 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LD-GAN: Low-Dimensional Generative Adversarial Network for Spectral Image Generation with Variance Regularization
Apr 29, 2023
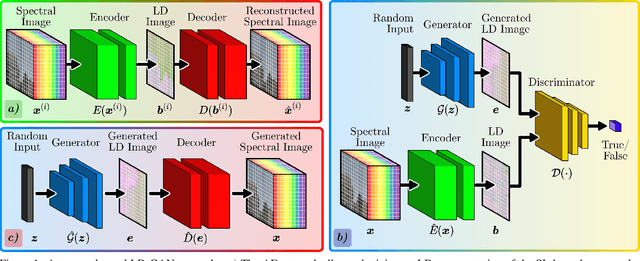
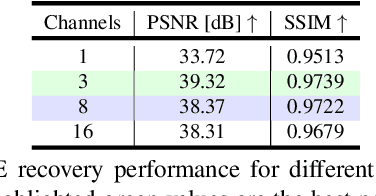

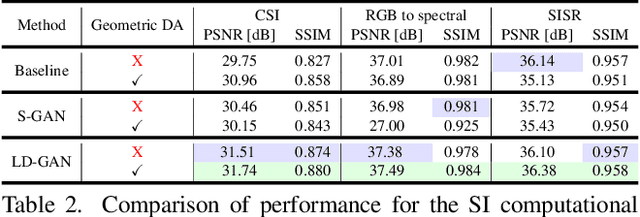
Deep learning methods are state-of-the-art for spectral image (SI) computational tasks. However, these methods are constrained in their performance since available datasets are limited due to the highly expensive and long acquisition time. Usually, data augmentation techniques are employed to mitigate the lack of data. Surpassing classical augmentation methods, such as geometric transformations, GANs enable diverse augmentation by learning and sampling from the data distribution. Nevertheless, GAN-based SI generation is challenging since the high-dimensionality nature of this kind of data hinders the convergence of the GAN training yielding to suboptimal generation. To surmount this limitation, we propose low-dimensional GAN (LD-GAN), where we train the GAN employing a low-dimensional representation of the {dataset} with the latent space of a pretrained autoencoder network. Thus, we generate new low-dimensional samples which are then mapped to the SI dimension with the pretrained decoder network. Besides, we propose a statistical regularization to control the low-dimensional representation variance for the autoencoder training and to achieve high diversity of samples generated with the GAN. We validate our method LD-GAN as data augmentation strategy for compressive spectral imaging, SI super-resolution, and RBG to spectral tasks with improvements varying from 0.5 to 1 [dB] in each task respectively. We perform comparisons against the non-data augmentation training, traditional DA, and with the same GAN adjusted and trained to generate the full-sized SIs. The code of this paper can be found in https://github.com/romanjacome99/LD_GAN.git
Brain Tumor Segmentation from MRI Images using Deep Learning Techniques
Apr 29, 2023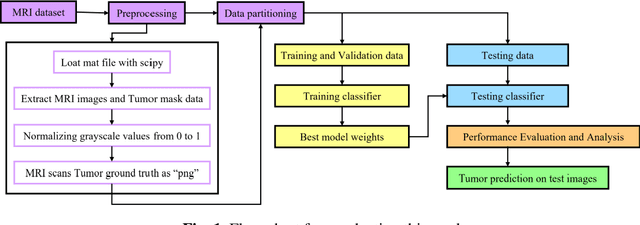
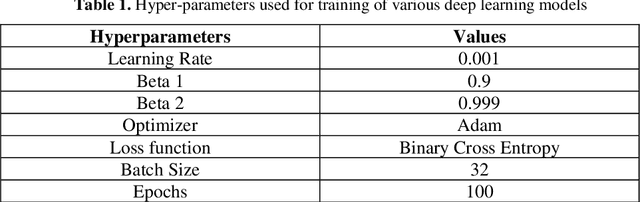
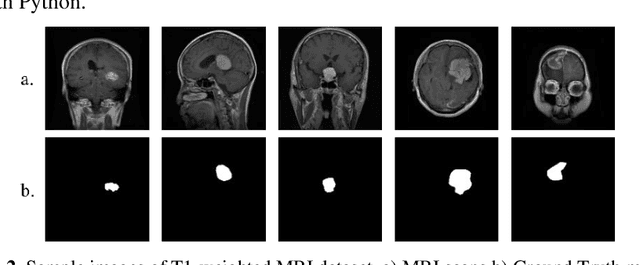
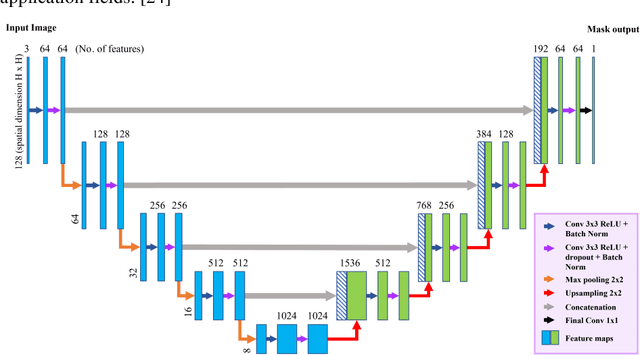
A brain tumor, whether benign or malignant, can potentially be life threatening and requires painstaking efforts in order to identify the type, origin and location, let alone cure one. Manual segmentation by medical specialists can be time-consuming, which calls out for the involvement of technology to hasten the process with high accuracy. For the purpose of medical image segmentation, we inspected and identified the capable deep learning model, which shows consistent results in the dataset used for brain tumor segmentation. In this study, a public MRI imaging dataset contains 3064 TI-weighted images from 233 patients with three variants of brain tumor, viz. meningioma, glioma, and pituitary tumor. The dataset files were converted and preprocessed before indulging into the methodology which employs implementation and training of some well-known image segmentation deep learning models like U-Net & Attention U-Net with various backbones, Deep Residual U-Net, ResUnet++ and Recurrent Residual U-Net. with varying parameters, acquired from our review of the literature related to human brain tumor classification and segmentation. The experimental findings showed that among all the applied approaches, the recurrent residual U-Net which uses Adam optimizer reaches a Mean Intersection Over Union of 0.8665 and outperforms other compared state-of-the-art deep learning models. The visual findings also show the remarkable results of the brain tumor segmentation from MRI scans and demonstrates how useful the algorithm will be for physicians to extract the brain cancers automatically from MRI scans and serve humanity.
STAR-RIS-Aided Mobile Edge Computing: Computation Rate Maximization with Binary Amplitude Coefficients
Apr 30, 2023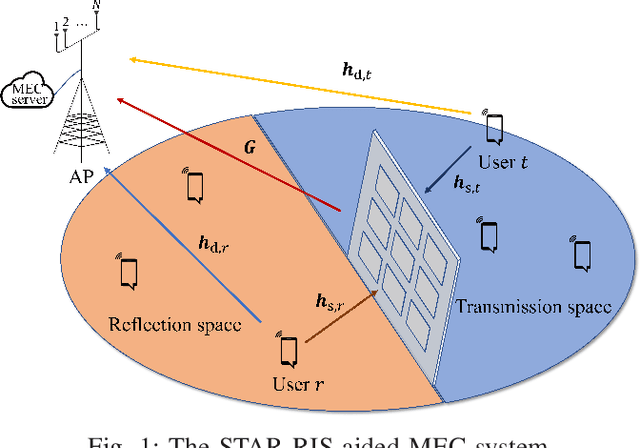
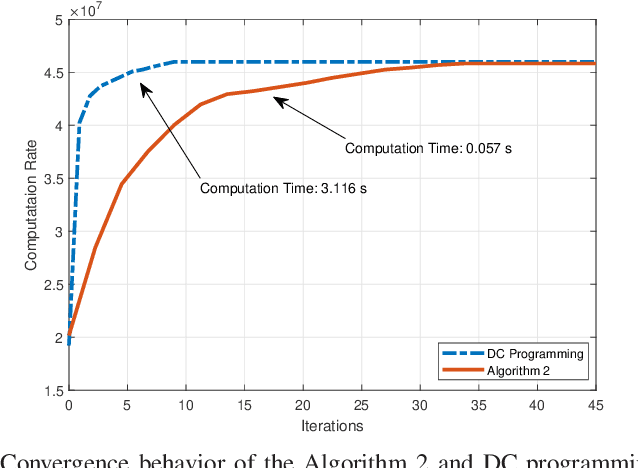
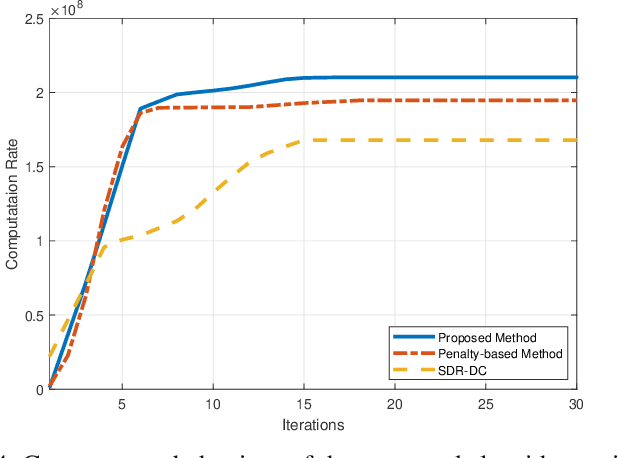
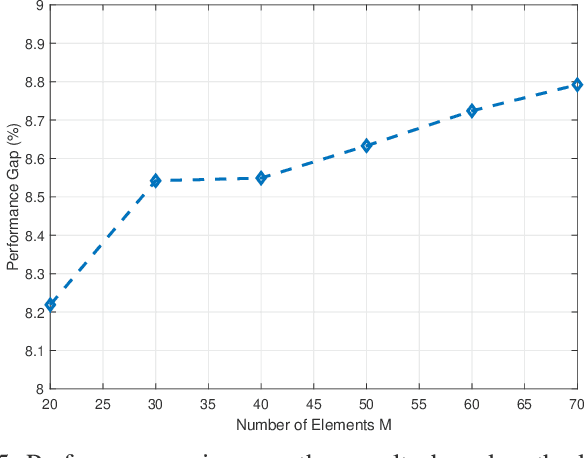
In this paper, simultaneously transmitting and reflecting (STAR) reconfigurable intelligent surface (RIS) is investigated in the multi-user mobile edge computing (MEC) system to improve the computation rate. Compared with traditional RIS-aided MEC, STAR-RIS extends the service coverage from half-space to full-space and provides new flexibility for improving the computation rate for end users. However, the STAR-RIS-aided MEC system design is a challenging problem due to the non-smooth and non-convex binary amplitude coefficients with coupled phase shifters. To fill this gap, this paper formulates a computation rate maximization problem via the joint design of the STAR-RIS phase shifts, reflection and transmission amplitude coefficients, the receive beamforming vectors, and energy partition strategies for local computing and offloading. To tackle the discontinuity caused by binary variables, we propose an efficient smoothing-based method to decrease convergence error, in contrast to the conventional penalty-based method, which brings many undesired stationary points and local optima. Furthermore, a fast iterative algorithm is proposed to obtain a stationary point for the joint optimization problem, with each subproblem solved by a low-complexity algorithm, making the proposed design scalable to a massive number of users and STAR-RIS elements. Simulation results validate the strength of the proposed smoothing-based method and show that the proposed fast iterative algorithm achieves a higher computation rate than the conventional method while saving the computation time by at least an order of magnitude. Moreover, the resultant STAR-RIS-aided MEC system significantly improves the computation rate compared to other baseline schemes with conventional reflect-only/transmit-only RIS.
DeFT-AN: Dense Frequency-Time Attentive Network for Multichannel Speech Enhancement
Dec 15, 2022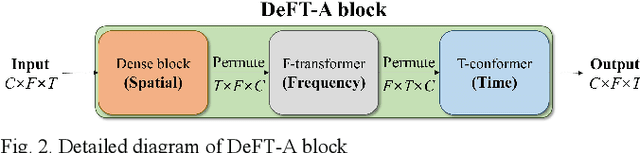
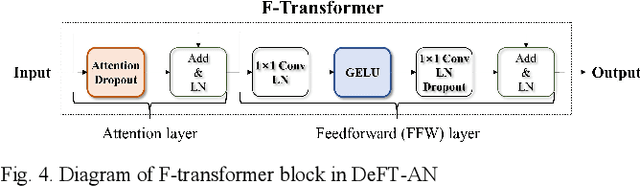
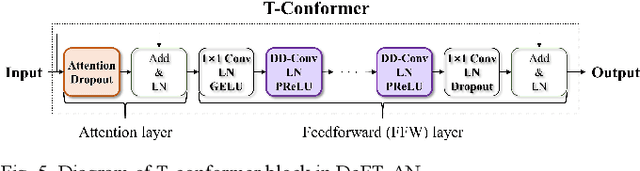
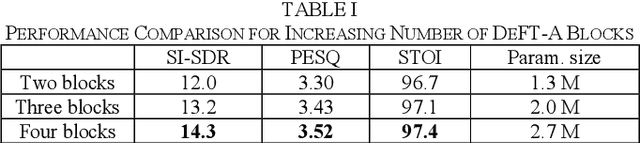
In this study, we propose a dense frequency-time attentive network (DeFT-AN) for multichannel speech enhancement. DeFT-AN is a mask estimation network that predicts a complex spectral masking pattern for suppressing the noise and reverberation embedded in the short-time Fourier transform (STFT) of an input signal. The proposed mask estimation network incorporates three different types of blocks for aggregating information in the spatial, spectral, and temporal dimensions. It utilizes a spectral transformer with a modified feed-forward network and a temporal conformer with sequential dilated convolutions. The use of dense blocks and transformers dedicated to the three different characteristics of audio signals enables more comprehensive denoising and dereverberation. The remarkable performance of DeFT-AN over state-of-the-art multichannel models is demonstrated based on two popular noisy and reverberant datasets in terms of various metrics for speech quality and intelligibility.
Full-Duplex Wireless for 6G: Progress Brings New Opportunities and Challenges
Apr 21, 2023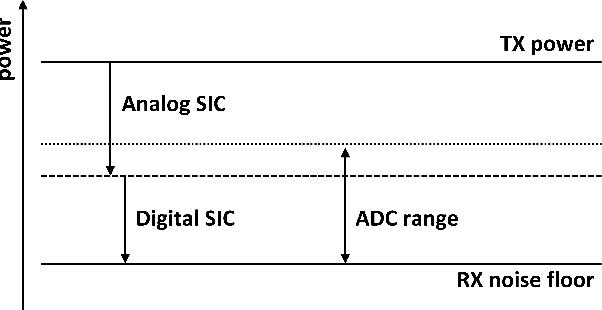
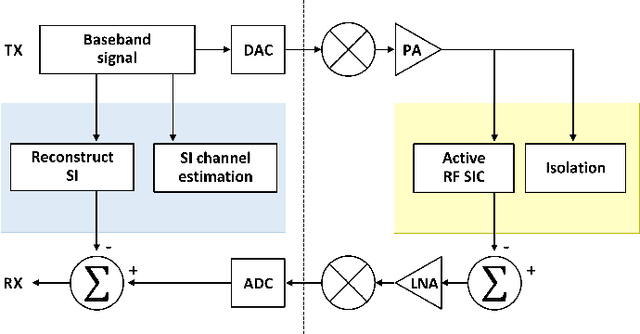
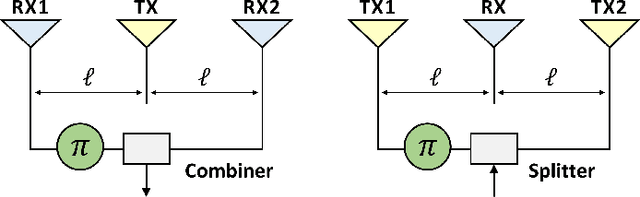
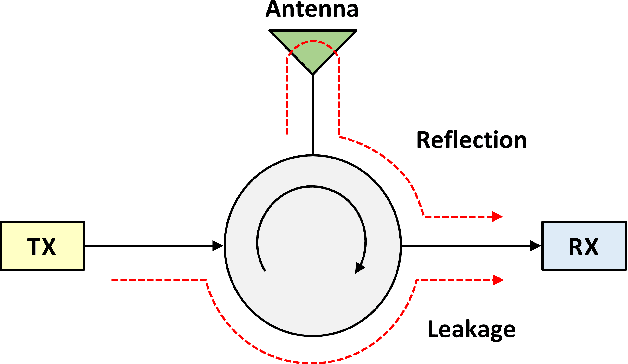
The use of in-band full-duplex (FD) enables nodes to simultaneously transmit and receive on the same frequency band, which challenges the traditional assumption in wireless network design. The full-duplex capability enhances spectral efficiency and decreases latency, which are two key drivers pushing the performance expectations of next-generation mobile networks. In less than ten years, in-band FD has advanced from being demonstrated in research labs to being implemented in standards and products, presenting new opportunities to utilize its foundational concepts. Some of the most significant opportunities include using FD to enable wireless networks to sense the physical environment, integrate sensing and communication applications, develop integrated access and backhaul solutions, and work with smart signal propagation environments powered by reconfigurable intelligent surfaces. However, these new opportunities also come with new challenges for large-scale commercial deployment of FD technology, such as managing self-interference, combating cross-link interference in multi-cell networks, and coexistence of dynamic time division duplex, subband FD and FD networks.
Missing Modality Robustness in Semi-Supervised Multi-Modal Semantic Segmentation
Apr 21, 2023

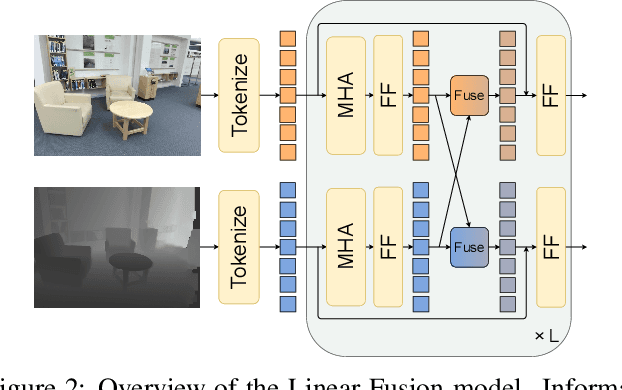
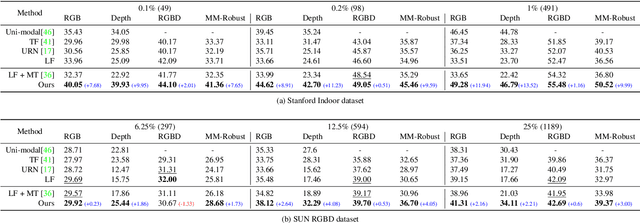
Using multiple spatial modalities has been proven helpful in improving semantic segmentation performance. However, there are several real-world challenges that have yet to be addressed: (a) improving label efficiency and (b) enhancing robustness in realistic scenarios where modalities are missing at the test time. To address these challenges, we first propose a simple yet efficient multi-modal fusion mechanism Linear Fusion, that performs better than the state-of-the-art multi-modal models even with limited supervision. Second, we propose M3L: Multi-modal Teacher for Masked Modality Learning, a semi-supervised framework that not only improves the multi-modal performance but also makes the model robust to the realistic missing modality scenario using unlabeled data. We create the first benchmark for semi-supervised multi-modal semantic segmentation and also report the robustness to missing modalities. Our proposal shows an absolute improvement of up to 10% on robust mIoU above the most competitive baselines. Our code is available at https://github.com/harshm121/M3L
A Convolutional Spiking Network for Gesture Recognition in Brain-Computer Interfaces
Apr 21, 2023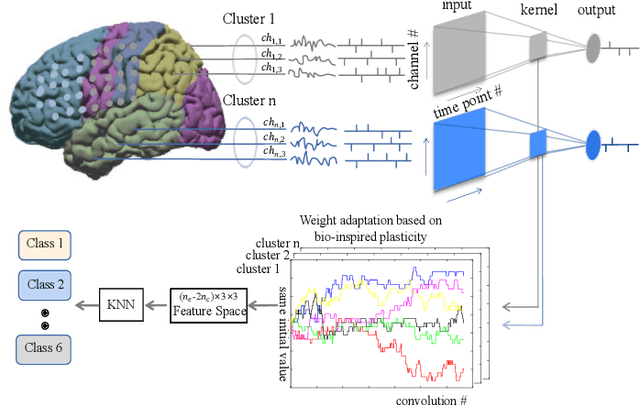
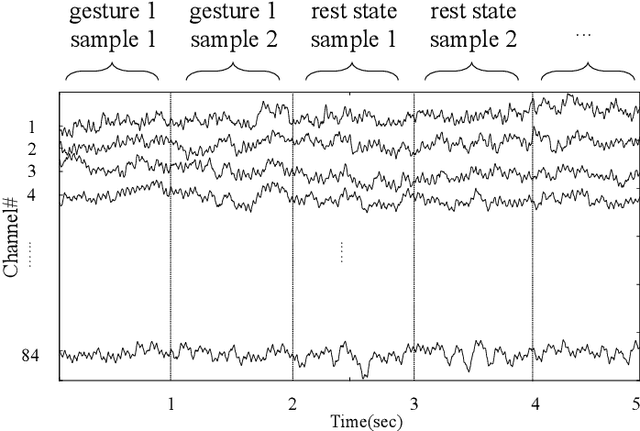
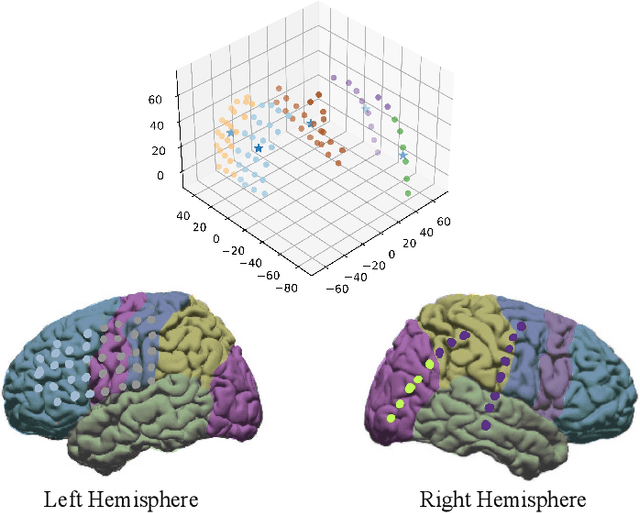
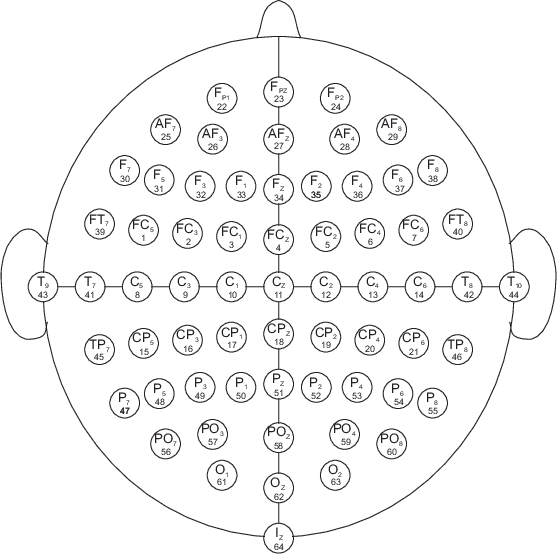
Brain-computer interfaces are being explored for a wide variety of therapeutic applications. Typically, this involves measuring and analyzing continuous-time electrical brain activity via techniques such as electrocorticogram (ECoG) or electroencephalography (EEG) to drive external devices. However, due to the inherent noise and variability in the measurements, the analysis of these signals is challenging and requires offline processing with significant computational resources. In this paper, we propose a simple yet efficient machine learning-based approach for the exemplary problem of hand gesture classification based on brain signals. We use a hybrid machine learning approach that uses a convolutional spiking neural network employing a bio-inspired event-driven synaptic plasticity rule for unsupervised feature learning of the measured analog signals encoded in the spike domain. We demonstrate that this approach generalizes to different subjects with both EEG and ECoG data and achieves superior accuracy in the range of 92.74-97.07% in identifying different hand gesture classes and motor imagery tasks.
TC-GAT: Graph Attention Network for Temporal Causality Discovery
Apr 21, 2023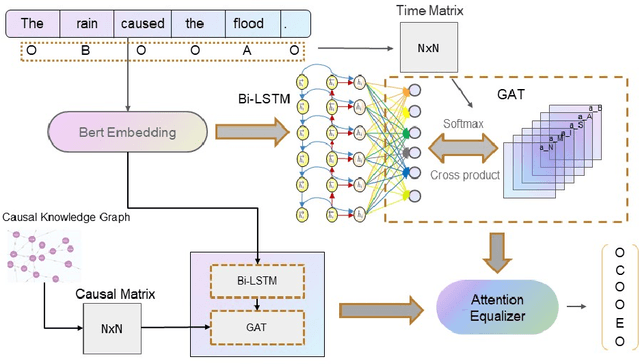
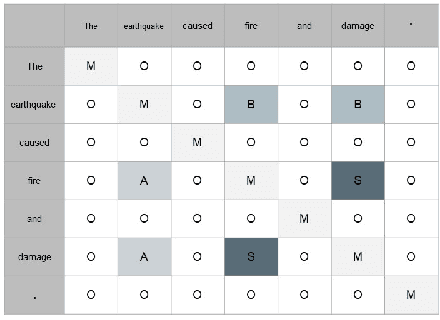
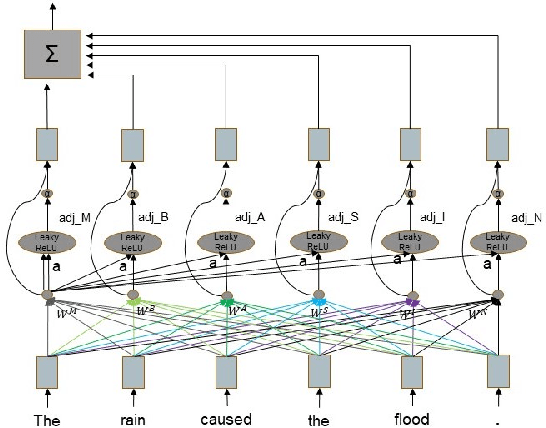

The present study explores the intricacies of causal relationship extraction, a vital component in the pursuit of causality knowledge. Causality is frequently intertwined with temporal elements, as the progression from cause to effect is not instantaneous but rather ensconced in a temporal dimension. Thus, the extraction of temporal causality holds paramount significance in the field. In light of this, we propose a method for extracting causality from the text that integrates both temporal and causal relations, with a particular focus on the time aspect. To this end, we first compile a dataset that encompasses temporal relationships. Subsequently, we present a novel model, TC-GAT, which employs a graph attention mechanism to assign weights to the temporal relationships and leverages a causal knowledge graph to determine the adjacency matrix. Additionally, we implement an equilibrium mechanism to regulate the interplay between temporal and causal relations. Our experiments demonstrate that our proposed method significantly surpasses baseline models in the task of causality extraction.
DeFeeNet: Consecutive 3D Human Motion Prediction with Deviation Feedback
Apr 14, 2023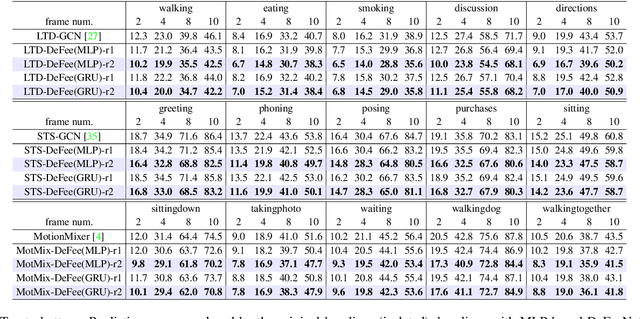

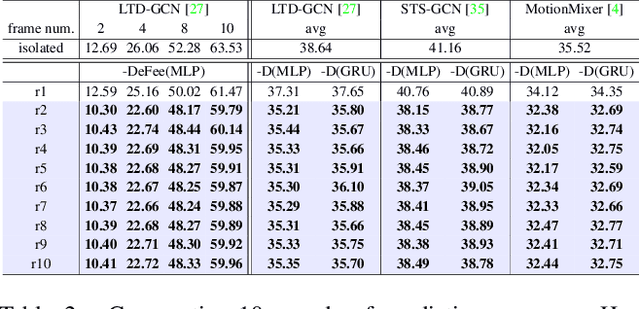
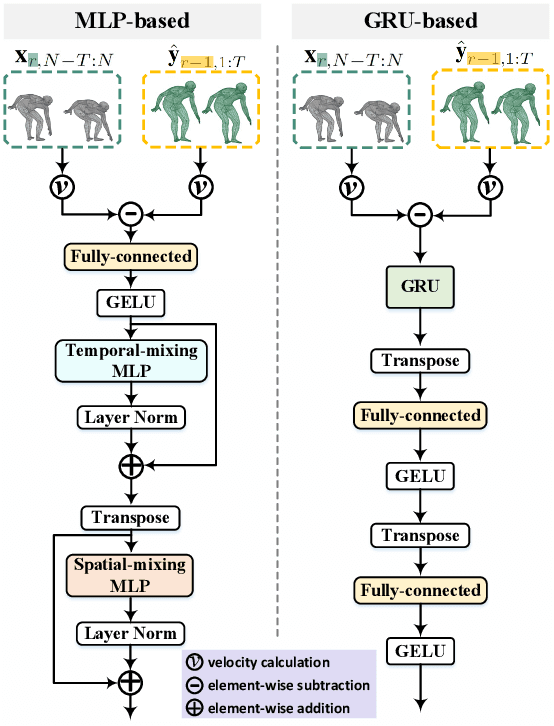
Let us rethink the real-world scenarios that require human motion prediction techniques, such as human-robot collaboration. Current works simplify the task of predicting human motions into a one-off process of forecasting a short future sequence (usually no longer than 1 second) based on a historical observed one. However, such simplification may fail to meet practical needs due to the neglect of the fact that motion prediction in real applications is not an isolated ``observe then predict'' unit, but a consecutive process composed of many rounds of such unit, semi-overlapped along the entire sequence. As time goes on, the predicted part of previous round has its corresponding ground truth observable in the new round, but their deviation in-between is neither exploited nor able to be captured by existing isolated learning fashion. In this paper, we propose DeFeeNet, a simple yet effective network that can be added on existing one-off prediction models to realize deviation perception and feedback when applied to consecutive motion prediction task. At each prediction round, the deviation generated by previous unit is first encoded by our DeFeeNet, and then incorporated into the existing predictor to enable a deviation-aware prediction manner, which, for the first time, allows for information transmit across adjacent prediction units. We design two versions of DeFeeNet as MLP-based and GRU-based, respectively. On Human3.6M and more complicated BABEL, experimental results indicate that our proposed network improves consecutive human motion prediction performance regardless of the basic model.
WizardLM: Empowering Large Language Models to Follow Complex Instructions
Apr 24, 2023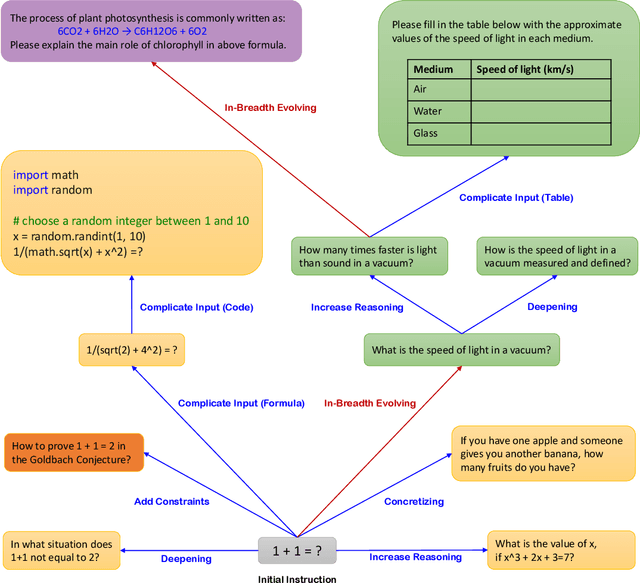
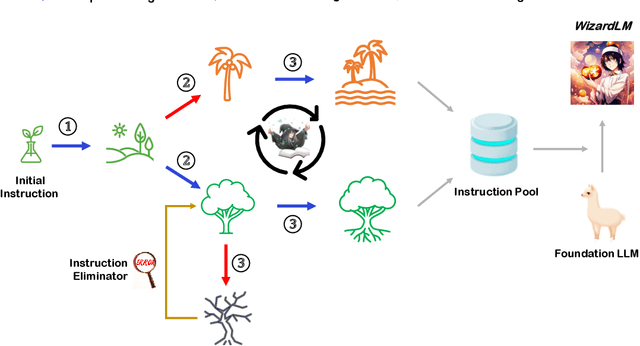
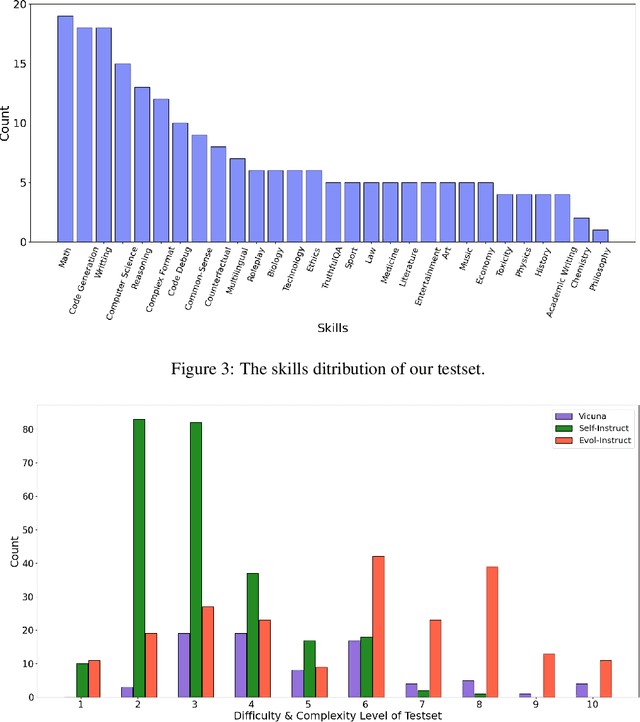

Training large language models (LLM) with open-domain instruction following data brings colossal success. However, manually creating such instruction data is very time-consuming and labor-intensive. Moreover, humans may struggle to produce high-complexity instructions. In this paper, we show an avenue for creating large amounts of instruction data with varying levels of complexity using LLM instead of humans. Starting with an initial set of instructions, we use our proposed Evol-Instruct to rewrite them step by step into more complex instructions. Then, we mix all generated instruction data to fine-tune LLaMA. We call the resulting model WizardLM. Human evaluations on a complexity-balanced test bed show that instructions from Evol-Instruct are superior to human-created ones. By analyzing the human evaluation results of the high complexity part, we demonstrate that outputs from our WizardLM model are preferred to outputs from OpenAI ChatGPT. Even though WizardLM still lags behind ChatGPT in some aspects, our findings suggest that fine-tuning with AI-evolved instructions is a promising direction for enhancing large language models. Our codes and generated data are public at https://github.com/nlpxucan/WizardLM