 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Learning for Equilibrium Pricing in Markets under Incomplete Information
Mar 28, 2023
The study of market equilibria is central to economic theory, particularly in efficiently allocating scarce resources. However, the computation of equilibrium prices at which the supply of goods matches their demand typically relies on having access to complete information on private attributes of agents, e.g., suppliers' cost functions, which are often unavailable in practice. Motivated by this practical consideration, we consider the problem of setting equilibrium prices in the incomplete information setting wherein a market operator seeks to satisfy the customer demand for a commodity by purchasing the required amount from competing suppliers with privately known cost functions unknown to the market operator. In this incomplete information setting, we consider the online learning problem of learning equilibrium prices over time while jointly optimizing three performance metrics -- unmet demand, cost regret, and payment regret -- pertinent in the context of equilibrium pricing over a horizon of $T$ periods. We first consider the setting when suppliers' cost functions are fixed and develop algorithms that achieve a regret of $O(\log \log T)$ when the customer demand is constant over time, or $O(\sqrt{T} \log \log T)$ when the demand is variable over time. Next, we consider the setting when the suppliers' cost functions can vary over time and illustrate that no online algorithm can achieve sublinear regret on all three metrics when the market operator has no information about how the cost functions change over time. Thus, we consider an augmented setting wherein the operator has access to hints/contexts that, without revealing the complete specification of the cost functions, reflect the variation in the cost functions over time and propose an algorithm with sublinear regret in this augmented setting.
Full-Duplex Wireless for 6G: Progress Brings New Opportunities and Challenges
Apr 24, 2023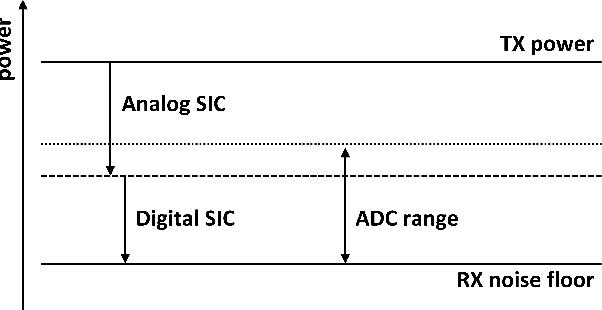
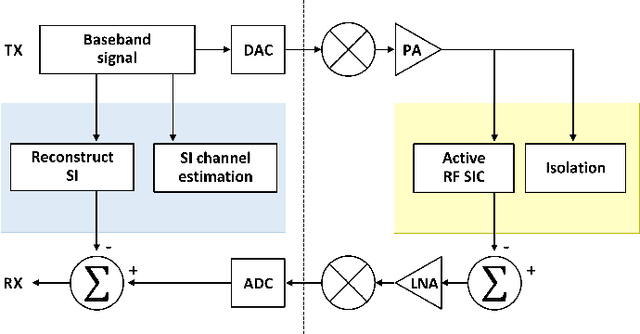
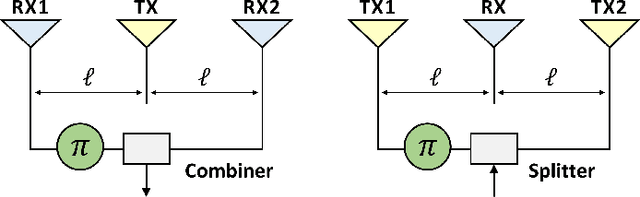
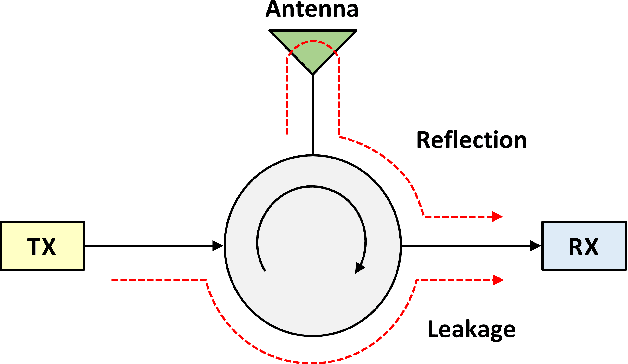
The use of in-band full-duplex (FD) enables nodes to simultaneously transmit and receive on the same frequency band, which challenges the traditional assumption in wireless network design. The full-duplex capability enhances spectral efficiency and decreases latency, which are two key drivers pushing the performance expectations of next-generation mobile networks. In less than ten years, in-band FD has advanced from being demonstrated in research labs to being implemented in standards, presenting new opportunities to utilize its foundational concepts. Some of the most significant opportunities include using FD to enable wireless networks to sense the physical environment, integrate sensing and communication applications, develop integrated access and backhaul solutions, and work with smart signal propagation environments powered by reconfigurable intelligent surfaces. However, these new opportunities also come with new challenges for large-scale commercial deployment of FD technology, such as managing self-interference, combating cross-link interference in multi-cell networks, and coexistence of dynamic time division duplex, subband FD and FD networks.
Policy Resilience to Environment Poisoning Attacks on Reinforcement Learning
Apr 24, 2023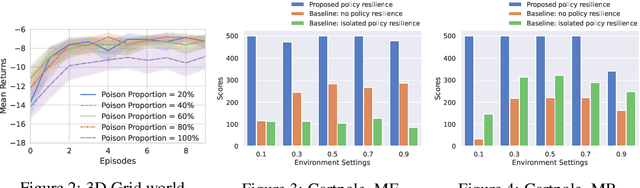
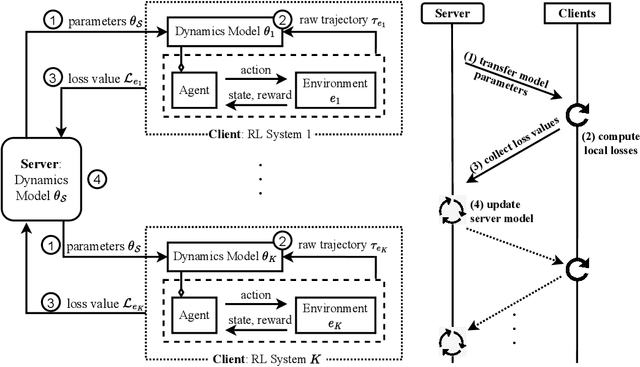
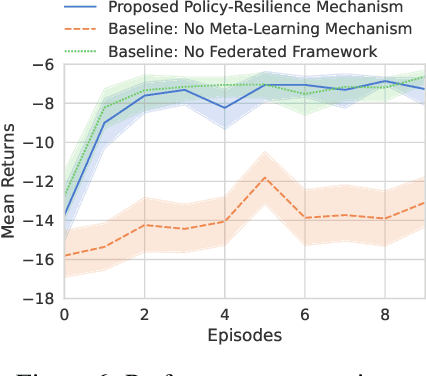
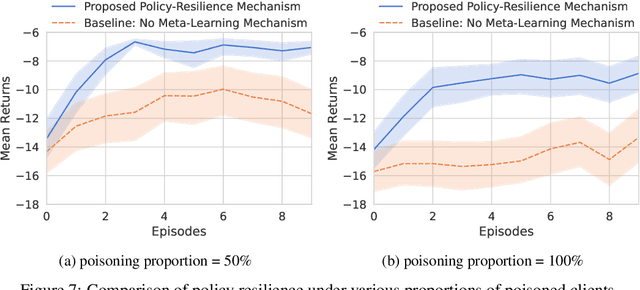
This paper investigates policy resilience to training-environment poisoning attacks on reinforcement learning (RL) policies, with the goal of recovering the deployment performance of a poisoned RL policy. Due to the fact that the policy resilience is an add-on concern to RL algorithms, it should be resource-efficient, time-conserving, and widely applicable without compromising the performance of RL algorithms. This paper proposes such a policy-resilience mechanism based on an idea of knowledge sharing. We summarize the policy resilience as three stages: preparation, diagnosis, recovery. Specifically, we design the mechanism as a federated architecture coupled with a meta-learning manner, pursuing an efficient extraction and sharing of the environment knowledge. With the shared knowledge, a poisoned agent can quickly identify the deployment condition and accordingly recover its policy performance. We empirically evaluate the resilience mechanism for both model-based and model-free RL algorithms, showing its effectiveness and efficiency in restoring the deployment performance of a poisoned policy.
Grad-PU: Arbitrary-Scale Point Cloud Upsampling via Gradient Descent with Learned Distance Functions
Apr 24, 2023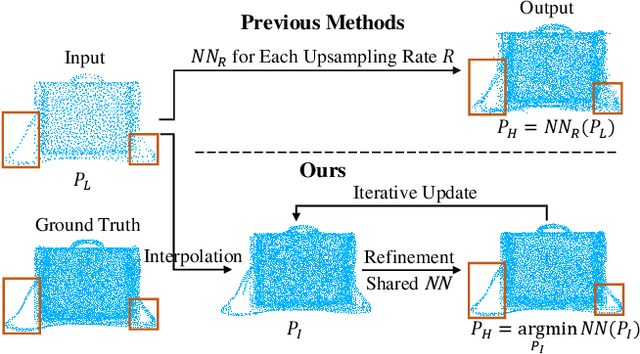
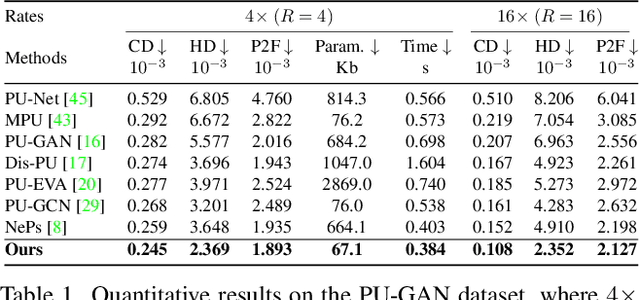
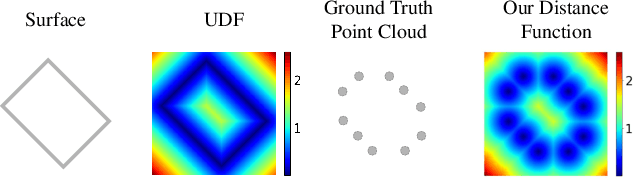
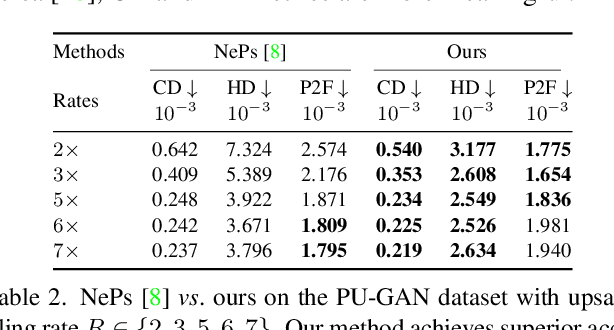
Most existing point cloud upsampling methods have roughly three steps: feature extraction, feature expansion and 3D coordinate prediction. However,they usually suffer from two critical issues: (1)fixed upsampling rate after one-time training, since the feature expansion unit is customized for each upsampling rate; (2)outliers or shrinkage artifact caused by the difficulty of precisely predicting 3D coordinates or residuals of upsampled points. To adress them, we propose a new framework for accurate point cloud upsampling that supports arbitrary upsampling rates. Our method first interpolates the low-res point cloud according to a given upsampling rate. And then refine the positions of the interpolated points with an iterative optimization process, guided by a trained model estimating the difference between the current point cloud and the high-res target. Extensive quantitative and qualitative results on benchmarks and downstream tasks demonstrate that our method achieves the state-of-the-art accuracy and efficiency.
The ACCompanion: Combining Reactivity, Robustness, and Musical Expressivity in an Automatic Piano Accompanist
Apr 24, 2023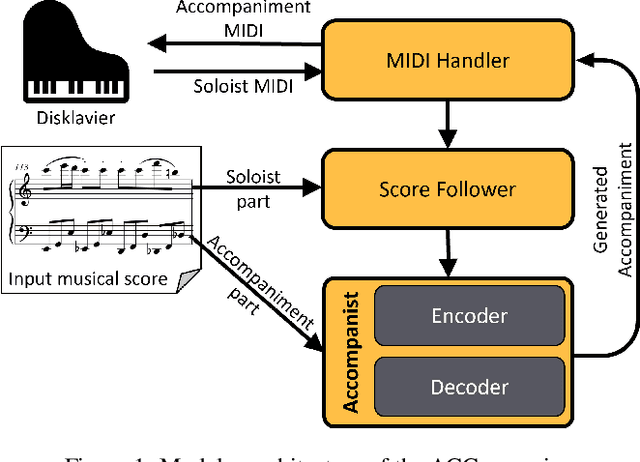

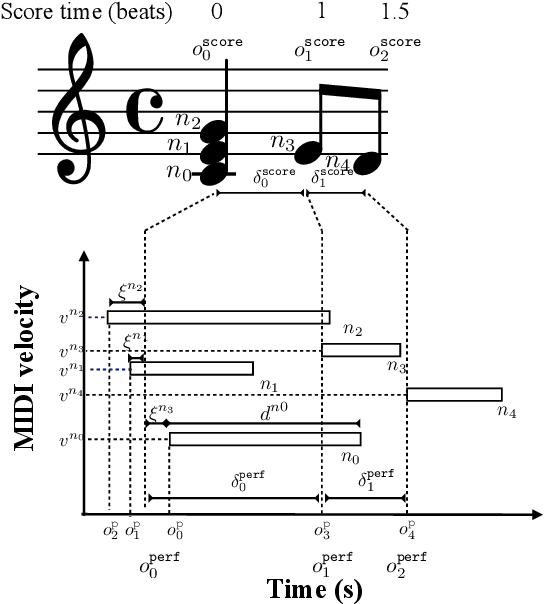
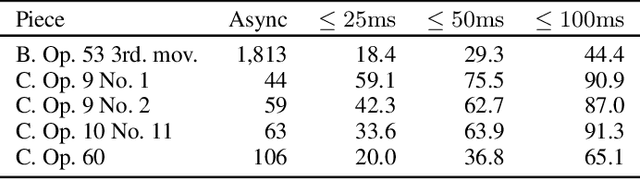
This paper introduces the ACCompanion, an expressive accompaniment system. Similarly to a musician who accompanies a soloist playing a given musical piece, our system can produce a human-like rendition of the accompaniment part that follows the soloist's choices in terms of tempo, dynamics, and articulation. The ACCompanion works in the symbolic domain, i.e., it needs a musical instrument capable of producing and playing MIDI data, with explicitly encoded onset, offset, and pitch for each played note. We describe the components that go into such a system, from real-time score following and prediction to expressive performance generation and online adaptation to the expressive choices of the human player. Based on our experience with repeated live demonstrations in front of various audiences, we offer an analysis of the challenges of combining these components into a system that is highly reactive and precise, while still a reliable musical partner, robust to possible performance errors and responsive to expressive variations.
A Survey on Few-Shot Class-Incremental Learning
Apr 17, 2023
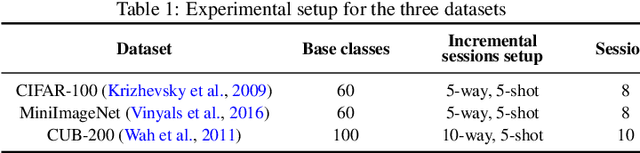
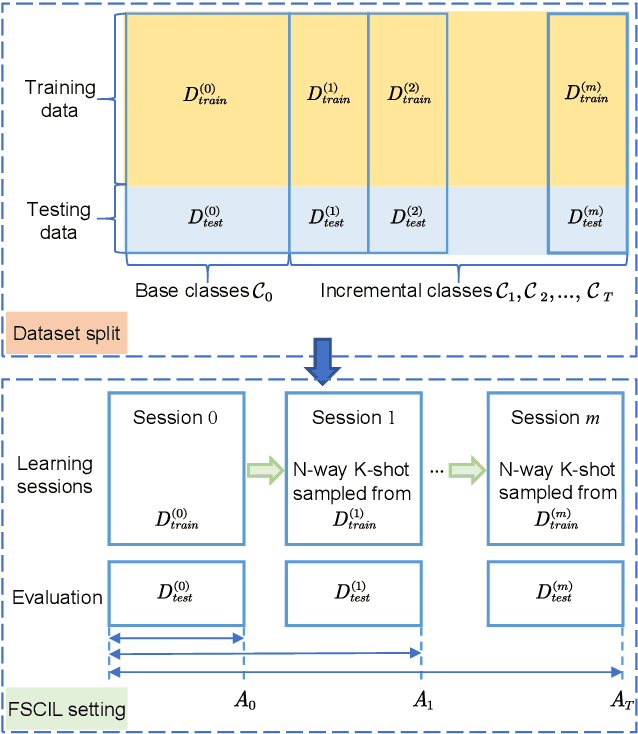
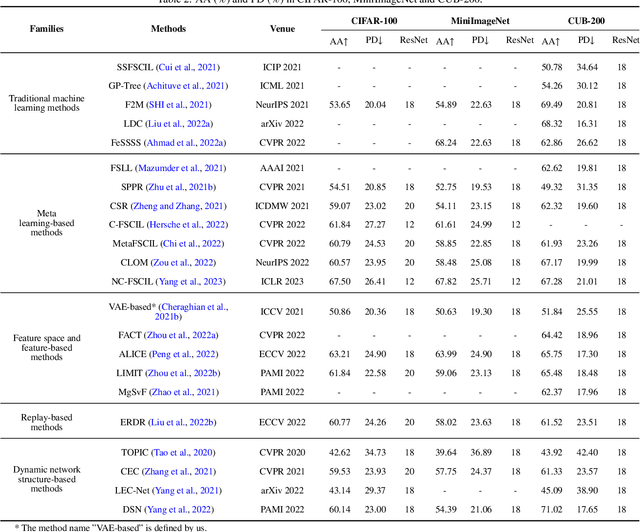
Large deep learning models are impressive, but they struggle when real-time data is not available. Few-shot class-incremental learning (FSCIL) poses a significant challenge for deep neural networks to learn new tasks from just a few labeled samples without forgetting the previously learned ones. This setup easily leads to catastrophic forgetting and overfitting problems, severely affecting model performance. Studying FSCIL helps overcome deep learning model limitations on data volume and acquisition time, while improving practicality and adaptability of machine learning models. This paper provides a comprehensive survey on FSCIL. Unlike previous surveys, we aim to synthesize few-shot learning and incremental learning, focusing on introducing FSCIL from two perspectives, while reviewing over 30 theoretical research studies and more than 20 applied research studies. From the theoretical perspective, we provide a novel categorization approach that divides the field into five subcategories, including traditional machine learning methods, meta-learning based methods, feature and feature space-based methods, replay-based methods, and dynamic network structure-based methods. We also evaluate the performance of recent theoretical research on benchmark datasets of FSCIL. From the application perspective, FSCIL has achieved impressive achievements in various fields of computer vision such as image classification, object detection, and image segmentation, as well as in natural language processing and graph. We summarize the important applications. Finally, we point out potential future research directions, including applications, problem setups, and theory development. Overall, this paper offers a comprehensive analysis of the latest advances in FSCIL from a methodological, performance, and application perspective.
InfluencerRank: Discovering Effective Influencers via Graph Convolutional Attentive Recurrent Neural Networks
Apr 12, 2023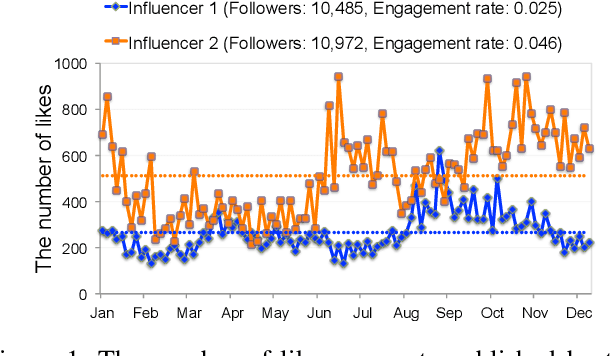

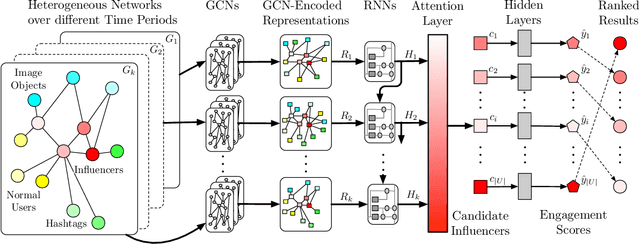
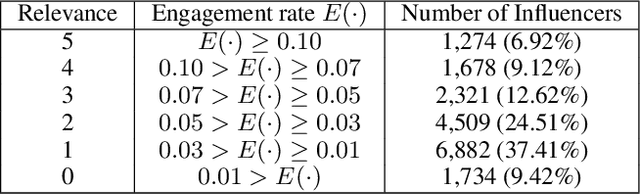
As influencers play considerable roles in social media marketing, companies increase the budget for influencer marketing. Hiring effective influencers is crucial in social influencer marketing, but it is challenging to find the right influencers among hundreds of millions of social media users. In this paper, we propose InfluencerRank that ranks influencers by their effectiveness based on their posting behaviors and social relations over time. To represent the posting behaviors and social relations, the graph convolutional neural networks are applied to model influencers with heterogeneous networks during different historical periods. By learning the network structure with the embedded node features, InfluencerRank can derive informative representations for influencers at each period. An attentive recurrent neural network finally distinguishes highly effective influencers from other influencers by capturing the knowledge of the dynamics of influencer representations over time. Extensive experiments have been conducted on an Instagram dataset that consists of 18,397 influencers with their 2,952,075 posts published within 12 months. The experimental results demonstrate that InfluencerRank outperforms existing baseline methods. An in-depth analysis further reveals that all of our proposed features and model components are beneficial to discover effective influencers.
Using Multiple RDF Knowledge Graphs for Enriching ChatGPT Responses
Apr 12, 2023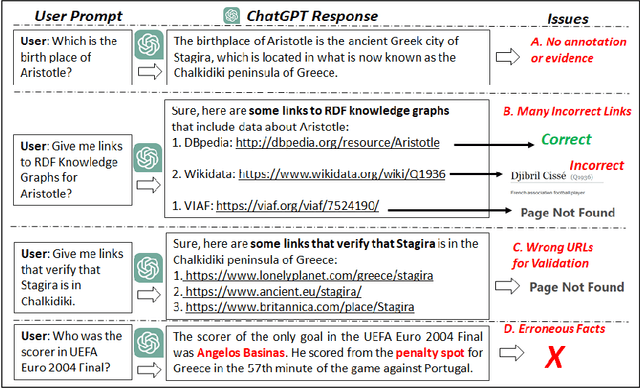
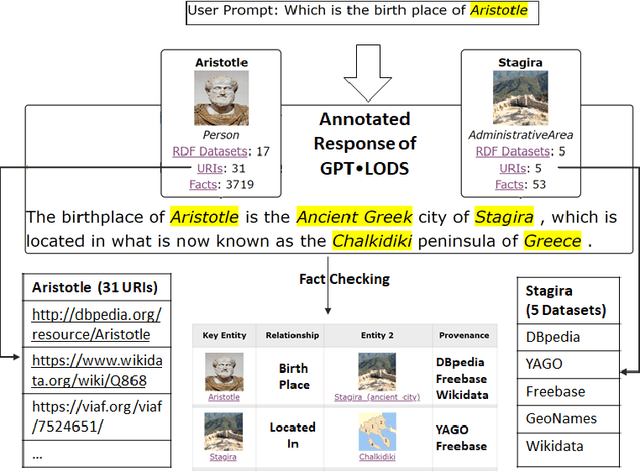
There is a recent trend for using the novel Artificial Intelligence ChatGPT chatbox, which provides detailed responses and articulate answers across many domains of knowledge. However, in many cases it returns plausible-sounding but incorrect or inaccurate responses, whereas it does not provide evidence. Therefore, any user has to further search for checking the accuracy of the answer or/and for finding more information about the entities of the response. At the same time there is a high proliferation of RDF Knowledge Graphs (KGs) over any real domain, that offer high quality structured data. For enabling the combination of ChatGPT and RDF KGs, we present a research prototype, called GPToLODS, which is able to enrich any ChatGPT response with more information from hundreds of RDF KGs. In particular, it identifies and annotates each entity of the response with statistics and hyperlinks to LODsyndesis KG (which contains integrated data from 400 RDF KGs and over 412 million entities). In this way, it is feasible to enrich the content of entities and to perform fact checking and validation for the facts of the response at real time.
A Comprehensive Review of YOLO: From YOLOv1 to YOLOv8 and Beyond
Apr 02, 2023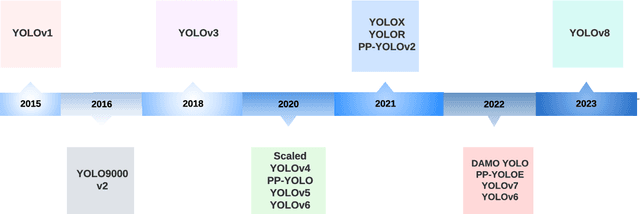
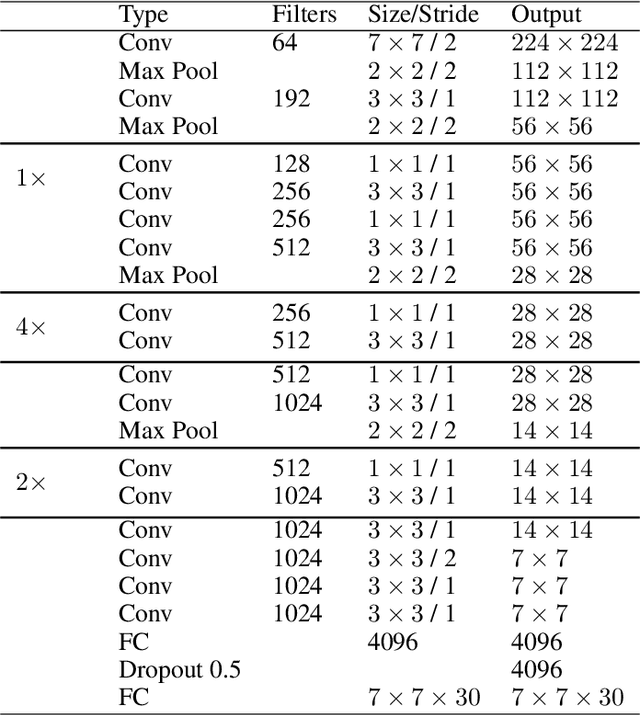
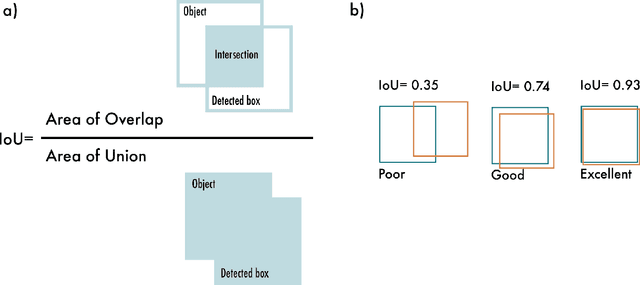
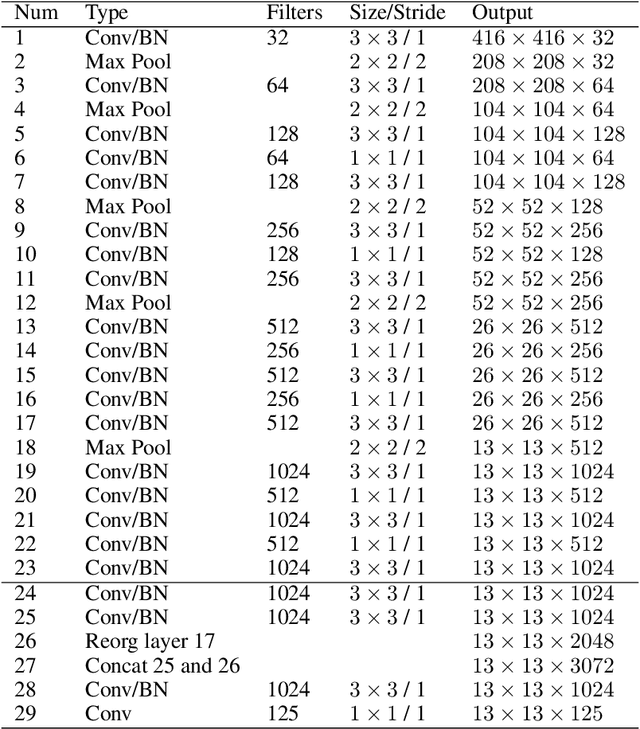
YOLO has become a central real-time object detection system for robotics, driverless cars, and video monitoring applications. We present a comprehensive analysis of YOLO's evolution, examining the innovations and contributions in each iteration from the original YOLO to YOLOv8. We start by describing the standard metrics and postprocessing; then, we discuss the major changes in network architecture and training tricks for each model. Finally, we summarize the essential lessons from YOLO's development and provide a perspective on its future, highlighting potential research directions to enhance real-time object detection systems.
SceneGenie: Scene Graph Guided Diffusion Models for Image Synthesis
Apr 28, 2023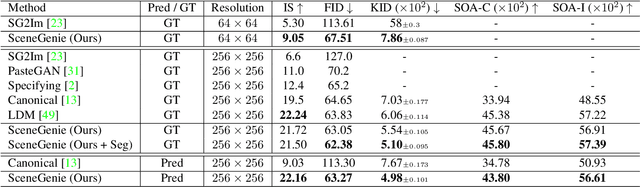
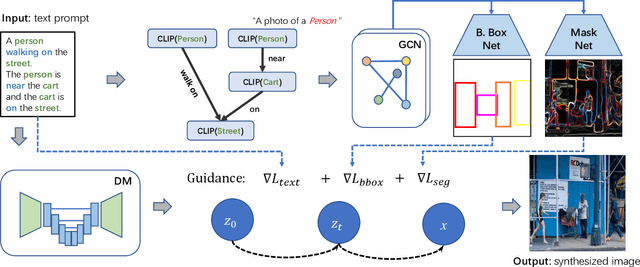
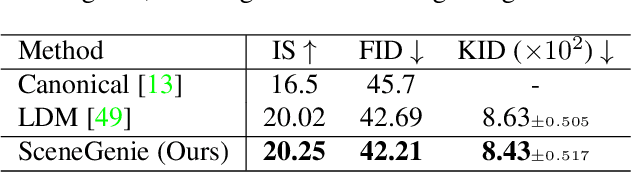
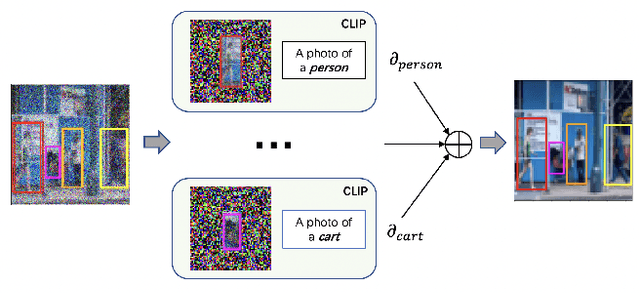
Text-conditioned image generation has made significant progress in recent years with generative adversarial networks and more recently, diffusion models. While diffusion models conditioned on text prompts have produced impressive and high-quality images, accurately representing complex text prompts such as the number of instances of a specific object remains challenging. To address this limitation, we propose a novel guidance approach for the sampling process in the diffusion model that leverages bounding box and segmentation map information at inference time without additional training data. Through a novel loss in the sampling process, our approach guides the model with semantic features from CLIP embeddings and enforces geometric constraints, leading to high-resolution images that accurately represent the scene. To obtain bounding box and segmentation map information, we structure the text prompt as a scene graph and enrich the nodes with CLIP embeddings. Our proposed model achieves state-of-the-art performance on two public benchmarks for image generation from scene graphs, surpassing both scene graph to image and text-based diffusion models in various metrics. Our results demonstrate the effectiveness of incorporating bounding box and segmentation map guidance in the diffusion model sampling process for more accurate text-to-image generation.