 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AIRCADE: an Anechoic and IR Convolution-based Auralization Data-compilation Ensemble
Apr 18, 2023
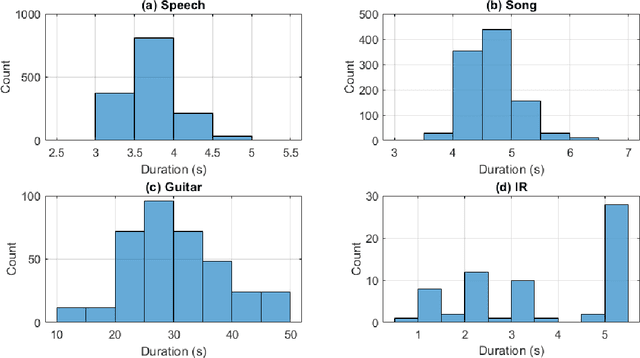
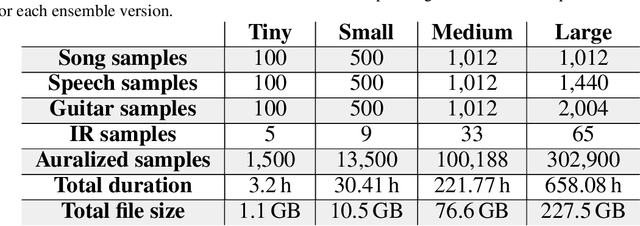
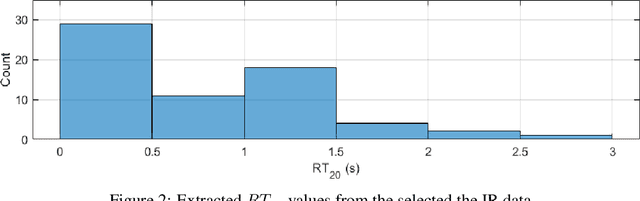
In this paper, we introduce a data-compilation ensemble, primarily intended to serve as a resource for researchers in the field of dereverberation, particularly for data-driven approaches. It comprises speech and song samples, together with acoustic guitar sounds, with original annotations pertinent to emotion recognition and Music Information Retrieval (MIR). Moreover, it includes a selection of impulse response (IR) samples with varying Reverberation Time (RT) values, providing a wide range of conditions for evaluation. This data-compilation can be used together with provided Python scripts, for generating auralized data ensembles in different sizes: tiny, small, medium and large. Additionally, the provided metadata annotations also allow for further analysis and investigation of the performance of dereverberation algorithms under different conditions. All data is licensed under Creative Commons Attribution 4.0 International License.
Early Detection of Parkinson's Disease using Motor Symptoms and Machine Learning
Apr 18, 2023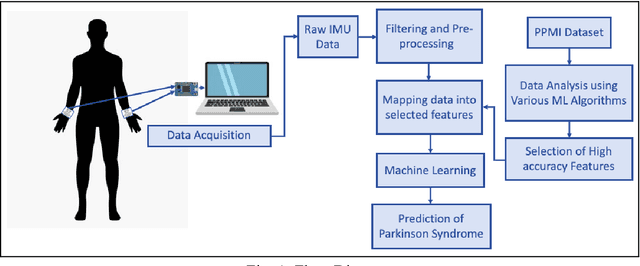
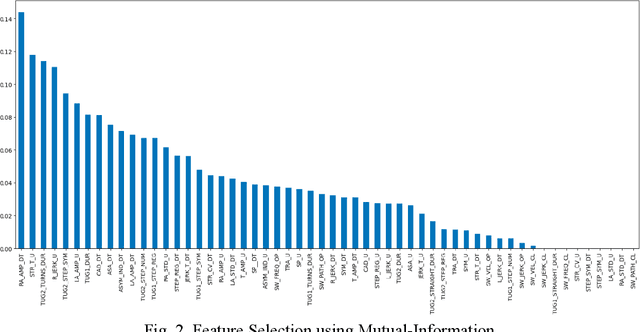
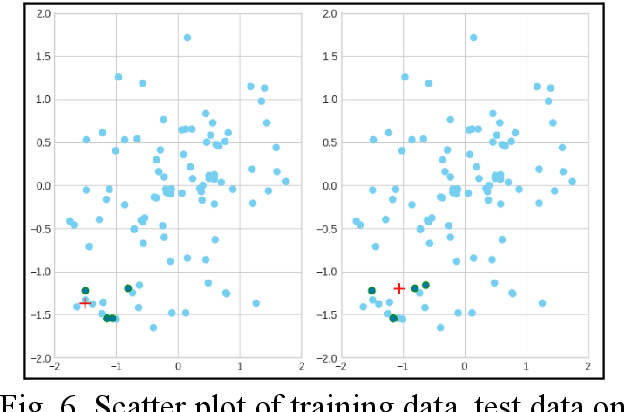
Parkinson's disease (PD) has been found to affect 1 out of every 1000 people, being more inclined towards the population above 60 years. Leveraging wearable-systems to find accurate biomarkers for diagnosis has become the need of the hour, especially for a neurodegenerative condition like Parkinson's. This work aims at focusing on early-occurring, common symptoms, such as motor and gait related parameters to arrive at a quantitative analysis on the feasibility of an economical and a robust wearable device. A subset of the Parkinson's Progression Markers Initiative (PPMI), PPMI Gait dataset has been utilised for feature-selection after a thorough analysis with various Machine Learning algorithms. Identified influential features has then been used to test real-time data for early detection of Parkinson Syndrome, with a model accuracy of 91.9%
Fairness in AI and Its Long-Term Implications on Society
Apr 16, 2023
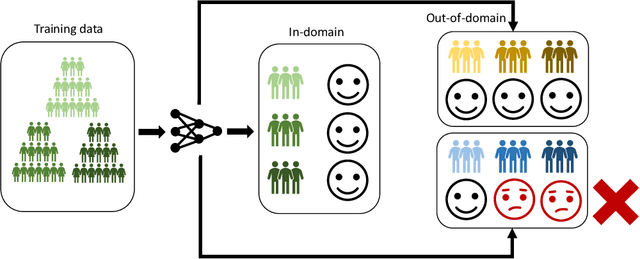

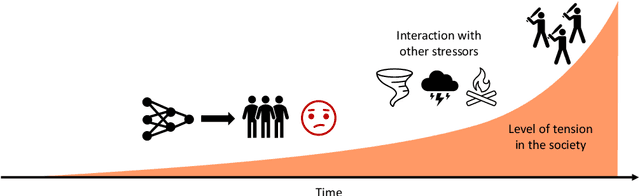
Successful deployment of artificial intelligence (AI) in various settings has led to numerous positive outcomes for individuals and society. However, AI systems have also been shown to harm parts of the population due to biased predictions. We take a closer look at AI fairness and analyse how lack of AI fairness can lead to deepening of biases over time and act as a social stressor. If the issues persist, it could have undesirable long-term implications on society, reinforced by interactions with other risks. We examine current strategies for improving AI fairness, assess their limitations in terms of real-world deployment, and explore potential paths forward to ensure we reap AI's benefits without harming significant parts of the society.
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Mar 27, 2023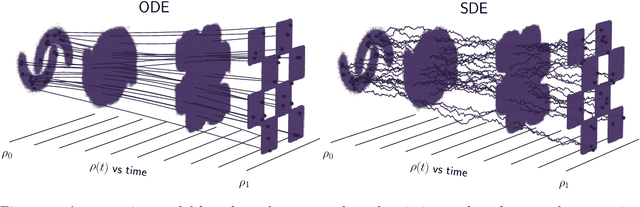
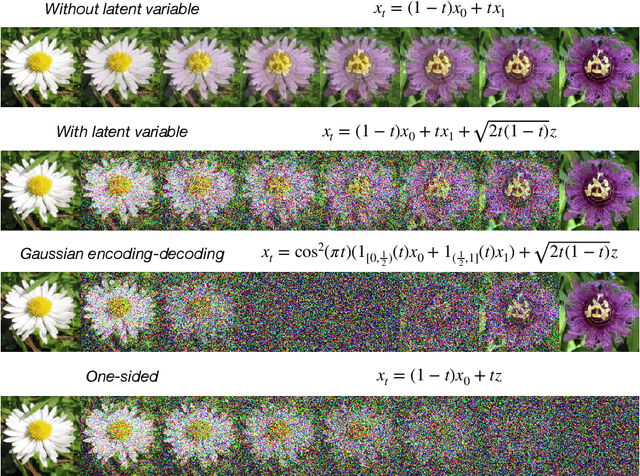
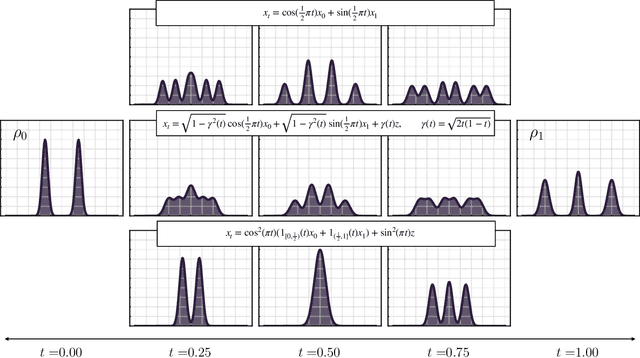
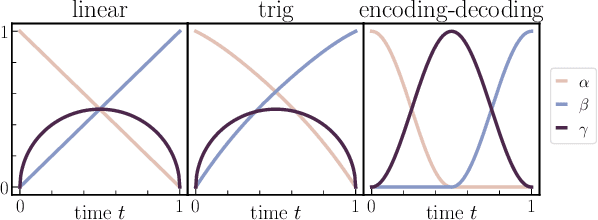
A class of generative models that unifies flow-based and diffusion-based methods is introduced. These models extend the framework proposed in Albergo & Vanden-Eijnden (2023), enabling the use of a broad class of continuous-time stochastic processes called `stochastic interpolants' to bridge any two arbitrary probability density functions exactly in finite time. These interpolants are built by combining data from the two prescribed densities with an additional latent variable that shapes the bridge in a flexible way. The time-dependent probability density function of the stochastic interpolant is shown to satisfy a first-order transport equation as well as a family of forward and backward Fokker-Planck equations with tunable diffusion. Upon consideration of the time evolution of an individual sample, this viewpoint immediately leads to both deterministic and stochastic generative models based on probability flow equations or stochastic differential equations with an adjustable level of noise. The drift coefficients entering these models are time-dependent velocity fields characterized as the unique minimizers of simple quadratic objective functions, one of which is a new objective for the score of the interpolant density. Remarkably, we show that minimization of these quadratic objectives leads to control of the likelihood for any of our generative models built upon stochastic dynamics. By contrast, we establish that generative models based upon a deterministic dynamics must, in addition, control the Fisher divergence between the target and the model. We also construct estimators for the likelihood and the cross-entropy of interpolant-based generative models, discuss connections with other stochastic bridges, and demonstrate that such models recover the Schr\"odinger bridge between the two target densities when explicitly optimizing over the interpolant.
Cardiac Arrhythmia Detection using Artificial Neural Network
Apr 17, 2023The prime purpose of this project is to develop a portable cardiac abnormality monitoring device which can drastically improvise the quality of the monitoring and the overall safety of the device. While a generic, low cost, wearable battery powered device for such applications may not yield sufficient performance, such devices combined with the capabilities of Artificial Neural Network algorithms can however, prove to be as competent as high end flexible and wearable monitoring devices fabricated using advanced manufacturing technologies. This paper evaluates the feasibility of the Levenberg-Marquardt ANN algorithm for use in any generic low power wearable devices implemented either as a pure real-time embedded system or as an IoT device capable of uploading the monitored readings to the cloud.
Snacks: a fast large-scale kernel SVM solver
Apr 17, 2023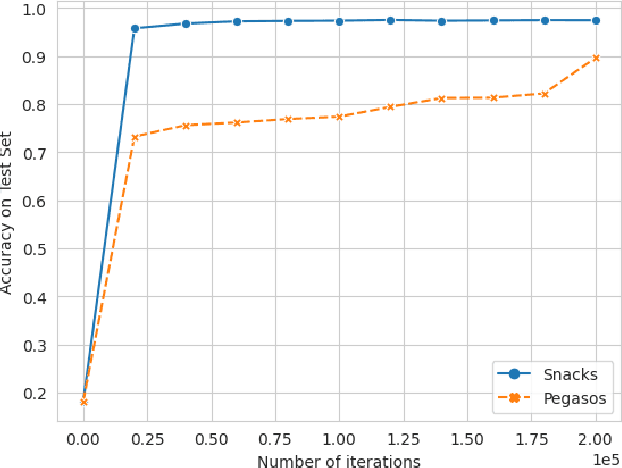
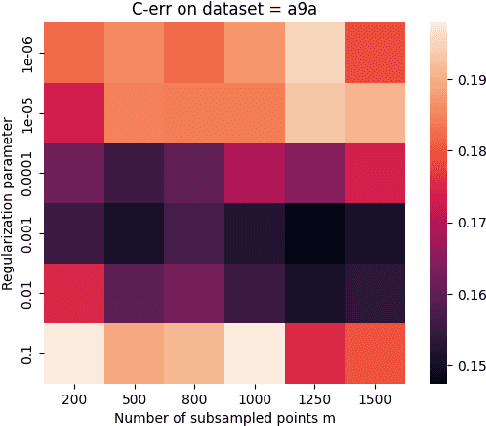

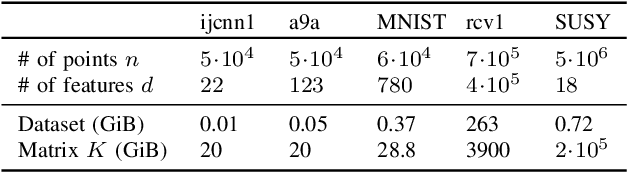
Kernel methods provide a powerful framework for non parametric learning. They are based on kernel functions and allow learning in a rich functional space while applying linear statistical learning tools, such as Ridge Regression or Support Vector Machines. However, standard kernel methods suffer from a quadratic time and memory complexity in the number of data points and thus have limited applications in large-scale learning. In this paper, we propose Snacks, a new large-scale solver for Kernel Support Vector Machines. Specifically, Snacks relies on a Nystr\"om approximation of the kernel matrix and an accelerated variant of the stochastic subgradient method. We demonstrate formally through a detailed empirical evaluation, that it competes with other SVM solvers on a variety of benchmark datasets.
Detecting Backdoors During the Inference Stage Based on Corruption Robustness Consistency
Mar 27, 2023
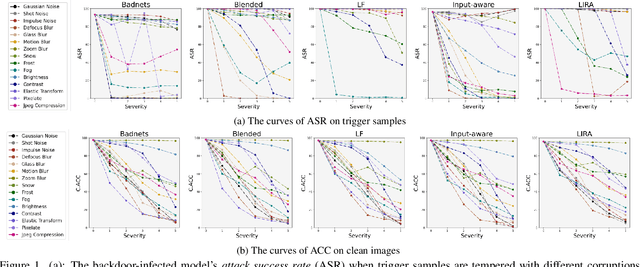
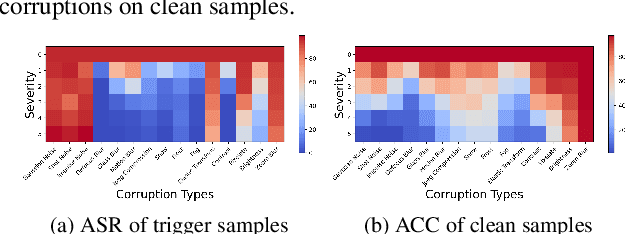
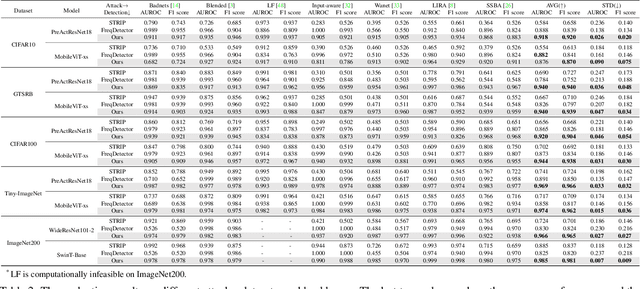
Deep neural networks are proven to be vulnerable to backdoor attacks. Detecting the trigger samples during the inference stage, i.e., the test-time trigger sample detection, can prevent the backdoor from being triggered. However, existing detection methods often require the defenders to have high accessibility to victim models, extra clean data, or knowledge about the appearance of backdoor triggers, limiting their practicality. In this paper, we propose the test-time corruption robustness consistency evaluation (TeCo), a novel test-time trigger sample detection method that only needs the hard-label outputs of the victim models without any extra information. Our journey begins with the intriguing observation that the backdoor-infected models have similar performance across different image corruptions for the clean images, but perform discrepantly for the trigger samples. Based on this phenomenon, we design TeCo to evaluate test-time robustness consistency by calculating the deviation of severity that leads to predictions' transition across different corruptions. Extensive experiments demonstrate that compared with state-of-the-art defenses, which even require either certain information about the trigger types or accessibility of clean data, TeCo outperforms them on different backdoor attacks, datasets, and model architectures, enjoying a higher AUROC by 10% and 5 times of stability.
HyMo: Vulnerability Detection in Smart Contracts using a Novel Multi-Modal Hybrid Model
Apr 25, 2023

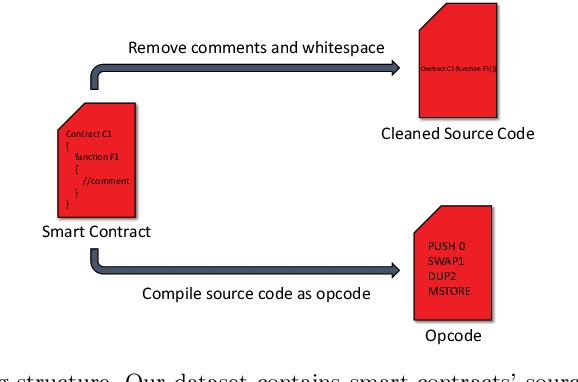
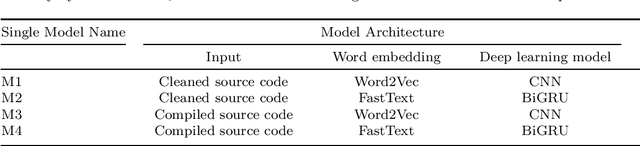
With blockchain technology rapidly progress, the smart contracts have become a common tool in a number of industries including finance, healthcare, insurance and gaming. The number of smart contracts has multiplied, and at the same time, the security of smart contracts has drawn considerable attention due to the monetary losses brought on by smart contract vulnerabilities. Existing analysis techniques are capable of identifying a large number of smart contract security flaws, but they rely too much on rigid criteria established by specialists, where the detection process takes much longer as the complexity of the smart contract rises. In this paper, we propose HyMo as a multi-modal hybrid deep learning model, which intelligently considers various input representations to consider multimodality and FastText word embedding technique, which represents each word as an n-gram of characters with BiGRU deep learning technique, as a sequence processing model that consists of two GRUs to achieve higher accuracy in smart contract vulnerability detection. The model gathers features using various deep learning models to identify the smart contract vulnerabilities. Through a series of studies on the currently publicly accessible dataset such as ScrawlD, we show that our hybrid HyMo model has excellent smart contract vulnerability detection performance. Therefore, HyMo performs better detection of smart contract vulnerabilities against other approaches.
SAFE: Machine Unlearning With Shard Graphs
Apr 25, 2023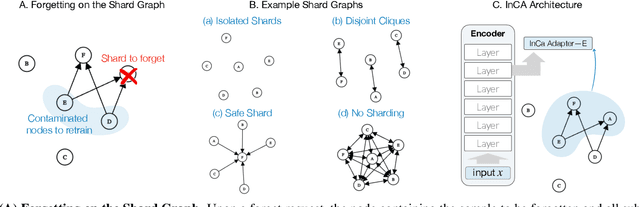
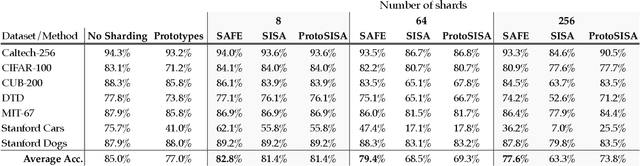
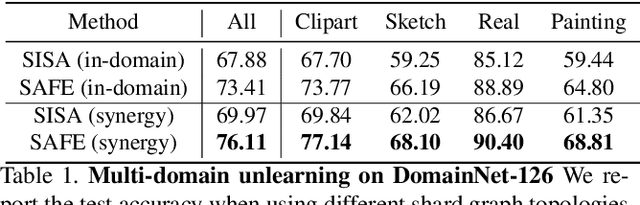
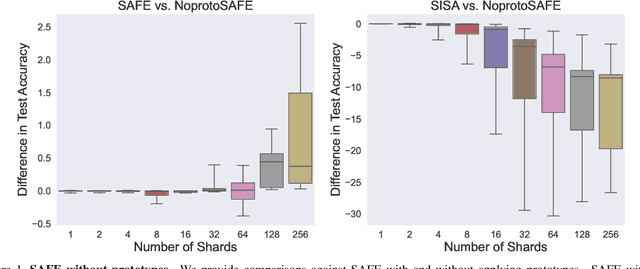
We present Synergy Aware Forgetting Ensemble (SAFE), a method to adapt large models on a diverse collection of data while minimizing the expected cost to remove the influence of training samples from the trained model. This process, also known as selective forgetting or unlearning, is often conducted by partitioning a dataset into shards, training fully independent models on each, then ensembling the resulting models. Increasing the number of shards reduces the expected cost to forget but at the same time it increases inference cost and reduces the final accuracy of the model since synergistic information between samples is lost during the independent model training. Rather than treating each shard as independent, SAFE introduces the notion of a shard graph, which allows incorporating limited information from other shards during training, trading off a modest increase in expected forgetting cost with a significant increase in accuracy, all while still attaining complete removal of residual influence after forgetting. SAFE uses a lightweight system of adapters which can be trained while reusing most of the computations. This allows SAFE to be trained on shards an order-of-magnitude smaller than current state-of-the-art methods (thus reducing the forgetting costs) while also maintaining high accuracy, as we demonstrate empirically on fine-grained computer vision datasets.
Application of Segment Anything Model for Civil Infrastructure Defect Assessment
Apr 25, 2023
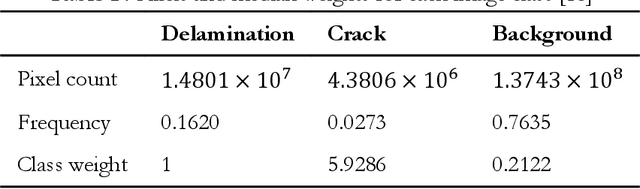

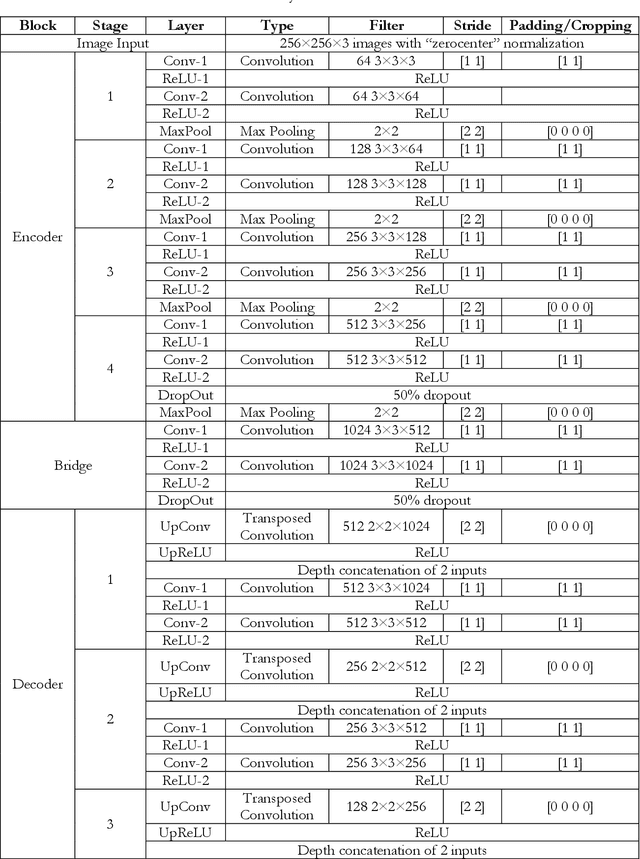
This research assesses the performance of two deep learning models, SAM and U-Net, for detecting cracks in concrete structures. The results indicate that each model has its own strengths and limitations for detecting different types of cracks. Using the SAM's unique crack detection approach, the image is divided into various parts that identify the location of the crack, making it more effective at detecting longitudinal cracks. On the other hand, the U-Net model can identify positive label pixels to accurately detect the size and location of spalling cracks. By combining both models, more accurate and comprehensive crack detection results can be achieved. The importance of using advanced technologies for crack detection in ensuring the safety and longevity of concrete structures cannot be overstated. This research can have significant implications for civil engineering, as the SAM and U-Net model can be used for a variety of concrete structures, including bridges, buildings, and roads, improving the accuracy and efficiency of crack detection and saving time and resources in maintenance and repair. In conclusion, the SAM and U-Net model presented in this study offer promising solutions for detecting cracks in concrete structures and leveraging the strengths of both models that can lead to more accurate and comprehensive results.