 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enabling and Accelerating Dynamic Vision Transformer Inference for Real-Time Applications
Dec 06, 2022
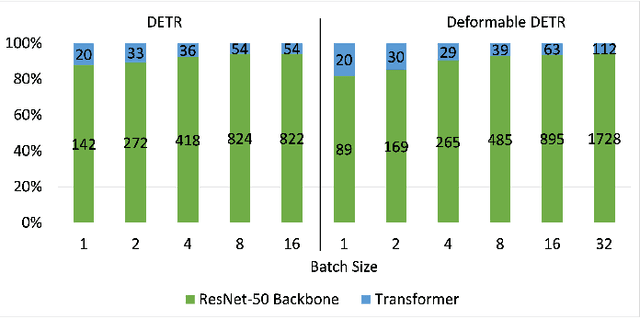
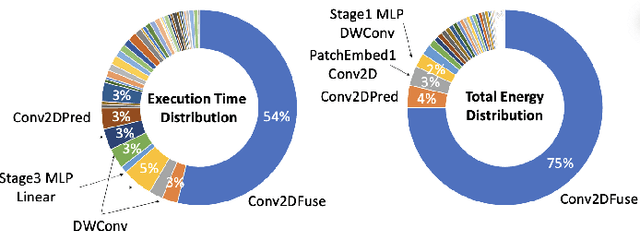
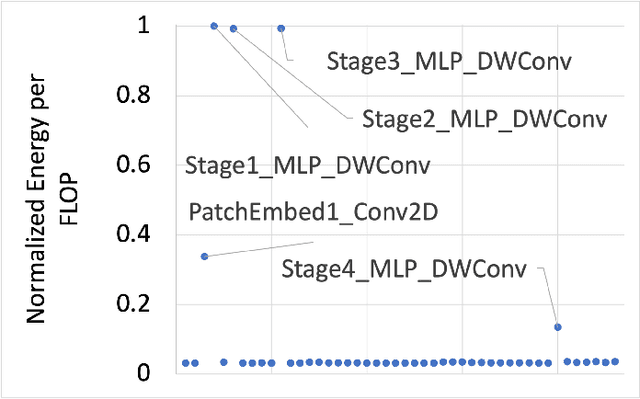
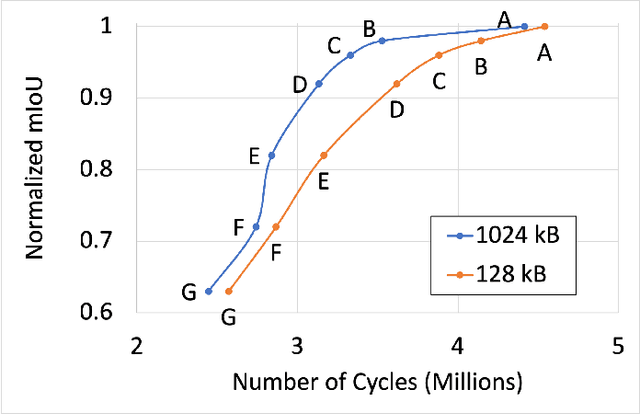
Many state-of-the-art deep learning models for computer vision tasks are based on the transformer architecture. Such models can be computationally expensive and are typically statically set to meet the deployment scenario. However, in real-time applications, the resources available for every inference can vary considerably and be smaller than what state-of-the-art models use. We can use dynamic models to adapt the model execution to meet real-time application resource constraints. While prior dynamic work has primarily minimized resource utilization for less complex input images while maintaining accuracy and focused on CNNs and early transformer models such as BERT, we adapt vision transformers to meet system dynamic resource constraints, independent of the input image. We find that unlike early transformer models, recent state-of-the-art vision transformers heavily rely on convolution layers. We show that pretrained models are fairly resilient to skipping computation in the convolution and self-attention layers, enabling us to create a low-overhead system for dynamic real-time inference without additional training. Finally, we create a optimized accelerator for these dynamic vision transformers in a 5nm technology. The PE array occupies 2.26mm$^2$ and is 17 times faster than a NVIDIA TITAN V GPU for state-of-the-art transformer-based models for semantic segmentation.
On the Bit Error Performance of OTFS Modulation using Discrete Zak Transform
Mar 22, 2023
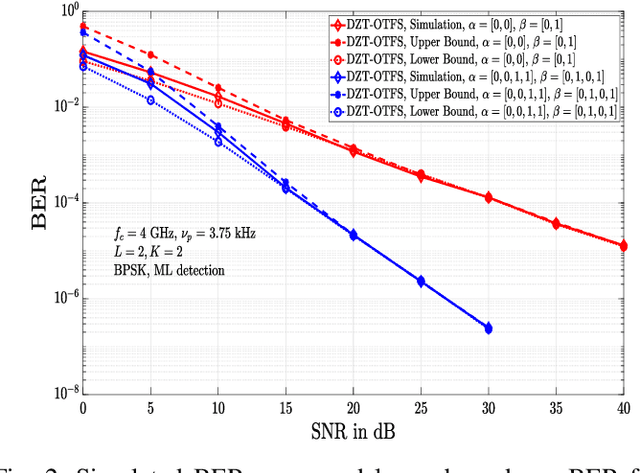
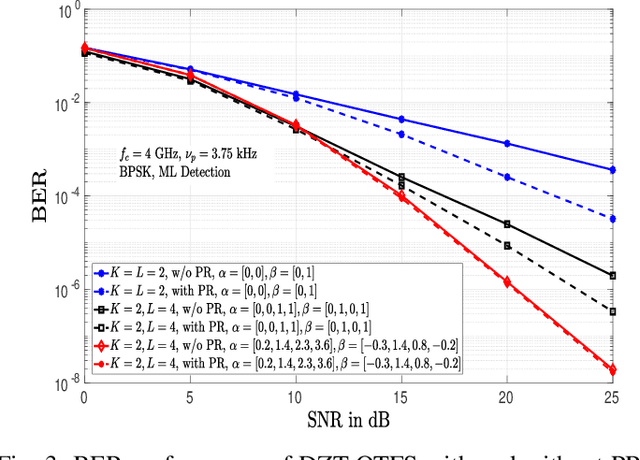
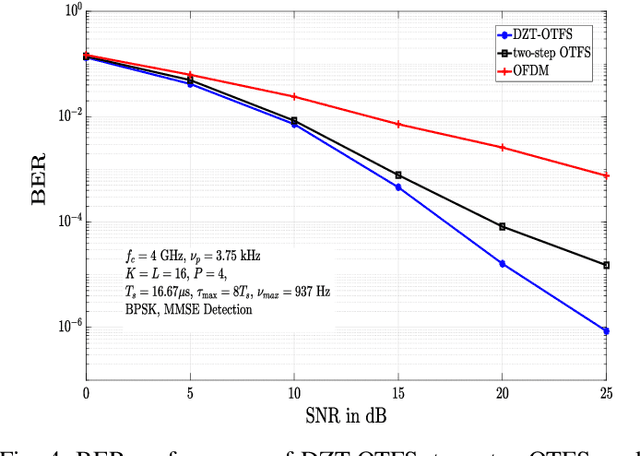
In orthogonal time frequency space (OTFS) modulation, Zak transform approach is a natural approach for converting information symbols multiplexed in the DD domain directly to time domain for transmission, and vice versa at the receiver. Past research on OTFS has primarily considered a two-step approach where DD domain symbols are first converted to time-frequency domain which are then converted to time domain for transmission, and vice versa at the receiver. The Zak transform approach can offer performance and complexity benefits compared to the two-step approach. This paper presents an early investigation on the bit error performance of OTFS realized using discrete Zak transform (DZT). We develop a compact DD domain input-output relation for DZT-OTFS using matrix decomposition that is valid for both integer and fractional delay-Dopplers. We analyze the bit error performance of DZT-OTFS using pairwise error probability analysis and simulations. Simulation results show that 1) both DZT-OTFS and two-step OTFS perform better than OFDM, and 2) DZT-OTFS achieves better performance compared to two-step OTFS over a wide range of Doppler spreads.
Real-time Bidding Strategy in Display Advertising: An Empirical Analysis
Nov 30, 2022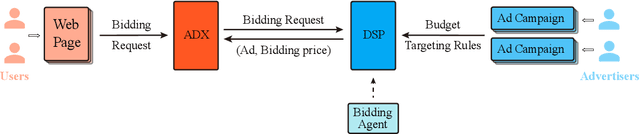
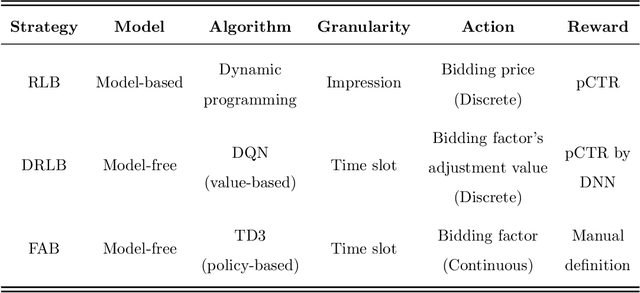
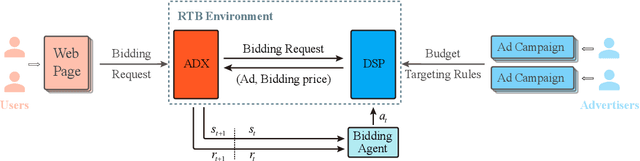

Bidding strategies that help advertisers determine bidding prices are receiving increasing attention as more and more ad impressions are sold through real-time bidding systems. This paper first describes the problem and challenges of optimizing bidding strategies for individual advertisers in real-time bidding display advertising. Then, several representative bidding strategies are introduced, especially the research advances and challenges of reinforcement learning-based bidding strategies. Further, we quantitatively evaluate the performance of several representative bidding strategies on the iPinYou dataset. Specifically, we examine the effects of state, action, and reward function on the performance of reinforcement learning-based bidding strategies. Finally, we summarize the general steps for optimizing bidding strategies using reinforcement learning algorithms and present our suggestions.
Towards an Effective and Efficient Transformer for Rain-by-snow Weather Removal
Apr 06, 2023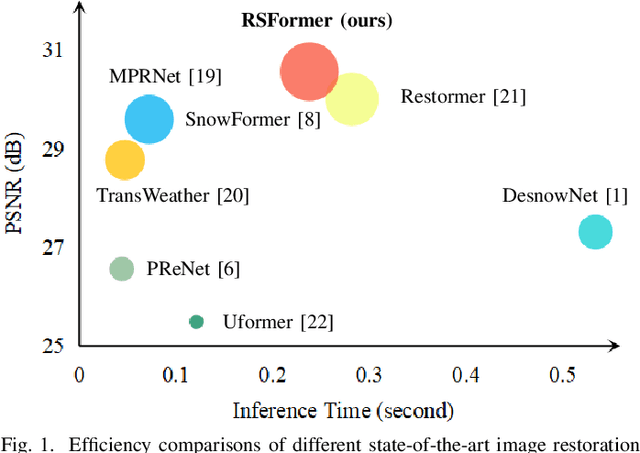
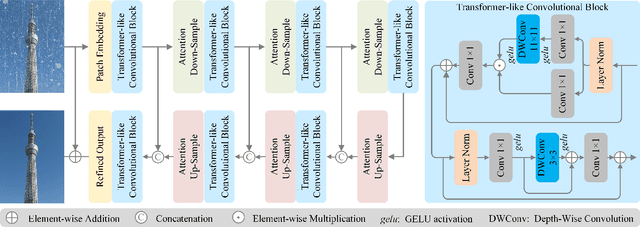
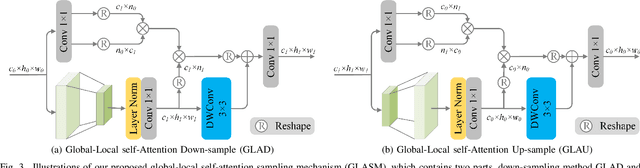
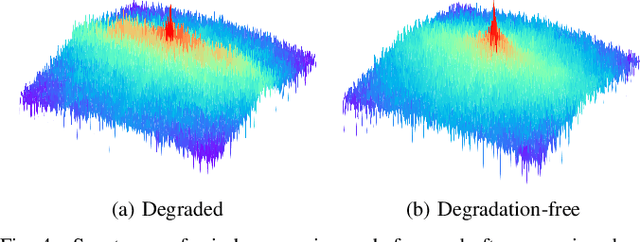
Rain-by-snow weather removal is a specialized task in weather-degraded image restoration aiming to eliminate coexisting rain streaks and snow particles. In this paper, we propose RSFormer, an efficient and effective Transformer that addresses this challenge. Initially, we explore the proximity of convolution networks (ConvNets) and vision Transformers (ViTs) in hierarchical architectures and experimentally find they perform approximately at intra-stage feature learning. On this basis, we utilize a Transformer-like convolution block (TCB) that replaces the computationally expensive self-attention while preserving attention characteristics for adapting to input content. We also demonstrate that cross-stage progression is critical for performance improvement, and propose a global-local self-attention sampling mechanism (GLASM) that down-/up-samples features while capturing both global and local dependencies. Finally, we synthesize two novel rain-by-snow datasets, RSCityScape and RS100K, to evaluate our proposed RSFormer. Extensive experiments verify that RSFormer achieves the best trade-off between performance and time-consumption compared to other restoration methods. For instance, it outperforms Restormer with a 1.53% reduction in the number of parameters and a 15.6% reduction in inference time. Datasets, source code and pre-trained models are available at \url{https://github.com/chdwyb/RSFormer}.
Modelling customer lifetime-value in the retail banking industry
Apr 06, 2023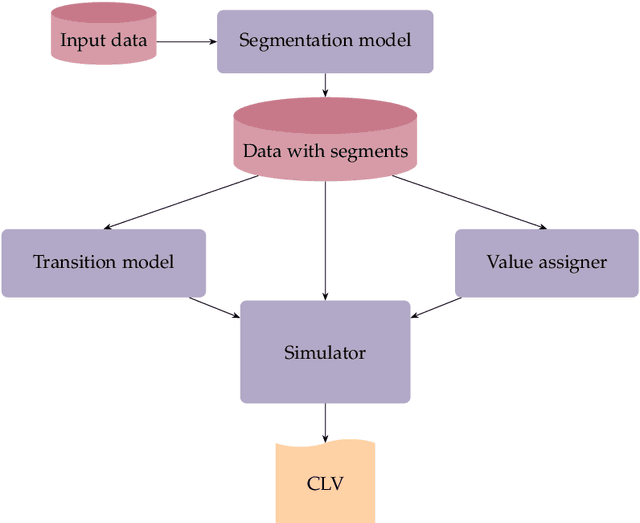
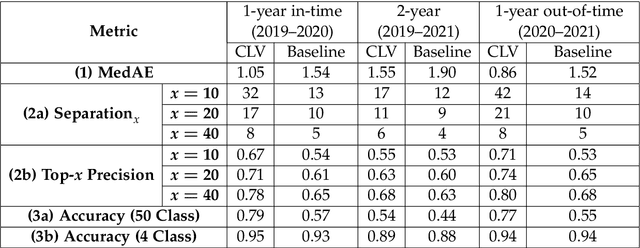
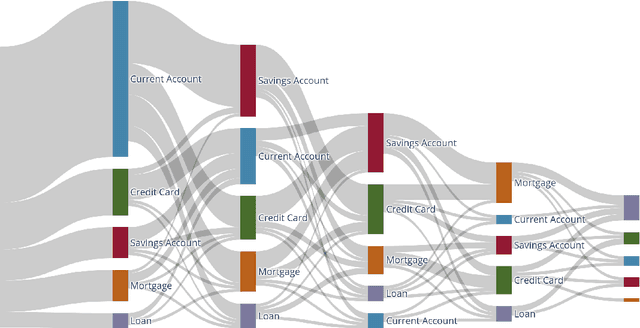
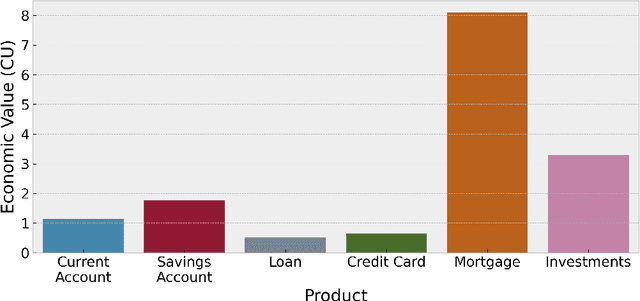
Understanding customer lifetime value is key to nurturing long-term customer relationships, however, estimating it is far from straightforward. In the retail banking industry, commonly used approaches rely on simple heuristics and do not take advantage of the high predictive ability of modern machine learning techniques. We present a general framework for modelling customer lifetime value which may be applied to industries with long-lasting contractual and product-centric customer relationships, of which retail banking is an example. This framework is novel in facilitating CLV predictions over arbitrary time horizons and product-based propensity models. We also detail an implementation of this model which is currently in production at a large UK lender. In testing, we estimate an 43% improvement in out-of-time CLV prediction error relative to a popular baseline approach. Propensity models derived from our CLV model have been used to support customer contact marketing campaigns. In testing, we saw that the top 10% of customers ranked by their propensity to take up investment products were 3.2 times more likely to take up an investment product in the next year than a customer chosen at random.
Online Learning for Equilibrium Pricing in Markets under Incomplete Information
Mar 21, 2023The study of market equilibria is central to economic theory, particularly in efficiently allocating scarce resources. However, the computation of equilibrium prices at which the supply of goods matches their demand typically relies on having access to complete information on private attributes of agents, e.g., suppliers' cost functions, which are often unavailable in practice. Motivated by this practical consideration, we consider the problem of setting equilibrium prices in the incomplete information setting wherein a market operator seeks to satisfy the customer demand for a commodity by purchasing the required amount from competing suppliers with privately known cost functions unknown to the market operator. In this incomplete information setting, we consider the online learning problem of learning equilibrium prices over time while jointly optimizing three performance metrics -- unmet demand, cost regret, and payment regret -- pertinent in the context of equilibrium pricing over a horizon of $T$ periods. We first consider the setting when suppliers' cost functions are fixed and develop algorithms that achieve a regret of $O(\log \log T)$ when the customer demand is constant over time, or $O(\sqrt{T} \log \log T)$ when the demand is variable over time. Next, we consider the setting when the suppliers' cost functions can vary over time and illustrate that no online algorithm can achieve sublinear regret on all three metrics when the market operator has no information about how the cost functions change over time. Thus, we consider an augmented setting wherein the operator has access to hints/contexts that, without revealing the complete specification of the cost functions, reflect the variation in the cost functions over time and propose an algorithm with sublinear regret in this augmented setting.
Learning to Detect Touches on Cluttered Tables
Apr 10, 2023
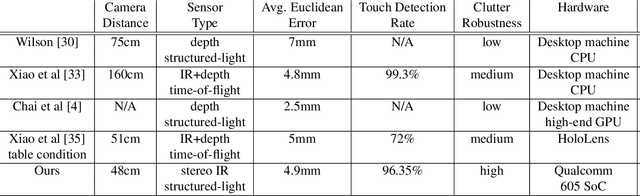

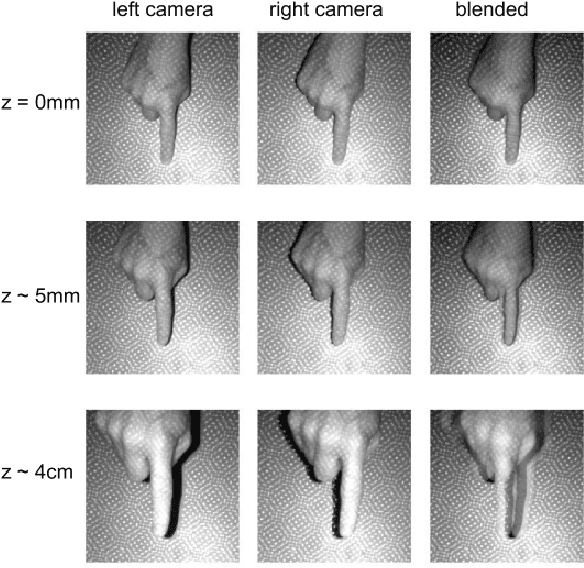
We present a novel self-contained camera-projector tabletop system with a lamp form-factor that brings digital intelligence to our tables. We propose a real-time, on-device, learning-based touch detection algorithm that makes any tabletop interactive. The top-down configuration and learning-based algorithm makes our method robust to the presence of clutter, a main limitation of existing camera-projector tabletop systems. Our research prototype enables a set of experiences that combine hand interactions and objects present on the table. A video can be found at https://youtu.be/hElC_c25Fg8.
Seeing is not always believing: A Quantitative Study on Human Perception of AI-Generated Images
Apr 25, 2023



Photos serve as a way for humans to record what they experience in their daily lives, and they are often regarded as trustworthy sources of information. However, there is a growing concern that the advancement of artificial intelligence (AI) technology may produce fake photos, which can create confusion and diminish trust in photographs. This study aims to answer the question of whether the current state-of-the-art AI-based visual content generation models can consistently deceive human eyes and convey false information. By conducting a high-quality quantitative study with fifty participants, we reveal, for the first time, that humans cannot distinguish between real photos and AI-created fake photos to a significant degree 38.7%. Our study also finds that an individual's background, such as their gender, age, and experience with AI-generated content (AIGC), does not significantly affect their ability to distinguish AI-generated images from real photographs. However, we do observe that there tend to be certain defects in AI-generated images that serve as cues for people to distinguish between real and fake photos. We hope that our study can raise awareness of the potential risks of AI-generated images and encourage further research to prevent the spread of false information. From a positive perspective, AI-generated images have the potential to revolutionize various industries and create a better future for humanity if they are used and regulated properly.
Methods and datasets for segmentation of minimally invasive surgical instruments in endoscopic images and videos: A review of the state of the art
Apr 25, 2023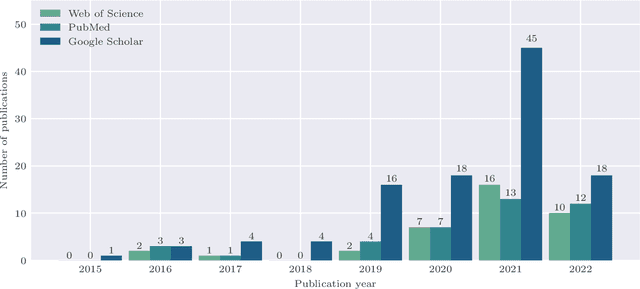
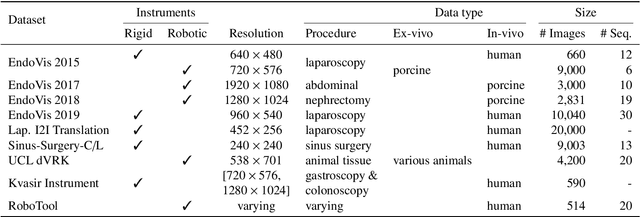
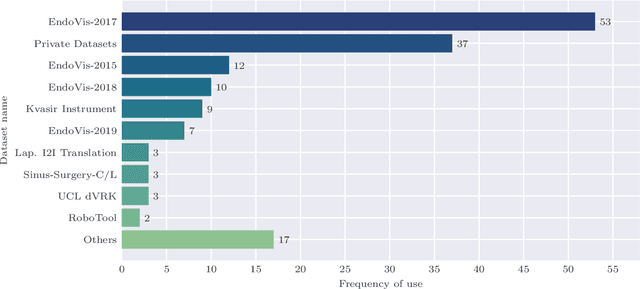
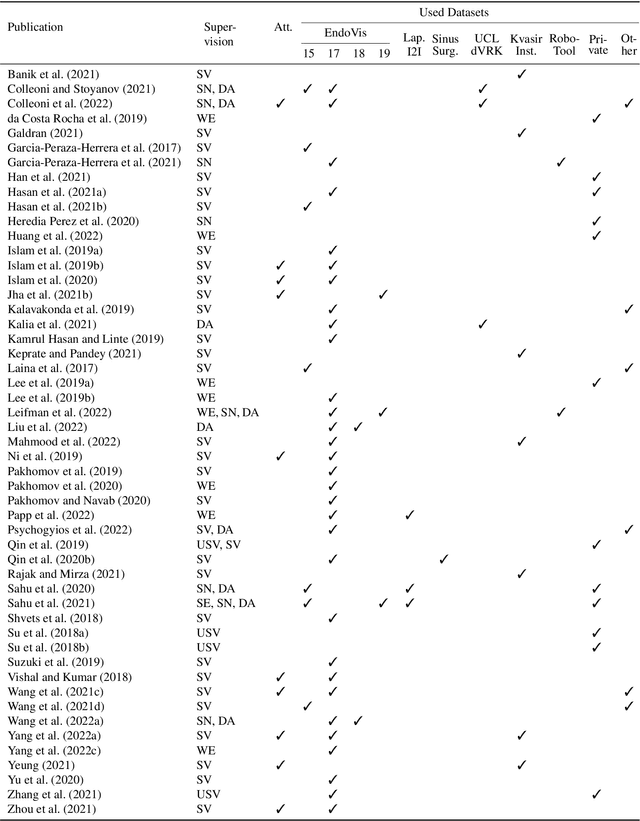
In the field of computer- and robot-assisted minimally invasive surgery, enormous progress has been made in recent years based on the recognition of surgical instruments in endoscopic images. Especially the determination of the position and type of the instruments is of great interest here. Current work involves both spatial and temporal information with the idea, that the prediction of movement of surgical tools over time may improve the quality of final segmentations. The provision of publicly available datasets has recently encouraged the development of new methods, mainly based on deep learning. In this review, we identify datasets used for method development and evaluation, as well as quantify their frequency of use in the literature. We further present an overview of the current state of research regarding the segmentation and tracking of minimally invasive surgical instruments in endoscopic images. The paper focuses on methods that work purely visually without attached markers of any kind on the instruments, taking into account both single-frame segmentation approaches as well as those involving temporal information. A discussion of the reviewed literature is provided, highlighting existing shortcomings and emphasizing available potential for future developments. The publications considered were identified through the platforms Google Scholar, Web of Science, and PubMed. The search terms used were "instrument segmentation", "instrument tracking", "surgical tool segmentation", and "surgical tool tracking" and result in 408 articles published between 2015 and 2022 from which 109 were included using systematic selection criteria.
Communication-Constrained Bandits under Additive Gaussian Noise
Apr 25, 2023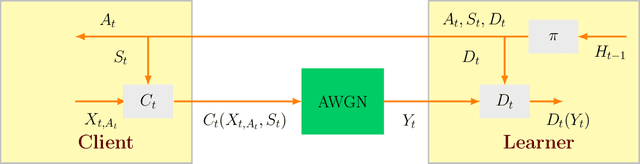
We study a distributed stochastic multi-armed bandit where a client supplies the learner with communication-constrained feedback based on the rewards for the corresponding arm pulls. In our setup, the client must encode the rewards such that the second moment of the encoded rewards is no more than $P$, and this encoded reward is further corrupted by additive Gaussian noise of variance $\sigma^2$; the learner only has access to this corrupted reward. For this setting, we derive an information-theoretic lower bound of $\Omega\left(\sqrt{\frac{KT}{\mathtt{SNR} \wedge1}} \right)$ on the minimax regret of any scheme, where $ \mathtt{SNR} := \frac{P}{\sigma^2}$, and $K$ and $T$ are the number of arms and time horizon, respectively. Furthermore, we propose a multi-phase bandit algorithm, $\mathtt{UE\text{-}UCB++}$, which matches this lower bound to a minor additive factor. $\mathtt{UE\text{-}UCB++}$ performs uniform exploration in its initial phases and then utilizes the {\em upper confidence bound }(UCB) bandit algorithm in its final phase. An interesting feature of $\mathtt{UE\text{-}UCB++}$ is that the coarser estimates of the mean rewards formed during a uniform exploration phase help to refine the encoding protocol in the next phase, leading to more accurate mean estimates of the rewards in the subsequent phase. This positive reinforcement cycle is critical to reducing the number of uniform exploration rounds and closely matching our lower bound.