domain Knowledge Transfer on Diabetic Retinopathy Fundus Images
Apr 20, 2023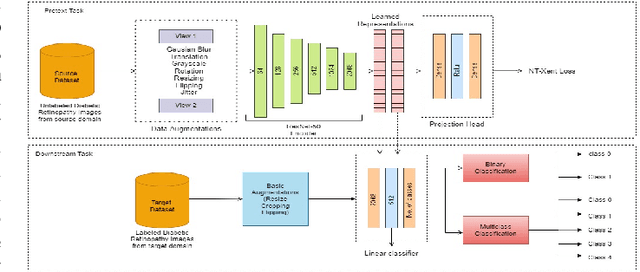
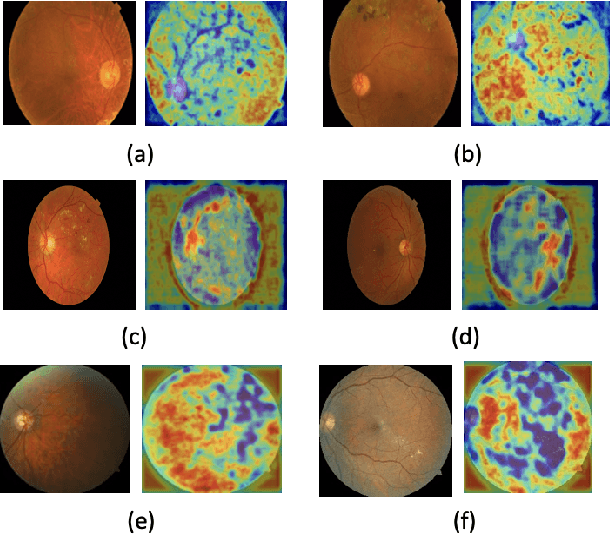
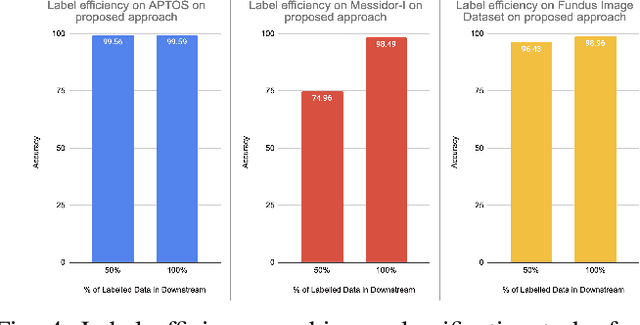
This work presents a novel label-efficient selfsupervised representation learning-based approach for classifying diabetic retinopathy (DR) images in cross-domain settings. Most of the existing DR image classification methods are based on supervised learning which requires a lot of time-consuming and expensive medical domain experts-annotated data for training. The proposed approach uses the prior learning from the source DR image dataset to classify images drawn from the target datasets. The image representations learned from the unlabeled source domain dataset through contrastive learning are used to classify DR images from the target domain dataset. Moreover, the proposed approach requires a few labeled images to perform successfully on DR image classification tasks in cross-domain settings. The proposed work experiments with four publicly available datasets: EyePACS, APTOS 2019, MESSIDOR-I, and Fundus Images for self-supervised representation learning-based DR image classification in cross-domain settings. The proposed method achieves state-of-the-art results on binary and multiclassification of DR images, even in cross-domain settings. The proposed method outperforms the existing DR image binary and multi-class classification methods proposed in the literature. The proposed method is also validated qualitatively using class activation maps, revealing that the method can learn explainable image representations. The source code and trained models are published on GitHub.
Fourier Neural Operator Surrogate Model to Predict 3D Seismic Waves Propagation
Apr 20, 2023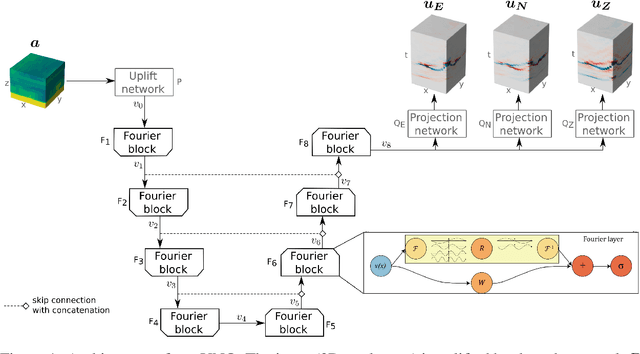
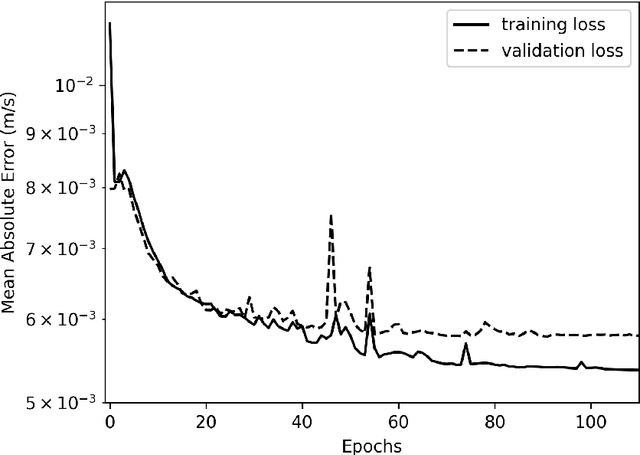
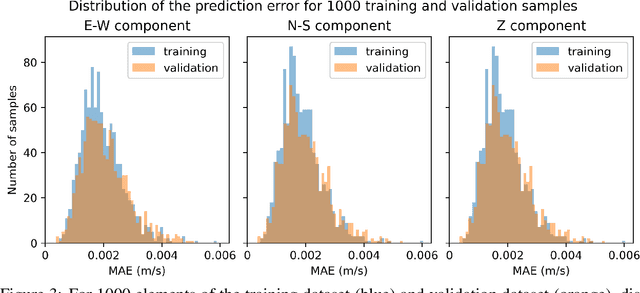
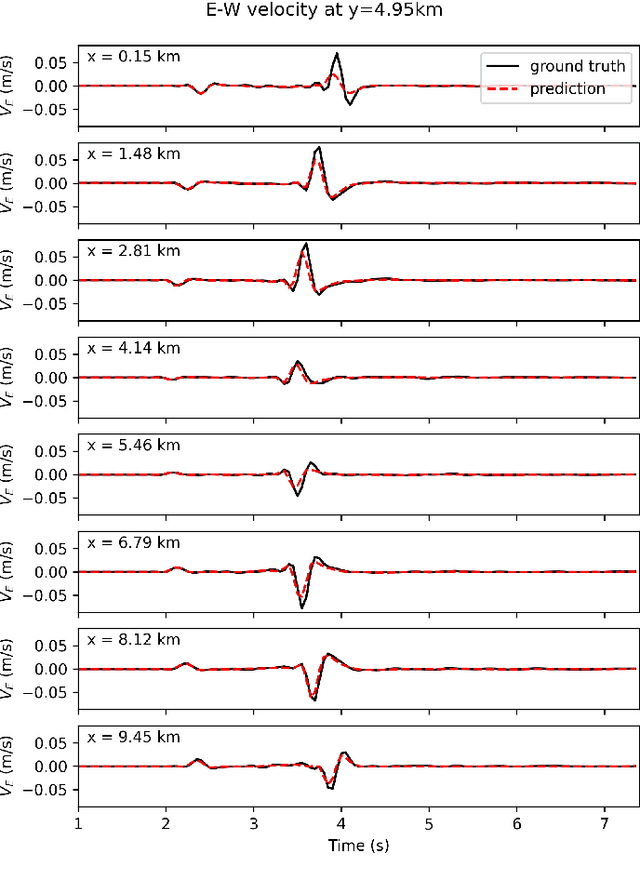
With the recent rise of neural operators, scientific machine learning offers new solutions to quantify uncertainties associated with high-fidelity numerical simulations. Traditional neural networks, such as Convolutional Neural Networks (CNN) or Physics-Informed Neural Networks (PINN), are restricted to the prediction of solutions in a predefined configuration. With neural operators, one can learn the general solution of Partial Differential Equations, such as the elastic wave equation, with varying parameters. There have been very few applications of neural operators in seismology. All of them were limited to two-dimensional settings, although the importance of three-dimensional (3D) effects is well known. In this work, we apply the Fourier Neural Operator (FNO) to predict ground motion time series from a 3D geological description. We used a high-fidelity simulation code, SEM3D, to build an extensive database of ground motions generated by 30,000 different geologies. With this database, we show that the FNO can produce accurate ground motion even when the underlying geology exhibits large heterogeneities. Intensity measures at moderate and large periods are especially well reproduced. We present the first seismological application of Fourier Neural Operators in 3D. Thanks to the generalizability of our database, we believe that our model can be used to assess the influence of geological features such as sedimentary basins on ground motion, which is paramount to evaluating site effects.
Learning a quantum computer's capability using convolutional neural networks
Apr 20, 2023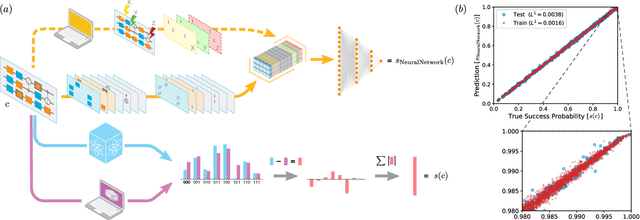
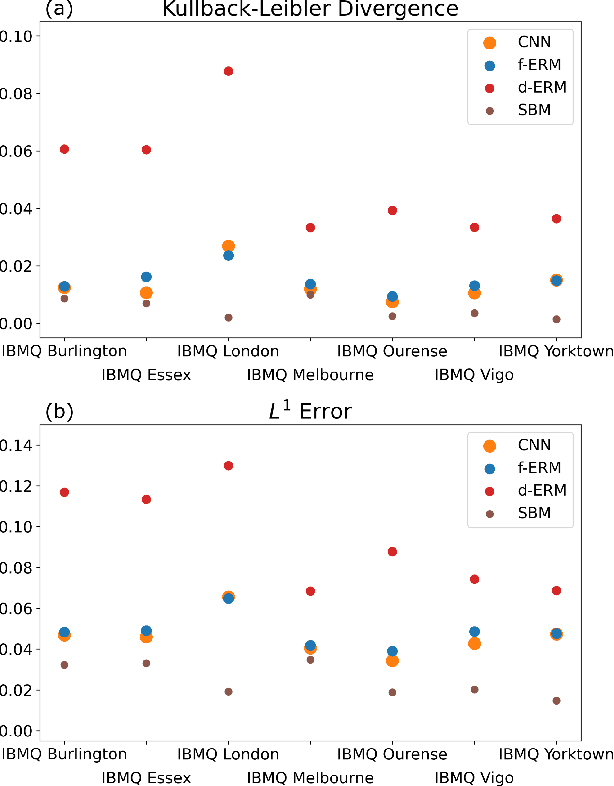
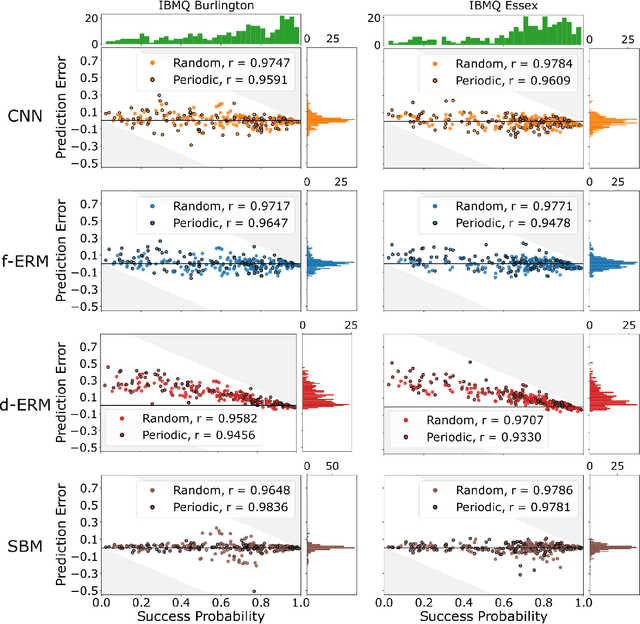
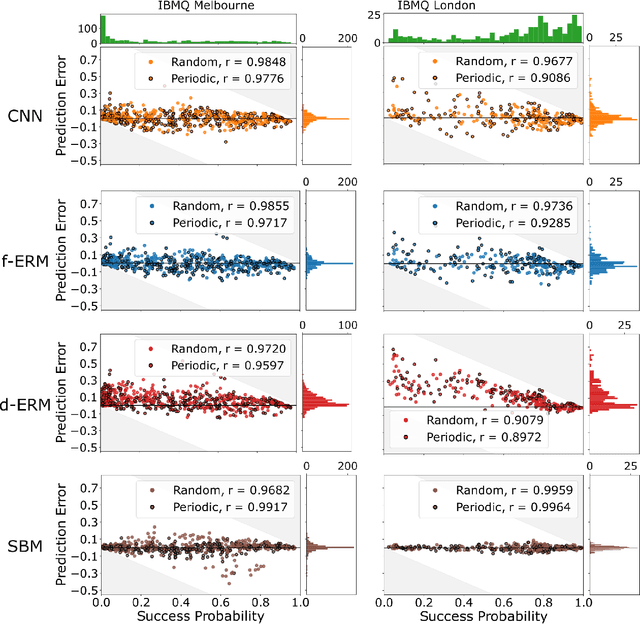
The computational power of contemporary quantum processors is limited by hardware errors that cause computations to fail. In principle, each quantum processor's computational capabilities can be described with a capability function that quantifies how well a processor can run each possible quantum circuit (i.e., program), as a map from circuits to the processor's success rates on those circuits. However, capability functions are typically unknown and challenging to model, as the particular errors afflicting a specific quantum processor are a priori unknown and difficult to completely characterize. In this work, we investigate using artificial neural networks to learn an approximation to a processor's capability function. We explore how to define the capability function, and we explain how data for training neural networks can be efficiently obtained for a capability function defined using process fidelity. We then investigate using convolutional neural networks to model a quantum computer's capability. Using simulations, we show that convolutional neural networks can accurately model a processor's capability when that processor experiences gate-dependent, time-dependent, and context-dependent stochastic errors. We then discuss some challenges to creating useful neural network capability models for experimental processors, such as generalizing beyond training distributions and modelling the effects of coherent errors. Lastly, we apply our neural networks to model the capabilities of cloud-access quantum computing systems, obtaining moderate prediction accuracy (average absolute error around 2-5%).
Causal Repair of Learning-enabled Cyber-physical Systems
Apr 06, 2023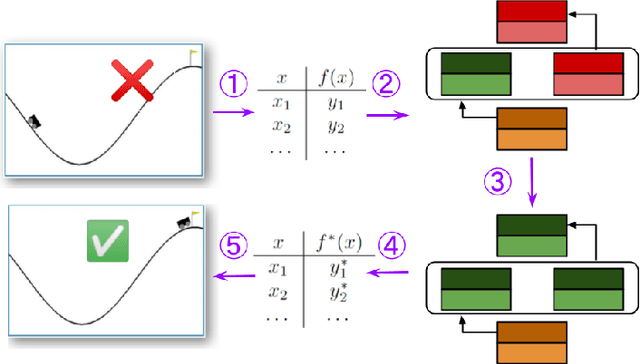
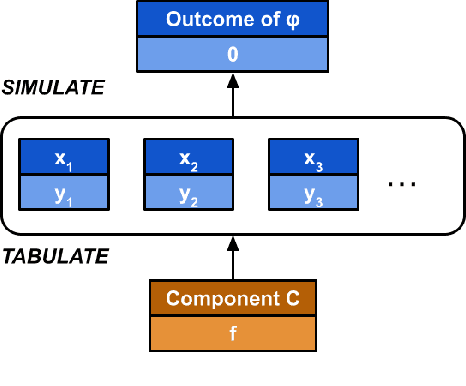
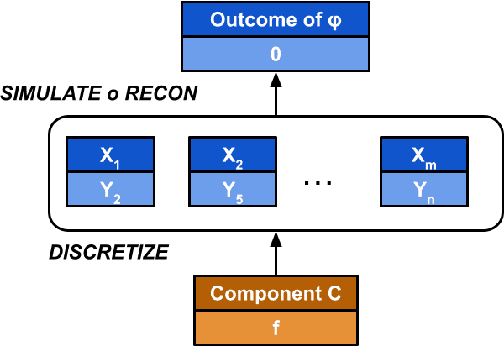
Models of actual causality leverage domain knowledge to generate convincing diagnoses of events that caused an outcome. It is promising to apply these models to diagnose and repair run-time property violations in cyber-physical systems (CPS) with learning-enabled components (LEC). However, given the high diversity and complexity of LECs, it is challenging to encode domain knowledge (e.g., the CPS dynamics) in a scalable actual causality model that could generate useful repair suggestions. In this paper, we focus causal diagnosis on the input/output behaviors of LECs. Specifically, we aim to identify which subset of I/O behaviors of the LEC is an actual cause for a property violation. An important by-product is a counterfactual version of the LEC that repairs the run-time property by fixing the identified problematic behaviors. Based on this insights, we design a two-step diagnostic pipeline: (1) construct and Halpern-Pearl causality model that reflects the dependency of property outcome on the component's I/O behaviors, and (2) perform a search for an actual cause and corresponding repair on the model. We prove that our pipeline has the following guarantee: if an actual cause is found, the system is guaranteed to be repaired; otherwise, we have high probabilistic confidence that the LEC under analysis did not cause the property violation. We demonstrate that our approach successfully repairs learned controllers on a standard OpenAI Gym benchmark.
A Bayesian Framework for Causal Analysis of Recurrent Events in Presence of Immortal Risk
Apr 06, 2023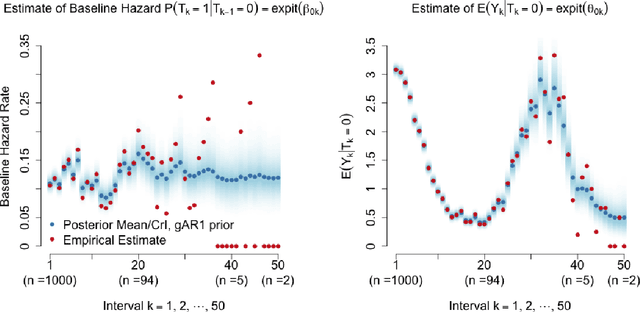
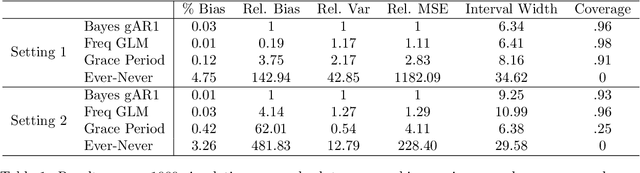
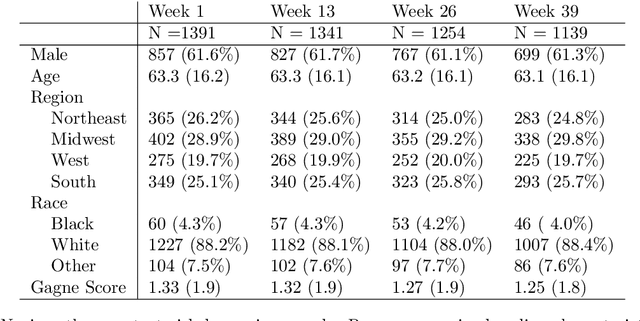
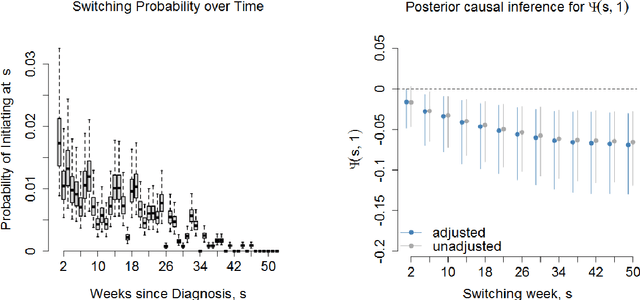
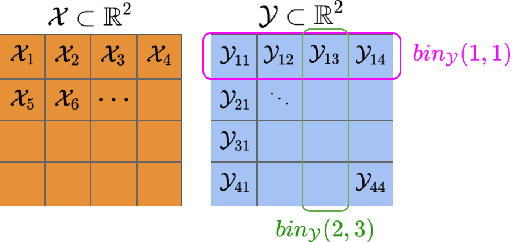
Observational studies of recurrent event rates are common in biomedical statistics. Broadly, the goal is to estimate differences in event rates under two treatments within a defined target population over a specified followup window. Estimation with observational claims data is challenging because while membership in the target population is defined in terms of eligibility criteria, treatment is rarely assigned exactly at the time of eligibility. Ad-hoc solutions to this timing misalignment, such as assigning treatment at eligibility based on subsequent assignment, incorrectly attribute prior event rates to treatment - resulting in immortal risk bias. Even if eligibility and treatment are aligned, a terminal event process (e.g. death) often stops the recurrent event process of interest. Both processes are also censored so that events are not observed over the entire followup window. Our approach addresses misalignment by casting it as a treatment switching problem: some patients are on treatment at eligibility while others are off treatment but may switch to treatment at a specified time - if they survive long enough. We define and identify an average causal effect of switching under specified causal assumptions. Estimation is done using a g-computation framework with a joint semiparametric Bayesian model for the death and recurrent event processes. Computing the estimand for various switching times allows us to assess the impact of treatment timing. We apply the method to contrast hospitalization rates under different opioid treatment strategies among patients with chronic back pain using Medicare claims data.
RPLKG: Robust Prompt Learning with Knowledge Graph
Apr 21, 2023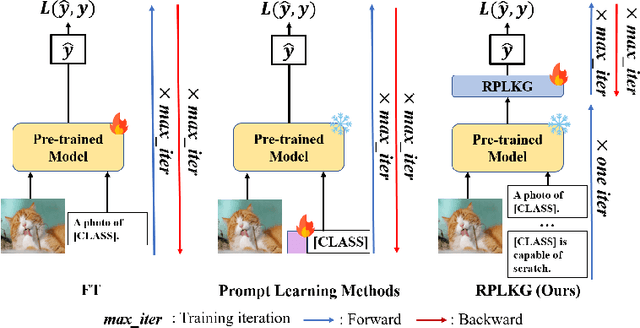
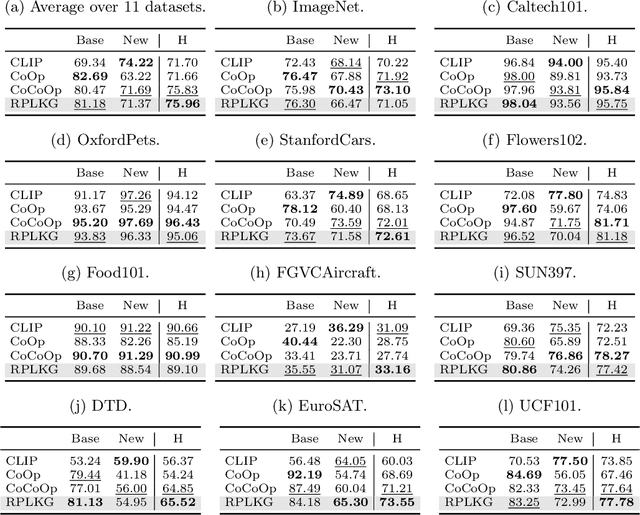

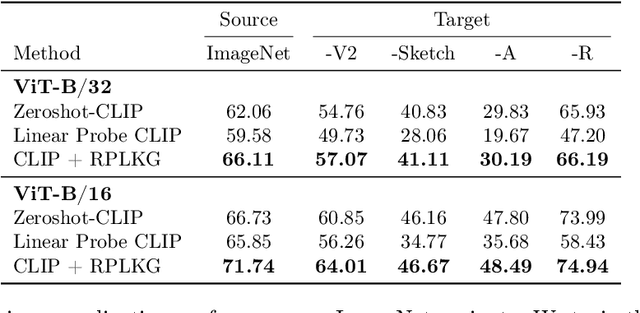
Large-scale pre-trained models have been known that they are transferable, and they generalize well on the unseen dataset. Recently, multimodal pre-trained models such as CLIP show significant performance improvement in diverse experiments. However, when the labeled dataset is limited, the generalization of a new dataset or domain is still challenging. To improve the generalization performance on few-shot learning, there have been diverse efforts, such as prompt learning and adapter. However, the current few-shot adaptation methods are not interpretable, and they require a high computation cost for adaptation. In this study, we propose a new method, robust prompt learning with knowledge graph (RPLKG). Based on the knowledge graph, we automatically design diverse interpretable and meaningful prompt sets. Our model obtains cached embeddings of prompt sets after one forwarding from a large pre-trained model. After that, model optimizes the prompt selection processes with GumbelSoftmax. In this way, our model is trained using relatively little memory and learning time. Also, RPLKG selects the optimal interpretable prompt automatically, depending on the dataset. In summary, RPLKG is i) interpretable, ii) requires small computation resources, and iii) easy to incorporate prior human knowledge. To validate the RPLKG, we provide comprehensive experimental results on few-shot learning, domain generalization and new class generalization setting. RPLKG shows a significant performance improvement compared to zero-shot learning and competitive performance against several prompt learning methods using much lower resources.