 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
VGOS: Voxel Grid Optimization for View Synthesis from Sparse Inputs
Apr 26, 2023
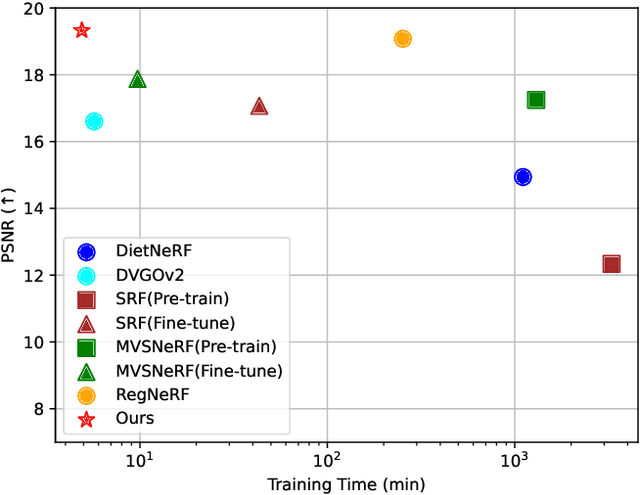
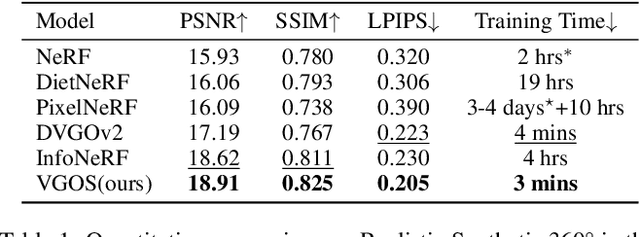
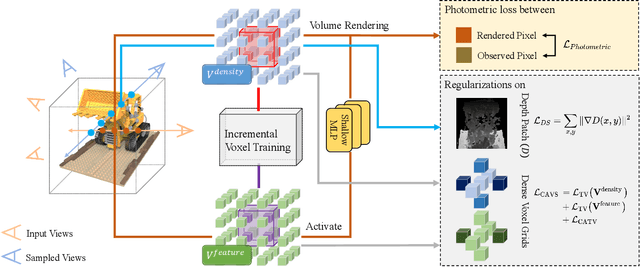
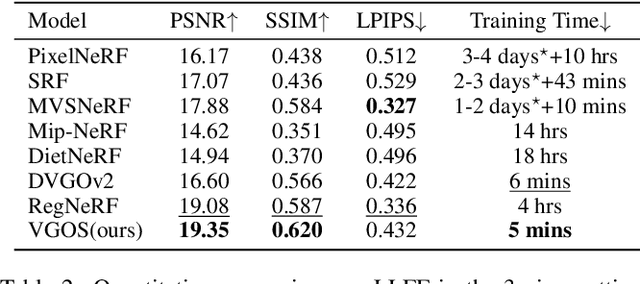
Neural Radiance Fields (NeRF) has shown great success in novel view synthesis due to its state-of-the-art quality and flexibility. However, NeRF requires dense input views (tens to hundreds) and a long training time (hours to days) for a single scene to generate high-fidelity images. Although using the voxel grids to represent the radiance field can significantly accelerate the optimization process, we observe that for sparse inputs, the voxel grids are more prone to overfitting to the training views and will have holes and floaters, which leads to artifacts. In this paper, we propose VGOS, an approach for fast (3-5 minutes) radiance field reconstruction from sparse inputs (3-10 views) to address these issues. To improve the performance of voxel-based radiance field in sparse input scenarios, we propose two methods: (a) We introduce an incremental voxel training strategy, which prevents overfitting by suppressing the optimization of peripheral voxels in the early stage of reconstruction. (b) We use several regularization techniques to smooth the voxels, which avoids degenerate solutions. Experiments demonstrate that VGOS achieves state-of-the-art performance for sparse inputs with super-fast convergence. Code will be available at https://github.com/SJoJoK/VGOS.
Is a prompt and a few samples all you need? Using GPT-4 for data augmentation in low-resource classification tasks
Apr 26, 2023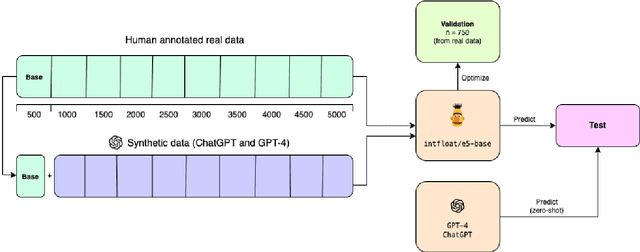

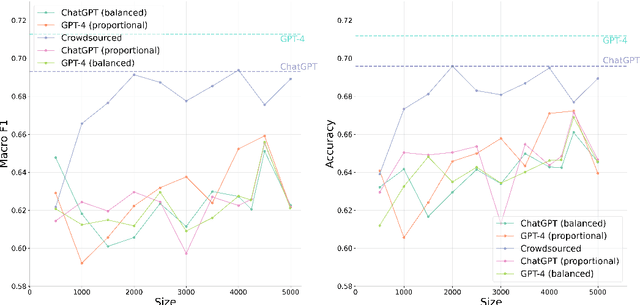
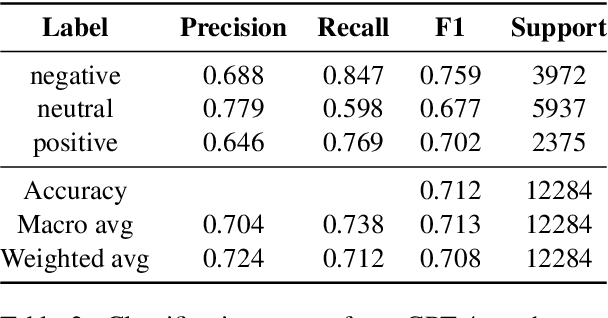
Obtaining and annotating data can be expensive and time-consuming, especially in complex, low-resource domains. We use GPT-4 and ChatGPT to augment small labeled datasets with synthetic data via simple prompts, in three different classification tasks with varying complexity. For each task, we randomly select a base sample of 500 texts to generate 5,000 new synthetic samples. We explore two augmentation strategies: one that preserves original label distribution and another that balances the distribution. Using a progressively larger training sample size, we train and evaluate a 110M parameter multilingual language model on the real and synthetic data separately. We also test GPT-4 and ChatGPT in a zero-shot setting on the test sets. We observe that GPT-4 and ChatGPT have strong zero-shot performance across all tasks. We find that data augmented with synthetic samples yields a good downstream performance, and particularly aids in low-resource settings, such as in identifying rare classes. Human-annotated data exhibits a strong predictive power, overtaking synthetic data in two out of the three tasks. This finding highlights the need for more complex prompts for synthetic datasets to consistently surpass human-generated ones.
Multimodal Composite Association Score: Measuring Gender Bias in Generative Multimodal Models
Apr 26, 2023
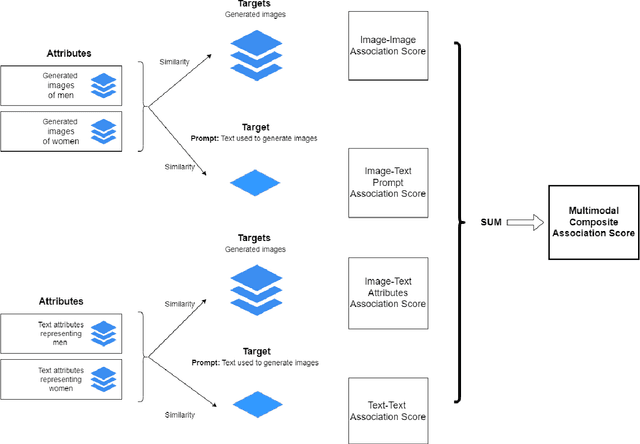

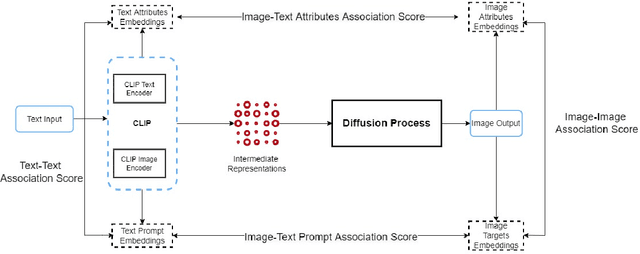
Generative multimodal models based on diffusion models have seen tremendous growth and advances in recent years. Models such as DALL-E and Stable Diffusion have become increasingly popular and successful at creating images from texts, often combining abstract ideas. However, like other deep learning models, they also reflect social biases they inherit from their training data, which is often crawled from the internet. Manually auditing models for biases can be very time and resource consuming and is further complicated by the unbounded and unconstrained nature of inputs these models can take. Research into bias measurement and quantification has generally focused on small single-stage models working on a single modality. Thus the emergence of multistage multimodal models requires a different approach. In this paper, we propose Multimodal Composite Association Score (MCAS) as a new method of measuring gender bias in multimodal generative models. Evaluating both DALL-E 2 and Stable Diffusion using this approach uncovered the presence of gendered associations of concepts embedded within the models. We propose MCAS as an accessible and scalable method of quantifying potential bias for models with different modalities and a range of potential biases.
OFAR: A Multimodal Evidence Retrieval Framework for Illegal Live-streaming Identification
Apr 26, 2023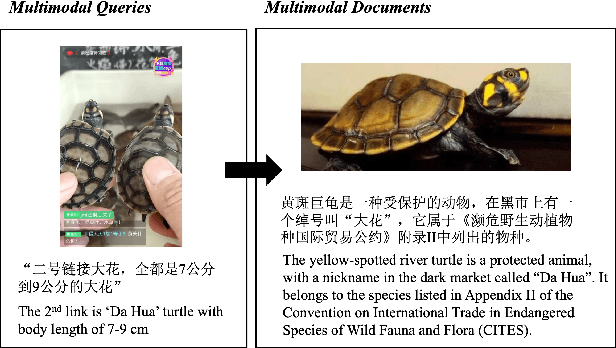
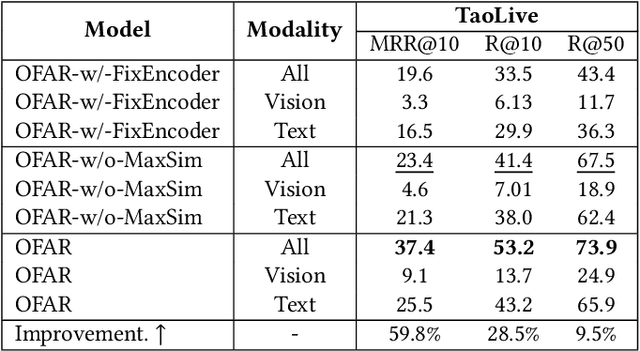
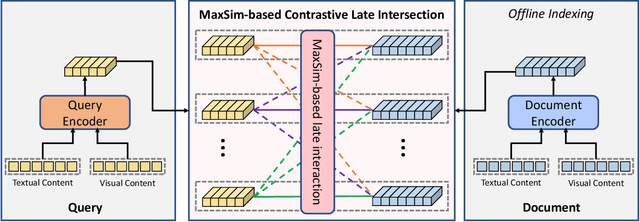
Illegal live-streaming identification, which aims to help live-streaming platforms immediately recognize the illegal behaviors in the live-streaming, such as selling precious and endangered animals, plays a crucial role in purifying the network environment. Traditionally, the live-streaming platform needs to employ some professionals to manually identify the potential illegal live-streaming. Specifically, the professional needs to search for related evidence from a large-scale knowledge database for evaluating whether a given live-streaming clip contains illegal behavior, which is time-consuming and laborious. To address this issue, in this work, we propose a multimodal evidence retrieval system, named OFAR, to facilitate the illegal live-streaming identification. OFAR consists of three modules: Query Encoder, Document Encoder, and MaxSim-based Contrastive Late Intersection. Both query encoder and document encoder are implemented with the advanced OFA encoder, which is pretrained on a large-scale multimodal dataset. In the last module, we introduce contrastive learning on the basis of the MaxiSim-based late intersection, to enhance the model's ability of query-document matching. The proposed framework achieves significant improvement on our industrial dataset TaoLive, demonstrating the advances of our scheme.
Probabilistic Querying of Continuous-Time Event Sequences
Nov 15, 2022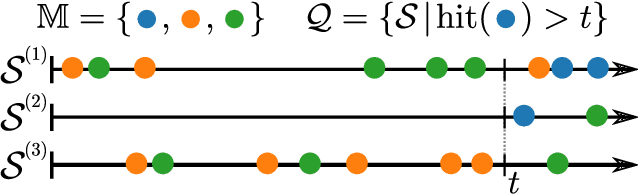

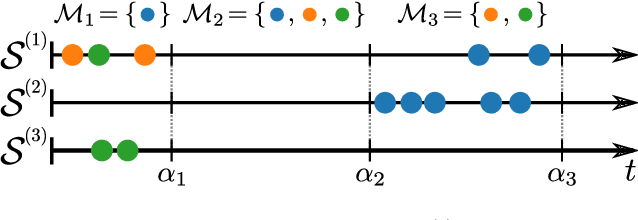
Continuous-time event sequences, i.e., sequences consisting of continuous time stamps and associated event types ("marks"), are an important type of sequential data with many applications, e.g., in clinical medicine or user behavior modeling. Since these data are typically modeled autoregressively (e.g., using neural Hawkes processes or their classical counterparts), it is natural to ask questions about future scenarios such as "what kind of event will occur next" or "will an event of type $A$ occur before one of type $B$". Unfortunately, some of these queries are notoriously hard to address since current methods are limited to naive simulation, which can be highly inefficient. This paper introduces a new typology of query types and a framework for addressing them using importance sampling. Example queries include predicting the $n^\text{th}$ event type in a sequence and the hitting time distribution of one or more event types. We also leverage these findings further to be applicable for estimating general "$A$ before $B$" type of queries. We prove theoretically that our estimation method is effectively always better than naive simulation and show empirically based on three real-world datasets that it is on average 1,000 times more efficient than existing approaches.
Asynchronous Federated Continual Learning
Apr 07, 2023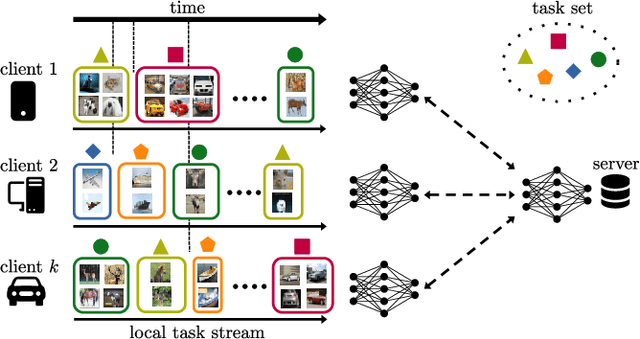
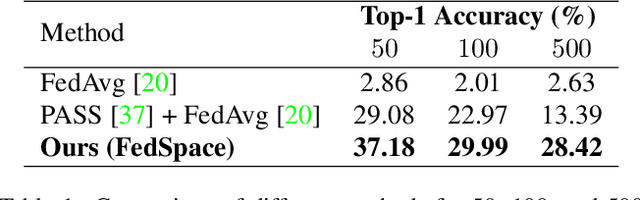
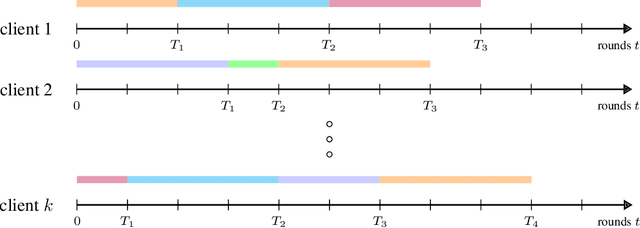
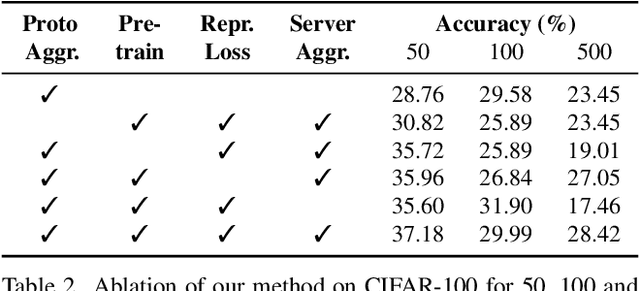
The standard class-incremental continual learning setting assumes a set of tasks seen one after the other in a fixed and predefined order. This is not very realistic in federated learning environments where each client works independently in an asynchronous manner getting data for the different tasks in time-frames and orders totally uncorrelated with the other ones. We introduce a novel federated learning setting (AFCL) where the continual learning of multiple tasks happens at each client with different orderings and in asynchronous time slots. We tackle this novel task using prototype-based learning, a representation loss, fractal pre-training, and a modified aggregation policy. Our approach, called FedSpace, effectively tackles this task as shown by the results on the CIFAR-100 dataset using 3 different federated splits with 50, 100, and 500 clients, respectively. The code and federated splits are available at https://github.com/LTTM/FedSpace.
Towards Better Long-range Time Series Forecasting using Generative Forecasting
Dec 09, 2022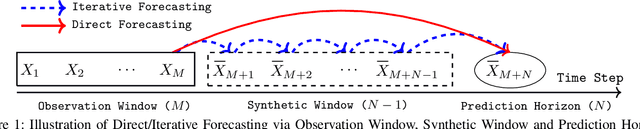
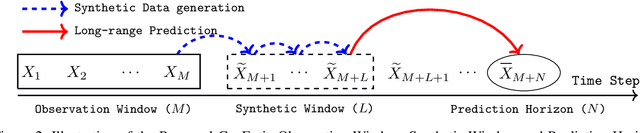
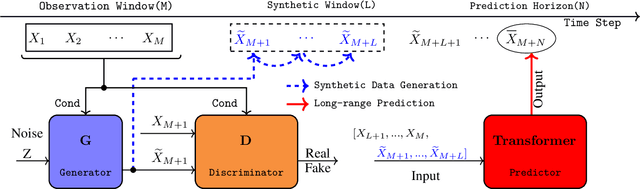
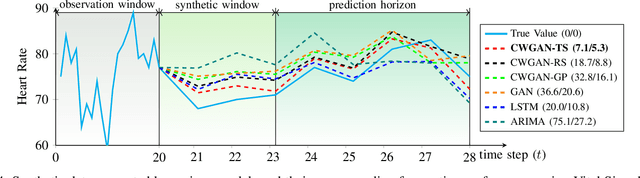
Long-range time series forecasting is usually based on one of two existing forecasting strategies: Direct Forecasting and Iterative Forecasting, where the former provides low bias, high variance forecasts and the latter leads to low variance, high bias forecasts. In this paper, we propose a new forecasting strategy called Generative Forecasting (GenF), which generates synthetic data for the next few time steps and then makes long-range forecasts based on generated and observed data. We theoretically prove that GenF is able to better balance the forecasting variance and bias, leading to a much smaller forecasting error. We implement GenF via three components: (i) a novel conditional Wasserstein Generative Adversarial Network (GAN) based generator for synthetic time series data generation, called CWGAN-TS. (ii) a transformer based predictor, which makes long-range predictions using both generated and observed data. (iii) an information theoretic clustering algorithm to improve the training of both the CWGAN-TS and the transformer based predictor. The experimental results on five public datasets demonstrate that GenF significantly outperforms a diverse range of state-of-the-art benchmarks and classical approaches. Specifically, we find a 5% - 11% improvement in predictive performance (mean absolute error) while having a 15% - 50% reduction in parameters compared to the benchmarks. Lastly, we conduct an ablation study to further explore and demonstrate the effectiveness of the components comprising GenF.
MS-LSTM: Exploring Spatiotemporal Multiscale Representations in Video Prediction Domain
Apr 22, 2023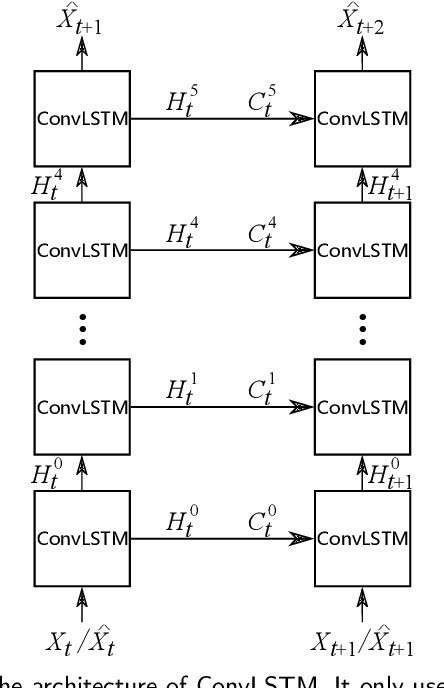
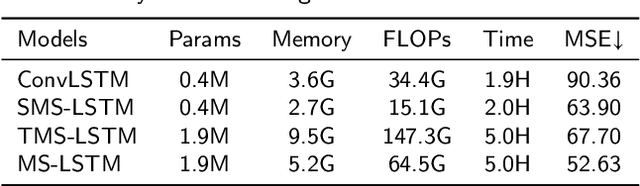
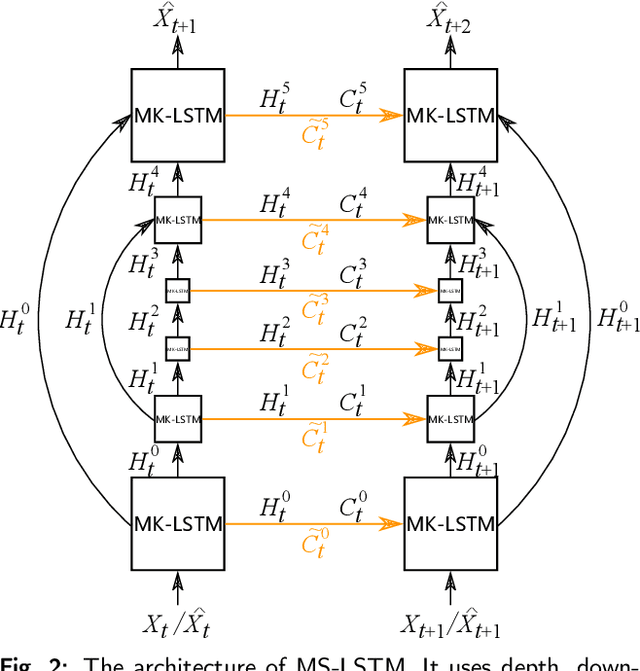
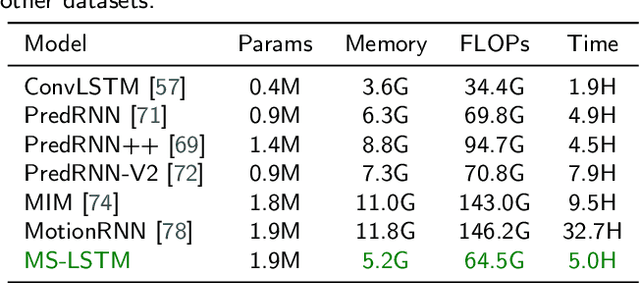
The drastic variation of motion in spatial and temporal dimensions makes the video prediction task extremely challenging. Existing RNN models obtain higher performance by deepening or widening the model. They obtain the multi-scale features of the video only by stacking layers, which is inefficient and brings unbearable training costs (such as memory, FLOPs, and training time). Different from them, this paper proposes a spatiotemporal multi-scale model called MS-LSTM wholly from a multi-scale perspective. On the basis of stacked layers, MS-LSTM incorporates two additional efficient multi-scale designs to fully capture spatiotemporal context information. Concretely, we employ LSTMs with mirrored pyramid structures to construct spatial multi-scale representations and LSTMs with different convolution kernels to construct temporal multi-scale representations. Detailed comparison experiments with eight baseline models on four video datasets show that MS-LSTM has better performance but lower training costs.
Optimal Virtual Tube Planning and Control for Swarm Robotics
Apr 22, 2023
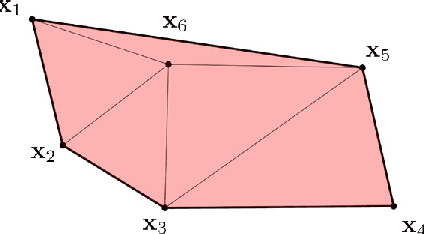
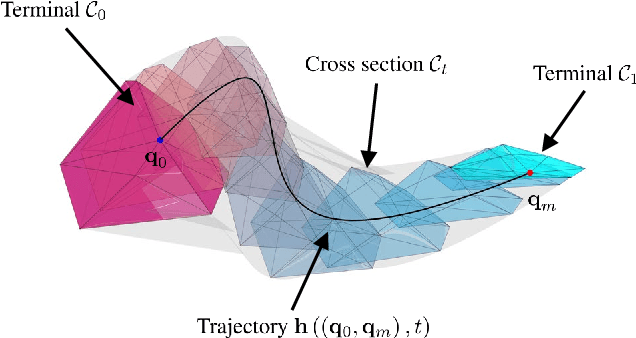
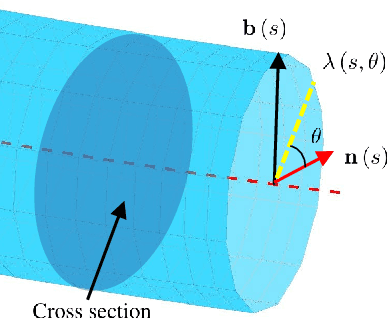
This paper presents a novel method for efficiently solving trajectory planning problems for swarm robotics in cluttered environments. While recent research has demonstrated high success rates in real-time local trajectory planning for swarm robotics in cluttered environments, optimizing every trajectory for each robot is computationally expensive, with a computational complexity of $O\left(n^2\right)$ to $ O\left(n^3\right)$. To address this issue, we first propose the concept of the \emph{optimal virtual tube}, which includes infinite optimal trajectories. Under certain conditions, any optimal trajectory in the optimal virtual tube can be expressed as a convex combination of a finite number of optimal trajectories, with a computational complexity of $O\left(1\right)$. Afterward, a planning method of \emph{the optimal virtual tube} is proposed. In simulations and experiments, we show that the proposed method efficiently reduces calculation and is validated by comparison with traditional methods.
LIMIT: Learning Interfaces to Maximize Information Transfer
Apr 17, 2023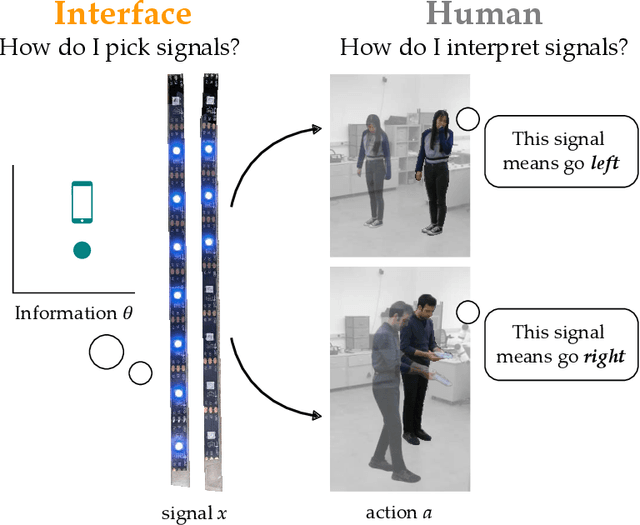

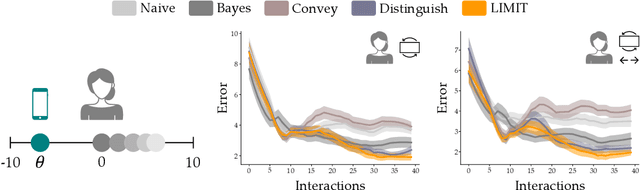

Robots can use auditory, visual, or haptic interfaces to convey information to human users. The way these interfaces select signals is typically pre-defined by the designer: for instance, a haptic wristband might vibrate when the robot is moving and squeeze when the robot stops. But different people interpret the same signals in different ways, so that what makes sense to one person might be confusing or unintuitive to another. In this paper we introduce a unified algorithmic formalism for learning co-adaptive interfaces from scratch. Our method does not need to know the human's task (i.e., what the human is using these signals for). Instead, our insight is that interpretable interfaces should select signals that maximize correlation between the human's actions and the information the interface is trying to convey. Applying this insight we develop LIMIT: Learning Interfaces to Maximize Information Transfer. LIMIT optimizes a tractable, real-time proxy of information gain in continuous spaces. The first time a person works with our system the signals may appear random; but over repeated interactions the interface learns a one-to-one mapping between displayed signals and human responses. Our resulting approach is both personalized to the current user and not tied to any specific interface modality. We compare LIMIT to state-of-the-art baselines across controlled simulations, an online survey, and an in-person user study with auditory, visual, and haptic interfaces. Overall, our results suggest that LIMIT learns interfaces that enable users to complete the task more quickly and efficiently, and users subjectively prefer LIMIT to the alternatives. See videos here: https://youtu.be/IvQ3TM1_2fA.