 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unadjusted Hamiltonian MCMC with Stratified Monte Carlo Time Integration
Nov 20, 2022
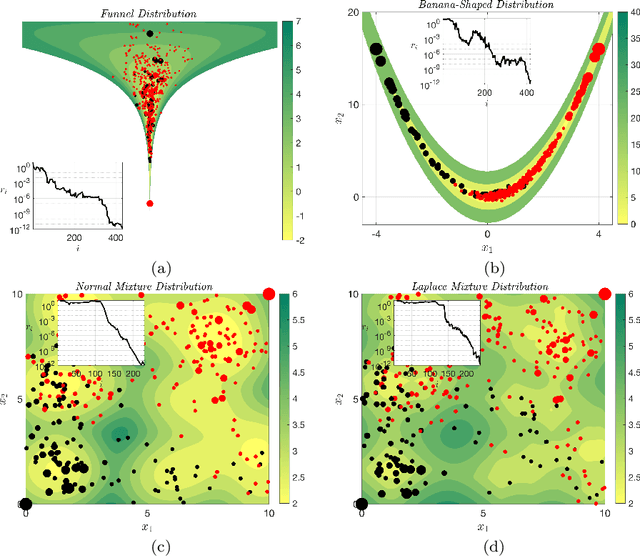
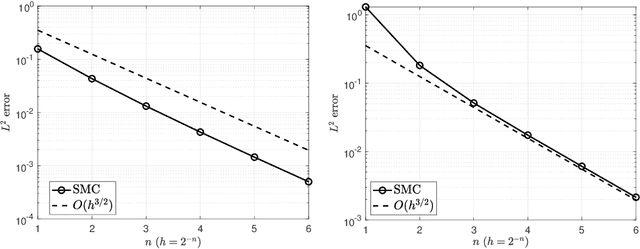
A novel unadjusted Hamiltonian Monte Carlo (uHMC) algorithm is suggested that uses a stratified Monte Carlo (SMC) time integrator for the underlying Hamiltonian dynamics in place of the usual Verlet time integrator. For target distributions of the form $\mu(dx) \propto e^{-U(x)} dx$ where $U: \mathbb{R}^d \to \mathbb{R}_{\ge 0}$ is both $K$-strongly convex and $L$-gradient Lipschitz, and initial distributions $\nu$ with finite second moment, coupling proofs reveal that an $\varepsilon$-accurate approximation of the target distribution $\mu$ in $L^2$-Wasserstein distance $\boldsymbol{\mathcal{W}}^2$ can be achieved by the uHMC algorithm with SMC time integration using $O\left((d/K)^{1/3} (L/K)^{5/3} \varepsilon^{-2/3} \log( \boldsymbol{\mathcal{W}}^2(\mu, \nu) / \varepsilon)^+\right)$ gradient evaluations; whereas without any additional assumptions the corresponding complexity of the uHMC algorithm with Verlet time integration is in general $O\left((d/K)^{1/2} (L/K)^2 \varepsilon^{-1} \log( \boldsymbol{\mathcal{W}}^2(\mu, \nu) / \varepsilon)^+ \right)$. The SMC time integrator involves a minor modification to Verlet, and hence, is easy to implement.
IMP: Iterative Matching and Pose Estimation with Adaptive Pooling
Apr 28, 2023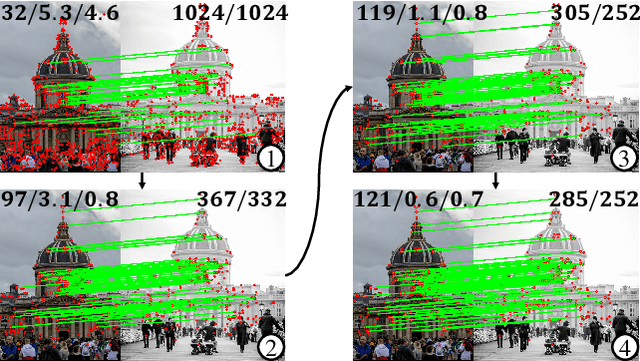
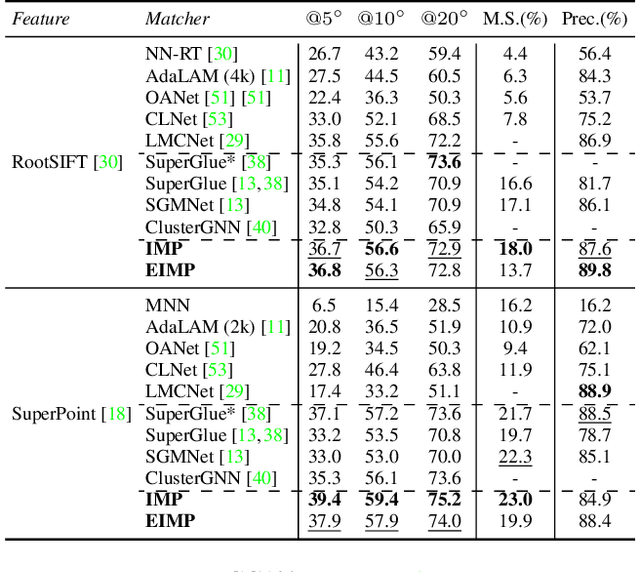
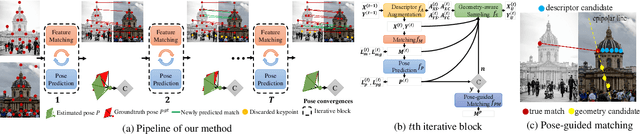
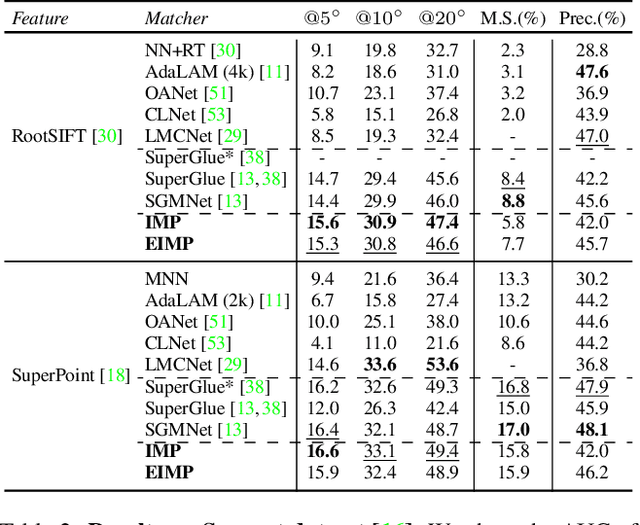
Previous methods solve feature matching and pose estimation using a two-stage process by first finding matches and then estimating the pose. As they ignore the geometric relationships between the two tasks, they focus on either improving the quality of matches or filtering potential outliers, leading to limited efficiency or accuracy. In contrast, we propose an iterative matching and pose estimation framework (IMP) leveraging the geometric connections between the two tasks: a few good matches are enough for a roughly accurate pose estimation; a roughly accurate pose can be used to guide the matching by providing geometric constraints. To this end, we implement a geometry-aware recurrent attention-based module which jointly outputs sparse matches and camera poses. Specifically, for each iteration, we first implicitly embed geometric information into the module via a pose-consistency loss, allowing it to predict geometry-aware matches progressively. Second, we introduce an \textbf{e}fficient IMP, called EIMP, to dynamically discard keypoints without potential matches, avoiding redundant updating and significantly reducing the quadratic time complexity of attention computation in transformers. Experiments on YFCC100m, Scannet, and Aachen Day-Night datasets demonstrate that the proposed method outperforms previous approaches in terms of accuracy and efficiency.
MLCopilot: Unleashing the Power of Large Language Models in Solving Machine Learning Tasks
Apr 28, 2023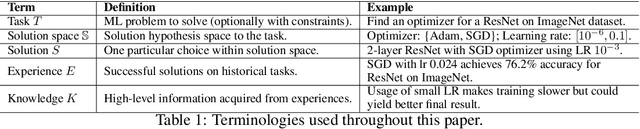
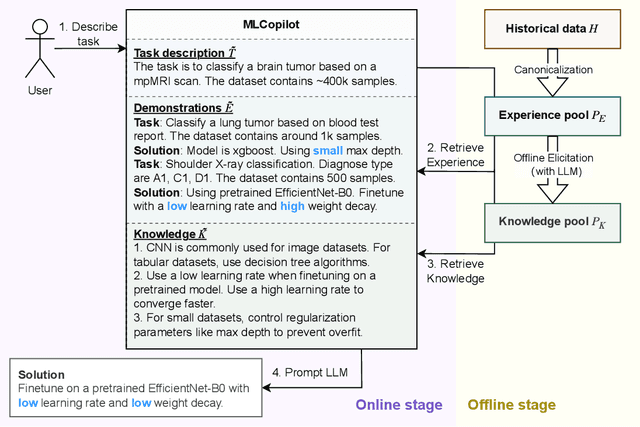
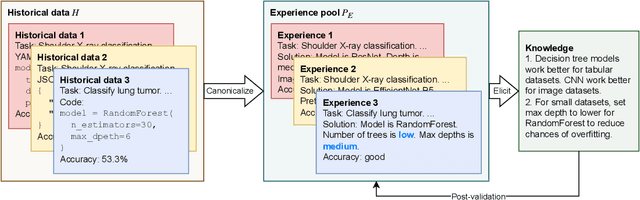
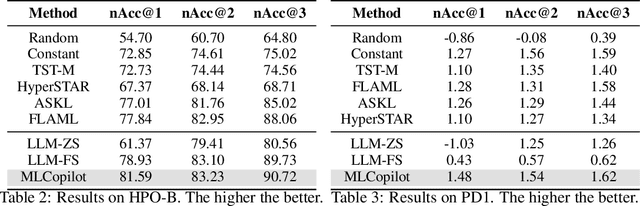
The field of machine learning (ML) has gained widespread adoption, leading to a significant demand for adapting ML to specific scenarios, which is yet expensive and non-trivial. The predominant approaches towards the automation of solving ML tasks (e.g., AutoML) are often time consuming and hard to understand for human developers. In contrast, though human engineers have the incredible ability to understand tasks and reason about solutions, their experience and knowledge are often sparse and difficult to utilize by quantitative approaches. In this paper, we aim to bridge the gap between machine intelligence and human knowledge by introducing a novel framework MLCopilot, which leverages the state-of-the-art LLMs to develop ML solutions for novel tasks. We showcase the possibility of extending the capability of LLMs to comprehend structured inputs and perform thorough reasoning for solving novel ML tasks. And we find that, after some dedicated design, the LLM can (i) observe from the existing experiences of ML tasks and (ii) reason effectively to deliver promising results for new tasks. The solution generated can be used directly to achieve high levels of competitiveness.
TorchBench: Benchmarking PyTorch with High API Surface Coverage
Apr 28, 2023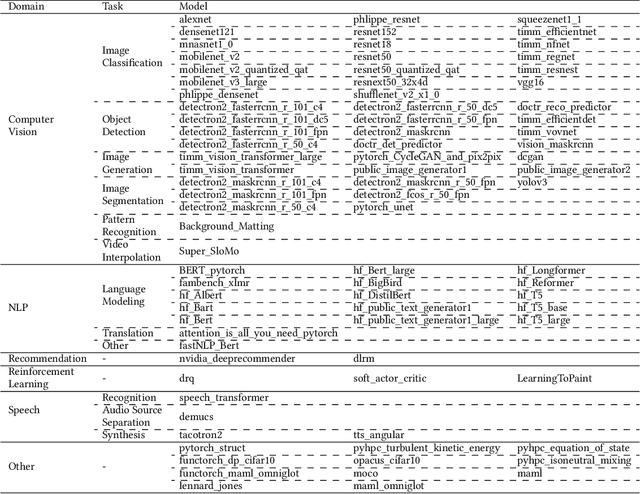
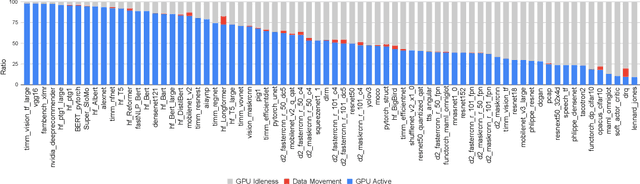
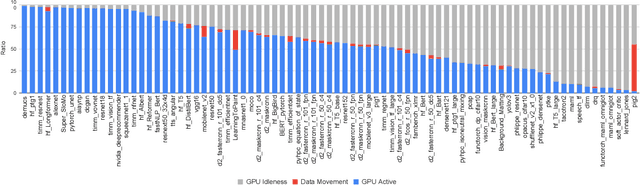
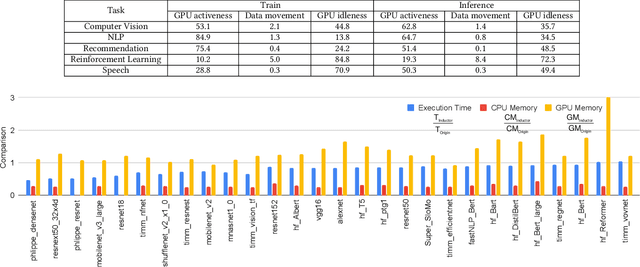
Deep learning (DL) has been a revolutionary technique in various domains. To facilitate the model development and deployment, many deep learning frameworks are proposed, among which PyTorch is one of the most popular solutions. The performance of ecosystem around PyTorch is critically important, which saves the costs of training models and reduces the response time of model inferences. In this paper, we propose TorchBench, a novel benchmark suite to study the performance of PyTorch software stack. Unlike existing benchmark suites, TorchBench encloses many representative models, covering a large PyTorch API surface. TorchBench is able to comprehensively characterize the performance of the PyTorch software stack, guiding the performance optimization across models, PyTorch framework, and GPU libraries. We show two practical use cases of TorchBench. (1) We profile TorchBench to identify GPU performance inefficiencies in PyTorch. We are able to optimize many performance bugs and upstream patches to the official PyTorch repository. (2) We integrate TorchBench into PyTorch continuous integration system. We are able to identify performance regression in multiple daily code checkins to prevent PyTorch repository from introducing performance bugs. TorchBench is open source and keeps evolving.
ChatGPT Evaluation on Sentence Level Relations: A Focus on Temporal, Causal, and Discourse Relations
Apr 28, 2023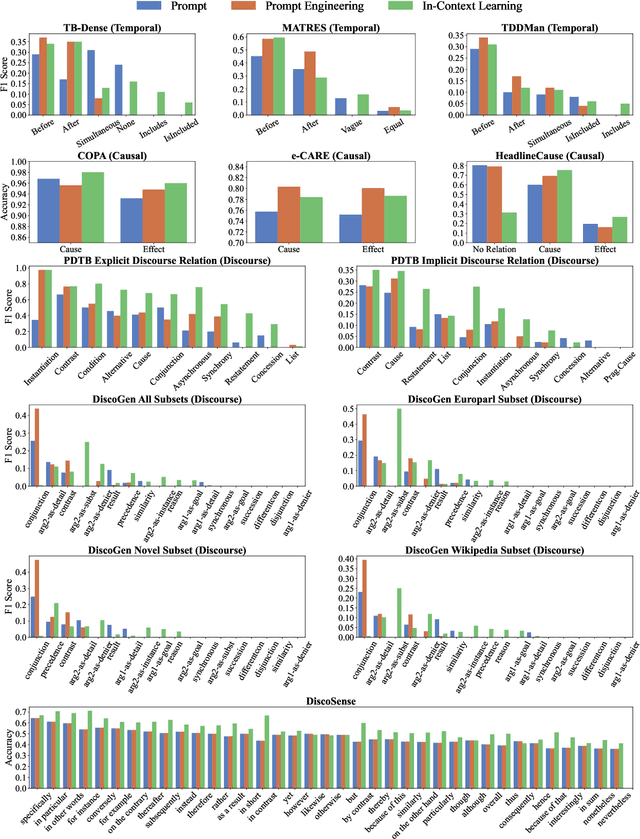
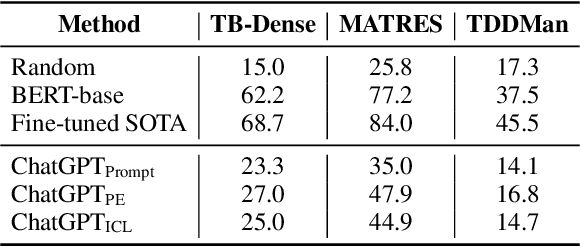
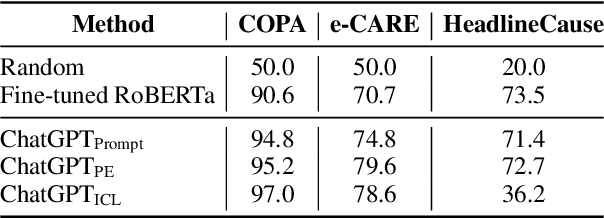
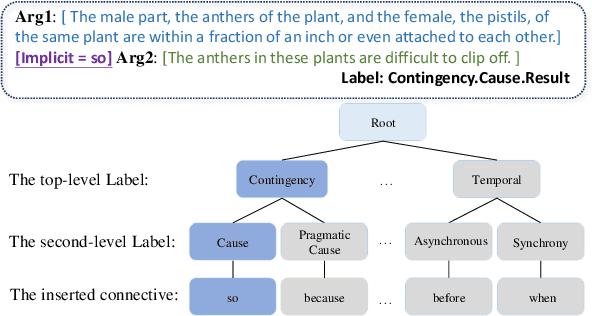
This paper aims to quantitatively evaluate the performance of ChatGPT, an interactive large language model, on inter-sentential relations such as temporal relations, causal relations, and discourse relations. Given ChatGPT's promising performance across various tasks, we conduct extensive evaluations on the whole test sets of 13 datasets, including temporal and causal relations, PDTB2.0-based and dialogue-based discourse relations, and downstream applications on discourse understanding. To achieve reliable results, we adopt three tailored prompt templates for each task, including the zero-shot prompt template, zero-shot prompt engineering (PE) template, and in-context learning (ICL) prompt template, to establish the initial baseline scores for all popular sentence-pair relation classification tasks for the first time. We find that ChatGPT exhibits strong performance in detecting and reasoning about causal relations, while it may not be proficient in identifying the temporal order between two events. It can recognize most discourse relations with existing explicit discourse connectives, but the implicit discourse relation still remains a challenging task. Meanwhile, ChatGPT performs poorly in the dialogue discourse parsing task that requires structural understanding in a dialogue before being aware of the discourse relation.
Time-reversal equivariant neural network potential and Hamiltonian for magnetic materials
Nov 21, 2022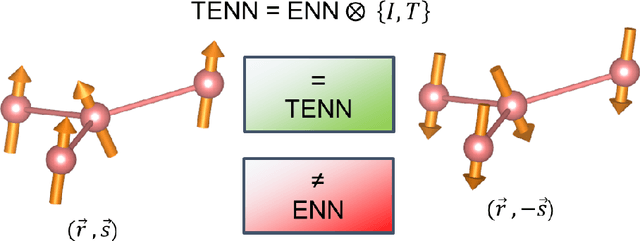

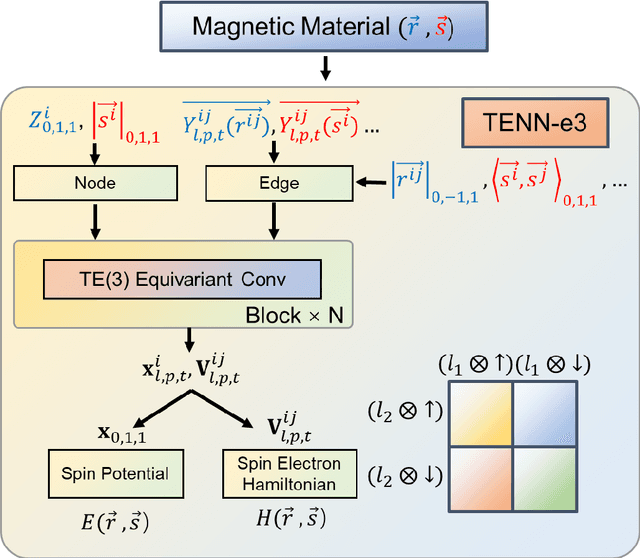
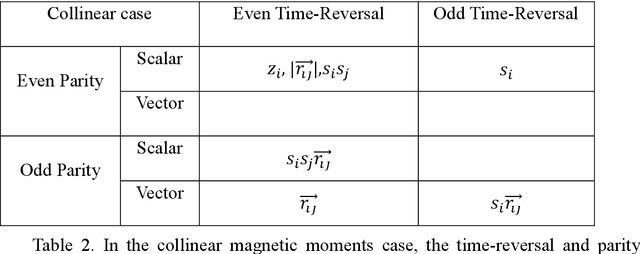
This work presents Time-reversal Equivariant Neural Network (TENN) framework. With TENN, the time-reversal symmetry is considered in the equivariant neural network (ENN), which generalizes the ENN to consider physical quantities related to time-reversal symmetry such as spin and velocity of atoms. TENN-e3, as the time-reversal-extension of E(3) equivariant neural network, is developed to keep the Time-reversal E(3) equivariant with consideration of whether to include the spin-orbit effect for both collinear and non-collinear magnetic moments situations for magnetic material. TENN-e3 can construct spin neural network potential and the Hamiltonian of magnetic material from ab-initio calculations. Time-reversal-E(3)-equivariant convolutions for interactions of spinor and geometric tensors are employed in TENN-e3. Compared to the popular ENN, TENN-e3 can describe the complex spin-lattice coupling with high accuracy and keep time-reversal symmetry which is not preserved in the existing E(3)-equivariant model. Also, the Hamiltonian of magnetic material with time-reversal symmetry can be built with TENN-e3. TENN paves a new way to spin-lattice dynamics simulations over long-time scales and electronic structure calculations of large-scale magnetic materials.
CoTMix: Contrastive Domain Adaptation for Time-Series via Temporal Mixup
Dec 03, 2022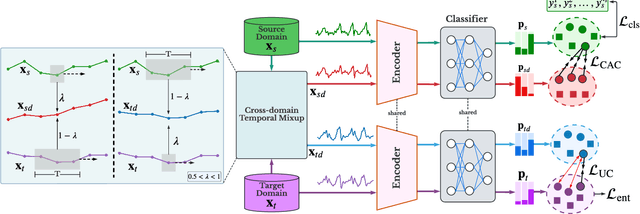
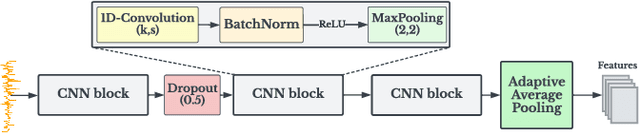
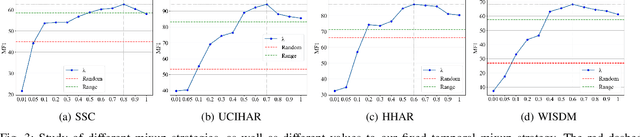
Unsupervised Domain Adaptation (UDA) has emerged as a powerful solution for the domain shift problem via transferring the knowledge from a labeled source domain to a shifted unlabeled target domain. Despite the prevalence of UDA for visual applications, it remains relatively less explored for time-series applications. In this work, we propose a novel lightweight contrastive domain adaptation framework called CoTMix for time-series data. Unlike existing approaches that either use statistical distances or adversarial techniques, we leverage contrastive learning solely to mitigate the distribution shift across the different domains. Specifically, we propose a novel temporal mixup strategy to generate two intermediate augmented views for the source and target domains. Subsequently, we leverage contrastive learning to maximize the similarity between each domain and its corresponding augmented view. The generated views consider the temporal dynamics of time-series data during the adaptation process while inheriting the semantics among the two domains. Hence, we gradually push both domains towards a common intermediate space, mitigating the distribution shift across them. Extensive experiments conducted on four real-world time-series datasets show that our approach can significantly outperform all state-of-the-art UDA methods. The implementation code of CoTMix is available at \href{https://github.com/emadeldeen24/CoTMix}{github.com/emadeldeen24/CoTMix}.
Time-Varying Correlation Networks for Interpretable Change Point Detection
Nov 08, 2022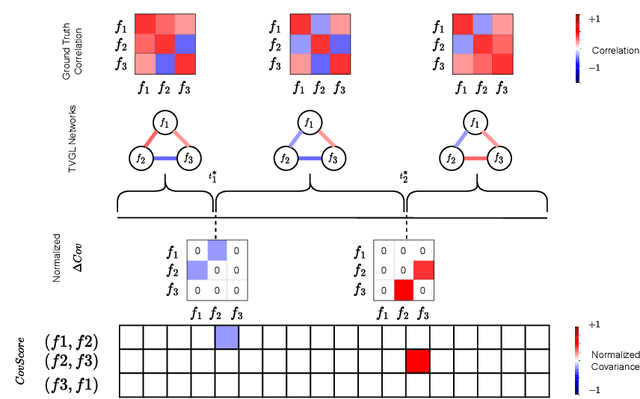
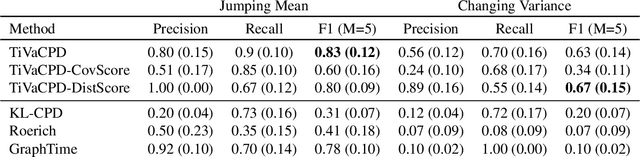
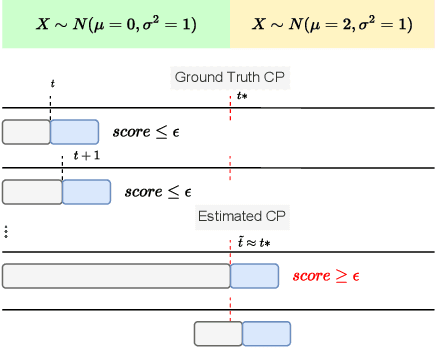
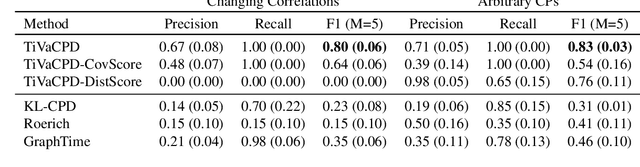
Change point detection (CPD) methods aim to detect abrupt changes in time-series data. Recent CPD methods have demonstrated their potential in identifying changes in underlying statistical distributions but often fail to capture complex changes in the correlation structure in time-series data. These methods also fail to generalize effectively, as even within the same time-series, different kinds of change points (CPs) may arise that are best characterized by different types of time-series perturbations. To address this issue, we propose TiVaCPD, a CPD methodology that uses a time-varying graphical lasso based method to identify changes in correlation patterns between features over time, and combines that with an aggregate Kernel Maximum Mean Discrepancy (MMD) test to identify subtle changes in the underlying statistical distributions of dynamically established time windows. We evaluate the performance of TiVaCPD in identifying and characterizing various types of CPs in time-series and show that our method outperforms current state-of-the-art CPD methods for all categories of CPs.
Taming graph kernels with random features
Apr 29, 2023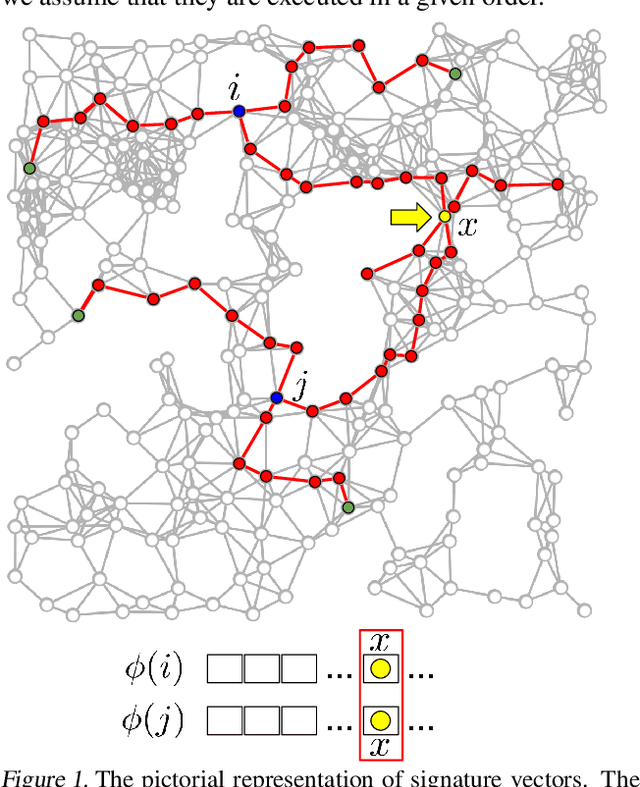
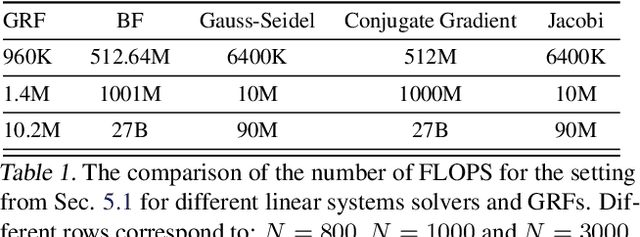

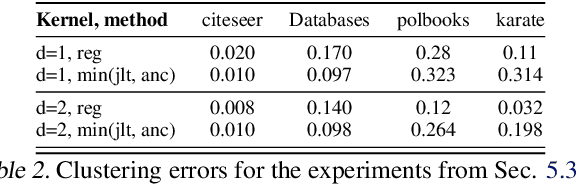
We introduce in this paper the mechanism of graph random features (GRFs). GRFs can be used to construct unbiased randomized estimators of several important kernels defined on graphs' nodes, in particular the regularized Laplacian kernel. As regular RFs for non-graph kernels, they provide means to scale up kernel methods defined on graphs to larger networks. Importantly, they give substantial computational gains also for smaller graphs, while applied in downstream applications. Consequently, GRFs address the notoriously difficult problem of cubic (in the number of the nodes of the graph) time complexity of graph kernels algorithms. We provide a detailed theoretical analysis of GRFs and an extensive empirical evaluation: from speed tests, through Frobenius relative error analysis to kmeans graph-clustering with graph kernels. We show that the computation of GRFs admits an embarrassingly simple distributed algorithm that can be applied if the graph under consideration needs to be split across several machines. We also introduce a (still unbiased) quasi Monte Carlo variant of GRFs, q-GRFs, relying on the so-called reinforced random walks, that might be used to optimize the variance of GRFs. As a byproduct, we obtain a novel approach to solve certain classes of linear equations with positive and symmetric matrices.
Invariant Representations in Deep Learning for Optoacoustic Imaging
Apr 29, 2023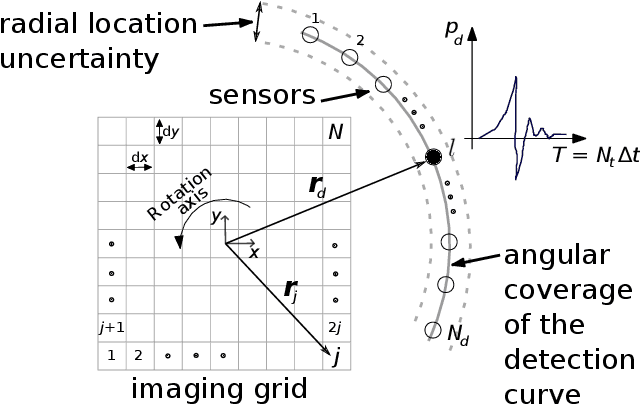

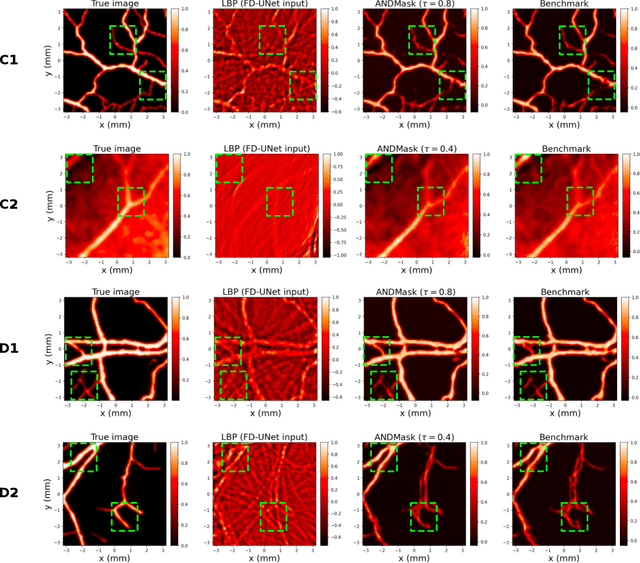
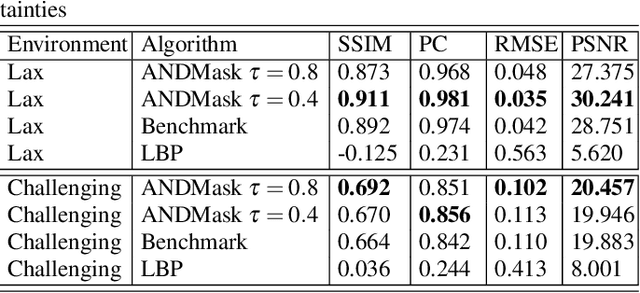
Image reconstruction in optoacoustic tomography (OAT) is a trending learning task highly dependent on measured physical magnitudes present at sensing time. The large number of different settings, and also the presence of uncertainties or partial knowledge of parameters, can lead to reconstructions algorithms that are specifically tailored and designed to a particular configuration which could not be the one that will be ultimately faced in a final practical situation. Being able to learn reconstruction algorithms that are robust to different environments (e.g. the different OAT image reconstruction settings) or invariant to such environments is highly valuable because it allows to focus on what truly matters for the application at hand and discard what are considered spurious features. In this work we explore the use of deep learning algorithms based on learning invariant and robust representations for the OAT inverse problem. In particular, we consider the application of the ANDMask scheme due to its easy adaptation to the OAT problem. Numerical experiments are conducted showing that, when out-of-distribution generalization (against variations in parameters such as the location of the sensors) is imposed, there is no degradation of the performance and, in some cases, it is even possible to achieve improvements with respect to standard deep learning approaches where invariance robustness is not explicitly considered.