 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Horizon-Free Regret for Linear Markov Decision Processes
Mar 15, 2024
A recent line of works showed regret bounds in reinforcement learning (RL) can be (nearly) independent of planning horizon, a.k.a.~the horizon-free bounds. However, these regret bounds only apply to settings where a polynomial dependency on the size of transition model is allowed, such as tabular Markov Decision Process (MDP) and linear mixture MDP. We give the first horizon-free bound for the popular linear MDP setting where the size of the transition model can be exponentially large or even uncountable. In contrast to prior works which explicitly estimate the transition model and compute the inhomogeneous value functions at different time steps, we directly estimate the value functions and confidence sets. We obtain the horizon-free bound by: (1) maintaining multiple weighted least square estimators for the value functions; and (2) a structural lemma which shows the maximal total variation of the inhomogeneous value functions is bounded by a polynomial factor of the feature dimension.
Structured Evaluation of Synthetic Tabular Data
Mar 15, 2024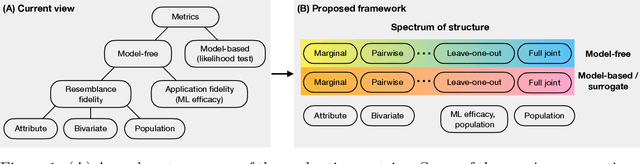
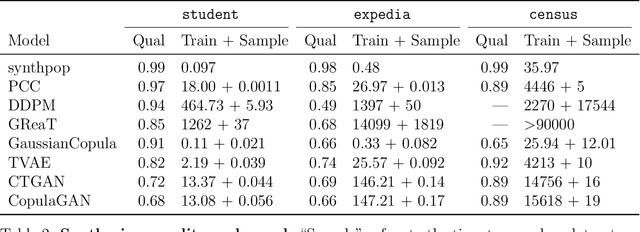
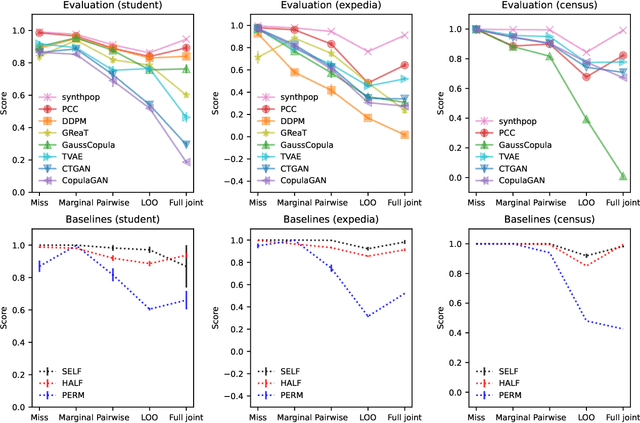
Tabular data is common yet typically incomplete, small in volume, and access-restricted due to privacy concerns. Synthetic data generation offers potential solutions. Many metrics exist for evaluating the quality of synthetic tabular data; however, we lack an objective, coherent interpretation of the many metrics. To address this issue, we propose an evaluation framework with a single, mathematical objective that posits that the synthetic data should be drawn from the same distribution as the observed data. Through various structural decomposition of the objective, this framework allows us to reason for the first time the completeness of any set of metrics, as well as unifies existing metrics, including those that stem from fidelity considerations, downstream application, and model-based approaches. Moreover, the framework motivates model-free baselines and a new spectrum of metrics. We evaluate structurally informed synthesizers and synthesizers powered by deep learning. Using our structured framework, we show that synthetic data generators that explicitly represent tabular structure outperform other methods, especially on smaller datasets.
Dynamic Multi-Network Mining of Tensor Time Series
Feb 22, 2024Subsequence clustering of time series is an essential task in data mining, and interpreting the resulting clusters is also crucial since we generally do not have prior knowledge of the data. Thus, given a large collection of tensor time series consisting of multiple modes, including timestamps, how can we achieve subsequence clustering for tensor time series and provide interpretable insights? In this paper, we propose a new method, Dynamic Multi-network Mining (DMM), that converts a tensor time series into a set of segment groups of various lengths (i.e., clusters) characterized by a dependency network constrained with l1-norm. Our method has the following properties. (a) Interpretable: it characterizes the cluster with multiple networks, each of which is a sparse dependency network of a corresponding non-temporal mode, and thus provides visible and interpretable insights into the key relationships. (b) Accurate: it discovers the clusters with distinct networks from tensor time series according to the minimum description length (MDL). (c) Scalable: it scales linearly in terms of the input data size when solving a non-convex problem to optimize the number of segments and clusters, and thus it is applicable to long-range and high-dimensional tensors. Extensive experiments with synthetic datasets confirm that our method outperforms the state-of-the-art methods in terms of clustering accuracy. We then use real datasets to demonstrate that DMM is useful for providing interpretable insights from tensor time series.
Fast Inference of Removal-Based Node Influence
Mar 16, 2024


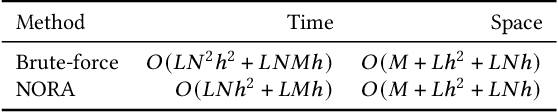
Graph neural networks (GNNs) are widely utilized to capture the information spreading patterns in graphs. While remarkable performance has been achieved, there is a new trending topic of evaluating node influence. We propose a new method of evaluating node influence, which measures the prediction change of a trained GNN model caused by removing a node. A real-world application is, "In the task of predicting Twitter accounts' polarity, had a particular account been removed, how would others' polarity change?". We use the GNN as a surrogate model whose prediction could simulate the change of nodes or edges caused by node removal. Our target is to obtain the influence score for every node, and a straightforward way is to alternately remove every node and apply the trained GNN on the modified graph to generate new predictions. It is reliable but time-consuming, so we need an efficient method. The related lines of work, such as graph adversarial attack and counterfactual explanation, cannot directly satisfy our needs, since their problem settings are different. We propose an efficient, intuitive, and effective method, NOde-Removal-based fAst GNN inference (NORA), which uses the gradient information to approximate the node-removal influence. It only costs one forward propagation and one backpropagation to approximate the influence score for all nodes. Extensive experiments on six datasets and six GNN models verify the effectiveness of NORA. Our code is available at https://github.com/weikai-li/NORA.git.
Surrogate Assisted Monte Carlo Tree Search in Combinatorial Optimization
Mar 14, 2024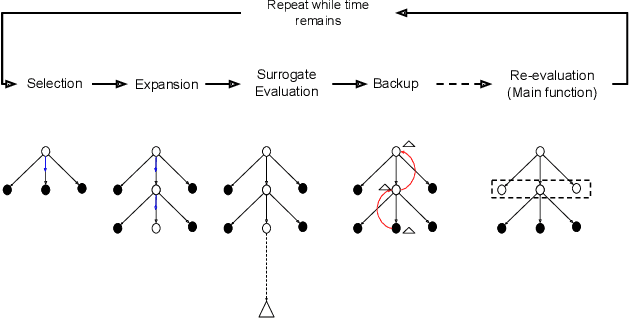
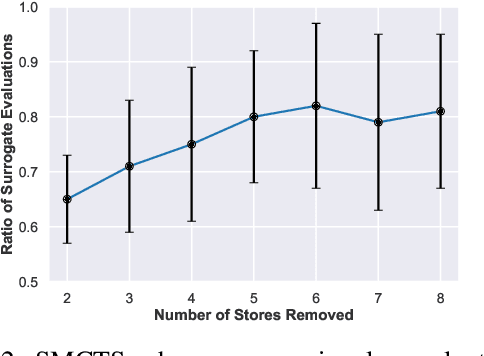
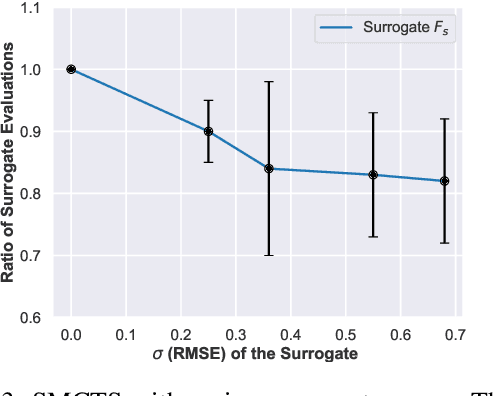
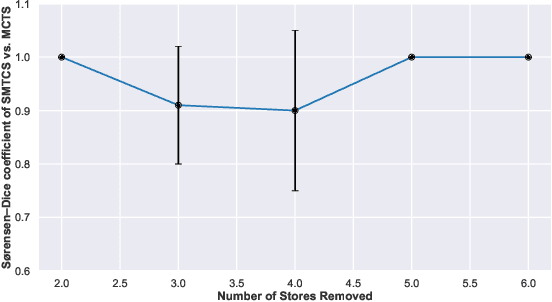
Industries frequently adjust their facilities network by opening new branches in promising areas and closing branches in areas where they expect low profits. In this paper, we examine a particular class of facility location problems. Our objective is to minimize the loss of sales resulting from the removal of several retail stores. However, estimating sales accurately is expensive and time-consuming. To overcome this challenge, we leverage Monte Carlo Tree Search (MCTS) assisted by a surrogate model that computes evaluations faster. Results suggest that MCTS supported by a fast surrogate function can generate solutions faster while maintaining a consistent solution compared to MCTS that does not benefit from the surrogate function.
DNGaussian: Optimizing Sparse-View 3D Gaussian Radiance Fields with Global-Local Depth Normalization
Mar 13, 2024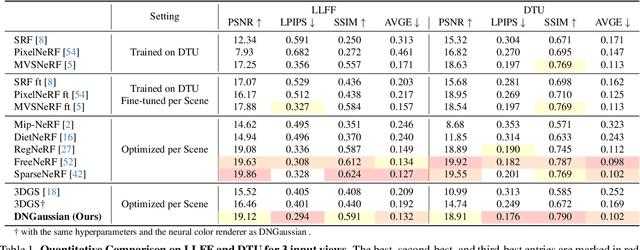
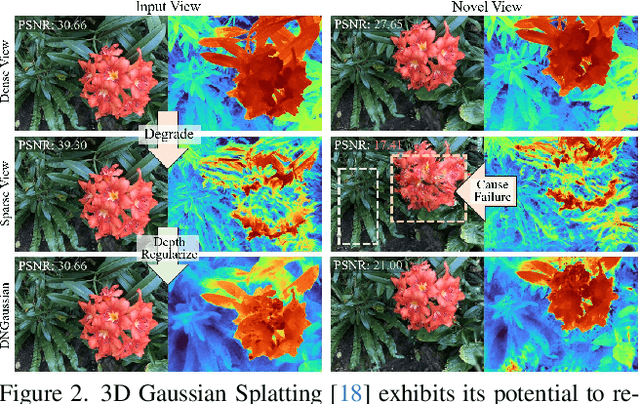
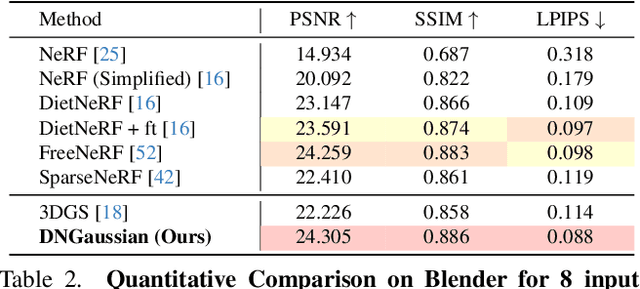
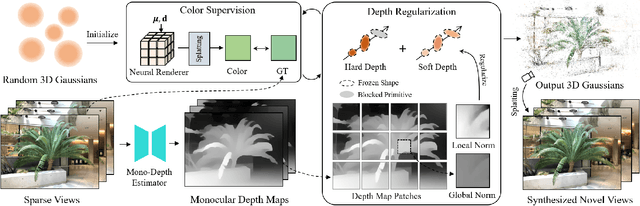
Radiance fields have demonstrated impressive performance in synthesizing novel views from sparse input views, yet prevailing methods suffer from high training costs and slow inference speed. This paper introduces DNGaussian, a depth-regularized framework based on 3D Gaussian radiance fields, offering real-time and high-quality few-shot novel view synthesis at low costs. Our motivation stems from the highly efficient representation and surprising quality of the recent 3D Gaussian Splatting, despite it will encounter a geometry degradation when input views decrease. In the Gaussian radiance fields, we find this degradation in scene geometry primarily lined to the positioning of Gaussian primitives and can be mitigated by depth constraint. Consequently, we propose a Hard and Soft Depth Regularization to restore accurate scene geometry under coarse monocular depth supervision while maintaining a fine-grained color appearance. To further refine detailed geometry reshaping, we introduce Global-Local Depth Normalization, enhancing the focus on small local depth changes. Extensive experiments on LLFF, DTU, and Blender datasets demonstrate that DNGaussian outperforms state-of-the-art methods, achieving comparable or better results with significantly reduced memory cost, a $25 \times$ reduction in training time, and over $3000 \times$ faster rendering speed.
Towards Embedding Dynamic Personas in Interactive Robots: Masquerading Animated Social Kinematics (MASK)
Mar 15, 2024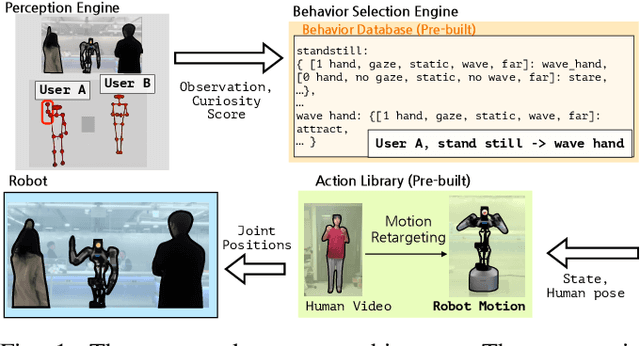
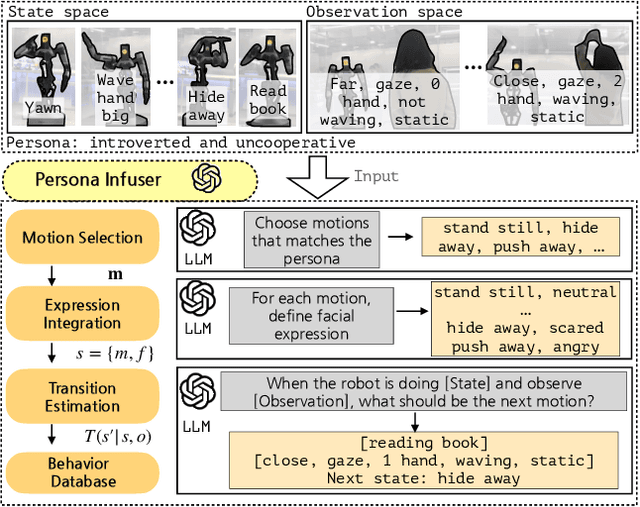
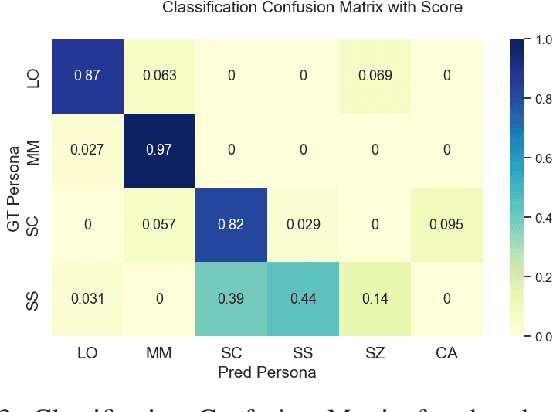

This paper presents the design and development of an innovative interactive robotic system to enhance audience engagement using character-like personas. Built upon the foundations of persona-driven dialog agents, this work extends the agent application to the physical realm, employing robots to provide a more immersive and interactive experience. The proposed system, named the Masquerading Animated Social Kinematics (MASK), leverages an anthropomorphic robot which interacts with guests using non-verbal interactions, including facial expressions and gestures. A behavior generation system based upon a finite-state machine structure effectively conditions robotic behavior to convey distinct personas. The MASK framework integrates a perception engine, a behavior selection engine, and a comprehensive action library to enable real-time, dynamic interactions with minimal human intervention in behavior design. Throughout the user subject studies, we examined whether the users could recognize the intended character in film-character-based persona conditions. We conclude by discussing the role of personas in interactive agents and the factors to consider for creating an engaging user experience.
Animate Your Motion: Turning Still Images into Dynamic Videos
Mar 15, 2024
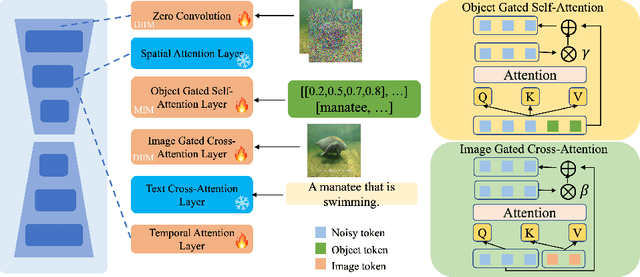
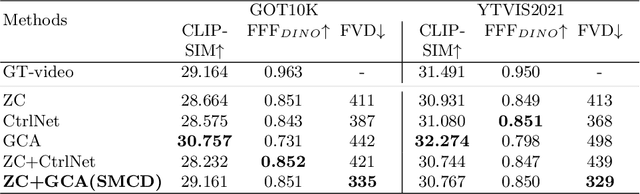
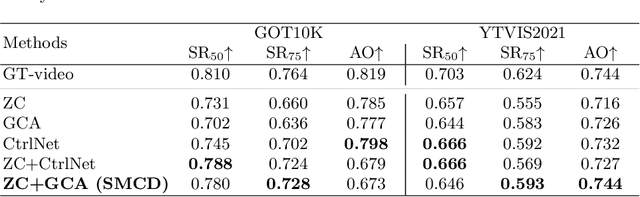
In recent years, diffusion models have made remarkable strides in text-to-video generation, sparking a quest for enhanced control over video outputs to more accurately reflect user intentions. Traditional efforts predominantly focus on employing either semantic cues, like images or depth maps, or motion-based conditions, like moving sketches or object bounding boxes. Semantic inputs offer a rich scene context but lack detailed motion specificity; conversely, motion inputs provide precise trajectory information but miss the broader semantic narrative. For the first time, we integrate both semantic and motion cues within a diffusion model for video generation, as demonstrated in Fig 1. To this end, we introduce the Scene and Motion Conditional Diffusion (SMCD), a novel methodology for managing multimodal inputs. It incorporates a recognized motion conditioning module and investigates various approaches to integrate scene conditions, promoting synergy between different modalities. For model training, we separate the conditions for the two modalities, introducing a two-stage training pipeline. Experimental results demonstrate that our design significantly enhances video quality, motion precision, and semantic coherence.
Learning on JPEG-LDPC Compressed Images: Classifying with Syndromes
Mar 15, 2024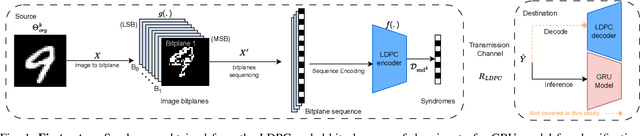
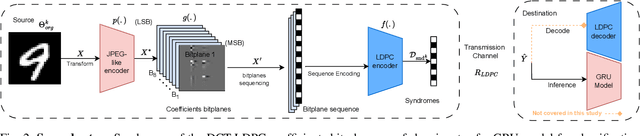
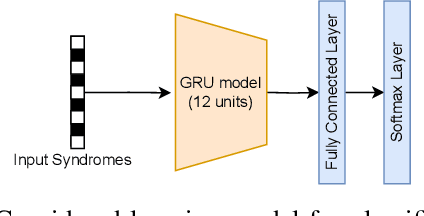

In goal-oriented communications, the objective of the receiver is often to apply a Deep-Learning model, rather than reconstructing the original data. In this context, direct learning over compressed data, without any prior decoding, holds promise for enhancing the time-efficient execution of inference models at the receiver. However, conventional entropic-coding methods like Huffman and Arithmetic break data structure, rendering them unsuitable for learning without decoding. In this paper, we propose an alternative approach in which entropic coding is realized with Low-Density Parity Check (LDPC) codes. We hypothesize that Deep Learning models can more effectively exploit the internal code structure of LDPC codes. At the receiver, we leverage a specific class of Recurrent Neural Networks (RNNs), specifically Gated Recurrent Unit (GRU), trained for image classification. Our numerical results indicate that classification based on LDPC-coded bit-planes surpasses Huffman and Arithmetic coding, while necessitating a significantly smaller learning model. This demonstrates the efficiency of classification directly from LDPC-coded data, eliminating the need for any form of decompression, even partial, prior to applying the learning model.
Stackelberg Meta-Learning Based Shared Control for Assistive Driving
Mar 15, 2024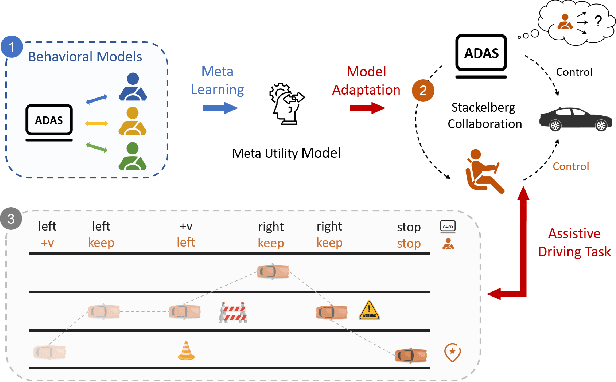
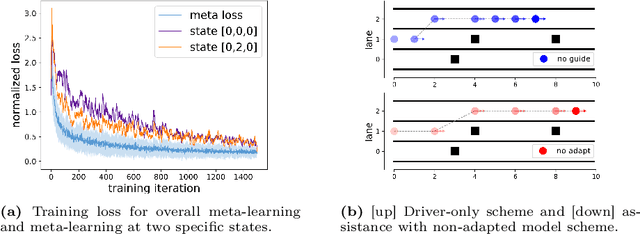
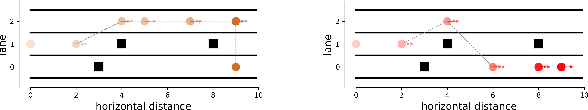
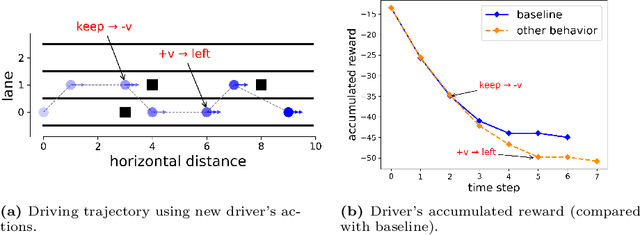
Shared control allows the human driver to collaborate with an assistive driving system while retaining the ability to make decisions and take control if necessary. However, human-vehicle teaming and planning are challenging due to environmental uncertainties, the human's bounded rationality, and the variability in human behaviors. An effective collaboration plan needs to learn and adapt to these uncertainties. To this end, we develop a Stackelberg meta-learning algorithm to create automated learning-based planning for shared control. The Stackelberg games are used to capture the leader-follower structure in the asymmetric interactions between the human driver and the assistive driving system. The meta-learning algorithm generates a common behavioral model, which is capable of fast adaptation using a small amount of driving data to assist optimal decision-making. We use a case study of an obstacle avoidance driving scenario to corroborate that the adapted human behavioral model can successfully assist the human driver in reaching the target destination. Besides, it saves driving time compared with a driver-only scheme and is also robust to drivers' bounded rationality and errors.