 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Autoencoders for discovering manifold dimension and coordinates in data from complex dynamical systems
May 01, 2023
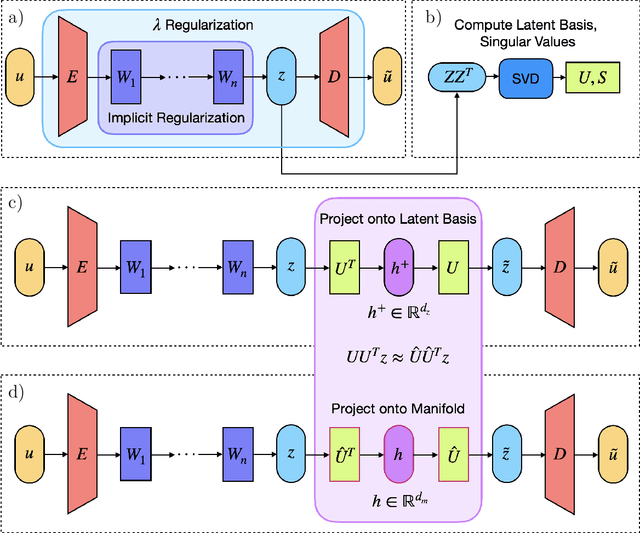

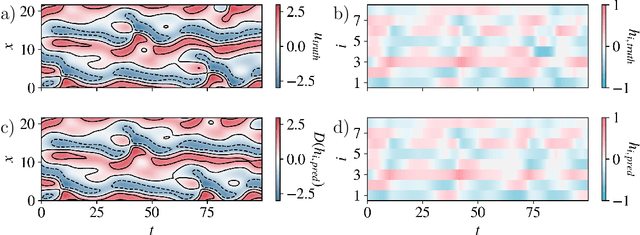
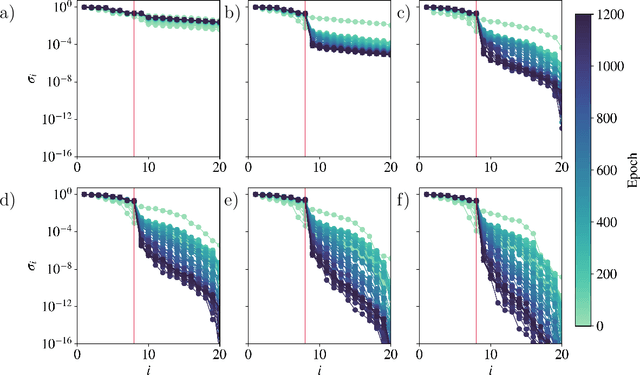
While many phenomena in physics and engineering are formally high-dimensional, their long-time dynamics often live on a lower-dimensional manifold. The present work introduces an autoencoder framework that combines implicit regularization with internal linear layers and $L_2$ regularization (weight decay) to automatically estimate the underlying dimensionality of a data set, produce an orthogonal manifold coordinate system, and provide the mapping functions between the ambient space and manifold space, allowing for out-of-sample projections. We validate our framework's ability to estimate the manifold dimension for a series of datasets from dynamical systems of varying complexities and compare to other state-of-the-art estimators. We analyze the training dynamics of the network to glean insight into the mechanism of low-rank learning and find that collectively each of the implicit regularizing layers compound the low-rank representation and even self-correct during training. Analysis of gradient descent dynamics for this architecture in the linear case reveals the role of the internal linear layers in leading to faster decay of a "collective weight variable" incorporating all layers, and the role of weight decay in breaking degeneracies and thus driving convergence along directions in which no decay would occur in its absence. We show that this framework can be naturally extended for applications of state-space modeling and forecasting by generating a data-driven dynamic model of a spatiotemporally chaotic partial differential equation using only the manifold coordinates. Finally, we demonstrate that our framework is robust to hyperparameter choices.
Correlation-Driven Multi-Level Multimodal Learning for Anomaly Detection on Multiple Energy Sources
May 01, 2023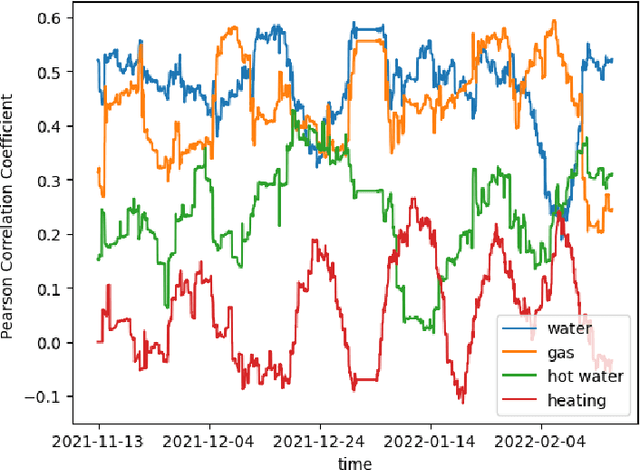
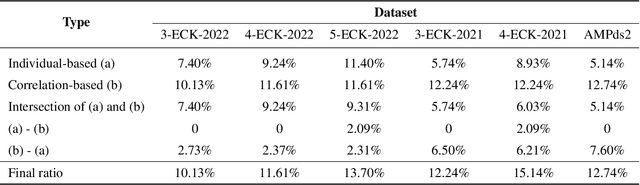
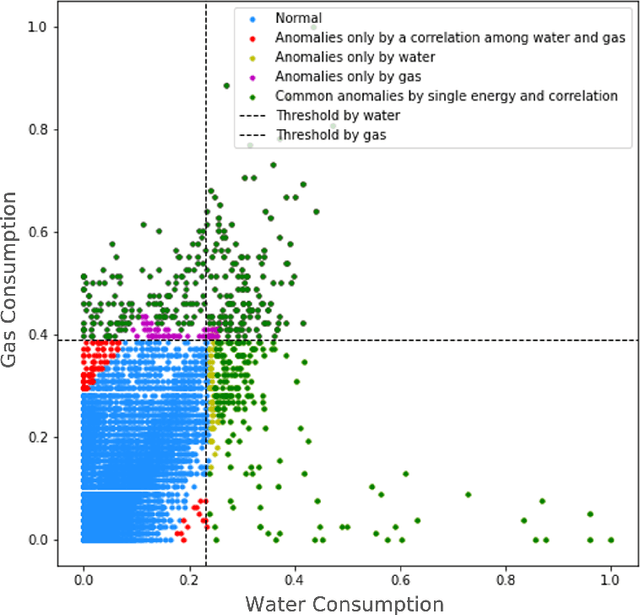

Advanced metering infrastructure (AMI) has been widely used as an intelligent energy consumption measurement system. Electric power was the representative energy source that can be collected by AMI; most existing studies to detect abnormal energy consumption have focused on a single energy source, i.e., power. Recently, other energy sources such as water, gas, and heating have also been actively collected. As a result, it is necessary to develop a unified methodology for anomaly detection across multiple energy sources; however, research efforts have rarely been made to tackle this issue. The inherent difficulty with this issue stems from the fact that anomalies are not usually annotated. Moreover, existing works of anomaly definition depend on only individual energy sources. In this paper, we first propose a method for defining anomalies considering not only individual energy sources but also correlations between them. Then, we propose a new Correlation-driven Multi-Level Multimodal Learning model for anomaly detection on multiple energy sources. The distinguishing property of the model incorporates multiple energy sources in multi-levels based on the strengths of the correlations between them. Furthermore, we generalize the proposed model in order to integrate arbitrary new energy sources with further performance improvement, considering not only correlated but also non-correlated sources. Through extensive experiments on real-world datasets consisting of three to five energy sources, we demonstrate that the proposed model clearly outperforms the existing multimodal learning and recent time-series anomaly detection models, and we observe that our model makes further the performance improvement as more correlated or non-correlated energy sources are integrated.
An Iterative Algorithm for Rescaled Hyperbolic Functions Regression
May 01, 2023Large language models (LLMs) have numerous real-life applications across various domains, such as natural language translation, sentiment analysis, language modeling, chatbots and conversational agents, creative writing, text classification, summarization, and generation. LLMs have shown great promise in improving the accuracy and efficiency of these tasks, and have the potential to revolutionize the field of natural language processing (NLP) in the years to come. Exponential function based attention unit is a fundamental element in LLMs. Several previous works have studied the convergence of exponential regression and softmax regression. The exponential regression [Li, Song, Zhou 2023] and softmax regression [Deng, Li, Song 2023] can be formulated as follows. Given matrix $A \in \mathbb{R}^{n \times d}$ and vector $b \in \mathbb{R}^n$, the goal of exponential regression is to solve \begin{align*} \min_{x} \| \exp(Ax) - b \|_2 \end{align*} and the goal of softmax regression is to solve \begin{align*} \min_{x} \| \langle \exp(Ax) , {\bf 1}_n \rangle^{-1} \exp(Ax) - b \|_2 . \end{align*} In this work, we define a slightly different formulation than softmax regression. \begin{align*} \min_{x \in \mathbb{R}^d } \| u(x) - \langle u(x) , {\bf 1}_n \rangle \cdot b \|_2 \end{align*} where $u(x) \in \{ \exp(Ax), \cosh(Ax) , \sinh(Ax) \}$. We provide an input sparsity time algorithm for this problem. Our algorithm framework is very general and can be applied to functions like $\cosh()$ and $\sinh()$ as well. Our technique is also general enough to be applied to in-context learning for rescaled softmax regression.
Towards systematic intraday news screening: a liquidity-focused approach
Apr 11, 2023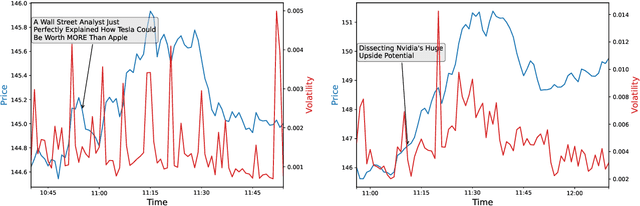
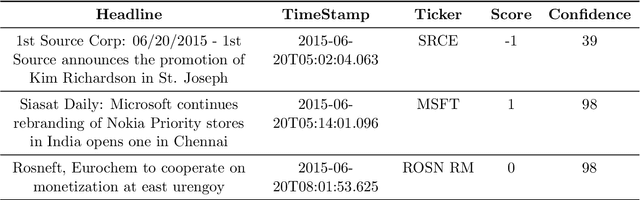
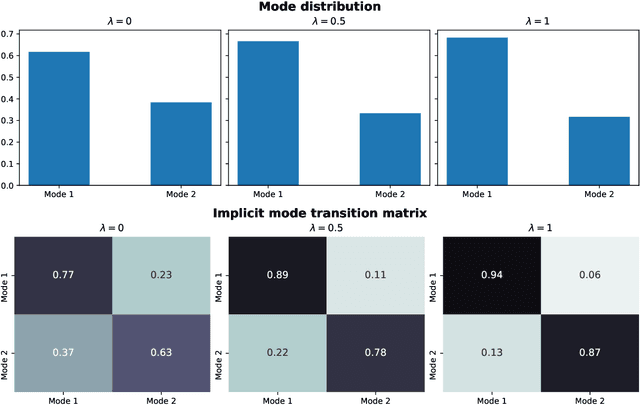
News can convey bearish or bullish views on financial assets. Institutional investors need to evaluate automatically the implied news sentiment based on textual data. Given the huge amount of news articles published each day, most of which are neutral, we present a systematic news screening method to identify the ``true'' impactful ones, aiming for more effective development of news sentiment learning methods. Based on several liquidity-driven variables, including volatility, turnover, bid-ask spread, and book size, we associate each 5-min time bin to one of two specific liquidity modes. One represents the ``calm'' state at which the market stays for most of the time and the other, featured with relatively higher levels of volatility and trading volume, describes the regime driven by some exogenous events. Then we focus on the moments where the liquidity mode switches from the former to the latter and consider the news articles published nearby impactful. We apply naive Bayes on these filtered samples for news sentiment classification as an illustrative example. We show that the screened dataset leads to more effective feature capturing and thus superior performance on short-term asset return prediction compared to the original dataset.
Survey on Leveraging Uncertainty Estimation Towards Trustworthy Deep Neural Networks: The Case of Reject Option and Post-training Processing
Apr 11, 2023
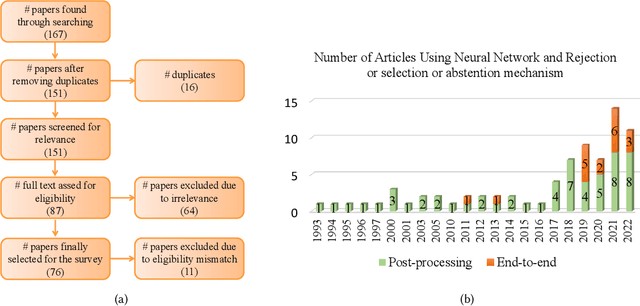

Although neural networks (especially deep neural networks) have achieved \textit{better-than-human} performance in many fields, their real-world deployment is still questionable due to the lack of awareness about the limitation in their knowledge. To incorporate such awareness in the machine learning model, prediction with reject option (also known as selective classification or classification with abstention) has been proposed in literature. In this paper, we present a systematic review of the prediction with the reject option in the context of various neural networks. To the best of our knowledge, this is the first study focusing on this aspect of neural networks. Moreover, we discuss different novel loss functions related to the reject option and post-training processing (if any) of network output for generating suitable measurements for knowledge awareness of the model. Finally, we address the application of the rejection option in reducing the prediction time for the real-time problems and present a comprehensive summary of the techniques related to the reject option in the context of extensive variety of neural networks. Our code is available on GitHub: \url{https://github.com/MehediHasanTutul/Reject_option}
Auditing and Generating Synthetic Data with Controllable Trust Trade-offs
May 02, 2023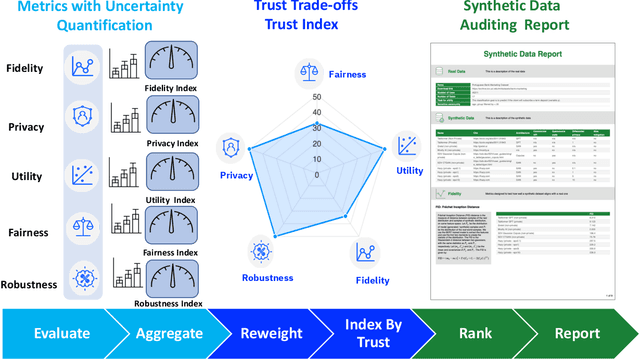
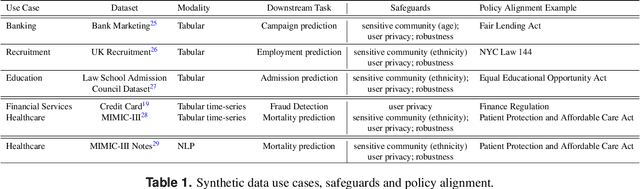
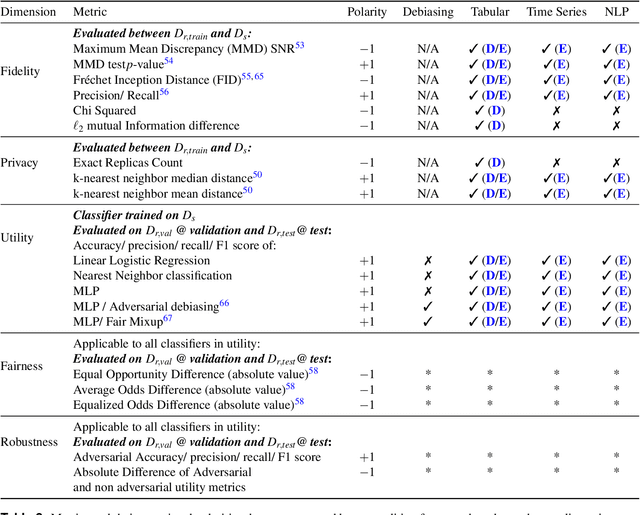
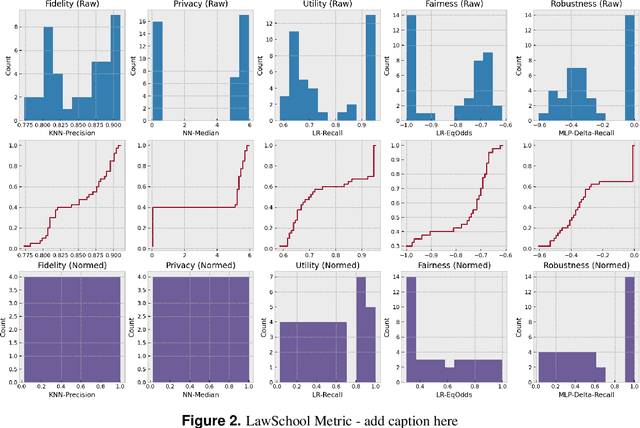
Data collected from the real world tends to be biased, unbalanced, and at risk of exposing sensitive and private information. This reality has given rise to the idea of creating synthetic datasets to alleviate risk, bias, harm, and privacy concerns inherent in the real data. This concept relies on Generative AI models to produce unbiased, privacy-preserving synthetic data while being true to the real data. In this new paradigm, how can we tell if this approach delivers on its promises? We present an auditing framework that offers a holistic assessment of synthetic datasets and AI models trained on them, centered around bias and discrimination prevention, fidelity to the real data, utility, robustness, and privacy preservation. We showcase our framework by auditing multiple generative models on diverse use cases, including education, healthcare, banking, human resources, and across different modalities, from tabular, to time-series, to natural language. Our use cases demonstrate the importance of a holistic assessment in order to ensure compliance with socio-technical safeguards that regulators and policymakers are increasingly enforcing. For this purpose, we introduce the trust index that ranks multiple synthetic datasets based on their prescribed safeguards and their desired trade-offs. Moreover, we devise a trust-index-driven model selection and cross-validation procedure via auditing in the training loop that we showcase on a class of transformer models that we dub TrustFormers, across different modalities. This trust-driven model selection allows for controllable trust trade-offs in the resulting synthetic data. We instrument our auditing framework with workflows that connect different stakeholders from model development to audit and certification via a synthetic data auditing report.
SIA-FTP: A Spoken Instruction Aware Flight Trajectory Prediction Framework
May 02, 2023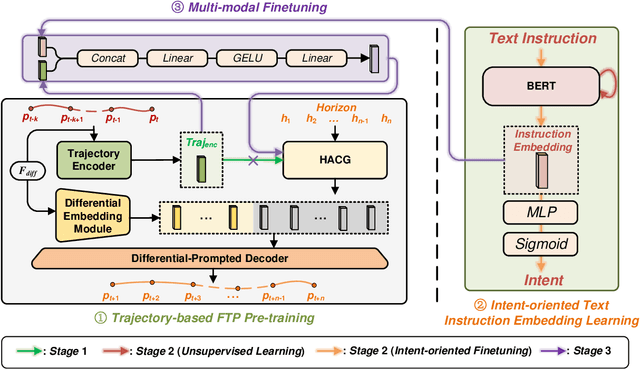

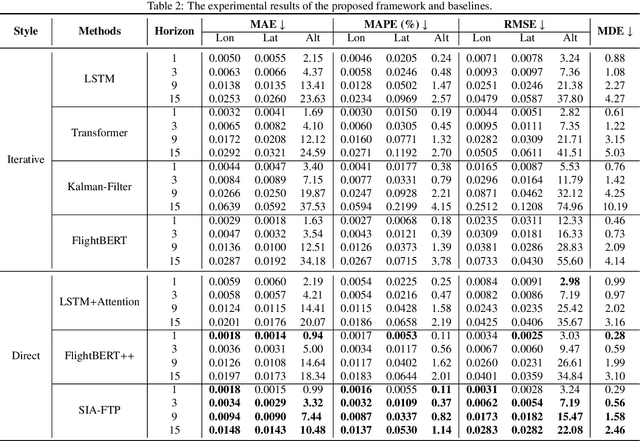
Ground-air negotiation via speech communication is a vital prerequisite for ensuring safety and efficiency in air traffic control (ATC) operations. However, with the increase in traffic flow, incorrect instructions caused by human factors bring a great threat to ATC safety. Existing flight trajectory prediction (FTP) approaches primarily rely on the flight status of historical trajectory, leading to significant delays in the prediction of real-time maneuvering instruction, which is not conducive to conflict detection. A major reason is that spoken instructions and flight trajectories are presented in different modalities in the current air traffic control (ATC) system, bringing great challenges to considering the maneuvering instruction in the FTP tasks. In this paper, a spoken instruction-aware FTP framework, called SIA-FTP, is innovatively proposed to support high-maneuvering FTP tasks by incorporating instant spoken instruction. To address the modality gap and minimize the data requirements, a 3-stage learning paradigm is proposed to implement the SIA-FTP framework in a progressive manner, including trajectory-based FTP pretraining, intent-oriented instruction embedding learning, and multi-modal finetuning. Specifically, the FTP model and the instruction embedding with maneuvering semantics are pre-trained using volumes of well-resourced trajectory and text data in the 1st and 2nd stages. In succession, a multi-modal fusion strategy is proposed to incorporate the pre-trained instruction embedding into the FTP model and integrate the two pre-trained networks into a joint model. Finally, the joint model is finetuned using the limited trajectory-instruction data to enhance the FTP performance within maneuvering instruction scenarios. The experimental results demonstrated that the proposed framework presents an impressive performance improvement in high-maneuvering scenarios.
ADVISE: AI-accelerated Design of Evidence Synthesis for Global Development
May 02, 2023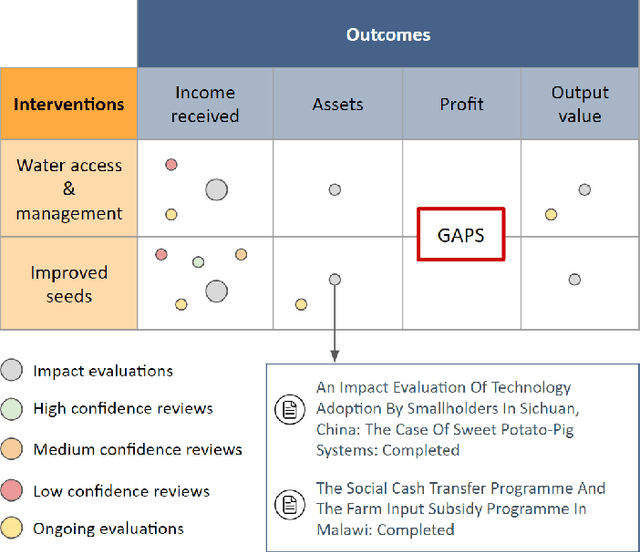
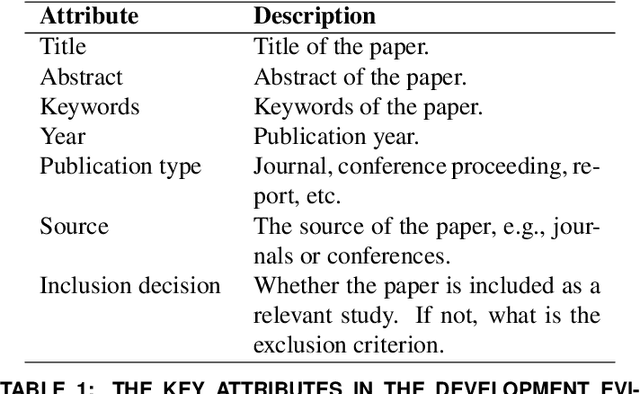
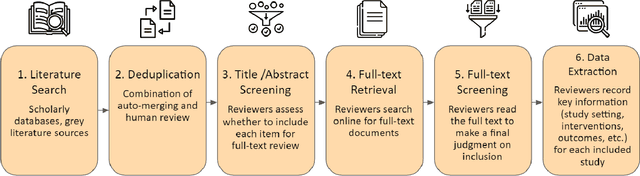

When designing evidence-based policies and programs, decision-makers must distill key information from a vast and rapidly growing literature base. Identifying relevant literature from raw search results is time and resource intensive, and is often done by manual screening. In this study, we develop an AI agent based on a bidirectional encoder representations from transformers (BERT) model and incorporate it into a human team designing an evidence synthesis product for global development. We explore the effectiveness of the human-AI hybrid team in accelerating the evidence synthesis process. To further improve team efficiency, we enhance the human-AI hybrid team through active learning (AL). Specifically, we explore different sampling strategies, including random sampling, least confidence (LC) sampling, and highest priority (HP) sampling, to study their influence on the collaborative screening process. Results show that incorporating the BERT-based AI agent into the human team can reduce the human screening effort by 68.5% compared to the case of no AI assistance and by 16.8% compared to the case of using a support vector machine (SVM)-based AI agent for identifying 80% of all relevant documents. When we apply the HP sampling strategy for AL, the human screening effort can be reduced even more: by 78.3% for identifying 80% of all relevant documents compared to no AI assistance. We apply the AL-enhanced human-AI hybrid teaming workflow in the design process of three evidence gap maps (EGMs) for USAID and find it to be highly effective. These findings demonstrate how AI can accelerate the development of evidence synthesis products and promote timely evidence-based decision making in global development in a human-AI hybrid teaming context.
Lightweight Machine Learning for Digital Cross-Link Interference Cancellation with RF Chain Characteristics in Flexible Duplex MIMO Systems
Apr 23, 2023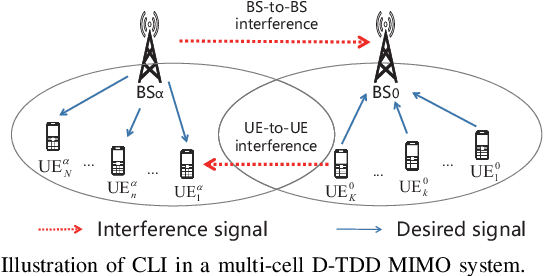
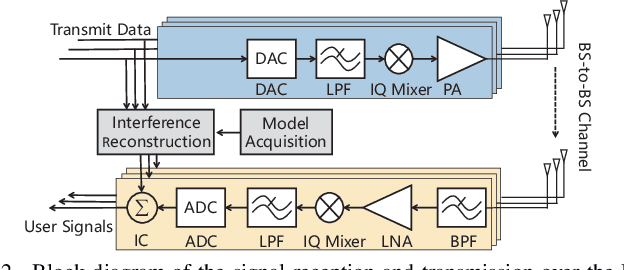
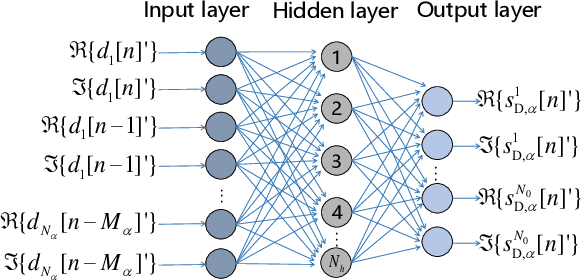
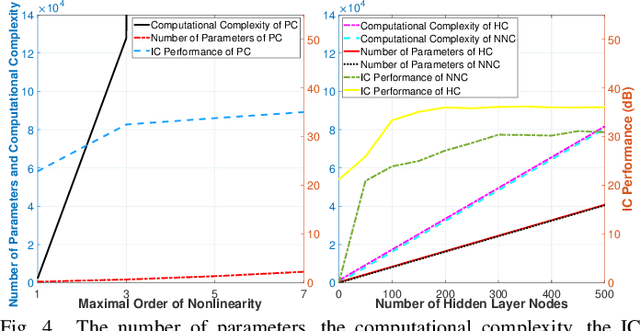
The flexible duplex (FD) technique, including dynamic time-division duplex (D-TDD) and dynamic frequency-division duplex (D-FDD), is regarded as a promising solution to achieving a more flexible uplink/downlink transmission in 5G-Advanced or 6G mobile communication systems. However, it may introduce serious cross-link interference (CLI). For better mitigating the impact of CLI, we first present a more realistic base station (BS)-to-BS channel model incorporating the radio frequency (RF) chain characteristics, which exhibit a hardware-dependent nonlinear property, and hence the accuracy of conventional channel modelling is inadequate for CLI cancellation. Then, we propose a channel parameter estimation based polynomial CLI canceller and two machine learning (ML) based CLI cancellers that use the lightweight feedforward neural network (FNN). Our simulation results and analysis show that the ML based CLI cancellers achieve notable performance improvement and dramatic reduction of computational complexity, in comparison with the polynomial CLI canceller.
AirBirds: A Large-scale Challenging Dataset for Bird Strike Prevention in Real-world Airports
Apr 23, 2023One fundamental limitation to the research of bird strike prevention is the lack of a large-scale dataset taken directly from real-world airports. Existing relevant datasets are either small in size or not dedicated for this purpose. To advance the research and practical solutions for bird strike prevention, in this paper, we present a large-scale challenging dataset AirBirds that consists of 118,312 time-series images, where a total of 409,967 bounding boxes of flying birds are manually, carefully annotated. The average size of all annotated instances is smaller than 10 pixels in 1920x1080 images. Images in the dataset are captured over 4 seasons of a whole year by a network of cameras deployed at a real-world airport, covering diverse bird species, lighting conditions and 13 meteorological scenarios. To the best of our knowledge, it is the first large-scale image dataset that directly collects flying birds in real-world airports for bird strike prevention. This dataset is publicly available at https://airbirdsdata.github.io/.