 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Single Image Depth Prediction Made Better: A Multivariate Gaussian Take
Apr 18, 2023

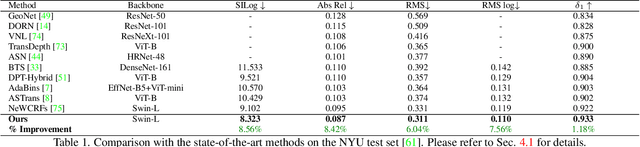
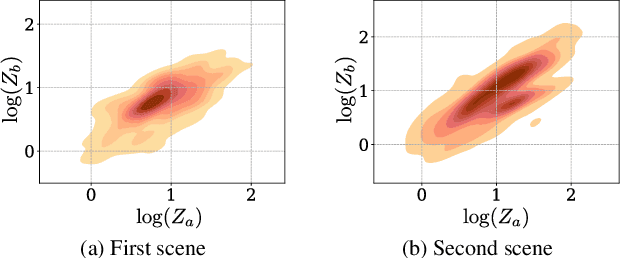
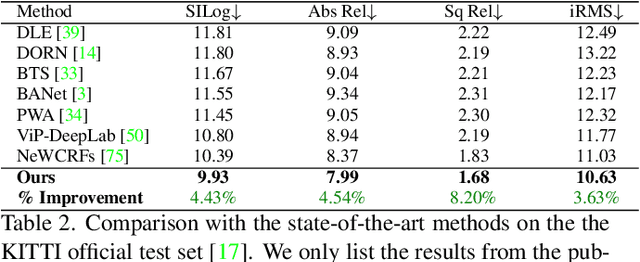
Neural-network-based single image depth prediction (SIDP) is a challenging task where the goal is to predict the scene's per-pixel depth at test time. Since the problem, by definition, is ill-posed, the fundamental goal is to come up with an approach that can reliably model the scene depth from a set of training examples. In the pursuit of perfect depth estimation, most existing state-of-the-art learning techniques predict a single scalar depth value per-pixel. Yet, it is well-known that the trained model has accuracy limits and can predict imprecise depth. Therefore, an SIDP approach must be mindful of the expected depth variations in the model's prediction at test time. Accordingly, we introduce an approach that performs continuous modeling of per-pixel depth, where we can predict and reason about the per-pixel depth and its distribution. To this end, we model per-pixel scene depth using a multivariate Gaussian distribution. Moreover, contrary to the existing uncertainty modeling methods -- in the same spirit, where per-pixel depth is assumed to be independent, we introduce per-pixel covariance modeling that encodes its depth dependency w.r.t all the scene points. Unfortunately, per-pixel depth covariance modeling leads to a computationally expensive continuous loss function, which we solve efficiently using the learned low-rank approximation of the overall covariance matrix. Notably, when tested on benchmark datasets such as KITTI, NYU, and SUN-RGB-D, the SIDP model obtained by optimizing our loss function shows state-of-the-art results. Our method's accuracy (named MG) is among the top on the KITTI depth-prediction benchmark leaderboard.
Two-stage Denoising Diffusion Model for Source Localization in Graph Inverse Problems
Apr 18, 2023
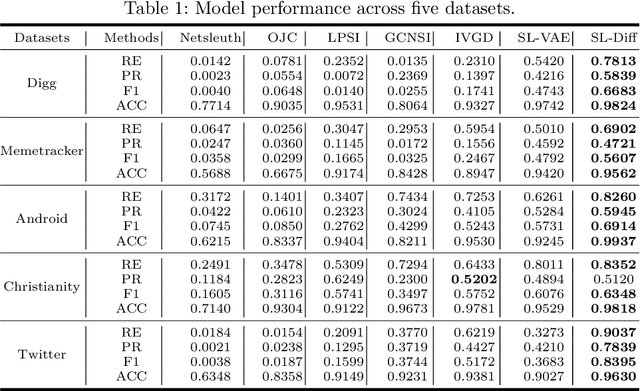
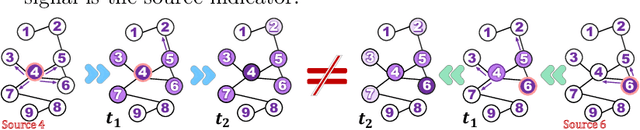
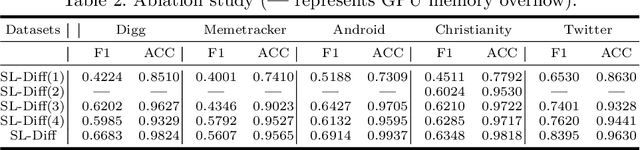
Source localization is the inverse problem of graph information dissemination and has broad practical applications. However, the inherent intricacy and uncertainty in information dissemination pose significant challenges, and the ill-posed nature of the source localization problem further exacerbates these challenges. Recently, deep generative models, particularly diffusion models inspired by classical non-equilibrium thermodynamics, have made significant progress. While diffusion models have proven to be powerful in solving inverse problems and producing high-quality reconstructions, applying them directly to the source localization is infeasible for two reasons. Firstly, it is impossible to calculate the posterior disseminated results on a large-scale network for iterative denoising sampling, which would incur enormous computational costs. Secondly, in the existing methods for this field, the training data itself are ill-posed (many-to-one); thus simply transferring the diffusion model would only lead to local optima. To address these challenges, we propose a two-stage optimization framework, the source localization denoising diffusion model (SL-Diff). In the coarse stage, we devise the source proximity degrees as the supervised signals to generate coarse-grained source predictions. This aims to efficiently initialize the next stage, significantly reducing its convergence time and calibrating the convergence process. Furthermore, the introduction of cascade temporal information in this training method transforms the many-to-one mapping relationship into a one-to-one relationship, perfectly addressing the ill-posed problem. In the fine stage, we design a diffusion model for the graph inverse problem that can quantify the uncertainty in the dissemination. The proposed SL-Diff yields excellent prediction results within a reasonable sampling time at extensive experiments.
Generative modeling of living cells with SO(3)-equivariant implicit neural representations
Apr 18, 2023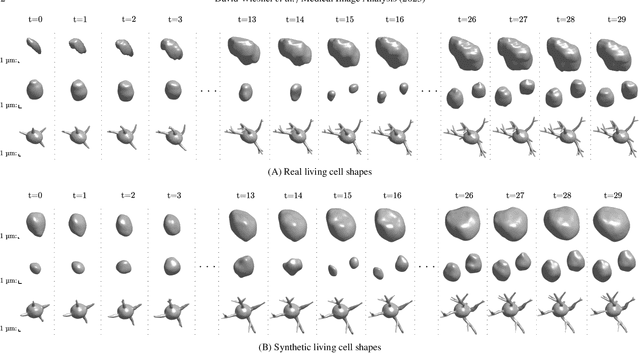
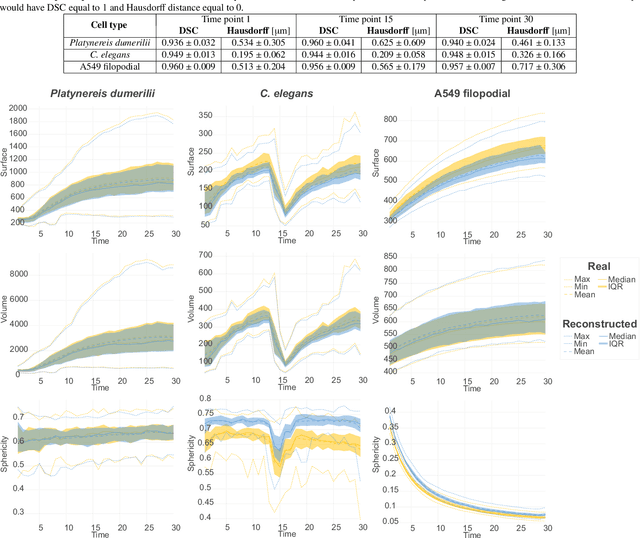
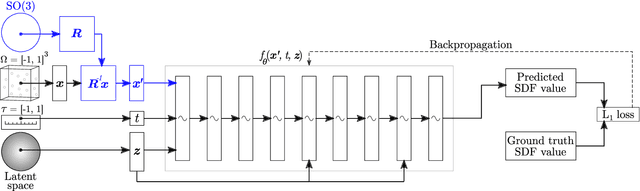
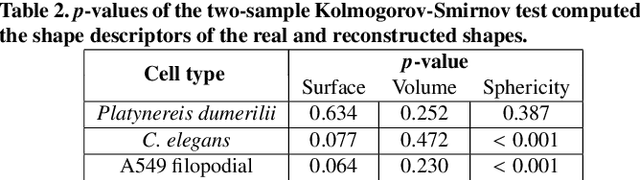
Data-driven cell tracking and segmentation methods in biomedical imaging require diverse and information-rich training data. In cases where the number of training samples is limited, synthetic computer-generated data sets can be used to improve these methods. This requires the synthesis of cell shapes as well as corresponding microscopy images using generative models. To synthesize realistic living cell shapes, the shape representation used by the generative model should be able to accurately represent fine details and changes in topology, which are common in cells. These requirements are not met by 3D voxel masks, which are restricted in resolution, and polygon meshes, which do not easily model processes like cell growth and mitosis. In this work, we propose to represent living cell shapes as level sets of signed distance functions (SDFs) which are estimated by neural networks. We optimize a fully-connected neural network to provide an implicit representation of the SDF value at any point in a 3D+time domain, conditioned on a learned latent code that is disentangled from the rotation of the cell shape. We demonstrate the effectiveness of this approach on cells that exhibit rapid deformations (Platynereis dumerilii), cells that grow and divide (C. elegans), and cells that have growing and branching filopodial protrusions (A549 human lung carcinoma cells). A quantitative evaluation using shape features, Hausdorff distance, and Dice similarity coefficients of real and synthetic cell shapes shows that our model can generate topologically plausible complex cell shapes in 3D+time with high similarity to real living cell shapes. Finally, we show how microscopy images of living cells that correspond to our generated cell shapes can be synthesized using an image-to-image model.
System-status-aware Adaptive Network for Online Streaming Video Understanding
Mar 28, 2023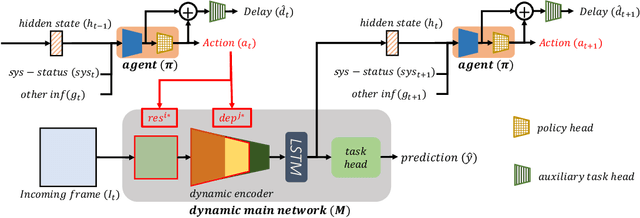
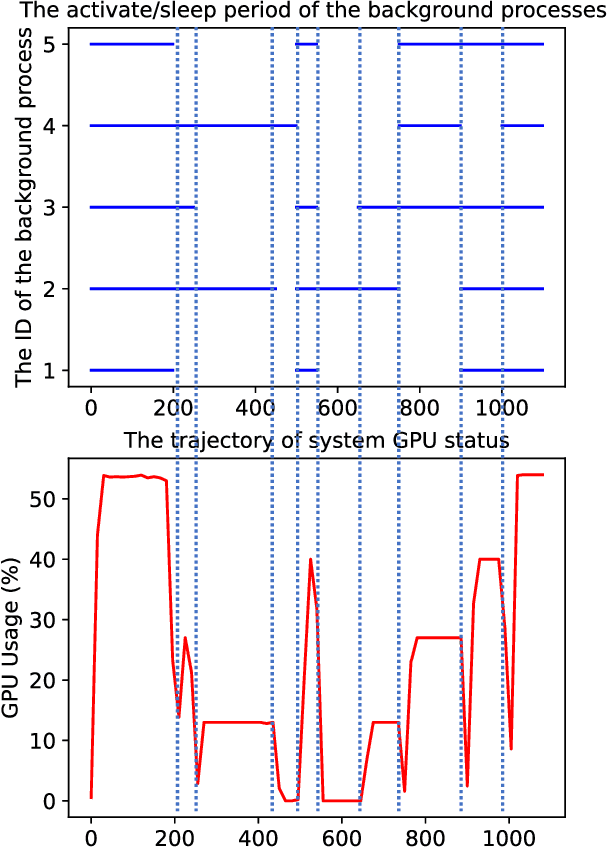
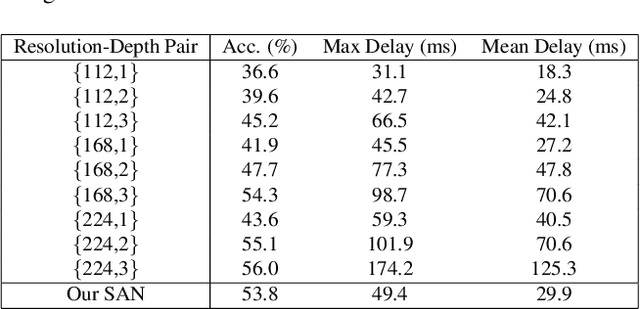
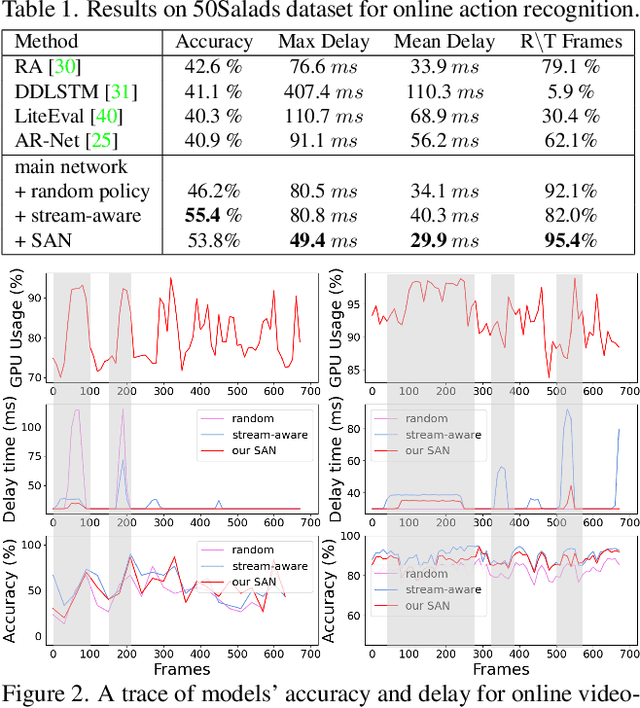
Recent years have witnessed great progress in deep neural networks for real-time applications. However, most existing works do not explicitly consider the general case where the device's state and the available resources fluctuate over time, and none of them investigate or address the impact of varying computational resources for online video understanding tasks. This paper proposes a System-status-aware Adaptive Network (SAN) that considers the device's real-time state to provide high-quality predictions with low delay. Usage of our agent's policy improves efficiency and robustness to fluctuations of the system status. On two widely used video understanding tasks, SAN obtains state-of-the-art performance while constantly keeping processing delays low. Moreover, training such an agent on various types of hardware configurations is not easy as the labeled training data might not be available, or can be computationally prohibitive. To address this challenging problem, we propose a Meta Self-supervised Adaptation (MSA) method that adapts the agent's policy to new hardware configurations at test-time, allowing for easy deployment of the model onto other unseen hardware platforms.
Power Grid Behavioral Patterns and Risks of Generalization in Applied Machine Learning
Apr 21, 2023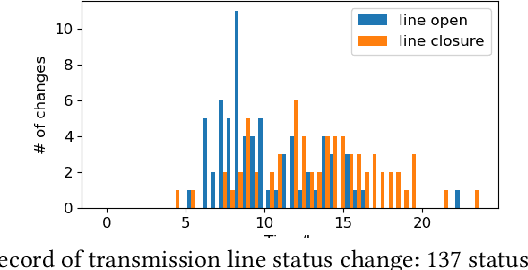
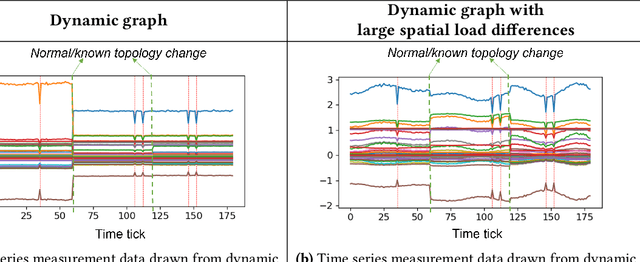
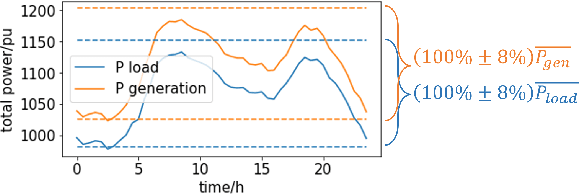
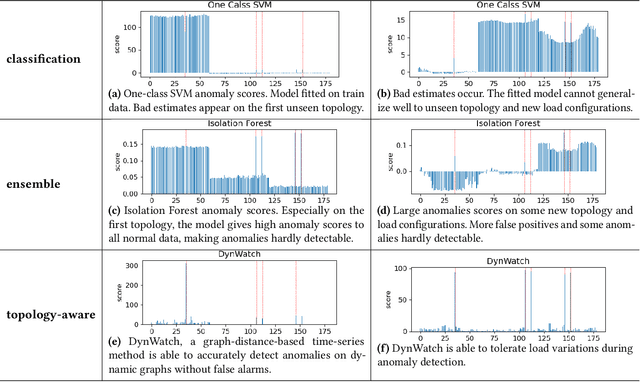
Recent years have seen a rich literature of data-driven approaches designed for power grid applications. However, insufficient consideration of domain knowledge can impose a high risk to the practicality of the methods. Specifically, ignoring the grid-specific spatiotemporal patterns (in load, generation, and topology, etc.) can lead to outputting infeasible, unrealizable, or completely meaningless predictions on new inputs. To address this concern, this paper investigates real-world operational data to provide insights into power grid behavioral patterns, including the time-varying topology, load, and generation, as well as the spatial differences (in peak hours, diverse styles) between individual loads and generations. Then based on these observations, we evaluate the generalization risks in some existing ML works causedby ignoring these grid-specific patterns in model design and training.
Event-based tracking of human hands
Apr 13, 2023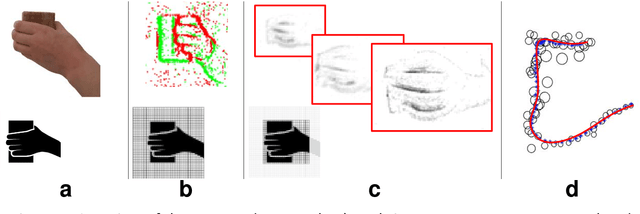
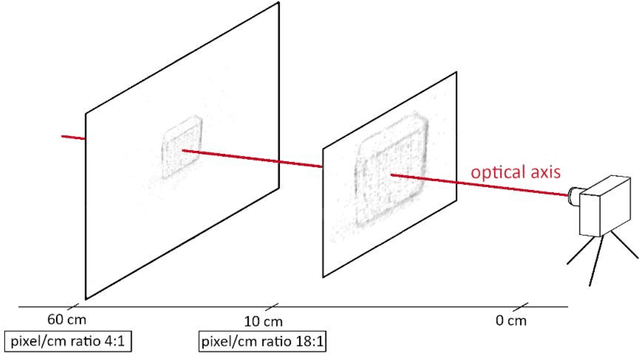
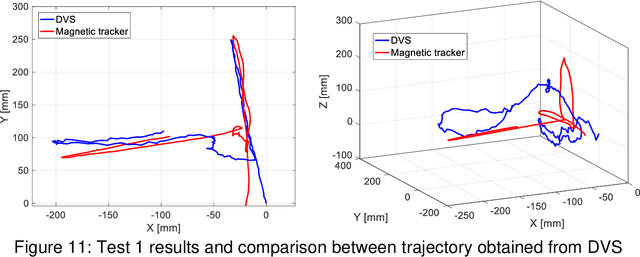
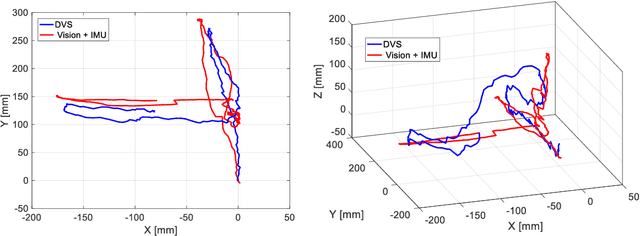
This paper proposes a novel method for human hands tracking using data from an event camera. The event camera detects changes in brightness, measuring motion, with low latency, no motion blur, low power consumption and high dynamic range. Captured frames are analysed using lightweight algorithms reporting 3D hand position data. The chosen pick-and-place scenario serves as an example input for collaborative human-robot interactions and in obstacle avoidance for human-robot safety applications. Events data are pre-processed into intensity frames. The regions of interest (ROI) are defined through object edge event activity, reducing noise. ROI features are extracted for use in-depth perception. Event-based tracking of human hand demonstrated feasible, in real time and at a low computational cost. The proposed ROI-finding method reduces noise from intensity images, achieving up to 89% of data reduction in relation to the original, while preserving the features. The depth estimation error in relation to ground truth (measured with wearables), measured using dynamic time warping and using a single event camera, is from 15 to 30 millimetres, depending on the plane it is measured. Tracking of human hands in 3D space using a single event camera data and lightweight algorithms to define ROI features (hands tracking in space).
Temporal Knowledge Sharing enable Spiking Neural Network Learning from Past and Future
Apr 13, 2023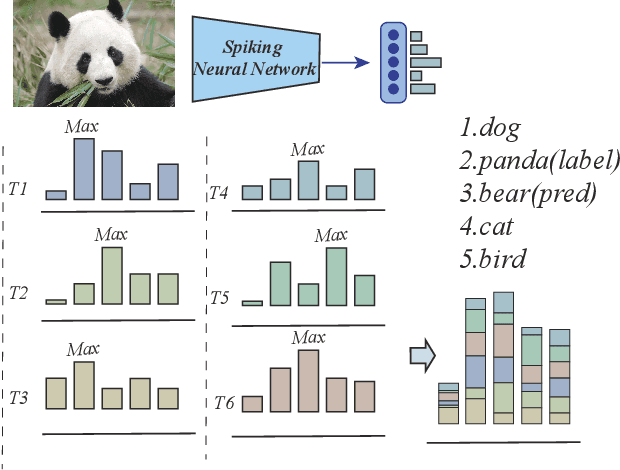
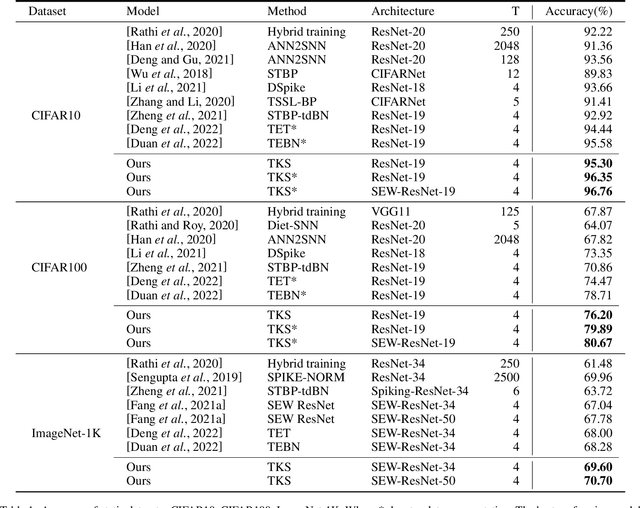
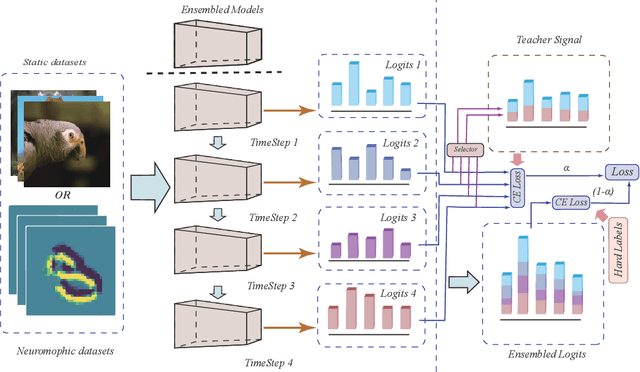
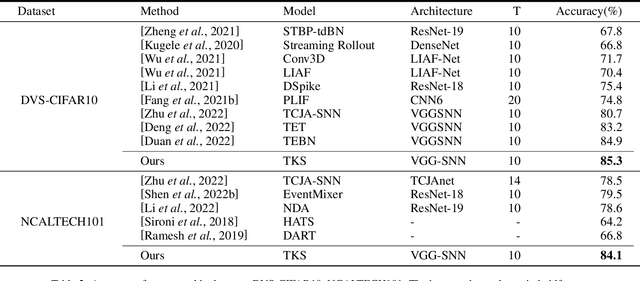
Spiking neural networks have attracted extensive attention from researchers in many fields due to their brain-like information processing mechanism. The proposal of surrogate gradient enables the spiking neural networks to migrate to more complex tasks, and gradually close the gap with the conventional artificial neural networks. Current spiking neural networks utilize the output of all moments to produce the final prediction, which compromises their temporal characteristics and causes a reduction in performance and efficiency. We propose a temporal knowledge sharing approach (TKS) that enables the interaction of information between different moments, by selecting the output of specific moments to compose teacher signals to guide the training of the network along with the real labels. We have validated TKS on both static datasets CIFAR10, CIFAR100, ImageNet-1k and neuromorphic datasets DVS-CIFAR10, NCALTECH101. Our experimental results indicate that we have achieved the current optimal performance in comparison with other algorithms. Experiments on Fine-grained classification datasets further demonstrate our algorithm's superiority with CUB-200-2011, StanfordDogs, and StanfordCars. TKS algorithm helps the model to have stronger temporal generalization capability, allowing the network to guarantee performance with large time steps in the training phase and with small time steps in the testing phase. This greatly facilitates the deployment of SNNs on edge devices.
Situational-Aware Multi-Graph Convolutional Recurrent Network (SA-MGCRN) for Travel Demand Forecasting During Wildfires
Apr 13, 2023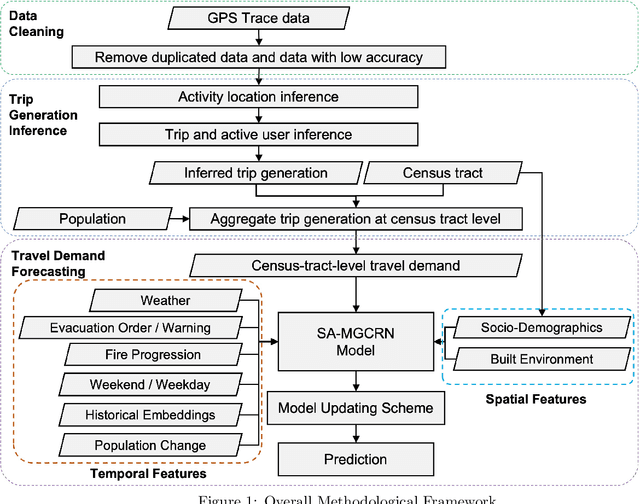
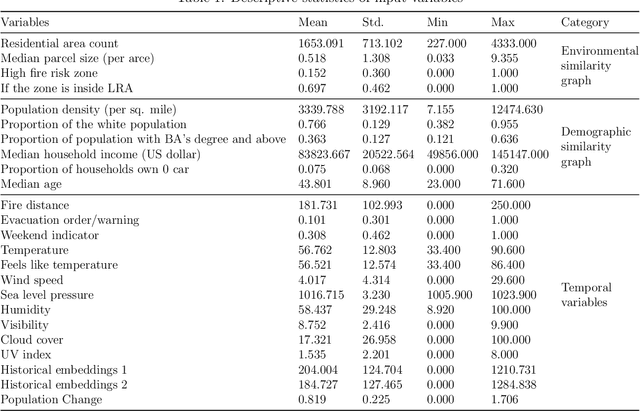
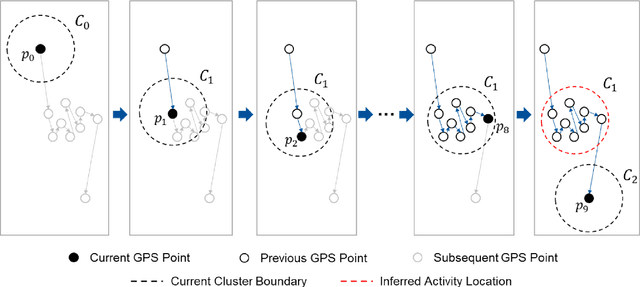
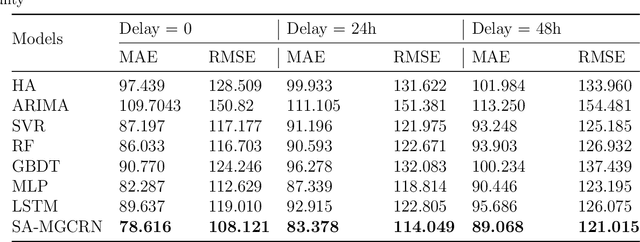
Real-time forecasting of travel demand during wildfire evacuations is crucial for emergency managers and transportation planners to make timely and better-informed decisions. However, few studies focus on accurate travel demand forecasting in large-scale emergency evacuations. Therefore, this study develops and tests a new methodological framework for modeling trip generation in wildfire evacuations by using (a) large-scale GPS data generated by mobile devices and (b) state-of-the-art AI technologies. The proposed methodology aims at forecasting evacuation trips and other types of trips. Based on the travel demand inferred from the GPS data, we develop a new deep learning model, i.e., Situational-Aware Multi-Graph Convolutional Recurrent Network (SA-MGCRN), along with a model updating scheme to achieve real-time forecasting of travel demand during wildfire evacuations. The proposed methodological framework is tested in this study for a real-world case study: the 2019 Kincade Fire in Sonoma County, CA. The results show that SA-MGCRN significantly outperforms all the selected state-of-the-art benchmarks in terms of prediction performance. Our finding suggests that the most important model components of SA-MGCRN are evacuation order/warning information, proximity to fire, and population change, which are consistent with behavioral theories and empirical findings.
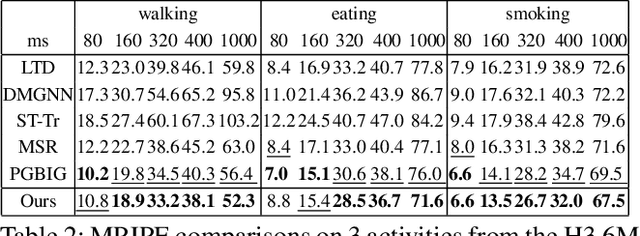
Meta-Auxiliary Learning for Adaptive Human Pose Prediction
Apr 13, 2023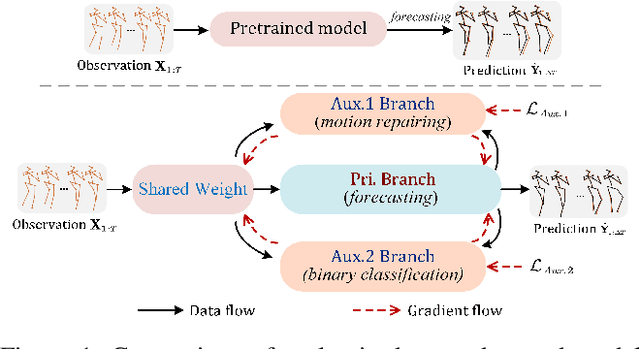
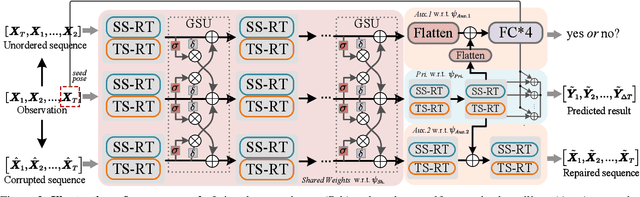
Predicting high-fidelity future human poses, from a historically observed sequence, is decisive for intelligent robots to interact with humans. Deep end-to-end learning approaches, which typically train a generic pre-trained model on external datasets and then directly apply it to all test samples, emerge as the dominant solution to solve this issue. Despite encouraging progress, they remain non-optimal, as the unique properties (e.g., motion style, rhythm) of a specific sequence cannot be adapted. More generally, at test-time, once encountering unseen motion categories (out-of-distribution), the predicted poses tend to be unreliable. Motivated by this observation, we propose a novel test-time adaptation framework that leverages two self-supervised auxiliary tasks to help the primary forecasting network adapt to the test sequence. In the testing phase, our model can adjust the model parameters by several gradient updates to improve the generation quality. However, due to catastrophic forgetting, both auxiliary tasks typically tend to the low ability to automatically present the desired positive incentives for the final prediction performance. For this reason, we also propose a meta-auxiliary learning scheme for better adaptation. In terms of general setup, our approach obtains higher accuracy, and under two new experimental designs for out-of-distribution data (unseen subjects and categories), achieves significant improvements.
SceneGenie: Scene Graph Guided Diffusion Models for Image Synthesis
Apr 28, 2023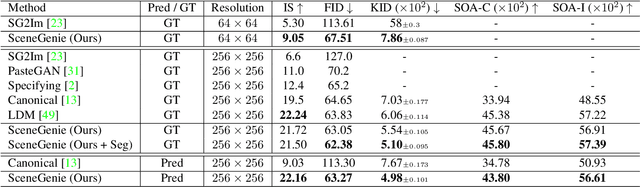
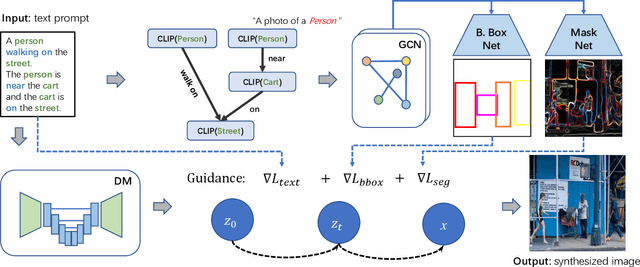
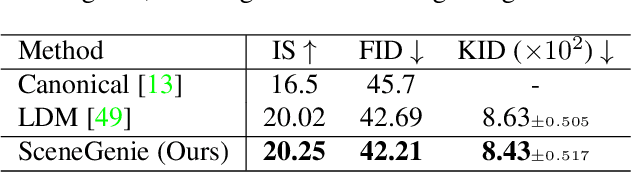
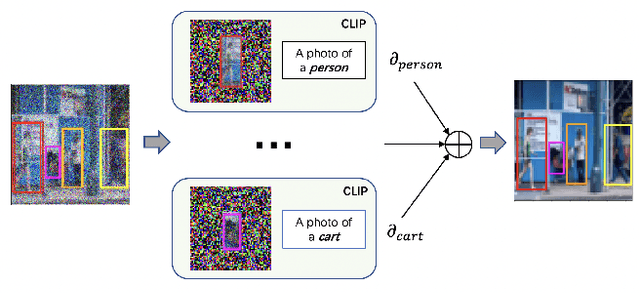
Text-conditioned image generation has made significant progress in recent years with generative adversarial networks and more recently, diffusion models. While diffusion models conditioned on text prompts have produced impressive and high-quality images, accurately representing complex text prompts such as the number of instances of a specific object remains challenging. To address this limitation, we propose a novel guidance approach for the sampling process in the diffusion model that leverages bounding box and segmentation map information at inference time without additional training data. Through a novel loss in the sampling process, our approach guides the model with semantic features from CLIP embeddings and enforces geometric constraints, leading to high-resolution images that accurately represent the scene. To obtain bounding box and segmentation map information, we structure the text prompt as a scene graph and enrich the nodes with CLIP embeddings. Our proposed model achieves state-of-the-art performance on two public benchmarks for image generation from scene graphs, surpassing both scene graph to image and text-based diffusion models in various metrics. Our results demonstrate the effectiveness of incorporating bounding box and segmentation map guidance in the diffusion model sampling process for more accurate text-to-image generation.