 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learned multiphysics inversion with differentiable programming and machine learning
Apr 12, 2023
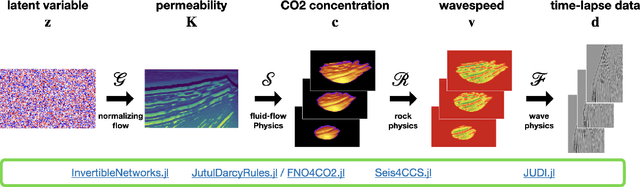
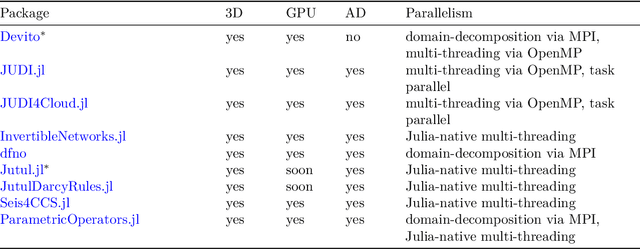
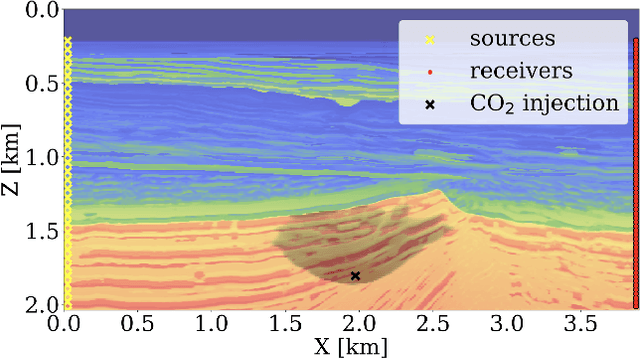
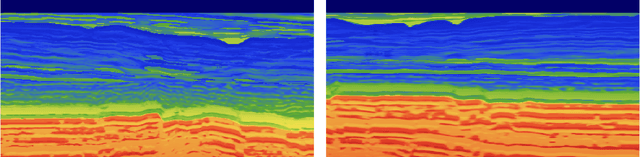
We present the Seismic Laboratory for Imaging and Modeling/Monitoring (SLIM) open-source software framework for computational geophysics and, more generally, inverse problems involving the wave-equation (e.g., seismic and medical ultrasound), regularization with learned priors, and learned neural surrogates for multiphase flow simulations. By integrating multiple layers of abstraction, our software is designed to be both readable and scalable. This allows researchers to easily formulate their problems in an abstract fashion while exploiting the latest developments in high-performance computing. We illustrate and demonstrate our design principles and their benefits by means of building a scalable prototype for permeability inversion from time-lapse crosswell seismic data, which aside from coupling of wave physics and multiphase flow, involves machine learning.
SINC: Spatial Composition of 3D Human Motions for Simultaneous Action Generation
Apr 20, 2023

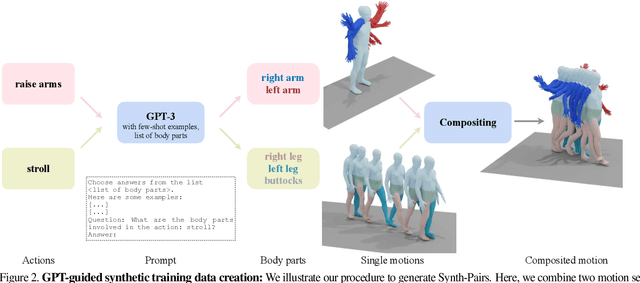

Our goal is to synthesize 3D human motions given textual inputs describing simultaneous actions, for example 'waving hand' while 'walking' at the same time. We refer to generating such simultaneous movements as performing 'spatial compositions'. In contrast to temporal compositions that seek to transition from one action to another, spatial compositing requires understanding which body parts are involved in which action, to be able to move them simultaneously. Motivated by the observation that the correspondence between actions and body parts is encoded in powerful language models, we extract this knowledge by prompting GPT-3 with text such as "what are the body parts involved in the action <action name>?", while also providing the parts list and few-shot examples. Given this action-part mapping, we combine body parts from two motions together and establish the first automated method to spatially compose two actions. However, training data with compositional actions is always limited by the combinatorics. Hence, we further create synthetic data with this approach, and use it to train a new state-of-the-art text-to-motion generation model, called SINC ("SImultaneous actioN Compositions for 3D human motions"). In our experiments, we find training on additional synthetic GPT-guided compositional motions improves text-to-motion generation.
Graph Neural Network-Based Anomaly Detection for River Network Systems
Apr 20, 2023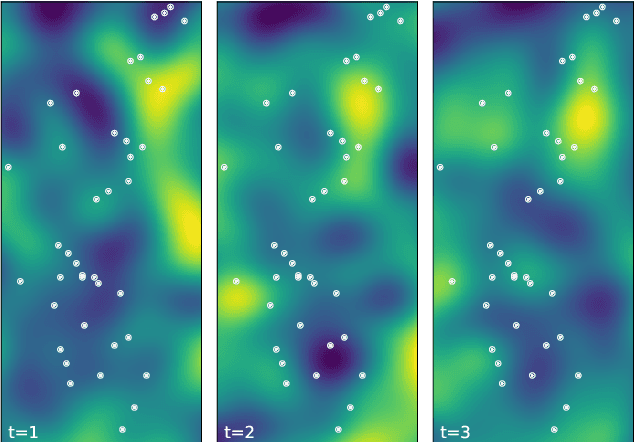
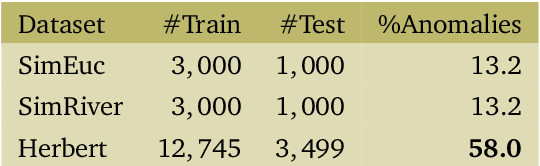
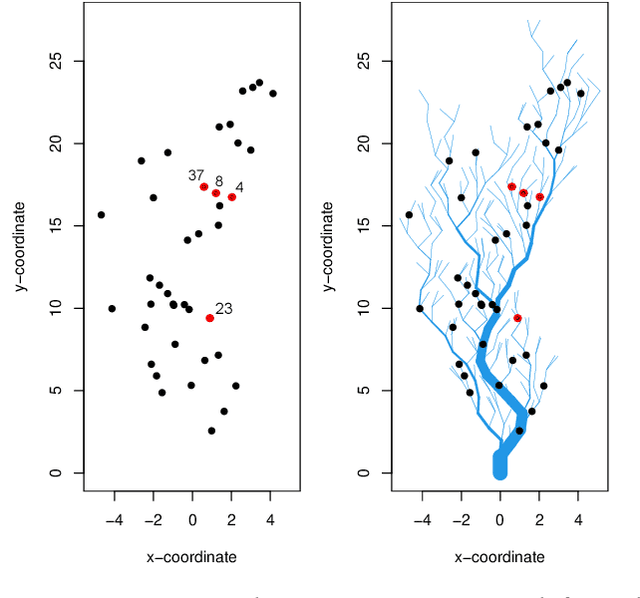
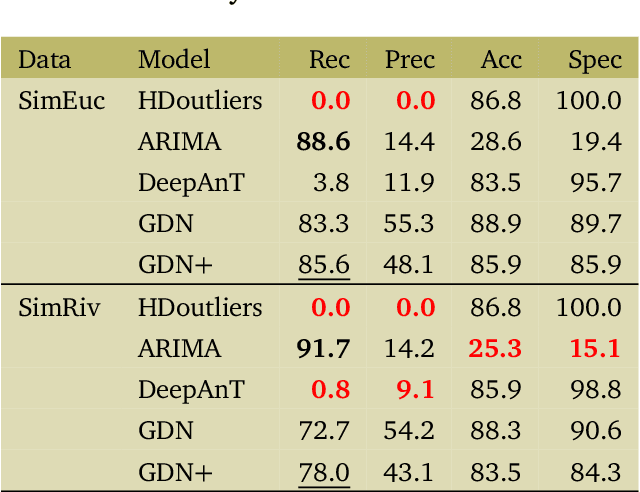
Water is the lifeblood of river networks, and its quality plays a crucial role in sustaining both aquatic ecosystems and human societies. Real-time monitoring of water quality is increasingly reliant on in-situ sensor technology. Anomaly detection is crucial for identifying erroneous patterns in sensor data, but can be a challenging task due to the complexity and variability of the data, even under normal conditions. This paper presents a solution to the challenging task of anomaly detection for river network sensor data, which is essential for accurate and continuous monitoring. We use a graph neural network model, the recently proposed Graph Deviation Network (GDN), which employs graph attention-based forecasting to capture the complex spatio-temporal relationships between sensors. We propose an alternate anomaly scoring method, GDN+, based on the learned graph. To evaluate the model's efficacy, we introduce new benchmarking simulation experiments with highly-sophisticated dependency structures and subsequence anomalies of various types. We further examine the strengths and weaknesses of this baseline approach, GDN, in comparison to other benchmarking methods on complex real-world river network data. Findings suggest that GDN+ outperforms the baseline approach in high-dimensional data, while also providing improved interpretability. We also introduce software called gnnad.
HyperTuner: A Cross-Layer Multi-Objective Hyperparameter Auto-Tuning Framework for Data Analytic Services
Apr 20, 2023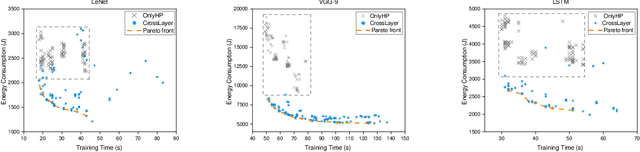

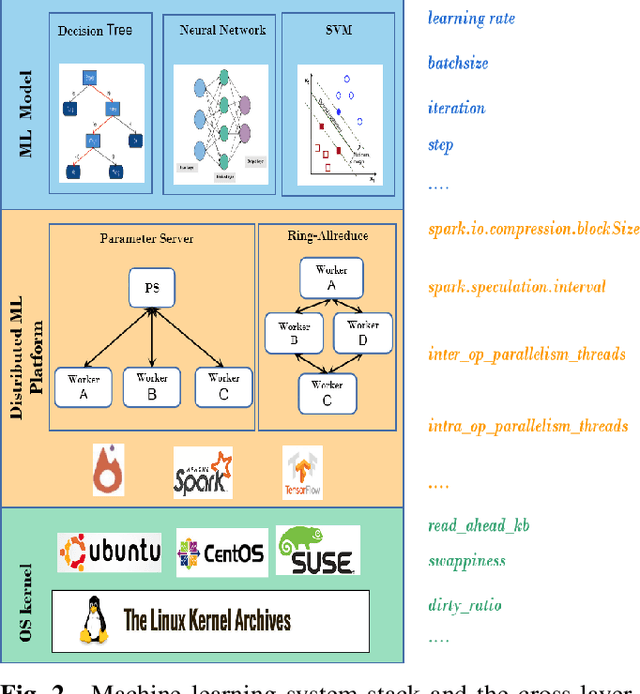
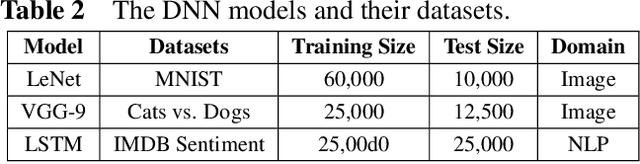
Hyper-parameters optimization (HPO) is vital for machine learning models. Besides model accuracy, other tuning intentions such as model training time and energy consumption are also worthy of attention from data analytic service providers. Hence, it is essential to take both model hyperparameters and system parameters into consideration to execute cross-layer multi-objective hyperparameter auto-tuning. Towards this challenging target, we propose HyperTuner in this paper. To address the formulated high-dimensional black-box multi-objective optimization problem, HyperTuner first conducts multi-objective parameter importance ranking with its MOPIR algorithm and then leverages the proposed ADUMBO algorithm to find the Pareto-optimal configuration set. During each iteration, ADUMBO selects the most promising configuration from the generated Pareto candidate set via maximizing a new well-designed metric, which can adaptively leverage the uncertainty as well as the predicted mean across all the surrogate models along with the iteration times. We evaluate HyperTuner on our local distributed TensorFlow cluster and experimental results show that it is always able to find a better Pareto configuration front superior in both convergence and diversity compared with the other four baseline algorithms. Besides, experiments with different training datasets, different optimization objectives and different machine learning platforms verify that HyperTuner can well adapt to various data analytic service scenarios.
Motion Artifacts Detection in Short-scan Dental CBCT Reconstructions
Apr 20, 2023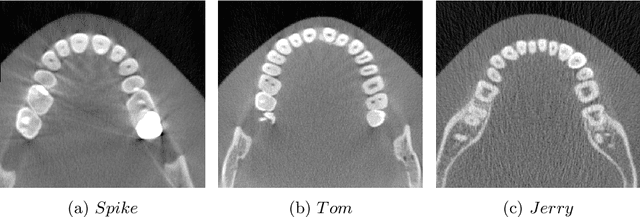
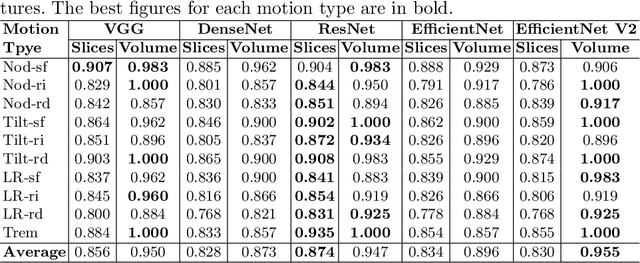
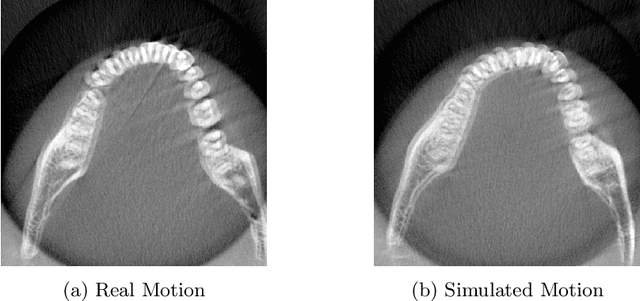
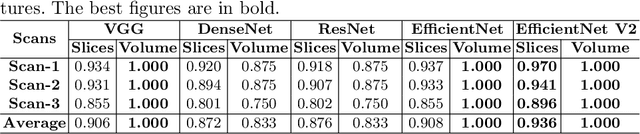
Cone Beam Computed Tomography (CBCT) is widely used in dentistry for diagnostics and treatment planning. CBCT Imaging has a long acquisition time and consequently, the patient is likely to move. This motion causes significant artifacts in the reconstructed data which may lead to misdiagnosis. Existing motion correction algorithms only address this issue partially, struggling with inconsistencies due to truncation, accuracy, and execution speed. On the other hand, a short-scan reconstruction using a subset of motion-free projections with appropriate weighting methods can have a sufficient clinical image quality for most diagnostic purposes. Therefore, a framework is used in this study to extract the motion-free part of the scanned projections with which a clean short-scan volume can be reconstructed without using correction algorithms. Motion artifacts are detected using deep learning with a slice-based prediction scheme followed by volume averaging to get the final result. A realistic motion simulation strategy and data augmentation has been implemented to address data scarcity. The framework has been validated by testing it with real motion-affected data while the model was trained only with simulated motion data. This shows the feasibility to apply the proposed framework to a broad variety of motion cases for further research.
Farm3D: Learning Articulated 3D Animals by Distilling 2D Diffusion
Apr 20, 2023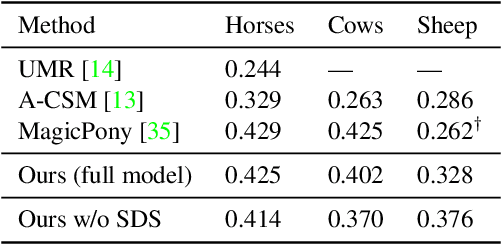
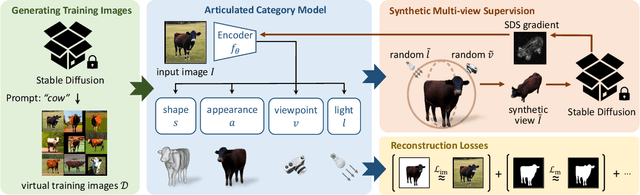

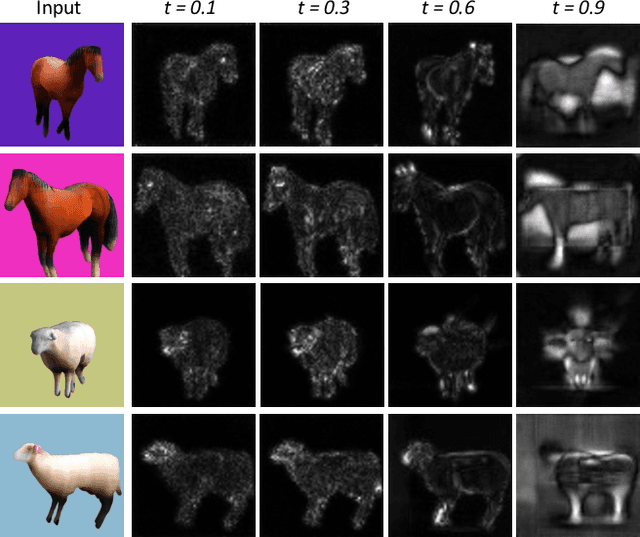
We present Farm3D, a method to learn category-specific 3D reconstructors for articulated objects entirely from "free" virtual supervision from a pre-trained 2D diffusion-based image generator. Recent approaches can learn, given a collection of single-view images of an object category, a monocular network to predict the 3D shape, albedo, illumination and viewpoint of any object occurrence. We propose a framework using an image generator like Stable Diffusion to generate virtual training data for learning such a reconstruction network from scratch. Furthermore, we include the diffusion model as a score to further improve learning. The idea is to randomise some aspects of the reconstruction, such as viewpoint and illumination, generating synthetic views of the reconstructed 3D object, and have the 2D network assess the quality of the resulting image, providing feedback to the reconstructor. Different from work based on distillation which produces a single 3D asset for each textual prompt in hours, our approach produces a monocular reconstruction network that can output a controllable 3D asset from a given image, real or generated, in only seconds. Our network can be used for analysis, including monocular reconstruction, or for synthesis, generating articulated assets for real-time applications such as video games.
DyNCA: Real-time Dynamic Texture Synthesis Using Neural Cellular Automata
Nov 21, 2022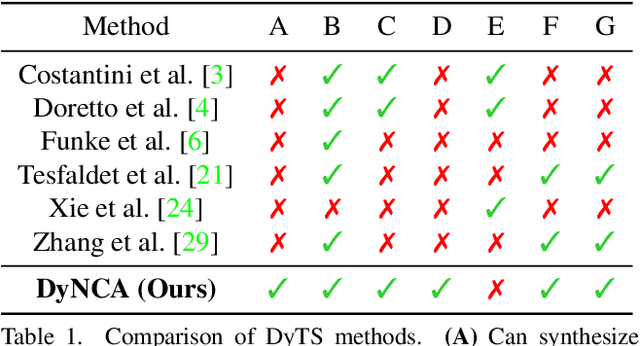
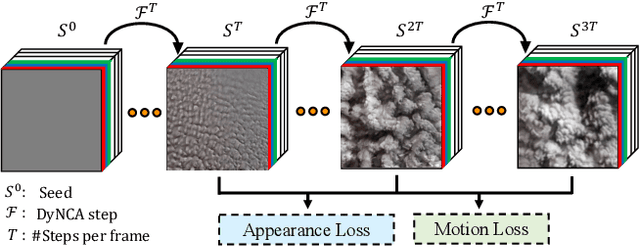
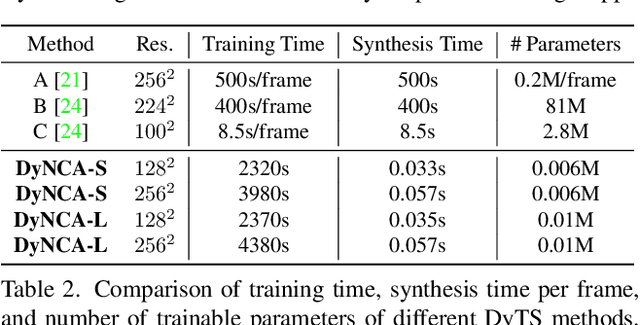
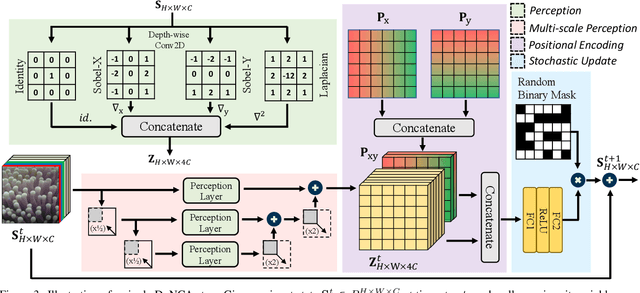
Current Dynamic Texture Synthesis (DyTS) models in the literature can synthesize realistic videos. However, these methods require a slow iterative optimization process to synthesize a single fixed-size short video, and they do not offer any post-training control over the synthesis process. We propose Dynamic Neural Cellular Automata (DyNCA), a framework for real-time and controllable dynamic texture synthesis. Our method is built upon the recently introduced NCA models, and can synthesize infinitely-long and arbitrary-size realistic texture videos in real-time. We quantitatively and qualitatively evaluate our model and show that our synthesized videos appear more realistic than the existing results. We improve the SOTA DyTS performance by $2\sim 4$ orders of magnitude. Moreover, our model offers several real-time and interactive video controls including motion speed, motion direction, and an editing brush tool.
Unfolded Self-Reconstruction LSH: Towards Machine Unlearning in Approximate Nearest Neighbour Search
Apr 06, 2023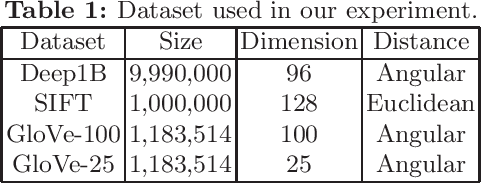
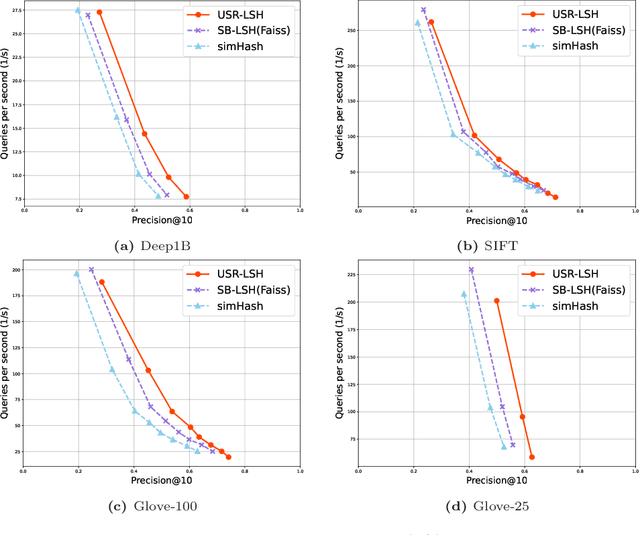
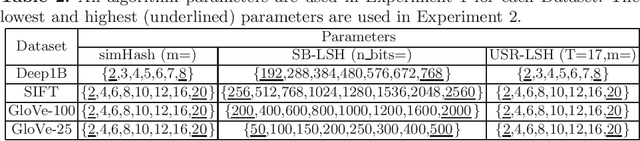
Approximate nearest neighbour (ANN) search is an essential component of search engines, recommendation systems, etc. Many recent works focus on learning-based data-distribution-dependent hashing and achieve good retrieval performance. However, due to increasing demand for users' privacy and security, we often need to remove users' data information from Machine Learning (ML) models to satisfy specific privacy and security requirements. This need requires the ANN search algorithm to support fast online data deletion and insertion. Current learning-based hashing methods need retraining the hash function, which is prohibitable due to the vast time-cost of large-scale data. To address this problem, we propose a novel data-dependent hashing method named unfolded self-reconstruction locality-sensitive hashing (USR-LSH). Our USR-LSH unfolded the optimization update for instance-wise data reconstruction, which is better for preserving data information than data-independent LSH. Moreover, our USR-LSH supports fast online data deletion and insertion without retraining. To the best of our knowledge, we are the first to address the machine unlearning of retrieval problems. Empirically, we demonstrate that USR-LSH outperforms the state-of-the-art data-distribution-independent LSH in ANN tasks in terms of precision and recall. We also show that USR-LSH has significantly faster data deletion and insertion time than learning-based data-dependent hashing.
Tensor Slicing and Optimization for Multicore NPUs
Apr 06, 2023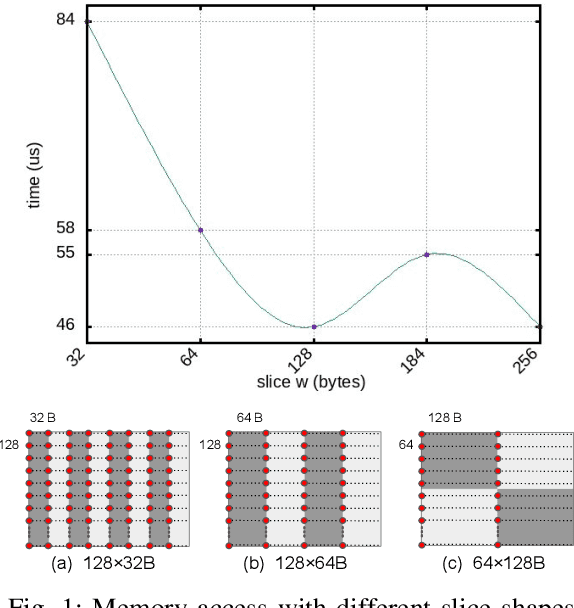
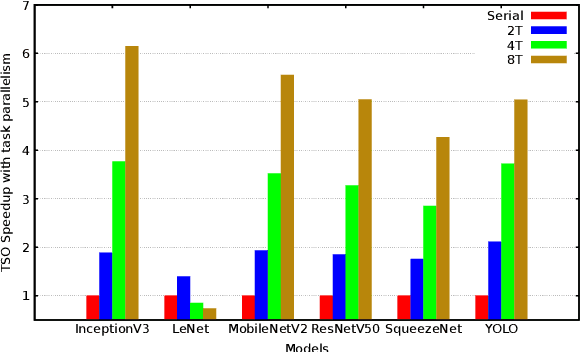
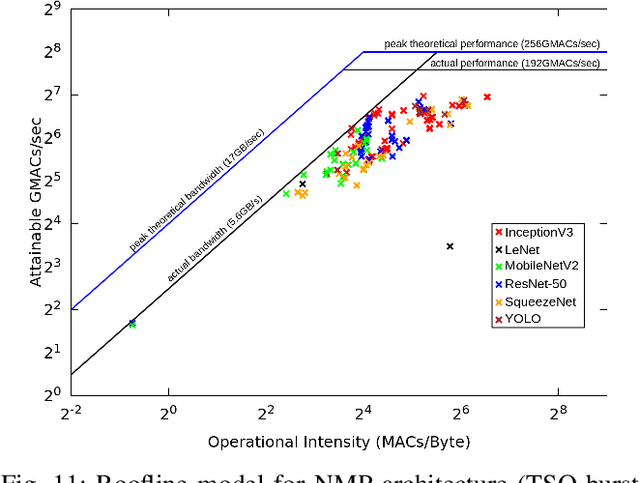
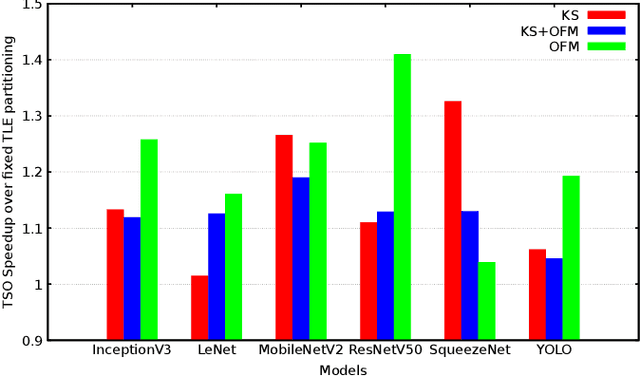
Although code generation for Convolution Neural Network (CNN) models has been extensively studied, performing efficient data slicing and parallelization for highly-constrai\-ned Multicore Neural Processor Units (NPUs) is still a challenging problem. Given the size of convolutions' input/output tensors and the small footprint of NPU on-chip memories, minimizing memory transactions while maximizing parallelism and MAC utilization are central to any effective solution. This paper proposes a TensorFlow XLA/LLVM compiler optimization pass for Multicore NPUs, called Tensor Slicing Optimization (TSO), which: (a) maximizes convolution parallelism and memory usage across NPU cores; and (b) reduces data transfers between host and NPU on-chip memories by using DRAM memory burst time estimates to guide tensor slicing. To evaluate the proposed approach, a set of experiments was performed using the NeuroMorphic Processor (NMP), a multicore NPU containing 32 RISC-V cores extended with novel CNN instructions. Experimental results show that TSO is capable of identifying the best tensor slicing that minimizes execution time for a set of CNN models. Speed-ups of up to 21.7\% result when comparing the TSO burst-based technique to a no-burst data slicing approach. To validate the generality of the TSO approach, the algorithm was also ported to the Glow Machine Learning framework. The performance of the models were measured on both Glow and TensorFlow XLA/LLVM compilers, revealing similar results.
MasaCtrl: Tuning-Free Mutual Self-Attention Control for Consistent Image Synthesis and Editing
Apr 17, 2023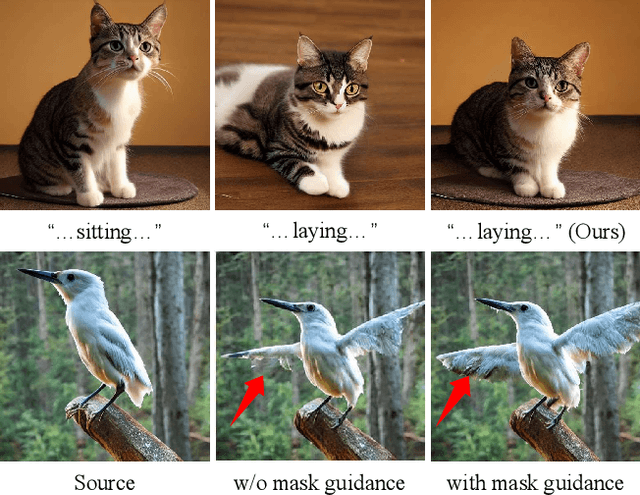
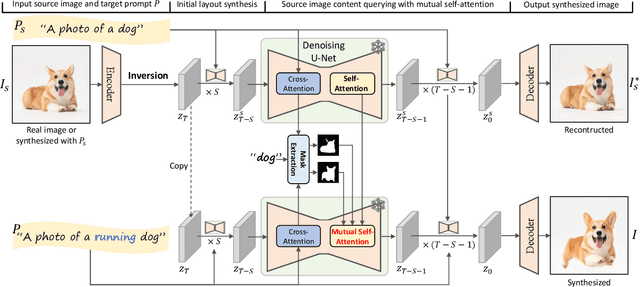
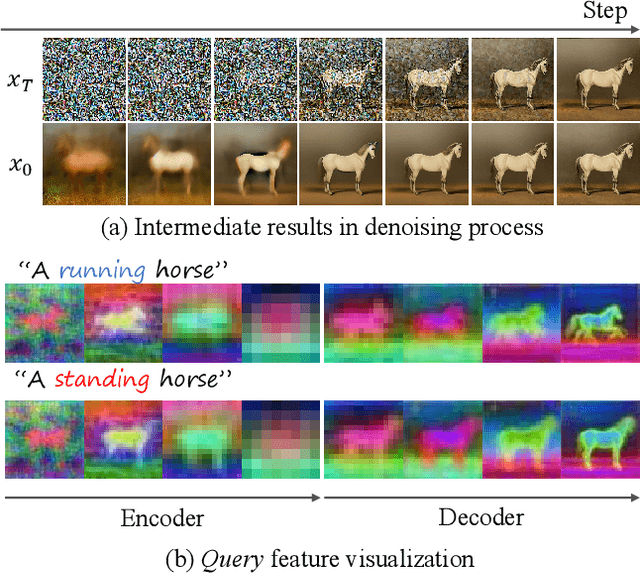
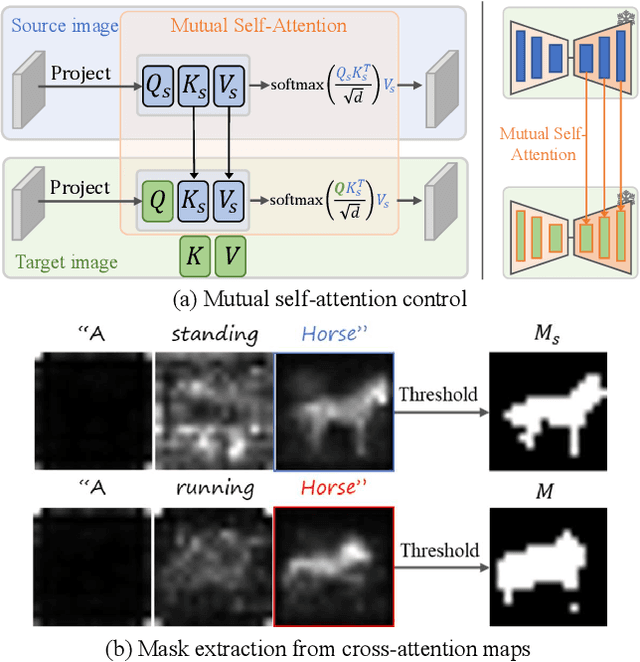
Despite the success in large-scale text-to-image generation and text-conditioned image editing, existing methods still struggle to produce consistent generation and editing results. For example, generation approaches usually fail to synthesize multiple images of the same objects/characters but with different views or poses. Meanwhile, existing editing methods either fail to achieve effective complex non-rigid editing while maintaining the overall textures and identity, or require time-consuming fine-tuning to capture the image-specific appearance. In this paper, we develop MasaCtrl, a tuning-free method to achieve consistent image generation and complex non-rigid image editing simultaneously. Specifically, MasaCtrl converts existing self-attention in diffusion models into mutual self-attention, so that it can query correlated local contents and textures from source images for consistency. To further alleviate the query confusion between foreground and background, we propose a mask-guided mutual self-attention strategy, where the mask can be easily extracted from the cross-attention maps. Extensive experiments show that the proposed MasaCtrl can produce impressive results in both consistent image generation and complex non-rigid real image editing.