 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cascaded Logic Gates Based on High-Performance Ambipolar Dual-Gate WSe2 Thin Film Transistors
May 02, 2023
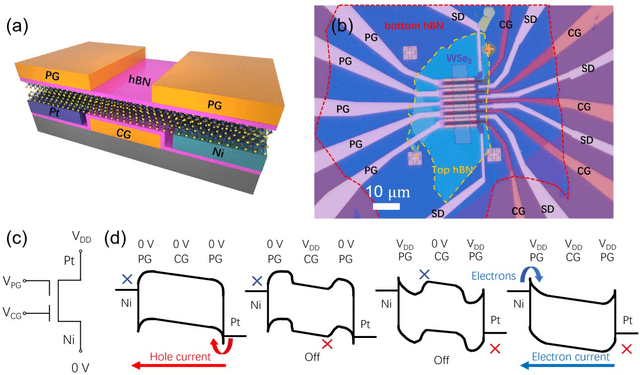
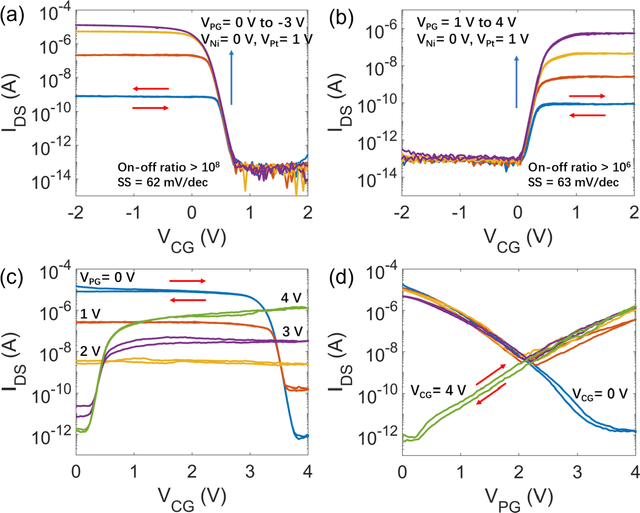
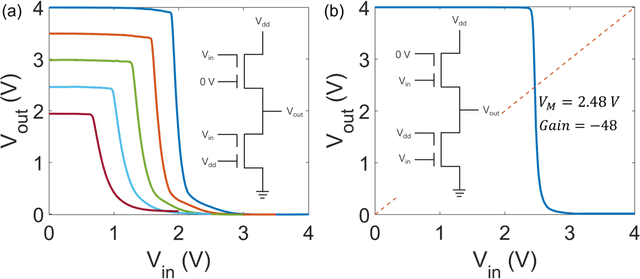
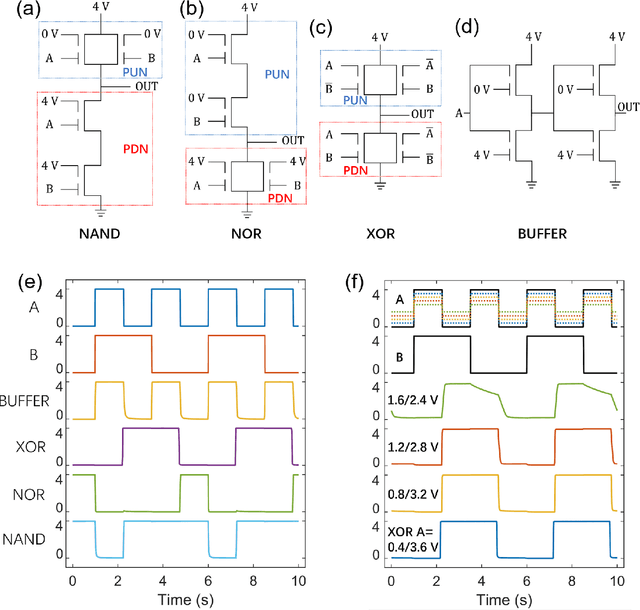
Ambipolar dual-gate transistors based on two-dimensional (2D) materials, such as graphene, carbon nanotubes, black phosphorus, and certain transition metal dichalcogenides (TMDs), enable reconfigurable logic circuits with suppressed off-state current. These circuits achieve the same logical output as CMOS with fewer transistors and offer greater flexibility in design. The primary challenge lies in the cascadability and power consumption of these logic gates with static CMOS-like connections. In this article, high-performance ambipolar dual-gate transistors based on tungsten diselenide (WSe2) are fabricated. A high on-off ratio of 10^8 and 10^6, a low off-state current of 100 to 300 fA, a negligible hysteresis, and an ideal subthreshold swing of 62 and 63 mV/dec are measured in the p- and n-type transport, respectively. For the first time, we demonstrate cascadable and cascaded logic gates using ambipolar TMD transistors with minimal static power consumption, including inverters, XOR, NAND, NOR, and buffers made by cascaded inverters. A thorough study of both the control gate and polarity gate behavior is conducted, which has previously been lacking. The noise margin of the logic gates is measured and analyzed. The large noise margin enables the implementation of VT-drop circuits, a type of logic with reduced transistor number and simplified circuit design. Finally, the speed performance of the VT-drop and other circuits built by dual-gate devices are qualitatively analyzed. This work lays the foundation for future developments in the field of ambipolar dual-gate TMD transistors, showing their potential for low-power, high-speed and more flexible logic circuits.
Structure Aware Incremental Learning with Personalized Imitation Weights for Recommender Systems
May 02, 2023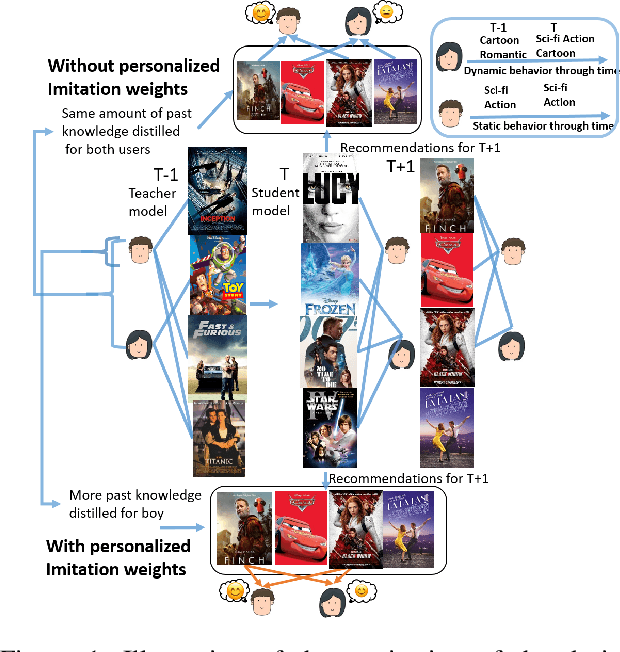
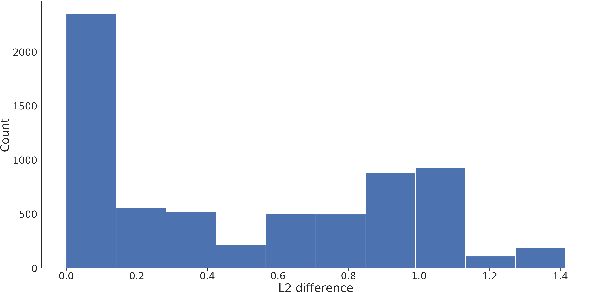
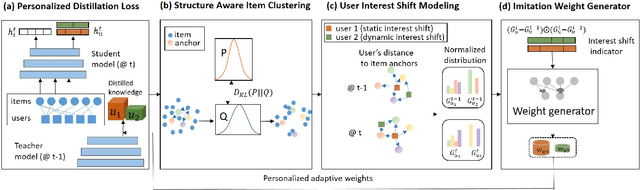
Recommender systems now consume large-scale data and play a significant role in improving user experience. Graph Neural Networks (GNNs) have emerged as one of the most effective recommender system models because they model the rich relational information. The ever-growing volume of data can make training GNNs prohibitively expensive. To address this, previous attempts propose to train the GNN models incrementally as new data blocks arrive. Feature and structure knowledge distillation techniques have been explored to allow the GNN model to train in a fast incremental fashion while alleviating the catastrophic forgetting problem. However, preserving the same amount of the historical information for all users is sub-optimal since it fails to take into account the dynamics of each user's change of preferences. For the users whose interests shift substantially, retaining too much of the old knowledge can overly constrain the model, preventing it from quickly adapting to the users' novel interests. In contrast, for users who have static preferences, model performance can benefit greatly from preserving as much of the user's long-term preferences as possible. In this work, we propose a novel training strategy that adaptively learns personalized imitation weights for each user to balance the contribution from the recent data and the amount of knowledge to be distilled from previous time periods. We demonstrate the effectiveness of learning imitation weights via a comparison on five diverse datasets for three state-of-art structure distillation based recommender systems. The performance shows consistent improvement over competitive incremental learning techninques.
Outlier galaxy images in the Dark Energy Survey and their identification with unsupervised machine learning
May 02, 2023
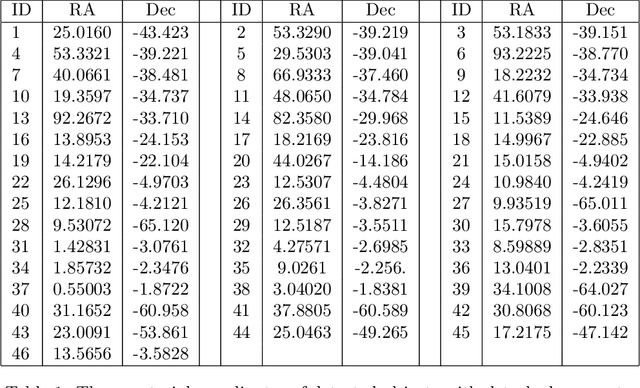

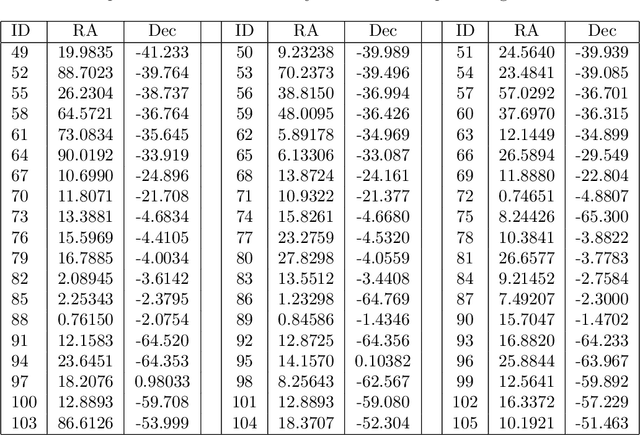
The Dark Energy Survey is able to collect image data of an extremely large number of extragalactic objects, and it can be reasonably assumed that many unusual objects of high scientific interest are hidden inside these data. Due to the extreme size of DES data, identifying these objects among many millions of other celestial objects is a challenging task. The problem of outlier detection is further magnified by the presence of noisy or saturated images. When the number of tested objects is extremely high, even a small rate of noise or false positives leads to a very large number of false detections, making an automatic system impractical. This study applies an automatic method for automatic detection of outlier objects in the first data release of the Dark Energy Survey. By using machine learning-based outlier detection, the algorithm is able to identify objects that are visually different from the majority of the other objects in the database. An important feature of the algorithm is that it allows to control the false-positive rate, and therefore can be used for practical outlier detection. The algorithm does not provide perfect accuracy in the detection of outlier objects, but it reduces the data substantially to allow practical outlier detection. For instance, the selection of the top 250 objects after applying the algorithm to more than $2\cdot10^6$ DES images provides a collection of uncommon galaxies. Such collection would have been extremely time-consuming to compile by using manual inspection of the data.
Orthogonal-Time-Frequency-Space Signal Design for Integrated Data and Energy Transfer: Benefits from Doppler Offsets
Feb 03, 2023
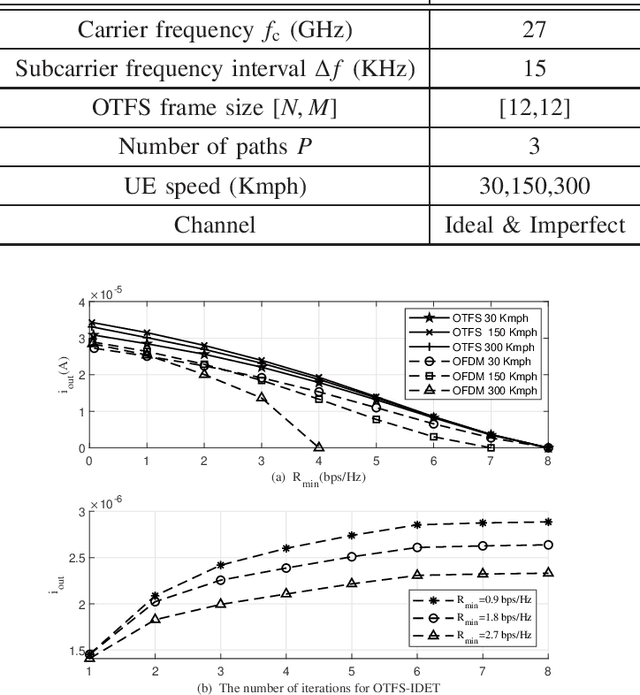
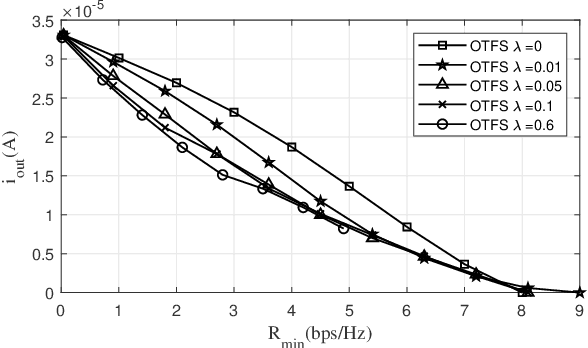
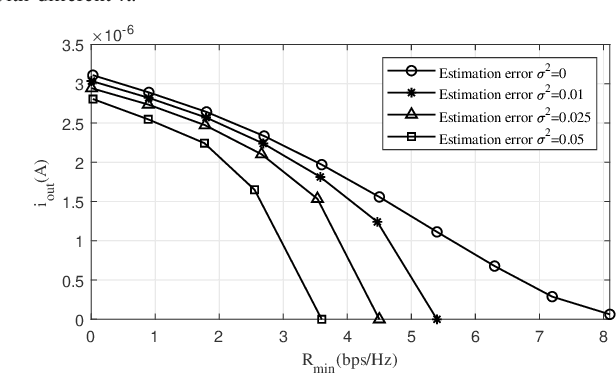
Integrated data and energy transfer (IDET) is an advanced technology for enabling energy sustainability for massively deployed low-power electronic consumption components. However, the existing work of IDET using the orthogonal-frequency-division-multiplexing (OFDM) waveforms is designed for static scenarios, which would be severely affected by the destructive Doppler offset in high-mobility scenarios. Therefore, we proposed an IDET system based on orthogonal-time-frequency-space (OTFS) waveforms with the imperfect channel assumption, which is capable of counteracting the Doppler offset in high-mobility scenarios. At the transmitter, the OTFS-IDET system superimposes the random data signals and deterministic energy signals in the delay-Doppler (DD) domain with optimally designed amplitudes. The receiver optimally splits the received signal in the power domain for achieving the best IDET performance. After formulating a non-convex optimisation problem, it is transformed into a geometric programming (GP) problem through inequality relaxations to obtain the optimal solution. The simulation demonstrates that a higher amount of energy can be harvested when employing our proposed OTFS-IDET waveforms than the conventional OFDM-IDET ones in high mobility scenarios.
Quantum Persistent Homology for Time Series
Nov 08, 2022
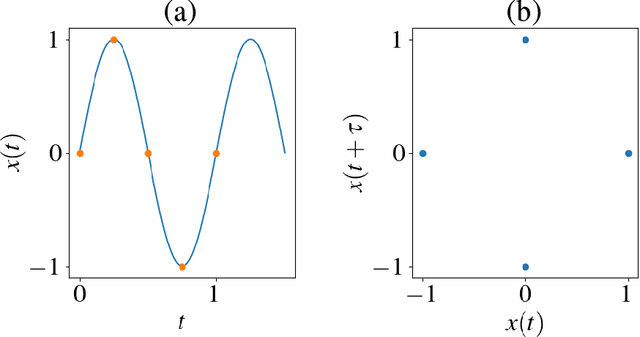
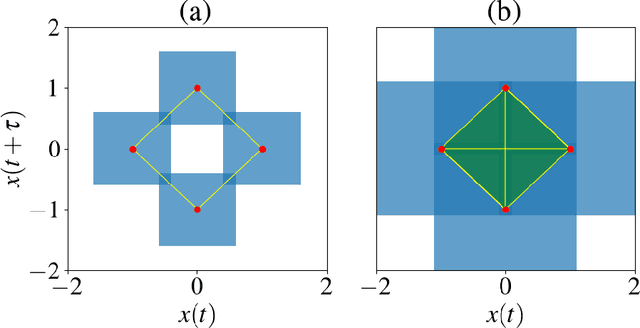
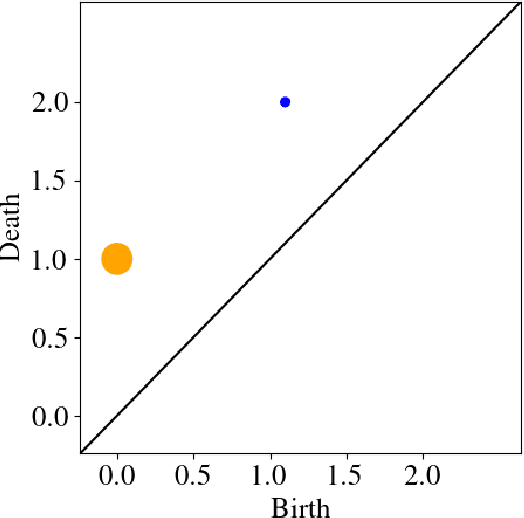
Persistent homology, a powerful mathematical tool for data analysis, summarizes the shape of data through tracking topological features across changes in different scales. Classical algorithms for persistent homology are often constrained by running times and memory requirements that grow exponentially on the number of data points. To surpass this problem, two quantum algorithms of persistent homology have been developed based on two different approaches. However, both of these quantum algorithms consider a data set in the form of a point cloud, which can be restrictive considering that many data sets come in the form of time series. In this paper, we alleviate this issue by establishing a quantum Takens's delay embedding algorithm, which turns a time series into a point cloud by considering a pertinent embedding into a higher dimensional space. Having this quantum transformation of time series to point clouds, then one may use a quantum persistent homology algorithm to extract the topological features from the point cloud associated with the original times series.
AffectMachine-Classical: A novel system for generating affective classical music
Apr 11, 2023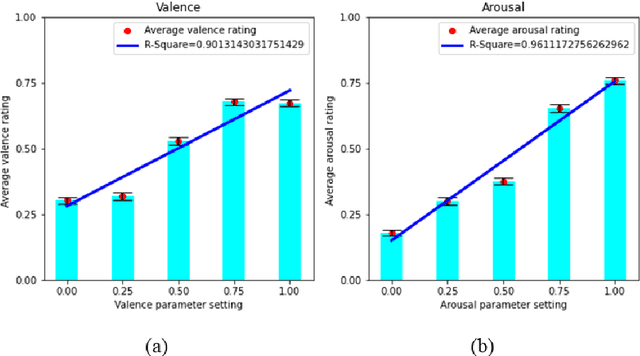
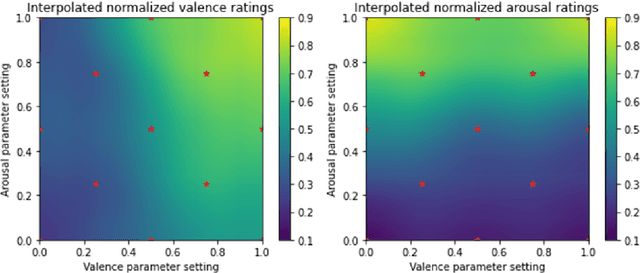
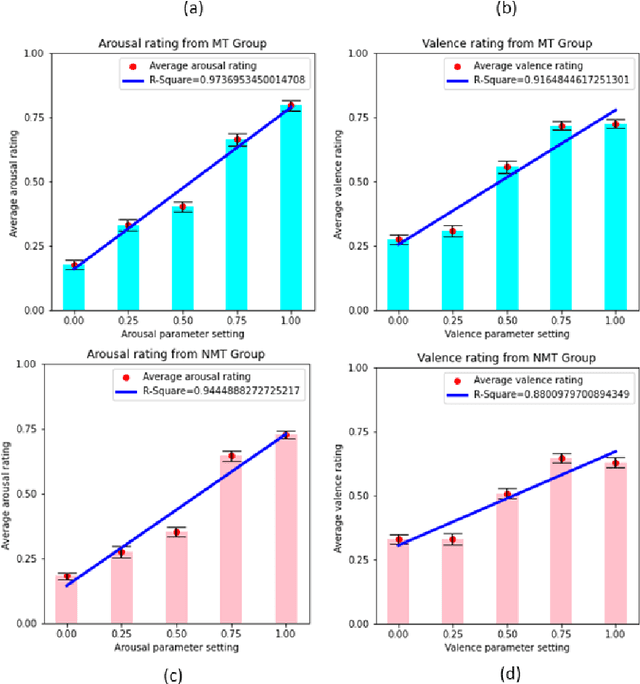
This work introduces a new music generation system, called AffectMachine-Classical, that is capable of generating affective Classic music in real-time. AffectMachine was designed to be incorporated into biofeedback systems (such as brain-computer-interfaces) to help users become aware of, and ultimately mediate, their own dynamic affective states. That is, this system was developed for music-based MedTech to support real-time emotion self-regulation in users. We provide an overview of the rule-based, probabilistic system architecture, describing the main aspects of the system and how they are novel. We then present the results of a listener study that was conducted to validate the ability of the system to reliably convey target emotions to listeners. The findings indicate that AffectMachine-Classical is very effective in communicating various levels of Arousal ($R^2 = .96$) to listeners, and is also quite convincing in terms of Valence (R^2 = .90). Future work will embed AffectMachine-Classical into biofeedback systems, to leverage the efficacy of the affective music for emotional well-being in listeners.
Transfer Learning Across Heterogeneous Features For Efficient Tensor Program Generation
Apr 11, 2023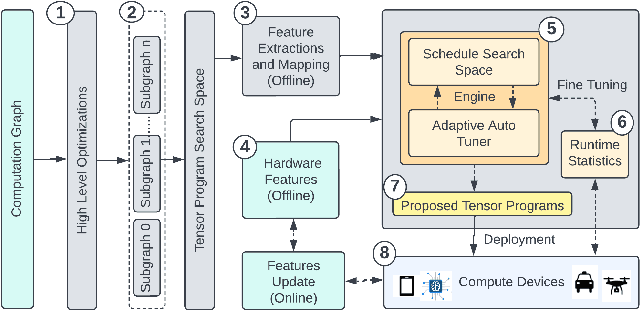
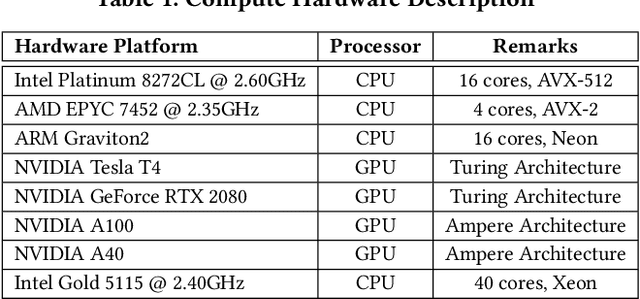
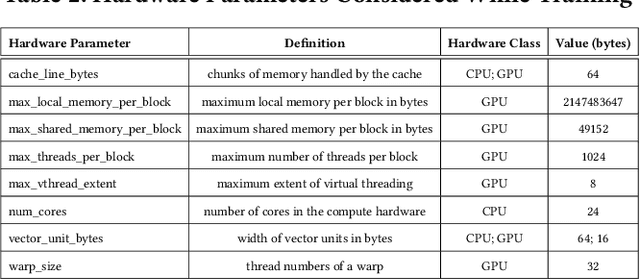
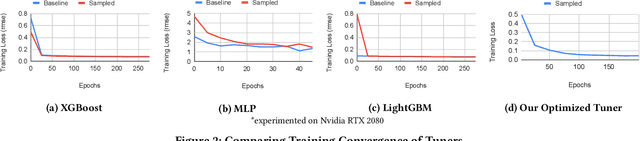
Tuning tensor program generation involves searching for various possible program transformation combinations for a given program on target hardware to optimize the tensor program execution. It is already a complex process because of the massive search space and exponential combinations of transformations make auto-tuning tensor program generation more challenging, especially when we have a heterogeneous target. In this research, we attempt to address these problems by learning the joint neural network and hardware features and transferring them to the new target hardware. We extensively study the existing state-of-the-art dataset, TenSet, perform comparative analysis on the test split strategies and propose methodologies to prune the dataset. We adopt an attention-inspired approach for tuning the tensor programs enabling them to embed neural network and hardware-specific features. Our approach could prune the dataset up to 45\% of the baseline without compromising the Pairwise Comparison Accuracy (PCA). Further, the proposed methodology can achieve on-par or improved mean inference time with 25%-40% of the baseline tuning time across different networks and target hardware.
TorchBench: Benchmarking PyTorch with High API Surface Coverage
Apr 27, 2023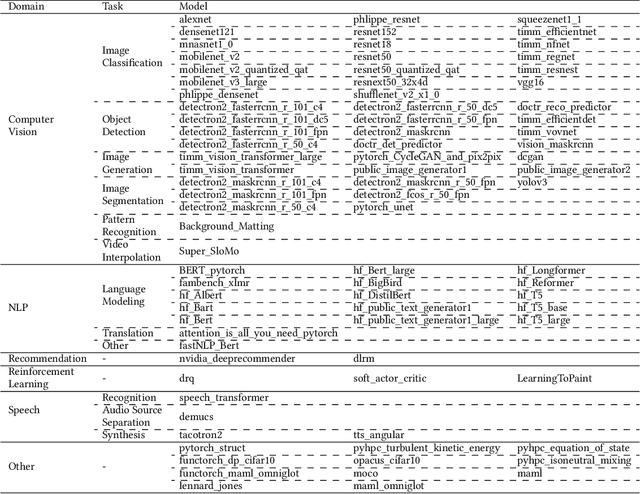
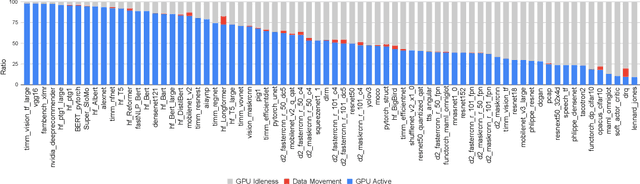
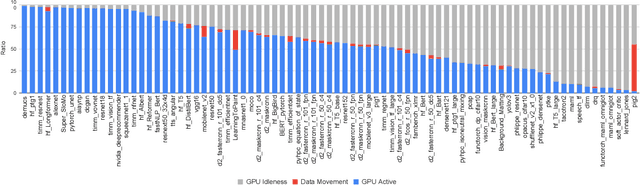
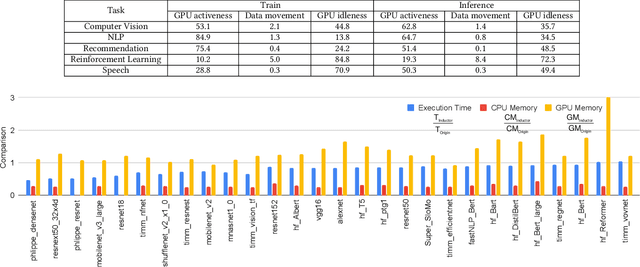
Deep learning (DL) has been a revolutionary technique in various domains. To facilitate the model development and deployment, many deep learning frameworks are proposed, among which PyTorch is one of the most popular solutions. The performance of ecosystem around PyTorch is critically important, which saves the costs of training models and reduces the response time of model inferences. In this paper, we propose TorchBench, a novel benchmark suite to study the performance of PyTorch software stack. Unlike existing benchmark suites, TorchBench encloses many representative models, covering a large PyTorch API surface. TorchBench is able to comprehensively characterize the performance of the PyTorch software stack, guiding the performance optimization across models, PyTorch framework, and GPU libraries. We show two practical use cases of TorchBench. (1) We profile TorchBench to identify GPU performance inefficiencies in PyTorch. We are able to optimize many performance bugs and upstream patches to the official PyTorch repository. (2) We integrate TorchBench into PyTorch continuous integration system. We are able to identify performance regression in multiple daily code checkins to prevent PyTorch repository from introducing performance bugs. TorchBench is open source and keeps evolving.
Energy-based Models as Zero-Shot Planners for Compositional Scene Rearrangement
Apr 27, 2023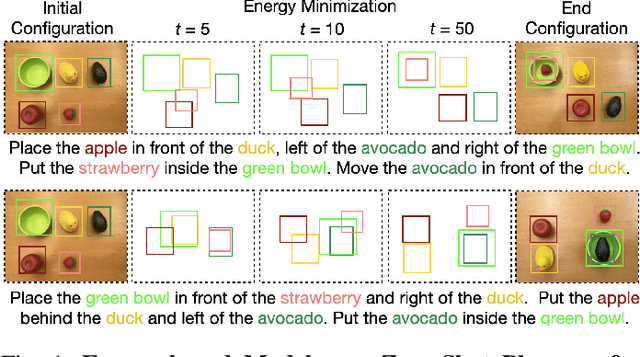
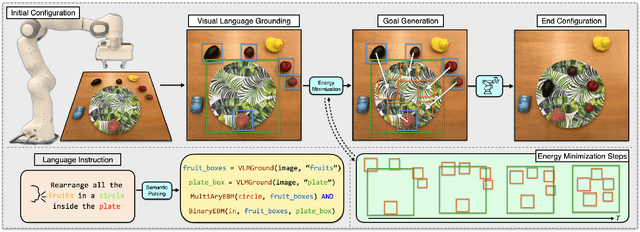


Language is compositional; an instruction can express multiple relation constraints to hold among objects in a scene that a robot is tasked to rearrange. Our focus in this work is an instructable scene rearranging framework that generalizes to longer instructions and to spatial concept compositions never seen at training time. We propose to represent language-instructed spatial concepts with energy functions over relative object arrangements. A language parser maps instructions to corresponding energy functions and an open-vocabulary visual-language model grounds their arguments to relevant objects in the scene. We generate goal scene configurations by gradient descent on the sum of energy functions, one per language predicate in the instruction. Local vision-based policies then relocate objects to the inferred goal locations. We test our model on established instruction-guided manipulation benchmarks, as well as benchmarks of compositional instructions we introduce. We show our model can execute highly compositional instructions zero-shot in simulation and in the real world. It outperforms language-to-action reactive policies and Large Language Model planners by a large margin, especially for long instructions that involve compositions of multiple spatial concepts.
Precise Few-shot Fat-free Thigh Muscle Segmentation in T1-weighted MRI
Apr 27, 2023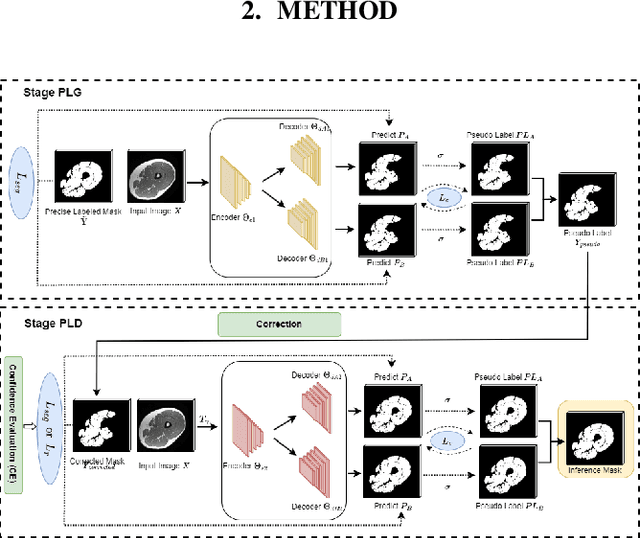
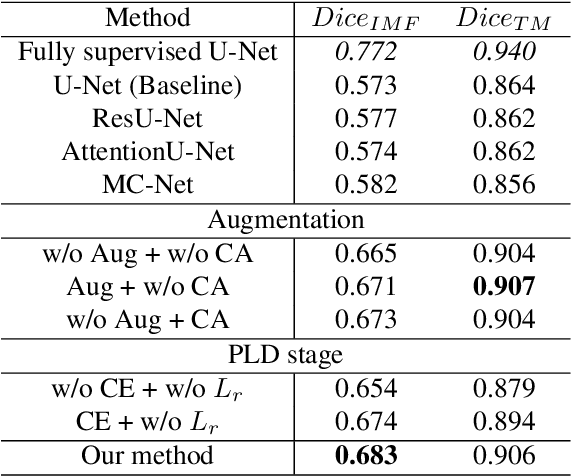
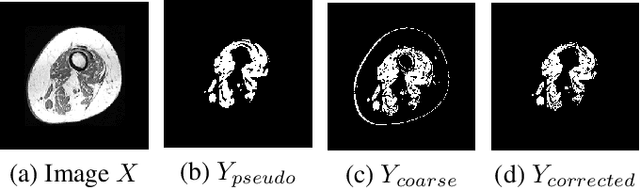

Precise thigh muscle volumes are crucial to monitor the motor functionality of patients with diseases that may result in various degrees of thigh muscle loss. T1-weighted MRI is the default surrogate to obtain thigh muscle masks due to its contrast between muscle and fat signals. Deep learning approaches have recently been widely used to obtain these masks through segmentation. However, due to the insufficient amount of precise annotations, thigh muscle masks generated by deep learning approaches tend to misclassify intra-muscular fat (IMF) as muscle impacting the analysis of muscle volumetrics. As IMF is infiltrated inside the muscle, human annotations require expertise and time. Thus, precise muscle masks where IMF is excluded are limited in practice. To alleviate this, we propose a few-shot segmentation framework to generate thigh muscle masks excluding IMF. In our framework, we design a novel pseudo-label correction and evaluation scheme, together with a new noise robust loss for exploiting high certainty areas. The proposed framework only takes $1\%$ of the fine-annotated training dataset, and achieves comparable performance with fully supervised methods according to the experimental results.