 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Text-Conditioned Sampling Framework for Text-to-Image Generation with Masked Generative Models
Apr 04, 2023

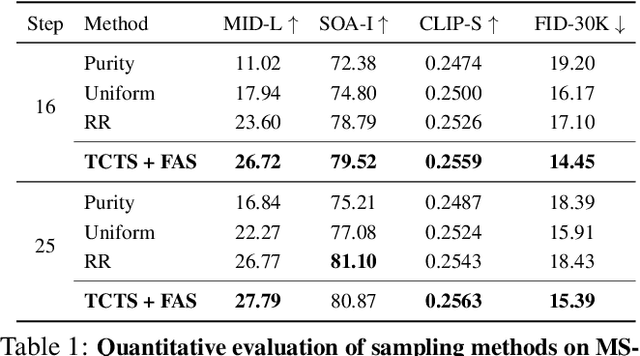

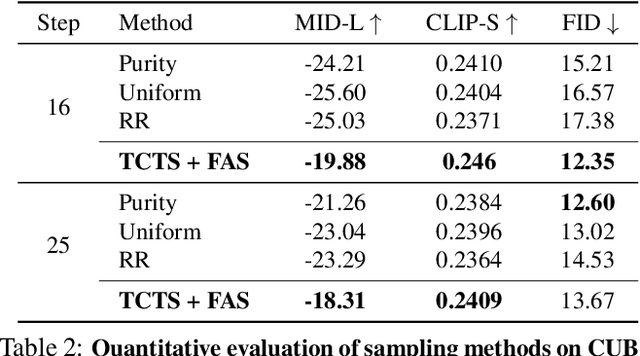
Token-based masked generative models are gaining popularity for their fast inference time with parallel decoding. While recent token-based approaches achieve competitive performance to diffusion-based models, their generation performance is still suboptimal as they sample multiple tokens simultaneously without considering the dependence among them. We empirically investigate this problem and propose a learnable sampling model, Text-Conditioned Token Selection (TCTS), to select optimal tokens via localized supervision with text information. TCTS improves not only the image quality but also the semantic alignment of the generated images with the given texts. To further improve the image quality, we introduce a cohesive sampling strategy, Frequency Adaptive Sampling (FAS), to each group of tokens divided according to the self-attention maps. We validate the efficacy of TCTS combined with FAS with various generative tasks, demonstrating that it significantly outperforms the baselines in image-text alignment and image quality. Our text-conditioned sampling framework further reduces the original inference time by more than 50% without modifying the original generative model.
A-CAP: Anticipation Captioning with Commonsense Knowledge
Apr 13, 2023
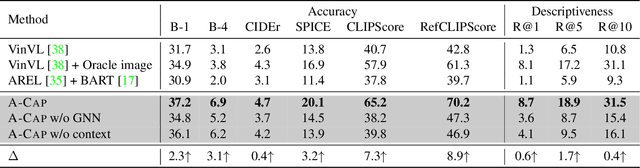
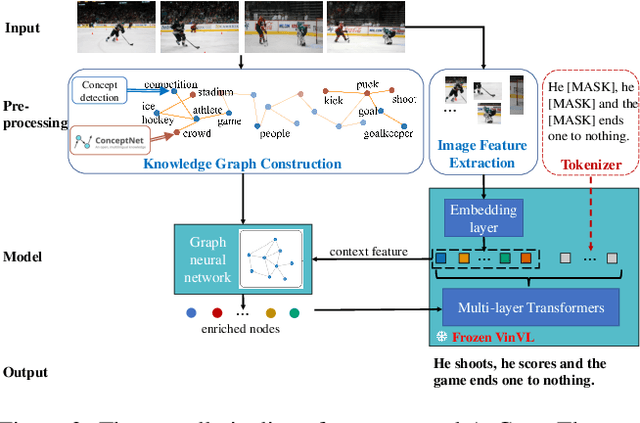
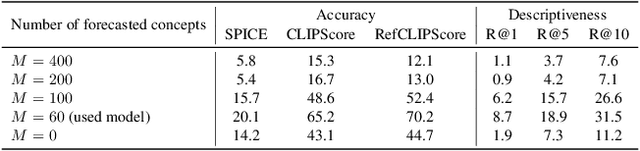
Humans possess the capacity to reason about the future based on a sparse collection of visual cues acquired over time. In order to emulate this ability, we introduce a novel task called Anticipation Captioning, which generates a caption for an unseen oracle image using a sparsely temporally-ordered set of images. To tackle this new task, we propose a model called A-CAP, which incorporates commonsense knowledge into a pre-trained vision-language model, allowing it to anticipate the caption. Through both qualitative and quantitative evaluations on a customized visual storytelling dataset, A-CAP outperforms other image captioning methods and establishes a strong baseline for anticipation captioning. We also address the challenges inherent in this task.
Improving Code Generation by Training with Natural Language Feedback
Mar 28, 2023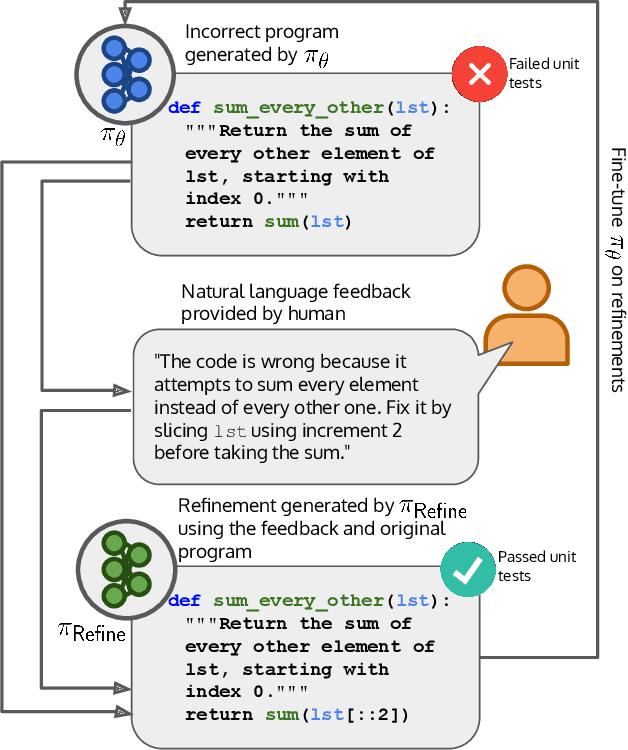



The potential for pre-trained large language models (LLMs) to use natural language feedback at inference time has been an exciting recent development. We build upon this observation by formalizing an algorithm for learning from natural language feedback at training time instead, which we call Imitation learning from Language Feedback (ILF). ILF requires only a small amount of human-written feedback during training and does not require the same feedback at test time, making it both user-friendly and sample-efficient. We further show that ILF can be seen as a form of minimizing the KL divergence to the ground truth distribution and demonstrate a proof-of-concept on a neural program synthesis task. We use ILF to improve a Codegen-Mono 6.1B model's pass@1 rate by 38% relative (and 10% absolute) on the Mostly Basic Python Problems (MBPP) benchmark, outperforming both fine-tuning on MBPP and fine-tuning on repaired programs written by humans. Overall, our results suggest that learning from human-written natural language feedback is both more effective and sample-efficient than training exclusively on demonstrations for improving an LLM's performance on code generation tasks.
Item Graph Convolution Collaborative Filtering for Inductive Recommendations
Mar 28, 2023Graph Convolutional Networks (GCN) have been recently employed as core component in the construction of recommender system algorithms, interpreting user-item interactions as the edges of a bipartite graph. However, in the absence of side information, the majority of existing models adopt an approach of randomly initialising the user embeddings and optimising them throughout the training process. This strategy makes these algorithms inherently transductive, curtailing their ability to generate predictions for users that were unseen at training time. To address this issue, we propose a convolution-based algorithm, which is inductive from the user perspective, while at the same time, depending only on implicit user-item interaction data. We propose the construction of an item-item graph through a weighted projection of the bipartite interaction network and to employ convolution to inject higher order associations into item embeddings, while constructing user representations as weighted sums of the items with which they have interacted. Despite not training individual embeddings for each user our approach achieves state of-the-art recommendation performance with respect to transductive baselines on four real-world datasets, showing at the same time robust inductive performance.
Prior based Sampling for Adaptive LiDAR
Apr 14, 2023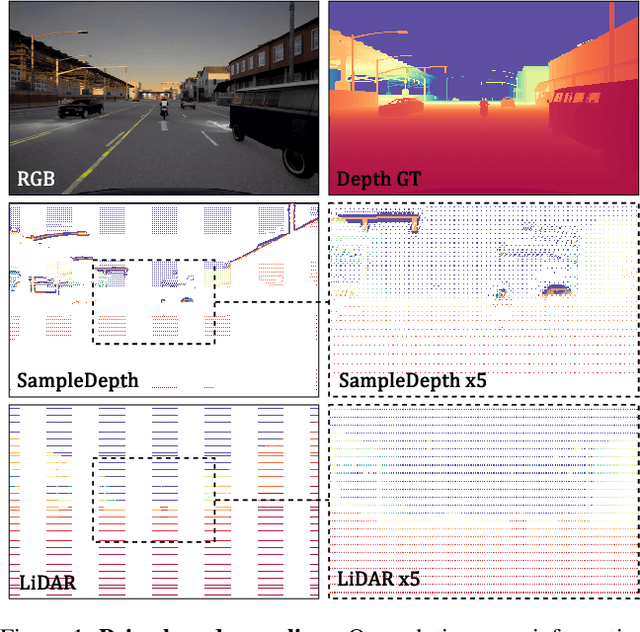
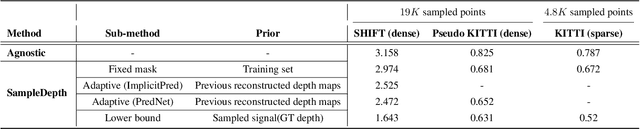
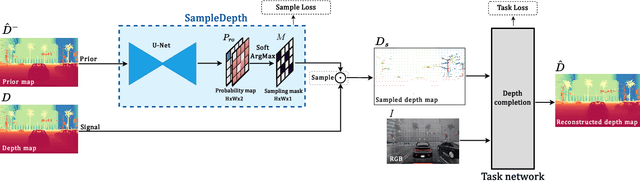
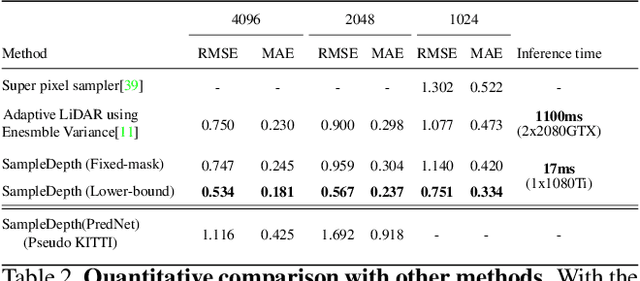
We propose SampleDepth, a Convolutional Neural Network (CNN), that is suited for an adaptive LiDAR. Typically,LiDAR sampling strategy is pre-defined, constant and independent of the observed scene. Instead of letting a LiDAR sample the scene in this agnostic fashion, SampleDepth determines, adaptively, where it is best to sample the current frame.To do that, SampleDepth uses depth samples from previous time steps to predict a sampling mask for the current frame. Crucially, SampleDepth is trained to optimize the performance of a depth completion downstream task. SampleDepth is evaluated on two different depth completion networks and two LiDAR datasets, KITTI Depth Completion and the newly introduced synthetic dataset, SHIFT. We show that SampleDepth is effective and suitable for different depth completion downstream tasks.
Learned Two-Plane Perspective Prior based Image Resampling for Efficient Object Detection
Mar 25, 2023
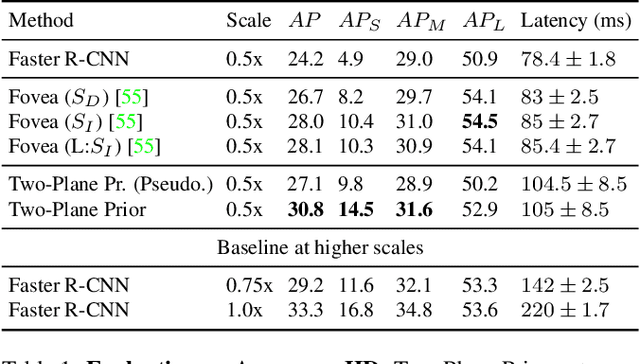
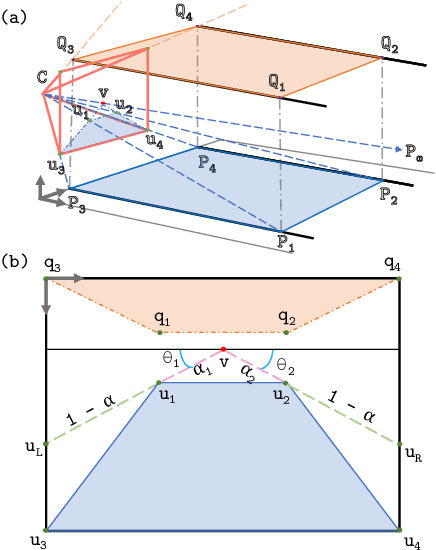
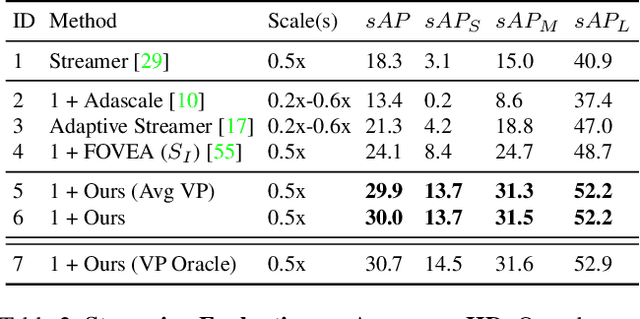
Real-time efficient perception is critical for autonomous navigation and city scale sensing. Orthogonal to architectural improvements, streaming perception approaches have exploited adaptive sampling improving real-time detection performance. In this work, we propose a learnable geometry-guided prior that incorporates rough geometry of the 3D scene (a ground plane and a plane above) to resample images for efficient object detection. This significantly improves small and far-away object detection performance while also being more efficient both in terms of latency and memory. For autonomous navigation, using the same detector and scale, our approach improves detection rate by +4.1 $AP_{S}$ or +39% and in real-time performance by +5.3 $sAP_{S}$ or +63% for small objects over state-of-the-art (SOTA). For fixed traffic cameras, our approach detects small objects at image scales other methods cannot. At the same scale, our approach improves detection of small objects by 195% (+12.5 $AP_{S}$) over naive-downsampling and 63% (+4.2 $AP_{S}$) over SOTA.
The State-of-the-Art in Air Pollution Monitoring and Forecasting Systems using IoT, Big Data, and Machine Learning
Apr 19, 2023The quality of air is closely linked with the life quality of humans, plantations, and wildlife. It needs to be monitored and preserved continuously. Transportations, industries, construction sites, generators, fireworks, and waste burning have a major percentage in degrading the air quality. These sources are required to be used in a safe and controlled manner. Using traditional laboratory analysis or installing bulk and expensive models every few miles is no longer efficient. Smart devices are needed for collecting and analyzing air data. The quality of air depends on various factors, including location, traffic, and time. Recent researches are using machine learning algorithms, big data technologies, and the Internet of Things to propose a stable and efficient model for the stated purpose. This review paper focuses on studying and compiling recent research in this field and emphasizes the Data sources, Monitoring, and Forecasting models. The main objective of this paper is to provide the astuteness of the researches happening to improve the various aspects of air polluting models. Further, it casts light on the various research issues and challenges also.
Robust Mean Teacher for Continual and Gradual Test-Time Adaptation
Nov 23, 2022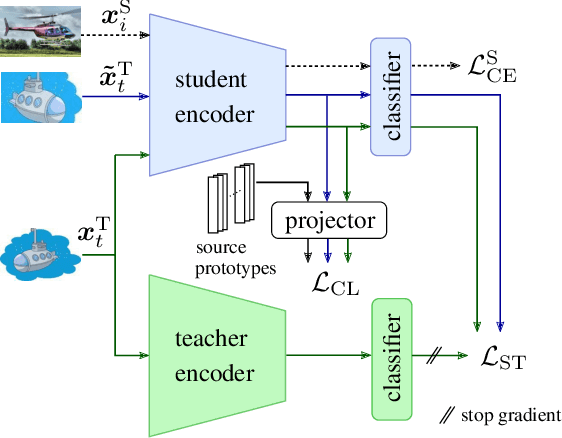
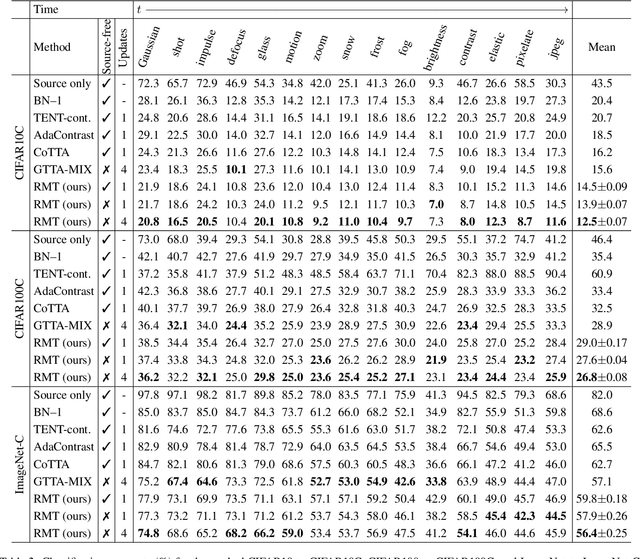
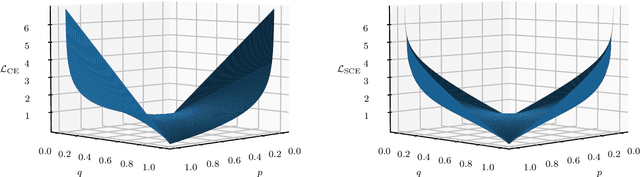
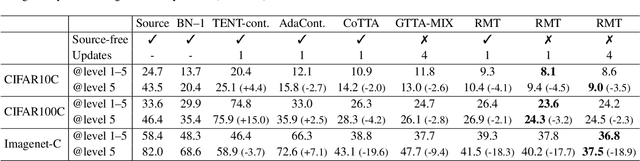
Since experiencing domain shifts during test-time is inevitable in practice, test-time adaption (TTA) continues to adapt the model during deployment. Recently, the area of continual and gradual test-time adaptation (TTA) emerged. In contrast to standard TTA, continual TTA considers not only a single domain shift, but a sequence of shifts. Gradual TTA further exploits the property that some shifts evolve gradually over time. Since in both settings long test sequences are present, error accumulation needs to be addressed for methods relying on self-training. In this work, we propose and show that in the setting of TTA, the symmetric cross-entropy is better suited as a consistency loss for mean teachers compared to the commonly used cross-entropy. This is justified by our analysis with respect to the (symmetric) cross-entropy's gradient properties. To pull the test feature space closer to the source domain, where the pre-trained model is well posed, contrastive learning is leveraged. Since applications differ in their requirements, we address different settings, namely having source data available and the more challenging source-free setting. We demonstrate the effectiveness of our proposed method 'robust mean teacher' (RMT) on the continual and gradual corruption benchmarks CIFAR10C, CIFAR100C, and Imagenet-C. We further consider ImageNet-R and propose a new continual DomainNet-126 benchmark. State-of-the-art results are achieved on all benchmarks.
Real Time Incremental Image Mosaicking Without Use of Any Camera Parameter
Dec 05, 2022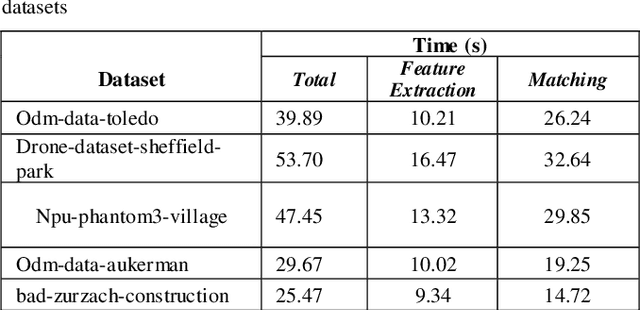

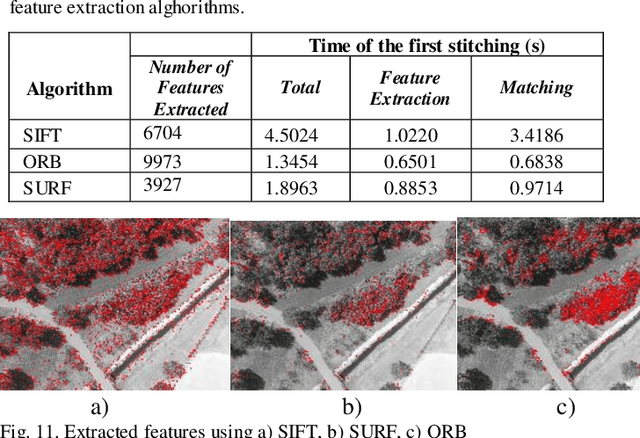

Over the past decade, there has been a significant increase in the use of Unmanned Aerial Vehicles (UAVs) to support a wide variety of missions, such as remote surveillance, vehicle tracking, and object detection. For problems involving processing of areas larger than a single image, the mosaicking of UAV imagery is a necessary step. Real-time image mosaicking is used for missions that requires fast response like search and rescue missions. It typically requires information from additional sensors, such as Global Position System (GPS) and Inertial Measurement Unit (IMU), to facilitate direct orientation, or 3D reconstruction approaches to recover the camera poses. This paper proposes a UAV-based system for real-time creation of incremental mosaics which does not require either direct or indirect camera parameters such as orientation information. Inspired by previous approaches, in the mosaicking process, feature extraction from images, matching of similar key points between images, finding homography matrix to warp and align images, and blending images to obtain mosaics better looking, plays important roles in the achievement of the high quality result. Edge detection is used in the blending step as a novel approach. Experimental results show that real-time incremental image mosaicking process can be completed satisfactorily and without need for any additional camera parameters.
Foldsformer: Learning Sequential Multi-Step Cloth Manipulation With Space-Time Attention
Jan 08, 2023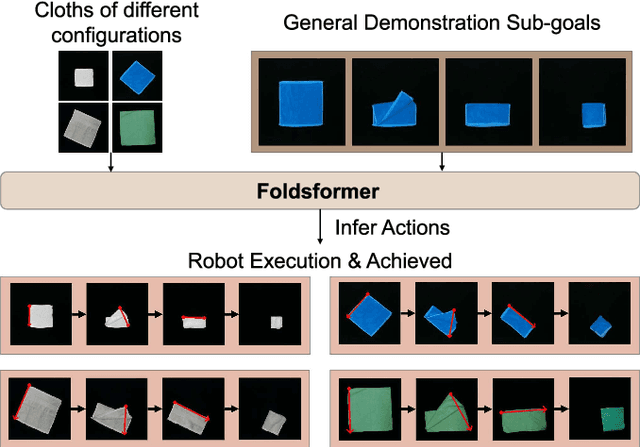
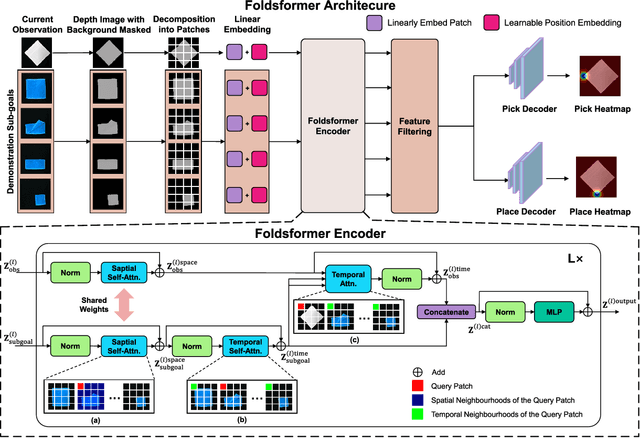
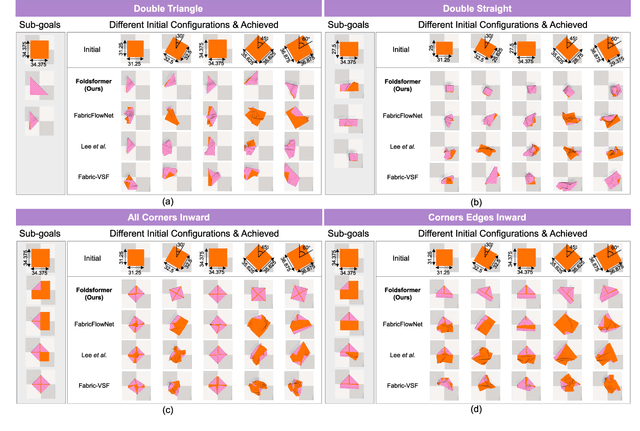
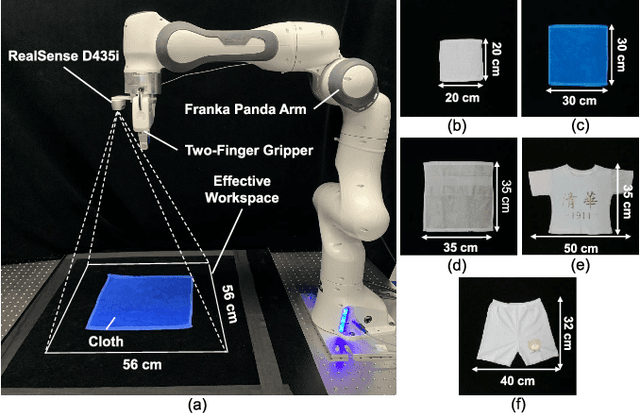
Sequential multi-step cloth manipulation is a challenging problem in robotic manipulation, requiring a robot to perceive the cloth state and plan a sequence of chained actions leading to the desired state. Most previous works address this problem in a goal-conditioned way, and goal observation must be given for each specific task and cloth configuration, which is not practical and efficient. Thus, we present a novel multi-step cloth manipulation planning framework named Foldformer. Foldformer can complete similar tasks with only a general demonstration and utilize a space-time attention mechanism to capture the instruction information behind this demonstration. We experimentally evaluate Foldsformer on four representative sequential multi-step manipulation tasks and show that Foldsformer significantly outperforms state-of-the-art approaches in simulation. Foldformer can complete multi-step cloth manipulation tasks even when configurations of the cloth (e.g., size and pose) vary from configurations in the general demonstrations. Furthermore, our approach can be transferred from simulation to the real world without additional training or domain randomization. Despite training on rectangular clothes, we also show that our approach can generalize to unseen cloth shapes (T-shirts and shorts). Videos and source code are available at: https://sites.google.com/view/foldsformer.
* 8 pages, 6 figures, published to IEEE Robotics & Automation Letters (RA-L)