 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-to-end deep learning-based framework for path planning and collision checking: bin picking application
Mar 31, 2023
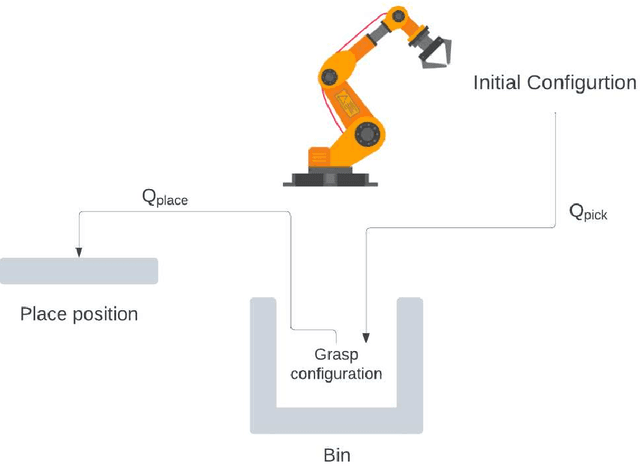
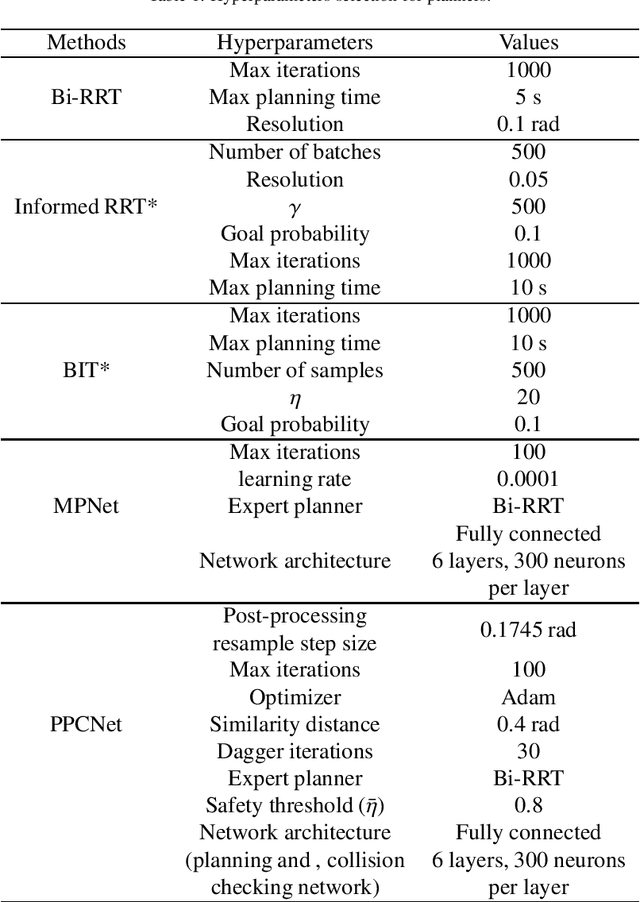
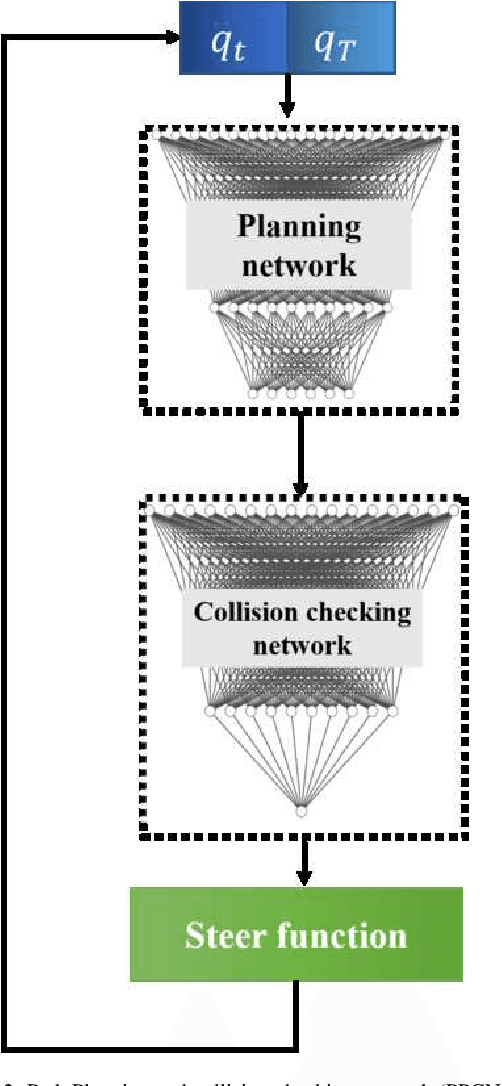
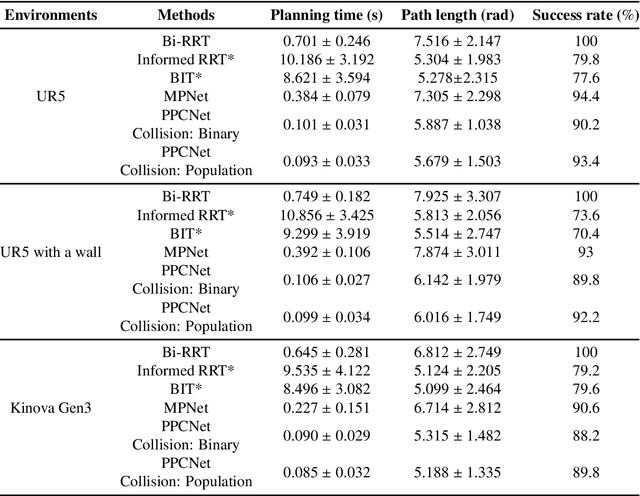
Real-time and efficient path planning is critical for all robotic systems. In particular, it is of greater importance for industrial robots since the overall planning and execution time directly impact the cycle time and automation economics in production lines. While the problem may not be complex in static environments, classical approaches are inefficient in high-dimensional environments in terms of planning time and optimality. Collision checking poses another challenge in obtaining a real-time solution for path planning in complex environments. To address these issues, we propose an end-to-end learning-based framework viz., Path Planning and Collision checking Network (PPCNet). The PPCNet generates the path by computing waypoints sequentially using two networks: the first network generates a waypoint, and the second one determines whether the waypoint is on a collision-free segment of the path. The end-to-end training process is based on imitation learning that uses data aggregation from the experience of an expert planner to train the two networks, simultaneously. We utilize two approaches for training a network that efficiently approximates the exact geometrical collision checking function. Finally, the PPCNet is evaluated in two different simulation environments and a practical implementation on a robotic arm for a bin-picking application. Compared to the state-of-the-art path planning methods, our results show significant improvement in performance by greatly reducing the planning time with comparable success rates and path lengths.
Recurrent Neural Networks and Long Short-Term Memory Networks: Tutorial and Survey
Apr 22, 2023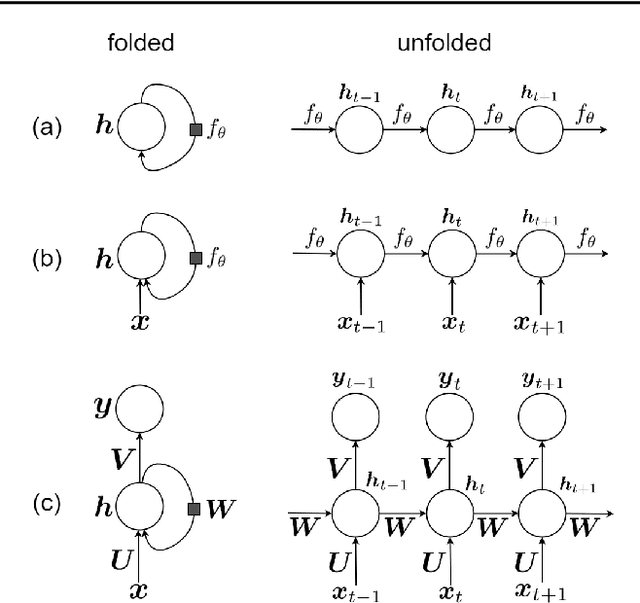
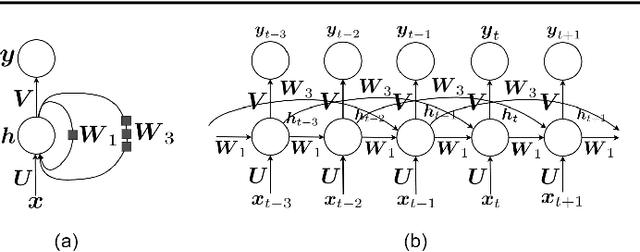
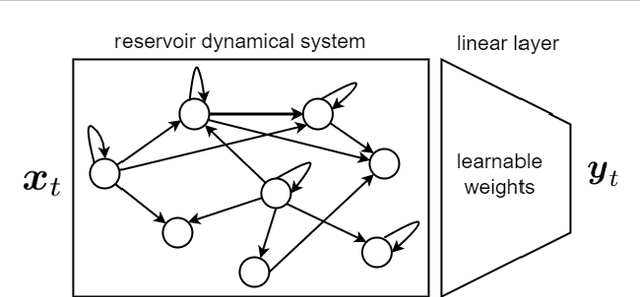
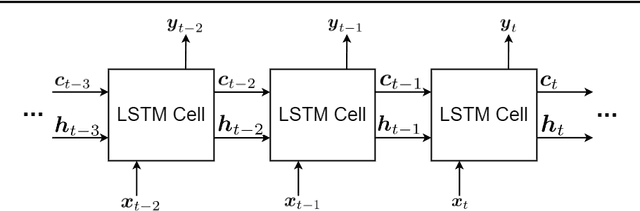
This is a tutorial paper on Recurrent Neural Network (RNN), Long Short-Term Memory Network (LSTM), and their variants. We start with a dynamical system and backpropagation through time for RNN. Then, we discuss the problems of gradient vanishing and explosion in long-term dependencies. We explain close-to-identity weight matrix, long delays, leaky units, and echo state networks for solving this problem. Then, we introduce LSTM gates and cells, history and variants of LSTM, and Gated Recurrent Units (GRU). Finally, we introduce bidirectional RNN, bidirectional LSTM, and the Embeddings from Language Model (ELMo) network, for processing a sequence in both directions.
Partial-Information Multiple Access Protocol for Orthogonal Transmissions
Apr 24, 2023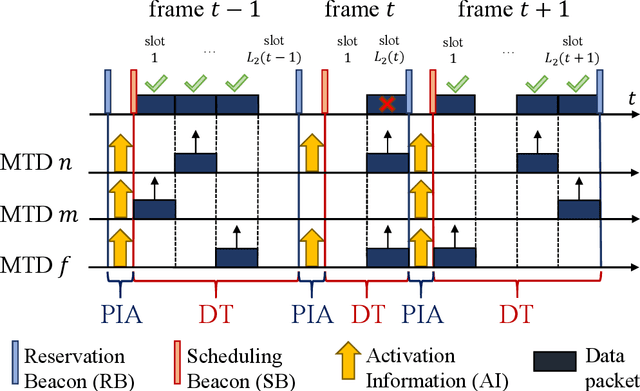
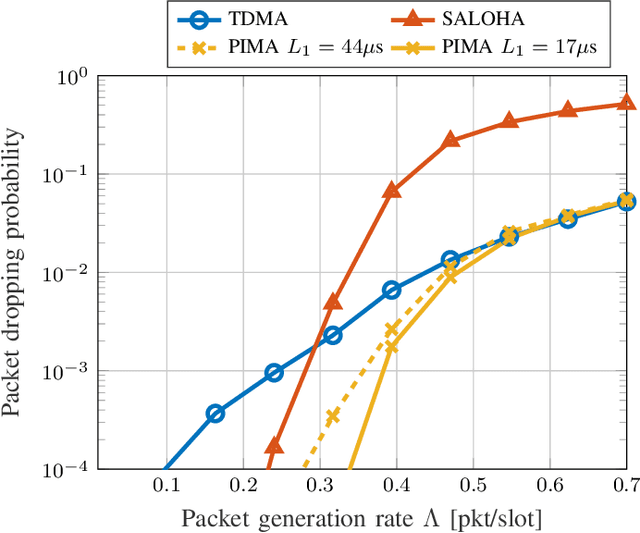
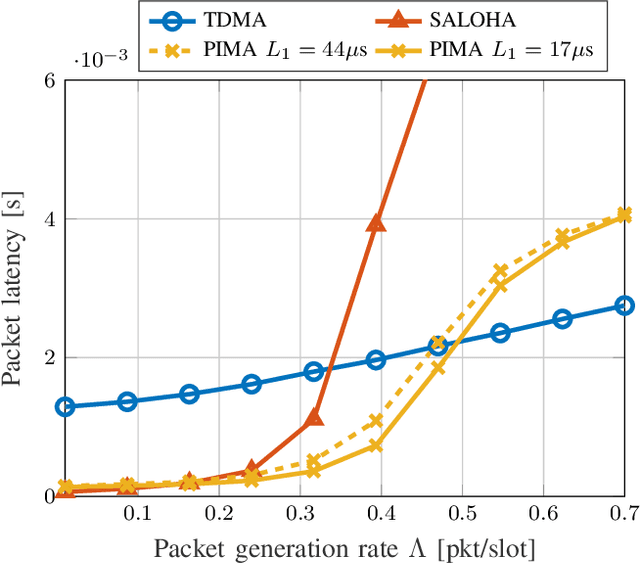
With the stringent requirements introduced by the new sixth-generation (6G) internet-of-things (IoT) use cases, traditional approaches to multiple access control have started to show their limitations. A new wave of grant-free (GF) approaches have been therefore proposed as a viable alternative. However, a definitive solution is still to be accomplished. In our work, we propose a new semi-GF coordinated random access (RA) protocol, denoted as partial-information multiple access (PIMA), to reduce packet loss and latency, particularly in the presence of sporadic activations. We consider a machine-type communications (MTC) scenario, wherein devices need to transmit data packets in the uplink to a base station (BS). When using PIMA, the BS can acquire partial information on the instantaneous traffic conditions and, using compute-over-the-air techniques, estimate the number of devices with packets waiting for transmission in their queue. Based on this knowledge, the BS assigns to each device a single slot for transmission. However, since each slot may still be assigned to multiple users, collisions may occur. Both the total number of allocated slots and the user assignments are optimized, based on the estimated number of active users, to reduce collisions and improve the efficiency of the multiple access scheme. To prove the validity of our solution, we compare PIMA to time-division multiple-access (TDMA) and slotted ALOHA (SALOHA) schemes, the ideal solutions for orthogonal multiple access (OMA) in the time domain in the case of low and high traffic conditions, respectively. We show that PIMA is able not only to adapt to different traffic conditions and to provide fewer packet drops regardless of the intensity of packet generations, but also able to merge the advantages of both TDMA and SALOHA schemes, thus providing performance improvements in terms of packet loss probability and latency.
GazeSAM: What You See is What You Segment
Apr 26, 2023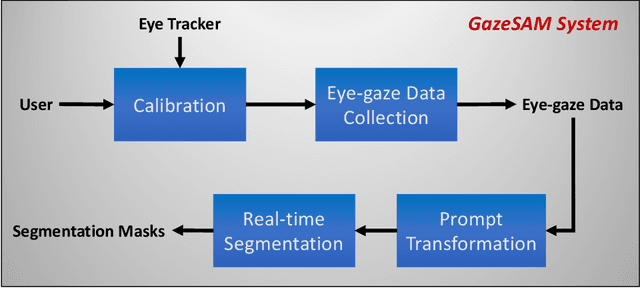
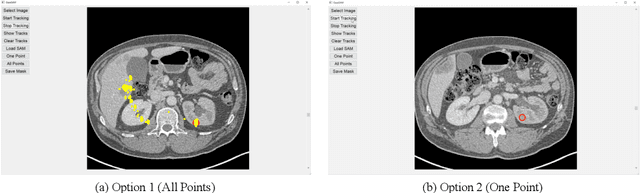
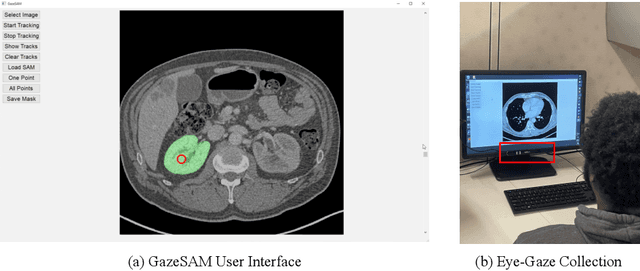
This study investigates the potential of eye-tracking technology and the Segment Anything Model (SAM) to design a collaborative human-computer interaction system that automates medical image segmentation. We present the \textbf{GazeSAM} system to enable radiologists to collect segmentation masks by simply looking at the region of interest during image diagnosis. The proposed system tracks radiologists' eye movement and utilizes the eye-gaze data as the input prompt for SAM, which automatically generates the segmentation mask in real time. This study is the first work to leverage the power of eye-tracking technology and SAM to enhance the efficiency of daily clinical practice. Moreover, eye-gaze data coupled with image and corresponding segmentation labels can be easily recorded for further advanced eye-tracking research. The code is available in \url{https://github.com/ukaukaaaa/GazeSAM}.
Development of a Realistic Crowd Simulation Environment for Fine-grained Validation of People Tracking Methods
Apr 26, 2023
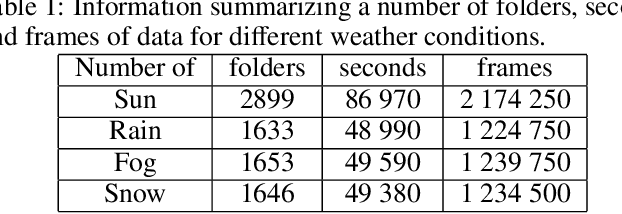


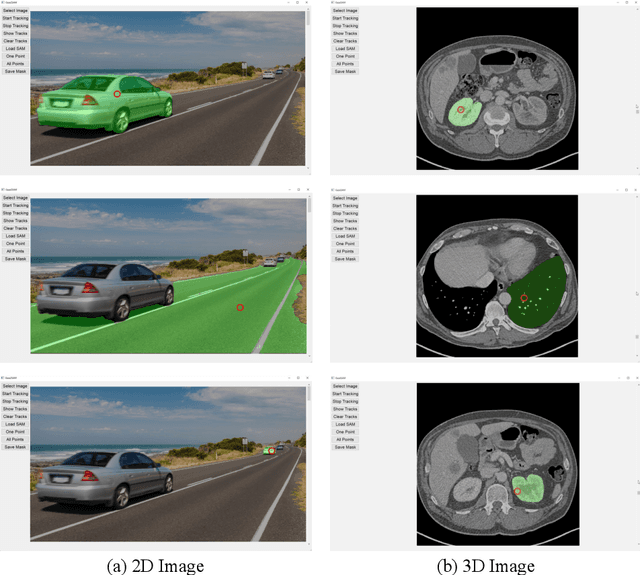
Generally, crowd datasets can be collected or generated from real or synthetic sources. Real data is generated by using infrastructure-based sensors (such as static cameras or other sensors). The use of simulation tools can significantly reduce the time required to generate scenario-specific crowd datasets, facilitate data-driven research, and next build functional machine learning models. The main goal of this work was to develop an extension of crowd simulation (named CrowdSim2) and prove its usability in the application of people-tracking algorithms. The simulator is developed using the very popular Unity 3D engine with particular emphasis on the aspects of realism in the environment, weather conditions, traffic, and the movement and models of individual agents. Finally, three methods of tracking were used to validate generated dataset: IOU-Tracker, Deep-Sort, and Deep-TAMA.
Real-time Health Monitoring of Heat Exchangers using Hypernetworks and PINNs
Dec 20, 2022
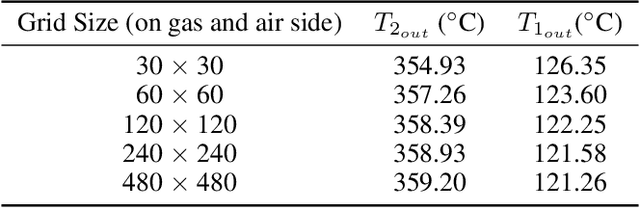
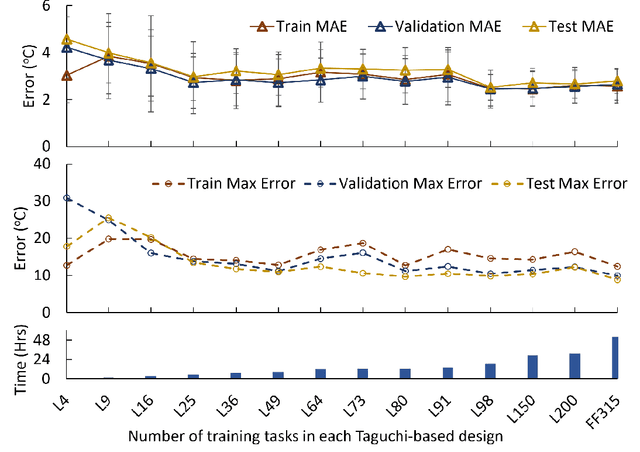
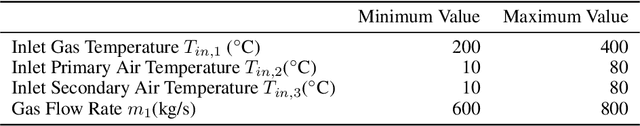
We demonstrate a Physics-informed Neural Network (PINN) based model for real-time health monitoring of a heat exchanger, that plays a critical role in improving energy efficiency of thermal power plants. A hypernetwork based approach is used to enable the domain-decomposed PINN learn the thermal behavior of the heat exchanger in response to dynamic boundary conditions, eliminating the need to re-train. As a result, we achieve orders of magnitude reduction in inference time in comparison to existing PINNs, while maintaining the accuracy on par with the physics-based simulations. This makes the approach very attractive for predictive maintenance of the heat exchanger in digital twin environments.
RPTQ: Reorder-based Post-training Quantization for Large Language Models
Apr 25, 2023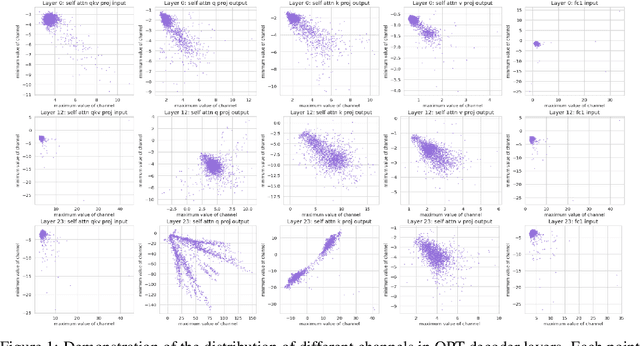
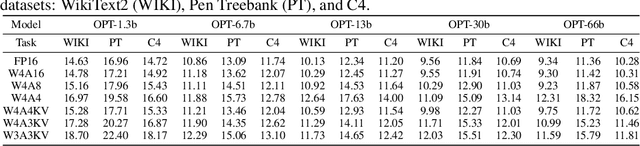
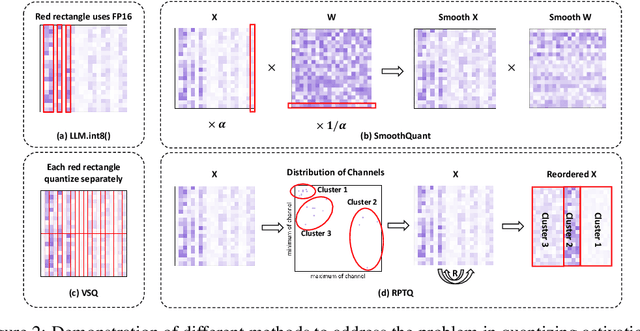
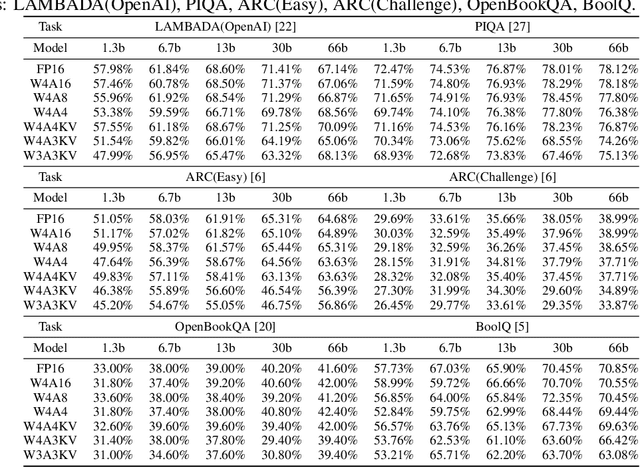
Large-scale language models (LLMs) have demonstrated outstanding performance on various tasks, but their deployment poses challenges due to their enormous model size. In this paper, we identify that the main challenge in quantizing LLMs stems from the different activation ranges between the channels, rather than just the issue of outliers.We propose a novel reorder-based quantization approach, RPTQ, that addresses the issue of quantizing the activations of LLMs. RPTQ rearranges the channels in the activations and then quantizing them in clusters, thereby reducing the impact of range difference of channels. In addition, we reduce the storage and computation overhead by avoiding explicit reordering. By implementing this approach, we achieved a significant breakthrough by pushing LLM models to 3 bit activation for the first time.
Electricity Price Prediction for Energy Storage System Arbitrage: A Decision-focused Approach
Apr 30, 2023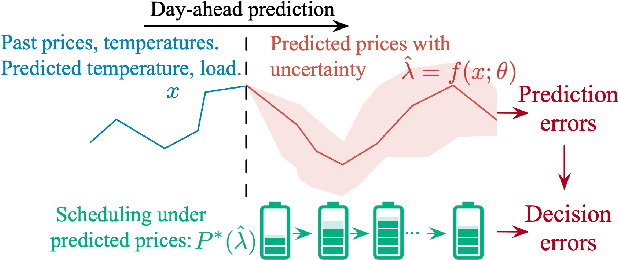
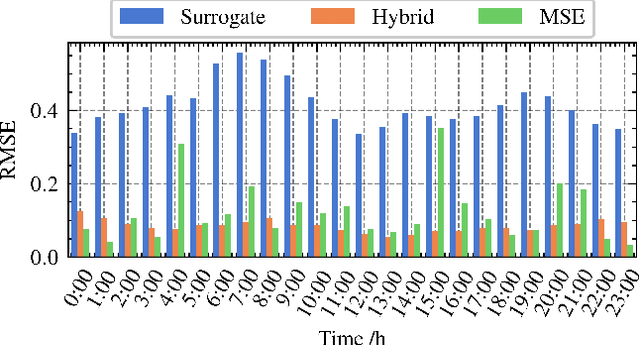
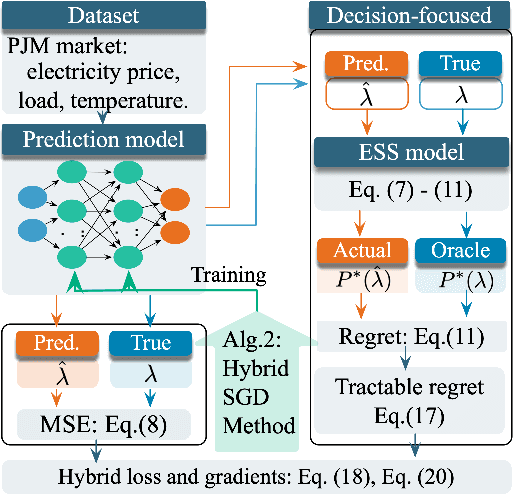
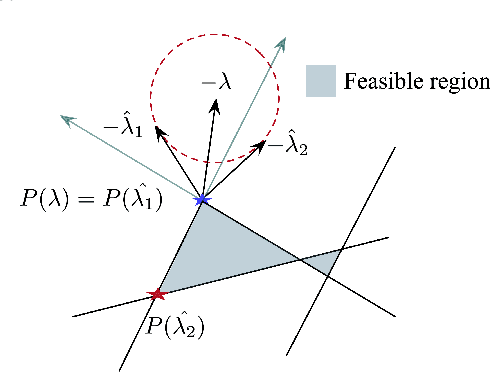
Electricity price prediction plays a vital role in energy storage system (ESS) management. Current prediction models focus on reducing prediction errors but overlook their impact on downstream decision-making. So this paper proposes a decision-focused electricity price prediction approach for ESS arbitrage to bridge the gap from the downstream optimization model to the prediction model. The decision-focused approach aims at utilizing the downstream arbitrage model for training prediction models. It measures the difference between actual decisions under the predicted price and oracle decisions under the true price, i.e., decision error, by regret, transforms it into the tractable surrogate regret, and then derives the gradients to predicted price for training prediction models. Based on the prediction and decision errors, this paper proposes the hybrid loss and corresponding stochastic gradient descent learning method to learn prediction models for prediction and decision accuracy. The case study verifies that the proposed approach can efficiently bring more economic benefits and reduce decision errors by flattening the time distribution of prediction errors, compared to prediction models for only minimizing prediction errors.
SMILE: Single-turn to Multi-turn Inclusive Language Expansion via ChatGPT for Mental Health Support
Apr 30, 2023
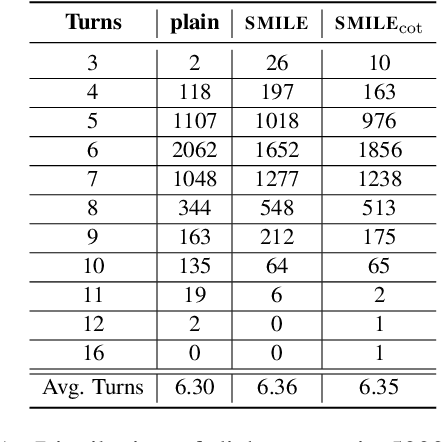


There has been an increasing research interest in developing specialized dialogue systems that can offer mental health support. However, gathering large-scale and real-life multi-turn conversations for mental health support poses challenges due to the sensitivity of personal information, as well as the time and cost involved. To address these issues, we introduce the SMILE approach, an inclusive language expansion technique that employs ChatGPT to extend public single-turn dialogues into multi-turn ones. Our research first presents a preliminary exploratory study that validates the effectiveness of the SMILE approach. Furthermore, we conduct a comprehensive and systematic contrastive analysis of datasets generated with and without the SMILE approach, demonstrating that the SMILE method results in a large-scale, diverse, and close-to-real-life multi-turn mental health support conversation corpus, including dialog topics, lexical and semantic features. Finally, we use the collected corpus (SMILECHAT) to develop a more effective dialogue system that offers emotional support and constructive suggestions in multi-turn conversations for mental health support.
Multi-User Matching and Resource Allocation in Vision Aided Communications
Apr 18, 2023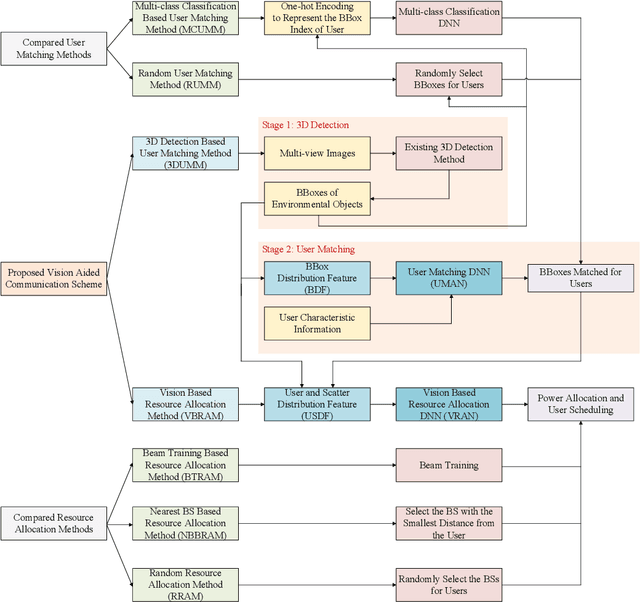
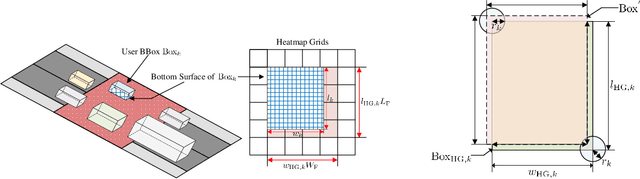
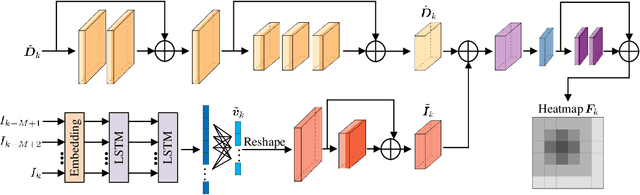
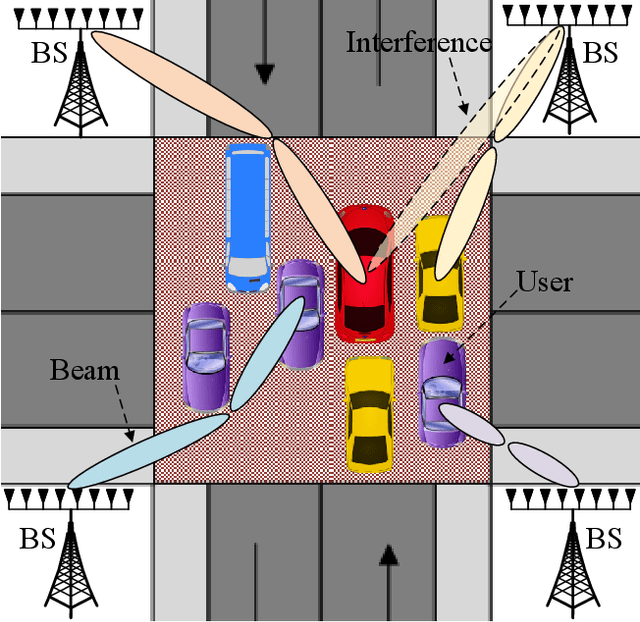
Visual perception is an effective way to obtain the spatial characteristics of wireless channels and to reduce the overhead for communications system. A critical problem for the visual assistance is that the communications system needs to match the radio signal with the visual information of the corresponding user, i.e., to identify the visual user that corresponds to the target radio signal from all the environmental objects. In this paper, we propose a user matching method for environment with a variable number of objects. Specifically, we apply 3D detection to extract all the environmental objects from the images taken by multiple cameras. Then, we design a deep neural network (DNN) to estimate the location distribution of users by the images and beam pairs at multiple moments, and thereby identify the users from all the extracted environmental objects. Moreover, we present a resource allocation method based on the taken images to reduce the time and spectrum overhead compared to traditional resource allocation methods. Simulation results show that the proposed user matching method outperforms the existing methods, and the proposed resource allocation method can achieve $92\%$ transmission rate of the traditional resource allocation method but with the time and spectrum overhead significantly reduced.