 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Standardized Benchmark Dataset for Localized Exposure to a Realistic Source at 10$-$90 GHz
May 03, 2023
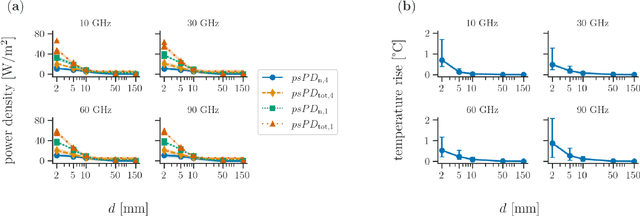
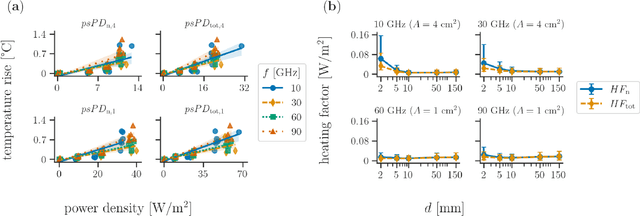
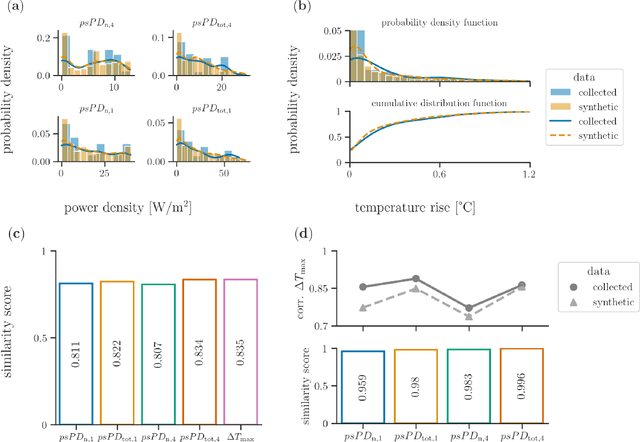
The lack of freely available standardized datasets represents an aggravating factor during the development and testing the performance of novel computational techniques in exposure assessment and dosimetry research. This hinders progress as researchers are required to generate numerical data (field, power and temperature distribution) anew using simulation software for each exposure scenario. Other than being time consuming, this approach is highly susceptible to errors that occur during the configuration of the electromagnetic model. To address this issue, in this paper, the limited available data on the incident power density and resultant maximum temperature rise on the skin surface considering various steady-state exposure scenarios at 10$-$90 GHz have been statistically modeled. The synthetic data have been sampled from the fitted statistical multivariate distribution with respect to predetermined dosimetric constraints. We thus present a comprehensive and open-source dataset compiled of the high-fidelity numerical data considering various exposures to a realistic source. Furthermore, different surrogate models for predicting maximum temperature rise on the skin surface were fitted based on the synthetic dataset. All surrogate models were tested on the originally available data where satisfactory predictive performance has been demonstrated. A simple technique of combining quadratic polynomial and tensor-product spline surrogates, each operating on its own cluster of data, has achieved the lowest mean absolute error of 0.058 {\deg}C. Therefore, overall experimental results indicate the validity of the proposed synthetic dataset.
Autonomous search of real-life environments combining dynamical system-based path planning and unsupervised learning
May 03, 2023In recent years, advancements have been made towards the goal of using chaotic coverage path planners for autonomous search and traversal of spaces with limited environmental cues. However, the state of this field is still in its infancy as there has been little experimental work done. Current experimental work has not developed robust methods to satisfactorily address the immediate set of problems a chaotic coverage path planner needs to overcome in order to scan realistic environments within reasonable coverage times. These immediate problems are as follows: (1) an obstacle avoidance technique which generally maintains the kinematic efficiency of the robot's motion, (2) a means to spread chaotic trajectories across the environment (especially crucial for large and/or complex-shaped environments) that need to be covered, and (3) a real-time coverage calculation technique that is accurate and independent of cell size. This paper aims to progress the field by proposing algorithms that address all of these problems by providing techniques for obstacle avoidance, chaotic trajectory dispersal, and accurate coverage calculation. The algorithms produce generally smooth chaotic trajectories and provide high scanning coverage of environments. These algorithms were created within the ROS framework and make up a newly developed chaotic path planning application. The performance of this application was comparable to that of a conventional optimal path planner. The performance tests were carried out in environments of various sizes, shapes, and obstacle densities, both in real-life and Gazebo simulations.
Modeling Nonlinear Dynamics in Continuous Time with Inductive Biases on Decay Rates and/or Frequencies
Dec 26, 2022
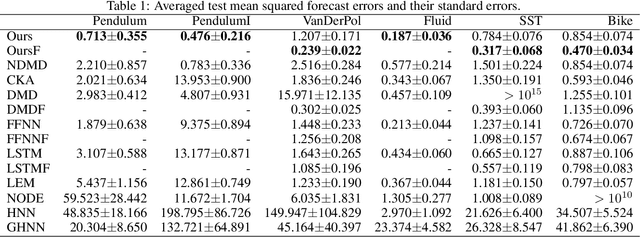
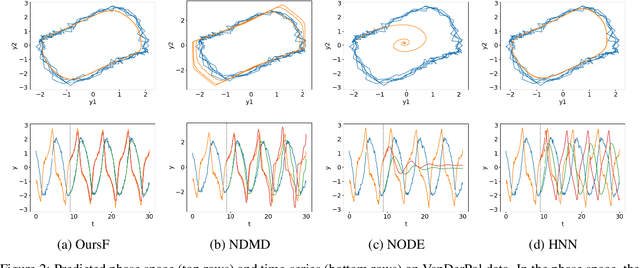

We propose a neural network-based model for nonlinear dynamics in continuous time that can impose inductive biases on decay rates and/or frequencies. Inductive biases are helpful for training neural networks especially when training data are small. The proposed model is based on the Koopman operator theory, where the decay rate and frequency information is used by restricting the eigenvalues of the Koopman operator that describe linear evolution in a Koopman space. We use neural networks to find an appropriate Koopman space, which are trained by minimizing multi-step forecasting and backcasting errors using irregularly sampled time-series data. Experiments on various time-series datasets demonstrate that the proposed method achieves higher forecasting performance given a single short training sequence than the existing methods.
Unsupervised anomaly localization in high-resolution breast scans using deep pluralistic image completion
May 04, 2023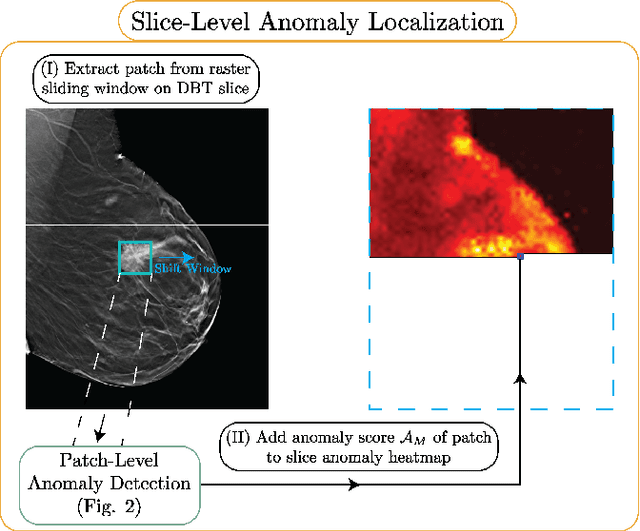

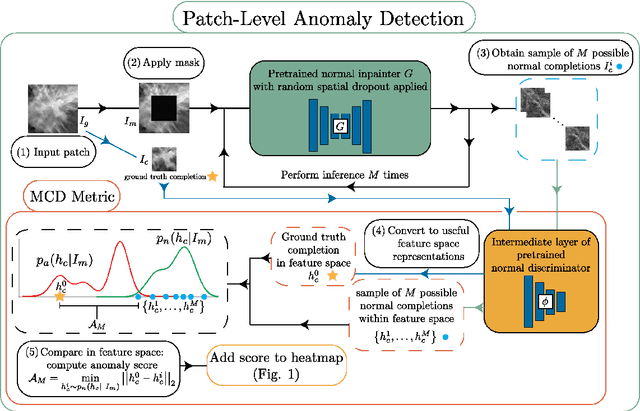
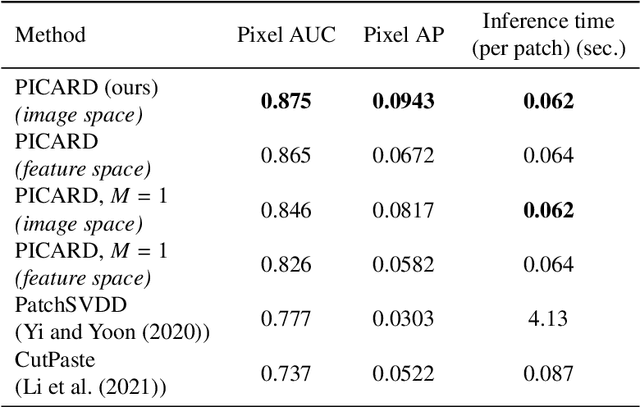
Automated tumor detection in Digital Breast Tomosynthesis (DBT) is a difficult task due to natural tumor rarity, breast tissue variability, and high resolution. Given the scarcity of abnormal images and the abundance of normal images for this problem, an anomaly detection/localization approach could be well-suited. However, most anomaly localization research in machine learning focuses on non-medical datasets, and we find that these methods fall short when adapted to medical imaging datasets. The problem is alleviated when we solve the task from the image completion perspective, in which the presence of anomalies can be indicated by a discrepancy between the original appearance and its auto-completion conditioned on the surroundings. However, there are often many valid normal completions given the same surroundings, especially in the DBT dataset, making this evaluation criterion less precise. To address such an issue, we consider pluralistic image completion by exploring the distribution of possible completions instead of generating fixed predictions. This is achieved through our novel application of spatial dropout on the completion network during inference time only, which requires no additional training cost and is effective at generating diverse completions. We further propose minimum completion distance (MCD), a new metric for detecting anomalies, thanks to these stochastic completions. We provide theoretical as well as empirical support for the superiority over existing methods of using the proposed method for anomaly localization. On the DBT dataset, our model outperforms other state-of-the-art methods by at least 10\% AUROC for pixel-level detection.
W-MAE: Pre-trained weather model with masked autoencoder for multi-variable weather forecasting
Apr 18, 2023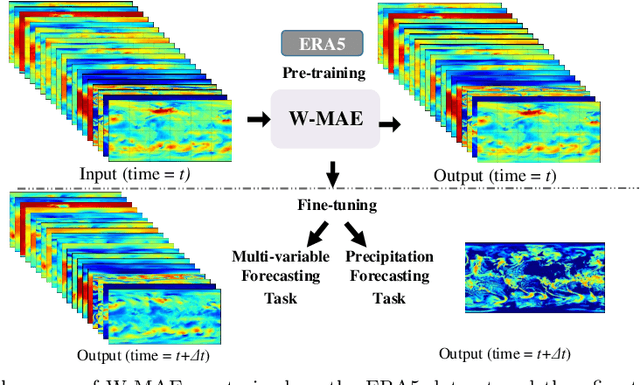
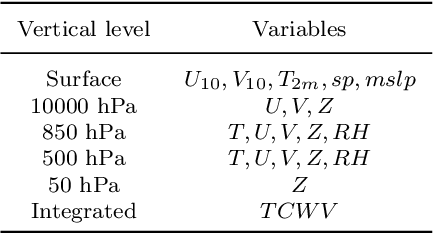
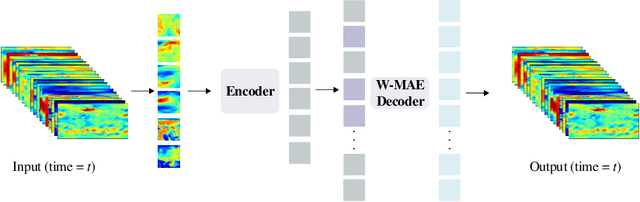
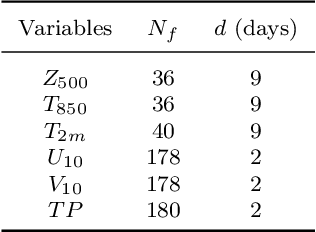
Weather forecasting is a long-standing computational challenge with direct societal and economic impacts. This task involves a large amount of continuous data collection and exhibits rich spatiotemporal dependencies over long periods, making it highly suitable for deep learning models. In this paper, we apply pre-training techniques to weather forecasting and propose W-MAE, a Weather model with Masked AutoEncoder pre-training for multi-variable weather forecasting. W-MAE is pre-trained in a self-supervised manner to reconstruct spatial correlations within meteorological variables. On the temporal scale, we fine-tune the pre-trained W-MAE to predict the future states of meteorological variables, thereby modeling the temporal dependencies present in weather data. We pre-train W-MAE using the fifth-generation ECMWF Reanalysis (ERA5) data, with samples selected every six hours and using only two years of data. Under the same training data conditions, we compare W-MAE with FourCastNet, and W-MAE outperforms FourCastNet in precipitation forecasting. In the setting where the training data is far less than that of FourCastNet, our model still performs much better in precipitation prediction (0.80 vs. 0.98). Additionally, experiments show that our model has a stable and significant advantage in short-to-medium-range forecasting (i.e., forecasting time ranges from 6 hours to one week), and the longer the prediction time, the more evident the performance advantage of W-MAE, further proving its robustness.
ScatterFormer: Locally-Invariant Scattering Transformer for Patient-Independent Multispectral Detection of Epileptiform Discharges
Apr 26, 2023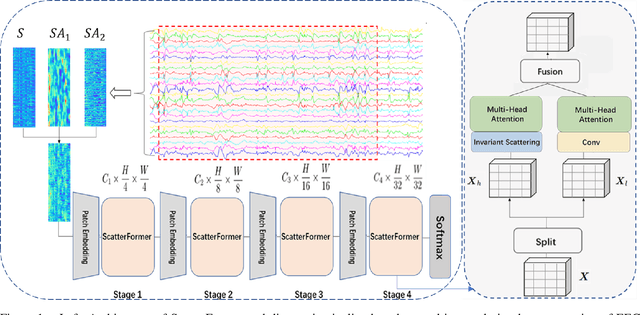
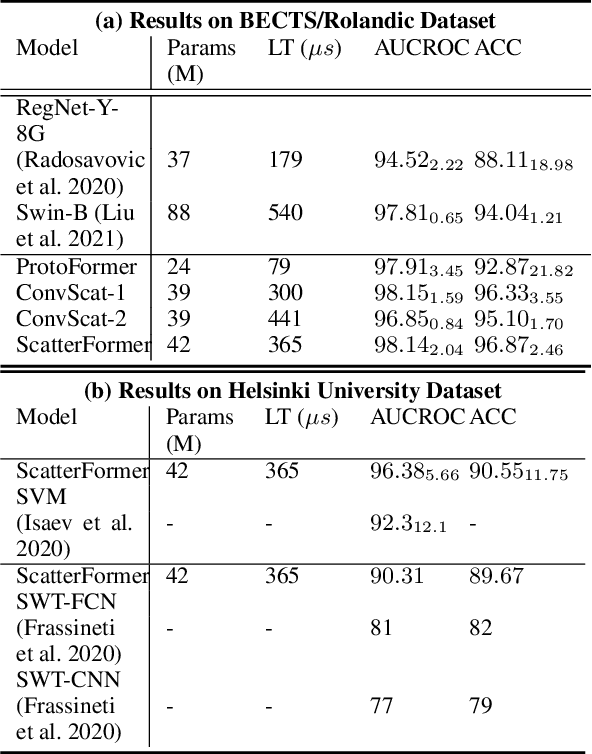
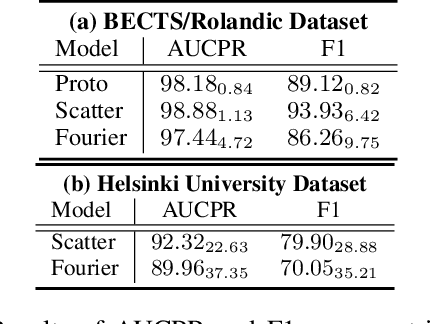
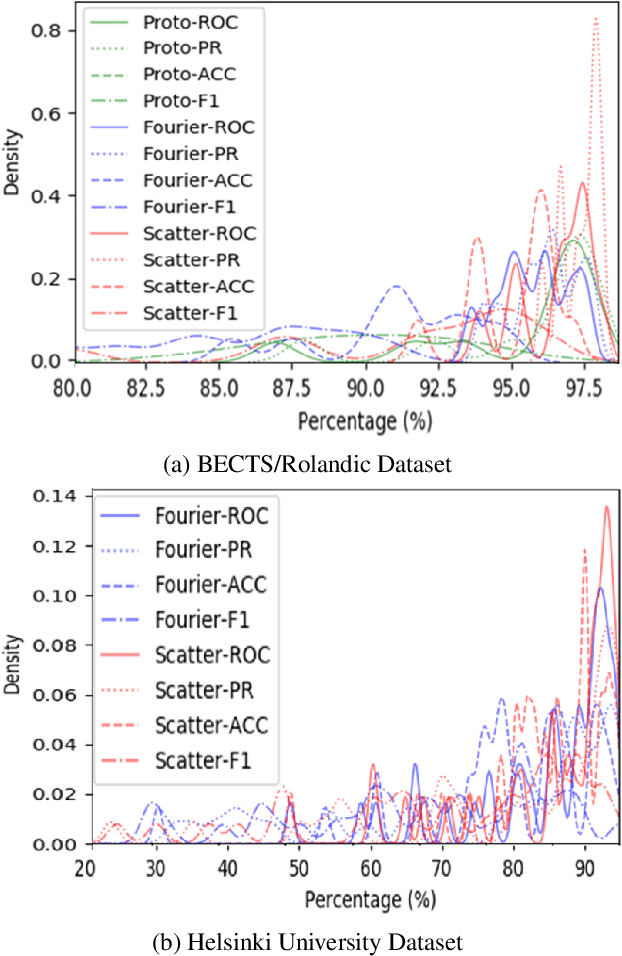
Patient-independent detection of epileptic activities based on visual spectral representation of continuous EEG (cEEG) has been widely used for diagnosing epilepsy. However, precise detection remains a considerable challenge due to subtle variabilities across subjects, channels and time points. Thus, capturing fine-grained, discriminative features of EEG patterns, which is associated with high-frequency textural information, is yet to be resolved. In this work, we propose Scattering Transformer (ScatterFormer), an invariant scattering transform-based hierarchical Transformer that specifically pays attention to subtle features. In particular, the disentangled frequency-aware attention (FAA) enables the Transformer to capture clinically informative high-frequency components, offering a novel clinical explainability based on visual encoding of multichannel EEG signals. Evaluations on two distinct tasks of epileptiform detection demonstrate the effectiveness our method. Our proposed model achieves median AUCROC and accuracy of 98.14%, 96.39% in patients with Rolandic epilepsy. On a neonatal seizure detection benchmark, it outperforms the state-of-the-art by 9% in terms of average AUCROC.
* 11 pages
Data-driven Piecewise Affine Decision Rules for Stochastic Programming with Covariate Information
Apr 26, 2023
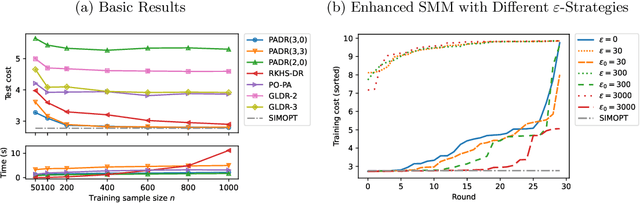

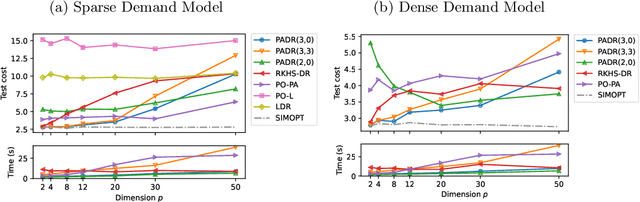
Focusing on stochastic programming (SP) with covariate information, this paper proposes an empirical risk minimization (ERM) method embedded within a nonconvex piecewise affine decision rule (PADR), which aims to learn the direct mapping from features to optimal decisions. We establish the nonasymptotic consistency result of our PADR-based ERM model for unconstrained problems and asymptotic consistency result for constrained ones. To solve the nonconvex and nondifferentiable ERM problem, we develop an enhanced stochastic majorization-minimization algorithm and establish the asymptotic convergence to (composite strong) directional stationarity along with complexity analysis. We show that the proposed PADR-based ERM method applies to a broad class of nonconvex SP problems with theoretical consistency guarantees and computational tractability. Our numerical study demonstrates the superior performance of PADR-based ERM methods compared to state-of-the-art approaches under various settings, with significantly lower costs, less computation time, and robustness to feature dimensions and nonlinearity of the underlying dependency.
FLEX: an Adaptive Exploration Algorithm for Nonlinear Systems
Apr 26, 2023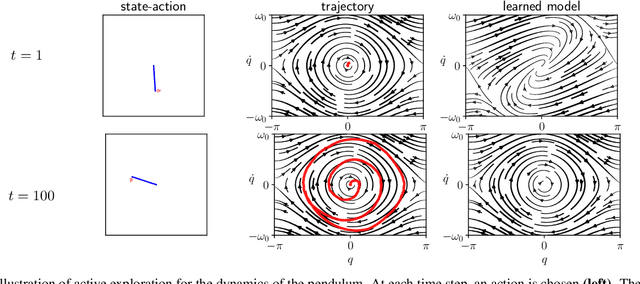
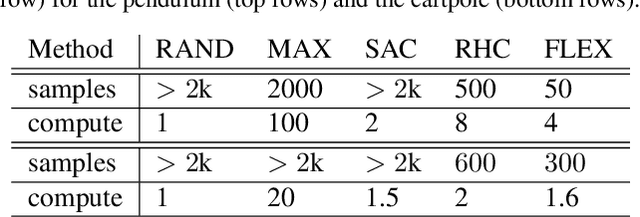
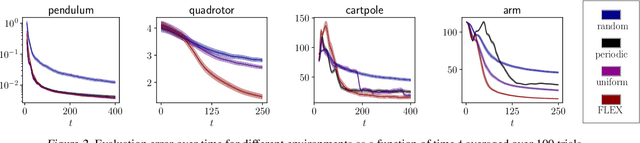
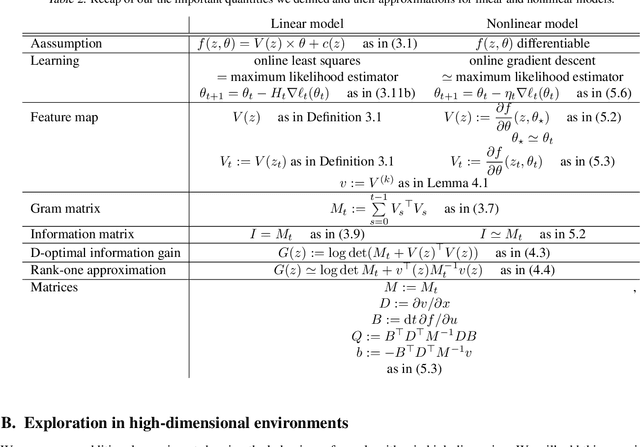
Model-based reinforcement learning is a powerful tool, but collecting data to fit an accurate model of the system can be costly. Exploring an unknown environment in a sample-efficient manner is hence of great importance. However, the complexity of dynamics and the computational limitations of real systems make this task challenging. In this work, we introduce FLEX, an exploration algorithm for nonlinear dynamics based on optimal experimental design. Our policy maximizes the information of the next step and results in an adaptive exploration algorithm, compatible with generic parametric learning models and requiring minimal resources. We test our method on a number of nonlinear environments covering different settings, including time-varying dynamics. Keeping in mind that exploration is intended to serve an exploitation objective, we also test our algorithm on downstream model-based classical control tasks and compare it to other state-of-the-art model-based and model-free approaches. The performance achieved by FLEX is competitive and its computational cost is low.
Membrane Potential Distribution Adjustment and Parametric Surrogate Gradient in Spiking Neural Networks
Apr 26, 2023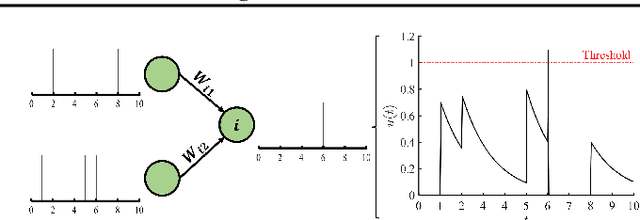
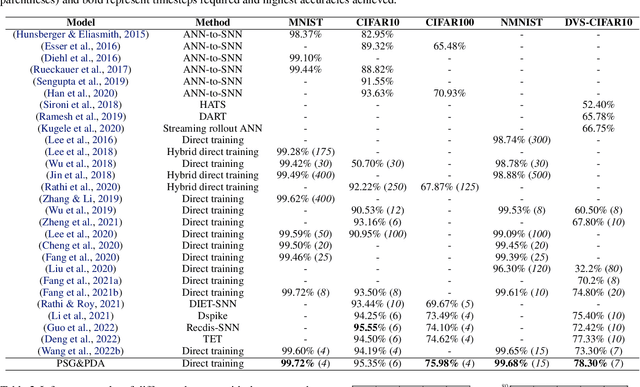

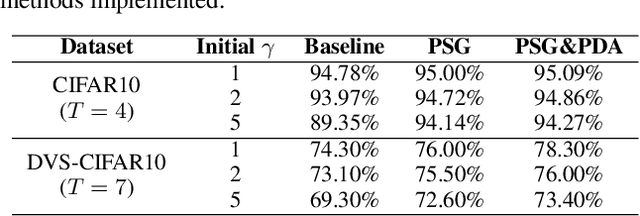
As an emerging network model, spiking neural networks (SNNs) have aroused significant research attentions in recent years. However, the energy-efficient binary spikes do not augur well with gradient descent-based training approaches. Surrogate gradient (SG) strategy is investigated and applied to circumvent this issue and train SNNs from scratch. Due to the lack of well-recognized SG selection rule, most SGs are chosen intuitively. We propose the parametric surrogate gradient (PSG) method to iteratively update SG and eventually determine an optimal surrogate gradient parameter, which calibrates the shape of candidate SGs. In SNNs, neural potential distribution tends to deviate unpredictably due to quantization error. We evaluate such potential shift and propose methodology for potential distribution adjustment (PDA) to minimize the loss of undesired pre-activations. Experimental results demonstrate that the proposed methods can be readily integrated with backpropagation through time (BPTT) algorithm and help modulated SNNs to achieve state-of-the-art performance on both static and dynamic dataset with fewer timesteps.
A Deep Learning Framework for Verilog Autocompletion Towards Design and Verification Automation
Apr 26, 2023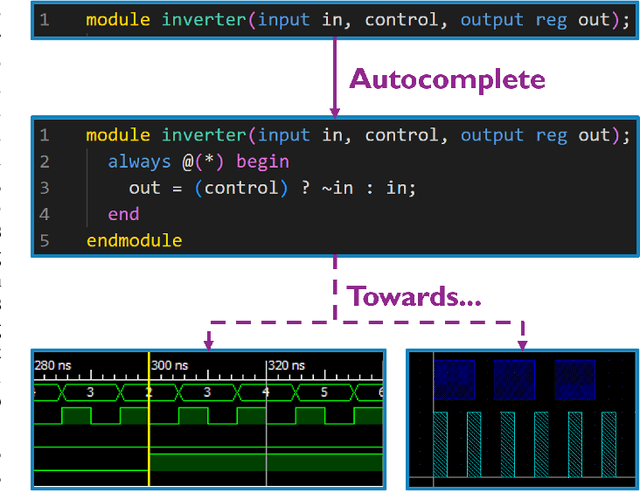

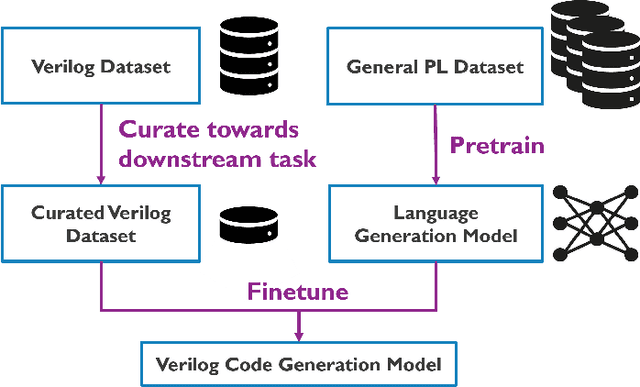
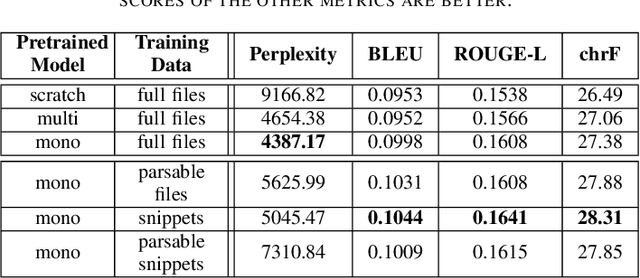
Innovative Electronic Design Automation (EDA) solutions are important to meet the design requirements for increasingly complex electronic devices. Verilog, a hardware description language, is widely used for the design and verification of digital circuits and is synthesized using specific EDA tools. However, writing code is a repetitive and time-intensive task. This paper proposes, primarily, a novel deep learning framework for training a Verilog autocompletion model and, secondarily, a Verilog dataset of files and snippets obtained from open-source repositories. The framework involves integrating models pretrained on general programming language data and finetuning them on a dataset curated to be similar to a target downstream task. This is validated by comparing different pretrained models trained on different subsets of the proposed Verilog dataset using multiple evaluation metrics. These experiments demonstrate that the proposed framework achieves better BLEU, ROUGE-L, and chrF scores by 9.5%, 6.7%, and 6.9%, respectively, compared to a model trained from scratch.