 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluation of Parameter-based Attacks against Embedded Neural Networks with Laser Injection
Apr 25, 2023

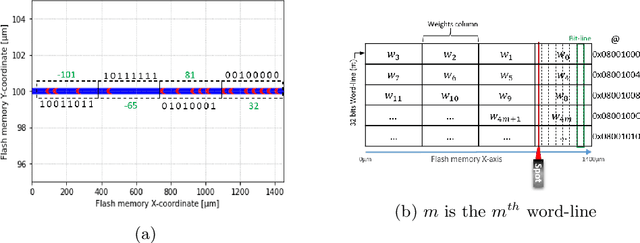
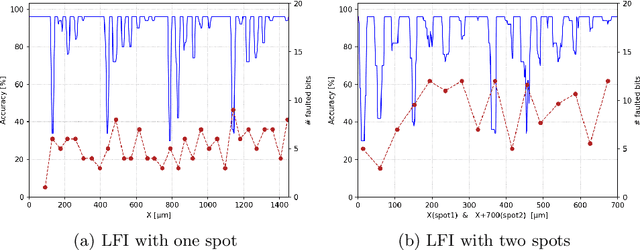
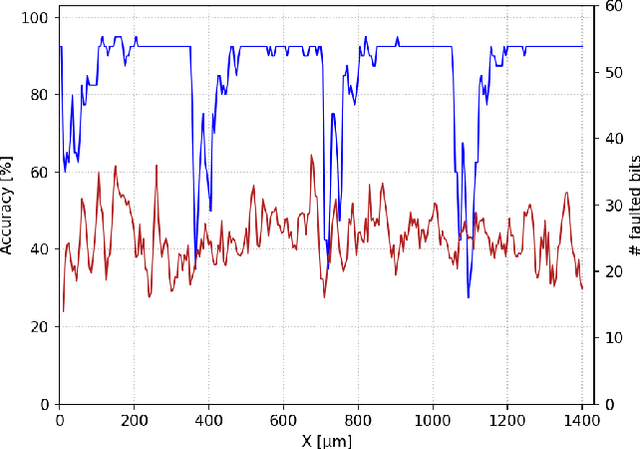
Upcoming certification actions related to the security of machine learning (ML) based systems raise major evaluation challenges that are amplified by the large-scale deployment of models in many hardware platforms. Until recently, most of research works focused on API-based attacks that consider a ML model as a pure algorithmic abstraction. However, new implementation-based threats have been revealed, emphasizing the urgency to propose both practical and simulation-based methods to properly evaluate the robustness of models. A major concern is parameter-based attacks (such as the Bit-Flip Attack, BFA) that highlight the lack of robustness of typical deep neural network models when confronted by accurate and optimal alterations of their internal parameters stored in memory. Setting in a security testing purpose, this work practically reports, for the first time, a successful variant of the BFA on a 32-bit Cortex-M microcontroller using laser fault injection. It is a standard fault injection means for security evaluation, that enables to inject spatially and temporally accurate faults. To avoid unrealistic brute-force strategies, we show how simulations help selecting the most sensitive set of bits from the parameters taking into account the laser fault model.
Machine Learning Approach and Extreme Value Theory to Correlated Stochastic Time Series with Application to Tree Ring Data
Jan 27, 2023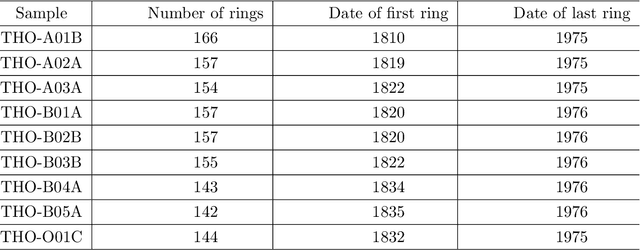
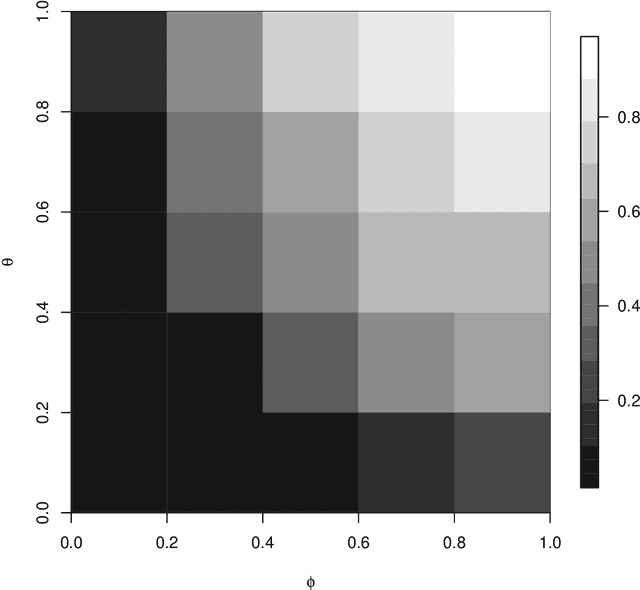
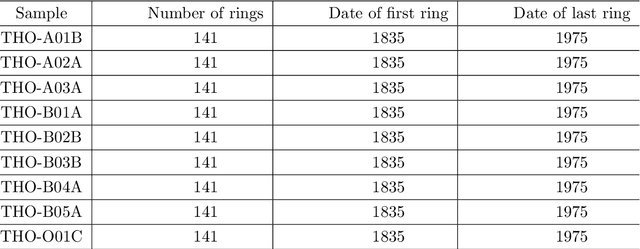
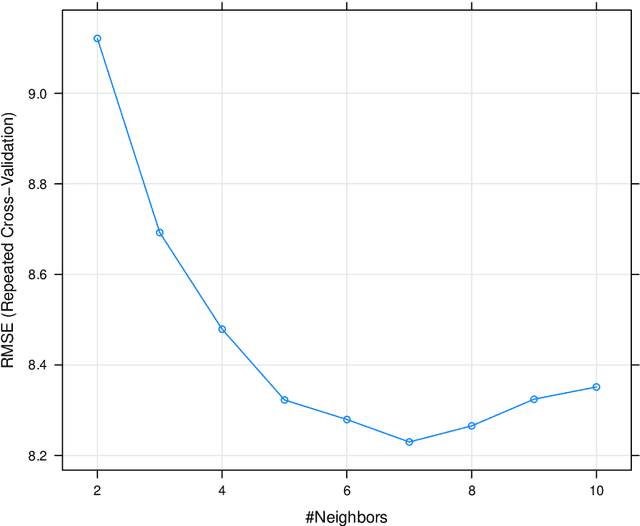
The main goal of machine learning (ML) is to study and improve mathematical models which can be trained with data provided by the environment to infer the future and to make decisions without necessarily having complete knowledge of all influencing elements. In this work, we describe how ML can be a powerful tool in studying climate modeling. Tree ring growth was used as an implementation in different aspects, for example, studying the history of buildings and environment. By growing and via the time, a new layer of wood to beneath its bark by the tree. After years of growing, time series can be applied via a sequence of tree ring widths. The purpose of this paper is to use ML algorithms and Extreme Value Theory in order to analyse a set of tree ring widths data from nine trees growing in Nottinghamshire. Initially, we start by exploring the data through a variety of descriptive statistical approaches. Transforming data is important at this stage to find out any problem in modelling algorithm. We then use algorithm tuning and ensemble methods to improve the k-nearest neighbors (KNN) algorithm. A comparison between the developed method in this study ad other methods are applied. Also, extreme value of the dataset will be more investigated. The results of the analysis study show that the ML algorithms in the Random Forest method would give accurate results in the analysis of tree ring widths data from nine trees growing in Nottinghamshire with the lowest Root Mean Square Error value. Also, we notice that as the assumed ARMA model parameters increased, the probability of selecting the true model also increased. In terms of the Extreme Value Theory, the Weibull distribution would be a good choice to model tree ring data.
Addressing Distribution Shift at Test Time in Pre-trained Language Models
Dec 05, 2022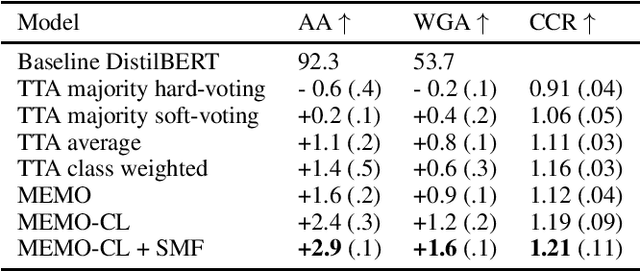
State-of-the-art pre-trained language models (PLMs) outperform other models when applied to the majority of language processing tasks. However, PLMs have been found to degrade in performance under distribution shift, a phenomenon that occurs when data at test-time does not come from the same distribution as the source training set. Equally as challenging is the task of obtaining labels in real-time due to issues like long-labeling feedback loops. The lack of adequate methods that address the aforementioned challenges constitutes the need for approaches that continuously adapt the PLM to a distinct distribution. Unsupervised domain adaptation adapts a source model to an unseen as well as unlabeled target domain. While some techniques such as data augmentation can adapt models in several scenarios, they have only been sparsely studied for addressing the distribution shift problem. In this work, we present an approach (MEMO-CL) that improves the performance of PLMs at test-time under distribution shift. Our approach takes advantage of the latest unsupervised techniques in data augmentation and adaptation to minimize the entropy of the PLM's output distribution. MEMO-CL operates on a batch of augmented samples from a single observation in the test set. The technique introduced is unsupervised, domain-agnostic, easy to implement, and requires no additional data. Our experiments result in a 3% improvement over current test-time adaptation baselines.
Generative AI Perceptions: A Survey to Measure the Perceptions of Faculty, Staff, and Students on Generative AI Tools in Academia
Apr 21, 2023


ChatGPT is a natural language processing tool that can engage in human-like conversations and generate coherent and contextually relevant responses to various prompts. ChatGPT is capable of understanding natural text that is input by a user and generating appropriate responses in various forms. This tool represents a major step in how humans are interacting with technology. This paper specifically focuses on how ChatGPT is revolutionizing the realm of engineering education and the relationship between technology, students, and faculty and staff. Because this tool is quickly changing and improving with the potential for even greater future capability, it is a critical time to collect pertinent data. A survey was created to measure the effects of ChatGPT on students, faculty, and staff. This survey is shared as a Texas A&M University technical report to allow other universities and entities to use this survey and measure the effects elsewhere.
Consensus Complementarity Control for Multi-Contact MPC
Apr 21, 2023
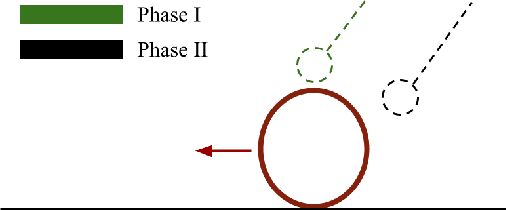
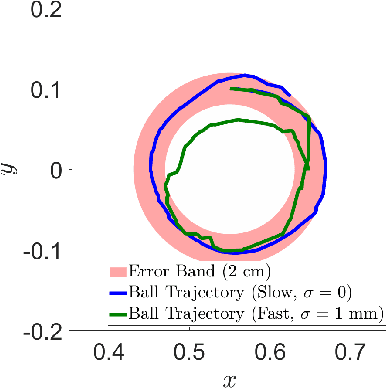

We propose a hybrid model predictive control algorithm, consensus complementarity control (C3), for systems that make and break contact with their environment. Many state-of-the-art controllers for tasks which require initiating contact with the environment, such as locomotion and manipulation, require a priori mode schedules or are too computationally complex to run at real-time rates. We present a method based on the alternating direction method of multipliers (ADMM) that is capable of high-speed reasoning over potential contact events. Via a consensus formulation, our approach enables parallelization of the contact scheduling problem. We validate our results on five numerical examples, including four high-dimensional frictional contact problems, and a physical experimentation on an underactuated multi-contact system. We further demonstrate the effectiveness of our method on a physical experiment accomplishing a high-dimensional, multi-contact manipulation task with a robot arm.
BoDiffusion: Diffusing Sparse Observations for Full-Body Human Motion Synthesis
Apr 21, 2023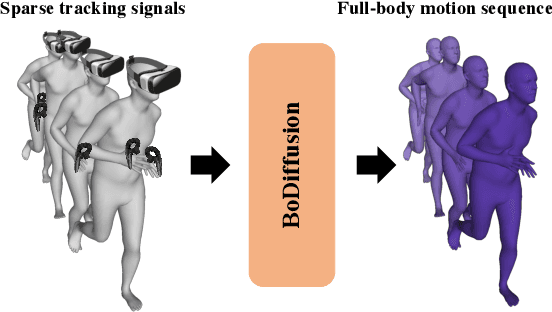

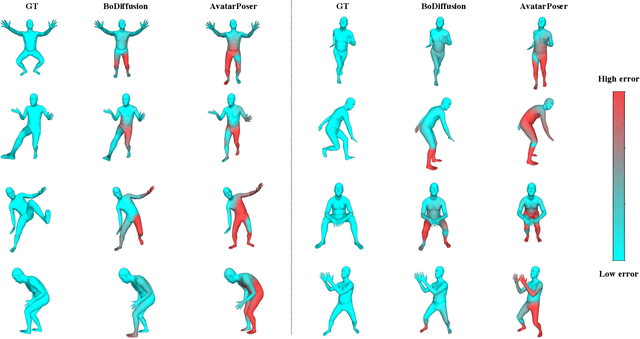
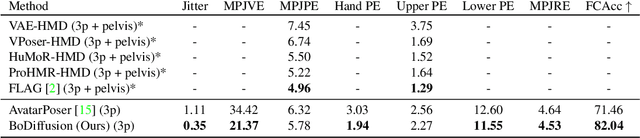
Mixed reality applications require tracking the user's full-body motion to enable an immersive experience. However, typical head-mounted devices can only track head and hand movements, leading to a limited reconstruction of full-body motion due to variability in lower body configurations. We propose BoDiffusion -- a generative diffusion model for motion synthesis to tackle this under-constrained reconstruction problem. We present a time and space conditioning scheme that allows BoDiffusion to leverage sparse tracking inputs while generating smooth and realistic full-body motion sequences. To the best of our knowledge, this is the first approach that uses the reverse diffusion process to model full-body tracking as a conditional sequence generation task. We conduct experiments on the large-scale motion-capture dataset AMASS and show that our approach outperforms the state-of-the-art approaches by a significant margin in terms of full-body motion realism and joint reconstruction error.
Online Convex Optimization of Programmable Quantum Computers to Simulate Time-Varying Quantum Channels
Dec 09, 2022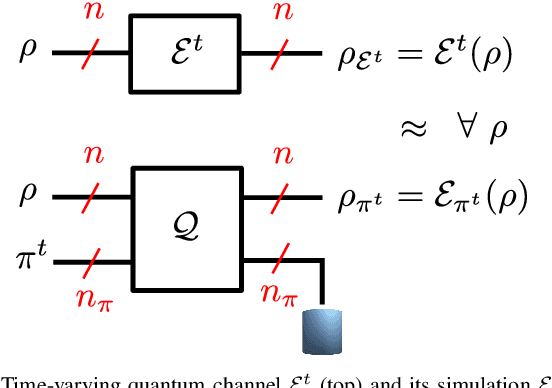
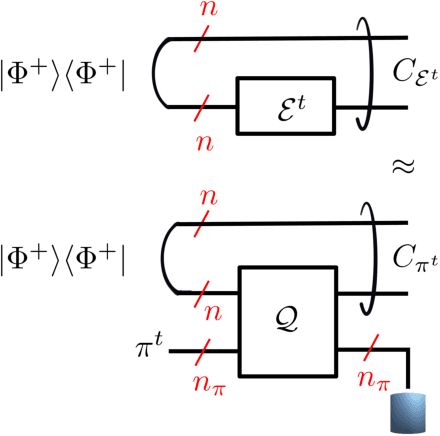
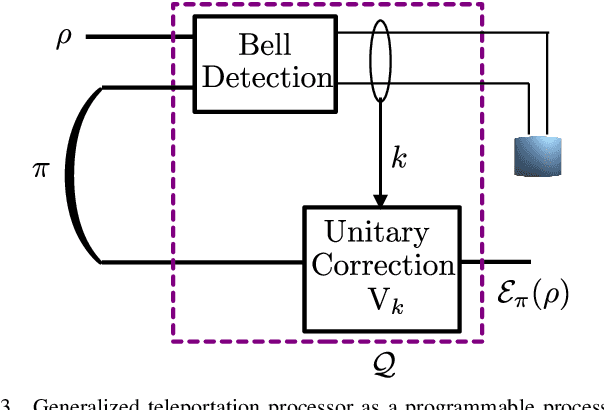
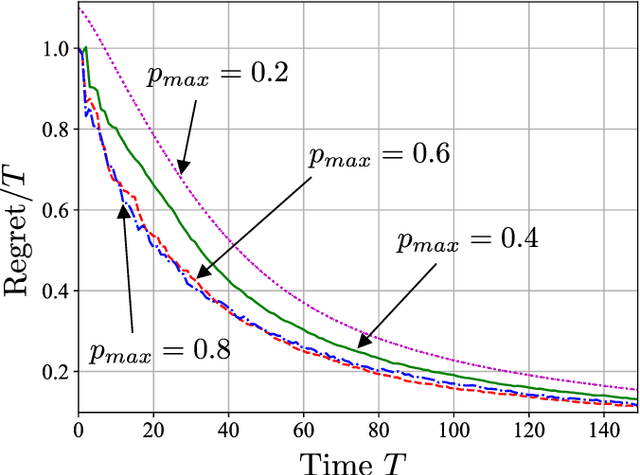
Simulating quantum channels is a fundamental primitive in quantum computing, since quantum channels define general (trace-preserving) quantum operations. An arbitrary quantum channel cannot be exactly simulated using a finite-dimensional programmable quantum processor, making it important to develop optimal approximate simulation techniques. In this paper, we study the challenging setting in which the channel to be simulated varies adversarially with time. We propose the use of matrix exponentiated gradient descent (MEGD), an online convex optimization method, and analytically show that it achieves a sublinear regret in time. Through experiments, we validate the main results for time-varying dephasing channels using a programmable generalized teleportation processor.
Shot Noise Reduction in Radiographic and Tomographic Multi-Channel Imaging with Self-Supervised Deep Learning
Mar 25, 2023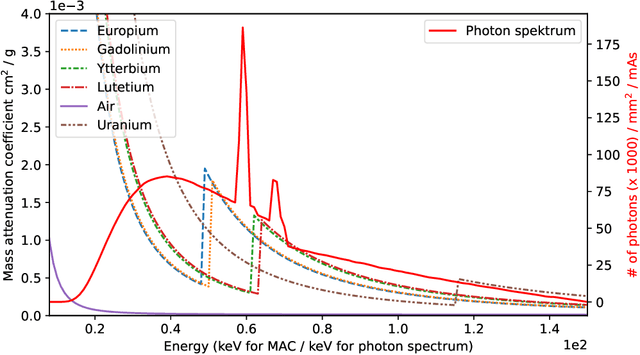
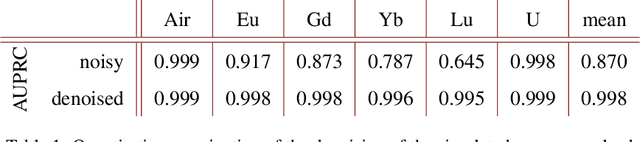
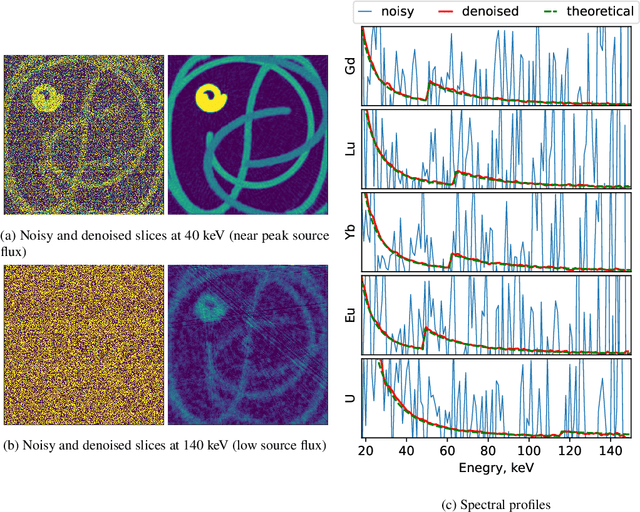

Noise is an important issue for radiographic and tomographic imaging techniques. It becomes particularly critical in applications where additional constraints force a strong reduction of the Signal-to-Noise Ratio (SNR) per image. These constraints may result from limitations on the maximum available flux or permissible dose and the associated restriction on exposure time. Often, a high SNR per image is traded for the ability to distribute a given total exposure capacity per pixel over multiple channels, thus obtaining additional information about the object by the same total exposure time. These can be energy channels in the case of spectroscopic imaging or time channels in the case of time-resolved imaging. In this paper, we report on a method for improving the quality of noisy multi-channel (time or energy-resolved) imaging datasets. The method relies on the recent Noise2Noise (N2N) self-supervised denoising approach that learns to predict a noise-free signal without access to noise-free data. N2N in turn requires drawing pairs of samples from a data distribution sharing identical signals while being exposed to different samples of random noise. The method is applicable if adjacent channels share enough information to provide images with similar enough information but independent noise. We demonstrate several representative case studies, namely spectroscopic (k-edge) X-ray tomography, in vivo X-ray cine-radiography, and energy-dispersive (Bragg edge) neutron tomography. In all cases, the N2N method shows dramatic improvement and outperforms conventional denoising methods. For such imaging techniques, the method can therefore significantly improve image quality, or maintain image quality with further reduced exposure time per image.
XGC-VQA: A unified video quality assessment model for User, Professionally, and Occupationally-Generated Content
Mar 24, 2023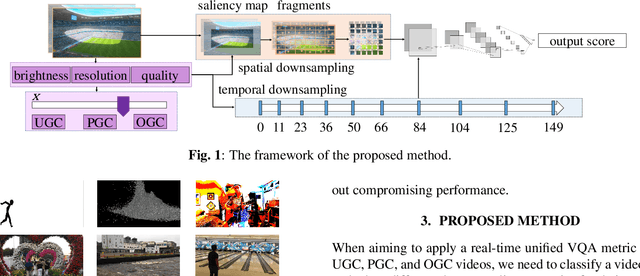
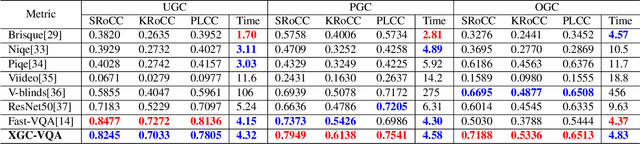
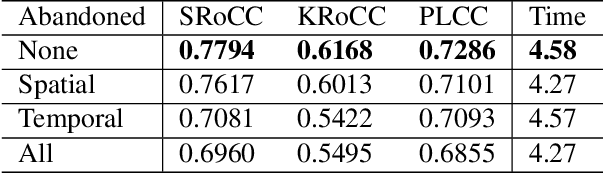
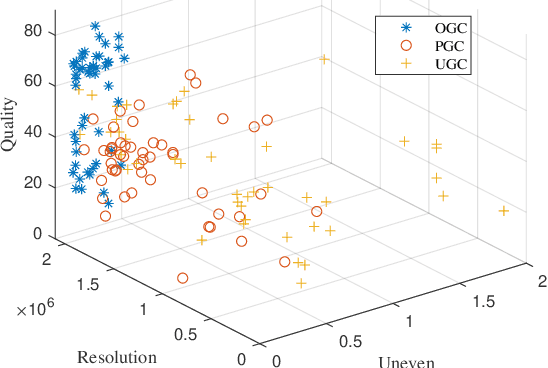
With the rapid growth of Internet video data amounts and types, a unified Video Quality Assessment (VQA) is needed to inspire video communication with perceptual quality. To meet the real-time and universal requirements in providing such inspiration, this study proposes a VQA model from a classification of User Generated Content (UGC), Professionally Generated Content (PGC), and Occupationally Generated Content (OGC). In the time domain, this study utilizes non-uniform sampling, as each content type has varying temporal importance based on its perceptual quality. In the spatial domain, centralized downsampling is performed before the VQA process by utilizing a patch splicing/sampling mechanism to lower complexity for real-time assessment. The experimental results demonstrate that the proposed method achieves a median correlation of $0.7$ while limiting the computation time below 5s for three content types, which ensures that the communication experience of UGC, PGC, and OGC can be optimized altogether.
Aiding reinforcement learning for set point control
Apr 20, 2023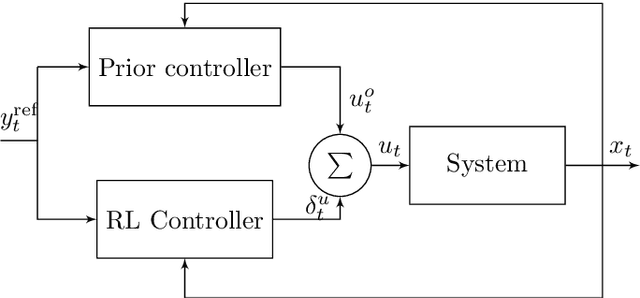

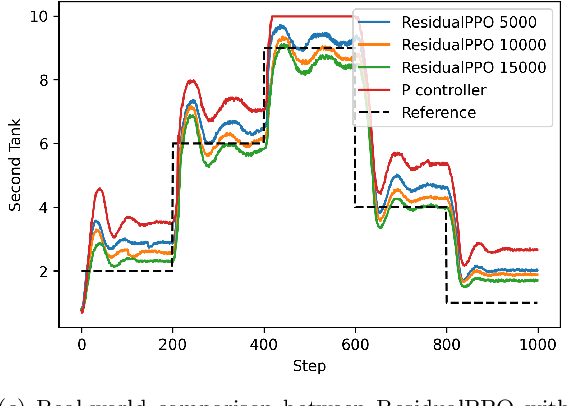
While reinforcement learning has made great improvements, state-of-the-art algorithms can still struggle with seemingly simple set-point feedback control problems. One reason for this is that the learned controller may not be able to excite the system dynamics well enough initially, and therefore it can take a long time to get data that is informative enough to learn for good control. The paper contributes by augmentation of reinforcement learning with a simple guiding feedback controller, for example, a proportional controller. The key advantage in set point control is a much improved excitation that improves the convergence properties of the reinforcement learning controller significantly. This can be very important in real-world control where quick and accurate convergence is needed. The proposed method is evaluated with simulation and on a real-world double tank process with promising results.