 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A fast and flexible algorithm for microstructure reconstruction combining simulated annealing and deep learning
Apr 25, 2023
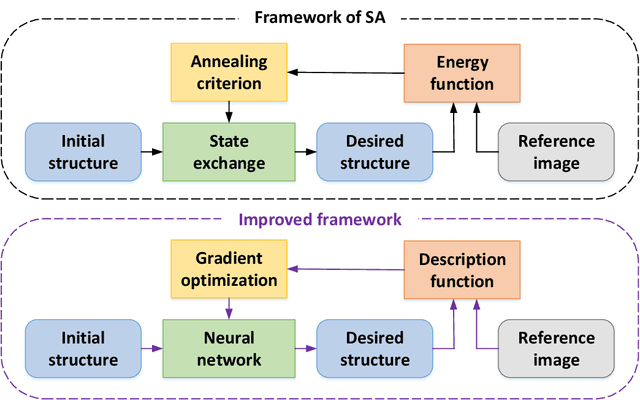


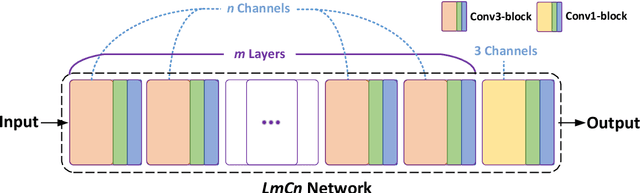
The microstructure analyses of porous media have considerable research value for the study of macroscopic properties. As the premise of conducting these analyses, the accurate reconstruction of microstructure digital model is also an important component of the research. Computational reconstruction algorithms of microstructure have attracted much attention due to their low cost and excellent performance. However, it is still a challenge for computational reconstruction algorithms to achieve faster and more efficient reconstruction. The bottleneck lies in computational reconstruction algorithms, they are either too slow (traditional reconstruction algorithms) or not flexible to the training process (deep learning reconstruction algorithms). To address these limitations, we proposed a fast and flexible computational reconstruction algorithm, neural networks based on improved simulated annealing framework (ISAF-NN). The proposed algorithm is flexible and can complete training and reconstruction in a short time with only one two-dimensional image. By adjusting the size of input, it can also achieve reconstruction of arbitrary size. Finally, the proposed algorithm is experimentally performed on a variety of isotropic and anisotropic materials to verify the effectiveness and generalization.
onlineFGO: Online Continuous-Time Factor Graph Optimization with Time-Centric Multi-Sensor Fusion for Robust Localization in Large-Scale Environments
Nov 10, 2022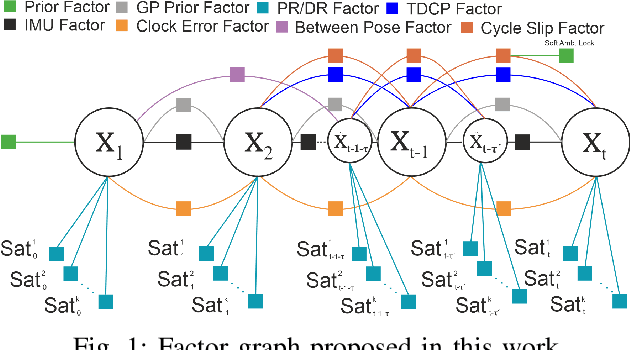
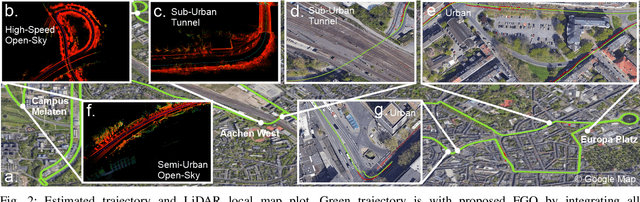

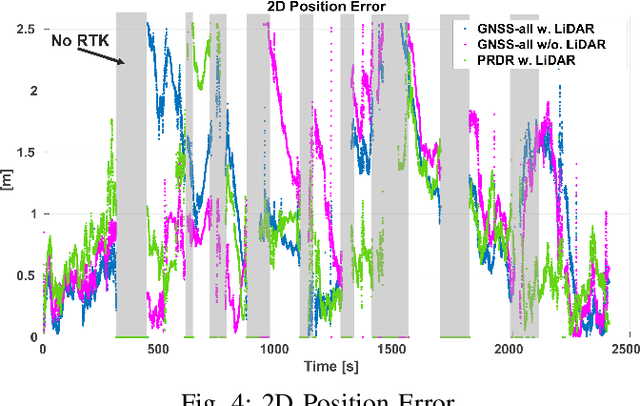
Accurate and consistent vehicle localization in urban areas is challenging due to the large-scale and complicated environments. In this paper, we propose onlineFGO, a novel time-centric graph-optimization-based localization method that fuses multiple sensor measurements with the continuous-time trajectory representation for vehicle localization tasks. We generalize the graph construction independent of any spatial sensor measurements by creating the states deterministically on time. As the trajectory representation in continuous-time enables querying states at arbitrary times, incoming sensor measurements can be factorized on the graph without requiring state alignment. We integrate different GNSS observations: pseudorange, deltarange, and time-differenced carrier phase (TDCP) to ensure global reference and fuse the relative motion from a LiDAR-odometry to improve the localization consistency while GNSS observations are not available. Experiments on general performance, effects of different factors, and hyper-parameter settings are conducted in a real-world measurement campaign in Aachen city that contains different urban scenarios. Our results show an average 2D error of 0.99m and consistent state estimation in urban scenarios.
Leveraging 5G private networks, UAVs and robots to detect and combat broad-leaved dock (Rumex obtusifolius) in feed production
Apr 30, 2023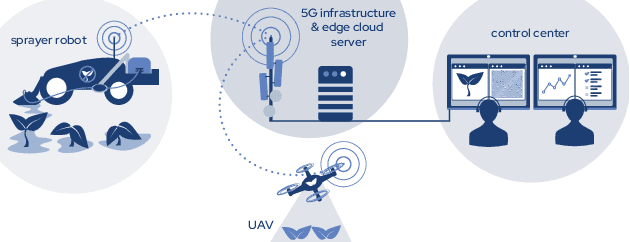
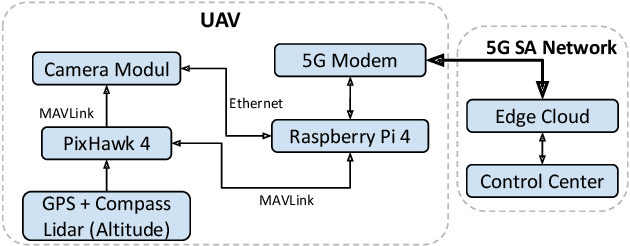

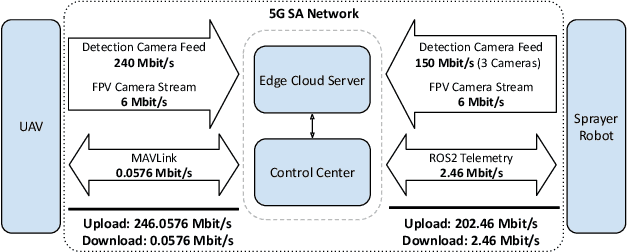
In this paper an autonomous system to detect and combat Rumex obtusifolius leveraging autonomous unmanned aerial vehicles (UAV), small autonomous sprayer robots and 5G SA connectivity is presented. Rumex obtusifolius is a plant found on grassland that drains nutrients from surrounding plants and has lower nutritive value than the surrounding grass. High concentrations of it have to be combated in order to use the grass as feed for livestock. One or more UAV are controlled through 5G to survey the current working area and send back high-definition photos of the ground to an edge cloud server. There an AI algorithm using neural networks detects the Rumex obtusifolius and calculates its position using the UAVs position data. When plants are detected an optimal path is calculated and sent via 5G to the sprayer robot to get to them in minimal time. It will then move to the position of the broad-leafed dock and use an on-board camera and the edge cloud to verify the position of the plant and precisely spray crop protection only where the target plant is. The spraying robot and UAV are already operational, the training of the detection algorithm is still ongoing. The described system is being tested with a fixed private 5G SA network and a nomadic 5G SA network as public cellular networks are not performant enough in regards to low latency and upload bandwidth.
DataComp: In search of the next generation of multimodal datasets
May 03, 2023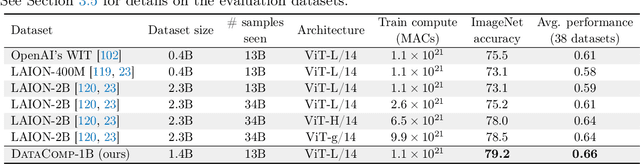
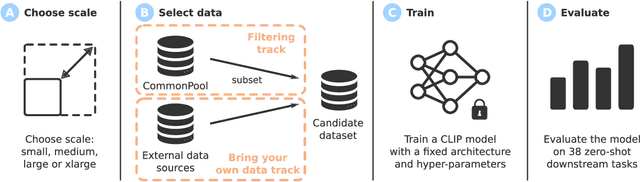


Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.
Task-Aware Risk Estimation of Perception Failures for Autonomous Vehicles
May 03, 2023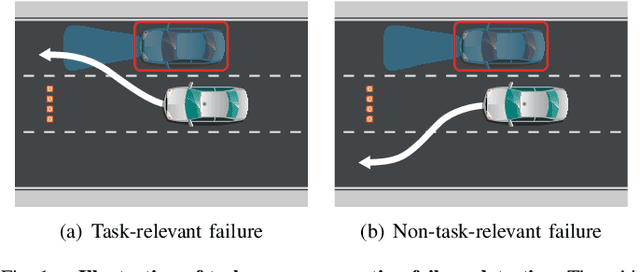
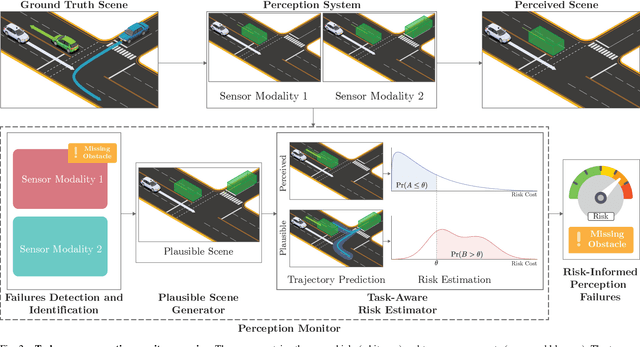
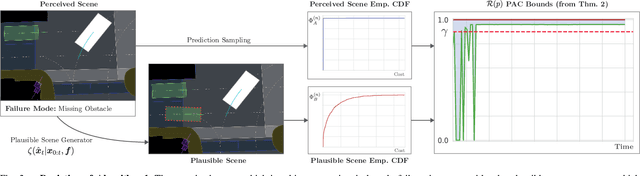
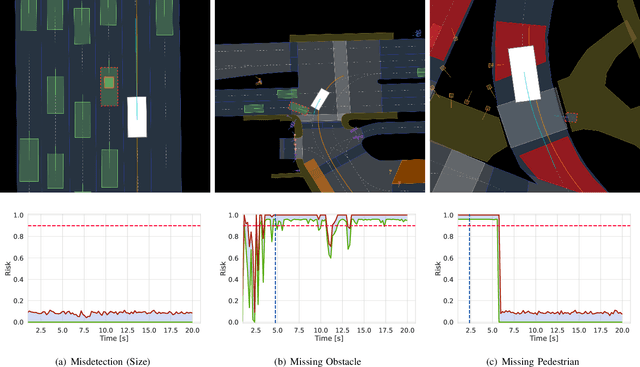
Safety and performance are key enablers for autonomous driving: on the one hand we want our autonomous vehicles (AVs) to be safe, while at the same time their performance (e.g., comfort or progression) is key to adoption. To effectively walk the tight-rope between safety and performance, AVs need to be risk-averse, but not entirely risk-avoidant. To facilitate safe-yet-performant driving, in this paper, we develop a task-aware risk estimator that assesses the risk a perception failure poses to the AV's motion plan. If the failure has no bearing on the safety of the AV's motion plan, then regardless of how egregious the perception failure is, our task-aware risk estimator considers the failure to have a low risk; on the other hand, if a seemingly benign perception failure severely impacts the motion plan, then our estimator considers it to have a high risk. In this paper, we propose a task-aware risk estimator to decide whether a safety maneuver needs to be triggered. To estimate the task-aware risk, first, we leverage the perception failure - detected by a perception monitor - to synthesize an alternative plausible model for the vehicle's surroundings. The risk due to the perception failure is then formalized as the "relative" risk to the AV's motion plan between the perceived and the alternative plausible scenario. We employ a statistical tool called copula, which models tail dependencies between distributions, to estimate this risk. The theoretical properties of the copula allow us to compute probably approximately correct (PAC) estimates of the risk. We evaluate our task-aware risk estimator using NuPlan and compare it with established baselines, showing that the proposed risk estimator achieves the best F1-score (doubling the score of the best baseline) and exhibits a good balance between recall and precision, i.e., a good balance of safety and performance.
Probabilistic Querying of Continuous-Time Event Sequences
Nov 15, 2022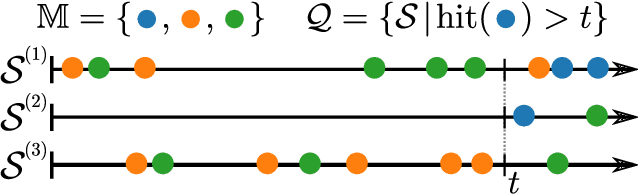

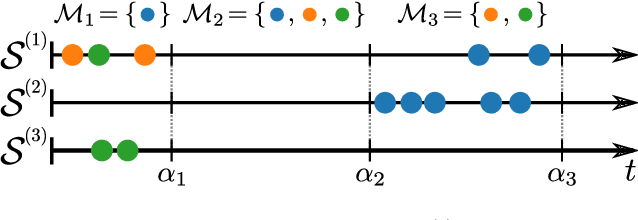
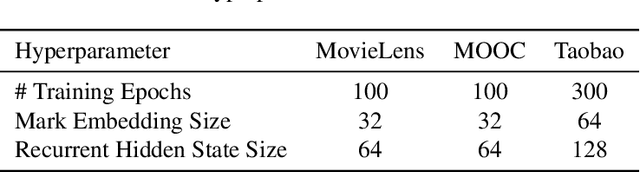
Continuous-time event sequences, i.e., sequences consisting of continuous time stamps and associated event types ("marks"), are an important type of sequential data with many applications, e.g., in clinical medicine or user behavior modeling. Since these data are typically modeled autoregressively (e.g., using neural Hawkes processes or their classical counterparts), it is natural to ask questions about future scenarios such as "what kind of event will occur next" or "will an event of type $A$ occur before one of type $B$". Unfortunately, some of these queries are notoriously hard to address since current methods are limited to naive simulation, which can be highly inefficient. This paper introduces a new typology of query types and a framework for addressing them using importance sampling. Example queries include predicting the $n^\text{th}$ event type in a sequence and the hitting time distribution of one or more event types. We also leverage these findings further to be applicable for estimating general "$A$ before $B$" type of queries. We prove theoretically that our estimation method is effectively always better than naive simulation and show empirically based on three real-world datasets that it is on average 1,000 times more efficient than existing approaches.
A tutorial on the Bayesian statistical approach to inverse problems
Apr 15, 2023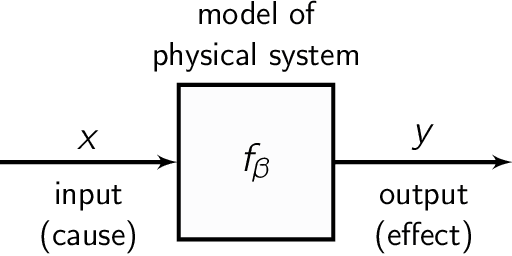
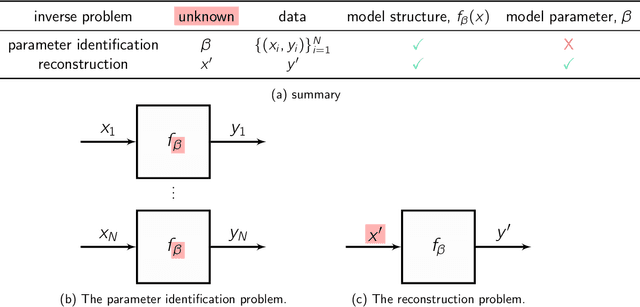

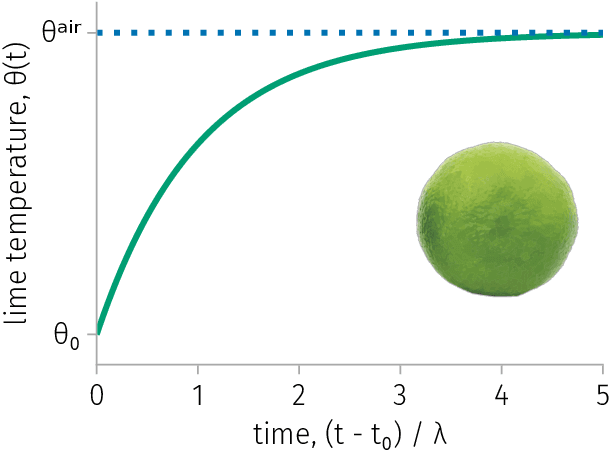
Inverse problems are ubiquitous in the sciences and engineering. Two categories of inverse problems concerning a physical system are (1) estimate parameters in a model of the system from observed input-output pairs and (2) given a model of the system, reconstruct the input to it that caused some observed output. Applied inverse problems are challenging because a solution may (i) not exist, (ii) not be unique, or (iii) be sensitive to measurement noise contaminating the data. Bayesian statistical inversion (BSI) is an approach to tackle ill-posed and/or ill-conditioned inverse problems. Advantageously, BSI provides a "solution" that (i) quantifies uncertainty by assigning a probability to each possible value of the unknown parameter/input and (ii) incorporates prior information and beliefs about the parameter/input. Herein, we provide a tutorial of BSI for inverse problems, by way of illustrative examples dealing with heat transfer from ambient air to a cold lime fruit. First, we use BSI to infer a parameter in a dynamic model of the lime temperature from measurements of the lime temperature over time. Second, we use BSI to reconstruct the initial condition of the lime from a measurement of its temperature later in time. We demonstrate the incorporation of prior information, visualize the posterior distributions of the parameter/initial condition, and show posterior samples of lime temperature trajectories from the model. Our tutorial aims to reach a wide range of scientists and engineers.
A Hierarchical Approach to Optimal Flow-Based Routing and Coordination of Connected and Automated Vehicles
Mar 31, 2023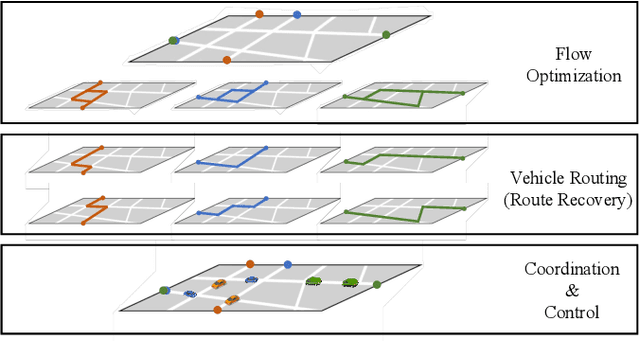

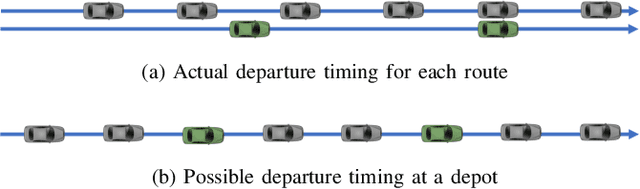
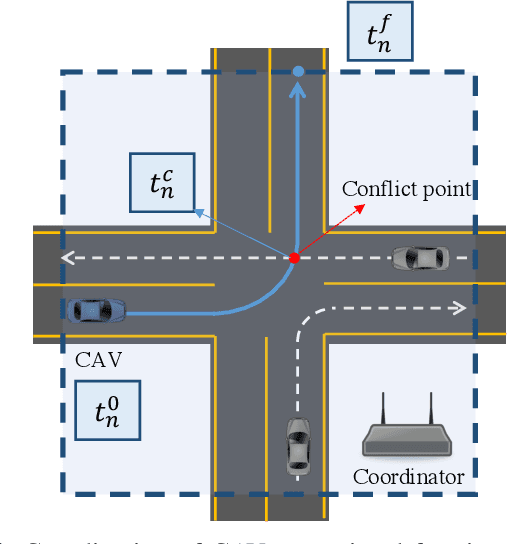
This paper addresses the challenge of generating optimal vehicle flow at the macroscopic level. Although several studies have focused on optimizing vehicle flow, little attention has been given to ensuring it can be practically achieved. To overcome this issue, we propose a route-recovery and eco-driving strategy for connected and automated vehicles (CAVs) that guarantees optimal flow generation. Our approach involves identifying the optimal vehicle flow that minimizes total travel time, given the constant travel demands in urban areas. We then develop a heuristic route-recovery algorithm to assign routes to CAVs that satisfy all travel demands while maintaining the optimal flow. Our method lets CAVs arrive at each road segment at their desired arrival time based on their assigned route and desired flow. In addition, we present an efficient coordination framework to minimize the energy consumption of CAVs and prevent collisions while crossing intersections. The proposed method can effectively generate optimal vehicle flow and potentially reduce travel time and energy consumption in urban areas.
Segment Anything Model for Medical Images?
May 01, 2023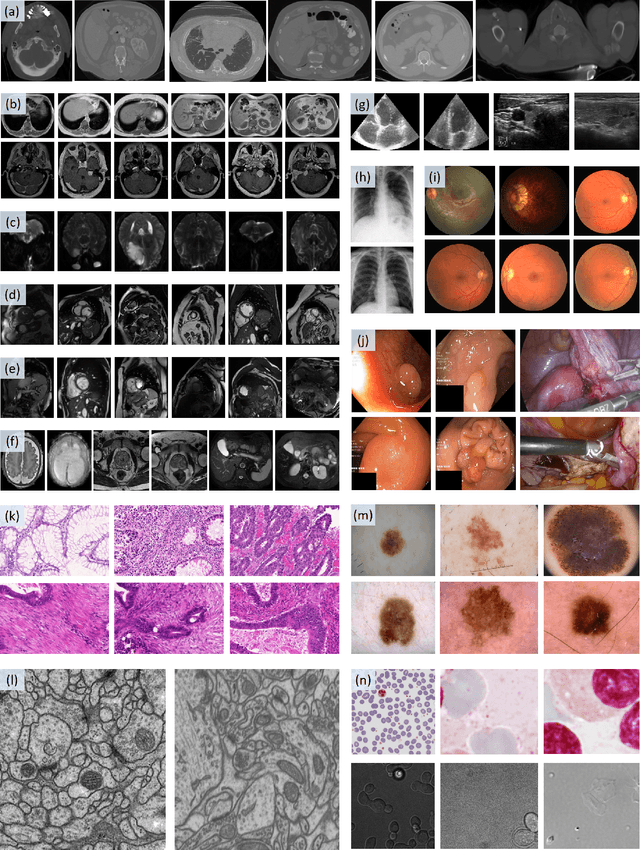
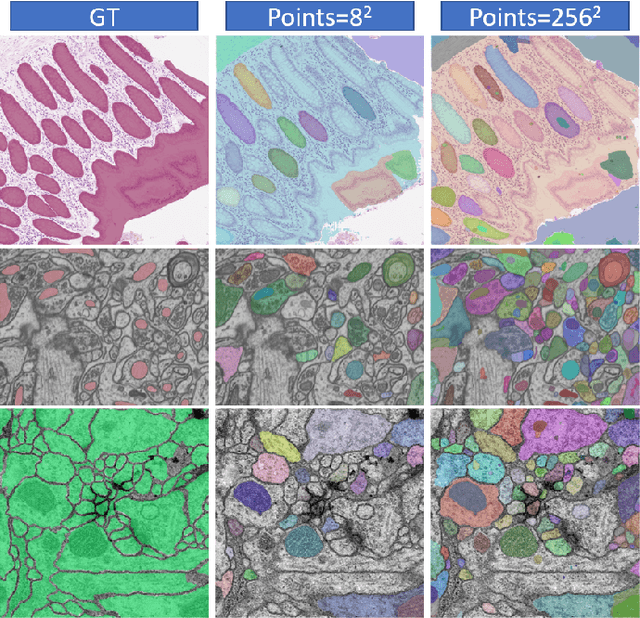
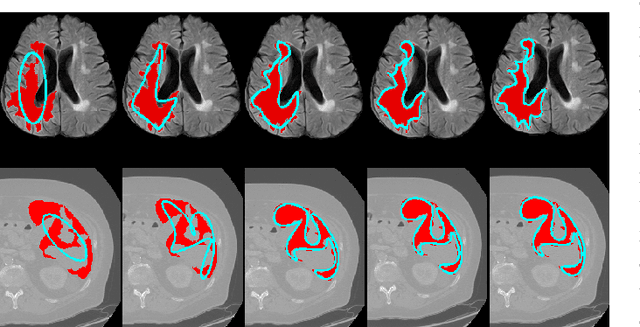
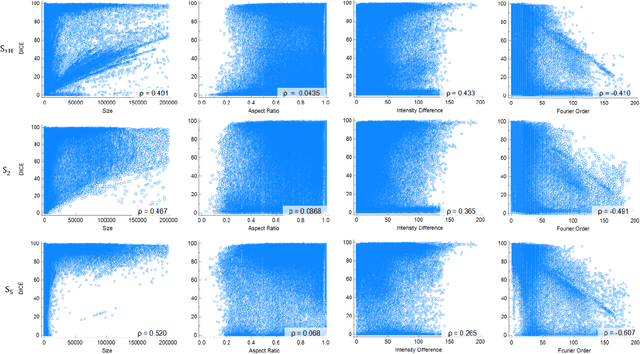
The Segment Anything Model (SAM) is the first foundation model for general image segmentation. It designed a novel promotable segmentation task, ensuring zero-shot image segmentation using the pre-trained model via two main modes including automatic everything and manual prompt. SAM has achieved impressive results on various natural image segmentation tasks. However, medical image segmentation (MIS) is more challenging due to the complex modalities, fine anatomical structures, uncertain and complex object boundaries, and wide-range object scales. Meanwhile, zero-shot and efficient MIS can well reduce the annotation time and boost the development of medical image analysis. Hence, SAM seems to be a potential tool and its performance on large medical datasets should be further validated. We collected and sorted 52 open-source datasets, and built a large medical segmentation dataset with 16 modalities, 68 objects, and 553K slices. We conducted a comprehensive analysis of different SAM testing strategies on the so-called COSMOS 553K dataset. Extensive experiments validate that SAM performs better with manual hints like points and boxes for object perception in medical images, leading to better performance in prompt mode compared to everything mode. Additionally, SAM shows remarkable performance in some specific objects and modalities, but is imperfect or even totally fails in other situations. Finally, we analyze the influence of different factors (e.g., the Fourier-based boundary complexity and size of the segmented objects) on SAM's segmentation performance. Extensive experiments validate that SAM's zero-shot segmentation capability is not sufficient to ensure its direct application to the MIS.
Autoencoders for discovering manifold dimension and coordinates in data from complex dynamical systems
May 01, 2023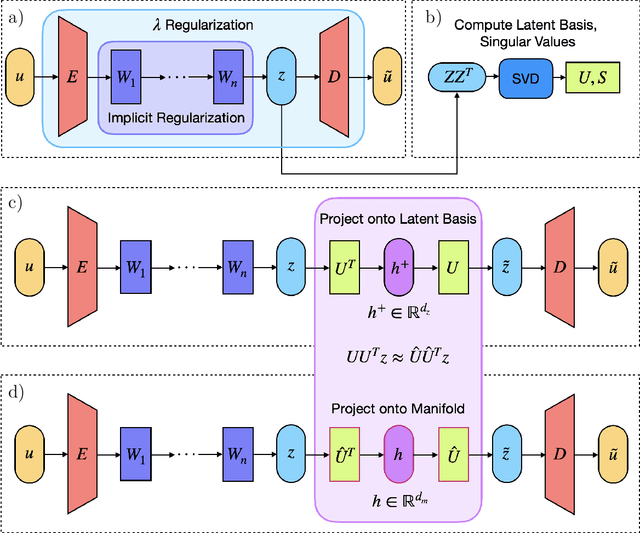

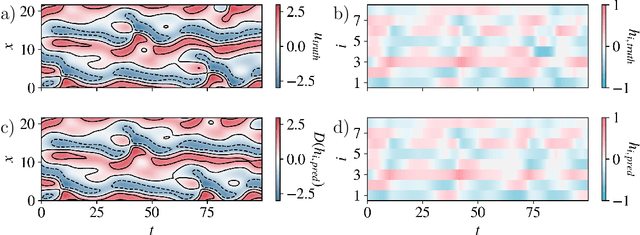
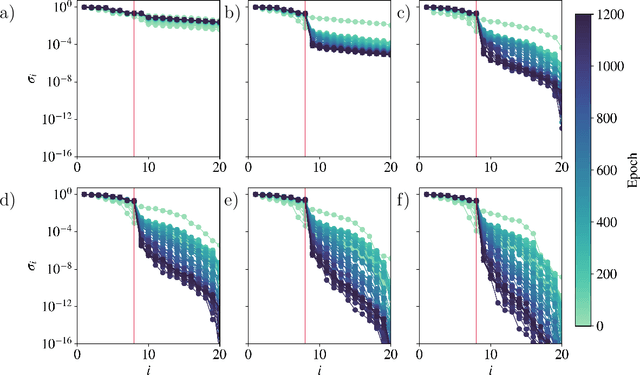
While many phenomena in physics and engineering are formally high-dimensional, their long-time dynamics often live on a lower-dimensional manifold. The present work introduces an autoencoder framework that combines implicit regularization with internal linear layers and $L_2$ regularization (weight decay) to automatically estimate the underlying dimensionality of a data set, produce an orthogonal manifold coordinate system, and provide the mapping functions between the ambient space and manifold space, allowing for out-of-sample projections. We validate our framework's ability to estimate the manifold dimension for a series of datasets from dynamical systems of varying complexities and compare to other state-of-the-art estimators. We analyze the training dynamics of the network to glean insight into the mechanism of low-rank learning and find that collectively each of the implicit regularizing layers compound the low-rank representation and even self-correct during training. Analysis of gradient descent dynamics for this architecture in the linear case reveals the role of the internal linear layers in leading to faster decay of a "collective weight variable" incorporating all layers, and the role of weight decay in breaking degeneracies and thus driving convergence along directions in which no decay would occur in its absence. We show that this framework can be naturally extended for applications of state-space modeling and forecasting by generating a data-driven dynamic model of a spatiotemporally chaotic partial differential equation using only the manifold coordinates. Finally, we demonstrate that our framework is robust to hyperparameter choices.