 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Two-phase Dual COPOD Method for Anomaly Detection in Industrial Control System
Apr 30, 2023
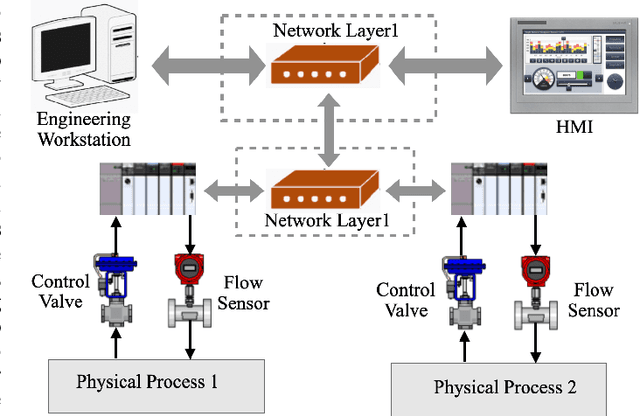
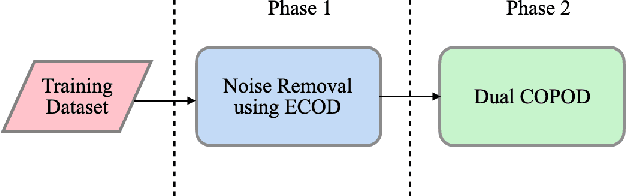
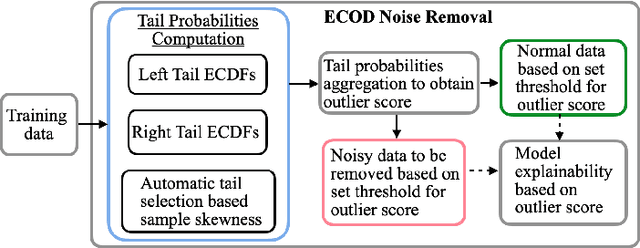
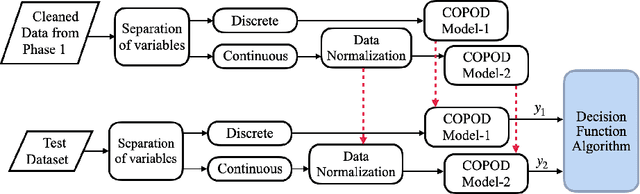
Critical infrastructures like water treatment facilities and power plants depend on industrial control systems (ICS) for monitoring and control, making them vulnerable to cyber attacks and system malfunctions. Traditional ICS anomaly detection methods lack transparency and interpretability, which make it difficult for practitioners to understand and trust the results. This paper proposes a two-phase dual Copula-based Outlier Detection (COPOD) method that addresses these challenges. The first phase removes unwanted outliers using an empirical cumulative distribution algorithm, and the second phase develops two parallel COPOD models based on the output data of phase 1. The method is based on empirical distribution functions, parameter-free, and provides interpretability by quantifying each feature's contribution to an anomaly. The method is also computationally and memory-efficient, suitable for low- and high-dimensional datasets. Experimental results demonstrate superior performance in terms of F1-score and recall on three open-source ICS datasets, enabling real-time ICS anomaly detection.
NewsPanda: Media Monitoring for Timely Conservation Action
Apr 30, 2023
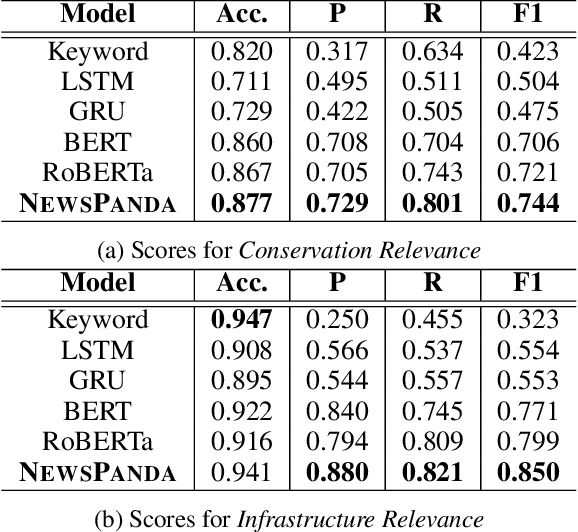
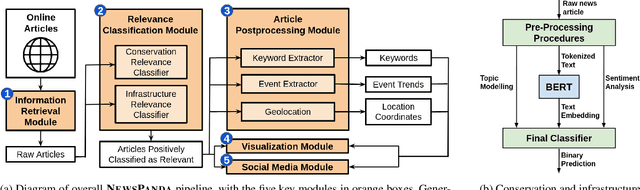
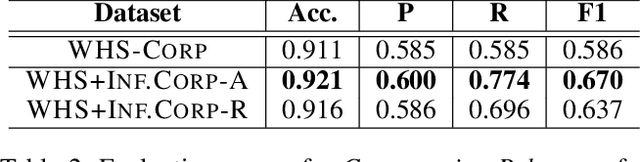
Non-governmental organizations for environmental conservation have a significant interest in monitoring conservation-related media and getting timely updates about infrastructure construction projects as they may cause massive impact to key conservation areas. Such monitoring, however, is difficult and time-consuming. We introduce NewsPanda, a toolkit which automatically detects and analyzes online articles related to environmental conservation and infrastructure construction. We fine-tune a BERT-based model using active learning methods and noise correction algorithms to identify articles that are relevant to conservation and infrastructure construction. For the identified articles, we perform further analysis, extracting keywords and finding potentially related sources. NewsPanda has been successfully deployed by the World Wide Fund for Nature teams in the UK, India, and Nepal since February 2022. It currently monitors over 80,000 websites and 1,074 conservation sites across India and Nepal, saving more than 30 hours of human efforts weekly. We have now scaled it up to cover 60,000 conservation sites globally.
Asynchronous Multi-Agent Reinforcement Learning for Efficient Real-Time Multi-Robot Cooperative Exploration
Jan 09, 2023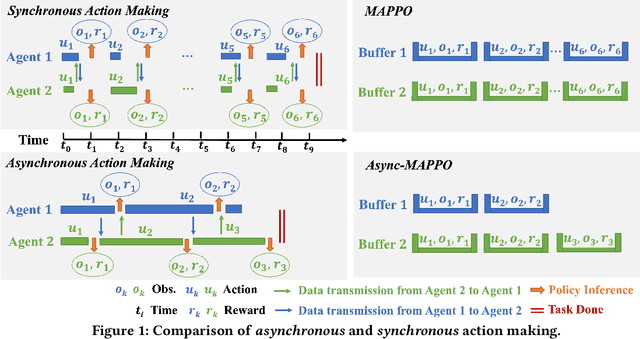
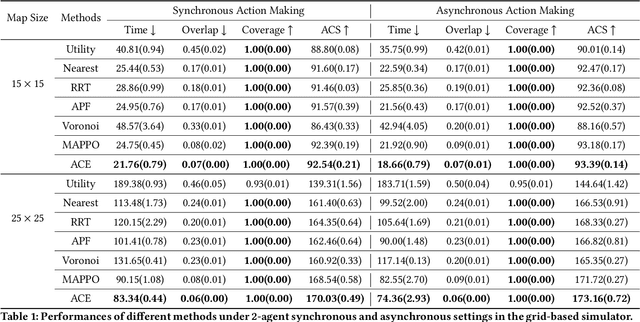
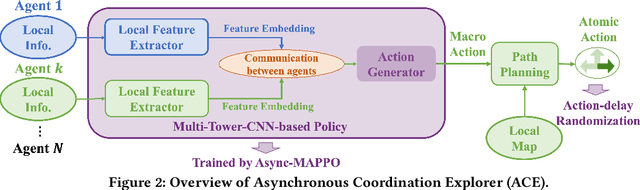
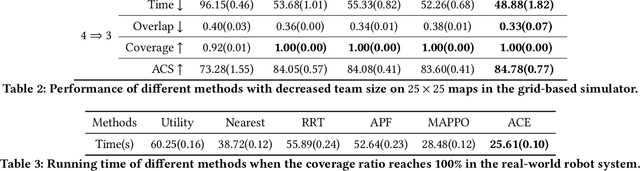
We consider the problem of cooperative exploration where multiple robots need to cooperatively explore an unknown region as fast as possible. Multi-agent reinforcement learning (MARL) has recently become a trending paradigm for solving this challenge. However, existing MARL-based methods adopt action-making steps as the metric for exploration efficiency by assuming all the agents are acting in a fully synchronous manner: i.e., every single agent produces an action simultaneously and every single action is executed instantaneously at each time step. Despite its mathematical simplicity, such a synchronous MARL formulation can be problematic for real-world robotic applications. It can be typical that different robots may take slightly different wall-clock times to accomplish an atomic action or even periodically get lost due to hardware issues. Simply waiting for every robot being ready for the next action can be particularly time-inefficient. Therefore, we propose an asynchronous MARL solution, Asynchronous Coordination Explorer (ACE), to tackle this real-world challenge. We first extend a classical MARL algorithm, multi-agent PPO (MAPPO), to the asynchronous setting and additionally apply action-delay randomization to enforce the learned policy to generalize better to varying action delays in the real world. Moreover, each navigation agent is represented as a team-size-invariant CNN-based policy, which greatly benefits real-robot deployment by handling possible robot lost and allows bandwidth-efficient intra-agent communication through low-dimensional CNN features. We first validate our approach in a grid-based scenario. Both simulation and real-robot results show that ACE reduces over 10% actual exploration time compared with classical approaches. We also apply our framework to a high-fidelity visual-based environment, Habitat, achieving 28% improvement in exploration efficiency.
RTMDet: An Empirical Study of Designing Real-Time Object Detectors
Dec 16, 2022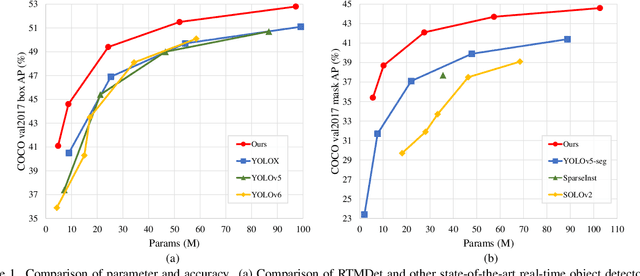
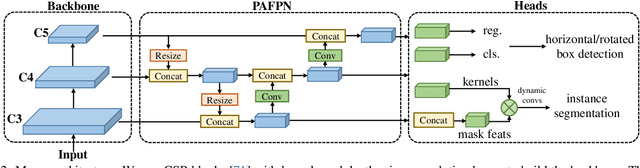
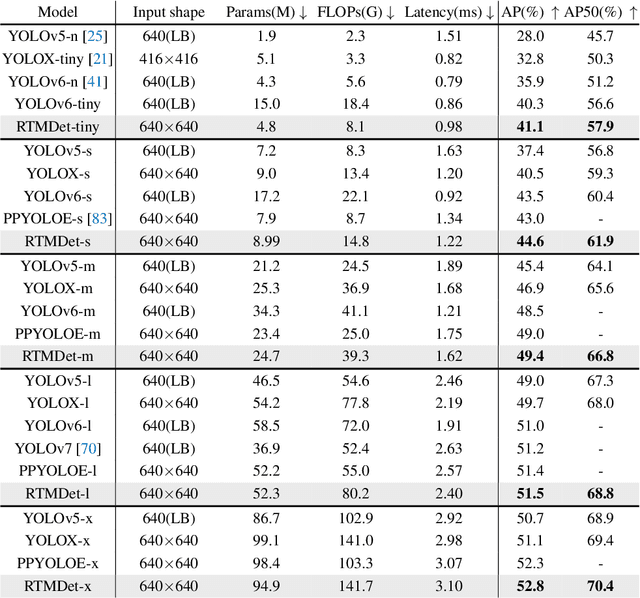
In this paper, we aim to design an efficient real-time object detector that exceeds the YOLO series and is easily extensible for many object recognition tasks such as instance segmentation and rotated object detection. To obtain a more efficient model architecture, we explore an architecture that has compatible capacities in the backbone and neck, constructed by a basic building block that consists of large-kernel depth-wise convolutions. We further introduce soft labels when calculating matching costs in the dynamic label assignment to improve accuracy. Together with better training techniques, the resulting object detector, named RTMDet, achieves 52.8% AP on COCO with 300+ FPS on an NVIDIA 3090 GPU, outperforming the current mainstream industrial detectors. RTMDet achieves the best parameter-accuracy trade-off with tiny/small/medium/large/extra-large model sizes for various application scenarios, and obtains new state-of-the-art performance on real-time instance segmentation and rotated object detection. We hope the experimental results can provide new insights into designing versatile real-time object detectors for many object recognition tasks. Code and models are released at https://github.com/open-mmlab/mmdetection/tree/3.x/configs/rtmdet.
An autoencoder compression approach for accelerating large-scale inverse problems
Apr 10, 2023



PDE-constrained inverse problems are some of the most challenging and computationally demanding problems in computational science today. Fine meshes that are required to accurately compute the PDE solution introduce an enormous number of parameters and require large scale computing resources such as more processors and more memory to solve such systems in a reasonable time. For inverse problems constrained by time dependent PDEs, the adjoint method that is often employed to efficiently compute gradients and higher order derivatives requires solving a time-reversed, so-called adjoint PDE that depends on the forward PDE solution at each timestep. This necessitates the storage of a high dimensional forward solution vector at every timestep. Such a procedure quickly exhausts the available memory resources. Several approaches that trade additional computation for reduced memory footprint have been proposed to mitigate the memory bottleneck, including checkpointing and compression strategies. In this work, we propose a close-to-ideal scalable compression approach using autoencoders to eliminate the need for checkpointing and substantial memory storage, thereby reducing both the time-to-solution and memory requirements. We compare our approach with checkpointing and an off-the-shelf compression approach on an earth-scale ill-posed seismic inverse problem. The results verify the expected close-to-ideal speedup for both the gradient and Hessian-vector product using the proposed autoencoder compression approach. To highlight the usefulness of the proposed approach, we combine the autoencoder compression with the data-informed active subspace (DIAS) prior to show how the DIAS method can be affordably extended to large scale problems without the need of checkpointing and large memory.
Who Should I Engage with At What Time? A Missing Event Aware Temporal Graph Neural Network
Jan 20, 2023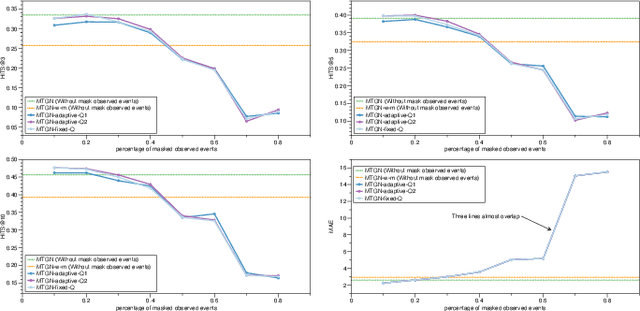
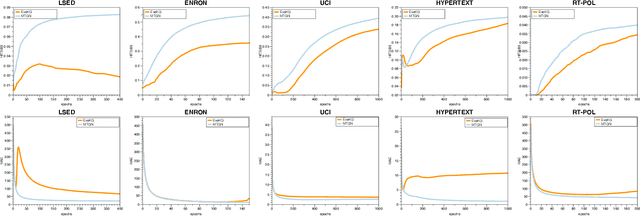
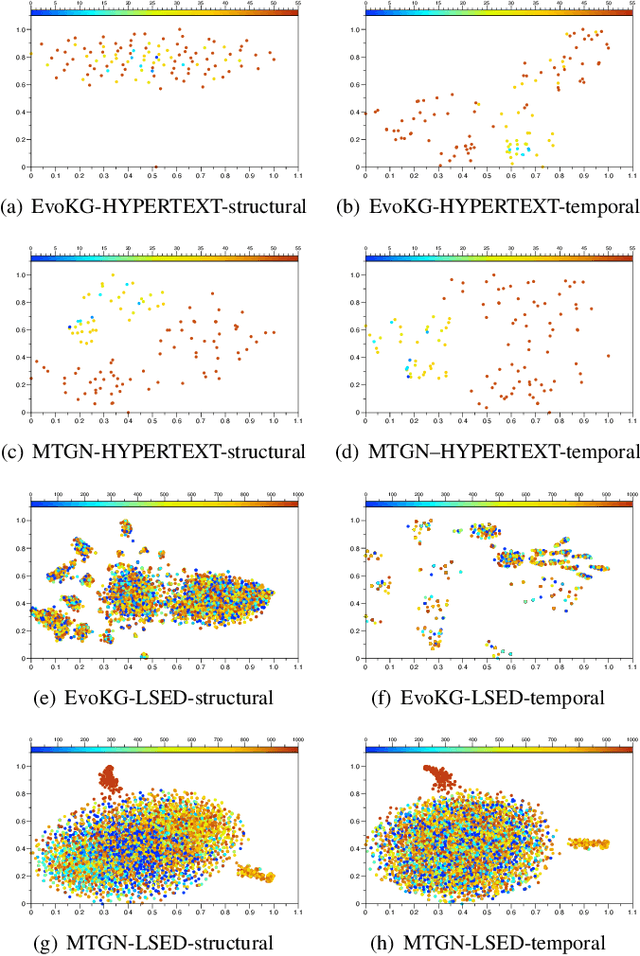
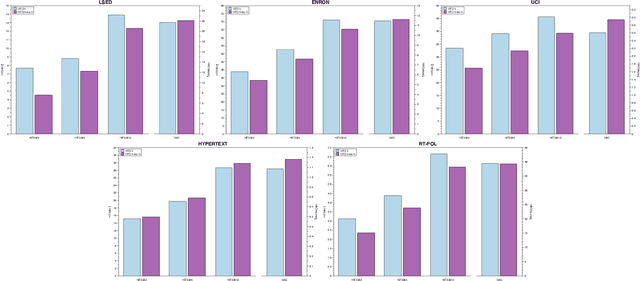
Temporal graph neural network has recently received significant attention due to its wide application scenarios, such as bioinformatics, knowledge graphs, and social networks. There are some temporal graph neural networks that achieve remarkable results. However, these works focus on future event prediction and are performed under the assumption that all historical events are observable. In real-world applications, events are not always observable, and estimating event time is as important as predicting future events. In this paper, we propose MTGN, a missing event-aware temporal graph neural network, which uniformly models evolving graph structure and timing of events to support predicting what will happen in the future and when it will happen.MTGN models the dynamic of both observed and missing events as two coupled temporal point processes, thereby incorporating the effects of missing events into the network. Experimental results on several real-world temporal graphs demonstrate that MTGN significantly outperforms existing methods with up to 89% and 112% more accurate time and link prediction. Code can be found on https://github.com/HIT-ICES/TNNLS-MTGN.
Robotic Gas Source Localization with Probabilistic Mapping and Online Dispersion Simulation
Apr 18, 2023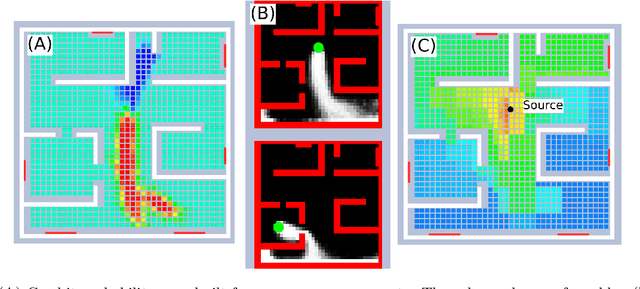
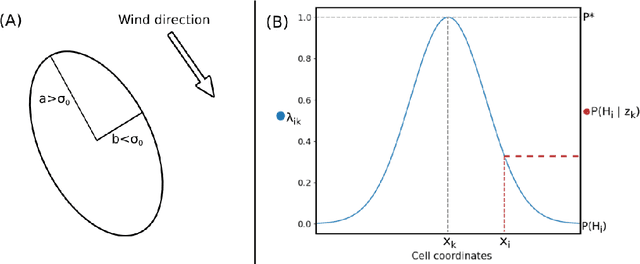
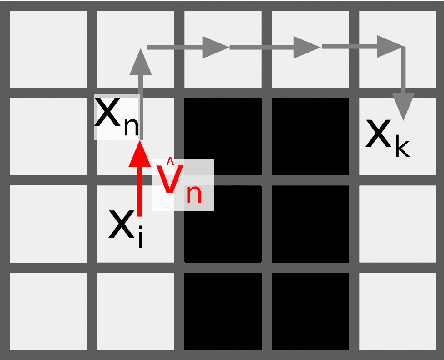
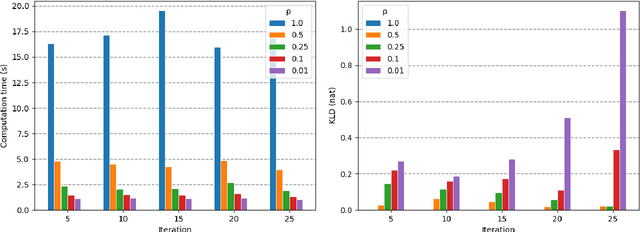
Gas source localization (GSL) with an autonomous robot is a problem with many prospective applications, from finding pipe leaks to emergency-response scenarios. In this work we present a new method to perform GSL in realistic indoor environments, featuring obstacles and turbulent flow. Given the highly complex relationship between the source position and the measurements available to the robot (the single-point gas concentration, and the wind vector) we propose an observation model that derives from contrasting the online, real-time simulation of the gas dispersion from any candidate source localization against a gas concentration map built from sensor readings. To account for a convenient and grounded integration of both into a probabilistic estimation framework, we introduce the concept of probabilistic gas-hit maps, which provide a higher level of abstraction to model the time-dependent nature of gas dispersion. Results from both simulated and real experiments show the capabilities of our current proposal to deal with source localization in complex indoor environments. To the best of our knowledge, this is the first work in olfactory robotics that doesn't make simplistic assumptions about environmental conditions like operating in open spaces and/or having an unrealistic laminar flow wind.
Few-shot Domain-Adaptive Visually-fused Event Detection from Text
May 04, 2023
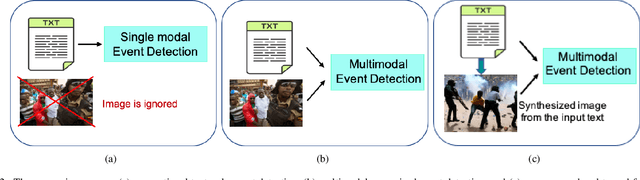
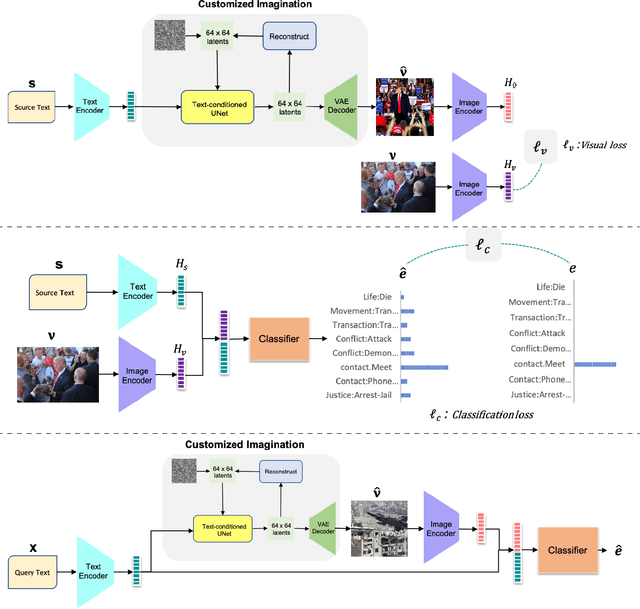

Incorporating auxiliary modalities such as images into event detection models has attracted increasing interest over the last few years. The complexity of natural language in describing situations has motivated researchers to leverage the related visual context to improve event detection performance. However, current approaches in this area suffer from data scarcity, where a large amount of labelled text-image pairs are required for model training. Furthermore, limited access to the visual context at inference time negatively impacts the performance of such models, which makes them practically ineffective in real-world scenarios. In this paper, we present a novel domain-adaptive visually-fused event detection approach that can be trained on a few labelled image-text paired data points. Specifically, we introduce a visual imaginator method that synthesises images from text in the absence of visual context. Moreover, the imaginator can be customised to a specific domain. In doing so, our model can leverage the capabilities of pre-trained vision-language models and can be trained in a few-shot setting. This also allows for effective inference where only single-modality data (i.e. text) is available. The experimental evaluation on the benchmark M2E2 dataset shows that our model outperforms existing state-of-the-art models, by up to 11 points.
Few-shot In-context Learning for Knowledge Base Question Answering
May 04, 2023
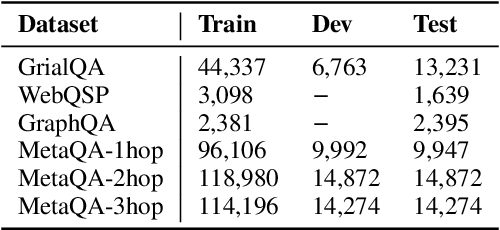
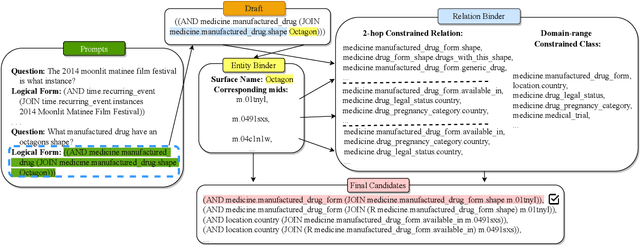
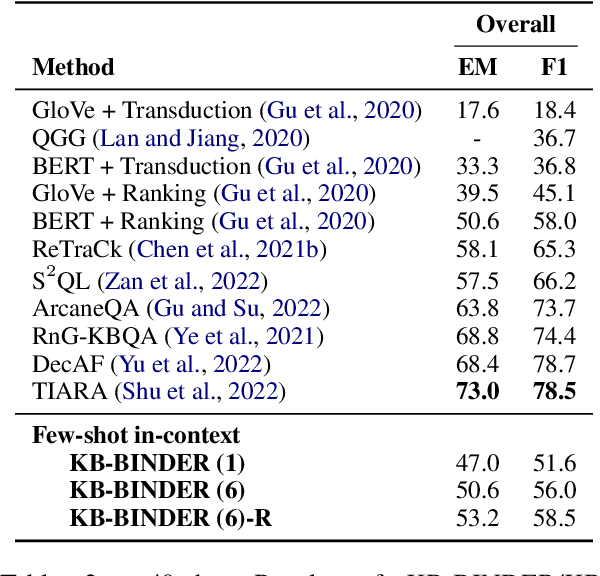
Question answering over knowledge bases is considered a difficult problem due to the challenge of generalizing to a wide variety of possible natural language questions. Additionally, the heterogeneity of knowledge base schema items between different knowledge bases often necessitates specialized training for different knowledge base question-answering (KBQA) datasets. To handle questions over diverse KBQA datasets with a unified training-free framework, we propose KB-BINDER, which for the first time enables few-shot in-context learning over KBQA tasks. Firstly, KB-BINDER leverages large language models like Codex to generate logical forms as the draft for a specific question by imitating a few demonstrations. Secondly, KB-BINDER grounds on the knowledge base to bind the generated draft to an executable one with BM25 score matching. The experimental results on four public heterogeneous KBQA datasets show that KB-BINDER can achieve a strong performance with only a few in-context demonstrations. Especially on GraphQA and 3-hop MetaQA, KB-BINDER can even outperform the state-of-the-art trained models. On GrailQA and WebQSP, our model is also on par with other fully-trained models. We believe KB-BINDER can serve as an important baseline for future research. Our code is available at https://github.com/ltl3A87/KB-BINDER.
Neuralizer: General Neuroimage Analysis without Re-Training
May 04, 2023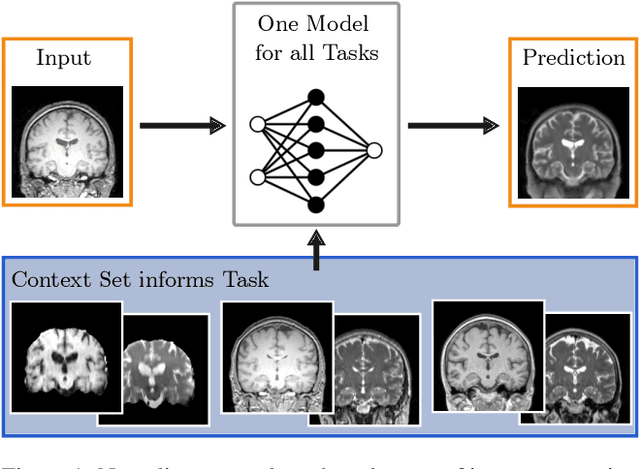
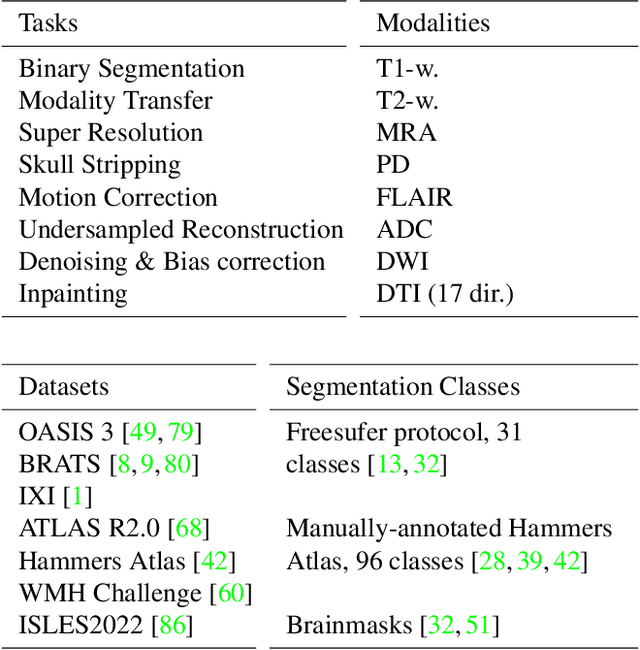
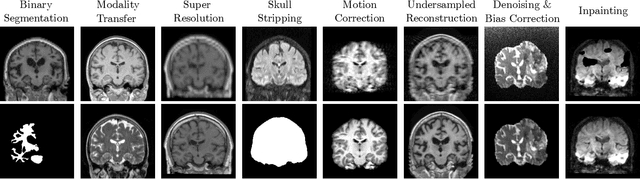

Neuroimage processing tasks like segmentation, reconstruction, and registration are central to the study of neuroscience. Robust deep learning strategies and architectures used to solve these tasks are often similar. Yet, when presented with a new task or a dataset with different visual characteristics, practitioners most often need to train a new model, or fine-tune an existing one. This is a time-consuming process that poses a substantial barrier for the thousands of neuroscientists and clinical researchers who often lack the resources or machine-learning expertise to train deep learning models. In practice, this leads to a lack of adoption of deep learning, and neuroscience tools being dominated by classical frameworks. We introduce Neuralizer, a single model that generalizes to previously unseen neuroimaging tasks and modalities without the need for re-training or fine-tuning. Tasks do not have to be known a priori, and generalization happens in a single forward pass during inference. The model can solve processing tasks across multiple image modalities, acquisition methods, and datasets, and generalize to tasks and modalities it has not been trained on. Our experiments on coronal slices show that when few annotated subjects are available, our multi-task network outperforms task-specific baselines without training on the task.