 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ChatGPT Evaluation on Sentence Level Relations: A Focus on Temporal, Causal, and Discourse Relations
Apr 28, 2023
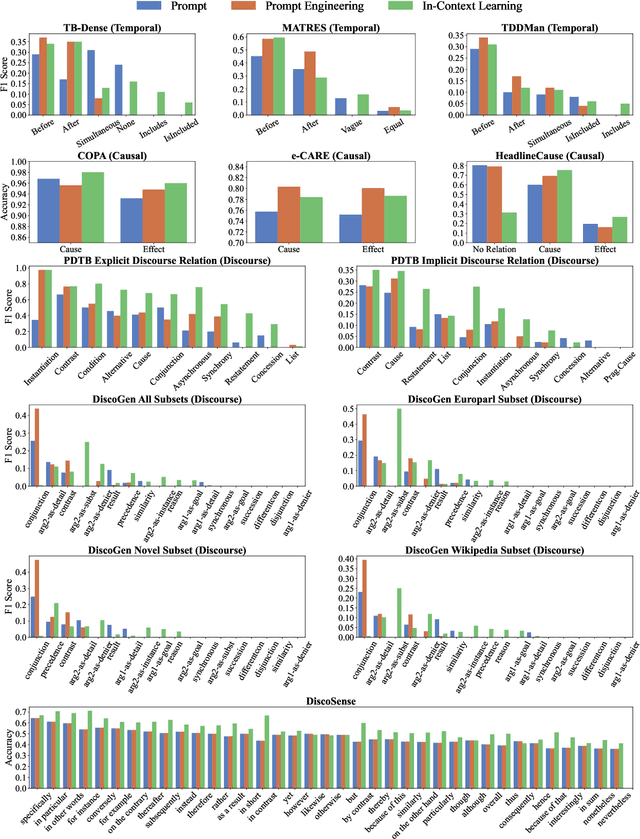
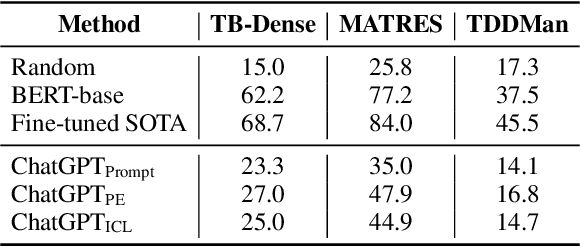
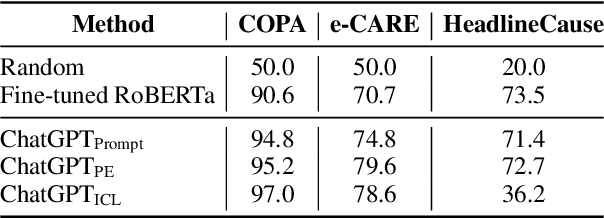
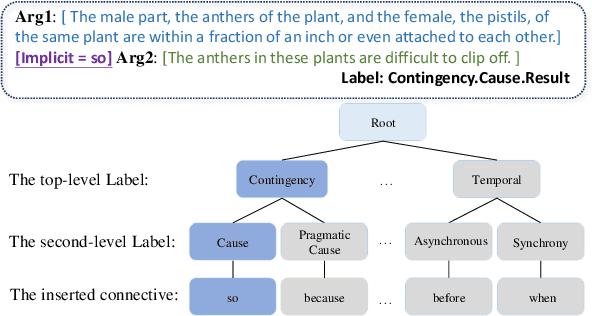
This paper aims to quantitatively evaluate the performance of ChatGPT, an interactive large language model, on inter-sentential relations such as temporal relations, causal relations, and discourse relations. Given ChatGPT's promising performance across various tasks, we conduct extensive evaluations on the whole test sets of 13 datasets, including temporal and causal relations, PDTB2.0-based and dialogue-based discourse relations, and downstream applications on discourse understanding. To achieve reliable results, we adopt three tailored prompt templates for each task, including the zero-shot prompt template, zero-shot prompt engineering (PE) template, and in-context learning (ICL) prompt template, to establish the initial baseline scores for all popular sentence-pair relation classification tasks for the first time. We find that ChatGPT exhibits strong performance in detecting and reasoning about causal relations, while it may not be proficient in identifying the temporal order between two events. It can recognize most discourse relations with existing explicit discourse connectives, but the implicit discourse relation still remains a challenging task. Meanwhile, ChatGPT performs poorly in the dialogue discourse parsing task that requires structural understanding in a dialogue before being aware of the discourse relation.
BO-ICP: Initialization of Iterative Closest Point Based on Bayesian Optimization
Apr 25, 2023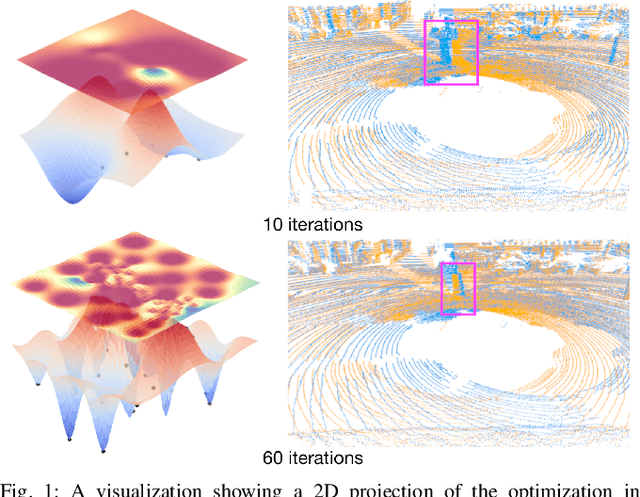

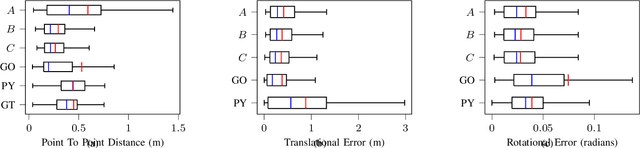

Typical algorithms for point cloud registration such as Iterative Closest Point (ICP) require a favorable initial transform estimate between two point clouds in order to perform a successful registration. State-of-the-art methods for choosing this starting condition rely on stochastic sampling or global optimization techniques such as branch and bound. In this work, we present a new method based on Bayesian optimization for finding the critical initial ICP transform. We provide three different configurations for our method which highlights the versatility of the algorithm to both find rapid results and refine them in situations where more runtime is available such as offline map building. Experiments are run on popular data sets and we show that our approach outperforms state-of-the-art methods when given similar computation time. Furthermore, it is compatible with other improvements to ICP, as it focuses solely on the selection of an initial transform, a starting point for all ICP-based methods.
Exact recovery for the non-uniform Hypergraph Stochastic Block Model
Apr 25, 2023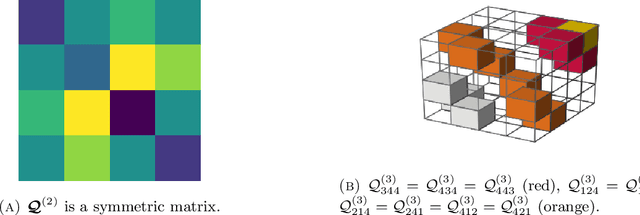
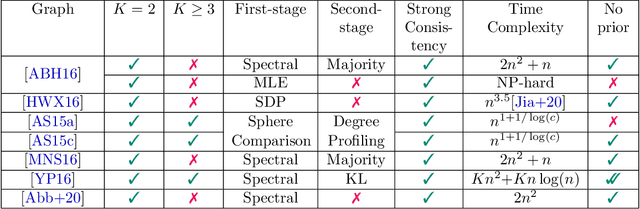
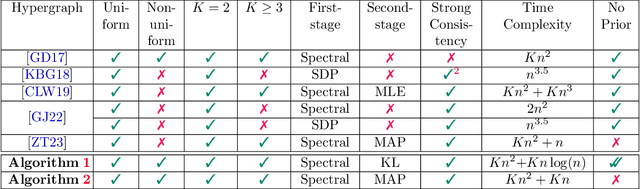
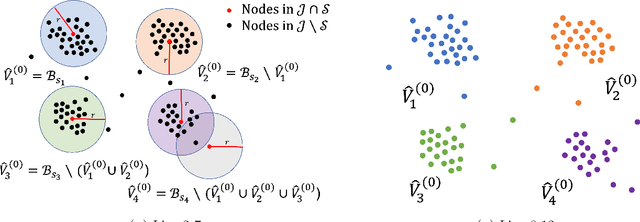
Consider the community detection problem in random hypergraphs under the non-uniform hypergraph stochastic block model (HSBM), where each hyperedge appears independently with some given probability depending only on the labels of its vertices. We establish, for the first time in the literature, a sharp threshold for exact recovery under this non-uniform case, subject to minor constraints; in particular, we consider the model with $K$ classes as well as the symmetric binary model ($K=2$). One crucial point here is that by aggregating information from all the uniform layers, we may obtain exact recovery even in cases when this may appear impossible if each layer were considered alone. Two efficient algorithms that successfully achieve exact recovery above the threshold are provided. The theoretical analysis of our algorithms relies on the concentration and regularization of the adjacency matrix for non-uniform random hypergraphs, which could be of independent interest. We also address some open problems regarding parameter knowledge and estimation.
Deep Learning Framework for the Design of Orbital Angular Momentum Generators Enabled by Leaky-wave Holograms
Apr 25, 2023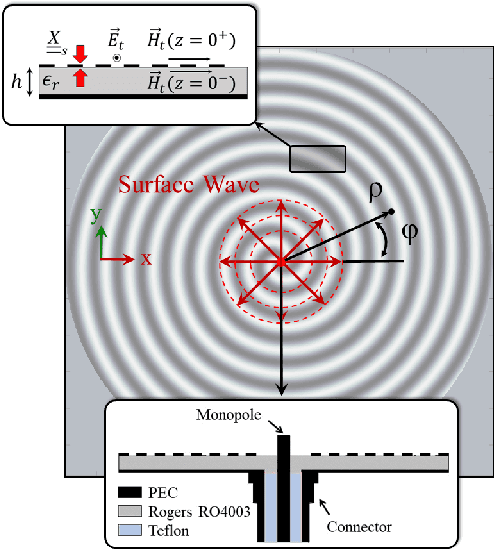
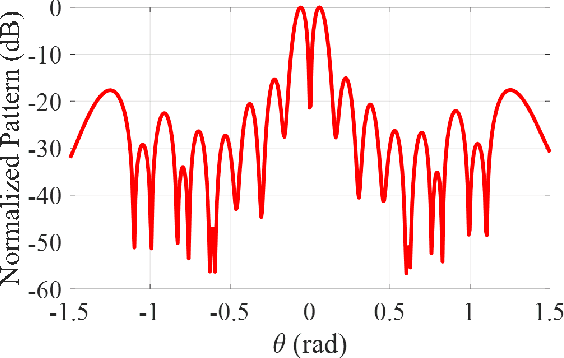
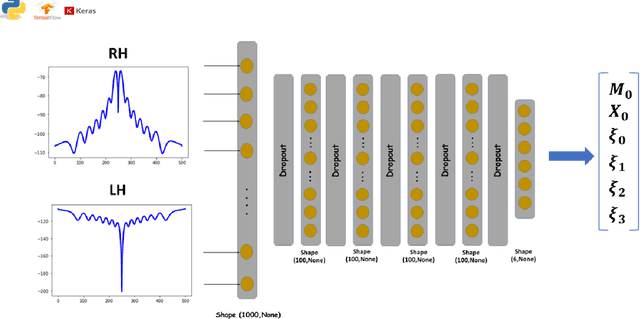
In this paper, we present a novel approach for the design of leaky-wave holographic antennas that generates OAM-carrying electromagnetic waves by combining Flat Optics (FO) and machine learning (ML) techniques. To improve the performance of our system, we use a machine learning technique to discover a mathematical function that can effectively control the entire radiation pattern, i.e., decrease the side lobe level (SLL) while simultaneously increasing the central null depth of the radiation pattern. Precise tuning of the parameters of the impedance equation based on holographic theory is necessary to achieve optimal results in a variety of scenarios. In this research, we applied machine learning to determine the approximate values of the parameters. We can determine the optimal values for each parameter, resulting in the desired radiation pattern, using a total of 77,000 generated datasets. Furthermore, the use of ML not only saves time, but also yields more precise and accurate results than manual parameter tuning and conventional optimization methods.
User-Centric Federated Learning: Trading off Wireless Resources for Personalization
Apr 25, 2023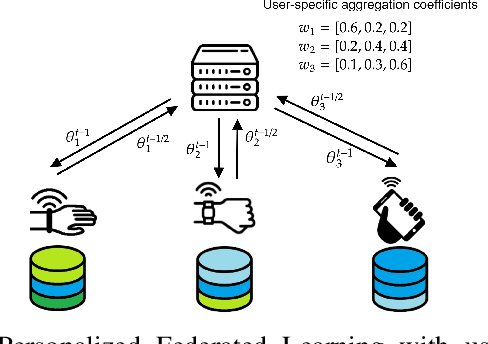
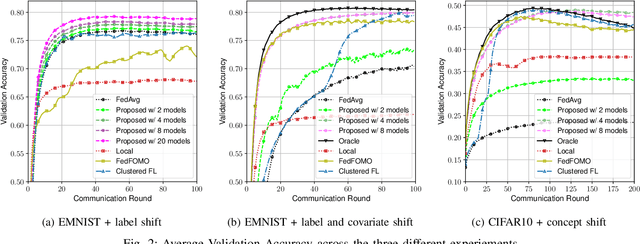
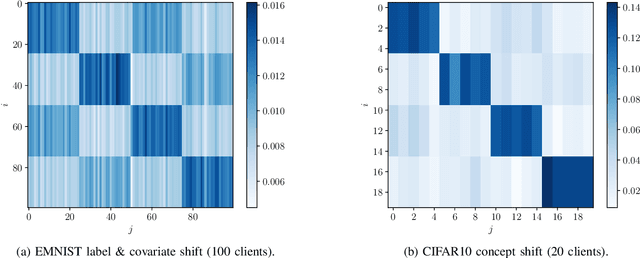
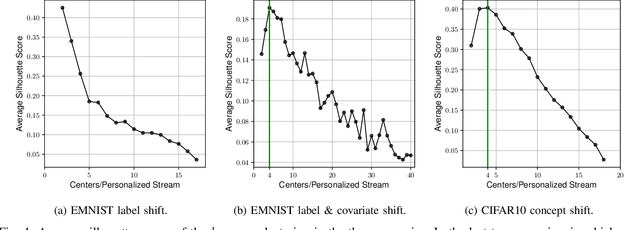
Statistical heterogeneity across clients in a Federated Learning (FL) system increases the algorithm convergence time and reduces the generalization performance, resulting in a large communication overhead in return for a poor model. To tackle the above problems without violating the privacy constraints that FL imposes, personalized FL methods have to couple statistically similar clients without directly accessing their data in order to guarantee a privacy-preserving transfer. In this work, we design user-centric aggregation rules at the parameter server (PS) that are based on readily available gradient information and are capable of producing personalized models for each FL client. The proposed aggregation rules are inspired by an upper bound of the weighted aggregate empirical risk minimizer. Secondly, we derive a communication-efficient variant based on user clustering which greatly enhances its applicability to communication-constrained systems. Our algorithm outperforms popular personalized FL baselines in terms of average accuracy, worst node performance, and training communication overhead.
Cooperative Distributed MPC via Decentralized Real-Time Optimization: Implementation Results for Robot Formations
Jan 19, 2023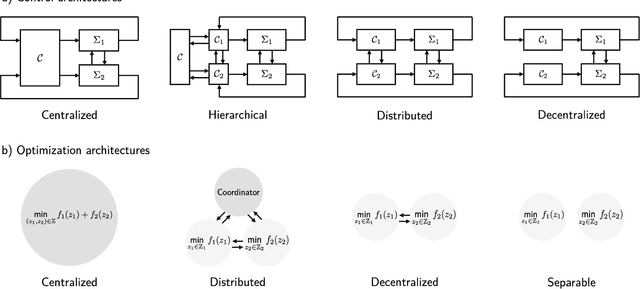


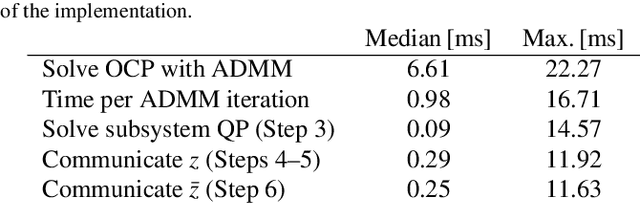
Distributed model predictive control (DMPC) is a flexible and scalable feedback control method applicable to a wide range of systems. While stability analysis of DMPC is quite well understood, there exist only limited implementation results for realistic applications involving distributed computation and networked communication. This article approaches formation control of mobile robots via a cooperative DMPC scheme. We discuss the implementation via decentralized optimization algorithms. To this end, we combine the alternating direction method of multipliers with decentralized sequential quadratic programming to solve the underlying optimal control problem in a decentralized fashion. Our approach only requires coupled subsystems to communicate and does not rely on a central coordinator. Our experimental results showcase the efficacy of DMPC for formation control and they demonstrate the real-time feasibility of the considered algorithms.
Computational Performance Aware Benchmarking of Unsupervised Concept Drift Detection
Apr 17, 2023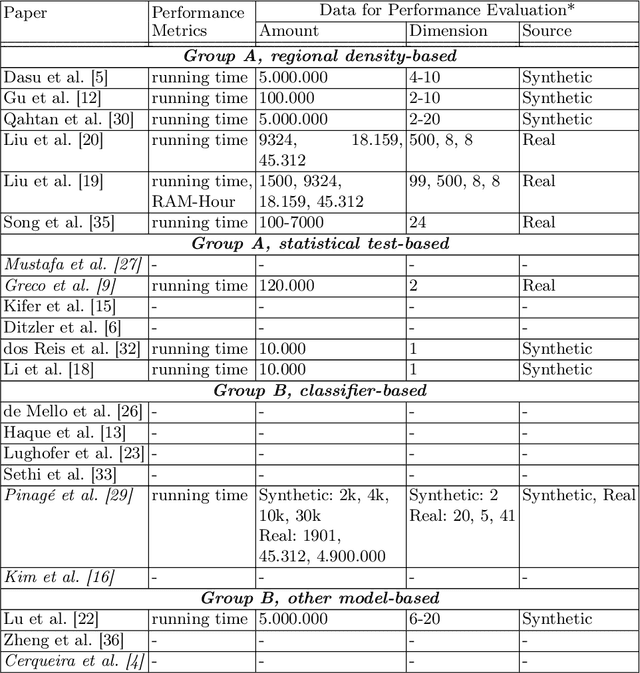
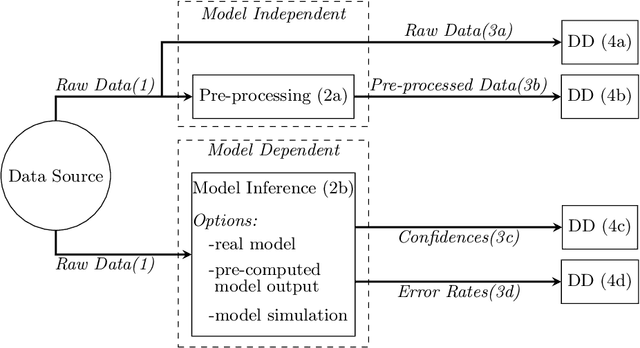
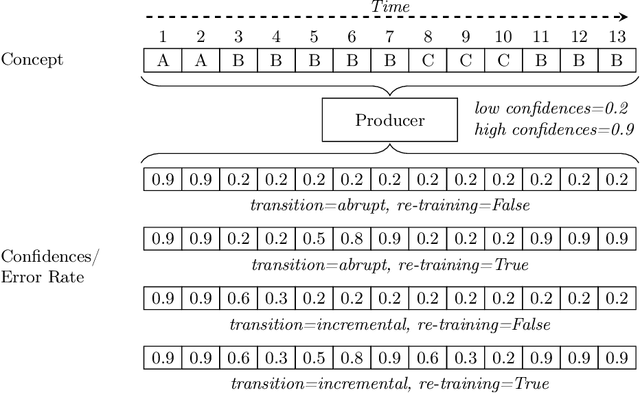
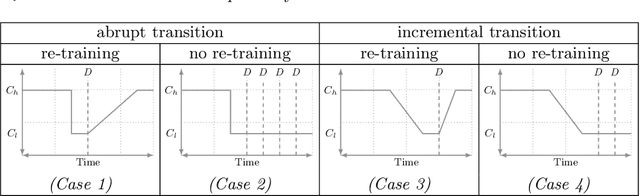
For many AI systems, concept drift detection is crucial to ensure the systems reliability. These systems often have to deal with large amounts of data or react in real time. Thus, drift detectors must meet computational requirements or constraints with a comprehensive performance evaluation. However, so far, the focus of developing drift detectors is on detection quality, e.g.~accuracy, but not on computational performance, such as running time. We show that the previous works consider computational performance only as a secondary objective and do not have a benchmark for such evaluation. Hence, we propose a novel benchmark suite for drift detectors that accounts both detection quality and computational performance to ensure a detector's applicability in various AI systems. In this work, we focus on unsupervised drift detectors that are not restricted to the availability of labeled data and thus being widely applicable. Our benchmark suite supports configurable synthetic and real world data streams. Moreover, it provides means for simulating a machine learning model's output to unify the performance evaluation across different drift detectors. This allows a fair and comprehensive comparison of drift detectors proposed in related work. Our benchmark suite is integrated in the existing framework, Massive Online Analysis (MOA). To evaluate our benchmark suite's capability, we integrate two representative unsupervised drift detectors. Our work enables the scientific community to achieve a baseline for unsupervised drift detectors with respect to both detection quality and computational performance.
Unsupervised 4D LiDAR Moving Object Segmentation in Stationary Settings with Multivariate Occupancy Time Series
Dec 30, 2022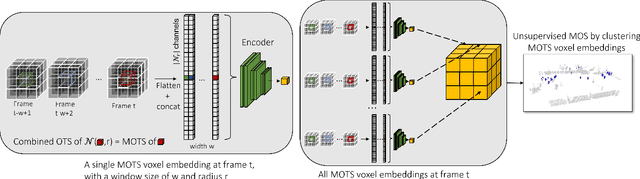

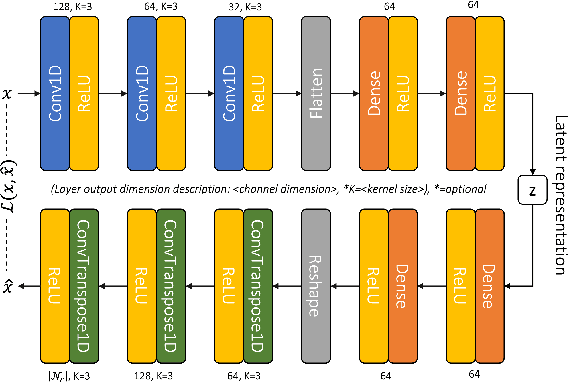

In this work, we address the problem of unsupervised moving object segmentation (MOS) in 4D LiDAR data recorded from a stationary sensor, where no ground truth annotations are involved. Deep learning-based state-of-the-art methods for LiDAR MOS strongly depend on annotated ground truth data, which is expensive to obtain and scarce in existence. To close this gap in the stationary setting, we propose a novel 4D LiDAR representation based on multivariate time series that relaxes the problem of unsupervised MOS to a time series clustering problem. More specifically, we propose modeling the change in occupancy of a voxel by a multivariate occupancy time series (MOTS), which captures spatio-temporal occupancy changes on the voxel level and its surrounding neighborhood. To perform unsupervised MOS, we train a neural network in a self-supervised manner to encode MOTS into voxel-level feature representations, which can be partitioned by a clustering algorithm into moving or stationary. Experiments on stationary scenes from the Raw KITTI dataset show that our fully unsupervised approach achieves performance that is comparable to that of supervised state-of-the-art approaches.
Taming graph kernels with random features
Apr 29, 2023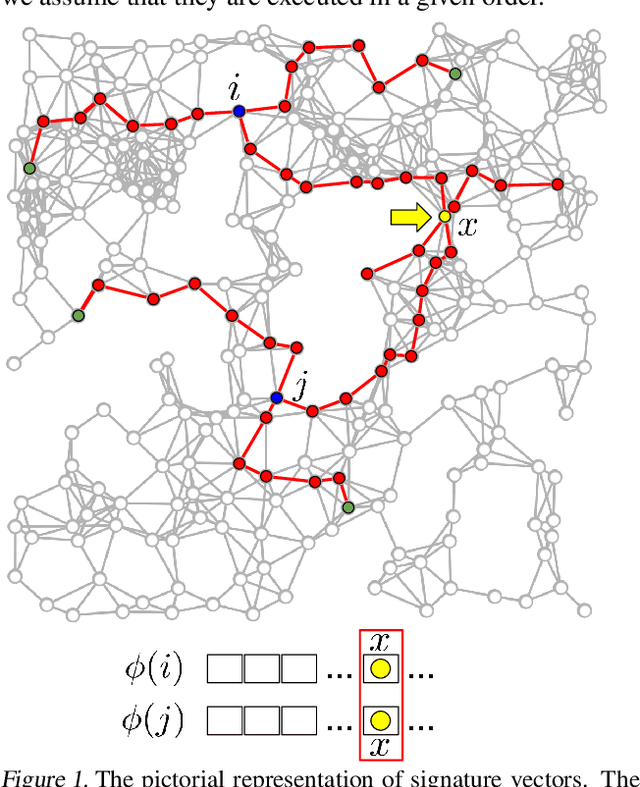
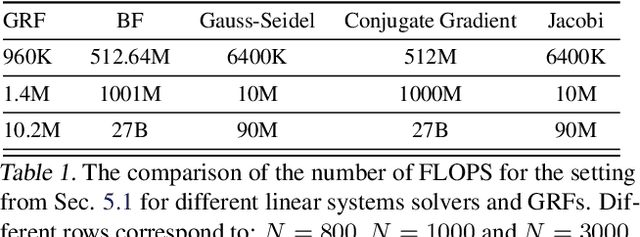

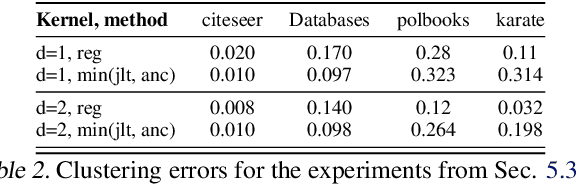
We introduce in this paper the mechanism of graph random features (GRFs). GRFs can be used to construct unbiased randomized estimators of several important kernels defined on graphs' nodes, in particular the regularized Laplacian kernel. As regular RFs for non-graph kernels, they provide means to scale up kernel methods defined on graphs to larger networks. Importantly, they give substantial computational gains also for smaller graphs, while applied in downstream applications. Consequently, GRFs address the notoriously difficult problem of cubic (in the number of the nodes of the graph) time complexity of graph kernels algorithms. We provide a detailed theoretical analysis of GRFs and an extensive empirical evaluation: from speed tests, through Frobenius relative error analysis to kmeans graph-clustering with graph kernels. We show that the computation of GRFs admits an embarrassingly simple distributed algorithm that can be applied if the graph under consideration needs to be split across several machines. We also introduce a (still unbiased) quasi Monte Carlo variant of GRFs, q-GRFs, relying on the so-called reinforced random walks, that might be used to optimize the variance of GRFs. As a byproduct, we obtain a novel approach to solve certain classes of linear equations with positive and symmetric matrices.
Path Planning for Multiple Tethered Robots Using Topological Braids
Apr 29, 2023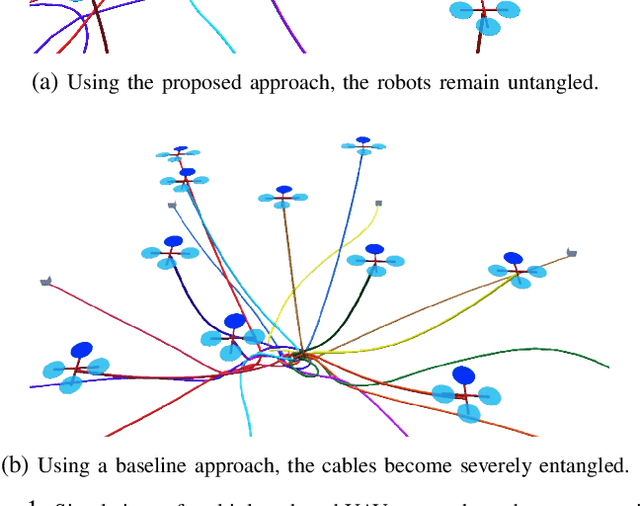
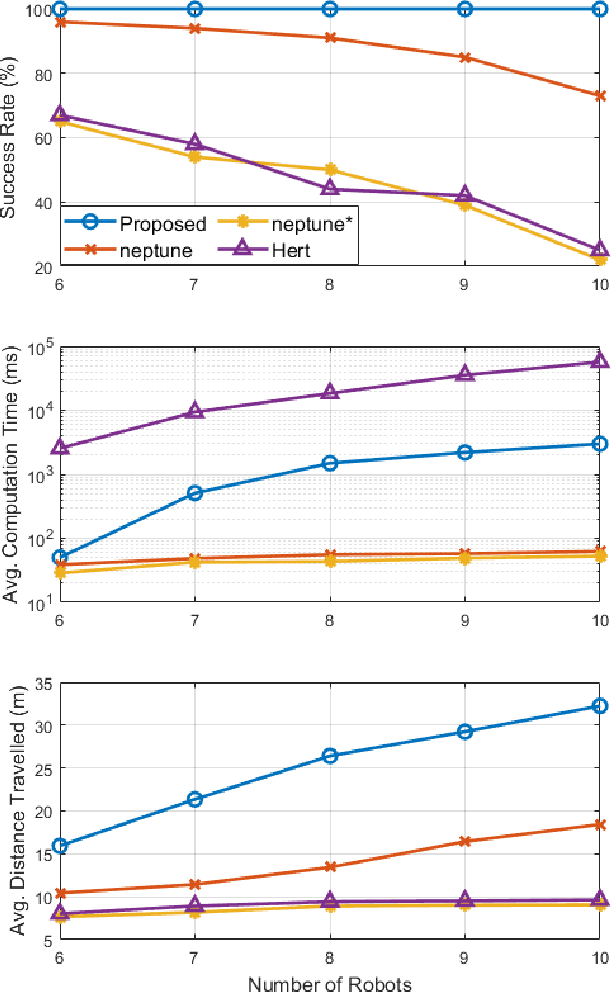
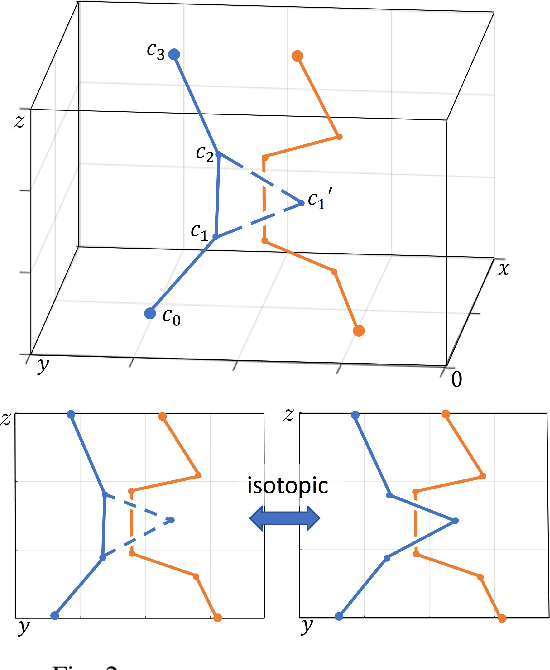
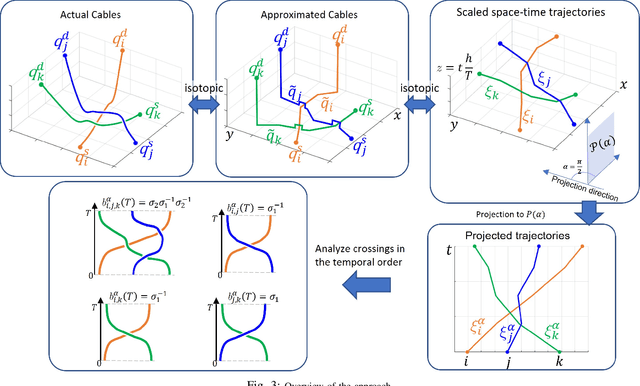
Path planning for multiple tethered robots is a challenging problem due to the complex interactions among the cables and the possibility of severe entanglements. Previous works on this problem either consider idealistic cable models or provide no guarantee for entanglement-free paths. In this work, we present a new approach to address this problem using the theory of braids. By establishing a topological equivalence between the physical cables and the space-time trajectories of the robots, and identifying particular braid patterns that emerge from the entangled trajectories, we obtain the key finding that all complex entanglements stem from a finite number of interaction patterns between 2 or 3 robots. Hence, non-entanglement can be guaranteed by avoiding these interaction patterns in the trajectories of the robots. Based on this finding, we present a graph search algorithm using the permutation grid to efficiently search for a feasible topology of paths and reject braid patterns that result in an entanglement. We demonstrate that the proposed algorithm can achieve 100% goal-reaching capability without entanglement for up to 10 drones with a slack cable model in a high-fidelity simulation platform. The practicality of the proposed approach is verified using three small tethered UAVs in indoor flight experiments.