 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fruit Picker Activity Recognition with Wearable Sensors and Machine Learning
Apr 20, 2023

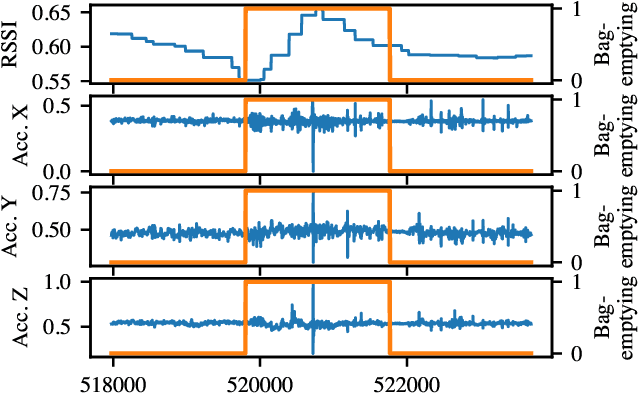
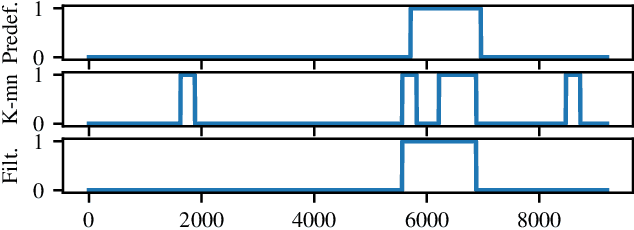
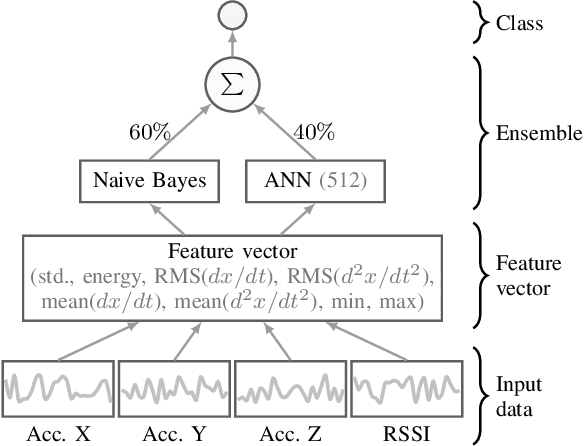
In this paper we present a novel application of detecting fruit picker activities based on time series data generated from wearable sensors. During harvesting, fruit pickers pick fruit into wearable bags and empty these bags into harvesting bins located in the orchard. Once full, these bins are quickly transported to a cooled pack house to improve the shelf life of picked fruits. For farmers and managers, the knowledge of when a picker bag is emptied is important for managing harvesting bins more effectively to minimise the time the picked fruit is left out in the heat (resulting in reduced shelf life). We propose a means to detect these bag-emptying events using human activity recognition with wearable sensors and machine learning methods. We develop a semi-supervised approach to labelling the data. A feature-based machine learning ensemble model and a deep recurrent convolutional neural network are developed and tested on a real-world dataset. When compared, the neural network achieves 86% detection accuracy.
MetaMorphosis: Task-oriented Privacy Cognizant Feature Generation for Multi-task Learning
May 13, 2023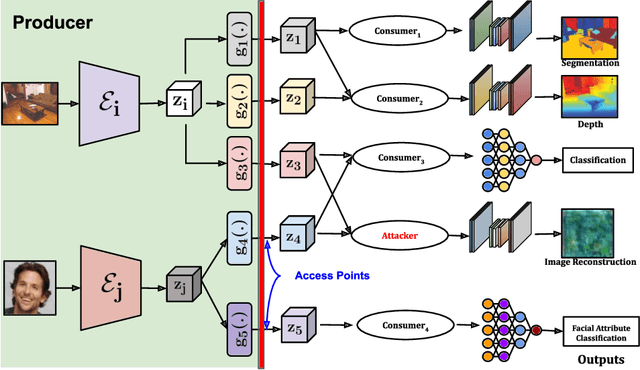

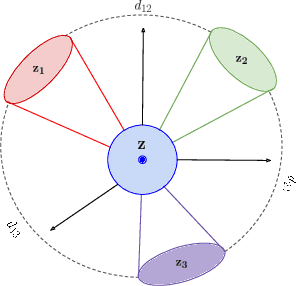
With the growth of computer vision applications, deep learning, and edge computing contribute to ensuring practical collaborative intelligence (CI) by distributing the workload among edge devices and the cloud. However, running separate single-task models on edge devices is inefficient regarding the required computational resource and time. In this context, multi-task learning allows leveraging a single deep learning model for performing multiple tasks, such as semantic segmentation and depth estimation on incoming video frames. This single processing pipeline generates common deep features that are shared among multi-task modules. However, in a collaborative intelligence scenario, generating common deep features has two major issues. First, the deep features may inadvertently contain input information exposed to the downstream modules (violating input privacy). Second, the generated universal features expose a piece of collective information than what is intended for a certain task, in which features for one task can be utilized to perform another task (violating task privacy). This paper proposes a novel deep learning-based privacy-cognizant feature generation process called MetaMorphosis that limits inference capability to specific tasks at hand. To achieve this, we propose a channel squeeze-excitation based feature metamorphosis module, Cross-SEC, to achieve distinct attention of all tasks and a de-correlation loss function with differential-privacy to train a deep learning model that produces distinct privacy-aware features as an output for the respective tasks. With extensive experimentation on four datasets consisting of diverse images related to scene understanding and facial attributes, we show that MetaMorphosis outperforms recent adversarial learning and universal feature generation methods by guaranteeing privacy requirements in an efficient way for image and video analytics.
PESTS: Persian_English Cross Lingual Corpus for Semantic Textual Similarity
May 13, 2023

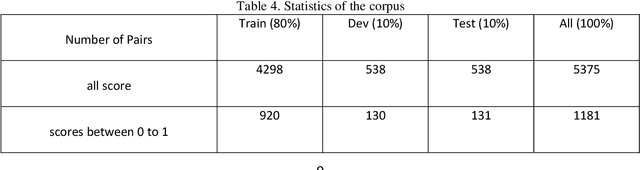
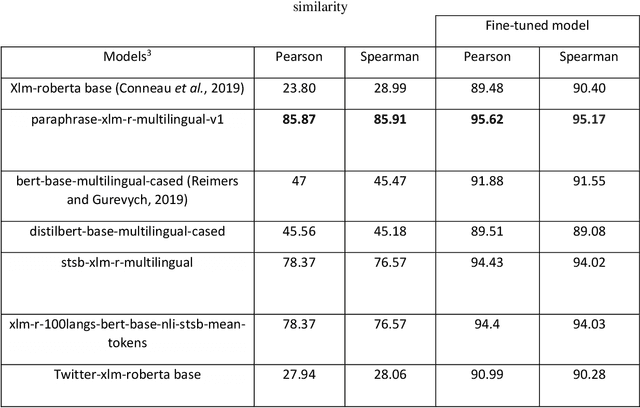
One of the components of natural language processing that has received a lot of investigation recently is semantic textual similarity. In computational linguistics and natural language processing, assessing the semantic similarity of words, phrases, paragraphs, and texts is crucial. Calculating the degree of semantic resemblance between two textual pieces, paragraphs, or phrases provided in both monolingual and cross-lingual versions is known as semantic similarity. Cross lingual semantic similarity requires corpora in which there are sentence pairs in both the source and target languages with a degree of semantic similarity between them. Many existing cross lingual semantic similarity models use a machine translation due to the unavailability of cross lingual semantic similarity dataset, which the propagation of the machine translation error reduces the accuracy of the model. On the other hand, when we want to use semantic similarity features for machine translation the same machine translations should not be used for semantic similarity. For Persian, which is one of the low resource languages, no effort has been made in this regard and the need for a model that can understand the context of two languages is felt more than ever. In this article, the corpus of semantic textual similarity between sentences in Persian and English languages has been produced for the first time by using linguistic experts. We named this dataset PESTS (Persian English Semantic Textual Similarity). This corpus contains 5375 sentence pairs. Also, different models based on transformers have been fine-tuned using this dataset. The results show that using the PESTS dataset, the Pearson correlation of the XLM ROBERTa model increases from 85.87% to 95.62%.
Uncoordinated Interference Avoidance Between Terrestrial and Non-Terrestrial Communications
Apr 14, 2023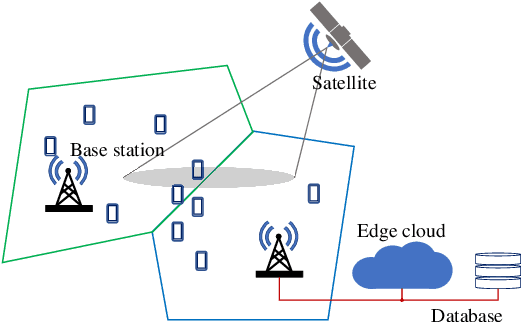

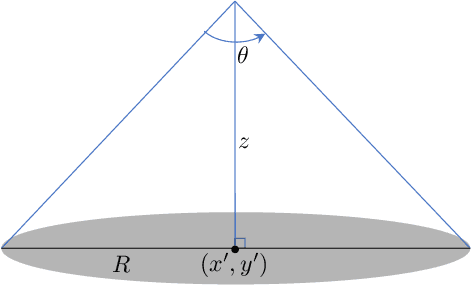
This paper proposes an algorithm that uses geospatial analytics and the muting of physical resources in next-generation base stations (BSs) to avoid interference between cellular (or terrestrial) and satellite communication systems as non-terrestrial systems. The information exchange between satellite and terrestrial links is very limited, but a hybrid edge cloud node with access to satellite trajectories can enable these BSs to take proactive measures. We show simulation results to validate the superiority of our proposed algorithm over a conventional method. Our algorithm runs in polynomial time, making it suitable for real-time interference avoidance.
Sensing User's Channel and Location with Terahertz Extra-Large Reconfigurable Intelligent Surface under Hybrid-Field Beam Squint Effect
May 12, 2023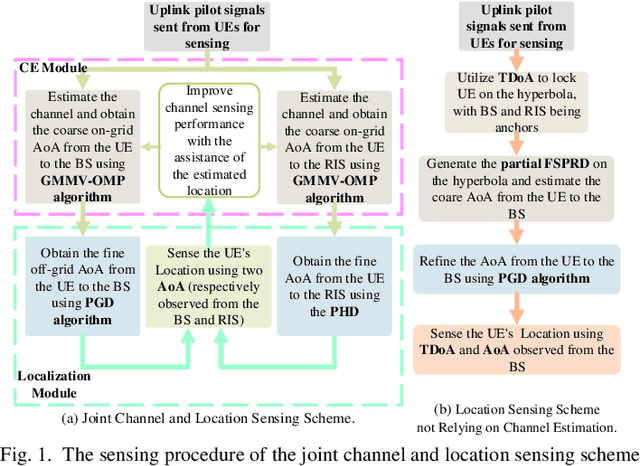
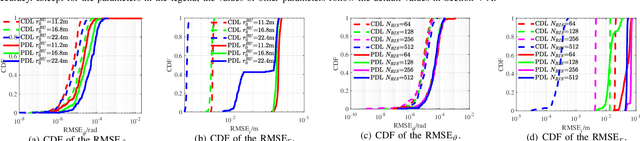
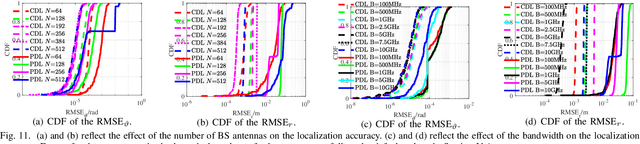
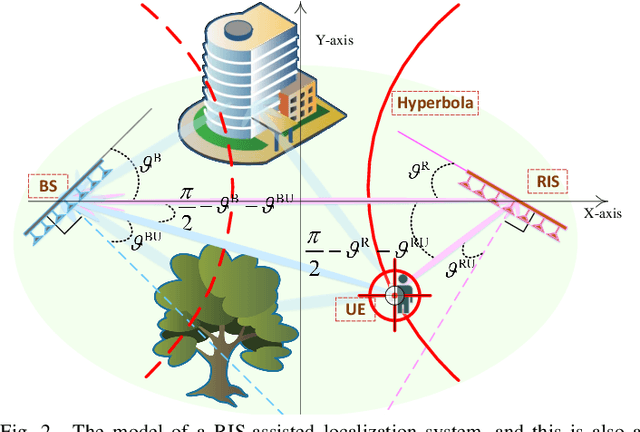
This paper investigates the sensing of user's uplink channel and location in terahertz extra-large reconfigurable intelligent surface (XL-RIS) systems, where the unique hybrid far-near field effect and the beam squint effect caused by the XL array aperture as well as the XL bandwidth are overcome. Specifically, we first propose a joint channel and location sensing scheme, which consists of a location-assisted generalized multiple measurement vector orthogonal matching pursuit (LA-GMMV-OMP) algorithm for channel estimation (CE) and a complete dictionary based localization (CDL) scheme, where a frequency selective polar-domain redundant dictionary is proposed to overcome the hybrid field beam squint effect. The CE module outputs coarse on-grid angle estimation (respectively observed from the BS and RIS) to the localization module, which returns the fine off-grid angle estimation to improve CE. Particularly, with RIS, CDL can obtain user's location via line intersection, and a polar-domain gradient descent (PGD) algorithm at the base station is proposed to achieve the off-grid angle estimation with super-resolution accuracy. Additionally, to further reduce the sensing overhead, we propose a partial dictionary-based localization scheme, which is decoupled from CE, where RIS is served as an anchor to lock the user on the hyperbola according to time difference of arrival and the user's off-grid location can be obtained by using the proposed PGD algorithm. Simulation results demonstrate the superiority of the two proposed localization schemes and the proposed CE scheme over state-of-the-art baseline approaches.
An Intelligent SDWN Routing Algorithm Based on Network Situational Awareness and Deep Reinforcement Learning
May 12, 2023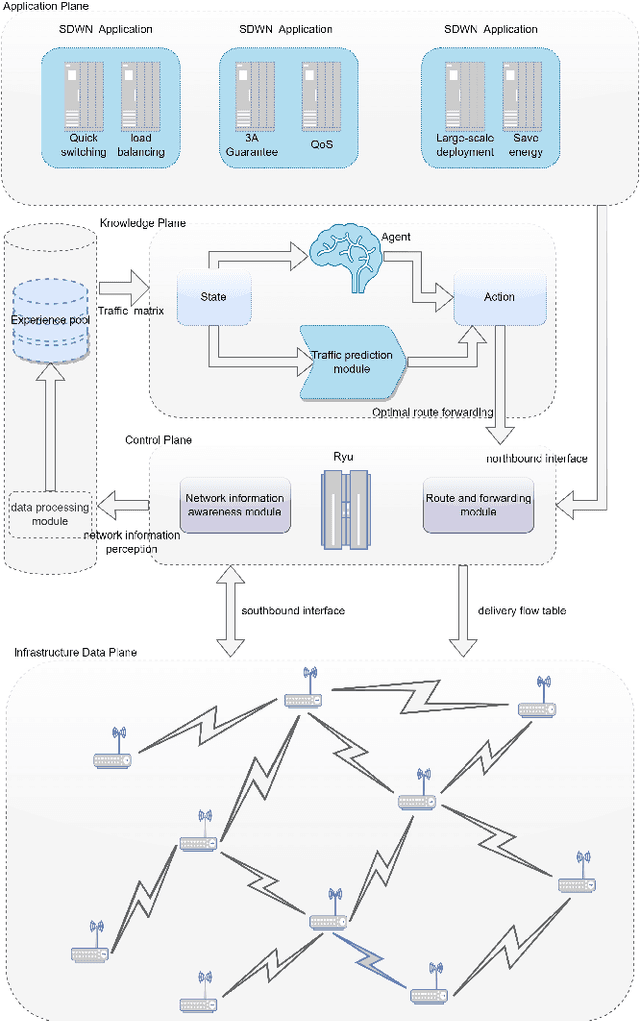
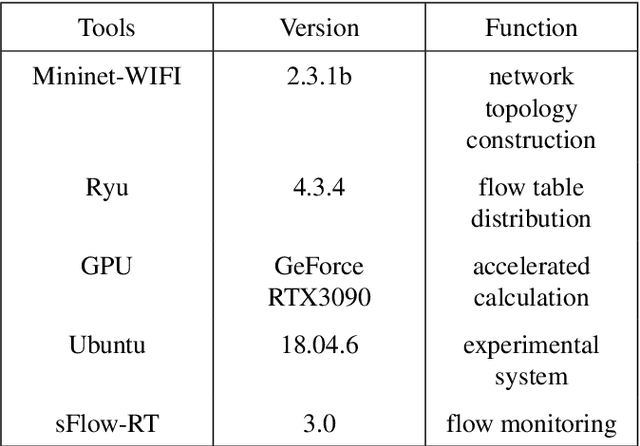
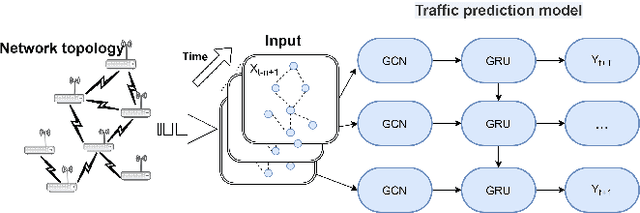
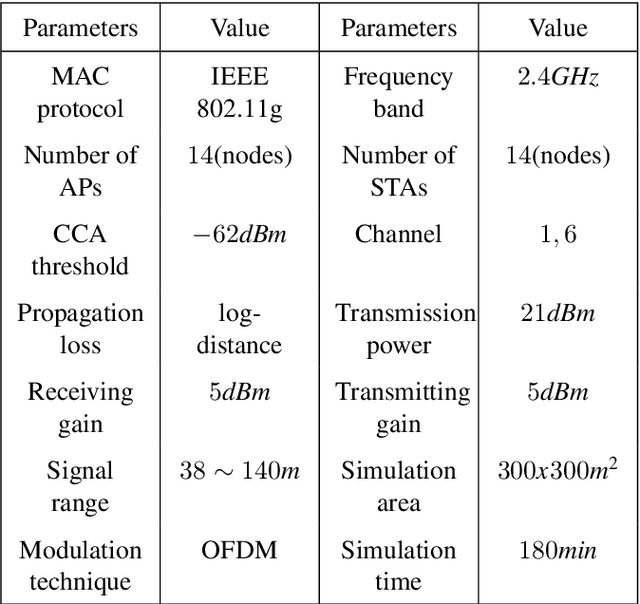
Due to the highly dynamic changes in wireless network topologies, efficiently obtaining network status information and flexibly forwarding data to improve communication quality of service are important challenges. This article introduces an intelligent routing algorithm (DRL-PPONSA) based on proximal policy optimization deep reinforcement learning with network situational awareness under a software-defined wireless networking architecture. First, a specific data plane is designed for network topology construction and data forwarding. The control plane collects network traffic information, sends flow tables, and uses a GCN-GRU prediction mechanism to perceive future traffic change trends to achieve network situational awareness. Second, a DRL-based data forwarding mechanism is designed in the knowledge plane. The predicted network traffic matrix and topology information matrix are treated as the environment for DRL agents, while next-hop adjacent nodes are treated as executable actions. Accordingly, action selection strategies are designed for different network conditions to achieve more intelligent, flexible, and efficient routing control. The reward function is designed using network link information and various reward and penalty mechanisms. Additionally, importance sampling and gradient clipping techniques are employed during gradient updating to enhance convergence speed and stability. Experimental results show that DRL-PPONSA outperforms traditional routing methods in network throughput, delay, packet loss rate, and wireless node distance. Compared to value-function-based Dueling DQN routing, the convergence speed is significantly improved, and the convergence effect is more stable. Simultaneously, its consumption of hardware storage space is reduced, and efficient routing decisions can be made in real-time using the current network state information.
VR Facial Animation for Immersive Telepresence Avatars
Apr 24, 2023

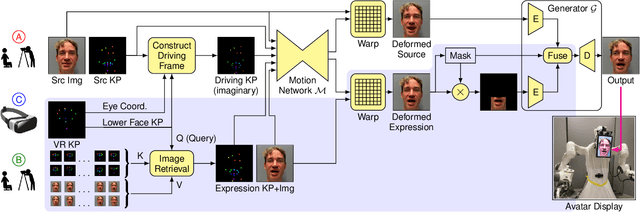
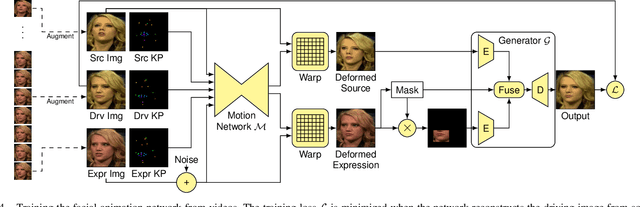
VR Facial Animation is necessary in applications requiring clear view of the face, even though a VR headset is worn. In our case, we aim to animate the face of an operator who is controlling our robotic avatar system. We propose a real-time capable pipeline with very fast adaptation for specific operators. In a quick enrollment step, we capture a sequence of source images from the operator without the VR headset which contain all the important operator-specific appearance information. During inference, we then use the operator keypoint information extracted from a mouth camera and two eye cameras to estimate the target expression and head pose, to which we map the appearance of a source still image. In order to enhance the mouth expression accuracy, we dynamically select an auxiliary expression frame from the captured sequence. This selection is done by learning to transform the current mouth keypoints into the source camera space, where the alignment can be determined accurately. We, furthermore, demonstrate an eye tracking pipeline that can be trained in less than a minute, a time efficient way to train the whole pipeline given a dataset that includes only complete faces, show exemplary results generated by our method, and discuss performance at the ANA Avatar XPRIZE semifinals.
Regions of Reliability in the Evaluation of Multivariate Probabilistic Forecasts
Apr 19, 2023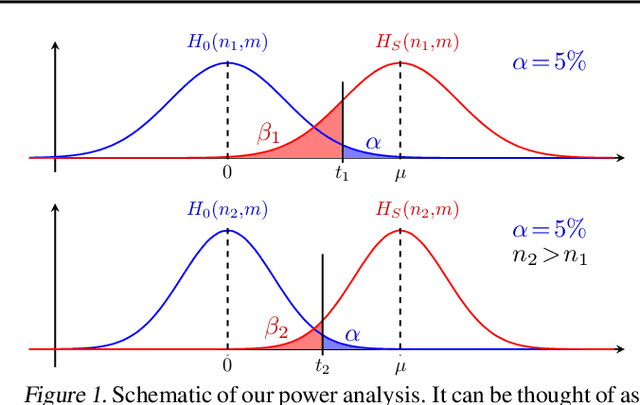
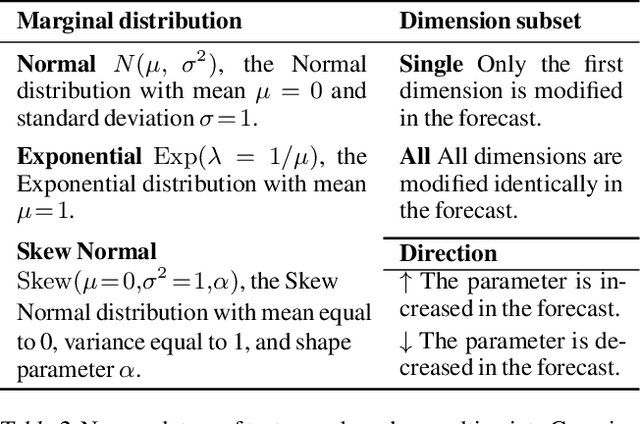

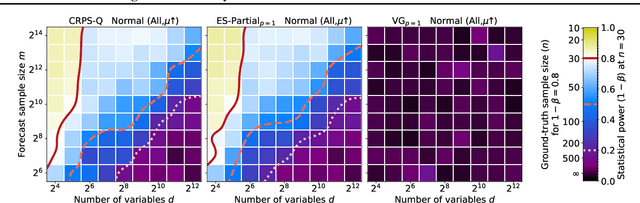
Multivariate probabilistic time series forecasts are commonly evaluated via proper scoring rules, i.e., functions that are minimal in expectation for the ground-truth distribution. However, this property is not sufficient to guarantee good discrimination in the non-asymptotic regime. In this paper, we provide the first systematic finite-sample study of proper scoring rules for time-series forecasting evaluation. Through a power analysis, we identify the "region of reliability" of a scoring rule, i.e., the set of practical conditions where it can be relied on to identify forecasting errors. We carry out our analysis on a comprehensive synthetic benchmark, specifically designed to test several key discrepancies between ground-truth and forecast distributions, and we gauge the generalizability of our findings to real-world tasks with an application to an electricity production problem. Our results reveal critical shortcomings in the evaluation of multivariate probabilistic forecasts as commonly performed in the literature.
CyFormer: Accurate State-of-Health Prediction of Lithium-Ion Batteries via Cyclic Attention
Apr 17, 2023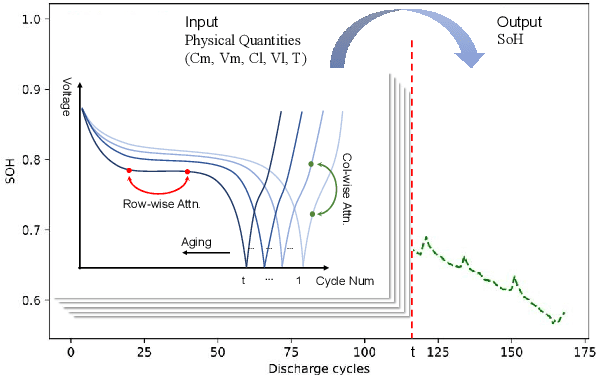
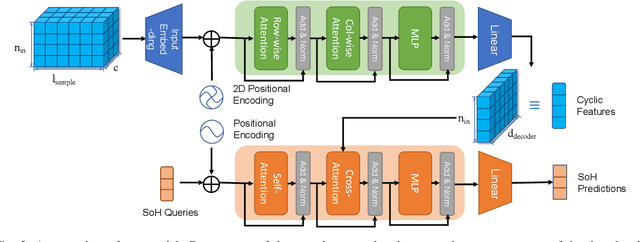
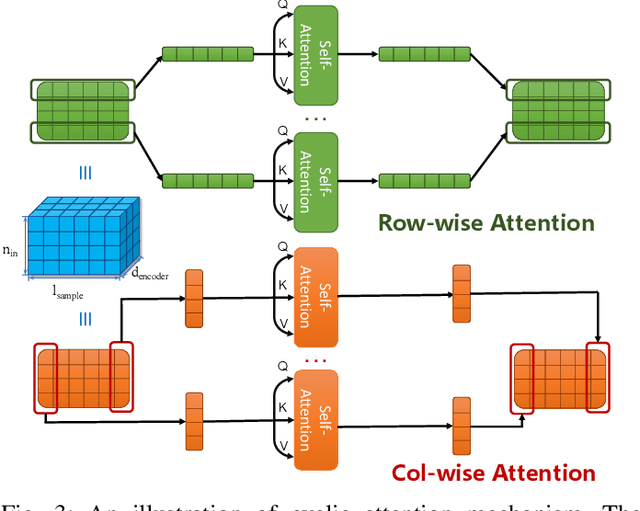
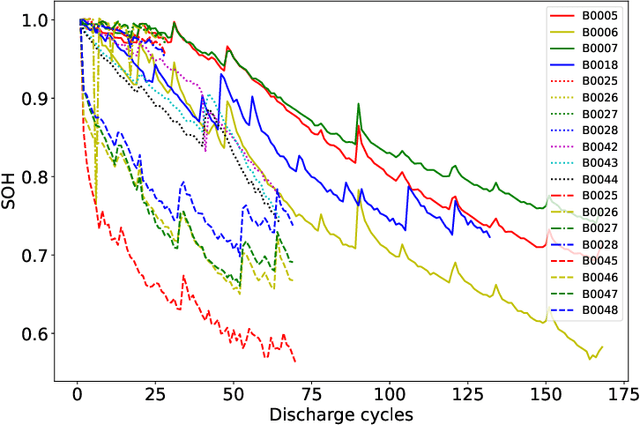
Predicting the State-of-Health (SoH) of lithium-ion batteries is a fundamental task of battery management systems on electric vehicles. It aims at estimating future SoH based on historical aging data. Most existing deep learning methods rely on filter-based feature extractors (e.g., CNN or Kalman filters) and recurrent time sequence models. Though efficient, they generally ignore cyclic features and the domain gap between training and testing batteries. To address this problem, we present CyFormer, a transformer-based cyclic time sequence model for SoH prediction. Instead of the conventional CNN-RNN structure, we adopt an encoder-decoder architecture. In the encoder, row-wise and column-wise attention blocks effectively capture intra-cycle and inter-cycle connections and extract cyclic features. In the decoder, the SoH queries cross-attend to these features to form the final predictions. We further utilize a transfer learning strategy to narrow the domain gap between the training and testing set. To be specific, we use fine-tuning to shift the model to a target working condition. Finally, we made our model more efficient by pruning. The experiment shows that our method attains an MAE of 0.75\% with only 10\% data for fine-tuning on a testing battery, surpassing prior methods by a large margin. Effective and robust, our method provides a potential solution for all cyclic time sequence prediction tasks.
Neural Operator Learning for Ultrasound Tomography Inversion
Apr 06, 2023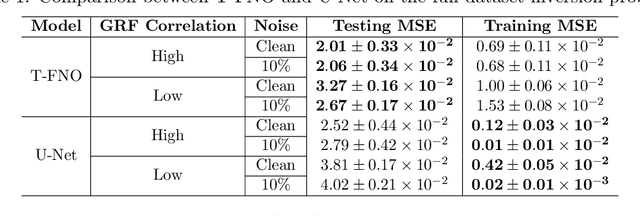
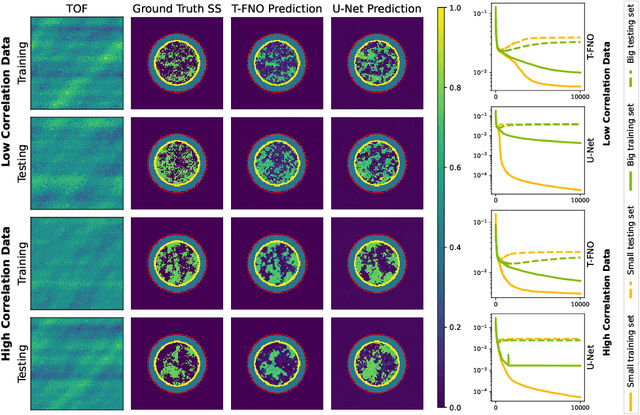
Neural operator learning as a means of mapping between complex function spaces has garnered significant attention in the field of computational science and engineering (CS&E). In this paper, we apply Neural operator learning to the time-of-flight ultrasound computed tomography (USCT) problem. We learn the mapping between time-of-flight (TOF) data and the heterogeneous sound speed field using a full-wave solver to generate the training data. This novel application of operator learning circumnavigates the need to solve the computationally intensive iterative inverse problem. The operator learns the non-linear mapping offline and predicts the heterogeneous sound field with a single forward pass through the model. This is the first time operator learning has been used for ultrasound tomography and is the first step in potential real-time predictions of soft tissue distribution for tumor identification in beast imaging.