 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Uncertainty-DTW for Time Series and Sequences
Oct 30, 2022
Dynamic Time Warping (DTW) is used for matching pairs of sequences and celebrated in applications such as forecasting the evolution of time series, clustering time series or even matching sequence pairs in few-shot action recognition. The transportation plan of DTW contains a set of paths; each path matches frames between two sequences under a varying degree of time warping, to account for varying temporal intra-class dynamics of actions. However, as DTW is the smallest distance among all paths, it may be affected by the feature uncertainty which varies across time steps/frames. Thus, in this paper, we propose to model the so-called aleatoric uncertainty of a differentiable (soft) version of DTW. To this end, we model the heteroscedastic aleatoric uncertainty of each path by the product of likelihoods from Normal distributions, each capturing variance of pair of frames. (The path distance is the sum of base distances between features of pairs of frames of the path.) The Maximum Likelihood Estimation (MLE) applied to a path yields two terms: (i) a sum of Euclidean distances weighted by the variance inverse, and (ii) a sum of log-variance regularization terms. Thus, our uncertainty-DTW is the smallest weighted path distance among all paths, and the regularization term (penalty for the high uncertainty) is the aggregate of log-variances along the path. The distance and the regularization term can be used in various objectives. We showcase forecasting the evolution of time series, estimating the Fr\'echet mean of time series, and supervised/unsupervised few-shot action recognition of the articulated human 3D body joints.
ReDWINE: A Clinical Datamart with Text Analytical Capabilities to Facilitate Rehabilitation Research
Apr 12, 2023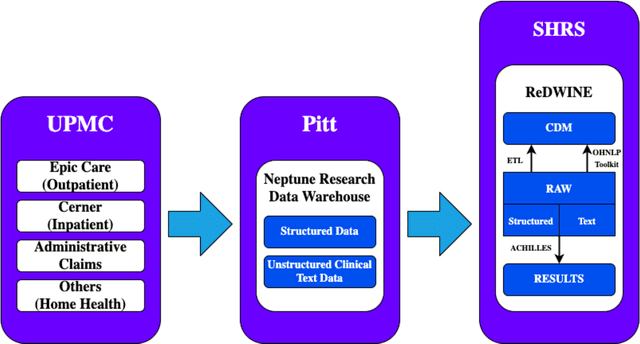
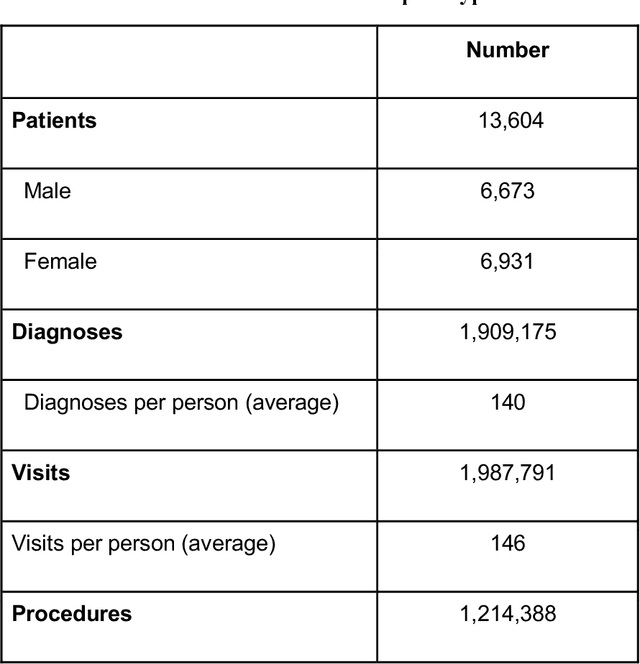
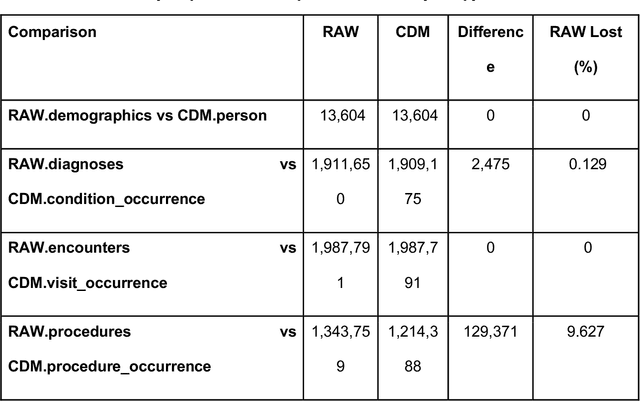
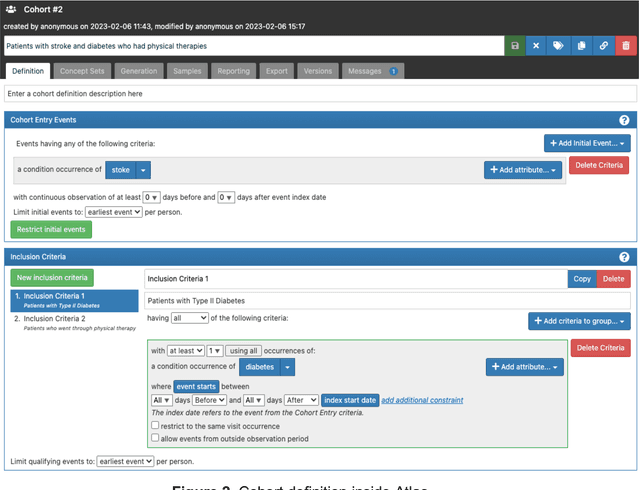
Rehabilitation research focuses on determining the components of a treatment intervention, the mechanism of how these components lead to recovery and rehabilitation, and ultimately the optimal intervention strategies to maximize patients' physical, psychologic, and social functioning. Traditional randomized clinical trials that study and establish new interventions face several challenges, such as high cost and time commitment. Observational studies that use existing clinical data to observe the effect of an intervention have shown several advantages over RCTs. Electronic Health Records (EHRs) have become an increasingly important resource for conducting observational studies. To support these studies, we developed a clinical research datamart, called ReDWINE (Rehabilitation Datamart With Informatics iNfrastructure for rEsearch), that transforms the rehabilitation-related EHR data collected from the UPMC health care system to the Observational Health Data Sciences and Informatics (OHDSI) Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM) to facilitate rehabilitation research. The standardized EHR data stored in ReDWINE will further reduce the time and effort required by investigators to pool, harmonize, clean, and analyze data from multiple sources, leading to more robust and comprehensive research findings. ReDWINE also includes deployment of data visualization and data analytics tools to facilitate cohort definition and clinical data analysis. These include among others the Open Health Natural Language Processing (OHNLP) toolkit, a high-throughput NLP pipeline, to provide text analytical capabilities at scale in ReDWINE. Using this comprehensive representation of patient data in ReDWINE for rehabilitation research will facilitate real-world evidence for health interventions and outcomes.
Addressing Distribution Shift at Test Time in Pre-trained Language Models
Dec 05, 2022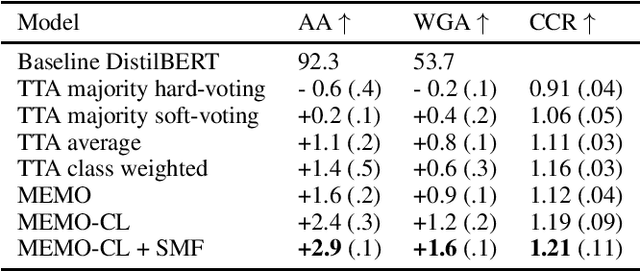
State-of-the-art pre-trained language models (PLMs) outperform other models when applied to the majority of language processing tasks. However, PLMs have been found to degrade in performance under distribution shift, a phenomenon that occurs when data at test-time does not come from the same distribution as the source training set. Equally as challenging is the task of obtaining labels in real-time due to issues like long-labeling feedback loops. The lack of adequate methods that address the aforementioned challenges constitutes the need for approaches that continuously adapt the PLM to a distinct distribution. Unsupervised domain adaptation adapts a source model to an unseen as well as unlabeled target domain. While some techniques such as data augmentation can adapt models in several scenarios, they have only been sparsely studied for addressing the distribution shift problem. In this work, we present an approach (MEMO-CL) that improves the performance of PLMs at test-time under distribution shift. Our approach takes advantage of the latest unsupervised techniques in data augmentation and adaptation to minimize the entropy of the PLM's output distribution. MEMO-CL operates on a batch of augmented samples from a single observation in the test set. The technique introduced is unsupervised, domain-agnostic, easy to implement, and requires no additional data. Our experiments result in a 3% improvement over current test-time adaptation baselines.
Online Convex Optimization of Programmable Quantum Computers to Simulate Time-Varying Quantum Channels
Dec 09, 2022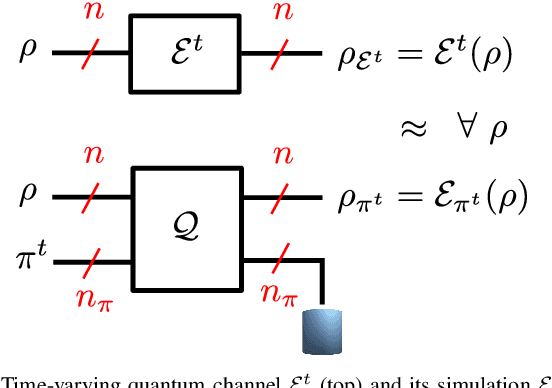
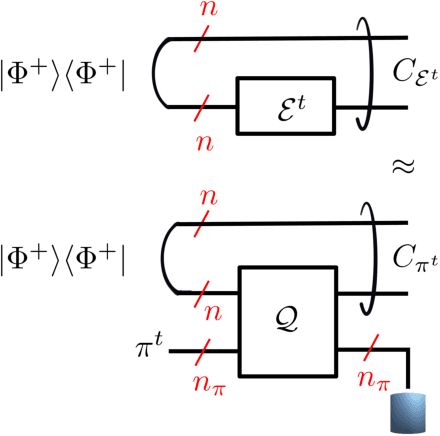
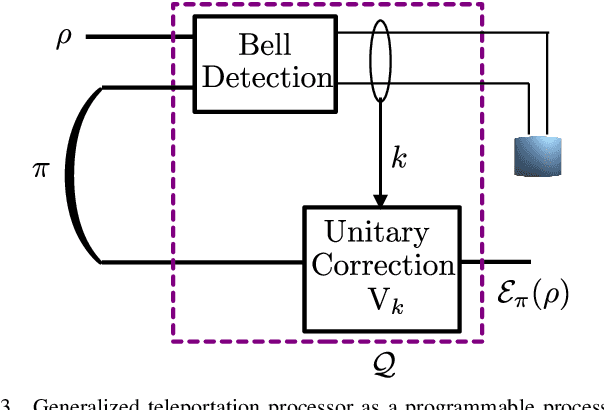
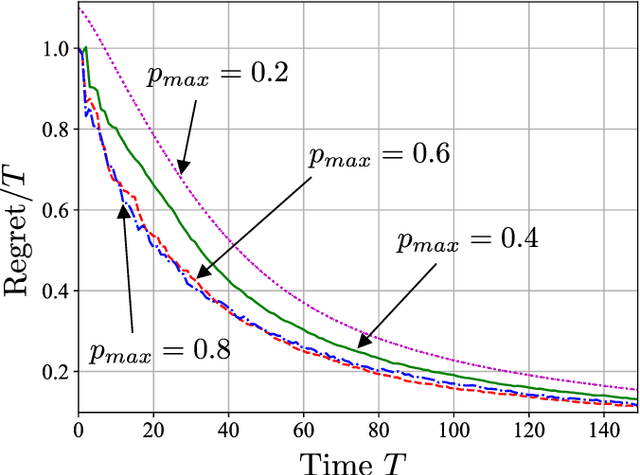
Simulating quantum channels is a fundamental primitive in quantum computing, since quantum channels define general (trace-preserving) quantum operations. An arbitrary quantum channel cannot be exactly simulated using a finite-dimensional programmable quantum processor, making it important to develop optimal approximate simulation techniques. In this paper, we study the challenging setting in which the channel to be simulated varies adversarially with time. We propose the use of matrix exponentiated gradient descent (MEGD), an online convex optimization method, and analytically show that it achieves a sublinear regret in time. Through experiments, we validate the main results for time-varying dephasing channels using a programmable generalized teleportation processor.
Recurrent Transformer for Dynamic Graph Representation Learning with Edge Temporal States
Apr 20, 2023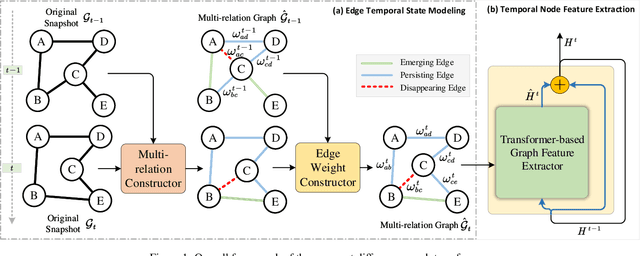
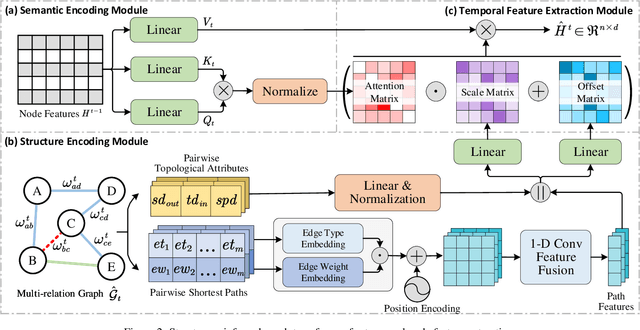
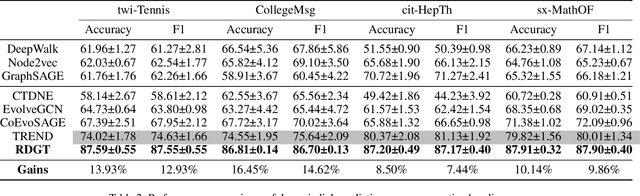
Dynamic graph representation learning is growing as a trending yet challenging research task owing to the widespread demand for graph data analysis in real world applications. Despite the encouraging performance of many recent works that build upon recurrent neural networks (RNNs) and graph neural networks (GNNs), they fail to explicitly model the impact of edge temporal states on node features over time slices. Additionally, they are challenging to extract global structural features because of the inherent over-smoothing disadvantage of GNNs, which further restricts the performance. In this paper, we propose a recurrent difference graph transformer (RDGT) framework, which firstly assigns the edges in each snapshot with various types and weights to illustrate their specific temporal states explicitly, then a structure-reinforced graph transformer is employed to capture the temporal node representations by a recurrent learning paradigm. Experimental results on four real-world datasets demonstrate the superiority of RDGT for discrete dynamic graph representation learning, as it consistently outperforms competing methods in dynamic link prediction tasks.
ReLight My NeRF: A Dataset for Novel View Synthesis and Relighting of Real World Objects
Apr 20, 2023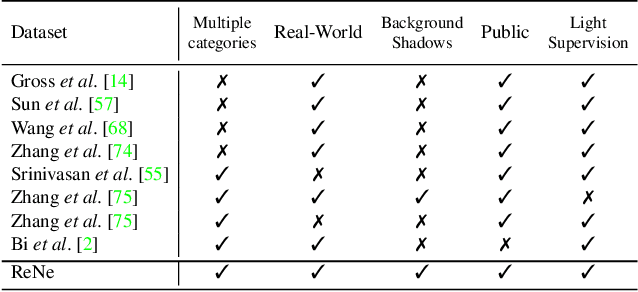
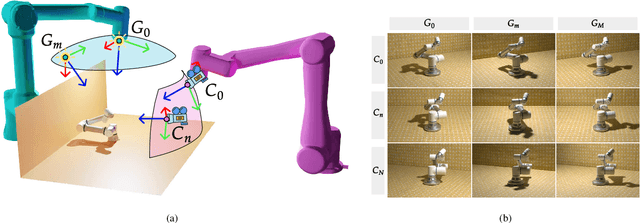
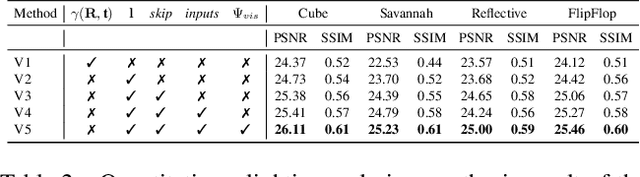
In this paper, we focus on the problem of rendering novel views from a Neural Radiance Field (NeRF) under unobserved light conditions. To this end, we introduce a novel dataset, dubbed ReNe (Relighting NeRF), framing real world objects under one-light-at-time (OLAT) conditions, annotated with accurate ground-truth camera and light poses. Our acquisition pipeline leverages two robotic arms holding, respectively, a camera and an omni-directional point-wise light source. We release a total of 20 scenes depicting a variety of objects with complex geometry and challenging materials. Each scene includes 2000 images, acquired from 50 different points of views under 40 different OLAT conditions. By leveraging the dataset, we perform an ablation study on the relighting capability of variants of the vanilla NeRF architecture and identify a lightweight architecture that can render novel views of an object under novel light conditions, which we use to establish a non-trivial baseline for the dataset. Dataset and benchmark are available at https://eyecan-ai.github.io/rene.
Enhancing Artificial intelligence Policies with Fusion and Forecasting: Insights from Indian Patents Using Network Analysis
Apr 20, 2023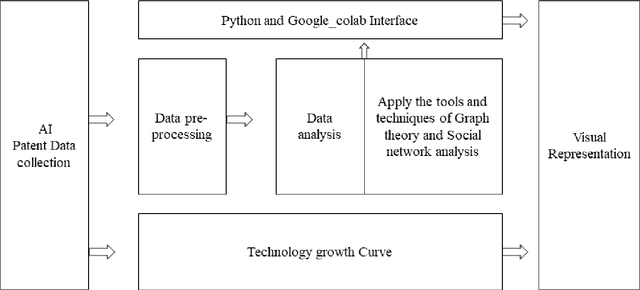
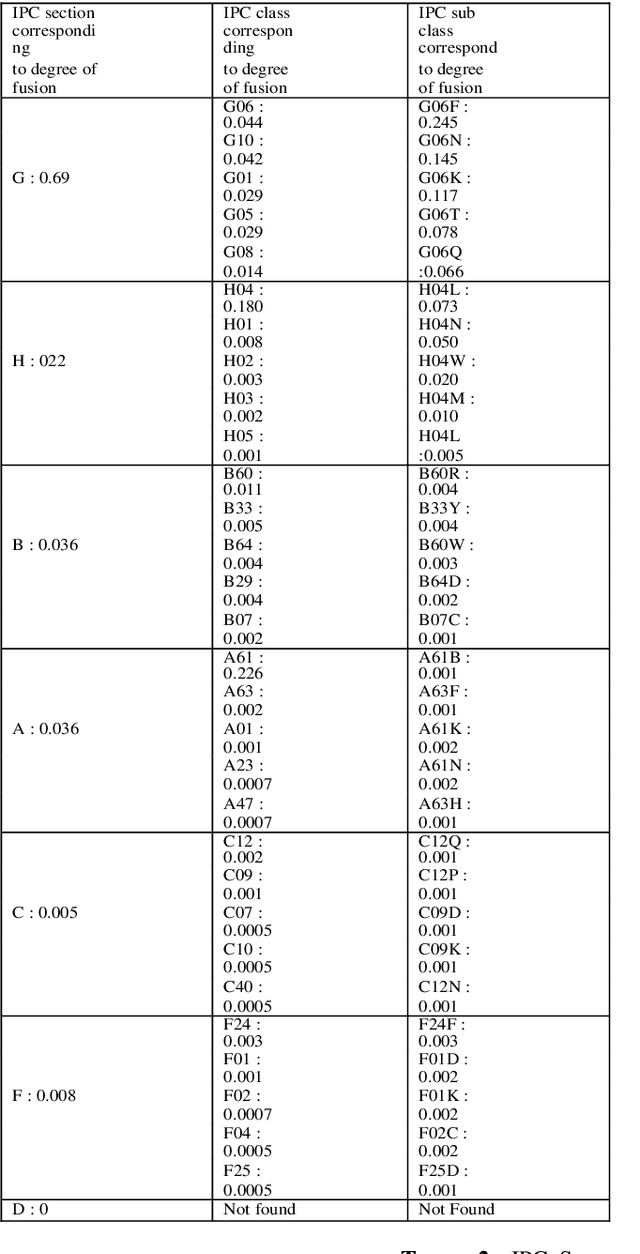
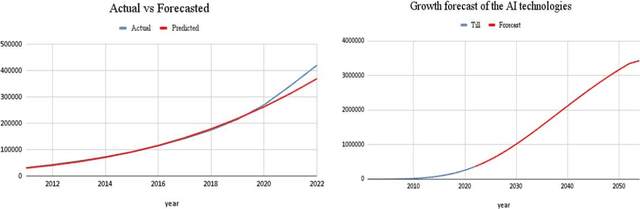
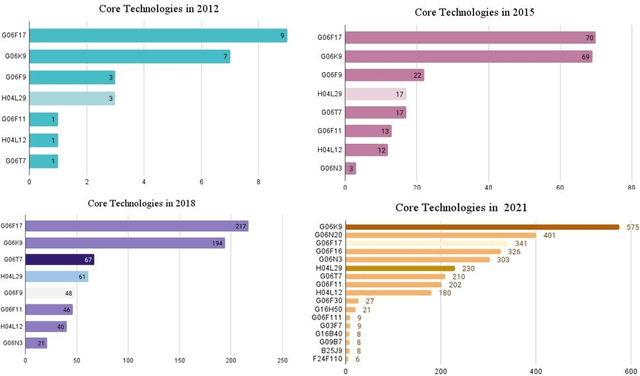
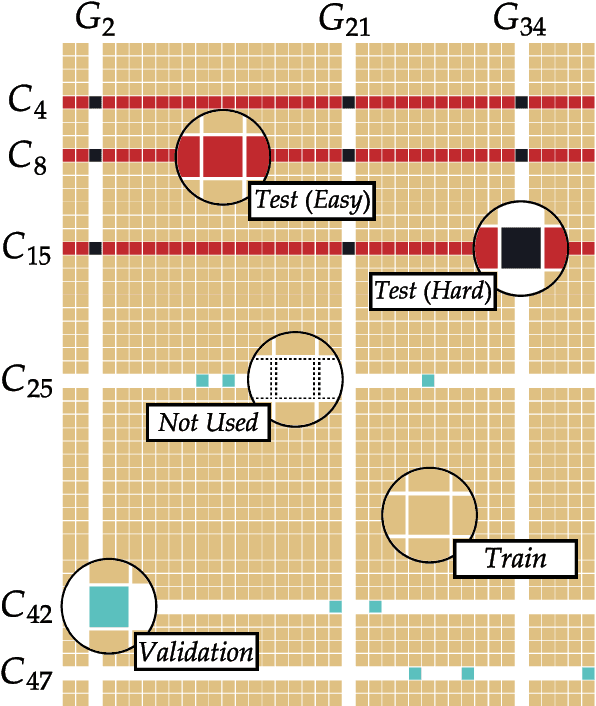
This paper presents a study of the interconnectivity and interdependence of various Artificial intelligence (AI) technologies through the use of centrality measures, clustering coefficients, and degree of fusion measures. By analyzing the technologies through different time windows and quantifying their importance, we have revealed important insights into the crucial components shaping the AI landscape and the maturity level of the domain. The results of this study have significant implications for future development and advancements in artificial intelligence and provide a clear understanding of key technology areas of fusion. Furthermore, this paper contributes to AI public policy research by offering a data-driven perspective on the current state and future direction of the field. However, it is important to acknowledge the limitations of this research and call for further studies to build on these results. With these findings, we hope to inform and guide future research in the field of AI, contributing to its continued growth and success.
HKNAS: Classification of Hyperspectral Imagery Based on Hyper Kernel Neural Architecture Search
Apr 23, 2023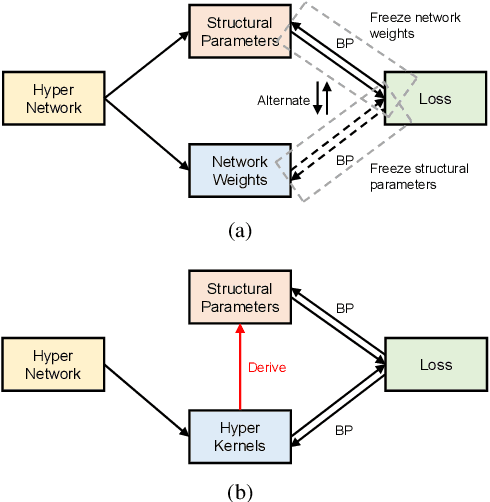
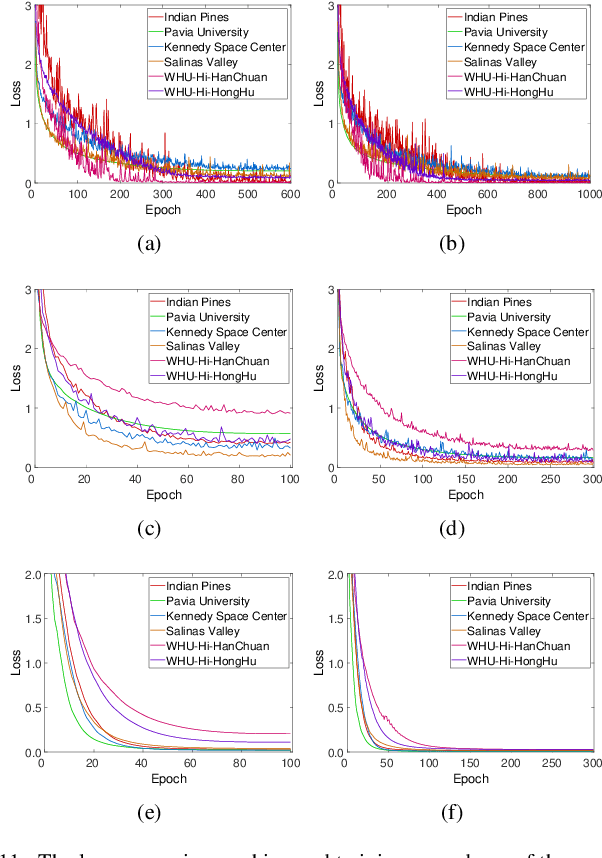
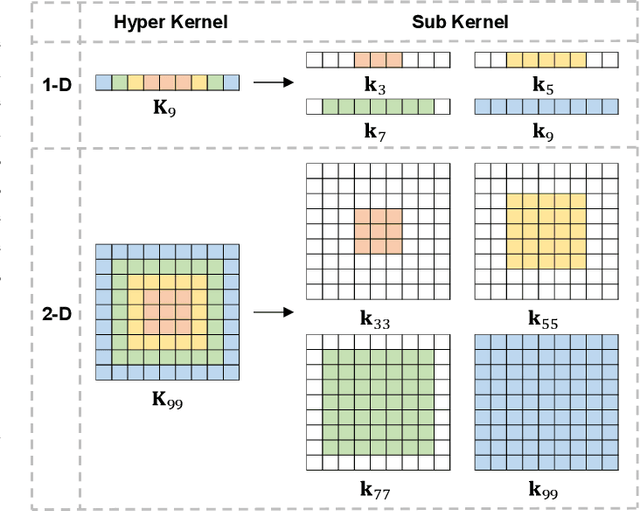
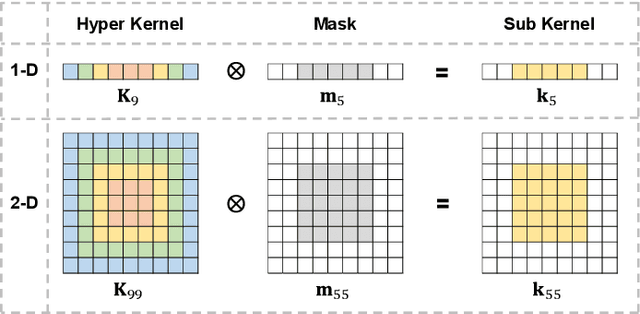
Recent neural architecture search (NAS) based approaches have made great progress in hyperspectral image (HSI) classification tasks. However, the architectures are usually optimized independently of the network weights, increasing searching time and restricting model performances. To tackle these issues, in this paper, different from previous methods that extra define structural parameters, we propose to directly generate structural parameters by utilizing the specifically designed hyper kernels, ingeniously converting the original complex dual optimization problem into easily implemented one-tier optimizations, and greatly shrinking searching costs. Then, we develop a hierarchical multi-module search space whose candidate operations only contain convolutions, and these operations can be integrated into unified kernels. Using the above searching strategy and searching space, we obtain three kinds of networks to separately conduct pixel-level or image-level classifications with 1-D or 3-D convolutions. In addition, by combining the proposed hyper kernel searching scheme with the 3-D convolution decomposition mechanism, we obtain diverse architectures to simulate 3-D convolutions, greatly improving network flexibilities. A series of quantitative and qualitative experiments on six public datasets demonstrate that the proposed methods achieve state-of-the-art results compared with other advanced NAS-based HSI classification approaches.
How to Control Hydrodynamic Force on Fluidic Pinball via Deep Reinforcement Learning
Apr 23, 2023Deep reinforcement learning (DRL) for fluidic pinball, three individually rotating cylinders in the uniform flow arranged in an equilaterally triangular configuration, can learn the efficient flow control strategies due to the validity of self-learning and data-driven state estimation for complex fluid dynamic problems. In this work, we present a DRL-based real-time feedback strategy to control the hydrodynamic force on fluidic pinball, i.e., force extremum and tracking, from cylinders' rotation. By adequately designing reward functions and encoding historical observations, and after automatic learning of thousands of iterations, the DRL-based control was shown to make reasonable and valid control decisions in nonparametric control parameter space, which is comparable to and even better than the optimal policy found through lengthy brute-force searching. Subsequently, one of these results was analyzed by a machine learning model that enabled us to shed light on the basis of decision-making and physical mechanisms of the force tracking process. The finding from this work can control hydrodynamic force on the operation of fluidic pinball system and potentially pave the way for exploring efficient active flow control strategies in other complex fluid dynamic problems.
TSGCNeXt: Dynamic-Static Multi-Graph Convolution for Efficient Skeleton-Based Action Recognition with Long-term Learning Potential
Apr 23, 2023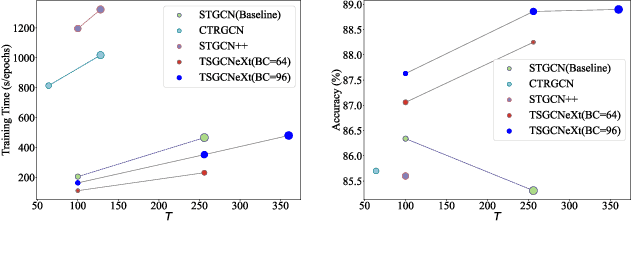
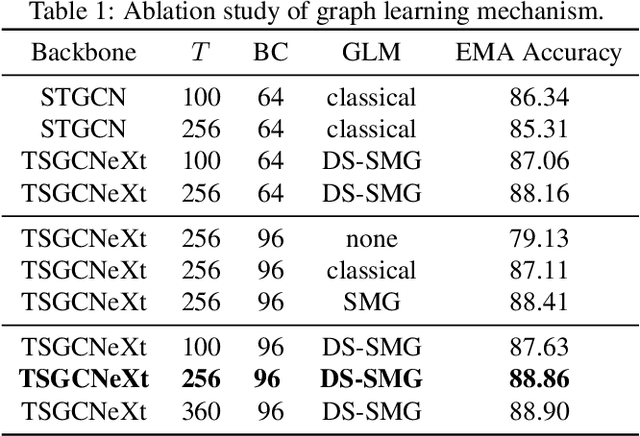
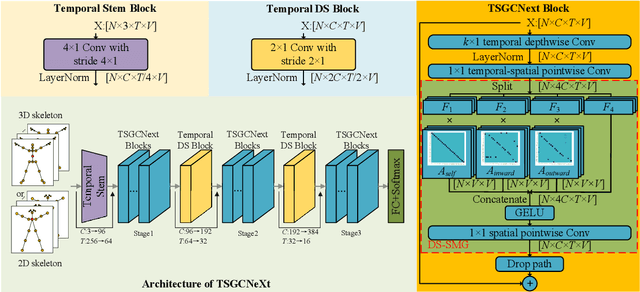
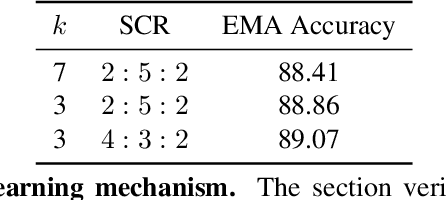
Skeleton-based action recognition has achieved remarkable results in human action recognition with the development of graph convolutional networks (GCNs). However, the recent works tend to construct complex learning mechanisms with redundant training and exist a bottleneck for long time-series. To solve these problems, we propose the Temporal-Spatio Graph ConvNeXt (TSGCNeXt) to explore efficient learning mechanism of long temporal skeleton sequences. Firstly, a new graph learning mechanism with simple structure, Dynamic-Static Separate Multi-graph Convolution (DS-SMG) is proposed to aggregate features of multiple independent topological graphs and avoid the node information being ignored during dynamic convolution. Next, we construct a graph convolution training acceleration mechanism to optimize the back-propagation computing of dynamic graph learning with 55.08\% speed-up. Finally, the TSGCNeXt restructure the overall structure of GCN with three Spatio-temporal learning modules,efficiently modeling long temporal features. In comparison with existing previous methods on large-scale datasets NTU RGB+D 60 and 120, TSGCNeXt outperforms on single-stream networks. In addition, with the ema model introduced into the multi-stream fusion, TSGCNeXt achieves SOTA levels. On the cross-subject and cross-set of the NTU 120, accuracies reach 90.22% and 91.74%.