 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GULP: Solar-Powered Smart Garbage Segregation Bins with SMS Notification and Machine Learning Image Processing
Apr 25, 2023
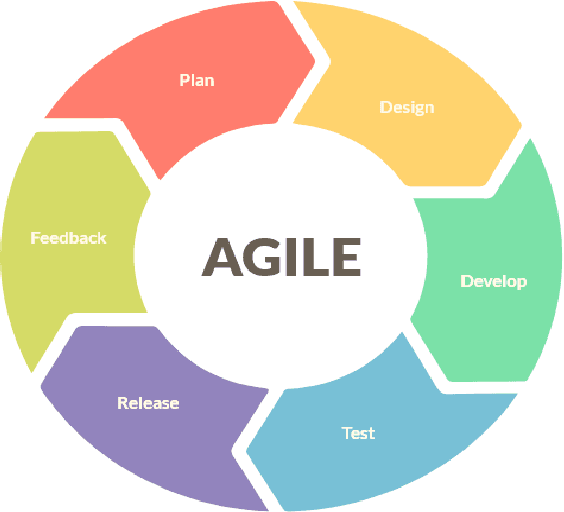
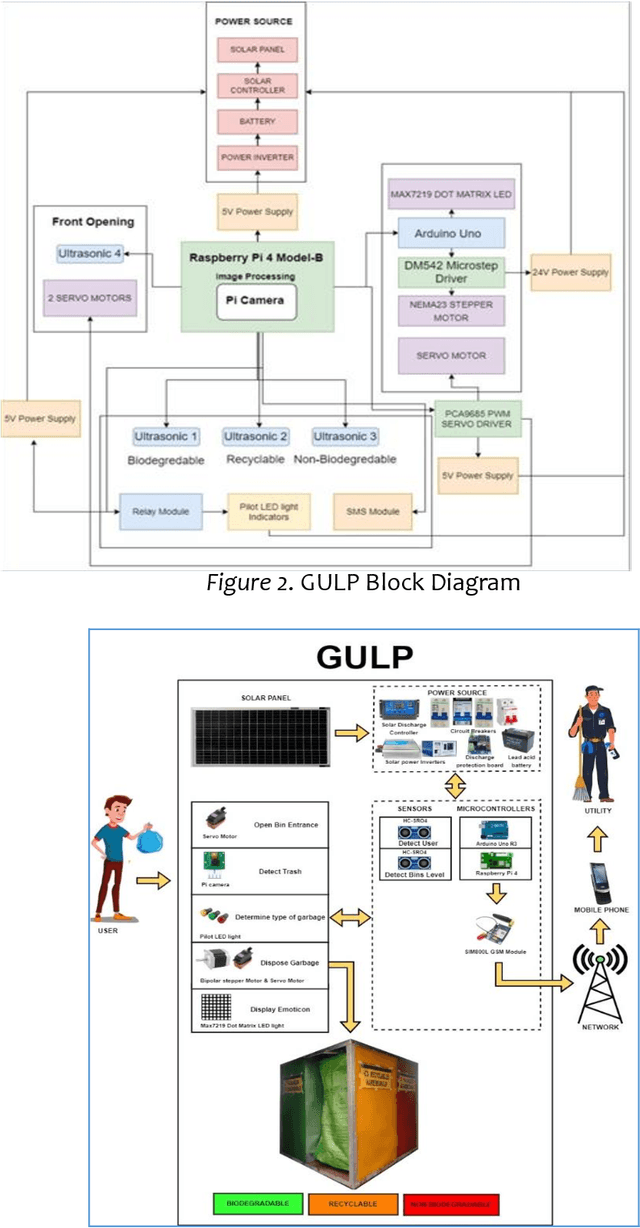
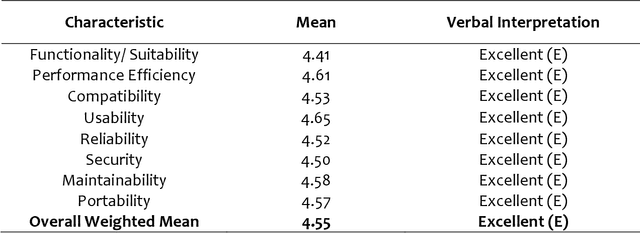
This study intends to build a smartbin that segregates solid waste into its respective bins. To make the waste management process more interesting for the end-users; to notify the utility staff when the smart bin needs to be unloaded; to encourage an environment-friendly smart bin by utilizing renewable solar energy source. The researchers employed an Agile Development approach because it enables teams to manage their workloads successfully and create the highest-quality product while staying within their allocated budget. The six fundamental phases are planning, design, development, test, release, and feedback. The Overall quality testing result that was provided through the ISO/IEC 25010 evaluation which concludes a positive outcome. The overall average was 4.55, which is verbally interpreted as excellent. Additionally, the application can also independently run with its solar energy source. Users were able to enjoy the whole process of waste disposal through its interesting mechanisms. Based on the findings, a compressor is recommended to compress the trash when the trash level reaches its maximum point to create more rooms for more garbage. An algorithm to determine multiple garbage at a time is also recommended. Adding a solar tracker coupled with solar panel will help produce more renewable energy for the smart bin.
* 19 pages, 6 figures, International Research Conference on Computer Engineering and Technology Education2023 (IRCCETE 2023)
Diffusion Probabilistic Model Based Accurate and High-Degree-of-Freedom Metasurface Inverse Design
Apr 25, 2023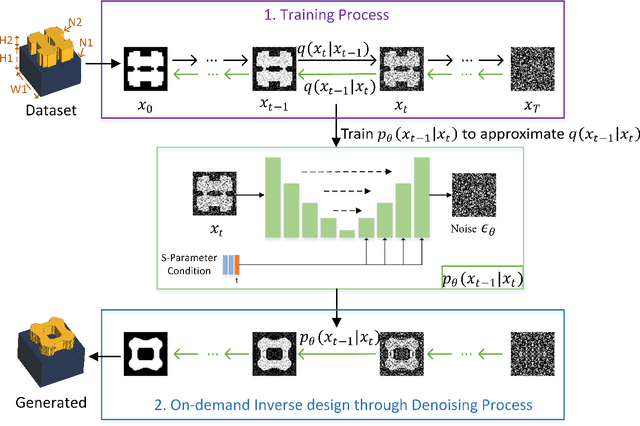
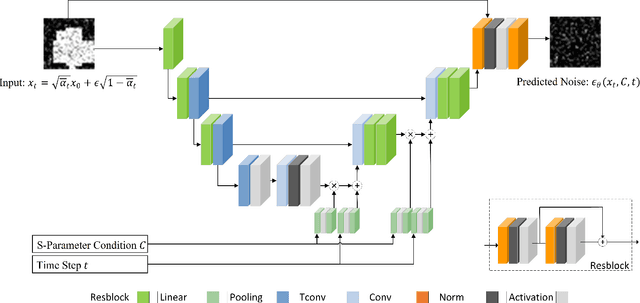
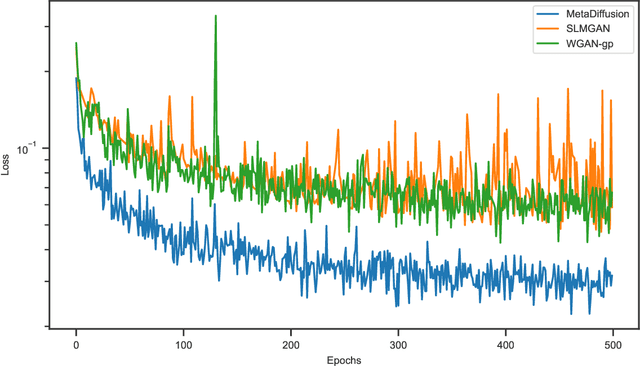
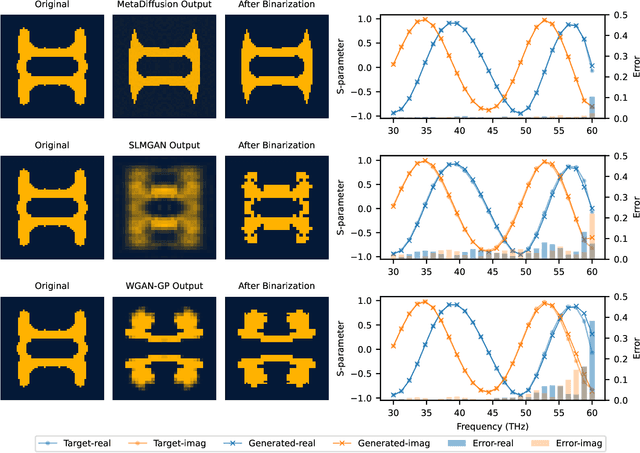
Conventional meta-atom designs rely heavily on researchers' prior knowledge and trial-and-error searches using full-wave simulations, resulting in time-consuming and inefficient processes. Inverse design methods based on optimization algorithms, such as evolutionary algorithms, and topological optimizations, have been introduced to design metamaterials. However, none of these algorithms are general enough to fulfill multi-objective tasks. Recently, deep learning methods represented by Generative Adversarial Networks (GANs) have been applied to inverse design of metamaterials, which can directly generate high-degree-of-freedom meta-atoms based on S-parameter requirements. However, the adversarial training process of GANs makes the network unstable and results in high modeling costs. This paper proposes a novel metamaterial inverse design method based on the diffusion probability theory. By learning the Markov process that transforms the original structure into a Gaussian distribution, the proposed method can gradually remove the noise starting from the Gaussian distribution and generate new high-degree-of-freedom meta-atoms that meet S-parameter conditions, which avoids the model instability introduced by the adversarial training process of GANs and ensures more accurate and high-quality generation results. Experiments have proven that our method is superior to representative methods of GANs in terms of model convergence speed, generation accuracy, and quality.
Out-of-distribution Evidence-aware Fake News Detection via Dual Adversarial Debiasing
Apr 25, 2023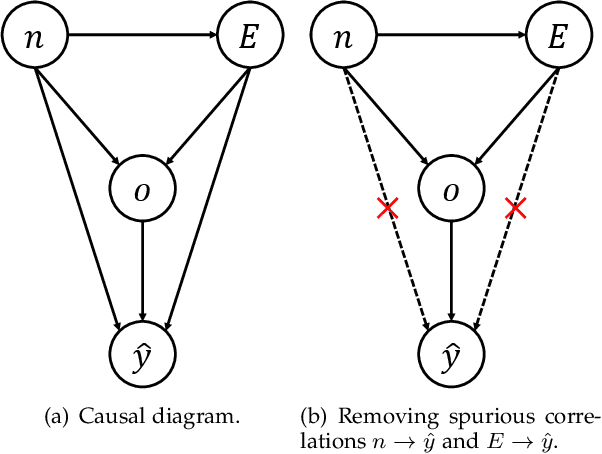

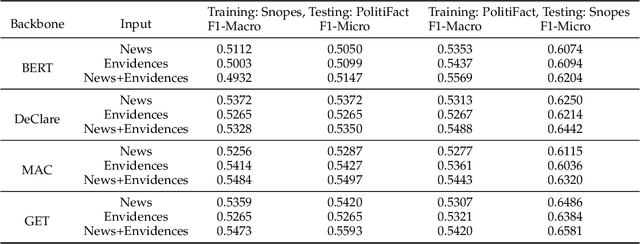
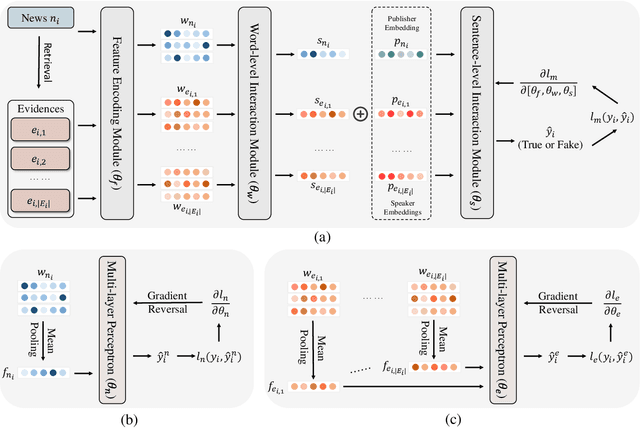
Evidence-aware fake news detection aims to conduct reasoning between news and evidence, which is retrieved based on news content, to find uniformity or inconsistency. However, we find evidence-aware detection models suffer from biases, i.e., spurious correlations between news/evidence contents and true/fake news labels, and are hard to be generalized to Out-Of-Distribution (OOD) situations. To deal with this, we propose a novel Dual Adversarial Learning (DAL) approach. We incorporate news-aspect and evidence-aspect debiasing discriminators, whose targets are both true/fake news labels, in DAL. Then, DAL reversely optimizes news-aspect and evidence-aspect debiasing discriminators to mitigate the impact of news and evidence content biases. At the same time, DAL also optimizes the main fake news predictor, so that the news-evidence interaction module can be learned. This process allows us to teach evidence-aware fake news detection models to better conduct news-evidence reasoning, and minimize the impact of content biases. To be noted, our proposed DAL approach is a plug-and-play module that works well with existing backbones. We conduct comprehensive experiments under two OOD settings, and plug DAL in four evidence-aware fake news detection backbones. Results demonstrate that, DAL significantly and stably outperforms the original backbones and some competitive debiasing methods.
A framework for fully autonomous design of materials via multiobjective optimization and active learning: challenges and next steps
Apr 15, 2023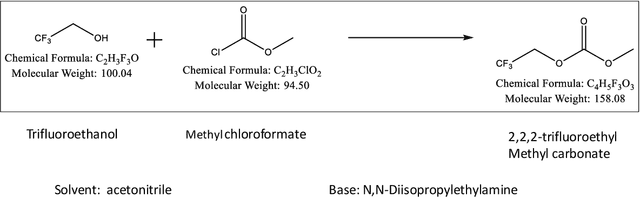
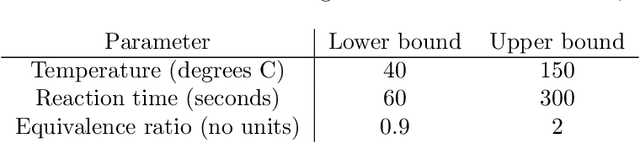
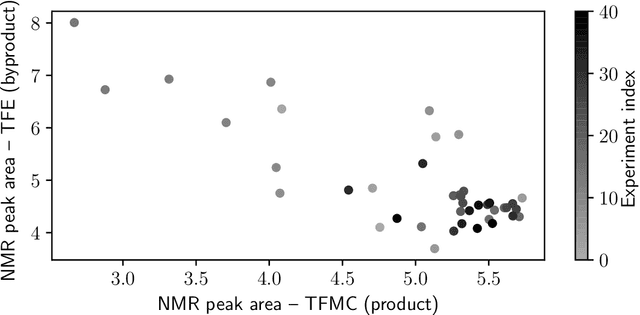
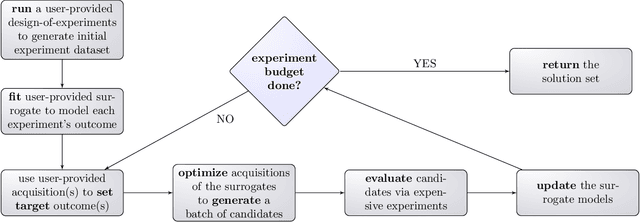
In order to deploy machine learning in a real-world self-driving laboratory where data acquisition is costly and there are multiple competing design criteria, systems need to be able to intelligently sample while balancing performance trade-offs and constraints. For these reasons, we present an active learning process based on multiobjective black-box optimization with continuously updated machine learning models. This workflow is built on open-source technologies for real-time data streaming and modular multiobjective optimization software development. We demonstrate a proof of concept for this workflow through the autonomous operation of a continuous-flow chemistry laboratory, which identifies ideal manufacturing conditions for the electrolyte 2,2,2-trifluoroethyl methyl carbonate.
AIRCADE: an Anechoic and IR Convolution-based Auralization Data-compilation Ensemble
Apr 18, 2023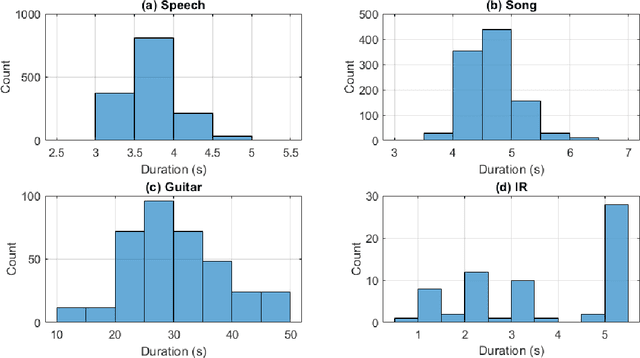
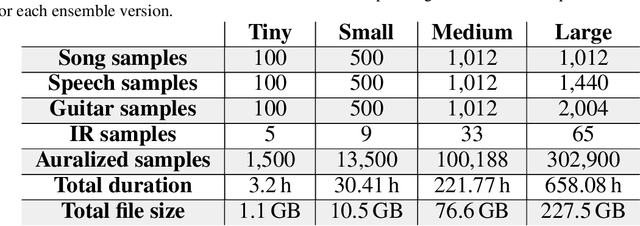
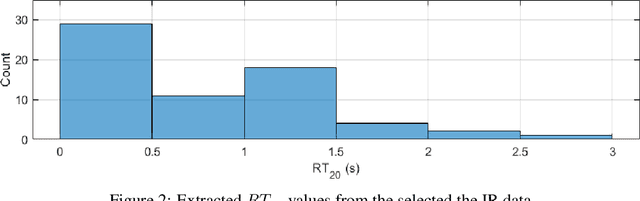
In this paper, we introduce a data-compilation ensemble, primarily intended to serve as a resource for researchers in the field of dereverberation, particularly for data-driven approaches. It comprises speech and song samples, together with acoustic guitar sounds, with original annotations pertinent to emotion recognition and Music Information Retrieval (MIR). Moreover, it includes a selection of impulse response (IR) samples with varying Reverberation Time (RT) values, providing a wide range of conditions for evaluation. This data-compilation can be used together with provided Python scripts, for generating auralized data ensembles in different sizes: tiny, small, medium and large. Additionally, the provided metadata annotations also allow for further analysis and investigation of the performance of dereverberation algorithms under different conditions. All data is licensed under Creative Commons Attribution 4.0 International License.
Early Detection of Parkinson's Disease using Motor Symptoms and Machine Learning
Apr 18, 2023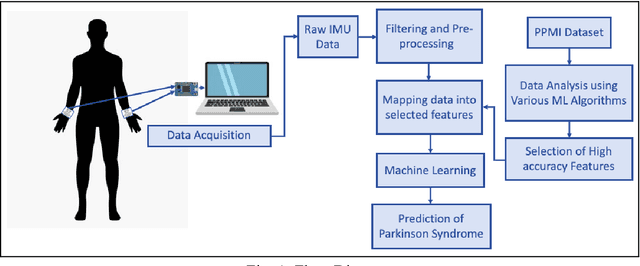
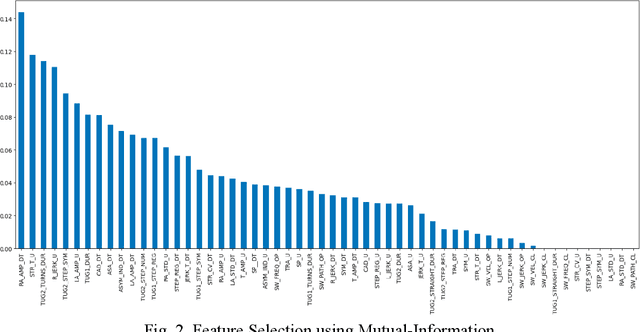
Parkinson's disease (PD) has been found to affect 1 out of every 1000 people, being more inclined towards the population above 60 years. Leveraging wearable-systems to find accurate biomarkers for diagnosis has become the need of the hour, especially for a neurodegenerative condition like Parkinson's. This work aims at focusing on early-occurring, common symptoms, such as motor and gait related parameters to arrive at a quantitative analysis on the feasibility of an economical and a robust wearable device. A subset of the Parkinson's Progression Markers Initiative (PPMI), PPMI Gait dataset has been utilised for feature-selection after a thorough analysis with various Machine Learning algorithms. Identified influential features has then been used to test real-time data for early detection of Parkinson Syndrome, with a model accuracy of 91.9%
Fairness in AI and Its Long-Term Implications on Society
Apr 16, 2023

Successful deployment of artificial intelligence (AI) in various settings has led to numerous positive outcomes for individuals and society. However, AI systems have also been shown to harm parts of the population due to biased predictions. We take a closer look at AI fairness and analyse how lack of AI fairness can lead to deepening of biases over time and act as a social stressor. If the issues persist, it could have undesirable long-term implications on society, reinforced by interactions with other risks. We examine current strategies for improving AI fairness, assess their limitations in terms of real-world deployment, and explore potential paths forward to ensure we reap AI's benefits without harming significant parts of the society.
Cardiac Arrhythmia Detection using Artificial Neural Network
Apr 17, 2023The prime purpose of this project is to develop a portable cardiac abnormality monitoring device which can drastically improvise the quality of the monitoring and the overall safety of the device. While a generic, low cost, wearable battery powered device for such applications may not yield sufficient performance, such devices combined with the capabilities of Artificial Neural Network algorithms can however, prove to be as competent as high end flexible and wearable monitoring devices fabricated using advanced manufacturing technologies. This paper evaluates the feasibility of the Levenberg-Marquardt ANN algorithm for use in any generic low power wearable devices implemented either as a pure real-time embedded system or as an IoT device capable of uploading the monitored readings to the cloud.
Snacks: a fast large-scale kernel SVM solver
Apr 17, 2023
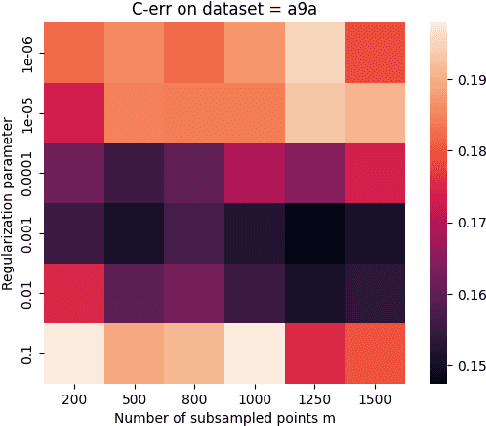

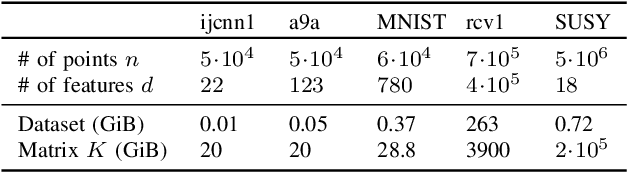
Kernel methods provide a powerful framework for non parametric learning. They are based on kernel functions and allow learning in a rich functional space while applying linear statistical learning tools, such as Ridge Regression or Support Vector Machines. However, standard kernel methods suffer from a quadratic time and memory complexity in the number of data points and thus have limited applications in large-scale learning. In this paper, we propose Snacks, a new large-scale solver for Kernel Support Vector Machines. Specifically, Snacks relies on a Nystr\"om approximation of the kernel matrix and an accelerated variant of the stochastic subgradient method. We demonstrate formally through a detailed empirical evaluation, that it competes with other SVM solvers on a variety of benchmark datasets.
Longitudinal Multimodal Transformer Integrating Imaging and Latent Clinical Signatures From Routine EHRs for Pulmonary Nodule Classification
Apr 10, 2023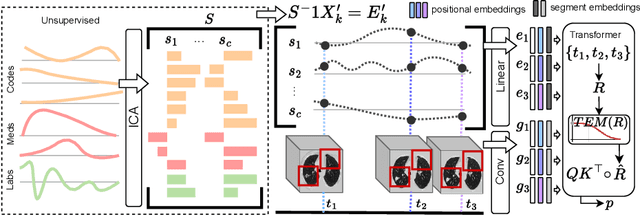
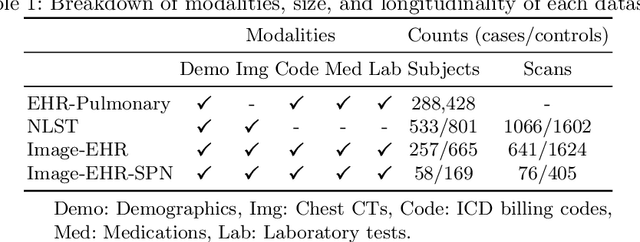
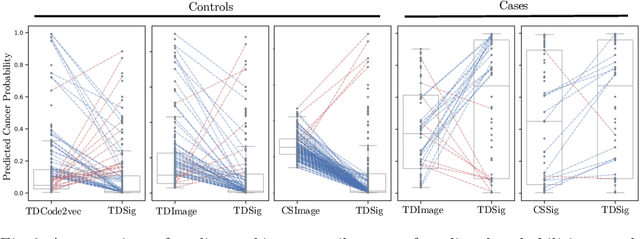
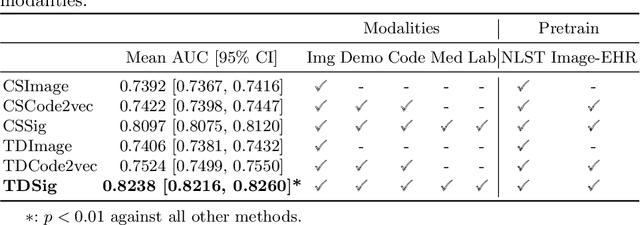
The accuracy of predictive models for solitary pulmonary nodule (SPN) diagnosis can be greatly increased by incorporating repeat imaging and medical context, such as electronic health records (EHRs). However, clinically routine modalities such as imaging and diagnostic codes can be asynchronous and irregularly sampled over different time scales which are obstacles to longitudinal multimodal learning. In this work, we propose a transformer-based multimodal strategy to integrate repeat imaging with longitudinal clinical signatures from routinely collected EHRs for SPN classification. We perform unsupervised disentanglement of latent clinical signatures and leverage time-distance scaled self-attention to jointly learn from clinical signatures expressions and chest computed tomography (CT) scans. Our classifier is pretrained on 2,668 scans from a public dataset and 1,149 subjects with longitudinal chest CTs, billing codes, medications, and laboratory tests from EHRs of our home institution. Evaluation on 227 subjects with challenging SPNs revealed a significant AUC improvement over a longitudinal multimodal baseline (0.824 vs 0.752 AUC), as well as improvements over a single cross-section multimodal scenario (0.809 AUC) and a longitudinal imaging-only scenario (0.741 AUC). This work demonstrates significant advantages with a novel approach for co-learning longitudinal imaging and non-imaging phenotypes with transformers.