 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Revolutionizing Packaging: A Robotic Bagging Pipeline with Constraint-aware Structure-of-Interest Planning
Mar 15, 2024

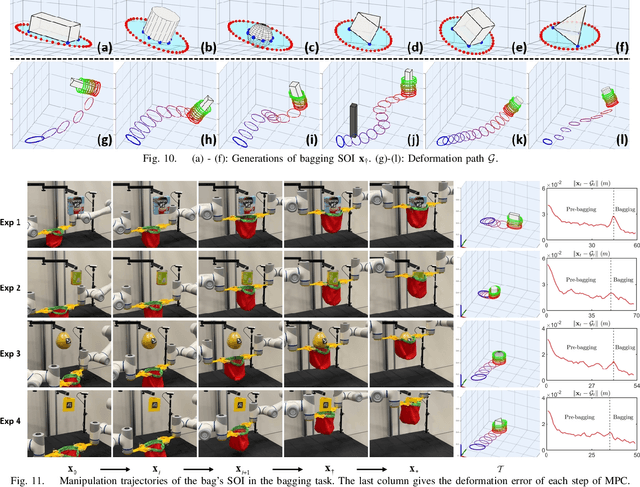
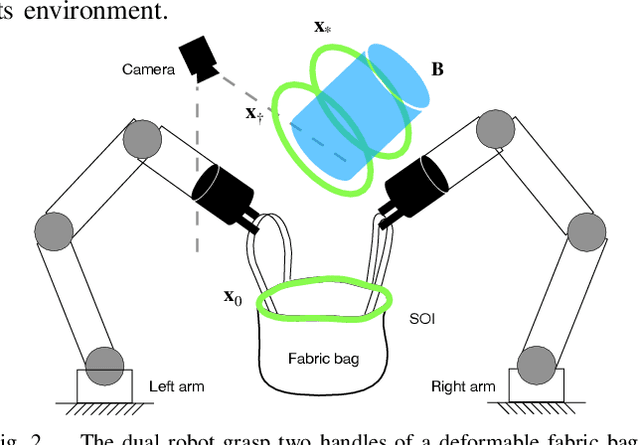
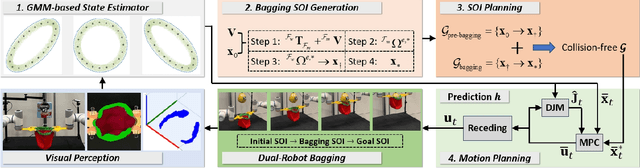
Bagging operations, common in packaging and assisted living applications, are challenging due to a bag's complex deformable properties. To address this, we develop a robotic system for automated bagging tasks using an adaptive structure-of-interest (SOI) manipulation approach. Our method relies on real-time visual feedback to dynamically adjust manipulation without requiring prior knowledge of bag materials or dynamics. We present a robust pipeline featuring state estimation for SOIs using Gaussian Mixture Models (GMM), SOI generation via optimization-based bagging techniques, SOI motion planning with Constrained Bidirectional Rapidly-exploring Random Trees (CBiRRT), and dual-arm manipulation coordinated by Model Predictive Control (MPC). Experiments demonstrate the system's ability to achieve precise, stable bagging of various objects using adaptive coordination of the manipulators. The proposed framework advances the capability of dual-arm robots to perform more sophisticated automation of common tasks involving interactions with deformable objects.
Accurate and Data-Efficient Micro-XRD Phase Identification Using Multi-Task Learning: Application to Hydrothermal Fluids
Mar 15, 2024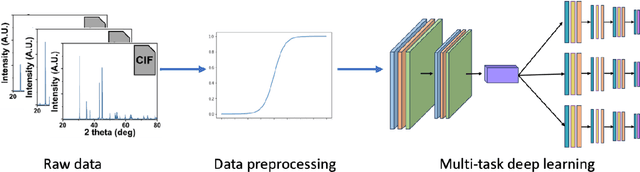

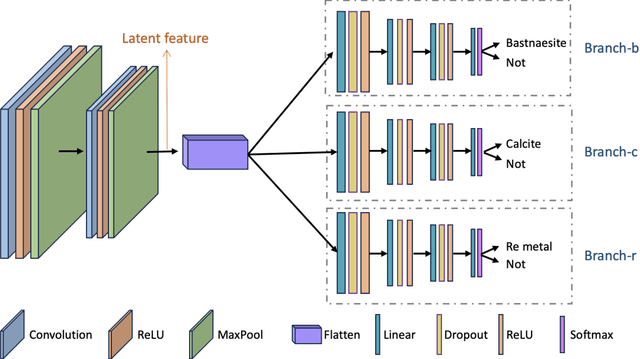
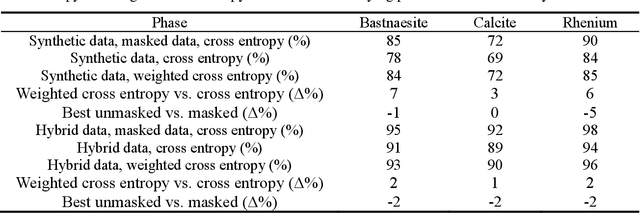
Traditional analysis of highly distorted micro-X-ray diffraction ({\mu}-XRD) patterns from hydrothermal fluid environments is a time-consuming process, often requiring substantial data preprocessing and labeled experimental data. This study demonstrates the potential of deep learning with a multitask learning (MTL) architecture to overcome these limitations. We trained MTL models to identify phase information in {\mu}-XRD patterns, minimizing the need for labeled experimental data and masking preprocessing steps. Notably, MTL models showed superior accuracy compared to binary classification CNNs. Additionally, introducing a tailored cross-entropy loss function improved MTL model performance. Most significantly, MTL models tuned to analyze raw and unmasked XRD patterns achieved close performance to models analyzing preprocessed data, with minimal accuracy differences. This work indicates that advanced deep learning architectures like MTL can automate arduous data handling tasks, streamline the analysis of distorted XRD patterns, and reduce the reliance on labor-intensive experimental datasets.
Identifying Optimal Launch Sites of High-Altitude Latex-Balloons using Bayesian Optimisation for the Task of Station-Keeping
Mar 16, 2024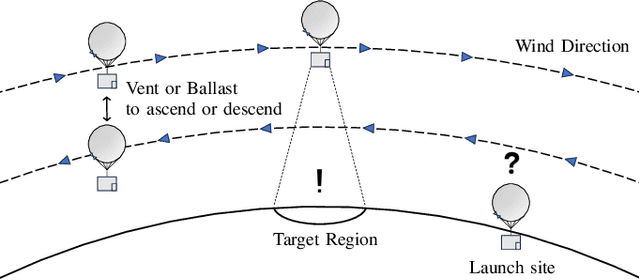
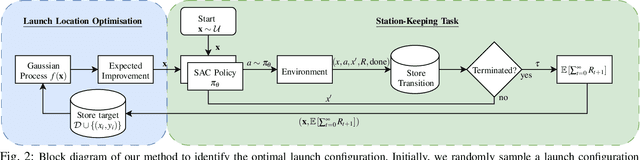
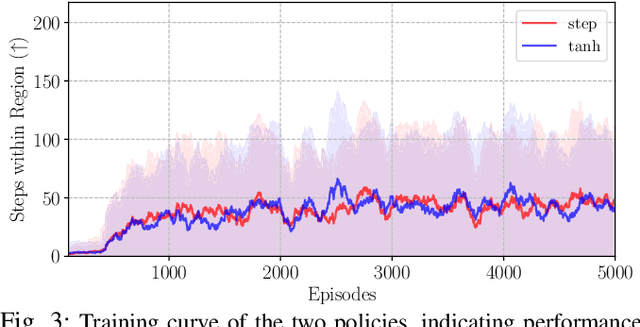
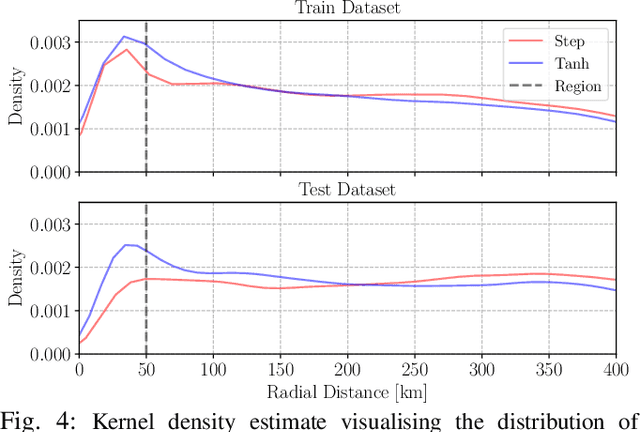
Station-keeping tasks for high-altitude balloons show promise in areas such as ecological surveys, atmospheric analysis, and communication relays. However, identifying the optimal time and position to launch a latex high-altitude balloon is still a challenging and multifaceted problem. For example, tasks such as forest fire tracking place geometric constraints on the launch location of the balloon. Furthermore, identifying the most optimal location also heavily depends on atmospheric conditions. We first illustrate how reinforcement learning-based controllers, frequently used for station-keeping tasks, can exploit the environment. This exploitation can degrade performance on unseen weather patterns and affect station-keeping performance when identifying an optimal launch configuration. Valuing all states equally in the region, the agent exploits the region's geometry by flying near the edge, leading to risky behaviours. We propose a modification which compensates for this exploitation and finds this leads to, on average, higher steps within the target region on unseen data. Then, we illustrate how Bayesian Optimisation (BO) can identify the optimal launch location to perform station-keeping tasks, maximising the expected undiscounted return from a given rollout. We show BO can find this launch location in fewer steps compared to other optimisation methods. Results indicate that, surprisingly, the most optimal location to launch from is not commonly within the target region. Please find further information about our project at https://sites.google.com/view/bo-lauch-balloon/.
Forecasting Geoffective Events from Solar Wind Data and Evaluating the Most Predictive Features through Machine Learning Approaches
Mar 14, 2024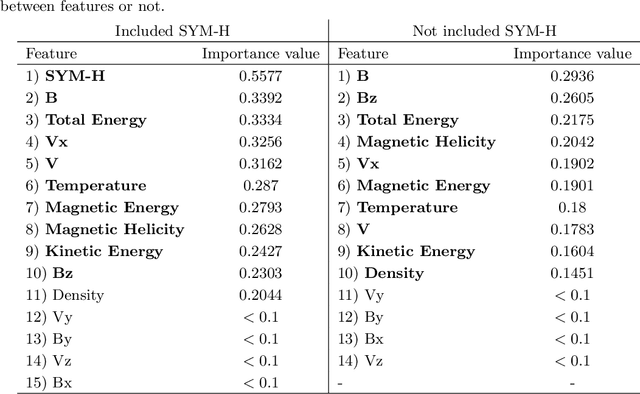
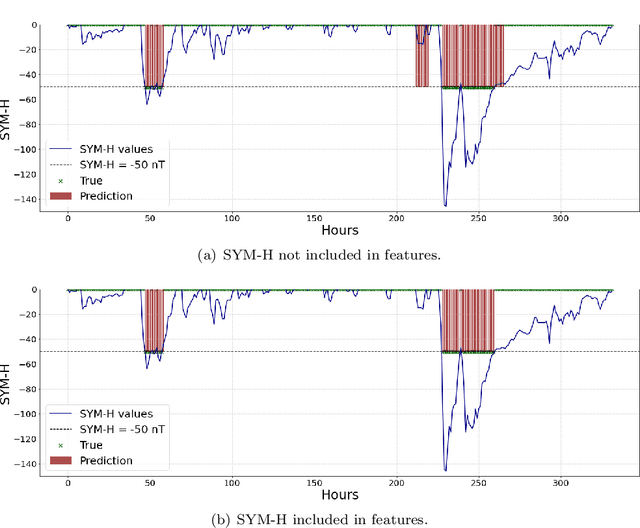
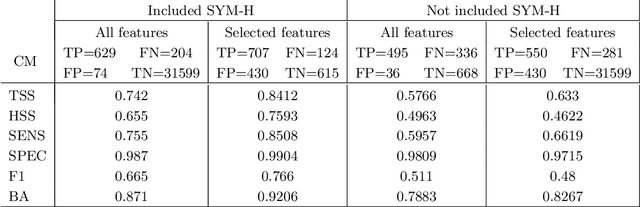
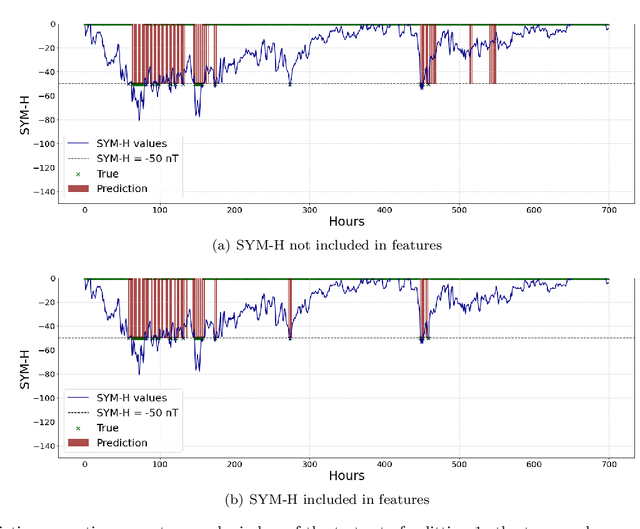
This study addresses the prediction of geomagnetic disturbances by exploiting machine learning techniques. Specifically, the Long-Short Term Memory recurrent neural network, which is particularly suited for application over long time series, is employed in the analysis of in-situ measurements of solar wind plasma and magnetic field acquired over more than one solar cycle, from $2005$ to $2019$, at the Lagrangian point L$1$. The problem is approached as a binary classification aiming to predict one hour in advance a decrease in the SYM-H geomagnetic activity index below the threshold of $-50$ nT, which is generally regarded as indicative of magnetospheric perturbations. The strong class imbalance issue is tackled by using an appropriate loss function tailored to optimize appropriate skill scores in the training phase of the neural network. Beside classical skill scores, value-weighted skill scores are then employed to evaluate predictions, suitable in the study of problems, such as the one faced here, characterized by strong temporal variability. For the first time, the content of magnetic helicity and energy carried by solar transients, associated with their detection and likelihood of geo-effectiveness, were considered as input features of the network architecture. Their predictive capabilities are demonstrated through a correlation-driven feature selection method to rank the most relevant characteristics involved in the neural network prediction model. The optimal performance of the adopted neural network in properly forecasting the onset of geomagnetic storms, which is a crucial point for giving real warnings in an operational setting, is finally showed.
Real-Time Adaptive Safety-Critical Control with Gaussian Processes in High-Order Uncertain Models
Feb 29, 2024This paper presents an adaptive online learning framework for systems with uncertain parameters to ensure safety-critical control in non-stationary environments. Our approach consists of two phases. The initial phase is centered on a novel sparse Gaussian process (GP) framework. We first integrate a forgetting factor to refine a variational sparse GP algorithm, thus enhancing its adaptability. Subsequently, the hyperparameters of the Gaussian model are trained with a specially compound kernel, and the Gaussian model's online inferential capability and computational efficiency are strengthened by updating a solitary inducing point derived from new samples, in conjunction with the learned hyperparameters. In the second phase, we propose a safety filter based on high-order control barrier functions (HOCBFs), synergized with the previously trained learning model. By leveraging the compound kernel from the first phase, we effectively address the inherent limitations of GPs in handling high-dimensional problems for real-time applications. The derived controller ensures a rigorous lower bound on the probability of satisfying the safety specification. Finally, the efficacy of our proposed algorithm is demonstrated through real-time obstacle avoidance experiments executed using both a simulation platform and a real-world 7-DOF robot.
Horizon-Free Regret for Linear Markov Decision Processes
Mar 15, 2024A recent line of works showed regret bounds in reinforcement learning (RL) can be (nearly) independent of planning horizon, a.k.a.~the horizon-free bounds. However, these regret bounds only apply to settings where a polynomial dependency on the size of transition model is allowed, such as tabular Markov Decision Process (MDP) and linear mixture MDP. We give the first horizon-free bound for the popular linear MDP setting where the size of the transition model can be exponentially large or even uncountable. In contrast to prior works which explicitly estimate the transition model and compute the inhomogeneous value functions at different time steps, we directly estimate the value functions and confidence sets. We obtain the horizon-free bound by: (1) maintaining multiple weighted least square estimators for the value functions; and (2) a structural lemma which shows the maximal total variation of the inhomogeneous value functions is bounded by a polynomial factor of the feature dimension.
Structured Evaluation of Synthetic Tabular Data
Mar 15, 2024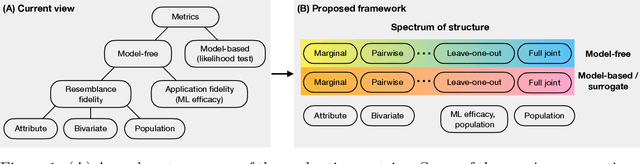
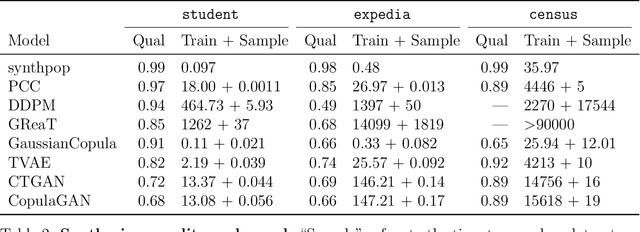
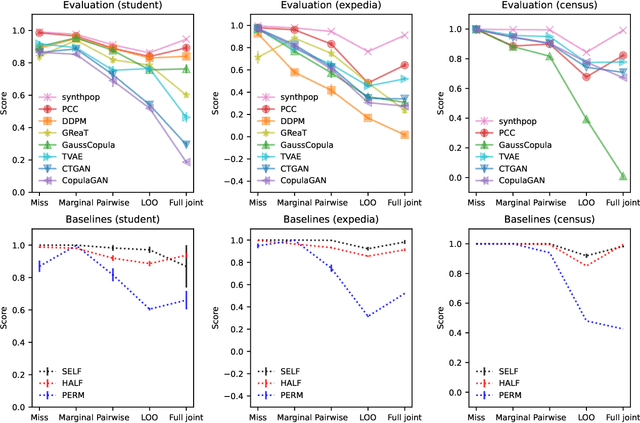
Tabular data is common yet typically incomplete, small in volume, and access-restricted due to privacy concerns. Synthetic data generation offers potential solutions. Many metrics exist for evaluating the quality of synthetic tabular data; however, we lack an objective, coherent interpretation of the many metrics. To address this issue, we propose an evaluation framework with a single, mathematical objective that posits that the synthetic data should be drawn from the same distribution as the observed data. Through various structural decomposition of the objective, this framework allows us to reason for the first time the completeness of any set of metrics, as well as unifies existing metrics, including those that stem from fidelity considerations, downstream application, and model-based approaches. Moreover, the framework motivates model-free baselines and a new spectrum of metrics. We evaluate structurally informed synthesizers and synthesizers powered by deep learning. Using our structured framework, we show that synthetic data generators that explicitly represent tabular structure outperform other methods, especially on smaller datasets.
Computer User Interface Understanding. A New Dataset and a Learning Framework
Mar 15, 2024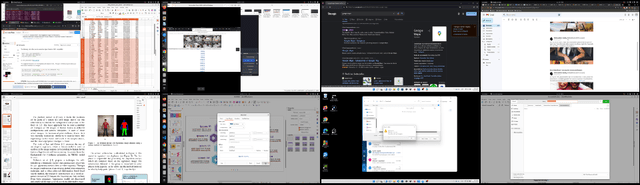
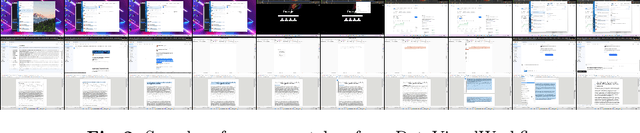
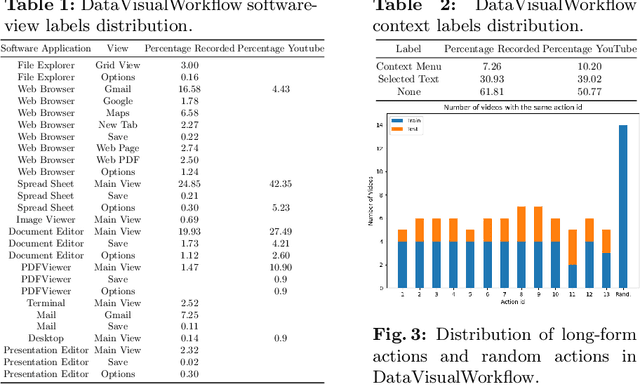
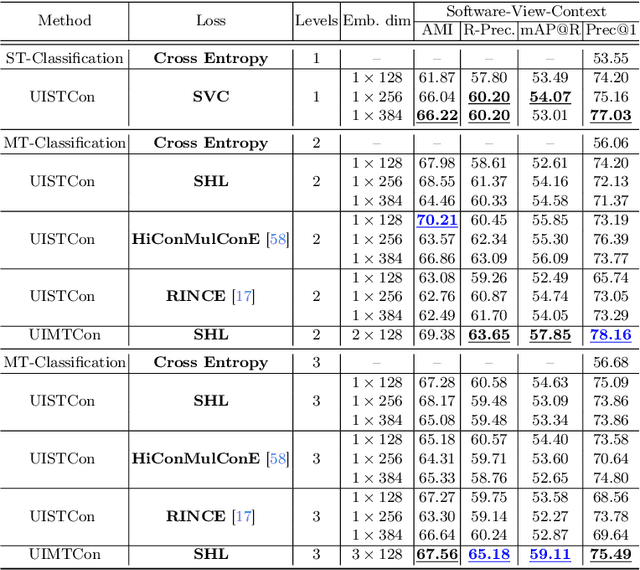
User Interface (UI) understanding has been an increasingly popular topic over the last few years. So far, there has been a vast focus solely on web and mobile applications. In this paper, we introduce the harder task of computer UI understanding. With the goal of enabling research in this field, we have generated a dataset with a set of videos where a user is performing a sequence of actions and each image shows the desktop contents at that time point. We also present a framework that is composed of a synthetic sample generation pipeline to augment the dataset with relevant characteristics, and a contrastive learning method to classify images in the videos. We take advantage of the natural conditional, tree-like, relationship of the images' characteristics to regularize the learning of the representations by dealing with multiple partial tasks simultaneously. Experimental results show that the proposed framework outperforms previously proposed hierarchical multi-label contrastive losses in fine-grain UI classification.
Lifelong LERF: Local 3D Semantic Inventory Monitoring Using FogROS2
Mar 15, 2024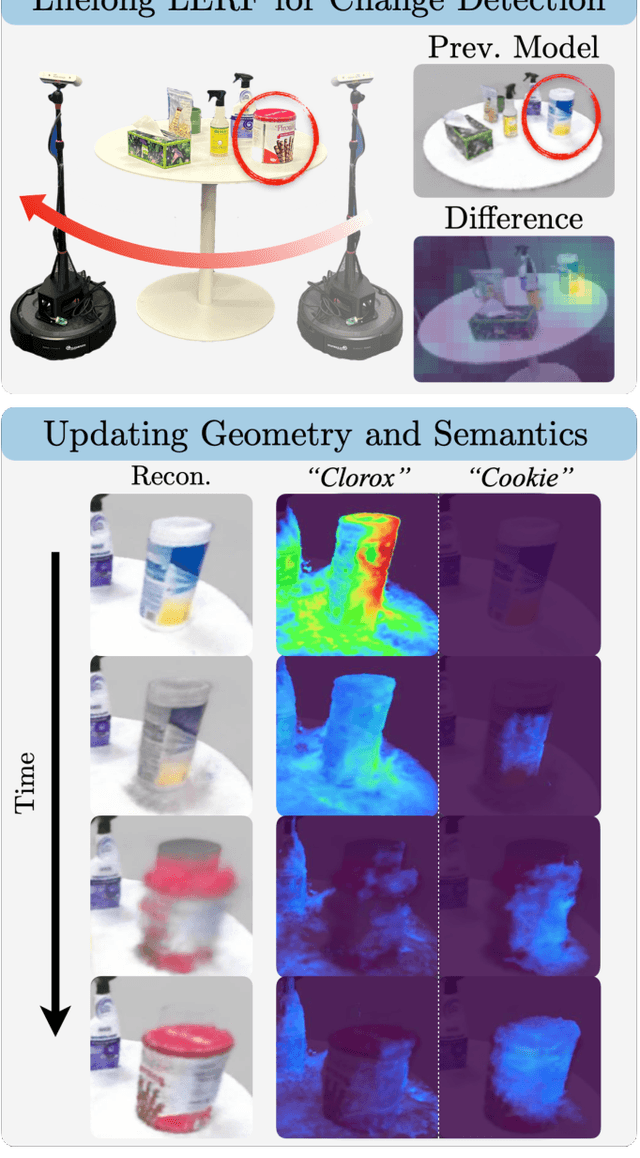
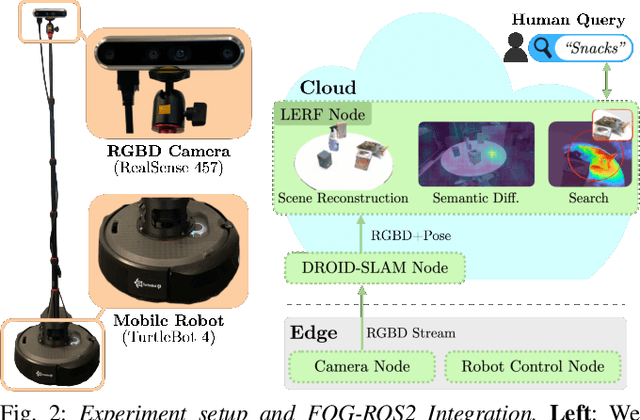
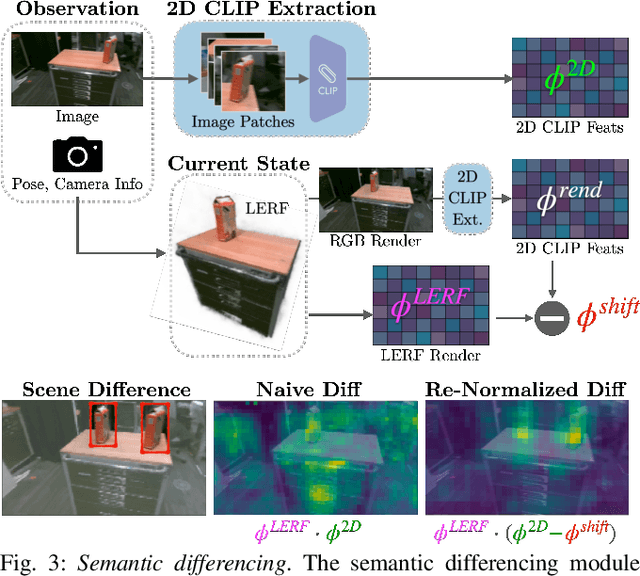

Inventory monitoring in homes, factories, and retail stores relies on maintaining data despite objects being swapped, added, removed, or moved. We introduce Lifelong LERF, a method that allows a mobile robot with minimal compute to jointly optimize a dense language and geometric representation of its surroundings. Lifelong LERF maintains this representation over time by detecting semantic changes and selectively updating these regions of the environment, avoiding the need to exhaustively remap. Human users can query inventory by providing natural language queries and receiving a 3D heatmap of potential object locations. To manage the computational load, we use Fog-ROS2, a cloud robotics platform, to offload resource-intensive tasks. Lifelong LERF obtains poses from a monocular RGBD SLAM backend, and uses these poses to progressively optimize a Language Embedded Radiance Field (LERF) for semantic monitoring. Experiments with 3-5 objects arranged on a tabletop and a Turtlebot with a RealSense camera suggest that Lifelong LERF can persistently adapt to changes in objects with up to 91% accuracy.
Real-Time Planning Under Uncertainty for AUVs Using Virtual Maps
Mar 07, 2024
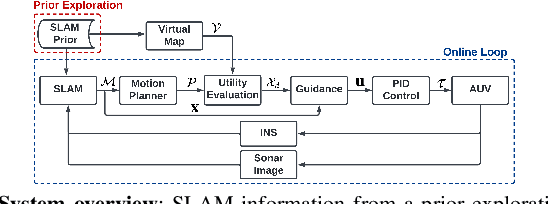
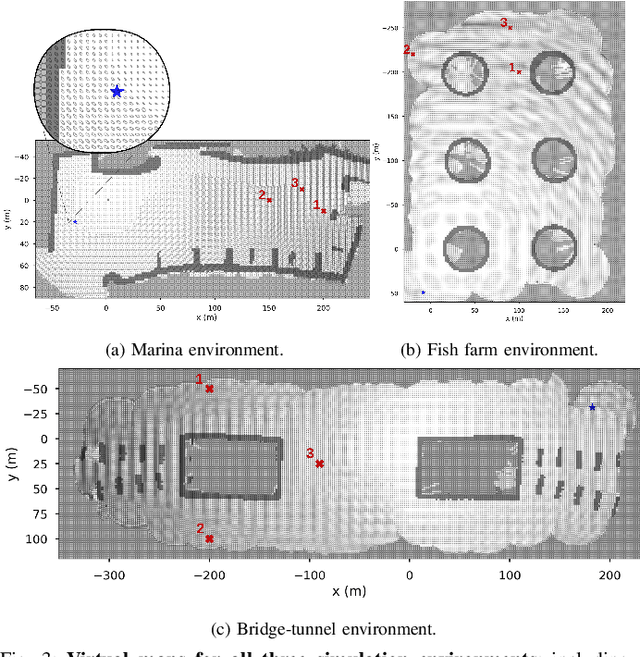
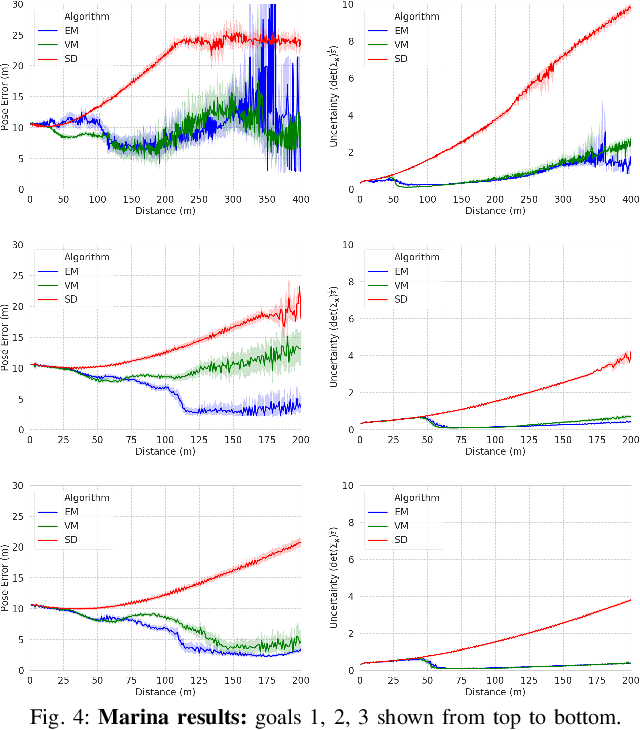
Reliable localization is an essential capability for marine robots navigating in GPS-denied environments. SLAM, commonly used to mitigate dead reckoning errors, still fails in feature-sparse environments or with limited-range sensors. Pose estimation can be improved by incorporating the uncertainty prediction of future poses into the planning process and choosing actions that reduce uncertainty. However, performing belief propagation is computationally costly, especially when operating in large-scale environments. This work proposes a computationally efficient planning under uncertainty frame-work suitable for large-scale, feature-sparse environments. Our strategy leverages SLAM graph and occupancy map data obtained from a prior exploration phase to create a virtual map, describing the uncertainty of each map cell using a multivariate Gaussian. The virtual map is then used as a cost map in the planning phase, and performing belief propagation at each step is avoided. A receding horizon planning strategy is implemented, managing a goal-reaching and uncertainty-reduction tradeoff. Simulation experiments in a realistic underwater environment validate this approach. Experimental comparisons against a full belief propagation approach and a standard shortest-distance approach are conducted.