 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Resource Allocation and Passive Beamforming for IRS-assisted URLLC Systems
Apr 17, 2023
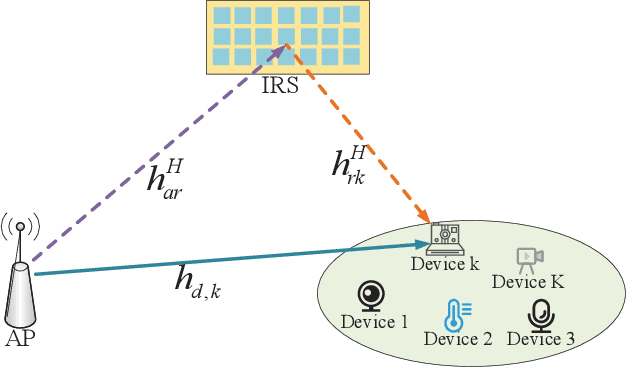
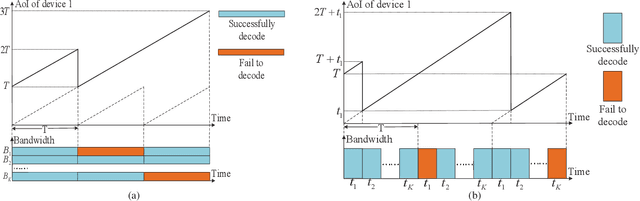
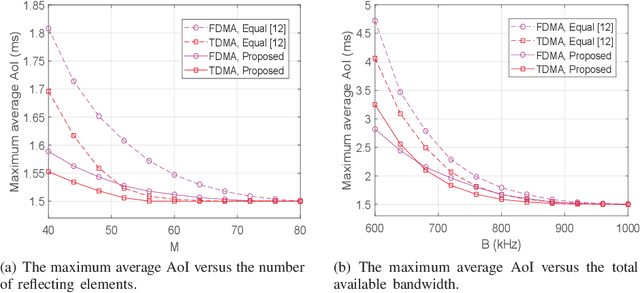
In this correspondence, we investigate an intelligent reflective surface (IRS) assisted downlink ultra-reliable and low-latency communication (URLLC) system, where an access point (AP) sends short packets to multiple devices with the help of an IRS. Specifically, a performance comparison between the frequency division multiple access (FDMA) and time division multiple access (TDMA) is conducted for the considered system, from the perspective of average age of information (AoI). Aiming to minimize the maximum average AoI among all devices by jointly optimizing the resource allocation and passive beamforming. However, the formulated problem is difficult to solve due to the non-convex objective function and coupled variables. Thus, we propose an alternating optimization based algorithm by dividing the original problem into two sub-problems which can be efficiently solved. Simulation results show that TDMA can achieve lower AoI by exploiting the time-selective passive beamforming of IRS for maximizing the signal to noise ratio (SNR) of each device consecutively. Moreover, it also shows that as the length of information bits becomes sufficiently large as compared to the available bandwidth, the proposed FDMA transmission scheme becomes more favorable instead, due to the more effective utilization of bandwidth.
Towards Carbon-Neutral Edge Computing: Greening Edge AI by Harnessing Spot and Future Carbon Markets
Apr 22, 2023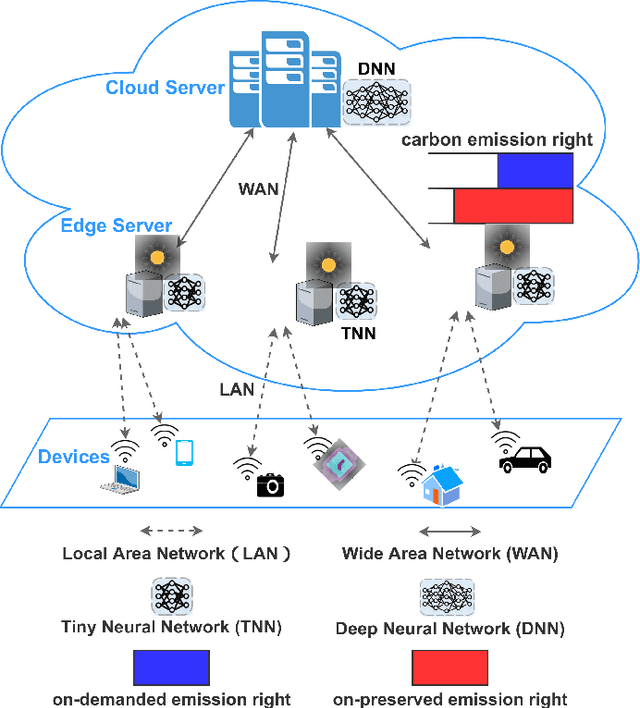
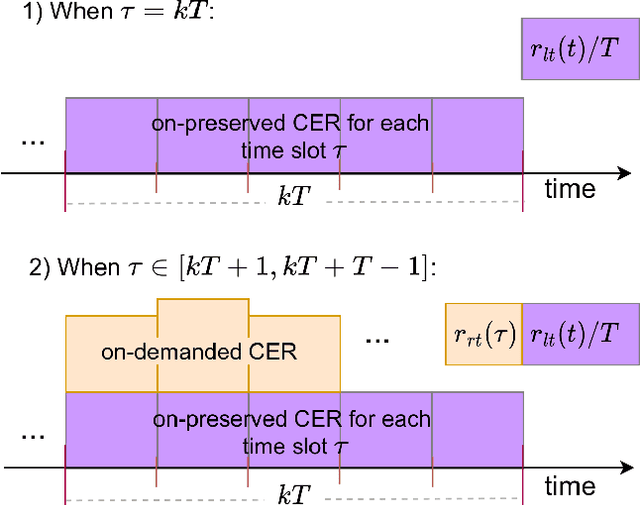
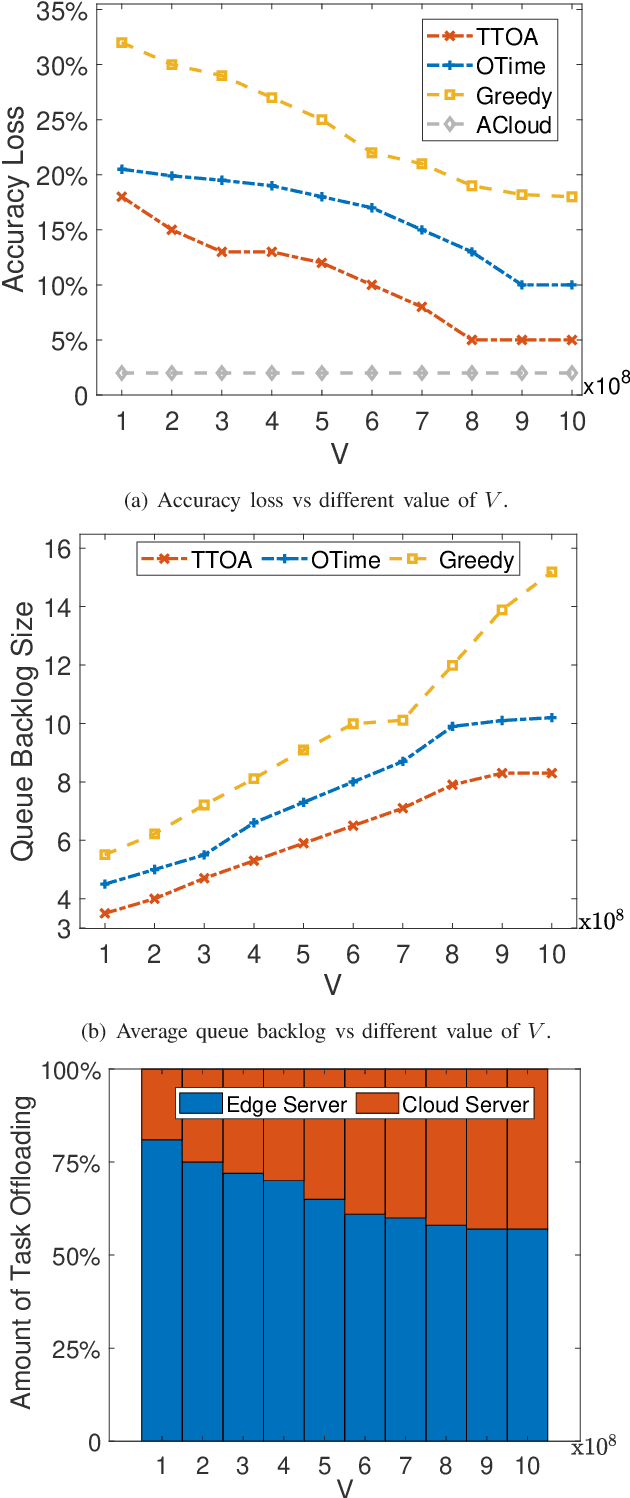
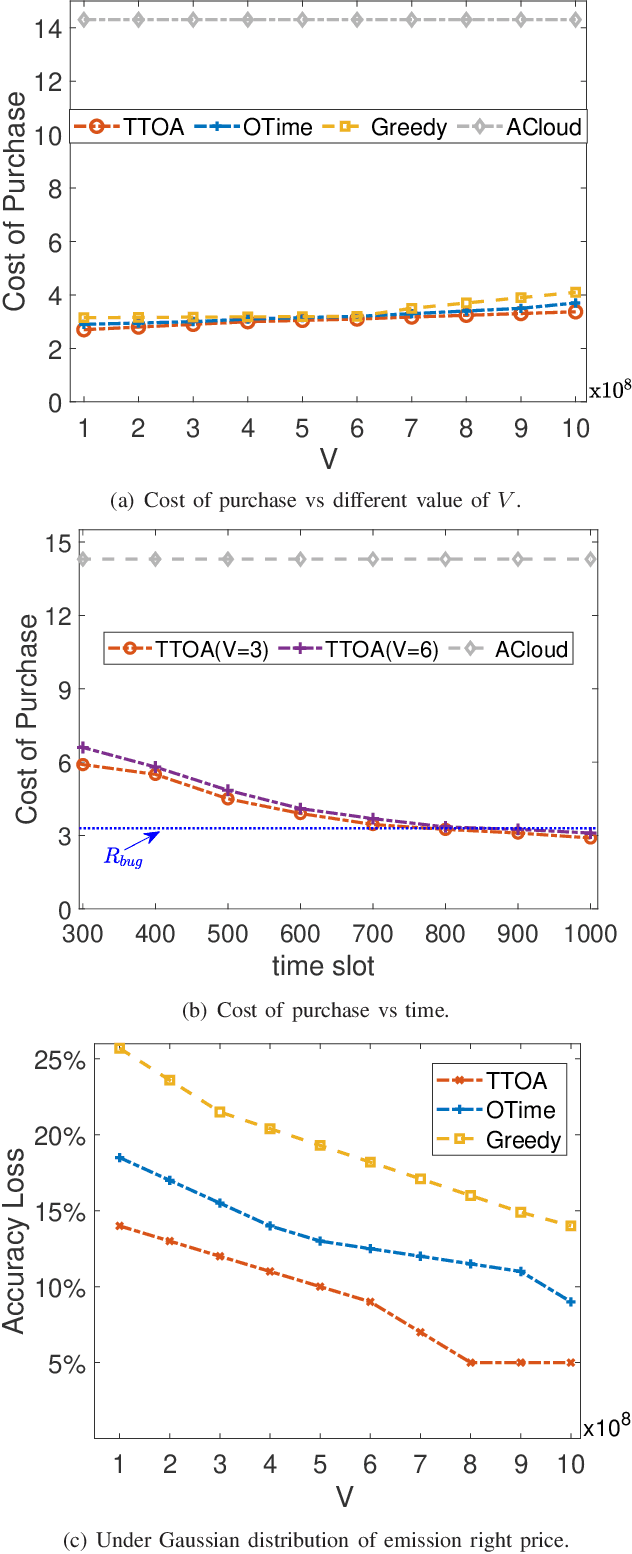
Provisioning dynamic machine learning (ML) inference as a service for artificial intelligence (AI) applications of edge devices faces many challenges, including the trade-off among accuracy loss, carbon emission, and unknown future costs. Besides, many governments are launching carbon emission rights (CER) for operators to reduce carbon emissions further to reverse climate change. Facing these challenges, to achieve carbon-aware ML task offloading under limited carbon emission rights thus to achieve green edge AI, we establish a joint ML task offloading and CER purchasing problem, intending to minimize the accuracy loss under the long-term time-averaged cost budget of purchasing the required CER. However, considering the uncertainty of the resource prices, the CER purchasing prices, the carbon intensity of sites, and ML tasks' arrivals, it is hard to decide the optimal policy online over a long-running period time. To overcome this difficulty, we leverage the two-timescale Lyapunov optimization technique, of which the $T$-slot drift-plus-penalty methodology inspires us to propose an online algorithm that purchases CER in multiple timescales (on-preserved in carbon future market and on-demanded in the carbon spot market) and makes decisions about where to offload ML tasks. Considering the NP-hardness of the $T$-slot problems, we further propose the resource-restricted randomized dependent rounding algorithm to help to gain the near-optimal solution with no help of any future information. Our theoretical analysis and extensive simulation results driven by the real carbon intensity trace show the superior performance of the proposed algorithms.
End-to-end deep learning-based framework for path planning and collision checking: bin picking application
Mar 31, 2023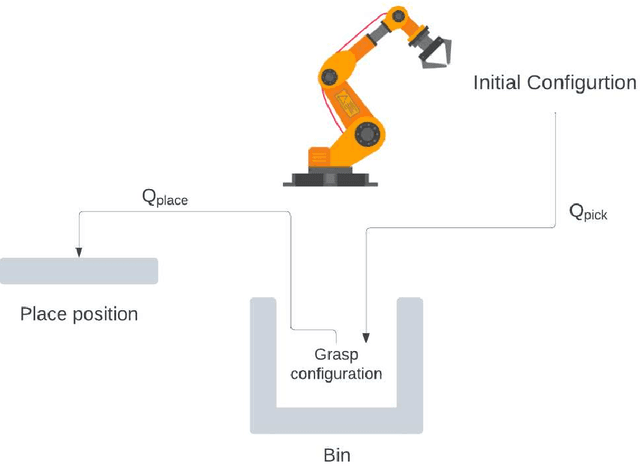
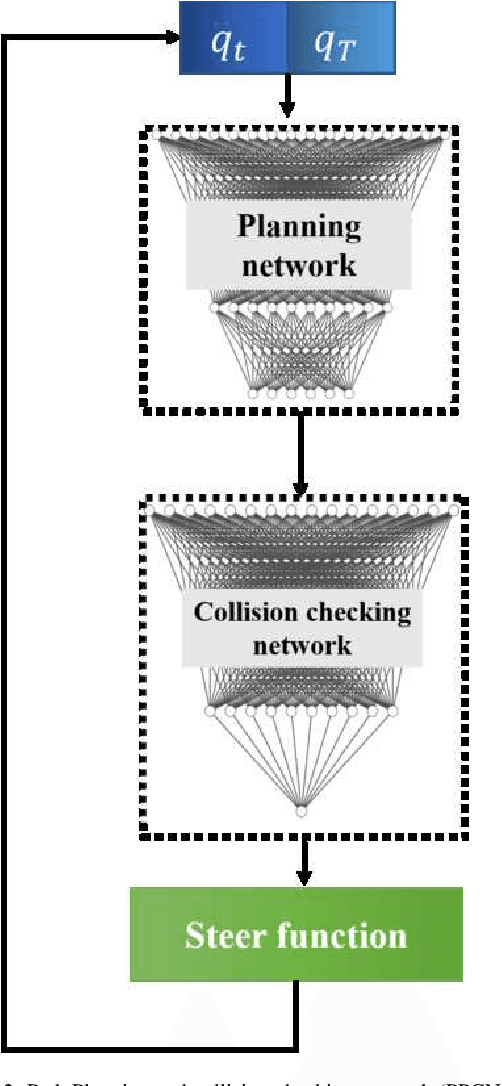
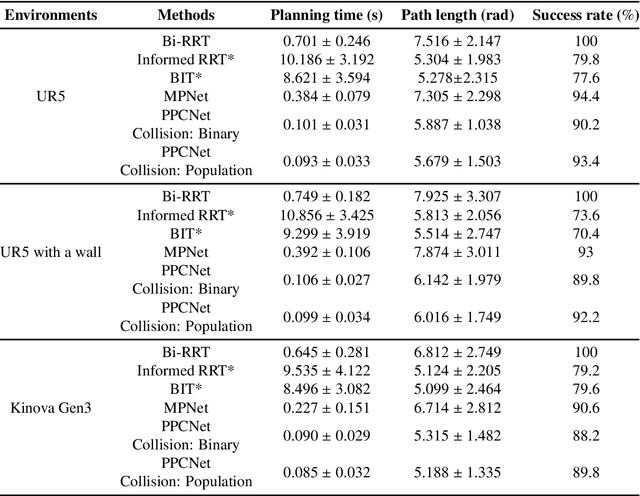
Real-time and efficient path planning is critical for all robotic systems. In particular, it is of greater importance for industrial robots since the overall planning and execution time directly impact the cycle time and automation economics in production lines. While the problem may not be complex in static environments, classical approaches are inefficient in high-dimensional environments in terms of planning time and optimality. Collision checking poses another challenge in obtaining a real-time solution for path planning in complex environments. To address these issues, we propose an end-to-end learning-based framework viz., Path Planning and Collision checking Network (PPCNet). The PPCNet generates the path by computing waypoints sequentially using two networks: the first network generates a waypoint, and the second one determines whether the waypoint is on a collision-free segment of the path. The end-to-end training process is based on imitation learning that uses data aggregation from the experience of an expert planner to train the two networks, simultaneously. We utilize two approaches for training a network that efficiently approximates the exact geometrical collision checking function. Finally, the PPCNet is evaluated in two different simulation environments and a practical implementation on a robotic arm for a bin-picking application. Compared to the state-of-the-art path planning methods, our results show significant improvement in performance by greatly reducing the planning time with comparable success rates and path lengths.
EV-Catcher: High-Speed Object Catching Using Low-latency Event-based Neural Networks
Apr 14, 2023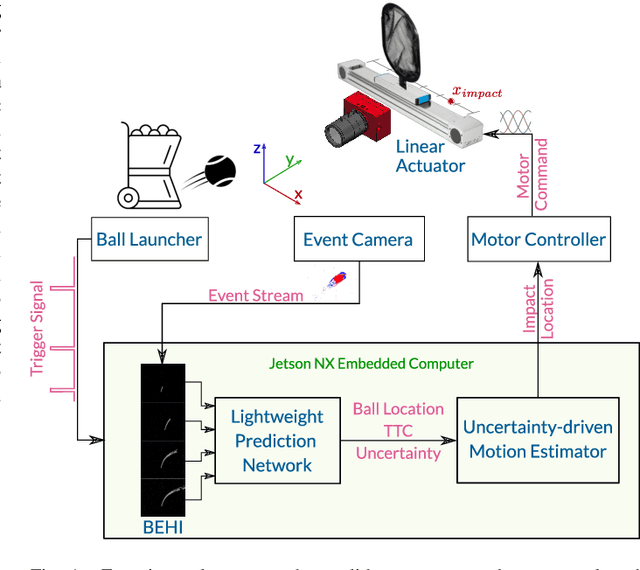
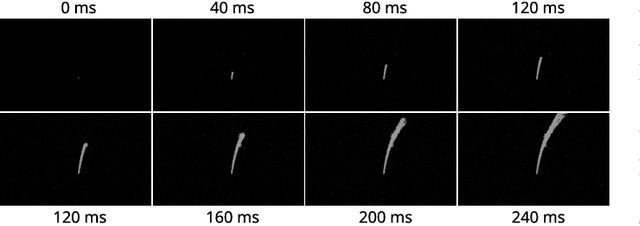
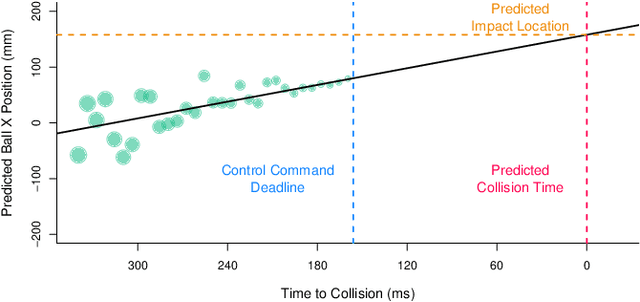
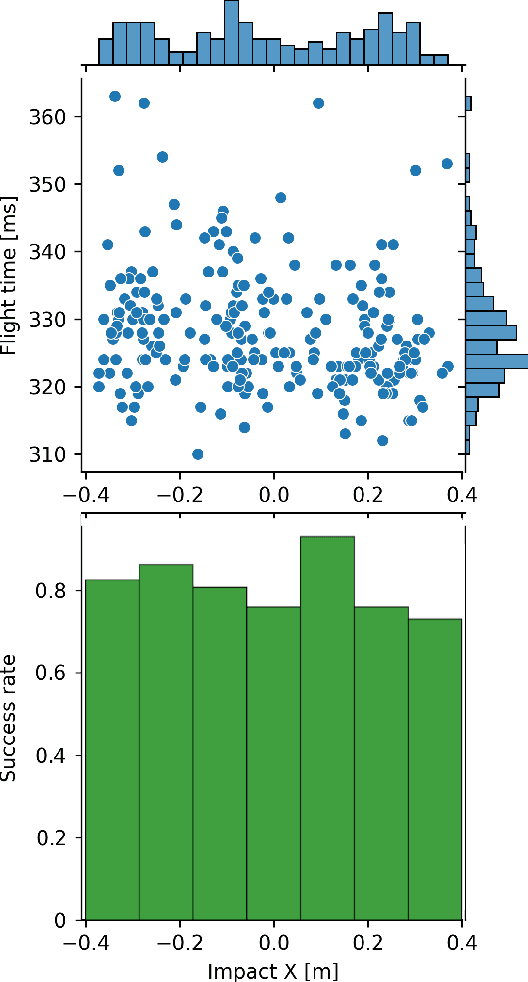
Event-based sensors have recently drawn increasing interest in robotic perception due to their lower latency, higher dynamic range, and lower bandwidth requirements compared to standard CMOS-based imagers. These properties make them ideal tools for real-time perception tasks in highly dynamic environments. In this work, we demonstrate an application where event cameras excel: accurately estimating the impact location of fast-moving objects. We introduce a lightweight event representation called Binary Event History Image (BEHI) to encode event data at low latency, as well as a learning-based approach that allows real-time inference of a confidence-enabled control signal to the robot. To validate our approach, we present an experimental catching system in which we catch fast-flying ping-pong balls. We show that the system is capable of achieving a success rate of 81% in catching balls targeted at different locations, with a velocity of up to 13 m/s even on compute-constrained embedded platforms such as the Nvidia Jetson NX.
Graph Attention for Automated Audio Captioning
Apr 10, 2023
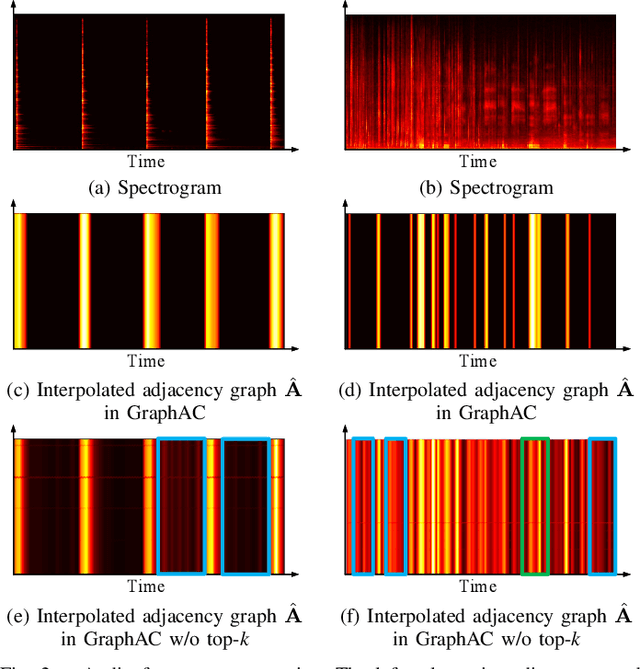

State-of-the-art audio captioning methods typically use the encoder-decoder structure with pretrained audio neural networks (PANNs) as encoders for feature extraction. However, the convolution operation used in PANNs is limited in capturing the long-time dependencies within an audio signal, thereby leading to potential performance degradation in audio captioning. This letter presents a novel method using graph attention (GraphAC) for encoder-decoder based audio captioning. In the encoder, a graph attention module is introduced after the PANNs to learn contextual association (i.e. the dependency among the audio features over different time frames) through an adjacency graph, and a top-k mask is used to mitigate the interference from noisy nodes. The learnt contextual association leads to a more effective feature representation with feature node aggregation. As a result, the decoder can predict important semantic information about the acoustic scene and events based on the contextual associations learned from the audio signal. Experimental results show that GraphAC outperforms the state-of-the-art methods with PANNs as the encoders, thanks to the incorporation of the graph attention module into the encoder for capturing the long-time dependencies within the audio signal. The source code is available at https://github.com/LittleFlyingSheep/GraphAC.
Optimizing Energy Efficiency in Metro Systems Under Uncertainty Disturbances Using Reinforcement Learning
Apr 27, 2023
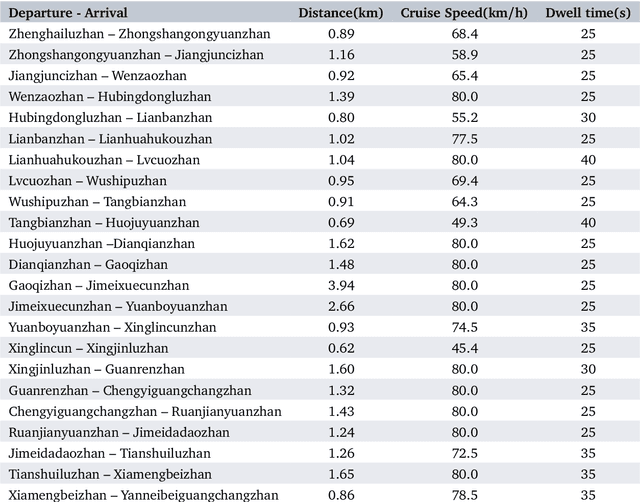
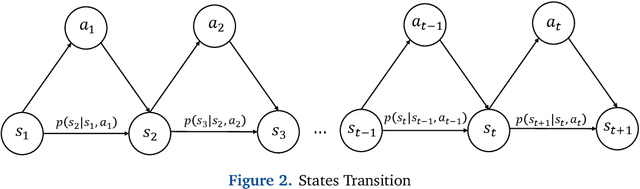
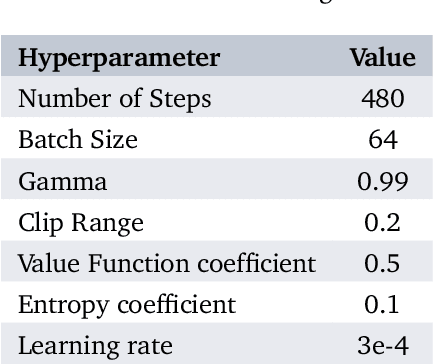
In the realm of urban transportation, metro systems serve as crucial and sustainable means of public transit. However, their substantial energy consumption poses a challenge to the goal of sustainability. Disturbances such as delays and passenger flow changes can further exacerbate this issue by negatively affecting energy efficiency in metro systems. To tackle this problem, we propose a policy-based reinforcement learning approach that reschedules the metro timetable and optimizes energy efficiency in metro systems under disturbances by adjusting the dwell time and cruise speed of trains. Our experiments conducted in a simulation environment demonstrate the superiority of our method over baseline methods, achieving a traction energy consumption reduction of up to 10.9% and an increase in regenerative braking energy utilization of up to 47.9%. This study provides an effective solution to the energy-saving problem of urban rail transit.
Cross-Domain Evaluation of POS Taggers: From Wall Street Journal to Fandom Wiki
Apr 27, 2023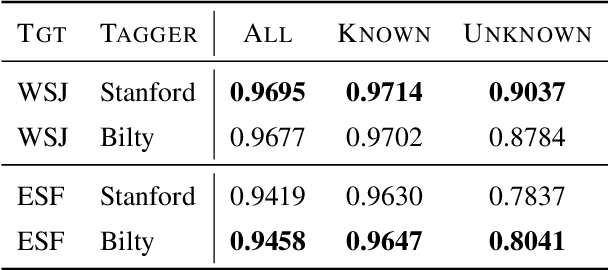
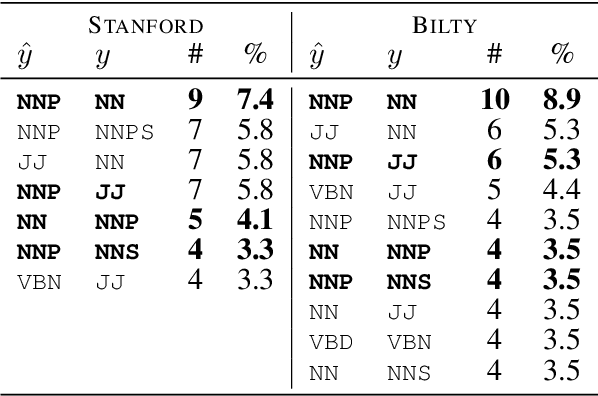
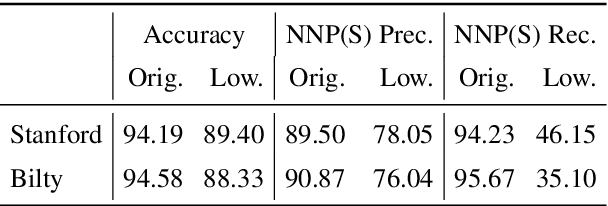
The Wall Street Journal section of the Penn Treebank has been the de-facto standard for evaluating POS taggers for a long time, and accuracies over 97\% have been reported. However, less is known about out-of-domain tagger performance, especially with fine-grained label sets. Using data from Elder Scrolls Fandom, a wiki about the \textit{Elder Scrolls} video game universe, we create a modest dataset for qualitatively evaluating the cross-domain performance of two POS taggers: the Stanford tagger (Toutanova et al. 2003) and Bilty (Plank et al. 2016), both trained on WSJ. Our analyses show that performance on tokens seen during training is almost as good as in-domain performance, but accuracy on unknown tokens decreases from 90.37% to 78.37% (Stanford) and 87.84\% to 80.41\% (Bilty) across domains. Both taggers struggle with proper nouns and inconsistent capitalization.
Optimizing Privacy, Utility and Efficiency in Constrained Multi-Objective Federated Learning
May 03, 2023


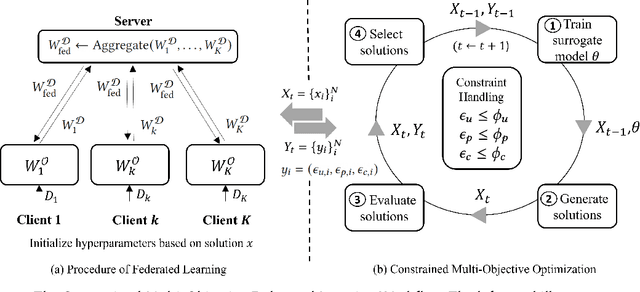
Conventionally, federated learning aims to optimize a single objective, typically the utility. However, for a federated learning system to be trustworthy, it needs to simultaneously satisfy multiple/many objectives, such as maximizing model performance, minimizing privacy leakage and training cost, and being robust to malicious attacks. Multi-Objective Optimization (MOO) aiming to optimize multiple conflicting objectives at the same time is quite suitable for solving the optimization problem of Trustworthy Federated Learning (TFL). In this paper, we unify MOO and TFL by formulating the problem of constrained multi-objective federated learning (CMOFL). Under this formulation, existing MOO algorithms can be adapted to TFL straightforwardly. Different from existing CMOFL works focusing on utility, efficiency, fairness, and robustness, we consider optimizing privacy leakage along with utility loss and training cost, the three primary objectives of a TFL system. We develop two improved CMOFL algorithms based on NSGA-II and PSL, respectively, for effectively and efficiently finding Pareto optimal solutions, and we provide theoretical analysis on their convergence. We design specific measurements of privacy leakage, utility loss, and training cost for three privacy protection mechanisms: Randomization, BatchCrypt (An efficient version of homomorphic encryption), and Sparsification. Empirical experiments conducted under each of the three protection mechanisms demonstrate the effectiveness of our proposed algorithms.
Quantifying the Dissimilarity of Texts
May 03, 2023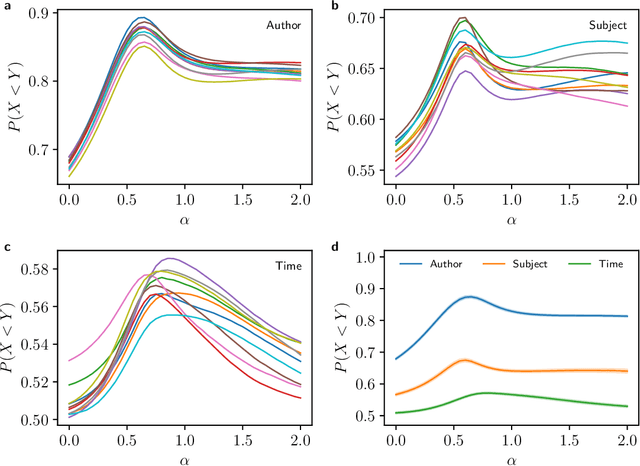
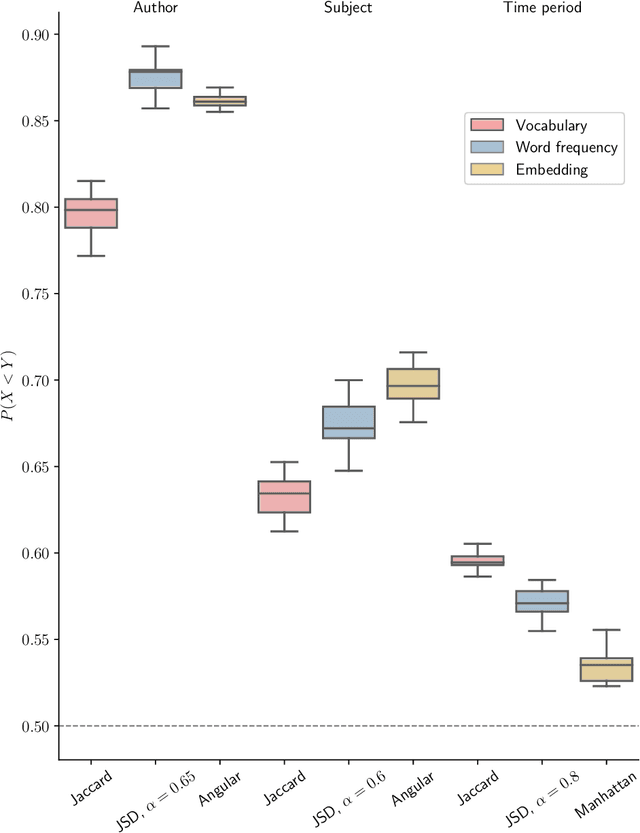
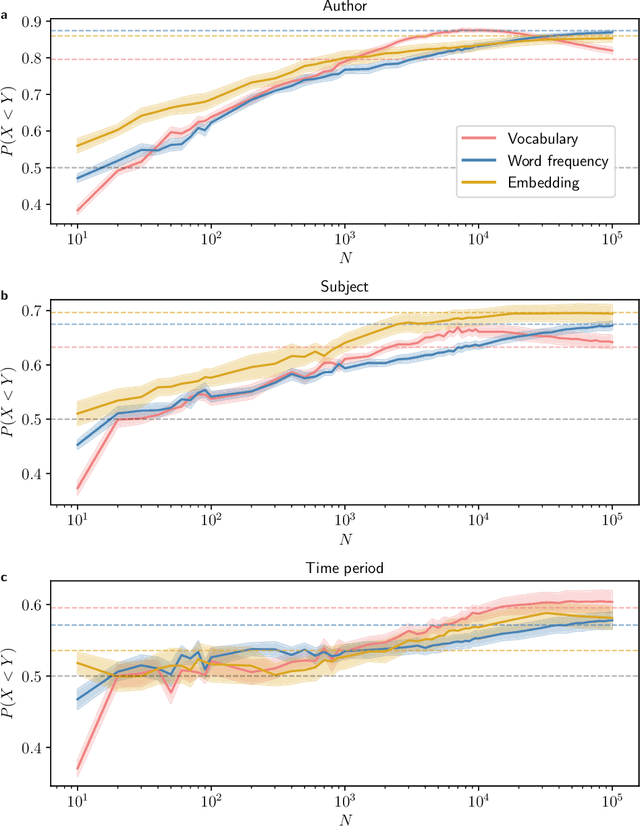
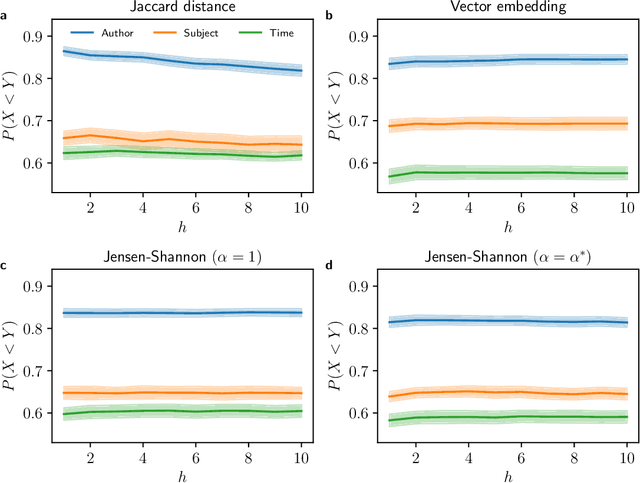
Quantifying the dissimilarity of two texts is an important aspect of a number of natural language processing tasks, including semantic information retrieval, topic classification, and document clustering. In this paper, we compared the properties and performance of different dissimilarity measures $D$ using three different representations of texts -- vocabularies, word frequency distributions, and vector embeddings -- and three simple tasks -- clustering texts by author, subject, and time period. Using the Project Gutenberg database, we found that the generalised Jensen--Shannon divergence applied to word frequencies performed strongly across all tasks, that $D$'s based on vector embedding representations led to stronger performance for smaller texts, and that the optimal choice of approach was ultimately task-dependent. We also investigated, both analytically and numerically, the behaviour of the different $D$'s when the two texts varied in length by a factor $h$. We demonstrated that the (natural) estimator of the Jaccard distance between vocabularies was inconsistent and computed explicitly the $h$-dependency of the bias of the estimator of the generalised Jensen--Shannon divergence applied to word frequencies. We also found numerically that the Jensen--Shannon divergence and embedding-based approaches were robust to changes in $h$, while the Jaccard distance was not.
* 16 pages, 4 figures, part of the Special Issue Novel Methods and Applications in Natural Language Processing
Recurrent Neural Networks and Long Short-Term Memory Networks: Tutorial and Survey
Apr 22, 2023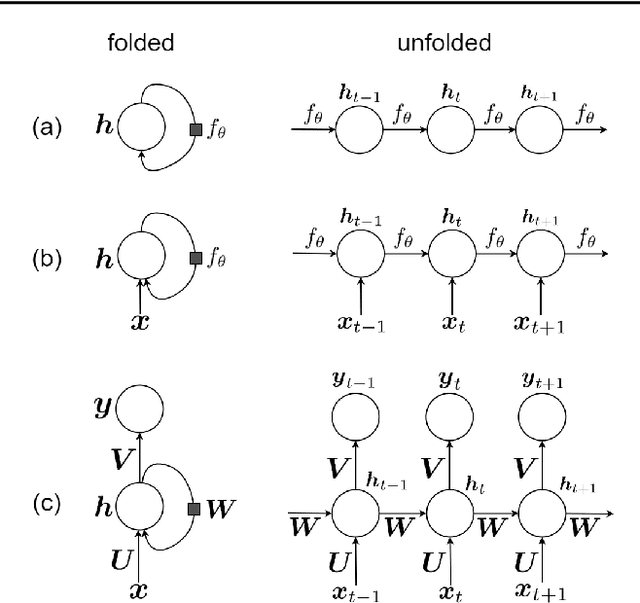
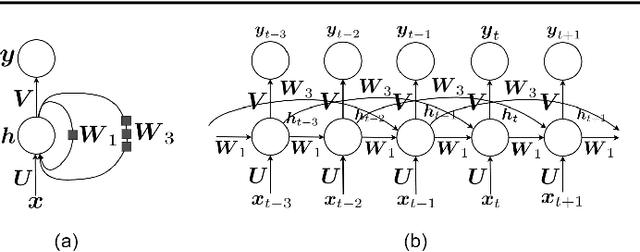
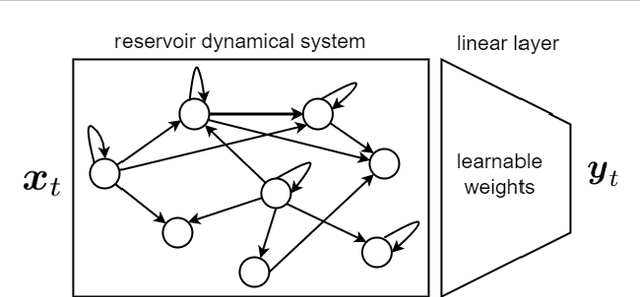
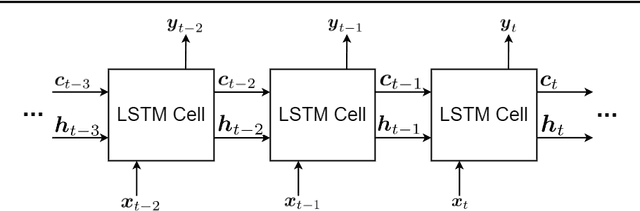
This is a tutorial paper on Recurrent Neural Network (RNN), Long Short-Term Memory Network (LSTM), and their variants. We start with a dynamical system and backpropagation through time for RNN. Then, we discuss the problems of gradient vanishing and explosion in long-term dependencies. We explain close-to-identity weight matrix, long delays, leaky units, and echo state networks for solving this problem. Then, we introduce LSTM gates and cells, history and variants of LSTM, and Gated Recurrent Units (GRU). Finally, we introduce bidirectional RNN, bidirectional LSTM, and the Embeddings from Language Model (ELMo) network, for processing a sequence in both directions.