 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Shot Optimization in Quantum Machine Learning Architectures to Accelerate Training
Apr 27, 2023
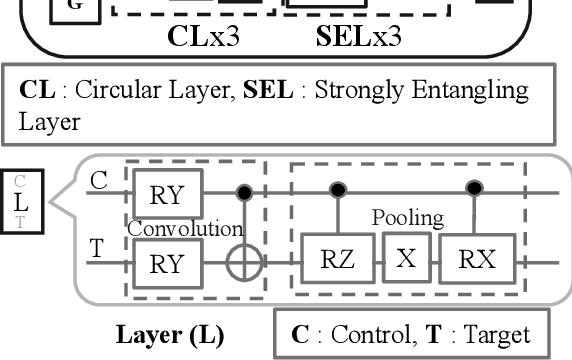
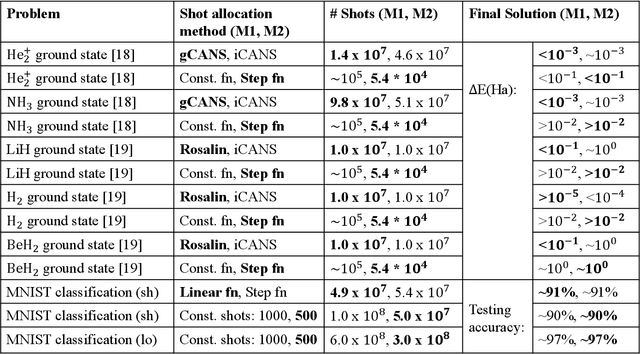
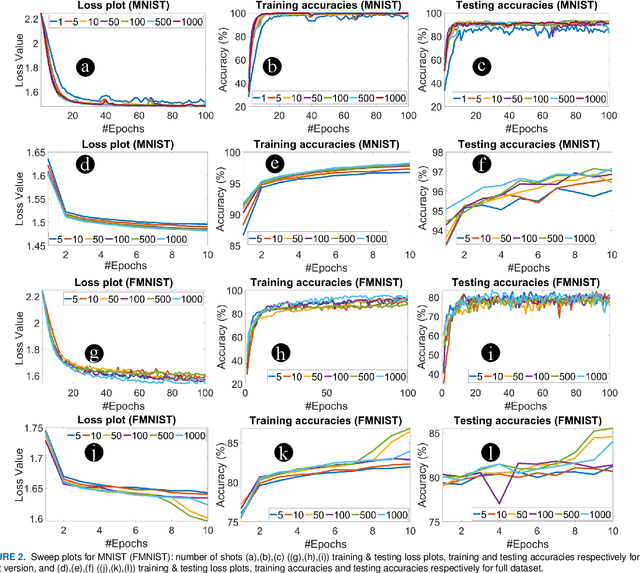
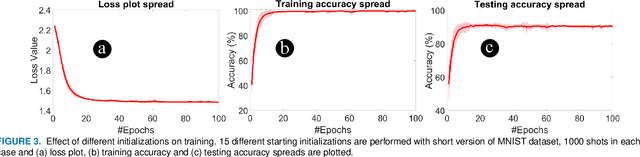
In this paper, we propose shot optimization method for QML models at the expense of minimal impact on model performance. We use classification task as a test case for MNIST and FMNIST datasets using a hybrid quantum-classical QML model. First, we sweep the number of shots for short and full versions of the dataset. We observe that training the full version provides 5-6% higher testing accuracy than short version of dataset with up to 10X higher number of shots for training. Therefore, one can reduce the dataset size to accelerate the training time. Next, we propose adaptive shot allocation on short version dataset to optimize the number of shots over training epochs and evaluate the impact on classification accuracy. We use a (a) linear function where the number of shots reduce linearly with epochs, and (b) step function where the number of shots reduce in step with epochs. We note around 0.01 increase in loss and around 4% (1%) reduction in testing accuracy for reduction in shots by up to 100X (10X) for linear (step) shot function compared to conventional constant shot function for MNIST dataset, and 0.05 increase in loss and around 5-7% (5-7%) reduction in testing accuracy with similar reduction in shots using linear (step) shot function on FMNIST dataset. For comparison, we also use the proposed shot optimization methods to perform ground state energy estimation of different molecules and observe that step function gives the best and most stable ground state energy prediction at 1000X less number of shots.
Quadric Representations for LiDAR Odometry, Mapping and Localization
Apr 27, 2023
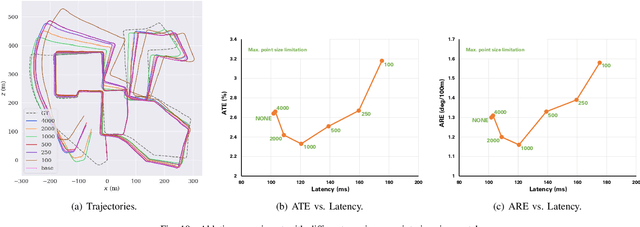
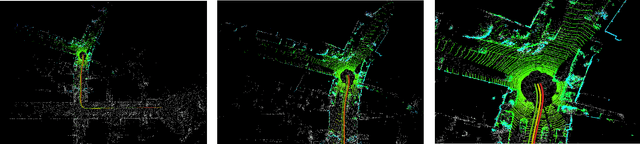
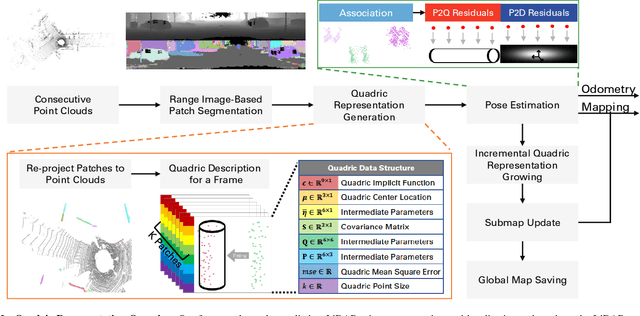
Current LiDAR odometry, mapping and localization methods leverage point-wise representations of 3D scenes and achieve high accuracy in autonomous driving tasks. However, the space-inefficiency of methods that use point-wise representations limits their development and usage in practical applications. In particular, scan-submap matching and global map representation methods are restricted by the inefficiency of nearest neighbor searching (NNS) for large-volume point clouds. To improve space-time efficiency, we propose a novel method of describing scenes using quadric surfaces, which are far more compact representations of 3D objects than conventional point clouds. In contrast to point cloud-based methods, our quadric representation-based method decomposes a 3D scene into a collection of sparse quadric patches, which improves storage efficiency and avoids the slow point-wise NNS process. Our method first segments a given point cloud into patches and fits each of them to a quadric implicit function. Each function is then coupled with other geometric descriptors of the patch, such as its center position and covariance matrix. Collectively, these patch representations fully describe a 3D scene, which can be used in place of the original point cloud and employed in LiDAR odometry, mapping and localization algorithms. We further design a novel incremental growing method for quadric representations, which eliminates the need to repeatedly re-fit quadric surfaces from the original point cloud. Extensive odometry, mapping and localization experiments on large-volume point clouds in the KITTI and UrbanLoco datasets demonstrate that our method maintains low latency and memory utility while achieving competitive, and even superior, accuracy.
A mean-field games laboratory for generative modeling
Apr 27, 2023In this paper, we demonstrate the versatility of mean-field games (MFGs) as a mathematical framework for explaining, enhancing, and designing generative models. There is a pervasive sense in the generative modeling community that the various flow and diffusion-based generative models have some foundational common structure and interrelationships. We establish connections between MFGs and major classes of flow and diffusion-based generative models including continuous-time normalizing flows, score-based models, and Wasserstein gradient flows. We derive these three classes of generative models through different choices of particle dynamics and cost functions. Furthermore, we study the mathematical structure and properties of each generative model by studying their associated MFG's optimality condition, which is a set of coupled nonlinear partial differential equations (PDEs). The theory of MFGs, therefore, enables the study of generative models through the theory of nonlinear PDEs. Through this perspective, we investigate the well-posedness and structure of normalizing flows, unravel the mathematical structure of score-based generative modeling, and derive a mean-field game formulation of the Wasserstein gradient flow. From an algorithmic perspective, the optimality conditions of MFGs also allow us to introduce HJB regularizers for enhanced training a broader class of generative models. We present this framework as an MFG laboratory which serves as a platform for revealing new avenues of experimentation and invention of generative models. This laboratory will give rise to a multitude of well-posed generative modeling formulations, providing a consistent theoretical framework upon which numerical and algorithmic tools may be developed.
Eagle: End-to-end Deep Reinforcement Learning based Autonomous Control of PTZ Cameras
Apr 10, 2023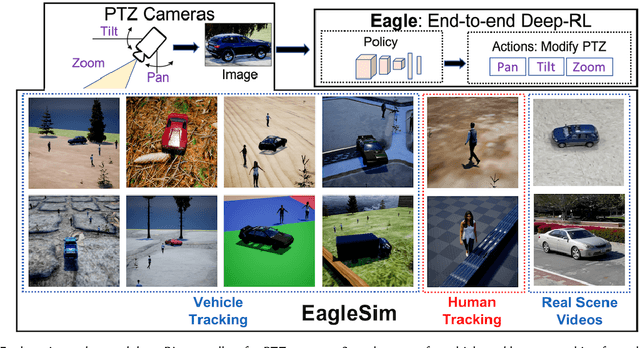

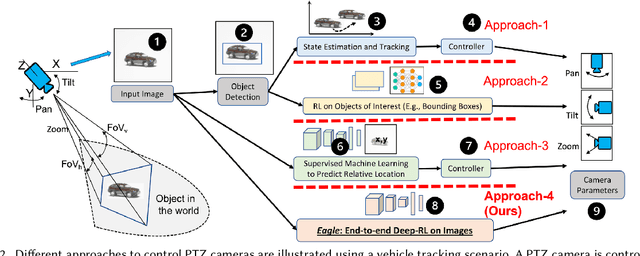
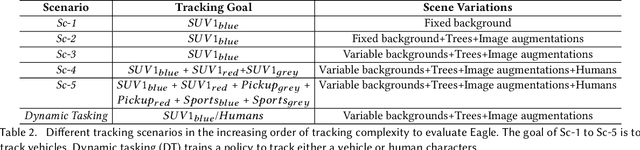
Existing approaches for autonomous control of pan-tilt-zoom (PTZ) cameras use multiple stages where object detection and localization are performed separately from the control of the PTZ mechanisms. These approaches require manual labels and suffer from performance bottlenecks due to error propagation across the multi-stage flow of information. The large size of object detection neural networks also makes prior solutions infeasible for real-time deployment in resource-constrained devices. We present an end-to-end deep reinforcement learning (RL) solution called Eagle to train a neural network policy that directly takes images as input to control the PTZ camera. Training reinforcement learning is cumbersome in the real world due to labeling effort, runtime environment stochasticity, and fragile experimental setups. We introduce a photo-realistic simulation framework for training and evaluation of PTZ camera control policies. Eagle achieves superior camera control performance by maintaining the object of interest close to the center of captured images at high resolution and has up to 17% more tracking duration than the state-of-the-art. Eagle policies are lightweight (90x fewer parameters than Yolo5s) and can run on embedded camera platforms such as Raspberry PI (33 FPS) and Jetson Nano (38 FPS), facilitating real-time PTZ tracking for resource-constrained environments. With domain randomization, Eagle policies trained in our simulator can be transferred directly to real-world scenarios.
Online Convex Optimization of Programmable Quantum Computers to Simulate Time-Varying Quantum Channels
Dec 09, 2022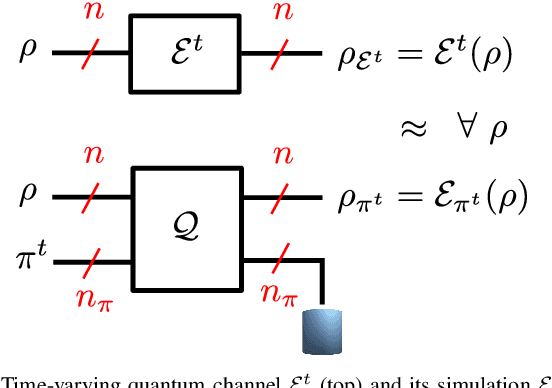
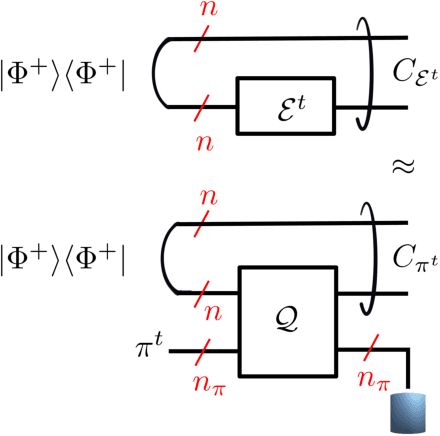
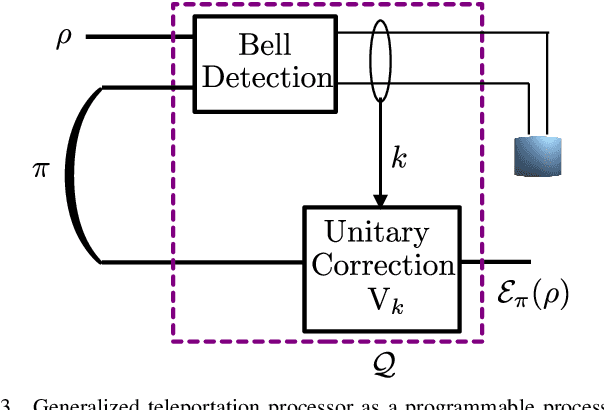
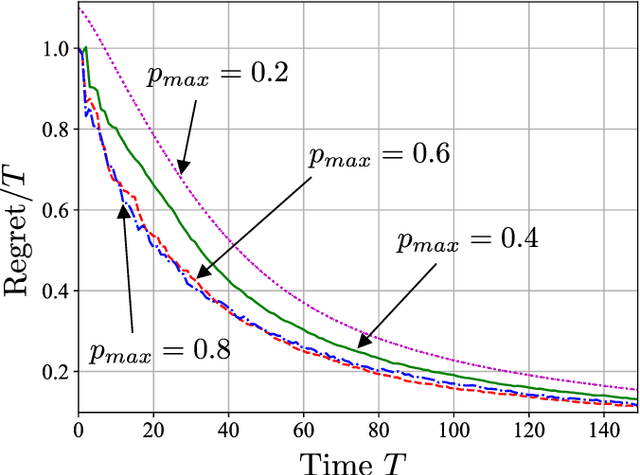
Simulating quantum channels is a fundamental primitive in quantum computing, since quantum channels define general (trace-preserving) quantum operations. An arbitrary quantum channel cannot be exactly simulated using a finite-dimensional programmable quantum processor, making it important to develop optimal approximate simulation techniques. In this paper, we study the challenging setting in which the channel to be simulated varies adversarially with time. We propose the use of matrix exponentiated gradient descent (MEGD), an online convex optimization method, and analytically show that it achieves a sublinear regret in time. Through experiments, we validate the main results for time-varying dephasing channels using a programmable generalized teleportation processor.
Addressing Distribution Shift at Test Time in Pre-trained Language Models
Dec 05, 2022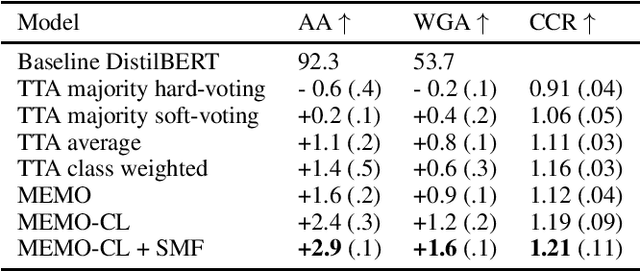
State-of-the-art pre-trained language models (PLMs) outperform other models when applied to the majority of language processing tasks. However, PLMs have been found to degrade in performance under distribution shift, a phenomenon that occurs when data at test-time does not come from the same distribution as the source training set. Equally as challenging is the task of obtaining labels in real-time due to issues like long-labeling feedback loops. The lack of adequate methods that address the aforementioned challenges constitutes the need for approaches that continuously adapt the PLM to a distinct distribution. Unsupervised domain adaptation adapts a source model to an unseen as well as unlabeled target domain. While some techniques such as data augmentation can adapt models in several scenarios, they have only been sparsely studied for addressing the distribution shift problem. In this work, we present an approach (MEMO-CL) that improves the performance of PLMs at test-time under distribution shift. Our approach takes advantage of the latest unsupervised techniques in data augmentation and adaptation to minimize the entropy of the PLM's output distribution. MEMO-CL operates on a batch of augmented samples from a single observation in the test set. The technique introduced is unsupervised, domain-agnostic, easy to implement, and requires no additional data. Our experiments result in a 3% improvement over current test-time adaptation baselines.
Uncertainty-DTW for Time Series and Sequences
Oct 30, 2022Dynamic Time Warping (DTW) is used for matching pairs of sequences and celebrated in applications such as forecasting the evolution of time series, clustering time series or even matching sequence pairs in few-shot action recognition. The transportation plan of DTW contains a set of paths; each path matches frames between two sequences under a varying degree of time warping, to account for varying temporal intra-class dynamics of actions. However, as DTW is the smallest distance among all paths, it may be affected by the feature uncertainty which varies across time steps/frames. Thus, in this paper, we propose to model the so-called aleatoric uncertainty of a differentiable (soft) version of DTW. To this end, we model the heteroscedastic aleatoric uncertainty of each path by the product of likelihoods from Normal distributions, each capturing variance of pair of frames. (The path distance is the sum of base distances between features of pairs of frames of the path.) The Maximum Likelihood Estimation (MLE) applied to a path yields two terms: (i) a sum of Euclidean distances weighted by the variance inverse, and (ii) a sum of log-variance regularization terms. Thus, our uncertainty-DTW is the smallest weighted path distance among all paths, and the regularization term (penalty for the high uncertainty) is the aggregate of log-variances along the path. The distance and the regularization term can be used in various objectives. We showcase forecasting the evolution of time series, estimating the Fr\'echet mean of time series, and supervised/unsupervised few-shot action recognition of the articulated human 3D body joints.
Continuous Time Analysis of Dynamic Matching in Heterogeneous Networks
Feb 20, 2023
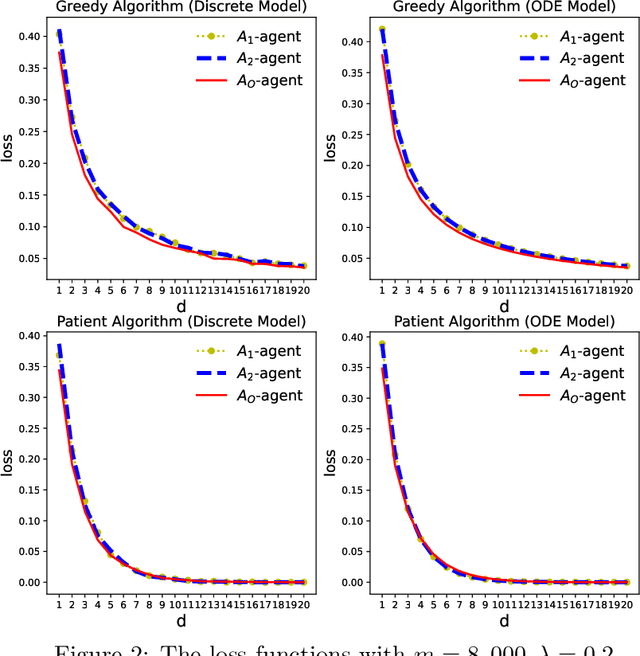
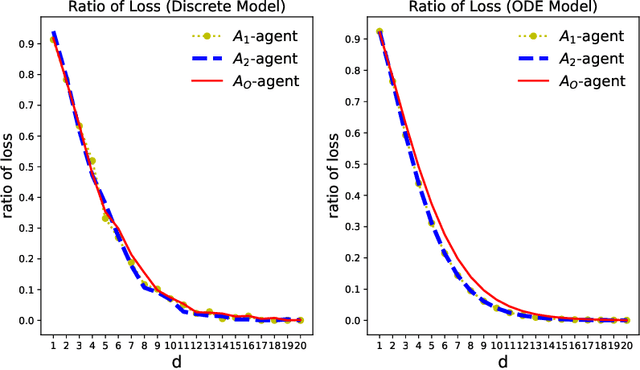
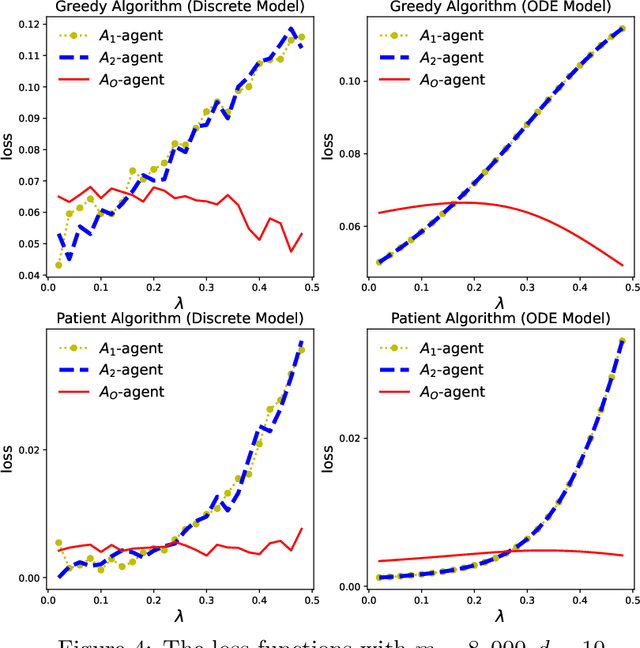
This paper addresses the problem of dynamic matching in heterogeneous networks, where agents are subject to compatibility restrictions and stochastic arrival and departure times. In particular, we consider networks with one type of easy-to-match agents and multiple types of hard-to-match agents, each subject to its own set of compatibility constraints. Such a setting arises in many real-world applications, including kidney exchange programs and carpooling platforms, where some participants may have more stringent compatibility requirements than others. We introduce a novel approach to modeling dynamic matching by establishing ordinary differential equation (ODE) models, offering a new perspective for evaluating various matching algorithms. We study two algorithms, the Greedy Algorithm and the Patient Algorithm, which prioritize the matching of compatible hard-to-match agents over easy-to-match agents in heterogeneous networks. Our results show the trade-off between the conflicting goals of matching agents quickly and optimally, offering insights into the design of real-world dynamic matching systems. We present simulations and a real-world case study using data from the Organ Procurement and Transplantation Network to validate theoretical predictions.
Knowledge Distillation from 3D to Bird's-Eye-View for LiDAR Semantic Segmentation
Apr 22, 2023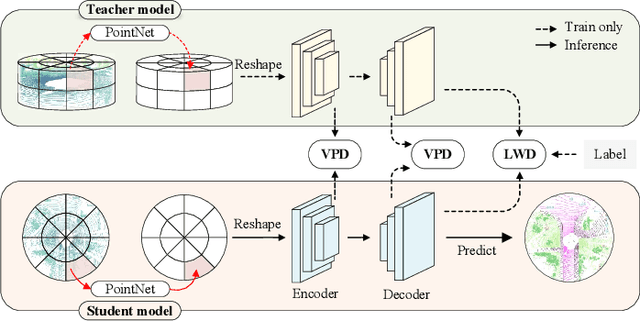
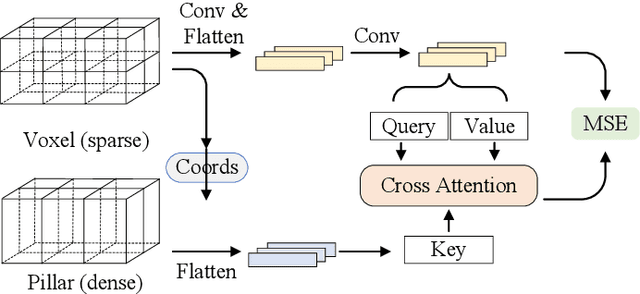
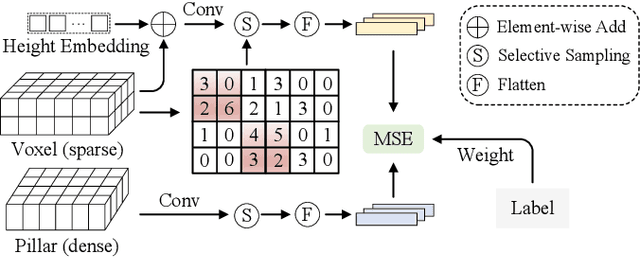
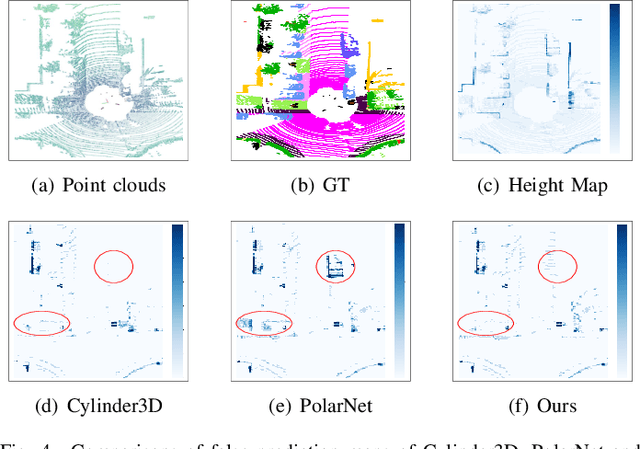
LiDAR point cloud segmentation is one of the most fundamental tasks for autonomous driving scene understanding. However, it is difficult for existing models to achieve both high inference speed and accuracy simultaneously. For example, voxel-based methods perform well in accuracy, while Bird's-Eye-View (BEV)-based methods can achieve real-time inference. To overcome this issue, we develop an effective 3D-to-BEV knowledge distillation method that transfers rich knowledge from 3D voxel-based models to BEV-based models. Our framework mainly consists of two modules: the voxel-to-pillar distillation module and the label-weight distillation module. Voxel-to-pillar distillation distills sparse 3D features to BEV features for middle layers to make the BEV-based model aware of more structural and geometric information. Label-weight distillation helps the model pay more attention to regions with more height information. Finally, we conduct experiments on the SemanticKITTI dataset and Paris-Lille-3D. The results on SemanticKITTI show more than 5% improvement on the test set, especially for classes such as motorcycle and person, with more than 15% improvement. The code can be accessed at https://github.com/fengjiang5/Knowledge-Distillation-from-Cylinder3D-to-PolarNet.
Fast Diffusion Probabilistic Model Sampling through the lens of Backward Error Analysis
Apr 22, 2023
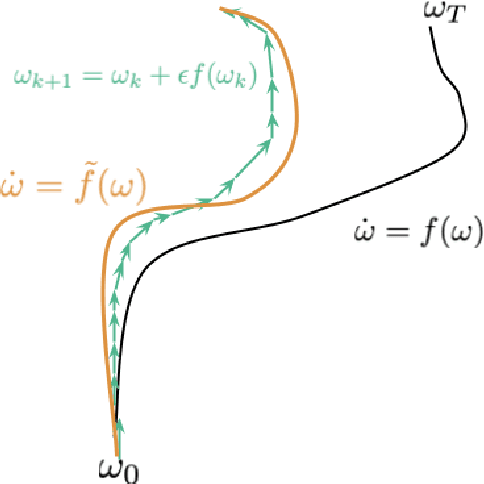
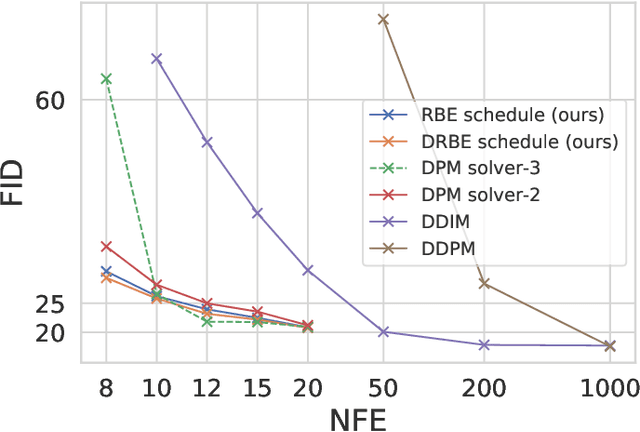
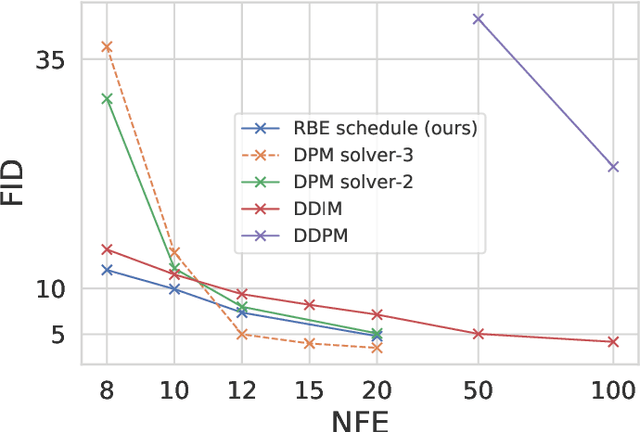
Denoising diffusion probabilistic models (DDPMs) are a class of powerful generative models. The past few years have witnessed the great success of DDPMs in generating high-fidelity samples. A significant limitation of the DDPMs is the slow sampling procedure. DDPMs generally need hundreds or thousands of sequential function evaluations (steps) of neural networks to generate a sample. This paper aims to develop a fast sampling method for DDPMs requiring much fewer steps while retaining high sample quality. The inference process of DDPMs approximates solving the corresponding diffusion ordinary differential equations (diffusion ODEs) in the continuous limit. This work analyzes how the backward error affects the diffusion ODEs and the sample quality in DDPMs. We propose fast sampling through the \textbf{Restricting Backward Error schedule (RBE schedule)} based on dynamically moderating the long-time backward error. Our method accelerates DDPMs without any further training. Our experiments show that sampling with an RBE schedule generates high-quality samples within only 8 to 20 function evaluations on various benchmark datasets. We achieved 12.01 FID in 8 function evaluations on the ImageNet $128\times128$, and a $20\times$ speedup compared with previous baseline samplers.