 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
How to Control Hydrodynamic Force on Fluidic Pinball via Deep Reinforcement Learning
Apr 23, 2023
Deep reinforcement learning (DRL) for fluidic pinball, three individually rotating cylinders in the uniform flow arranged in an equilaterally triangular configuration, can learn the efficient flow control strategies due to the validity of self-learning and data-driven state estimation for complex fluid dynamic problems. In this work, we present a DRL-based real-time feedback strategy to control the hydrodynamic force on fluidic pinball, i.e., force extremum and tracking, from cylinders' rotation. By adequately designing reward functions and encoding historical observations, and after automatic learning of thousands of iterations, the DRL-based control was shown to make reasonable and valid control decisions in nonparametric control parameter space, which is comparable to and even better than the optimal policy found through lengthy brute-force searching. Subsequently, one of these results was analyzed by a machine learning model that enabled us to shed light on the basis of decision-making and physical mechanisms of the force tracking process. The finding from this work can control hydrodynamic force on the operation of fluidic pinball system and potentially pave the way for exploring efficient active flow control strategies in other complex fluid dynamic problems.
Advances on Concept Drift Detection in Regression Tasks using Social Networks Theory
Apr 19, 2023Mining data streams is one of the main studies in machine learning area due to its application in many knowledge areas. One of the major challenges on mining data streams is concept drift, which requires the learner to discard the current concept and adapt to a new one. Ensemble-based drift detection algorithms have been used successfully to the classification task but usually maintain a fixed size ensemble of learners running the risk of needlessly spending processing time and memory. In this paper we present improvements to the Scale-free Network Regressor (SFNR), a dynamic ensemble-based method for regression that employs social networks theory. In order to detect concept drifts SFNR uses the Adaptive Window (ADWIN) algorithm. Results show improvements in accuracy, especially in concept drift situations and better performance compared to other state-of-the-art algorithms in both real and synthetic data.
TIDE: Time Derivative Diffusion for Deep Learning on Graphs
Dec 05, 2022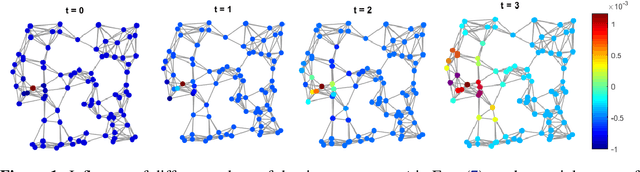
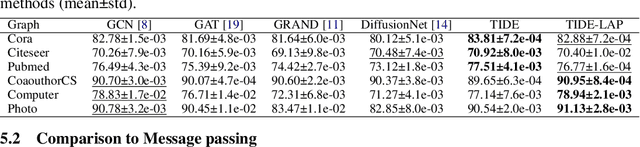
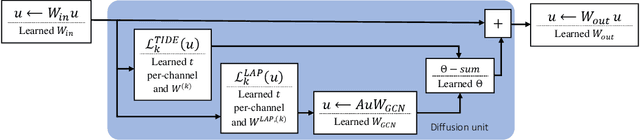
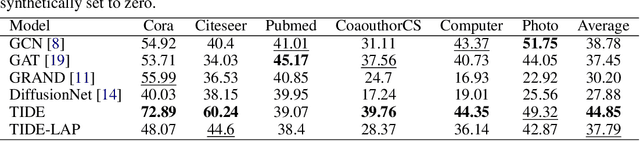
A prominent paradigm for graph neural networks is based on the message passing framework. In this framework, information communication is realized only between neighboring nodes. The challenge of approaches that use this paradigm is to ensure efficient and accurate \textit{long distance communication} between nodes, as deep convolutional networks are prone to over-smoothing. In this paper, we present a novel method based on time derivative graph diffusion (TIDE), with a learnable time parameter. Our approach allows to adapt the spatial extent of diffusion across different tasks and network channels, thus enabling medium and long-distance communication efficiently. Furthermore, we show that our architecture directly enables local message passing and thus inherits from the expressive power of local message passing approaches. We show that on widely used graph benchmarks we achieve comparable performance and on a synthetic mesh dataset we outperform state-of-the-art methods like GCN or GRAND by a significant margin.
OTFDM: A Novel 2D Modulation Waveform Modeling Dot-product Doubly-selective Channel
Apr 04, 2023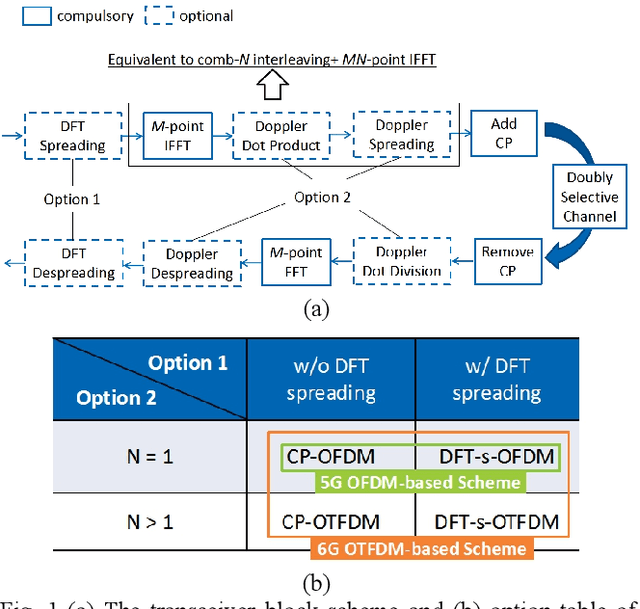
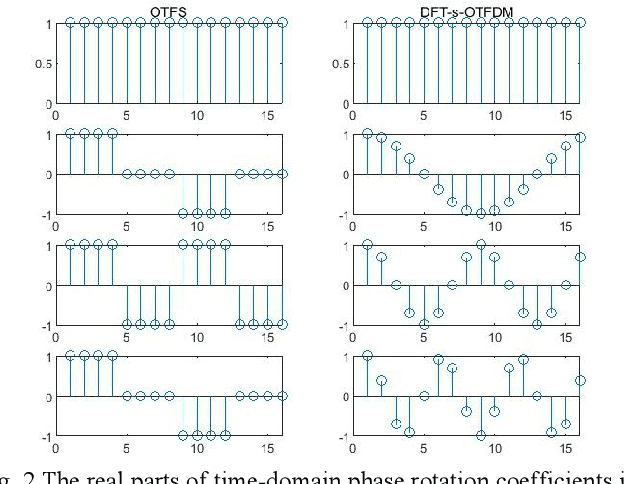
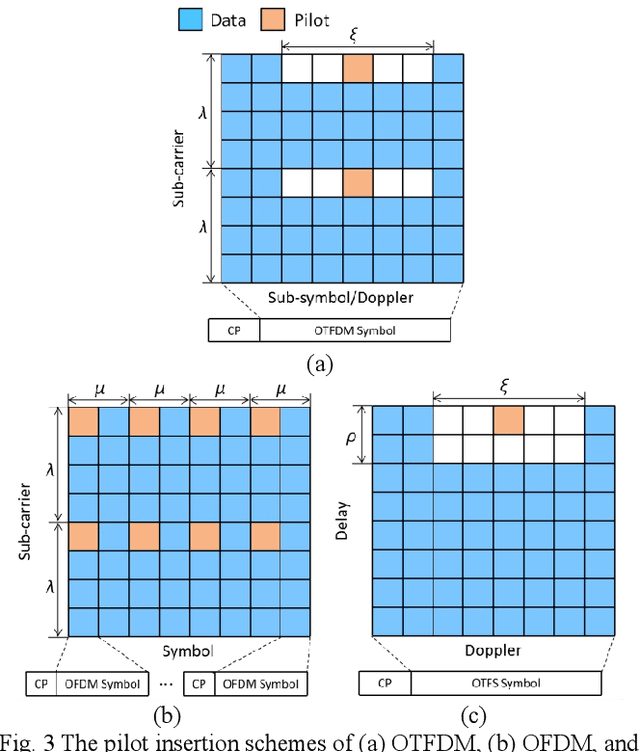
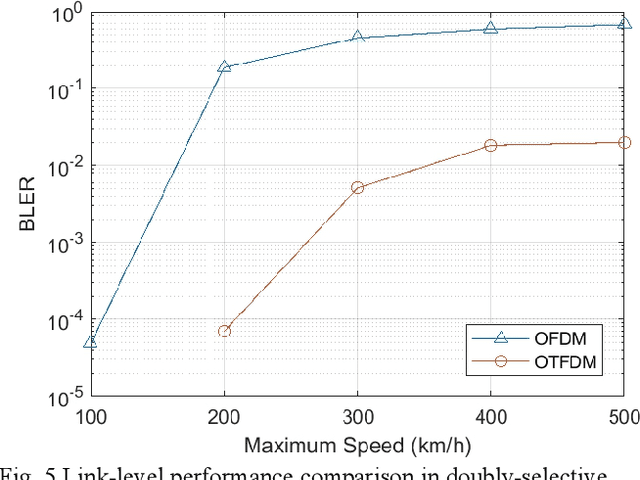
Recently, a two-dimension (2D) modulation waveform of orthogonal time-frequency-space (OTFS) has been a popular 6G candidate to replace existing orthogonal frequency division multiplexing (OFDM). The extensive OTFS researches help to make both the advantages and limitations of OTFS more and more clear. The limitations are not easy to overcome as they come from OTFS on-grid 2D convolution channel model. Instead of solving OTFS inborn challenges, this paper proposes a novel 2D modulation waveform named orthogonal time-frequency division multiplexing (OTFDM). OTFDM uses a 2D dot-product channel model to cope with doubly-selectivity. Compared with OTFS, OTFDM supports grid-free channel delay and Doppler and gains a simple and efficient 2D equalization. The concise dot-division equalization can be easily combined with MIMO. The simulation result shows that OTFDM is able to bear high mobility and greatly outperforms OFDM in doubly-selective channel.
MATE: Masked Autoencoders are Online 3D Test-Time Learners
Nov 21, 2022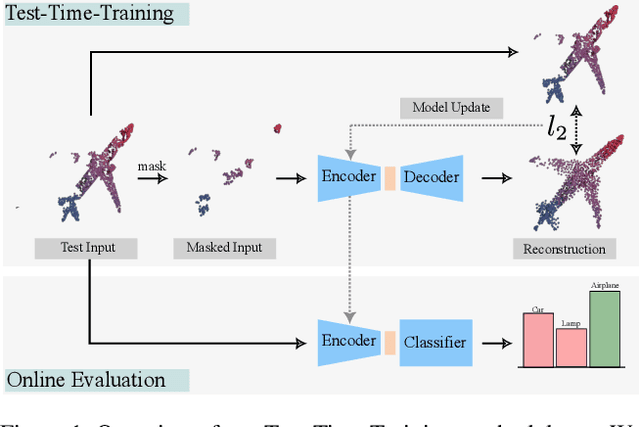

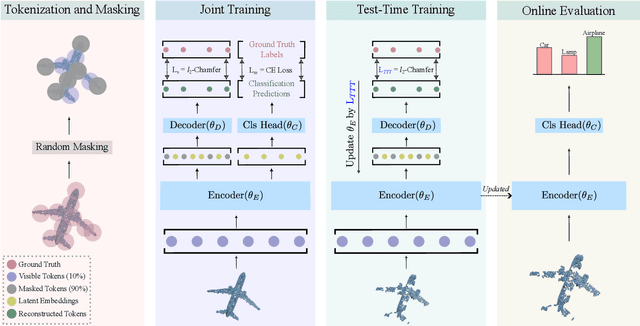

We propose MATE, the first Test-Time-Training (TTT) method designed for 3D data. It makes deep networks trained in point cloud classification robust to distribution shifts occurring in test data, which could not be anticipated during training. Like existing TTT methods, which focused on classifying 2D images in the presence of distribution shifts at test-time, MATE also leverages test data for adaptation. Its test-time objective is that of a Masked Autoencoder: Each test point cloud has a large portion of its points removed before it is fed to the network, tasked with reconstructing the full point cloud. Once the network is updated, it is used to classify the point cloud. We test MATE on several 3D object classification datasets and show that it significantly improves robustness of deep networks to several types of corruptions commonly occurring in 3D point clouds. Further, we show that MATE is very efficient in terms of the fraction of points it needs for the adaptation. It can effectively adapt given as few as 5% of tokens of each test sample, which reduces its memory footprint and makes it lightweight. We also highlight that MATE achieves competitive performance by adapting sparingly on the test data, which further reduces its computational overhead, making it ideal for real-time applications.
A novel approach of a deep reinforcement learning based motion cueing algorithm for vehicle driving simulation
Apr 15, 2023
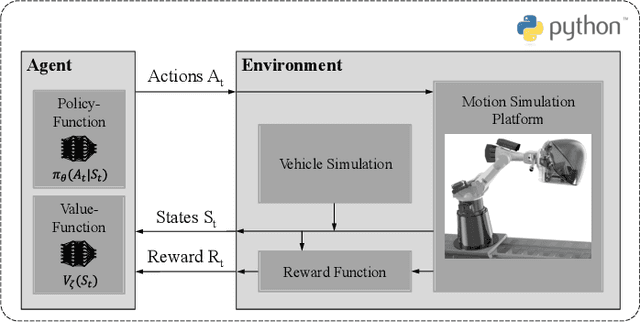
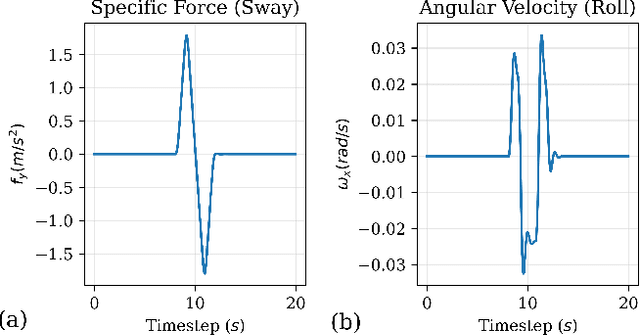
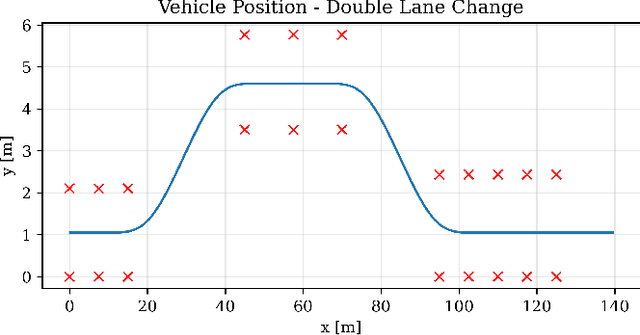
In the field of motion simulation, the level of immersion strongly depends on the motion cueing algorithm (MCA), as it transfers the reference motion of the simulated vehicle to a motion of the motion simulation platform (MSP). The challenge for the MCA is to reproduce the motion perception of a real vehicle driver as accurately as possible without exceeding the limits of the workspace of the MSP in order to provide a realistic virtual driving experience. In case of a large discrepancy between the perceived motion signals and the optical cues, motion sickness may occur with the typical symptoms of nausea, dizziness, headache and fatigue. Existing approaches either produce non-optimal results, e.g., due to filtering, linearization, or simplifications, or the required computational time exceeds the real-time requirements of a closed-loop application. In this work a new solution is presented, where not a human designer specifies the principles of the MCA but an artificial intelligence (AI) learns the optimal motion by trial and error in an interaction with the MSP. To achieve this, deep reinforcement learning (RL) is applied, where an agent interacts with an environment formulated as a Markov decision process~(MDP). This allows the agent to directly control a simulated MSP to obtain feedback on its performance in terms of platform workspace usage and the motion acting on the simulator user. The RL algorithm used is proximal policy optimization (PPO), where the value function and the policy corresponding to the control strategy are learned and both are mapped in artificial neural networks (ANN). This approach is implemented in Python and the functionality is demonstrated by the practical example of pre-recorded lateral maneuvers. The subsequent validation on a standardized double lane change shows that the RL algorithm is able to learn the control strategy and improve the quality of...
Inductive Graph Transformer for Delivery Time Estimation
Nov 05, 2022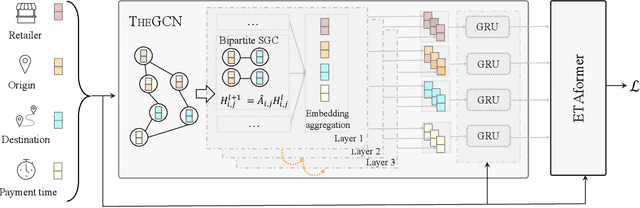
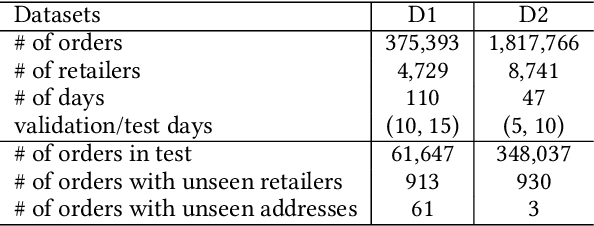
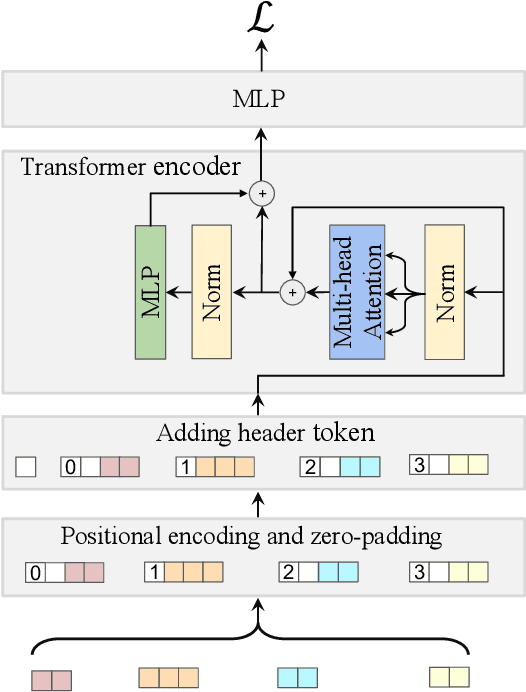

Providing accurate estimated time of package delivery on users' purchasing pages for e-commerce platforms is of great importance to their purchasing decisions and post-purchase experiences. Although this problem shares some common issues with the conventional estimated time of arrival (ETA), it is more challenging with the following aspects: 1) Inductive inference. Models are required to predict ETA for orders with unseen retailers and addresses; 2) High-order interaction of order semantic information. Apart from the spatio-temporal features, the estimated time also varies greatly with other factors, such as the packaging efficiency of retailers, as well as the high-order interaction of these factors. In this paper, we propose an inductive graph transformer (IGT) that leverages raw feature information and structural graph data to estimate package delivery time. Different from previous graph transformer architectures, IGT adopts a decoupled pipeline and trains transformer as a regression function that can capture the multiplex information from both raw feature and dense embeddings encoded by a graph neural network (GNN). In addition, we further simplify the GNN structure by removing its non-linear activation and the learnable linear transformation matrix. The reduced parameter search space and linear information propagation in the simplified GNN enable the IGT to be applied in large-scale industrial scenarios. Experiments on real-world logistics datasets show that our proposed model can significantly outperform the state-of-the-art methods on estimation of delivery time. The source code is available at: https://github.com/enoche/IGT-WSDM23.
Finite-Sample Bounds for Adaptive Inverse Reinforcement Learning using Passive Langevin Dynamics
Apr 18, 2023Stochastic gradient Langevin dynamics (SGLD) are a useful methodology for sampling from probability distributions. This paper provides a finite sample analysis of a passive stochastic gradient Langevin dynamics algorithm (PSGLD) designed to achieve inverse reinforcement learning. By "passive", we mean that the noisy gradients available to the PSGLD algorithm (inverse learning process) are evaluated at randomly chosen points by an external stochastic gradient algorithm (forward learner). The PSGLD algorithm thus acts as a randomized sampler which recovers the cost function being optimized by this external process. Previous work has analyzed the asymptotic performance of this passive algorithm using stochastic approximation techniques; in this work we analyze the non-asymptotic performance. Specifically, we provide finite-time bounds on the 2-Wasserstein distance between the passive algorithm and its stationary measure, from which the reconstructed cost function is obtained.
Large-scale Dynamic Network Representation via Tensor Ring Decomposition
Apr 18, 2023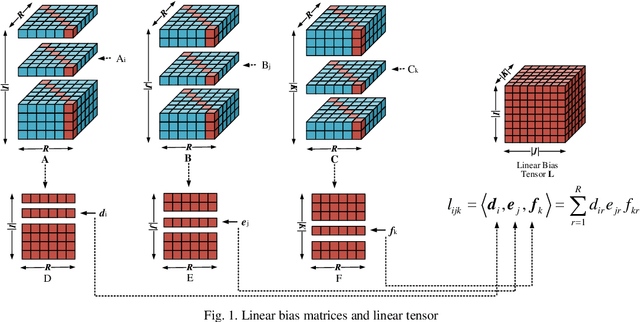
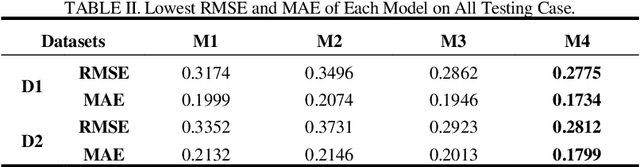
Large-scale Dynamic Networks (LDNs) are becoming increasingly important in the Internet age, yet the dynamic nature of these networks captures the evolution of the network structure and how edge weights change over time, posing unique challenges for data analysis and modeling. A Latent Factorization of Tensors (LFT) model facilitates efficient representation learning for a LDN. But the existing LFT models are almost based on Canonical Polyadic Factorization (CPF). Therefore, this work proposes a model based on Tensor Ring (TR) decomposition for efficient representation learning for a LDN. Specifically, we incorporate the principle of single latent factor-dependent, non-negative, and multiplicative update (SLF-NMU) into the TR decomposition model, and analyze the particular bias form of TR decomposition. Experimental studies on two real LDNs demonstrate that the propose method achieves higher accuracy than existing models.
Robust Time Series Chain Discovery with Incremental Nearest Neighbors
Nov 03, 2022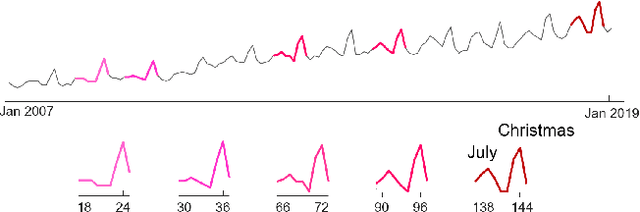
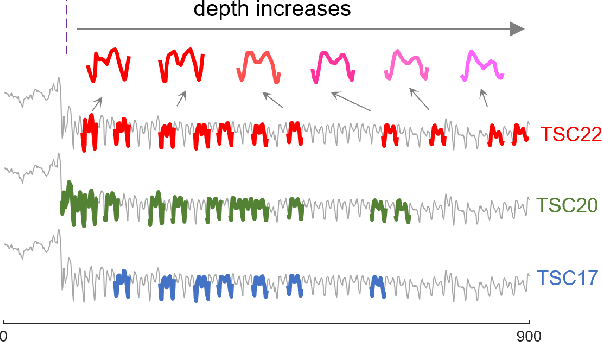
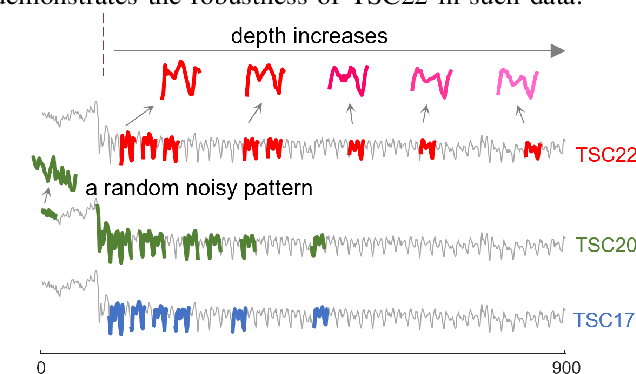
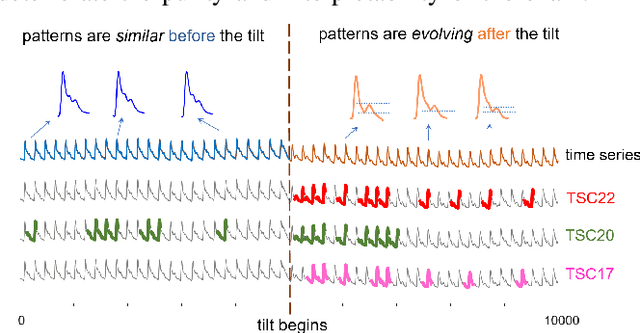
Time series motif discovery has been a fundamental task to identify meaningful repeated patterns in time series. Recently, time series chains were introduced as an expansion of time series motifs to identify the continuous evolving patterns in time series data. Informally, a time series chain (TSC) is a temporally ordered set of time series subsequences, in which every subsequence is similar to the one that precedes it, but the last and the first can be arbitrarily dissimilar. TSCs are shown to be able to reveal latent continuous evolving trends in the time series, and identify precursors of unusual events in complex systems. Despite its promising interpretability, unfortunately, we have observed that existing TSC definitions lack the ability to accurately cover the evolving part of a time series: the discovered chains can be easily cut by noise and can include non-evolving patterns, making them impractical in real-world applications. Inspired by a recent work that tracks how the nearest neighbor of a time series subsequence changes over time, we introduce a new TSC definition which is much more robust to noise in the data, in the sense that they can better locate the evolving patterns while excluding the non-evolving ones. We further propose two new quality metrics to rank the discovered chains. With extensive empirical evaluations, we demonstrate that the proposed TSC definition is significantly more robust to noise than the state of the art, and the top ranked chains discovered can reveal meaningful regularities in a variety of real world datasets.