 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-reversal equivariant neural network potential and Hamiltonian for magnetic materials
Nov 21, 2022
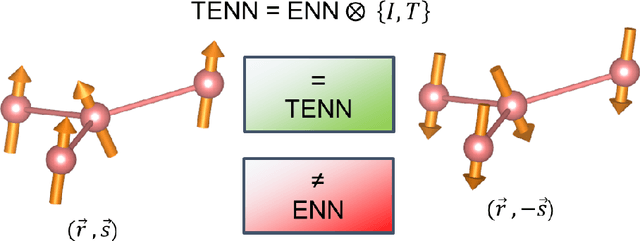

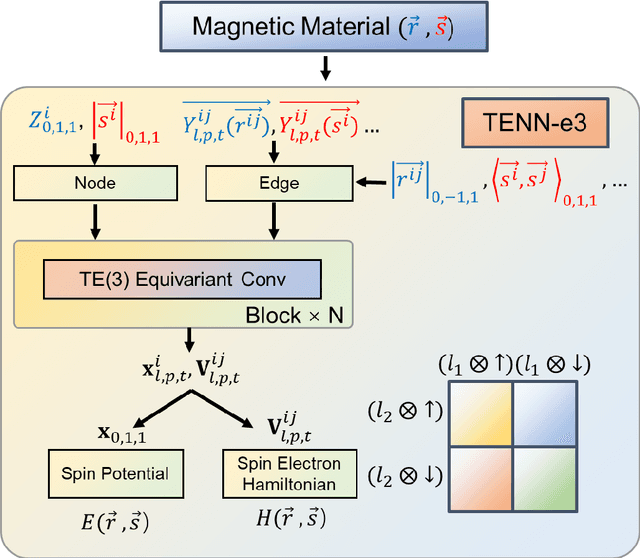
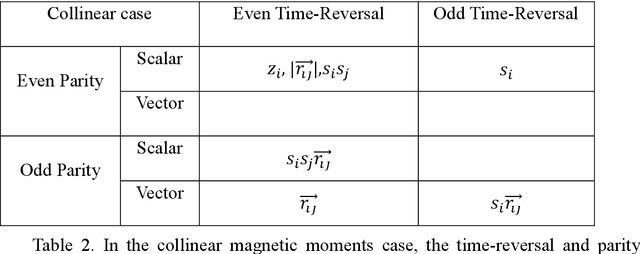
This work presents Time-reversal Equivariant Neural Network (TENN) framework. With TENN, the time-reversal symmetry is considered in the equivariant neural network (ENN), which generalizes the ENN to consider physical quantities related to time-reversal symmetry such as spin and velocity of atoms. TENN-e3, as the time-reversal-extension of E(3) equivariant neural network, is developed to keep the Time-reversal E(3) equivariant with consideration of whether to include the spin-orbit effect for both collinear and non-collinear magnetic moments situations for magnetic material. TENN-e3 can construct spin neural network potential and the Hamiltonian of magnetic material from ab-initio calculations. Time-reversal-E(3)-equivariant convolutions for interactions of spinor and geometric tensors are employed in TENN-e3. Compared to the popular ENN, TENN-e3 can describe the complex spin-lattice coupling with high accuracy and keep time-reversal symmetry which is not preserved in the existing E(3)-equivariant model. Also, the Hamiltonian of magnetic material with time-reversal symmetry can be built with TENN-e3. TENN paves a new way to spin-lattice dynamics simulations over long-time scales and electronic structure calculations of large-scale magnetic materials.
Inline Citation Classification using Peripheral Context and Time-evolving Augmentation
Mar 01, 2023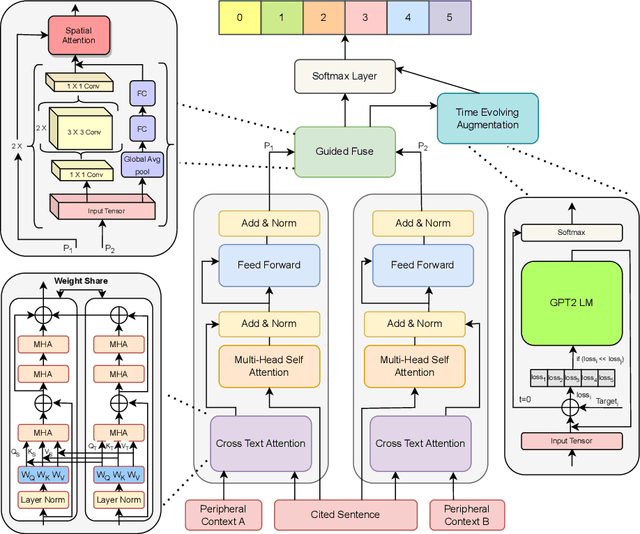
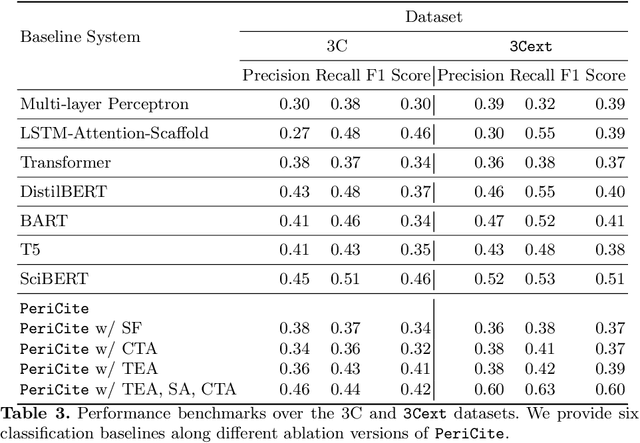
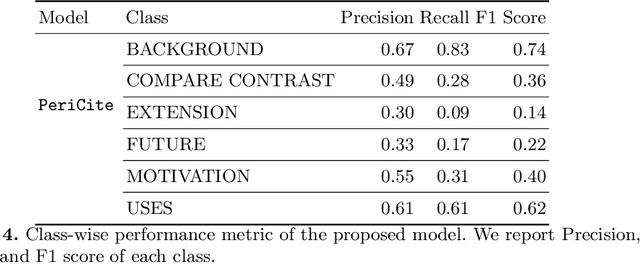
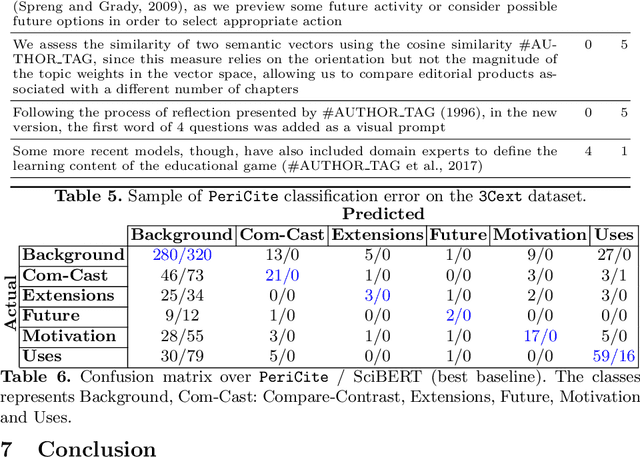
Citation plays a pivotal role in determining the associations among research articles. It portrays essential information in indicative, supportive, or contrastive studies. The task of inline citation classification aids in extrapolating these relationships; However, existing studies are still immature and demand further scrutiny. Current datasets and methods used for inline citation classification only use citation-marked sentences constraining the model to turn a blind eye to domain knowledge and neighboring contextual sentences. In this paper, we propose a new dataset, named 3Cext, which along with the cited sentences, provides discourse information using the vicinal sentences to analyze the contrasting and entailing relationships as well as domain information. We propose PeriCite, a Transformer-based deep neural network that fuses peripheral sentences and domain knowledge. Our model achieves the state-of-the-art on the 3Cext dataset by +0.09 F1 against the best baseline. We conduct extensive ablations to analyze the efficacy of the proposed dataset and model fusion methods.
Real-Time High-Resolution Pedestrian Detection in Crowded Scenes via Parallel Edge Offloading
Jan 20, 2023
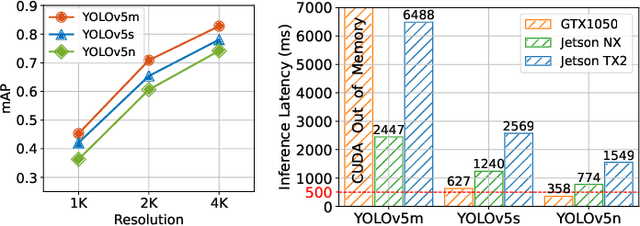
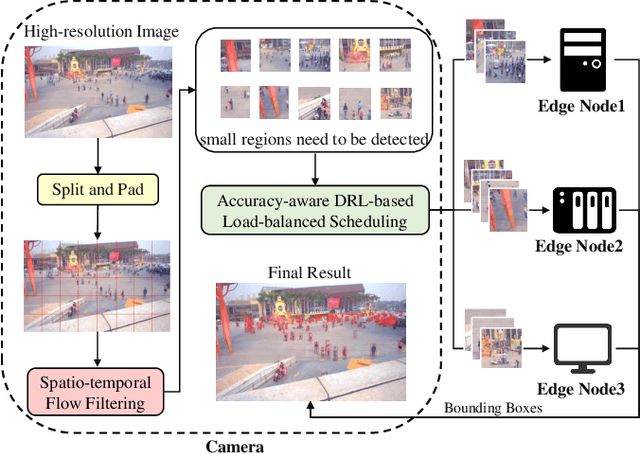

To identify dense and small-size pedestrians in surveillance systems, high-resolution cameras are widely deployed, where high-resolution images are captured and delivered to off-the-shelf pedestrian detection models. However, given the highly computation-intensive workload brought by the high resolution, the resource-constrained cameras fail to afford accurate inference in real time. To address that, we propose Hode, an offloaded video analytic framework that utilizes multiple edge nodes in proximity to expedite pedestrian detection with high-resolution inputs. Specifically, Hode can intelligently split high-resolution images into respective regions and then offload them to distributed edge nodes to perform pedestrian detection in parallel. A spatio-temporal flow filtering method is designed to enable context-aware region partitioning, as well as a DRL-based scheduling algorithm to allow accuracy-aware load balance among heterogeneous edge nodes. Extensive evaluation results using realistic prototypes show that Hode can achieve up to 2.01% speedup with very mild accuracy loss.
Video Frame Interpolation with Densely Queried Bilateral Correlation
Apr 26, 2023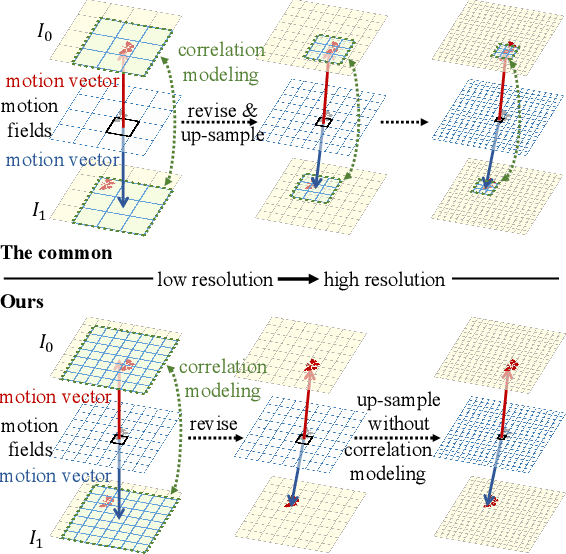
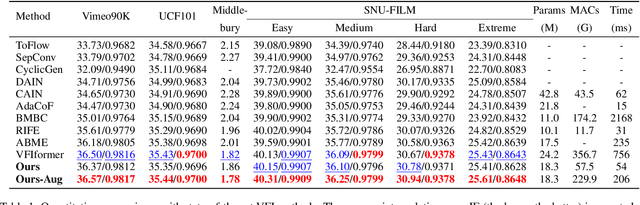
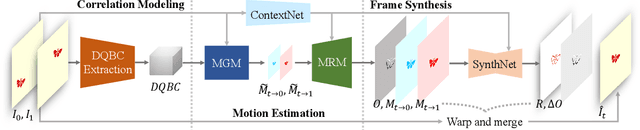
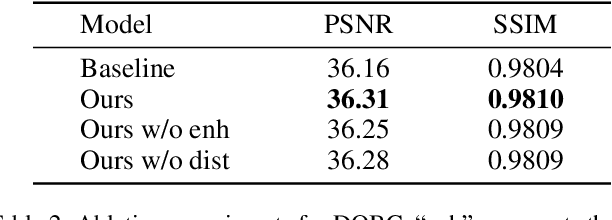
Video Frame Interpolation (VFI) aims to synthesize non-existent intermediate frames between existent frames. Flow-based VFI algorithms estimate intermediate motion fields to warp the existent frames. Real-world motions' complexity and the reference frame's absence make motion estimation challenging. Many state-of-the-art approaches explicitly model the correlations between two neighboring frames for more accurate motion estimation. In common approaches, the receptive field of correlation modeling at higher resolution depends on the motion fields estimated beforehand. Such receptive field dependency makes common motion estimation approaches poor at coping with small and fast-moving objects. To better model correlations and to produce more accurate motion fields, we propose the Densely Queried Bilateral Correlation (DQBC) that gets rid of the receptive field dependency problem and thus is more friendly to small and fast-moving objects. The motion fields generated with the help of DQBC are further refined and up-sampled with context features. After the motion fields are fixed, a CNN-based SynthNet synthesizes the final interpolated frame. Experiments show that our approach enjoys higher accuracy and less inference time than the state-of-the-art. Source code is available at https://github.com/kinoud/DQBC.
Is a prompt and a few samples all you need? Using GPT-4 for data augmentation in low-resource classification tasks
Apr 26, 2023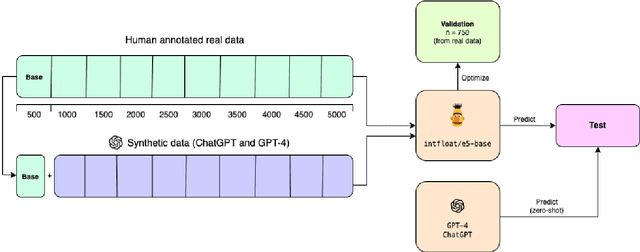

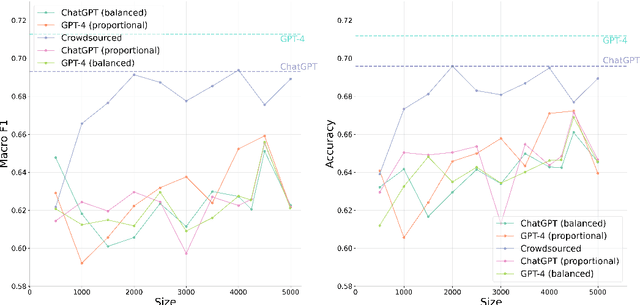
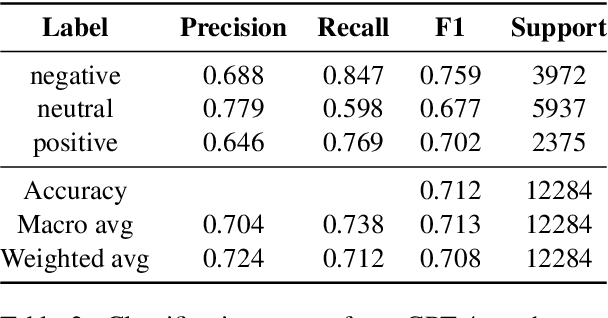
Obtaining and annotating data can be expensive and time-consuming, especially in complex, low-resource domains. We use GPT-4 and ChatGPT to augment small labeled datasets with synthetic data via simple prompts, in three different classification tasks with varying complexity. For each task, we randomly select a base sample of 500 texts to generate 5,000 new synthetic samples. We explore two augmentation strategies: one that preserves original label distribution and another that balances the distribution. Using a progressively larger training sample size, we train and evaluate a 110M parameter multilingual language model on the real and synthetic data separately. We also test GPT-4 and ChatGPT in a zero-shot setting on the test sets. We observe that GPT-4 and ChatGPT have strong zero-shot performance across all tasks. We find that data augmented with synthetic samples yields a good downstream performance, and particularly aids in low-resource settings, such as in identifying rare classes. Human-annotated data exhibits a strong predictive power, overtaking synthetic data in two out of the three tasks. This finding highlights the need for more complex prompts for synthetic datasets to consistently surpass human-generated ones.
Multimodal Composite Association Score: Measuring Gender Bias in Generative Multimodal Models
Apr 26, 2023
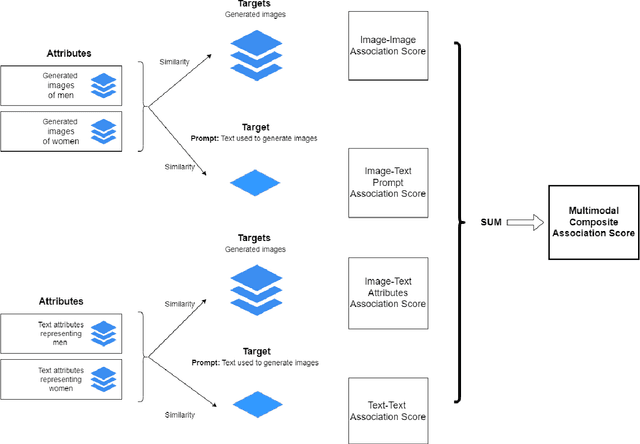

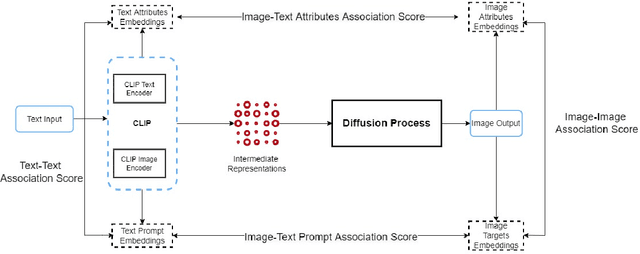
Generative multimodal models based on diffusion models have seen tremendous growth and advances in recent years. Models such as DALL-E and Stable Diffusion have become increasingly popular and successful at creating images from texts, often combining abstract ideas. However, like other deep learning models, they also reflect social biases they inherit from their training data, which is often crawled from the internet. Manually auditing models for biases can be very time and resource consuming and is further complicated by the unbounded and unconstrained nature of inputs these models can take. Research into bias measurement and quantification has generally focused on small single-stage models working on a single modality. Thus the emergence of multistage multimodal models requires a different approach. In this paper, we propose Multimodal Composite Association Score (MCAS) as a new method of measuring gender bias in multimodal generative models. Evaluating both DALL-E 2 and Stable Diffusion using this approach uncovered the presence of gendered associations of concepts embedded within the models. We propose MCAS as an accessible and scalable method of quantifying potential bias for models with different modalities and a range of potential biases.
OFAR: A Multimodal Evidence Retrieval Framework for Illegal Live-streaming Identification
Apr 26, 2023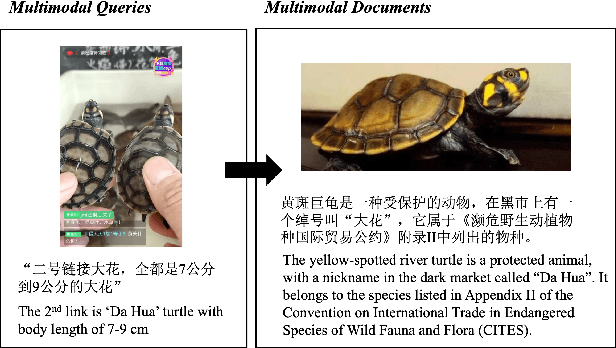
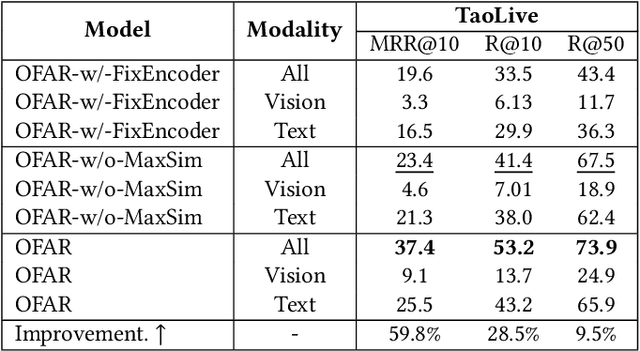
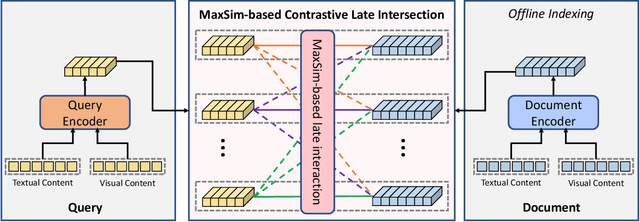
Illegal live-streaming identification, which aims to help live-streaming platforms immediately recognize the illegal behaviors in the live-streaming, such as selling precious and endangered animals, plays a crucial role in purifying the network environment. Traditionally, the live-streaming platform needs to employ some professionals to manually identify the potential illegal live-streaming. Specifically, the professional needs to search for related evidence from a large-scale knowledge database for evaluating whether a given live-streaming clip contains illegal behavior, which is time-consuming and laborious. To address this issue, in this work, we propose a multimodal evidence retrieval system, named OFAR, to facilitate the illegal live-streaming identification. OFAR consists of three modules: Query Encoder, Document Encoder, and MaxSim-based Contrastive Late Intersection. Both query encoder and document encoder are implemented with the advanced OFA encoder, which is pretrained on a large-scale multimodal dataset. In the last module, we introduce contrastive learning on the basis of the MaxiSim-based late intersection, to enhance the model's ability of query-document matching. The proposed framework achieves significant improvement on our industrial dataset TaoLive, demonstrating the advances of our scheme.
VGOS: Voxel Grid Optimization for View Synthesis from Sparse Inputs
Apr 26, 2023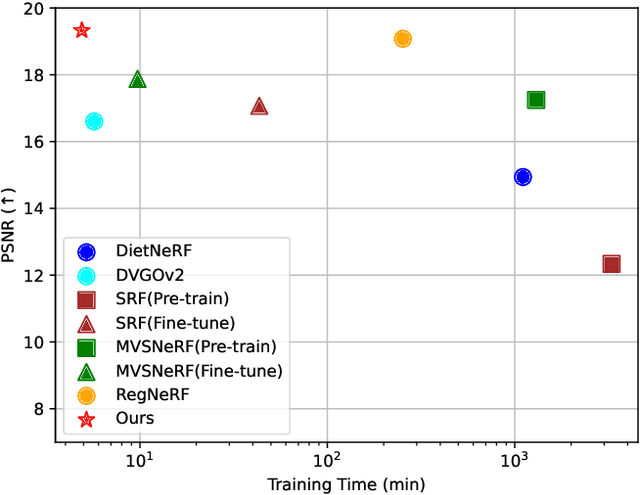
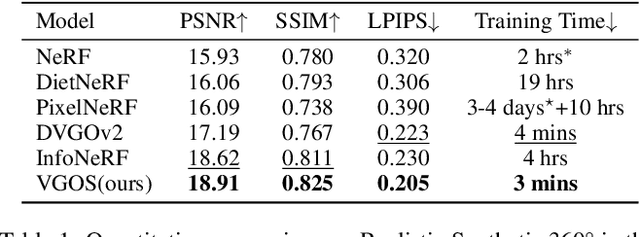
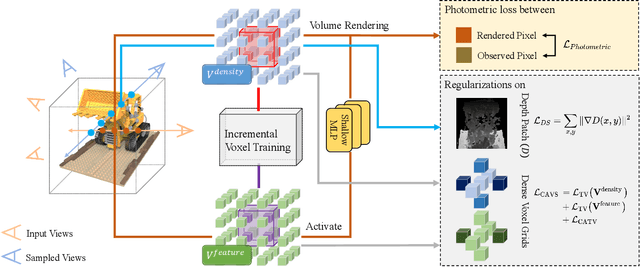
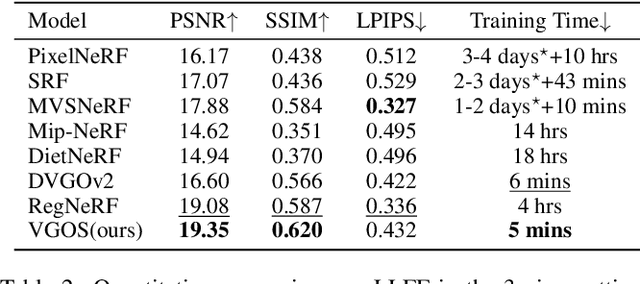
Neural Radiance Fields (NeRF) has shown great success in novel view synthesis due to its state-of-the-art quality and flexibility. However, NeRF requires dense input views (tens to hundreds) and a long training time (hours to days) for a single scene to generate high-fidelity images. Although using the voxel grids to represent the radiance field can significantly accelerate the optimization process, we observe that for sparse inputs, the voxel grids are more prone to overfitting to the training views and will have holes and floaters, which leads to artifacts. In this paper, we propose VGOS, an approach for fast (3-5 minutes) radiance field reconstruction from sparse inputs (3-10 views) to address these issues. To improve the performance of voxel-based radiance field in sparse input scenarios, we propose two methods: (a) We introduce an incremental voxel training strategy, which prevents overfitting by suppressing the optimization of peripheral voxels in the early stage of reconstruction. (b) We use several regularization techniques to smooth the voxels, which avoids degenerate solutions. Experiments demonstrate that VGOS achieves state-of-the-art performance for sparse inputs with super-fast convergence. Code will be available at https://github.com/SJoJoK/VGOS.
Distance Weighted Supervised Learning for Offline Interaction Data
Apr 26, 2023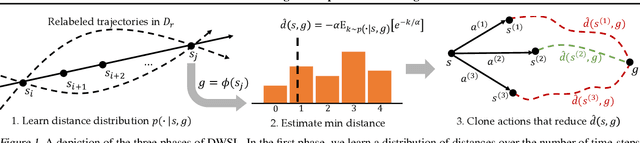
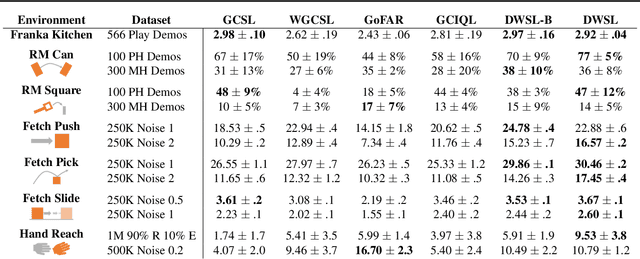
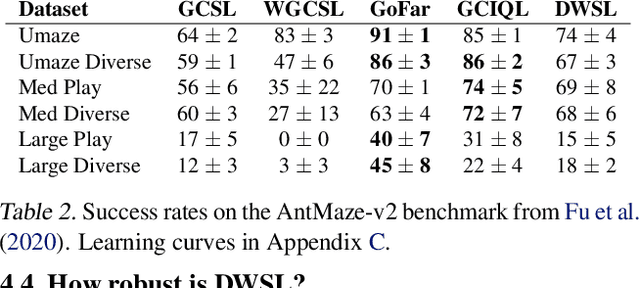
Sequential decision making algorithms often struggle to leverage different sources of unstructured offline interaction data. Imitation learning (IL) methods based on supervised learning are robust, but require optimal demonstrations, which are hard to collect. Offline goal-conditioned reinforcement learning (RL) algorithms promise to learn from sub-optimal data, but face optimization challenges especially with high-dimensional data. To bridge the gap between IL and RL, we introduce Distance Weighted Supervised Learning or DWSL, a supervised method for learning goal-conditioned policies from offline data. DWSL models the entire distribution of time-steps between states in offline data with only supervised learning, and uses this distribution to approximate shortest path distances. To extract a policy, we weight actions by their reduction in distance estimates. Theoretically, DWSL converges to an optimal policy constrained to the data distribution, an attractive property for offline learning, without any bootstrapping. Across all datasets we test, DWSL empirically maintains behavior cloning as a lower bound while still exhibiting policy improvement. In high-dimensional image domains, DWSL surpasses the performance of both prior goal-conditioned IL and RL algorithms. Visualizations and code can be found at https://sites.google.com/view/dwsl/home .
DAMO-StreamNet: Optimizing Streaming Perception in Autonomous Driving
Mar 30, 2023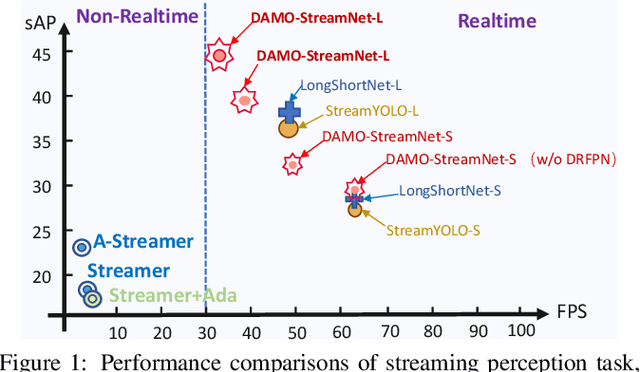
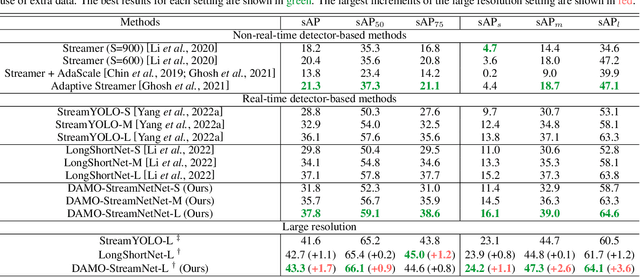
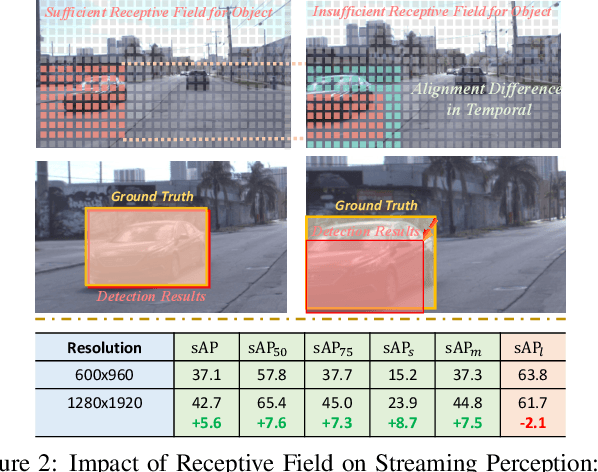
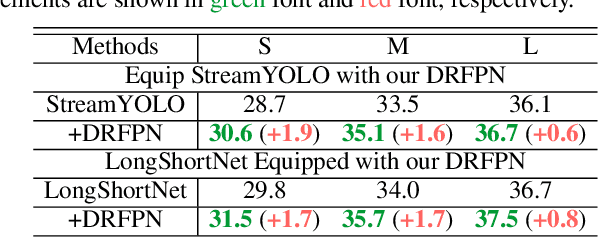
Real-time perception, or streaming perception, is a crucial aspect of autonomous driving that has yet to be thoroughly explored in existing research. To address this gap, we present DAMO-StreamNet, an optimized framework that combines recent advances from the YOLO series with a comprehensive analysis of spatial and temporal perception mechanisms, delivering a cutting-edge solution. The key innovations of DAMO-StreamNet are: (1) A robust neck structure incorporating deformable convolution, enhancing the receptive field and feature alignment capabilities. (2) A dual-branch structure that integrates short-path semantic features and long-path temporal features, improving motion state prediction accuracy. (3) Logits-level distillation for efficient optimization, aligning the logits of teacher and student networks in semantic space. (4) A real-time forecasting mechanism that updates support frame features with the current frame, ensuring seamless streaming perception during inference. Our experiments demonstrate that DAMO-StreamNet surpasses existing state-of-the-art methods, achieving 37.8% (normal size (600, 960)) and 43.3% (large size (1200, 1920)) sAP without using extra data. This work not only sets a new benchmark for real-time perception but also provides valuable insights for future research. Additionally, DAMO-StreamNet can be applied to various autonomous systems, such as drones and robots, paving the way for real-time perception.