 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evolution of linkages for prototyping of linkage based robots
May 02, 2023
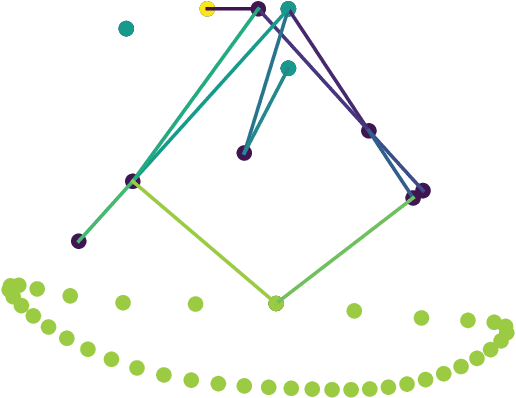

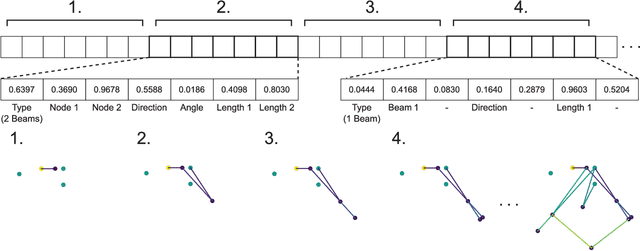
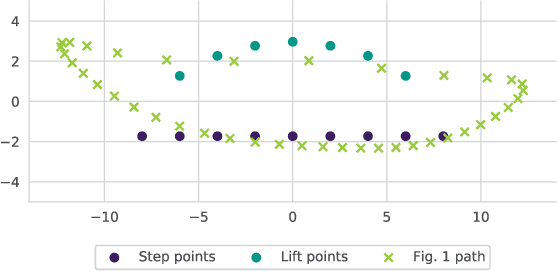
Prototyping robotic systems is a time consuming process. Computer aided design, however, might speed up the process significantly. Quality-diversity evolutionary approaches optimise for novelty as well as performance, and can be used to generate a repertoire of diverse designs. This design repertoire could be used as a tool to guide a designer and kick-start the rapid prototyping process. This paper explores this idea in the context of mechanical linkage based robots. These robots can be a good test-bed for rapid prototyping, as they can be modified quickly for swift iterations in design. We compare three evolutionary algorithms for optimising 2D mechanical linkages: 1) a standard evolutionary algorithm, 2) the multi-objective algorithm NSGA-II, and 3) the quality-diversity algorithm MAP-Elites. Some of the found linkages are then realized on a physical hexapod robot through a prototyping process, and tested on two different floors. We find that all the tested approaches, except the standard evolutionary algorithm, are capable of finding mechanical linkages that creates a path similar to a specified desired path. However, the quality-diversity approaches that had the length of the linkage as a behaviour descriptor were the most useful when prototyping. This was due to the quality-diversity approaches having a larger variety of similar designs to choose from, and because the search could be constrained by the behaviour descriptors to make linkages that were viable for construction on our hexapod platform.
Unbounded Differentially Private Quantile and Maximum Estimation
May 02, 2023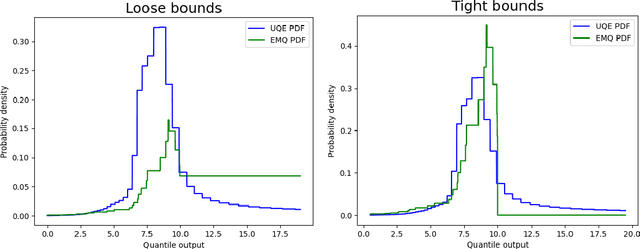
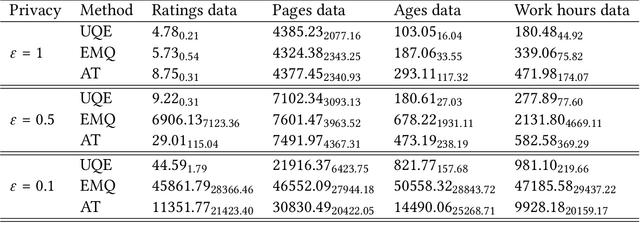
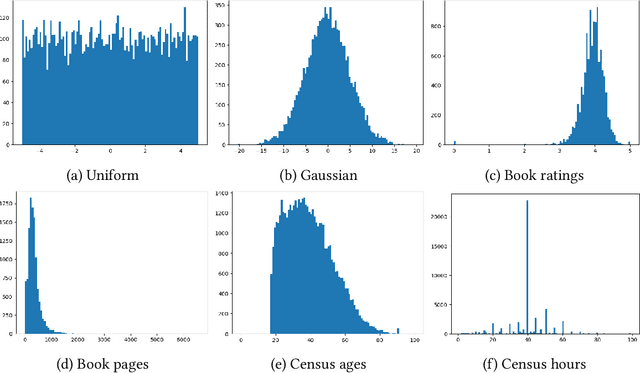
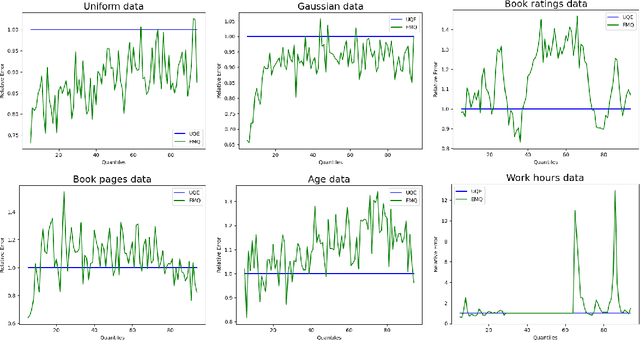
In this work we consider the problem of differentially private computation of quantiles for the data, especially the highest quantiles such as maximum, but with an unbounded range for the dataset. We show that this can be done efficiently through a simple invocation of $\texttt{AboveThreshold}$, a subroutine that is iteratively called in the fundamental Sparse Vector Technique, even when there is no upper bound on the data. In particular, we show that this procedure can give more accurate and robust estimates on the highest quantiles with applications towards clipping that is essential for differentially private sum and mean estimation. In addition, we show how two invocations can handle the fully unbounded data setting. Within our study, we show that an improved analysis of $\texttt{AboveThreshold}$ can improve the privacy guarantees for the widely used Sparse Vector Technique that is of independent interest. We give a more general characterization of privacy loss for $\texttt{AboveThreshold}$ which we immediately apply to our method for improved privacy guarantees. Our algorithm only requires one $O(n)$ pass through the data, which can be unsorted, and each subsequent query takes $O(1)$ time. We empirically compare our unbounded algorithm with the state-of-the-art algorithms in the bounded setting. For inner quantiles, we find that our method often performs better on non-synthetic datasets. For the maximal quantiles, which we apply to differentially private sum computation, we find that our method performs significantly better.
Deep Learning-Based Multiband Signal Fusion for 3-D SAR Super-Resolution
May 03, 2023
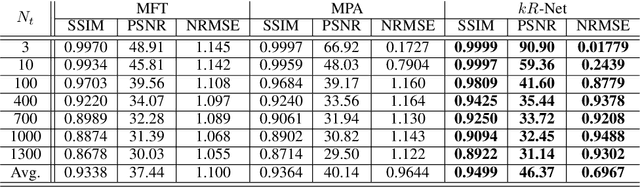
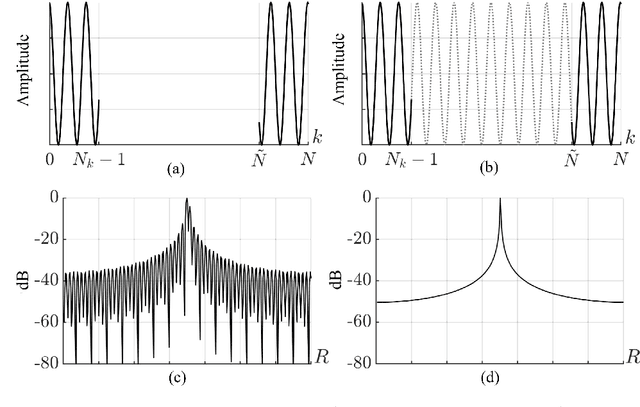
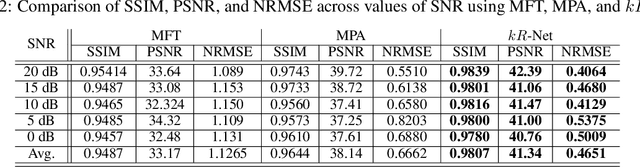
Three-dimensional (3-D) synthetic aperture radar (SAR) is widely used in many security and industrial applications requiring high-resolution imaging of concealed or occluded objects. The ability to resolve intricate 3-D targets is essential to the performance of such applications and depends directly on system bandwidth. However, because high-bandwidth systems face several prohibitive hurdles, an alternative solution is to operate multiple radars at distinct frequency bands and fuse the multiband signals. Current multiband signal fusion methods assume a simple target model and a small number of point reflectors, which is invalid for realistic security screening and industrial imaging scenarios wherein the target model effectively consists of a large number of reflectors. To the best of our knowledge, this study presents the first use of deep learning for multiband signal fusion. The proposed network, called kR-Net, employs a hybrid, dual-domain complex-valued convolutional neural network (CV-CNN) to fuse multiband signals and impute the missing samples in the frequency gaps between subbands. By exploiting the relationships in both the wavenumber domain and wavenumber spectral domain, the proposed framework overcomes the drawbacks of existing multiband imaging techniques for realistic scenarios at a fraction of the computation time of existing multiband fusion algorithms. Our method achieves high-resolution imaging of intricate targets previously impossible using conventional techniques and enables finer resolution capacity for concealed weapon detection and occluded object classification using multiband signaling without requiring more advanced hardware. Furthermore, a fully integrated multiband imaging system is developed using commercially available millimeter-wave (mmWave) radars for efficient multiband imaging.
Integrated 5G mmWave Positioning in Deep Urban Environments: Advantages and Challenges
May 03, 2023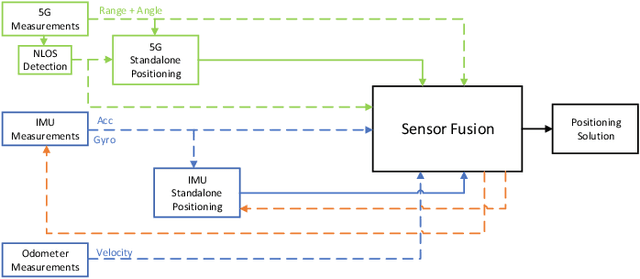
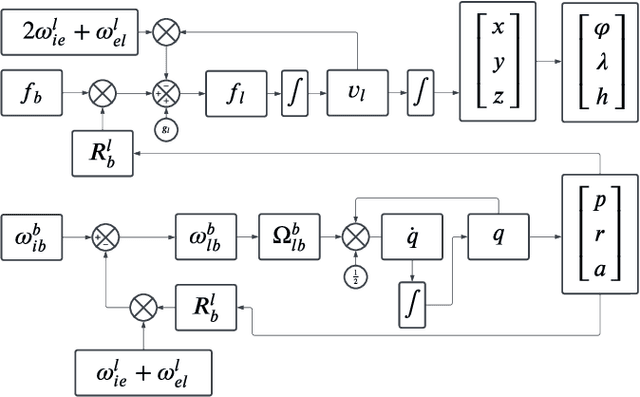

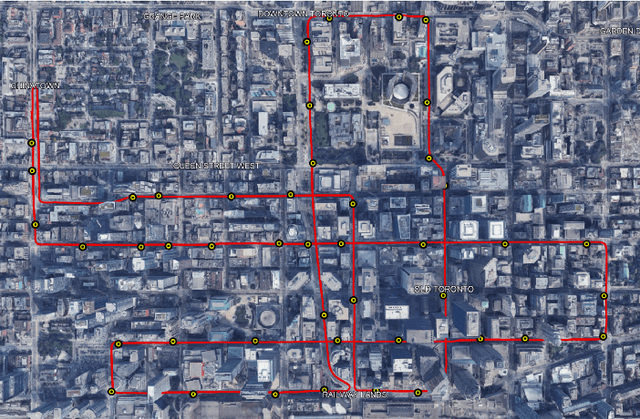
Achieving the highest levels of autonomy within autonomous vehicles (AVs) requires a precise and dependable positioning solution that is not influenced by the environment. 5G mmWave signals have been extensively studied in the literature to provide such a positioning solution. Yet, it is evident that 5G alone will not be able to provide uninterrupted positioning services, as outages are inevitable to occur. Towards that end, few works have explored the benefits of integrating mmWave positioning with onboard motion sensors (OBMS) like inertial measurement units (IMUs) and odometers. Inspired by INS-GNSS integration literature, all methods defaulted to a tightly-coupled (TC) integration scheme, which hinders the potential of such an integration. Additionally, the proposed methods were validated using simulated 5G and INS data with probability-based line-of-sight (LOS) assumptions. Such an experimental setup fails to highlight the true advantages and challenges of 5G-OBMS integration. Therefore, this study first explores a loosely-coupled (LC) 5G-OBMS integration scheme as a viable alternative to TC schemes. Next, it examines the merits and challenges of such an integration in a deep-urban setting using a novel quasi-real simulation setup. The setup comprises quasi-real 5G measurements from the Siradel simulator and real commercial-grade IMU measurements from a challenging one-hour-long trajectory in downtown Toronto. The trajectory featured multiple natural 5G outages which helped with assessing the integration's performance. The proposed LC method achieved a 14-cm level of accuracy for 95% of the time, while significantly limiting positioning errors during natural 5G outages.
The Impact of Asynchrony on Parallel Model-Based EAs
Mar 27, 2023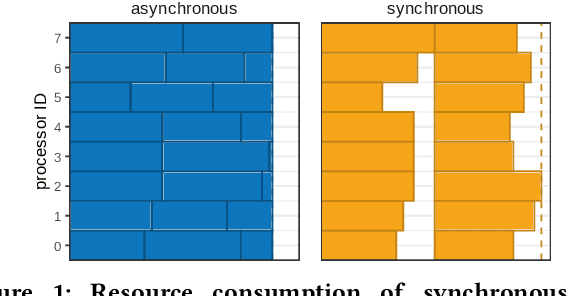
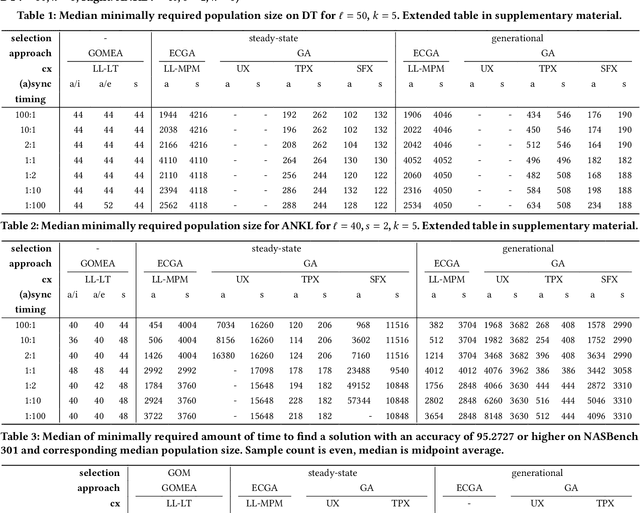
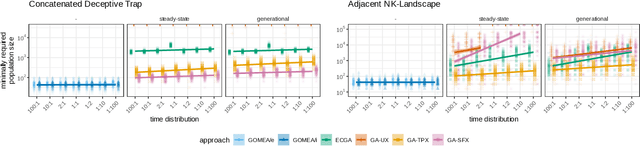

In a parallel EA one can strictly adhere to the generational clock, and wait for all evaluations in a generation to be done. However, this idle time limits the throughput of the algorithm and wastes computational resources. Alternatively, an EA can be made asynchronous parallel. However, EAs using classic recombination and selection operators (GAs) are known to suffer from an evaluation time bias, which also influences the performance of the approach. Model-Based Evolutionary Algorithms (MBEAs) are more scalable than classic GAs by virtue of capturing the structure of a problem in a model. If this model is learned through linkage learning based on the population, the learned model may also capture biases. Thus, if an asynchronous parallel MBEA is also affected by an evaluation time bias, this could result in learned models to be less suited to solving the problem, reducing performance. Therefore, in this work, we study the impact and presence of evaluation time biases on MBEAs in an asynchronous parallelization setting, and compare this to the biases in GAs. We find that a modern MBEA, GOMEA, is unaffected by evaluation time biases, while the more classical MBEA, ECGA, is affected, much like GAs are.
Computational Performance Aware Benchmarking of Unsupervised Concept Drift Detection
Apr 17, 2023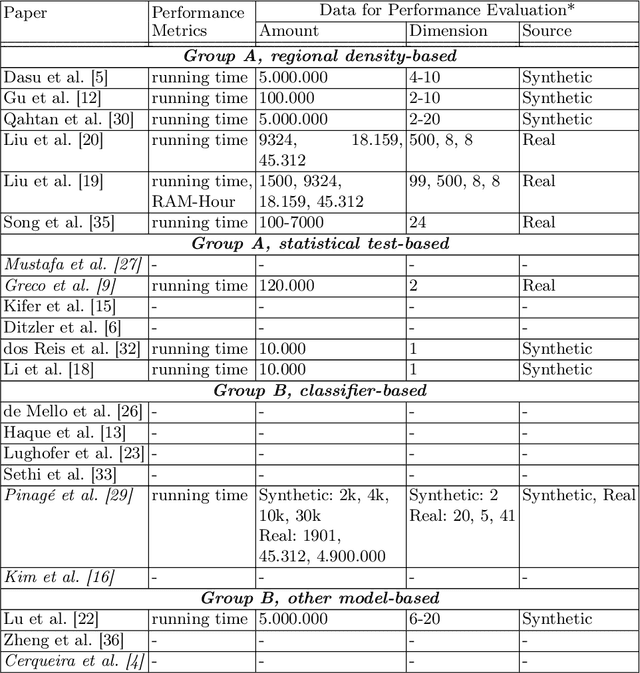
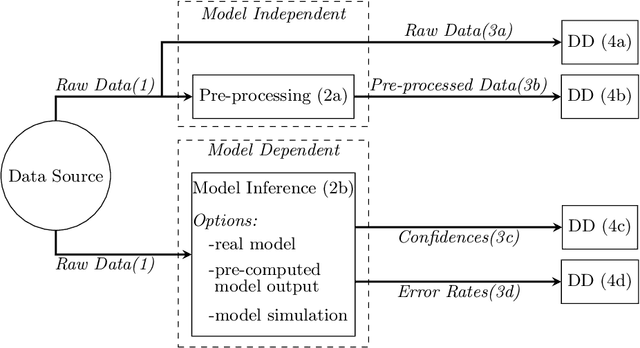
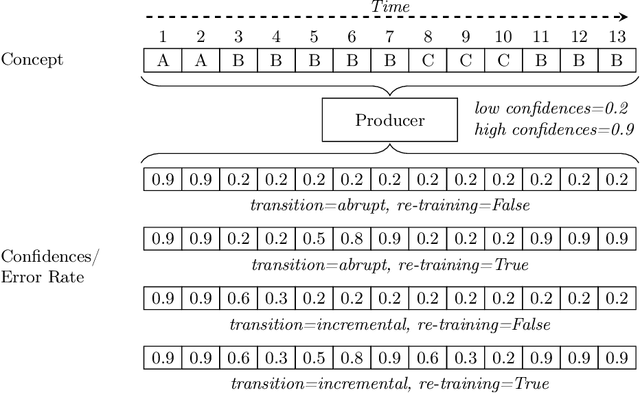
For many AI systems, concept drift detection is crucial to ensure the systems reliability. These systems often have to deal with large amounts of data or react in real time. Thus, drift detectors must meet computational requirements or constraints with a comprehensive performance evaluation. However, so far, the focus of developing drift detectors is on detection quality, e.g.~accuracy, but not on computational performance, such as running time. We show that the previous works consider computational performance only as a secondary objective and do not have a benchmark for such evaluation. Hence, we propose a novel benchmark suite for drift detectors that accounts both detection quality and computational performance to ensure a detector's applicability in various AI systems. In this work, we focus on unsupervised drift detectors that are not restricted to the availability of labeled data and thus being widely applicable. Our benchmark suite supports configurable synthetic and real world data streams. Moreover, it provides means for simulating a machine learning model's output to unify the performance evaluation across different drift detectors. This allows a fair and comprehensive comparison of drift detectors proposed in related work. Our benchmark suite is integrated in the existing framework, Massive Online Analysis (MOA). To evaluate our benchmark suite's capability, we integrate two representative unsupervised drift detectors. Our work enables the scientific community to achieve a baseline for unsupervised drift detectors with respect to both detection quality and computational performance.
BO-ICP: Initialization of Iterative Closest Point Based on Bayesian Optimization
Apr 25, 2023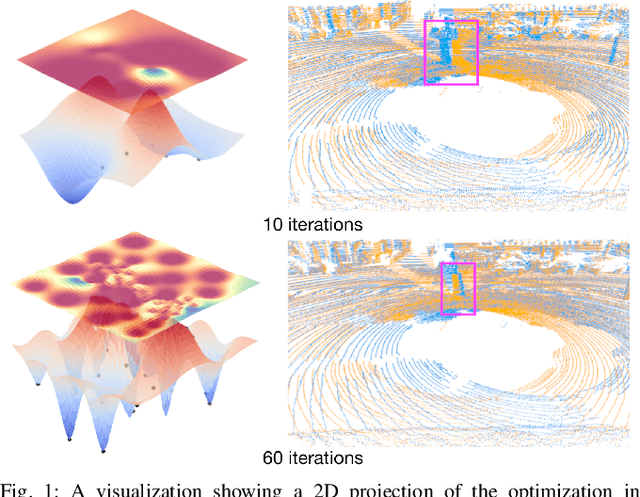


Typical algorithms for point cloud registration such as Iterative Closest Point (ICP) require a favorable initial transform estimate between two point clouds in order to perform a successful registration. State-of-the-art methods for choosing this starting condition rely on stochastic sampling or global optimization techniques such as branch and bound. In this work, we present a new method based on Bayesian optimization for finding the critical initial ICP transform. We provide three different configurations for our method which highlights the versatility of the algorithm to both find rapid results and refine them in situations where more runtime is available such as offline map building. Experiments are run on popular data sets and we show that our approach outperforms state-of-the-art methods when given similar computation time. Furthermore, it is compatible with other improvements to ICP, as it focuses solely on the selection of an initial transform, a starting point for all ICP-based methods.
Exact recovery for the non-uniform Hypergraph Stochastic Block Model
Apr 25, 2023
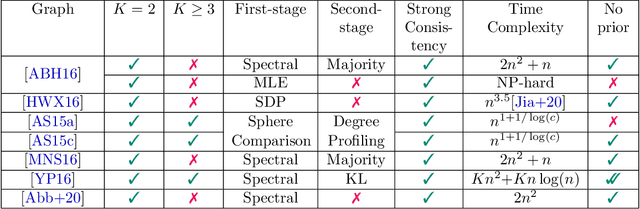
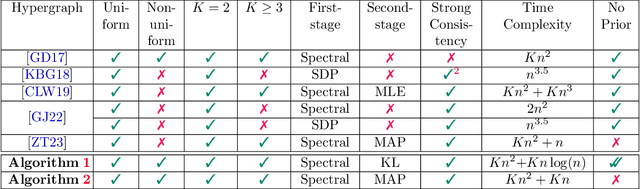
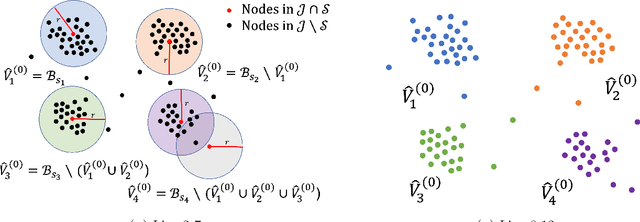
Consider the community detection problem in random hypergraphs under the non-uniform hypergraph stochastic block model (HSBM), where each hyperedge appears independently with some given probability depending only on the labels of its vertices. We establish, for the first time in the literature, a sharp threshold for exact recovery under this non-uniform case, subject to minor constraints; in particular, we consider the model with $K$ classes as well as the symmetric binary model ($K=2$). One crucial point here is that by aggregating information from all the uniform layers, we may obtain exact recovery even in cases when this may appear impossible if each layer were considered alone. Two efficient algorithms that successfully achieve exact recovery above the threshold are provided. The theoretical analysis of our algorithms relies on the concentration and regularization of the adjacency matrix for non-uniform random hypergraphs, which could be of independent interest. We also address some open problems regarding parameter knowledge and estimation.
User-Centric Federated Learning: Trading off Wireless Resources for Personalization
Apr 25, 2023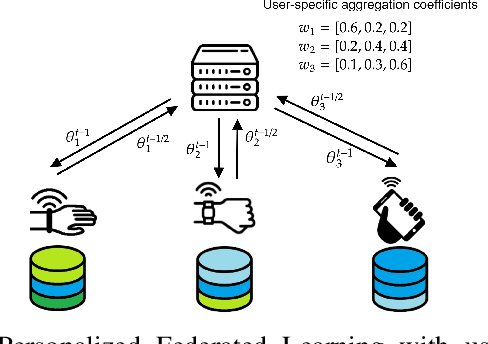
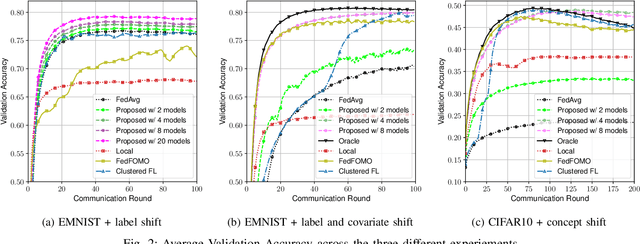
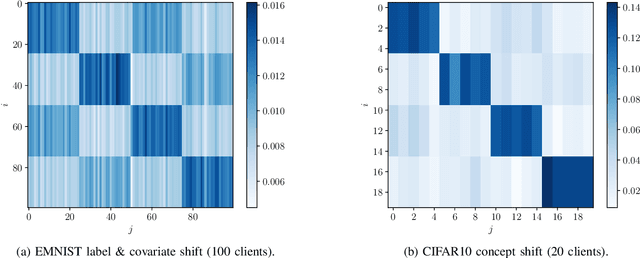
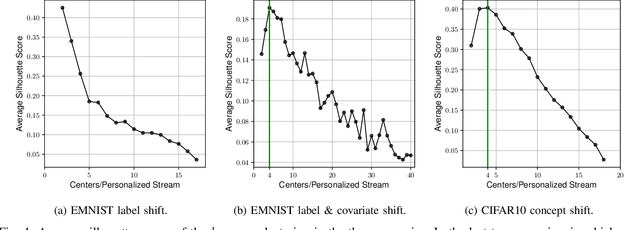
Statistical heterogeneity across clients in a Federated Learning (FL) system increases the algorithm convergence time and reduces the generalization performance, resulting in a large communication overhead in return for a poor model. To tackle the above problems without violating the privacy constraints that FL imposes, personalized FL methods have to couple statistically similar clients without directly accessing their data in order to guarantee a privacy-preserving transfer. In this work, we design user-centric aggregation rules at the parameter server (PS) that are based on readily available gradient information and are capable of producing personalized models for each FL client. The proposed aggregation rules are inspired by an upper bound of the weighted aggregate empirical risk minimizer. Secondly, we derive a communication-efficient variant based on user clustering which greatly enhances its applicability to communication-constrained systems. Our algorithm outperforms popular personalized FL baselines in terms of average accuracy, worst node performance, and training communication overhead.
Deep Learning Framework for the Design of Orbital Angular Momentum Generators Enabled by Leaky-wave Holograms
Apr 25, 2023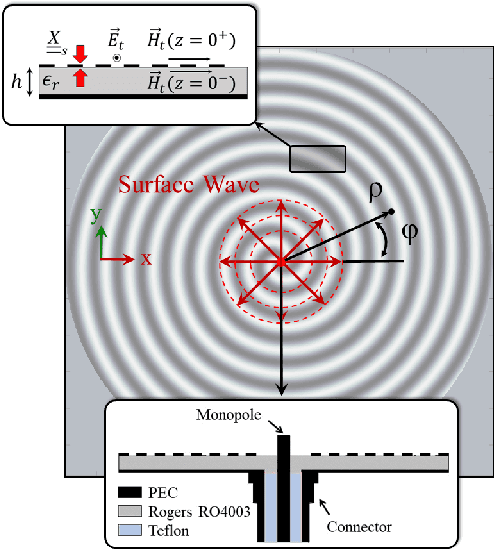
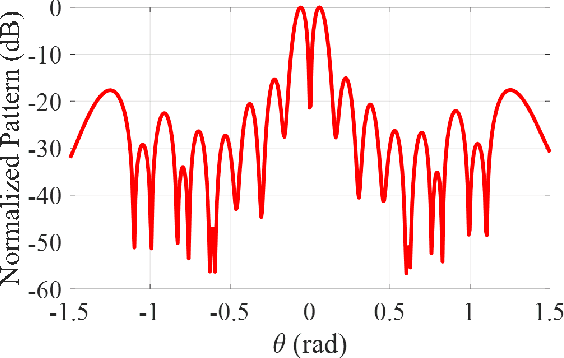
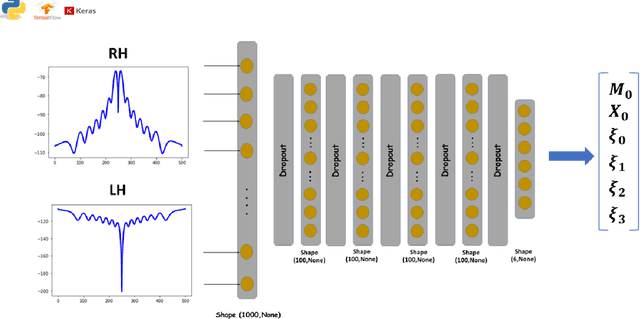
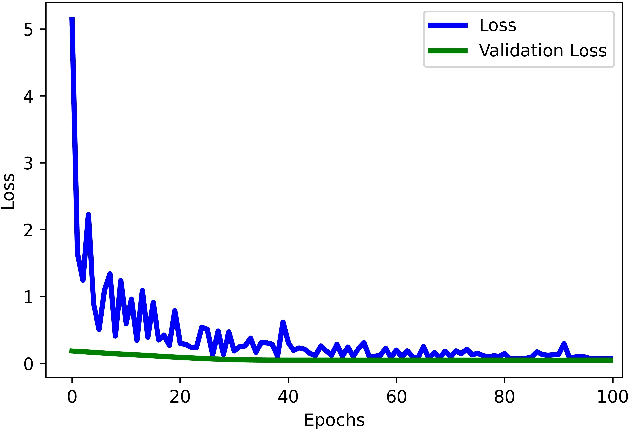
In this paper, we present a novel approach for the design of leaky-wave holographic antennas that generates OAM-carrying electromagnetic waves by combining Flat Optics (FO) and machine learning (ML) techniques. To improve the performance of our system, we use a machine learning technique to discover a mathematical function that can effectively control the entire radiation pattern, i.e., decrease the side lobe level (SLL) while simultaneously increasing the central null depth of the radiation pattern. Precise tuning of the parameters of the impedance equation based on holographic theory is necessary to achieve optimal results in a variety of scenarios. In this research, we applied machine learning to determine the approximate values of the parameters. We can determine the optimal values for each parameter, resulting in the desired radiation pattern, using a total of 77,000 generated datasets. Furthermore, the use of ML not only saves time, but also yields more precise and accurate results than manual parameter tuning and conventional optimization methods.