 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MATE: Masked Autoencoders are Online 3D Test-Time Learners
Nov 24, 2022
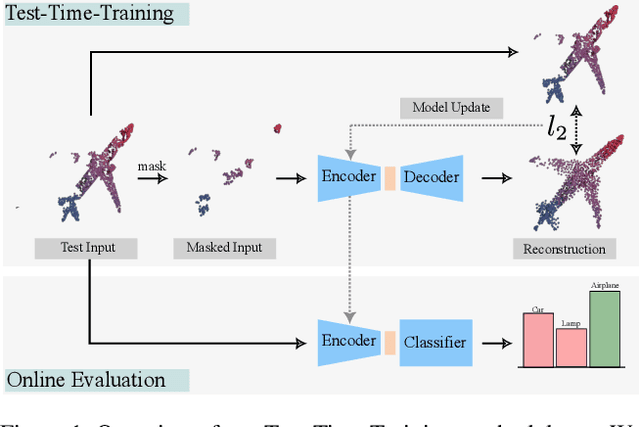

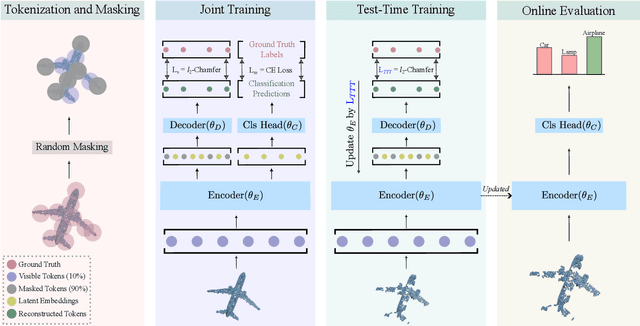

We propose MATE, the first Test-Time-Training (TTT) method designed for 3D data. It makes deep networks trained in point cloud classification robust to distribution shifts occurring in test data, which could not be anticipated during training. Like existing TTT methods, which focused on classifying 2D images in the presence of distribution shifts at test-time, MATE also leverages test data for adaptation. Its test-time objective is that of a Masked Autoencoder: Each test point cloud has a large portion of its points removed before it is fed to the network, tasked with reconstructing the full point cloud. Once the network is updated, it is used to classify the point cloud. We test MATE on several 3D object classification datasets and show that it significantly improves robustness of deep networks to several types of corruptions commonly occurring in 3D point clouds. Further, we show that MATE is very efficient in terms of the fraction of points it needs for the adaptation. It can effectively adapt given as few as 5% of tokens of each test sample, which reduces its memory footprint and makes it lightweight. We also highlight that MATE achieves competitive performance by adapting sparingly on the test data, which further reduces its computational overhead, making it ideal for real-time applications.
Emergent and Predictable Memorization in Large Language Models
Apr 21, 2023
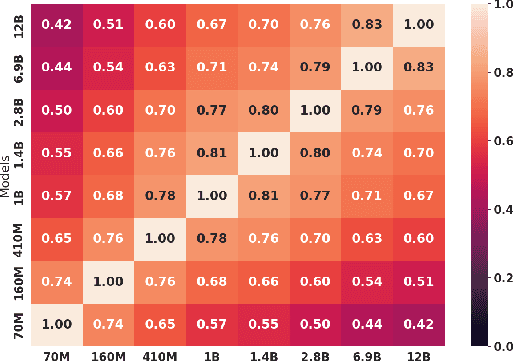
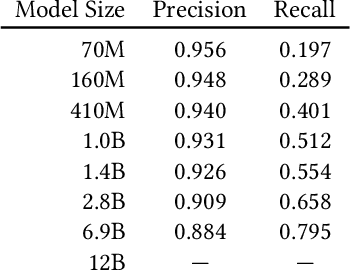
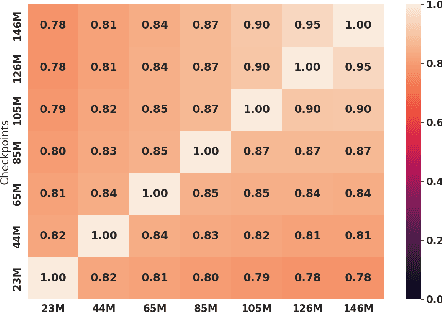
Memorization, or the tendency of large language models (LLMs) to output entire sequences from their training data verbatim, is a key concern for safely deploying language models. In particular, it is vital to minimize a model's memorization of sensitive datapoints such as those containing personal identifiable information (PII). The prevalence of such undesirable memorization can pose issues for model trainers, and may even require discarding an otherwise functional model. We therefore seek to predict which sequences will be memorized before a large model's full train-time by extrapolating the memorization behavior of lower-compute trial runs. We measure memorization of the Pythia model suite, and find that intermediate checkpoints are better predictors of a model's memorization behavior than smaller fully-trained models. We additionally provide further novel discoveries on the distribution of memorization scores across models and data.
Energy Efficiency Considerations for Popular AI Benchmarks
Apr 17, 2023
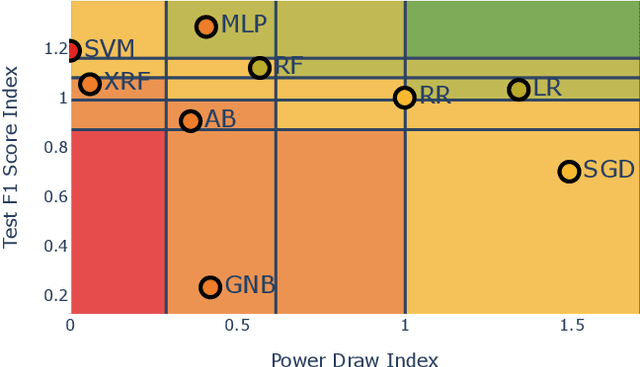
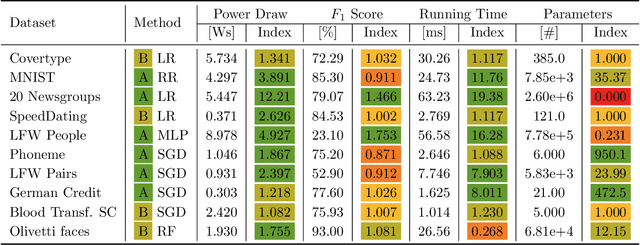
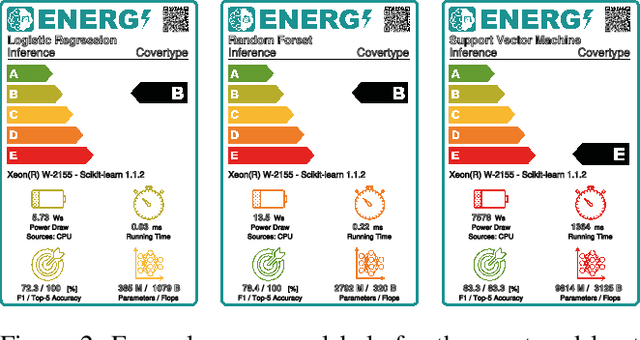
Advances in artificial intelligence need to become more resource-aware and sustainable. This requires clear assessment and reporting of energy efficiency trade-offs, like sacrificing fast running time for higher predictive performance. While first methods for investigating efficiency have been proposed, we still lack comprehensive results for popular methods and data sets. In this work, we attempt to fill this information gap by providing empiric insights for popular AI benchmarks, with a total of 100 experiments. Our findings are evidence of how different data sets all have their own efficiency landscape, and show that methods can be more or less likely to act efficiently.
Efficient Uncertainty Estimation in Spiking Neural Networks via MC-dropout
Apr 20, 2023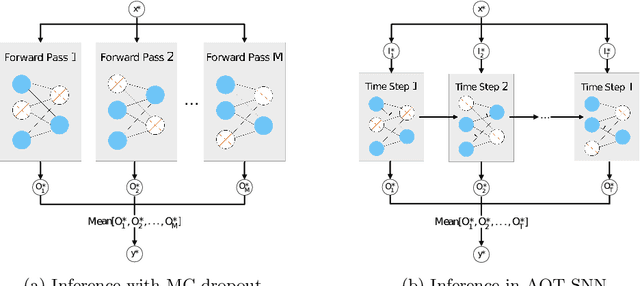
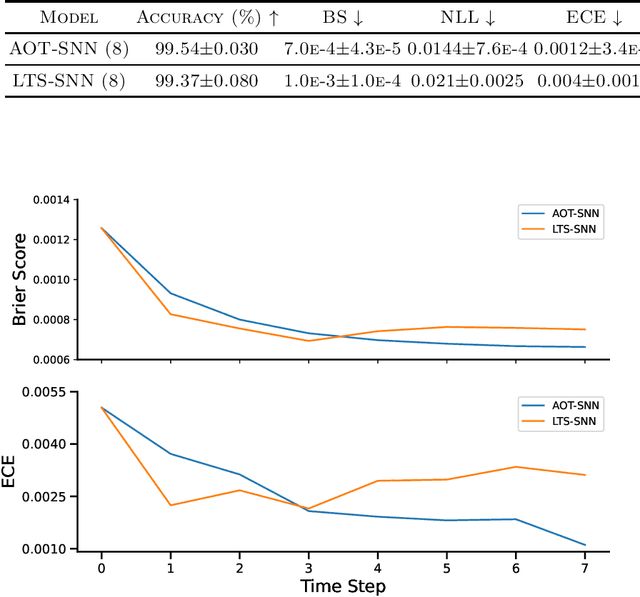
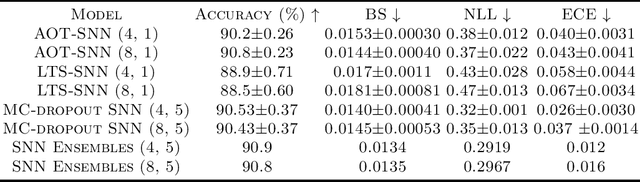
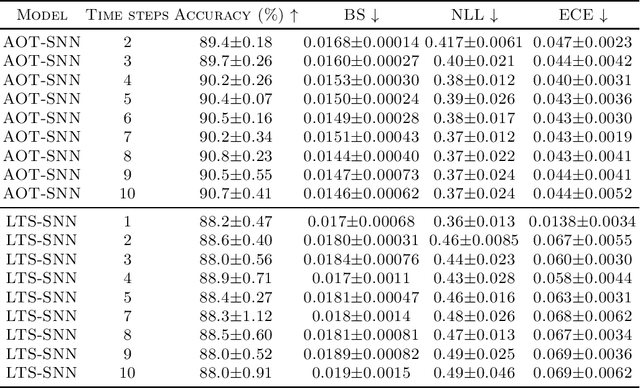
Spiking neural networks (SNNs) have gained attention as models of sparse and event-driven communication of biological neurons, and as such have shown increasing promise for energy-efficient applications in neuromorphic hardware. As with classical artificial neural networks (ANNs), predictive uncertainties are important for decision making in high-stakes applications, such as autonomous vehicles, medical diagnosis, and high frequency trading. Yet, discussion of uncertainty estimation in SNNs is limited, and approaches for uncertainty estimation in artificial neural networks (ANNs) are not directly applicable to SNNs. Here, we propose an efficient Monte Carlo(MC)-dropout based approach for uncertainty estimation in SNNs. Our approach exploits the time-step mechanism of SNNs to enable MC-dropout in a computationally efficient manner, without introducing significant overheads during training and inference while demonstrating high accuracy and uncertainty quality.
SALSA: Simulated Annealing based Loop-Ordering Scheduler for DNN Accelerators
Apr 20, 2023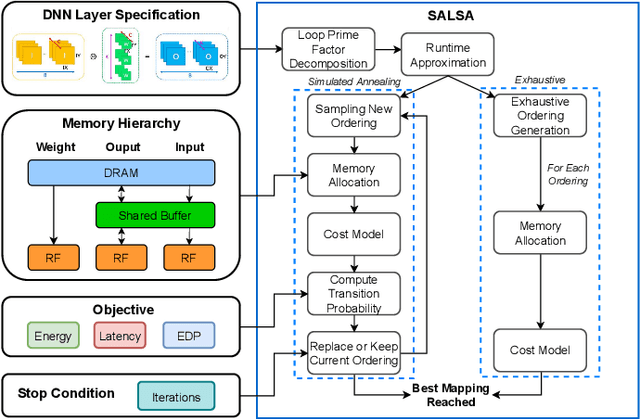
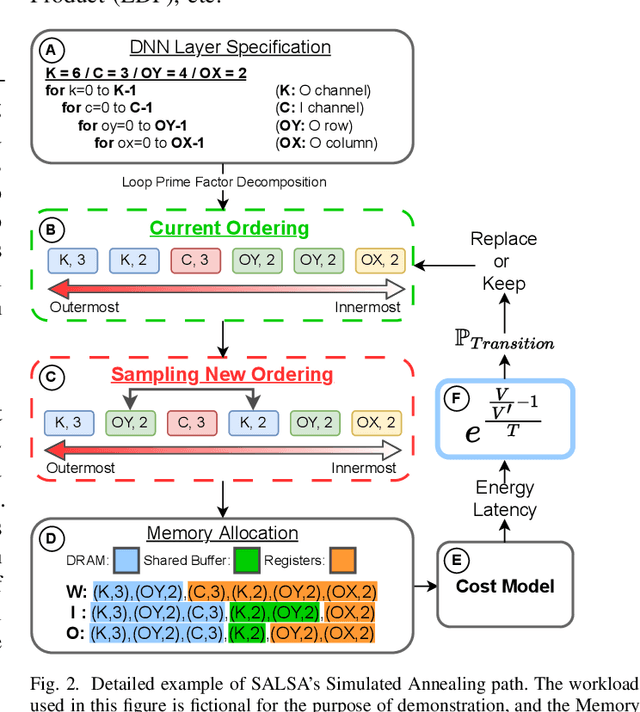
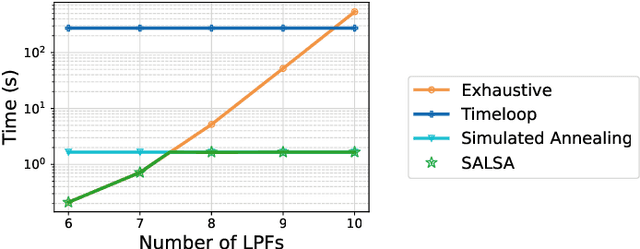
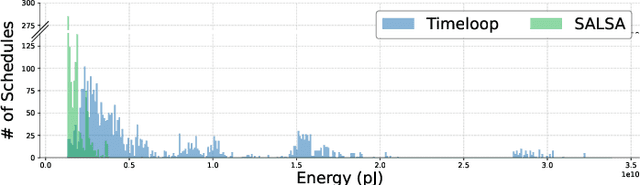
To meet the growing need for computational power for DNNs, multiple specialized hardware architectures have been proposed. Each DNN layer should be mapped onto the hardware with the most efficient schedule, however, SotA schedulers struggle to consistently provide optimum schedules in a reasonable time across all DNN-HW combinations. This paper proposes SALSA, a fast dual-engine scheduler to generate optimal execution schedules for both even and uneven mapping. We introduce a new strategy, combining exhaustive search with simulated annealing to address the dynamic nature of the loop ordering design space size across layers. SALSA is extensively benchmarked against two SotA schedulers, LOMA and Timeloop on 5 different DNNs, on average SALSA finds schedules with 11.9% and 7.6% lower energy while speeding up the search by 1.7x and 24x compared to LOMA and Timeloop, respectively.
q2d: Turning Questions into Dialogs to Teach Models How to Search
Apr 27, 2023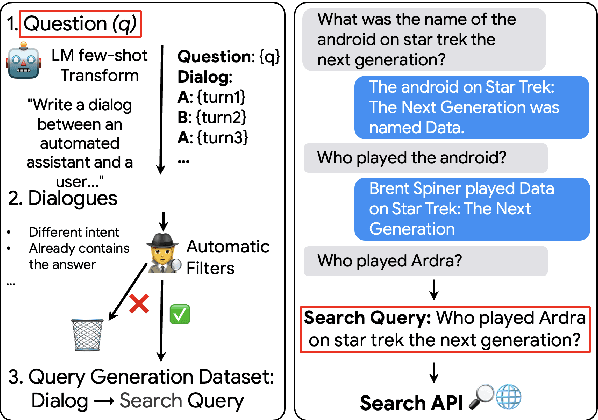


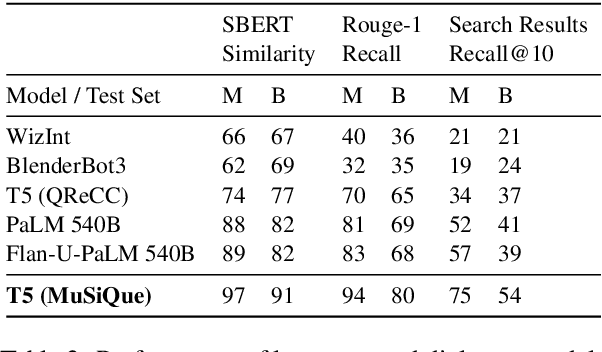
One of the exciting capabilities of recent language models for dialog is their ability to independently search for relevant information to ground a given dialog response. However, obtaining training data to teach models how to issue search queries is time and resource consuming. In this work, we propose q2d: an automatic data generation pipeline that generates information-seeking dialogs from questions. We prompt a large language model (PaLM) to create conversational versions of question answering datasets, and use it to improve query generation models that communicate with external search APIs to ground dialog responses. Unlike previous approaches which relied on human written dialogs with search queries, our method allows to automatically generate query-based grounded dialogs with better control and scale. Our experiments demonstrate that: (1) For query generation on the QReCC dataset, models trained on our synthetically-generated data achieve 90%--97% of the performance of models trained on the human-generated data; (2) We can successfully generate data for training dialog models in new domains without any existing dialog data as demonstrated on the multi-hop MuSiQue and Bamboogle QA datasets. (3) We perform a thorough analysis of the generated dialogs showing that humans find them of high quality and struggle to distinguish them from human-written dialogs.
Inferring Preferences from Demonstrations in Multi-objective Reinforcement Learning: A Dynamic Weight-based Approach
Apr 27, 2023
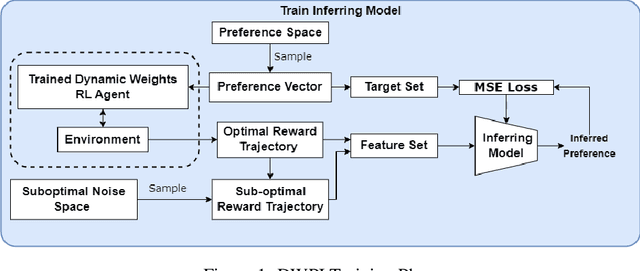
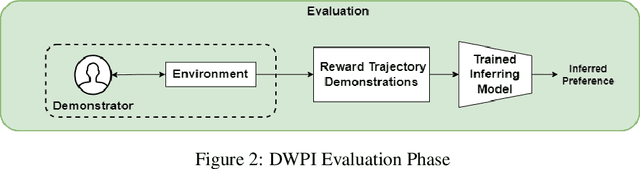
Many decision-making problems feature multiple objectives. In such problems, it is not always possible to know the preferences of a decision-maker for different objectives. However, it is often possible to observe the behavior of decision-makers. In multi-objective decision-making, preference inference is the process of inferring the preferences of a decision-maker for different objectives. This research proposes a Dynamic Weight-based Preference Inference (DWPI) algorithm that can infer the preferences of agents acting in multi-objective decision-making problems, based on observed behavior trajectories in the environment. The proposed method is evaluated on three multi-objective Markov decision processes: Deep Sea Treasure, Traffic, and Item Gathering. The performance of the proposed DWPI approach is compared to two existing preference inference methods from the literature, and empirical results demonstrate significant improvements compared to the baseline algorithms, in terms of both time requirements and accuracy of the inferred preferences. The Dynamic Weight-based Preference Inference algorithm also maintains its performance when inferring preferences for sub-optimal behavior demonstrations. In addition to its impressive performance, the Dynamic Weight-based Preference Inference algorithm does not require any interactions during training with the agent whose preferences are inferred, all that is required is a trajectory of observed behavior.
Learning Neural PDE Solvers with Parameter-Guided Channel Attention
Apr 27, 2023

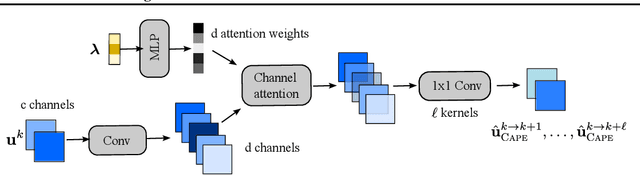
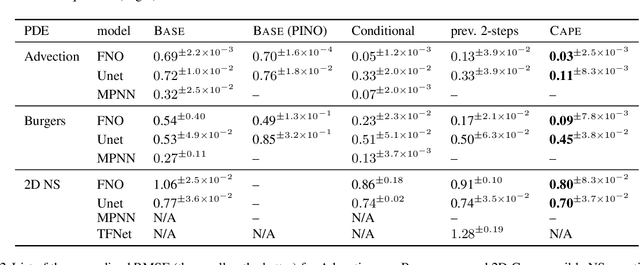
Scientific Machine Learning (SciML) is concerned with the development of learned emulators of physical systems governed by partial differential equations (PDE). In application domains such as weather forecasting, molecular dynamics, and inverse design, ML-based surrogate models are increasingly used to augment or replace inefficient and often non-differentiable numerical simulation algorithms. While a number of ML-based methods for approximating the solutions of PDEs have been proposed in recent years, they typically do not adapt to the parameters of the PDEs, making it difficult to generalize to PDE parameters not seen during training. We propose a Channel Attention mechanism guided by PDE Parameter Embeddings (CAPE) component for neural surrogate models and a simple yet effective curriculum learning strategy. The CAPE module can be combined with neural PDE solvers allowing them to adapt to unseen PDE parameters. The curriculum learning strategy provides a seamless transition between teacher-forcing and fully auto-regressive training. We compare CAPE in conjunction with the curriculum learning strategy using a popular PDE benchmark and obtain consistent and significant improvements over the baseline models. The experiments also show several advantages of CAPE, such as its increased ability to generalize to unseen PDE parameters without large increases inference time and parameter count.
MINN: Learning the dynamics of differential-algebraic equations and application to battery modeling
Apr 27, 2023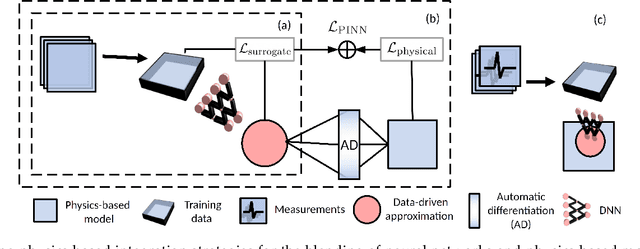

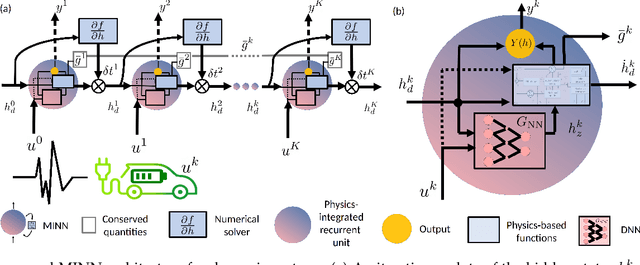
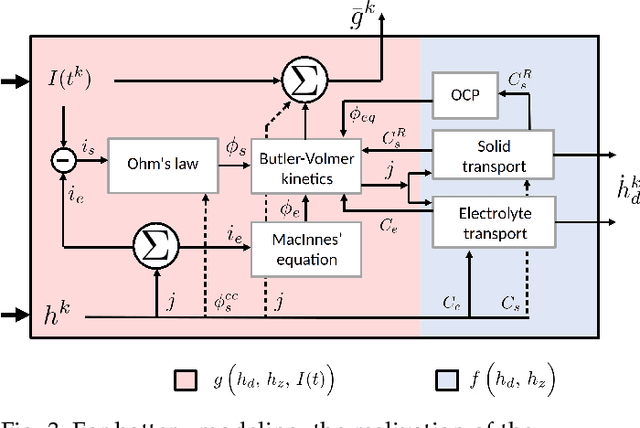
The concept of integrating physics-based and data-driven approaches has become popular for modeling sustainable energy systems. However, the existing literature mainly focuses on the data-driven surrogates generated to replace physics-based models. These models often trade accuracy for speed but lack the generalisability, adaptability, and interpretability inherent in physics-based models, which are often indispensable in the modeling of real-world dynamic systems for optimization and control purposes. In this work, we propose a novel architecture for generating model-integrated neural networks (MINN) to allow integration on the level of learning physics-based dynamics of the system. The obtained hybrid model solves an unsettled research problem in control-oriented modeling, i.e., how to obtain an optimally simplified model that is physically insightful, numerically accurate, and computationally tractable simultaneously. We apply the proposed neural network architecture to model the electrochemical dynamics of lithium-ion batteries and show that MINN is extremely data-efficient to train while being sufficiently generalizable to previously unseen input data, owing to its underlying physical invariants. The MINN battery model has an accuracy comparable to the first principle-based model in predicting both the system outputs and any locally distributed electrochemical behaviors but achieves two orders of magnitude reduction in the solution time.
Vehicle Trajectory Prediction based Predictive Collision Risk Assessment for Autonomous Driving in Highway Scenarios
Apr 12, 2023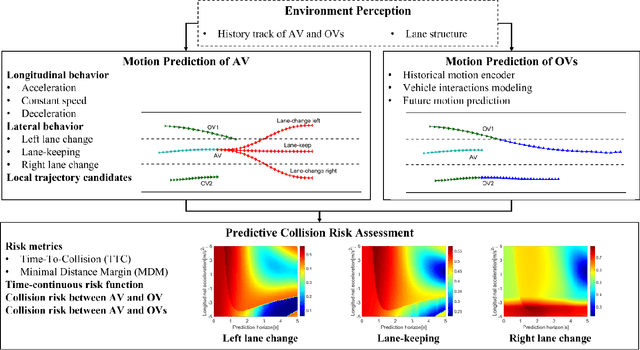
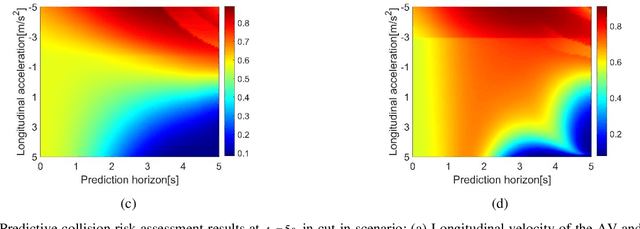
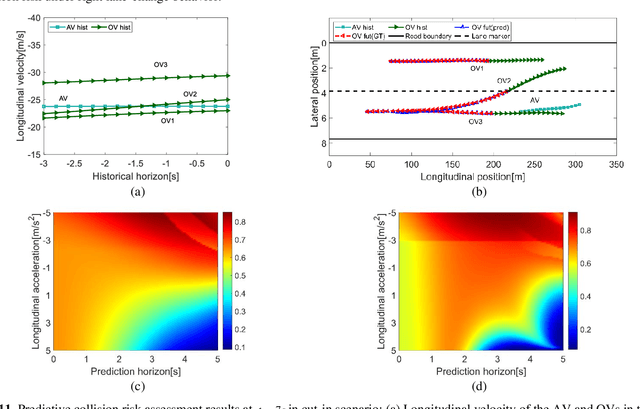
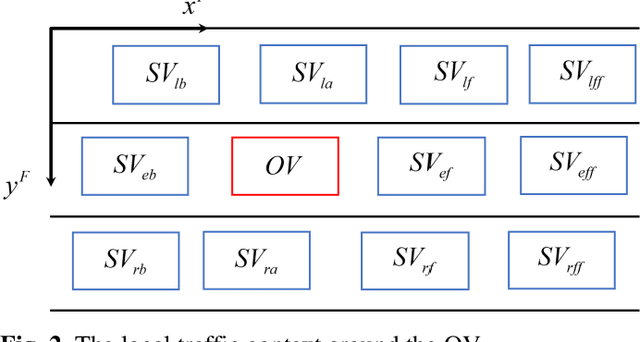
For driving safely and efficiently in highway scenarios, autonomous vehicles (AVs) must be able to predict future behaviors of surrounding object vehicles (OVs), and assess collision risk accurately for reasonable decision-making. Aiming at autonomous driving in highway scenarios, a predictive collision risk assessment method based on trajectory prediction of OVs is proposed in this paper. Firstly, the vehicle trajectory prediction is formulated as a sequence generation task with long short-term memory (LSTM) encoder-decoder framework. Convolutional social pooling (CSP) and graph attention network (GAN) are adopted for extracting local spatial vehicle interactions and distant spatial vehicle interactions, respectively. Then, two basic risk metrics, time-to-collision (TTC) and minimal distance margin (MDM), are calculated between the predicted trajectory of OV and the candidate trajectory of AV. Consequently, a time-continuous risk function is constructed with temporal and spatial risk metrics. Finally, the vehicle trajectory prediction model CSP-GAN-LSTM is evaluated on two public highway datasets. The quantitative results indicate that the proposed CSP-GAN-LSTM model outperforms the existing state-of-the-art (SOTA) methods in terms of position prediction accuracy. Besides, simulation results in typical highway scenarios further validate the feasibility and effectiveness of the proposed predictive collision risk assessment method.