 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TimeXer: Empowering Transformers for Time Series Forecasting with Exogenous Variables
Feb 29, 2024
Recent studies have demonstrated remarkable performance in time series forecasting. However, due to the partially-observed nature of real-world applications, solely focusing on the target of interest, so-called endogenous variables, is usually insufficient to guarantee accurate forecasting. Notably, a system is often recorded into multiple variables, where the exogenous series can provide valuable external information for endogenous variables. Thus, unlike prior well-established multivariate or univariate forecasting that either treats all the variables equally or overlooks exogenous information, this paper focuses on a practical setting, which is time series forecasting with exogenous variables. We propose a novel framework, TimeXer, to utilize external information to enhance the forecasting of endogenous variables. With a deftly designed embedding layer, TimeXer empowers the canonical Transformer architecture with the ability to reconcile endogenous and exogenous information, where patch-wise self-attention and variate-wise cross-attention are employed. Moreover, a global endogenous variate token is adopted to effectively bridge the exogenous series into endogenous temporal patches. Experimentally, TimeXer significantly improves time series forecasting with exogenous variables and achieves consistent state-of-the-art performance in twelve real-world forecasting benchmarks.
Evaluating Large Language Models as Virtual Annotators for Time-series Physical Sensing Data
Mar 02, 2024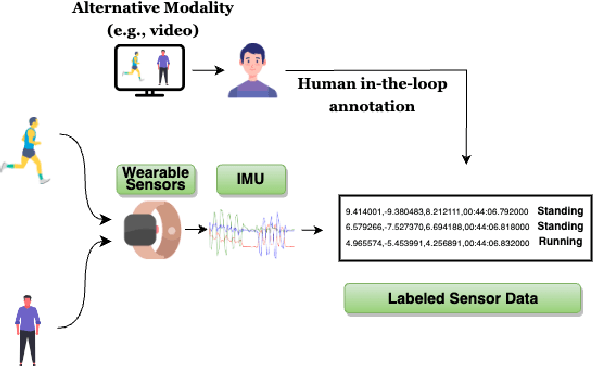

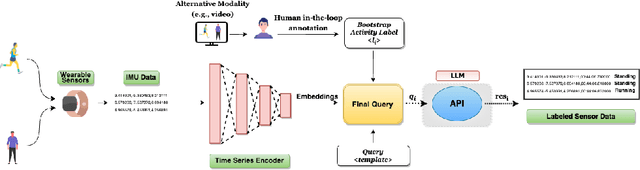

Traditional human-in-the-loop-based annotation for time-series data like inertial data often requires access to alternate modalities like video or audio from the environment. These alternate sources provide the necessary information to the human annotator, as the raw numeric data is often too obfuscated even for an expert. However, this traditional approach has many concerns surrounding overall cost, efficiency, storage of additional modalities, time, scalability, and privacy. Interestingly, recent large language models (LLMs) are also trained with vast amounts of publicly available alphanumeric data, which allows them to comprehend and perform well on tasks beyond natural language processing. Naturally, this opens up a potential avenue to explore LLMs as virtual annotators where the LLMs will be directly provided the raw sensor data for annotation instead of relying on any alternate modality. Naturally, this could mitigate the problems of the traditional human-in-the-loop approach. Motivated by this observation, we perform a detailed study in this paper to assess whether the state-of-the-art (SOTA) LLMs can be used as virtual annotators for labeling time-series physical sensing data. To perform this in a principled manner, we segregate the study into two major phases. In the first phase, we investigate the challenges an LLM like GPT-4 faces in comprehending raw sensor data. Considering the observations from phase 1, in the next phase, we investigate the possibility of encoding the raw sensor data using SOTA SSL approaches and utilizing the projected time-series data to get annotations from the LLM. Detailed evaluation with four benchmark HAR datasets shows that SSL-based encoding and metric-based guidance allow the LLM to make more reasonable decisions and provide accurate annotations without requiring computationally expensive fine-tuning or sophisticated prompt engineering.
Wildfire danger prediction optimization with transfer learning
Mar 19, 2024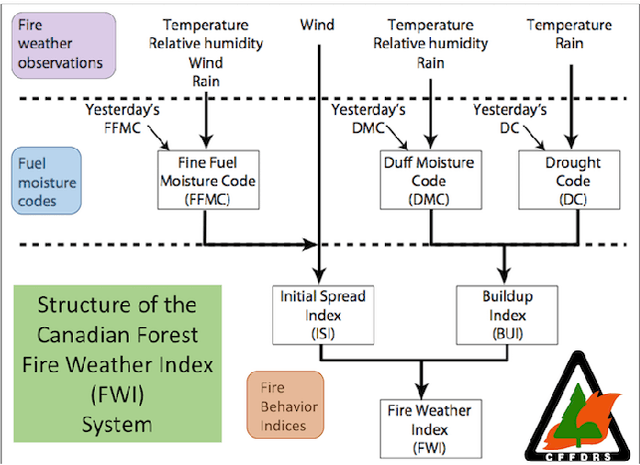
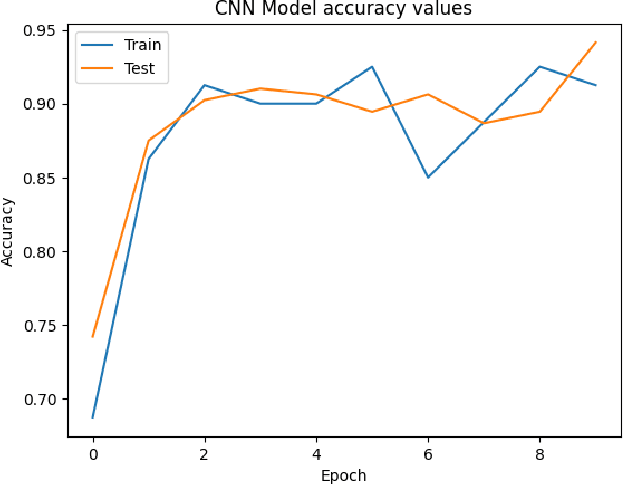
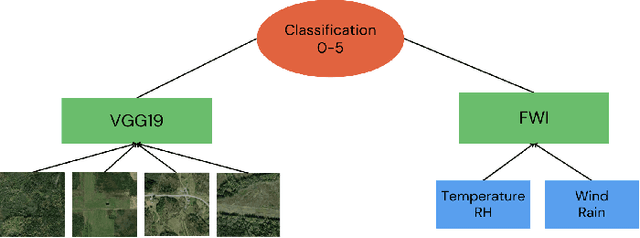

Convolutional Neural Networks (CNNs) have proven instrumental across various computer science domains, enabling advancements in object detection, classification, and anomaly detection. This paper explores the application of CNNs to analyze geospatial data specifically for identifying wildfire-affected areas. Leveraging transfer learning techniques, we fine-tuned CNN hyperparameters and integrated the Canadian Fire Weather Index (FWI) to assess moisture conditions. The study establishes a methodology for computing wildfire risk levels on a scale of 0 to 5, dynamically linked to weather patterns. Notably, through the integration of transfer learning, the CNN model achieved an impressive accuracy of 95\% in identifying burnt areas. This research sheds light on the inner workings of CNNs and their practical, real-time utility in predicting and mitigating wildfires. By combining transfer learning and CNNs, this study contributes a robust approach to assess burnt areas, facilitating timely interventions and preventative measures against conflagrations.
Interactive Robot-Environment Self-Calibration via Compliant Exploratory Actions
Mar 19, 2024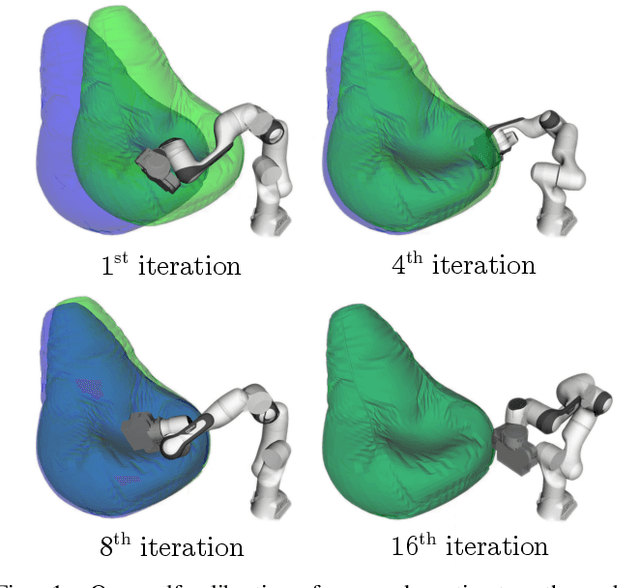

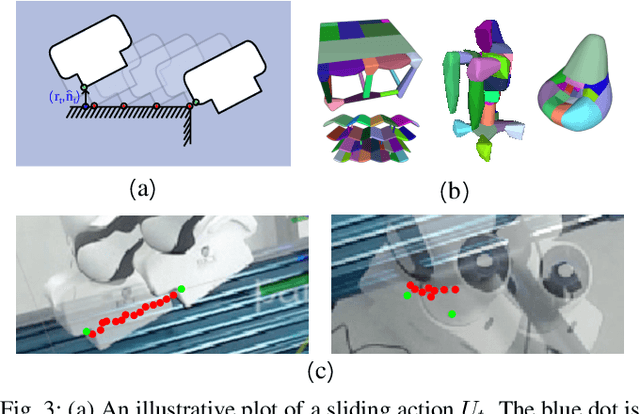

Calibrating robots into their workspaces is crucial for manipulation tasks. Existing calibration techniques often rely on sensors external to the robot (cameras, laser scanners, etc.) or specialized tools. This reliance complicates the calibration process and increases the costs and time requirements. Furthermore, the associated setup and measurement procedures require significant human intervention, which makes them more challenging to operate. Using the built-in force-torque sensors, which are nowadays a default component in collaborative robots, this work proposes a self-calibration framework where robot-environmental spatial relations are automatically estimated through compliant exploratory actions by the robot itself. The self-calibration approach converges, verifies its own accuracy, and terminates upon completion, autonomously purely through interactive exploration of the environment's geometries. Extensive experiments validate the effectiveness of our self-calibration approach in accurately establishing the robot-environment spatial relationships without the need for additional sensing equipment or any human intervention.
Jetfire: Efficient and Accurate Transformer Pretraining with INT8 Data Flow and Per-Block Quantization
Mar 19, 2024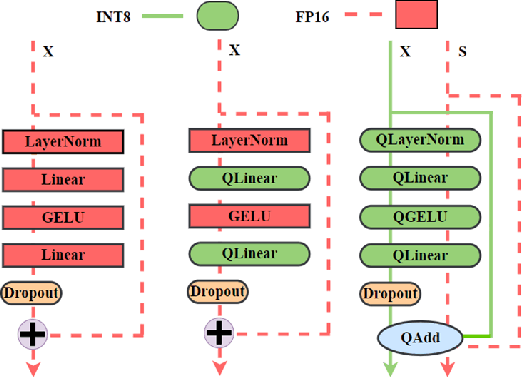

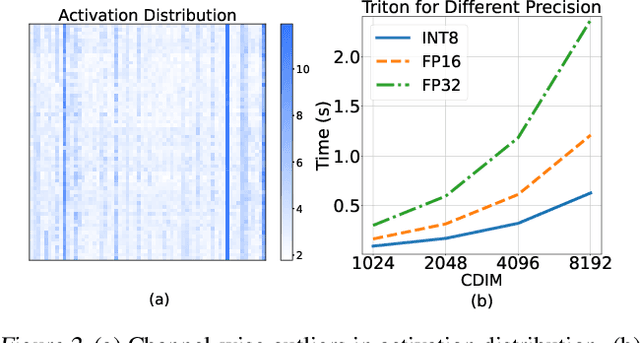
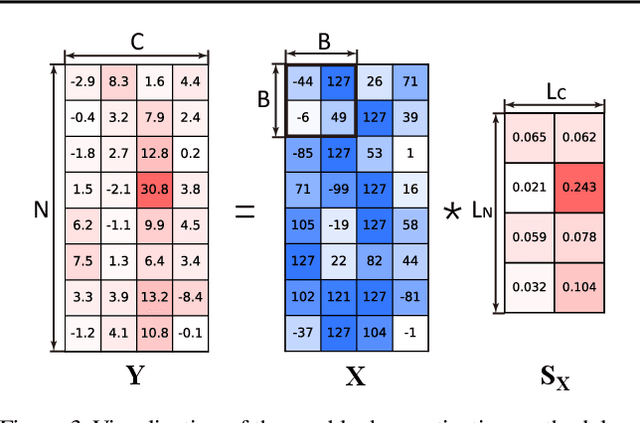
Pretraining transformers are generally time-consuming. Fully quantized training (FQT) is a promising approach to speed up pretraining. However, most FQT methods adopt a quantize-compute-dequantize procedure, which often leads to suboptimal speedup and significant performance degradation when used in transformers due to the high memory access overheads and low-precision computations. In this work, we propose Jetfire, an efficient and accurate INT8 training method specific to transformers. Our method features an INT8 data flow to optimize memory access and a per-block quantization method to maintain the accuracy of pretrained transformers. Extensive experiments demonstrate that our INT8 FQT method achieves comparable accuracy to the FP16 training baseline and outperforms the existing INT8 training works for transformers. Moreover, for a standard transformer block, our method offers an end-to-end training speedup of 1.42x and a 1.49x memory reduction compared to the FP16 baseline.
Sim2Real in Reconstructive Spectroscopy: Deep Learning with Augmented Device-Informed Data Simulation
Mar 19, 2024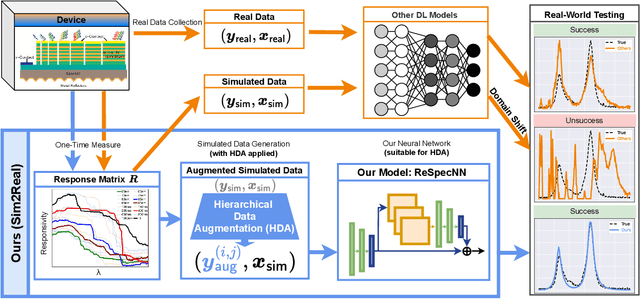
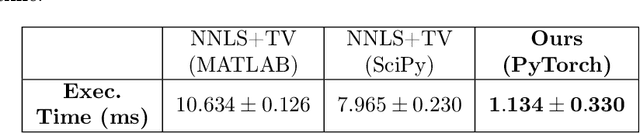
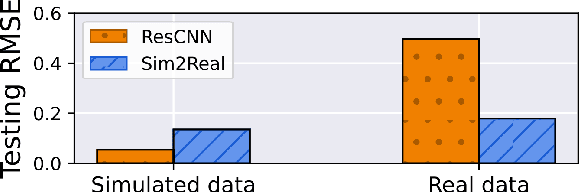
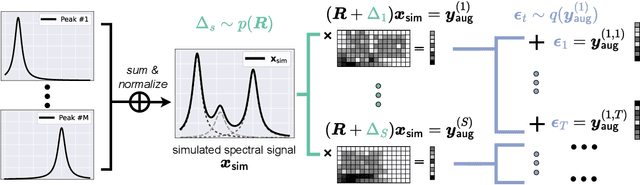
This work proposes a deep learning (DL)-based framework, namely Sim2Real, for spectral signal reconstruction in reconstructive spectroscopy, focusing on efficient data sampling and fast inference time. The work focuses on the challenge of reconstructing real-world spectral signals under the extreme setting where only device-informed simulated data are available for training. Such device-informed simulated data are much easier to collect than real-world data but exhibit large distribution shifts from their real-world counterparts. To leverage such simulated data effectively, a hierarchical data augmentation strategy is introduced to mitigate the adverse effects of this domain shift, and a corresponding neural network for the spectral signal reconstruction with our augmented data is designed. Experiments using a real dataset measured from our spectrometer device demonstrate that Sim2Real achieves significant speed-up during the inference while attaining on-par performance with the state-of-the-art optimization-based methods.
DyBluRF: Dynamic Neural Radiance Fields from Blurry Monocular Video
Mar 19, 2024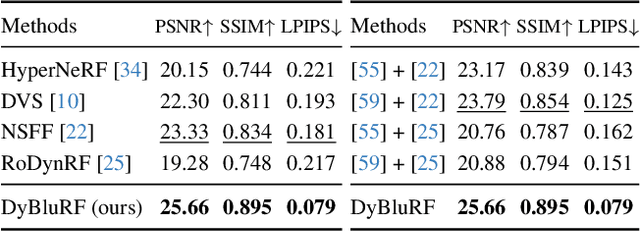
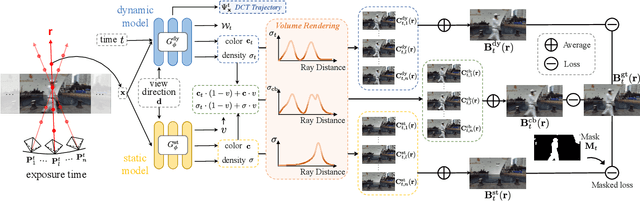
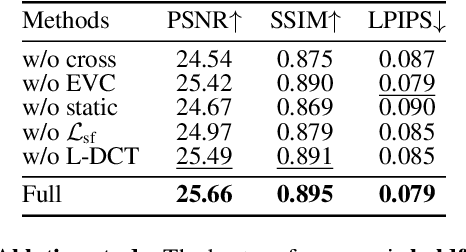
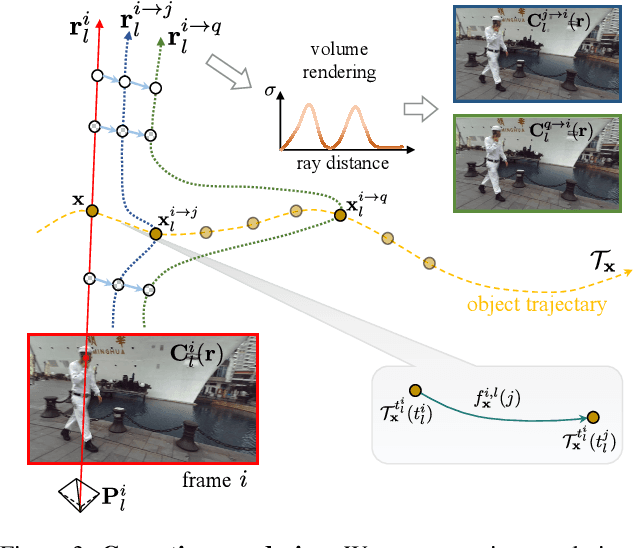
Recent advancements in dynamic neural radiance field methods have yielded remarkable outcomes. However, these approaches rely on the assumption of sharp input images. When faced with motion blur, existing dynamic NeRF methods often struggle to generate high-quality novel views. In this paper, we propose DyBluRF, a dynamic radiance field approach that synthesizes sharp novel views from a monocular video affected by motion blur. To account for motion blur in input images, we simultaneously capture the camera trajectory and object Discrete Cosine Transform (DCT) trajectories within the scene. Additionally, we employ a global cross-time rendering approach to ensure consistent temporal coherence across the entire scene. We curate a dataset comprising diverse dynamic scenes that are specifically tailored for our task. Experimental results on our dataset demonstrate that our method outperforms existing approaches in generating sharp novel views from motion-blurred inputs while maintaining spatial-temporal consistency of the scene.
JORA: JAX Tensor-Parallel LoRA Library for Retrieval Augmented Fine-Tuning
Mar 19, 2024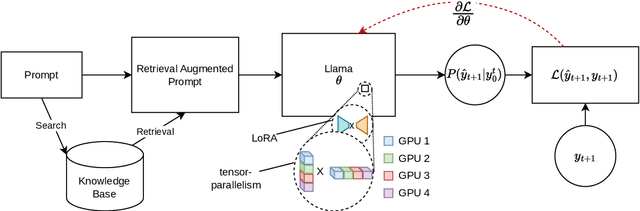
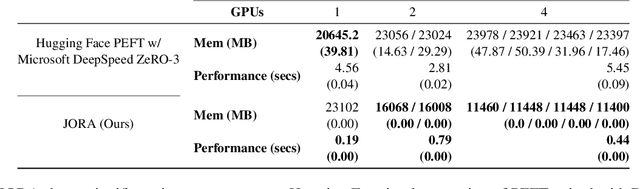
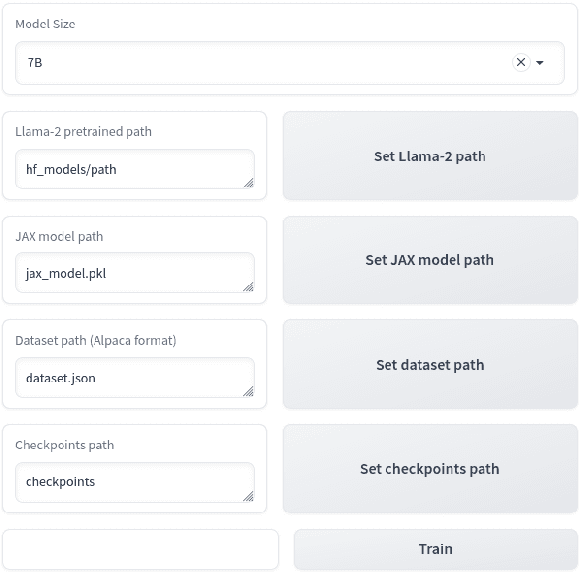
The scaling of Large Language Models (LLMs) for retrieval-based tasks, particularly in Retrieval Augmented Generation (RAG), faces significant memory constraints, especially when fine-tuning extensive prompt sequences. Current open-source libraries support full-model inference and fine-tuning across multiple GPUs but fall short of accommodating the efficient parameter distribution required for retrieved context. Addressing this gap, we introduce a novel framework for PEFT-compatible fine-tuning of Llama-2 models, leveraging distributed training. Our framework uniquely utilizes JAX's just-in-time (JIT) compilation and tensor-sharding for efficient resource management, thereby enabling accelerated fine-tuning with reduced memory requirements. This advancement significantly improves the scalability and feasibility of fine-tuning LLMs for complex RAG applications, even on systems with limited GPU resources. Our experiments show more than 12x improvement in runtime compared to Hugging Face/DeepSpeed implementation with four GPUs while consuming less than half the VRAM per GPU.
Enhancing Bandwidth Efficiency for Video Motion Transfer Applications using Deep Learning Based Keypoint Prediction
Mar 17, 2024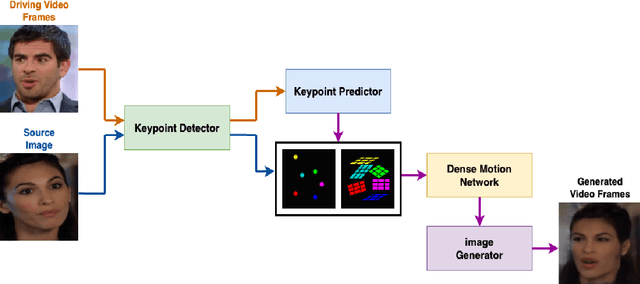

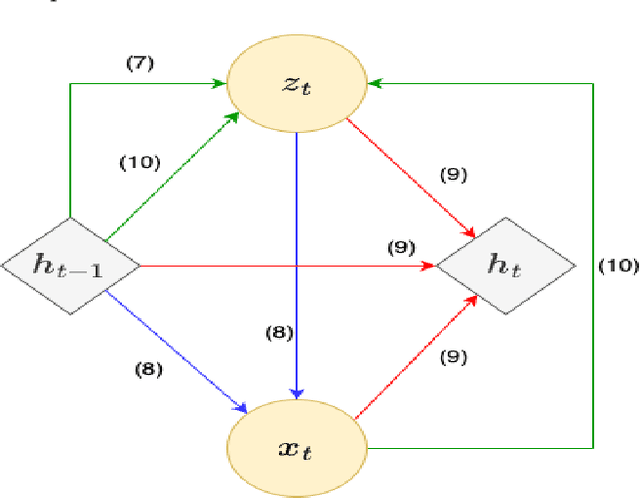

We propose a deep learning based novel prediction framework for enhanced bandwidth reduction in motion transfer enabled video applications such as video conferencing, virtual reality gaming and privacy preservation for patient health monitoring. To model complex motion, we use the First Order Motion Model (FOMM) that represents dynamic objects using learned keypoints along with their local affine transformations. Keypoints are extracted by a self-supervised keypoint detector and organized in a time series corresponding to the video frames. Prediction of keypoints, to enable transmission using lower frames per second on the source device, is performed using a Variational Recurrent Neural Network (VRNN). The predicted keypoints are then synthesized to video frames using an optical flow estimator and a generator network. This efficacy of leveraging keypoint based representations in conjunction with VRNN based prediction for both video animation and reconstruction is demonstrated on three diverse datasets. For real-time applications, our results show the effectiveness of our proposed architecture by enabling up to 2x additional bandwidth reduction over existing keypoint based video motion transfer frameworks without significantly compromising video quality.
Large-scale flood modeling and forecasting with FloodCast
Mar 18, 2024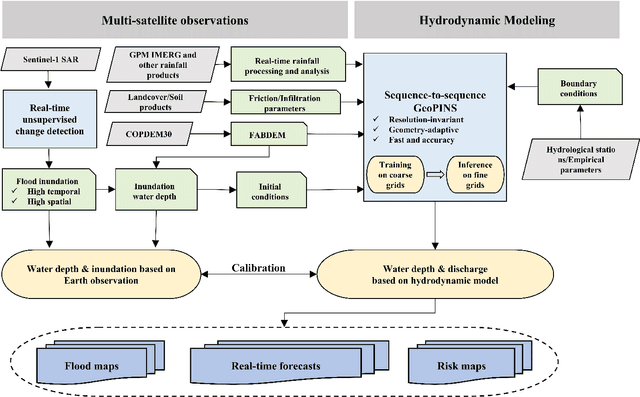



Large-scale hydrodynamic models generally rely on fixed-resolution spatial grids and model parameters as well as incurring a high computational cost. This limits their ability to accurately forecast flood crests and issue time-critical hazard warnings. In this work, we build a fast, stable, accurate, resolution-invariant, and geometry-adaptative flood modeling and forecasting framework that can perform at large scales, namely FloodCast. The framework comprises two main modules: multi-satellite observation and hydrodynamic modeling. In the multi-satellite observation module, a real-time unsupervised change detection method and a rainfall processing and analysis tool are proposed to harness the full potential of multi-satellite observations in large-scale flood prediction. In the hydrodynamic modeling module, a geometry-adaptive physics-informed neural solver (GeoPINS) is introduced, benefiting from the absence of a requirement for training data in physics-informed neural networks and featuring a fast, accurate, and resolution-invariant architecture with Fourier neural operators. GeoPINS demonstrates impressive performance on popular PDEs across regular and irregular domains. Building upon GeoPINS, we propose a sequence-to-sequence GeoPINS model to handle long-term temporal series and extensive spatial domains in large-scale flood modeling. Next, we establish a benchmark dataset in the 2022 Pakistan flood to assess various flood prediction methods. Finally, we validate the model in three dimensions - flood inundation range, depth, and transferability of spatiotemporal downscaling. Traditional hydrodynamics and sequence-to-sequence GeoPINS exhibit exceptional agreement during high water levels, while comparative assessments with SAR-based flood depth data show that sequence-to-sequence GeoPINS outperforms traditional hydrodynamics, with smaller prediction errors.